Spark Day10: Spark Streaming
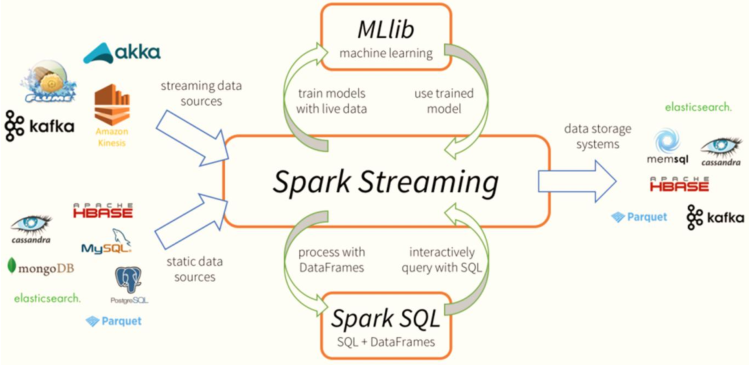
01 - [understand] - yesterday's course content review
Practical exercise: Taking the background of DMP advertising industry as an example, the processing of advertising click data is divided into two aspects [advertising data ETL conversion and business report development], as follows:
[[premise]: use SparkSQL Complete the case exercise and write the code
1,Advertising data ETL transformation
JSON Text data -> DataFrame: extract IP Address, parsed and converted to province and city -> Save to Hive Partition table
data source
File system( HDFS,LocalFS)Text file data: JSON format
data processing
ip Address, converting provinces and cities
Implementation: Using DSL Programming, you can call similar SQL Similar statements and functions can also be called RDD Conversion functions, such as mapPartitions
Data terminal Sink
Hive Partition table
2,Business report analysis
[Premise]: by default, the data of the previous day is analyzed each time
Data flow:
Hive Partition table -> DataFrame: Report analysis and statistics based on business -> MySQL In database table
[[note]:
a. When loading data, consider filtering and only obtain the data of the previous day
b. During report analysis
use SQL Programming, relatively easy
Can consider DSL programming
c. When saving data
Cannot be used directly SparkSQL Provide external data source interface and use the original ecology JDBC
dataframe.rdd.foreachPartition(iter => saveToMySQL(iter))
[Extend]: to MySQL When the table writes data, the upsert[If the primary key exists, it will be updated; if it does not exist, it will be inserted
- Method 1: use REPALCE replace INSERT
replace INTO db_test.tb_wordcount (word, count) VALUES(?, ?)
In this way, there are some limitations, such as the need to list all columns
- Mode 2: ON DUPLICATE KEY UPDATE
INSERT INTO ods_qq_group_members ( gid, uin, datadate )
VALUES (111, 1111111, '2016-11-29' )
ON DUPLICATE KEY UPDATE gid=222, uin=22222, datadate='2016-11-29'
02 - [understand] - outline of today's course content
Starting today, let's enter Spark framework: Explanation on streaming data analysis module.
- SparkCore and SparkSQL, offline analysis batch processing, and analysis data are static and unchanged
- SparkStreaming and StructuredStreaming are real-time streaming data analysis. The analysis data is generated continuously and analyzed as soon as it is generated
Firstly, learn the SparkStreaming streaming computing module to process streaming data with batch processing idea for real-time analysis.
1,Streaming Overview of flow computing Streaming At present, there are many application scenarios Lambda Architecture, offline and real-time Streaming Calculation mode SparkStreaming Computational thought 2,Introductory case Word frequency statistics of official case operation“ Programming implementation code: SparkStreaming Introductory programming Streaming working principle How to use the idea of batch to process streaming data 3,DStream: Separated and discrete flow DStream What is it? DStream = Seq[RDD] DStream Operations Functions are divided into two categories: conversion functions and output functions Streaming application status
03 - [understand] - data structure abstraction of each module in Spark framework
Spark framework is a unified analysis engine, which contains many modules. Each module has a data structure to encapsulate data.
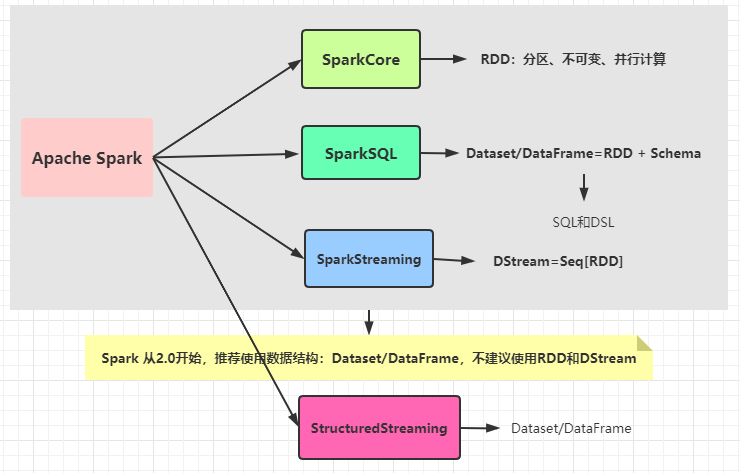
stay Spark1.x The main three modules are encapsulated by their own data structure - SparkCore: RDD - SparkSQL: DataFrame/Dataset - SparkStreaming: DStream reach Spark2.x It is recommended to use SparkSQL Analysis of offline data and streaming data Dataset/DataFrame appear StructuredStreaming Module, encapsulating streaming data into Dataset In, use DSL and SQL Analyze streaming data
04 - [understand] - streaming application scenario overview of streaming
- 1) E-commerce real-time large screen: at double eleven every year, the real-time order sales and product quantity of Taobao and JD are displayed on a large screen

- 2) Commodity recommendation: Jingdong and Taobao shopping malls have commodity recommendation modules in shopping carts, commodity details and other places
- 3) Industrial big data: in the current workshop, equipment can be networked to report their own operation status, which can be targeted at the application layer
These data are used to analyze the operation status and robustness, and show the completion status and operation status of the workpiece
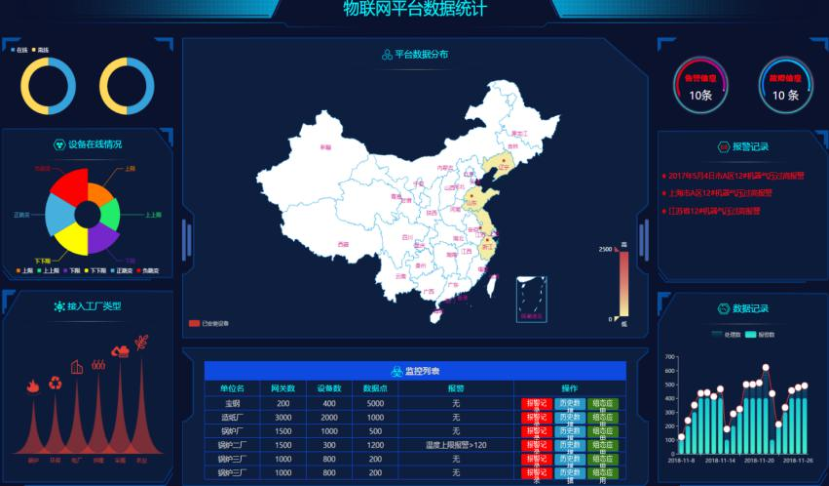
- 4) Cluster monitoring: general large clusters and platforms need to be monitored
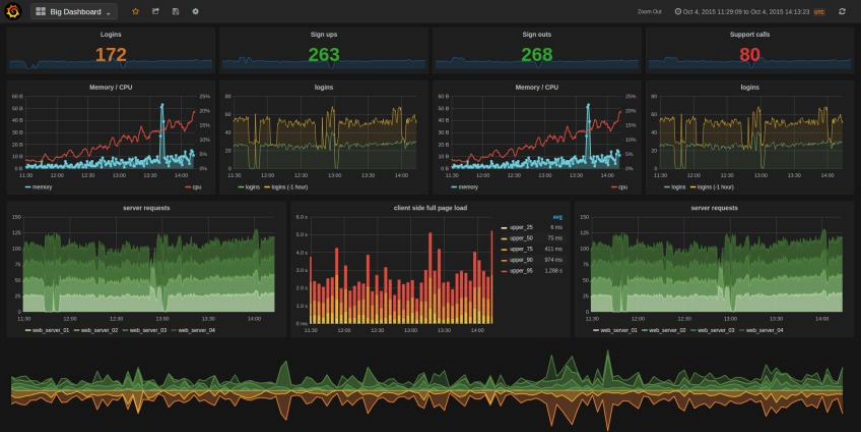
Specifically, the application scenarios of streaming computing are as follows:

05 - [Master] - Lambda architecture of Straming overview
Lambda architecture is a real-time big data processing framework proposed by Nathan Marz, the author of Storm.
- The big data architecture can only conduct offline data analysis and real-time data calculation.
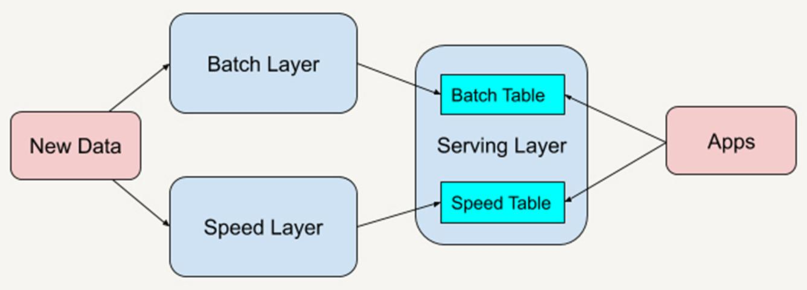
Lambda The architecture is divided into three layers: - first floor: Batch Layer Batch layer Data offline analysis - The second floor: Speed Layer Velocity layer Data real-time calculation - Third floor: ServingLayer Service layer Provide external services for offline analysis and real-time calculation results, such as visual display
Lambda architecture integrates offline computing and real-time computing, integrates a series of architecture principles such as immutability, read-write separation and complexity isolation, and can integrate Hadoop, Kafka, Storm, Spark, Hbase and other big data components.
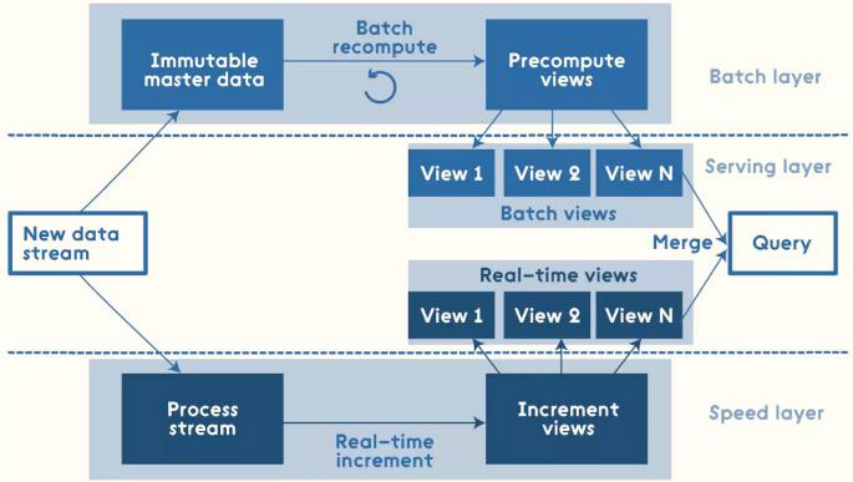
for instance: [Annual double 11 Carnival Shopping Festival, the number of user transaction orders on that day] - Point 1: real time statistics of sales in transaction orders totalAmt Finally, it will be displayed on the large screen in real time - Second point: 11.11 Later, 11.12 In the early morning, we began to analyze the transaction data of the previous day Which province is the worst loser Which city has the best female consumption Whether real-time computing or offline analysis, it needs to be displayed in the end Provide data for calculation and analysis
Lambda architecture solves this problem by decomposing three-tier architecture: Batch Layer, SpeedLayer and Serving Layer.
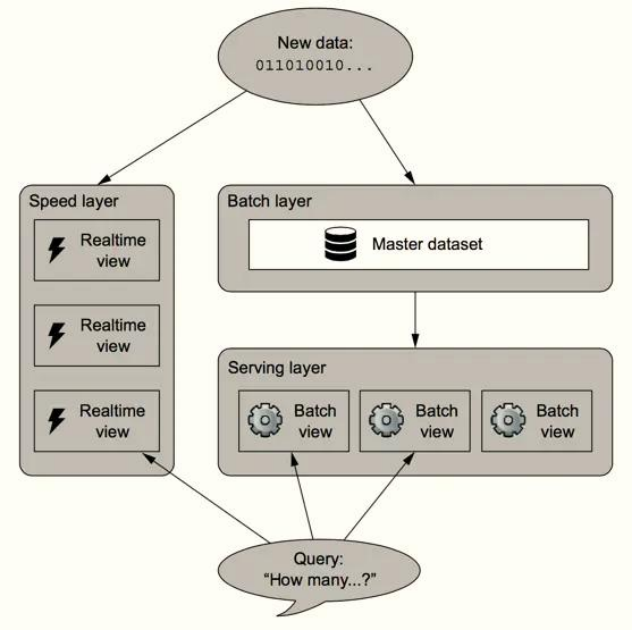
06 - [Master] - streaming data computing mode outlined by streaming
At present, there are several streaming computing frameworks in the field of big data framework:
- 1) . Storm framework
- Alibaba double 11 used this framework a few years ago
- 2) , Samza, open source of Lingying company
- It relies heavily on Kafka and is rarely used by domestic companies
- 3),SparkStreaming
- The upstream computing framework based on SparkCore is not widely used at present
- 4) , Flink framework
- At present, the most popular framework in the field of big data streaming computing, especially in China, is widely promoted. It is used by all major manufacturers, with high real-time performance and large throughput, especially in Alibaba.
- 5),StructuredStreaming
- For streaming data processing function module in SparkSQL framework
- Proposed from Spark2.0, it is relatively excellent. When many companies use SparkSQL, if streaming data needs real-time processing, they directly choose structured streaming
Different streaming processing frameworks have different characteristics and adapt to different scenarios. There are mainly the following two modes.
In general, the streaming computing engine (framework) processes streaming data (there are 2 patterns)
- Mode 1: Native stream processing
All input records will be processed one by one. Storm and Flink mentioned above adopt this method;
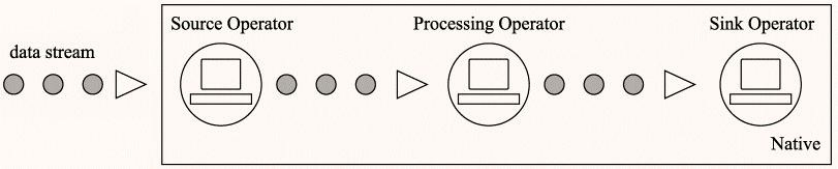
Generate a piece of data and process a piece of data. This kind of framework processes data very fast and has high real-time performance
- Mode 2: Micro Batch
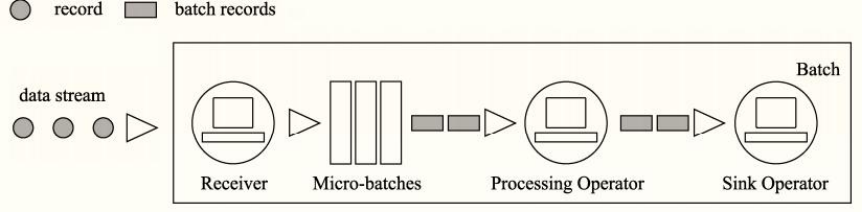
Micro batch processing divides streaming data into many batches, often according to time intervals, such as 1 second, for processing and analysis
about Spark in StructuredStreaming Structured six - By default, it belongs to micro batch mode Batch by batch processing data - Spark 2.3 Start, Continues Processing Continuous stream processing is the native stream pattern analysis data
07 - [Master] - SparkStreaming's computing idea of Straming overview
Spark Streaming is an important framework in spark ecosystem. It is based on Spark Core. The following figure also shows the status of Spark Streaming in spark ecosystem.

Officially defined Spark Streaming module:

SparkStreaming It makes it easier for users to build scalable and fault-tolerant semantic streaming applications.
SparkStreaming is a real-time computing framework based on SparkCore. It can consume data from many data sources and process data in real time. It has the characteristics of high throughput and strong fault tolerance.

about Spark Streaming For example, stream data at time intervals BatchInterval Divided into many parts, each part Batch(Batch), for each batch of data Batch treat as RDD Conduct rapid analysis and processing. - First, divide streaming data according to time interval batchInterval,Like 1 second - Second, divide data into batches Batch Each batch of data is considered to be RDD - Third, when processing streaming data, only each batch is processed RDD that will do RDD Data analysis and processing
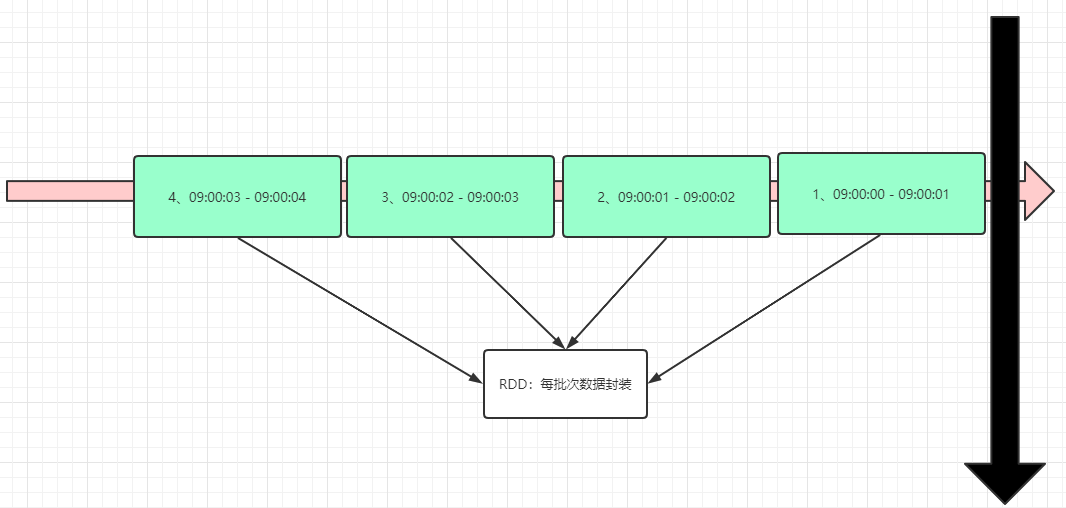
Data structure: DStream,Encapsulate streaming data Essentially a series of RDD A collection of, DStream Data streams can be divided in batches according to time intervals such as seconds and minutes

The streaming data is divided into many batches according to [X seconds]. Each Batch data is encapsulated in RDD for processing and analysis, and finally each Batch data is output.
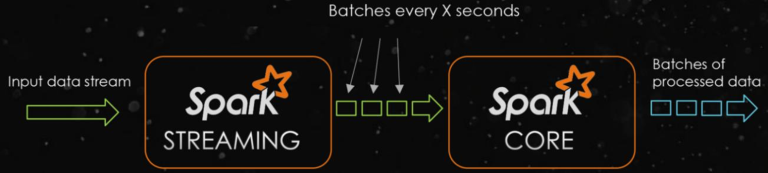
For the current version of Spark Streaming, the minimum Batch Size is between 0.5 and 5 seconds, so Spark Streaming can meet the streaming quasi real-time computing scenario,
08 - [Master] - running official word frequency statistics of introductory cases
SparkStreaming officially provides an Example case. Function Description: from the TCP Socket data source, real-time consumption data, word frequency statistics WordCount is carried out for each Batch of Batch data. The flow chart is as follows:
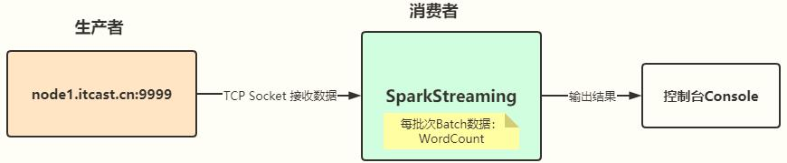
1,Data source: TCP Socket Where to read real-time data and then conduct real-time analysis 2,Data terminal: output console Where is the result data output 3,Function: real time statistics of each batch of data, time interval BatchInterval: 1s
Run the officially provided case and run it with the [$spark_home / bin / run example] command. The effect is as follows:
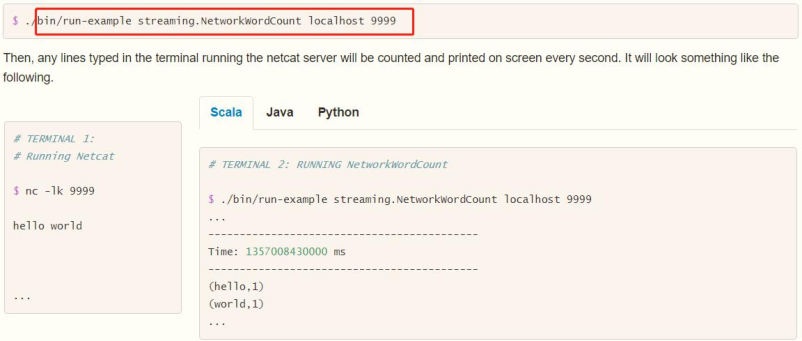
The specific steps are as follows:


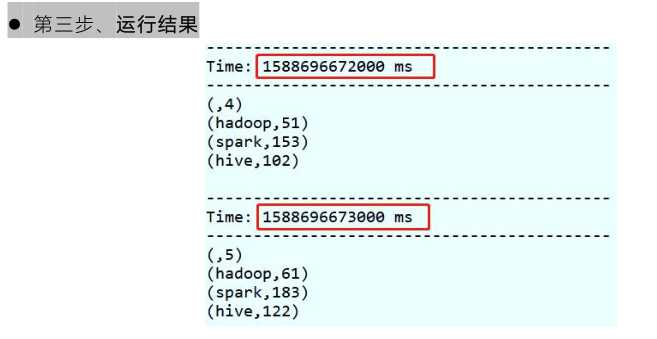
SparkStreaming module is used for streaming data processing, which is between Batch processing and RealTime real-time processing.
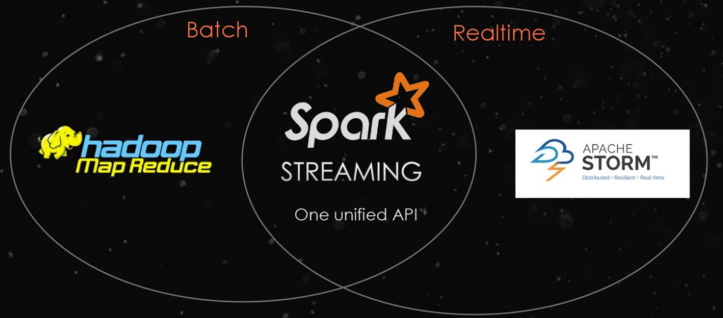
09 - [Master] - Streaming programming module of introductory case
Based on the IDEA integrated development environment, programming implementation: read the streaming data in real time from the TCP Socket, count the word frequency of the data in each batch, and WordCount.
stay Spark Each module in the framework has its own data structure and its own program entry: - SparkCore RDD SparkContext - SparkSQL DataFrame/Dataset SparkSession/SQLContext(Spark 1.x) - SparkStreaming DStream StreamingContext Parameter: split streaming data interval BatchInterval: 1s,5s((Demo) Bottom or SparkContext,Each batch of data as RDD
According to the official documents, there are two ways to build the StreamingContext instance object. The screenshot is as follows:
- The first way: build a SparkConf object
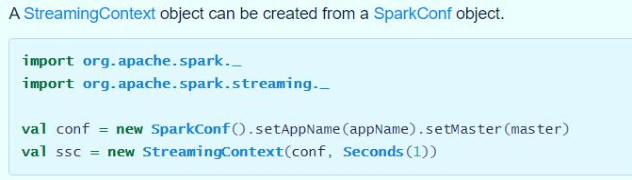
- The second method: build a SparkContext object
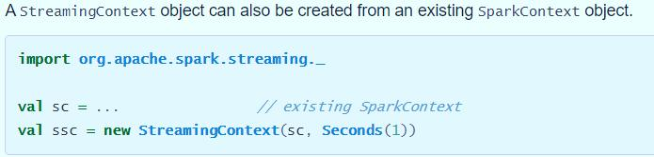
For SparkStreaming streaming applications, the code logic is roughly as follows:

Write the SparkStreaming program module, build the StreamingContext streaming context instance object, start the streaming application and wait for termination
package cn.itcast.spark.start
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Based on the IDEA integrated development environment, it is programmed to read streaming data in real time from TCP Socket and make word frequency statistics on the data in each batch.
*/
object _01StreamingWordCount {
def main(args: Array[String]): Unit = {
// TODO: 1. Build the StreamingContext instance object and pass the time interval BatchInterval
val ssc: StreamingContext = {
// Create a SparkConf object and set the application properties
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// Passing sparkConf object and time interval batchInterval: 5 seconds
new StreamingContext(sparkConf, Seconds(5))
}
// TODO: 2. Define data source, obtain streaming data, and package it into DStream
// TODO: 3. Call the conversion function in DStream (similar to the conversion function in RDD) according to business requirements
// TODO: 4. Define the data terminal and output the result data of each batch
// TODO: 5. Start streaming application and wait for termination
ssc.start() // Start the streaming application, start consuming data in real time from the data source, processing data and outputting results
// Streaming applications run as long as they are started, unless the program terminates abnormally or is considered terminated
ssc.awaitTermination()
// When the streaming application stops, the resource needs to be closed
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
10 - [Master] - code implementation and test run of introductory cases
Each streaming application (whether SparkStreaming, StructuredStreaming, or Flink) has three core steps
- Step 1: data source Source Where to consume streaming data in real time - Step 2: data conversion Transformation Process data by business Call function - Step 3: data terminal Sink Save the processing result data to the external system
package cn.itcast.spark.start
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Based on the IDEA integrated development environment, it is programmed to read streaming data in real time from TCP Socket and make word frequency statistics on the data in each batch.
*/
object _01StreamingWordCount {
def main(args: Array[String]): Unit = {
// TODO: 1. Build the StreamingContext instance object and pass the time interval BatchInterval
val ssc: StreamingContext = {
// Create a SparkConf object and set the application properties
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// Passing sparkConf object and time interval batchInterval: 5 seconds
new StreamingContext(sparkConf, Seconds(5))
}
// TODO: 2. Define data source, obtain streaming data, and package it into DStream
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node1.itcast.cn", 9999)
// TODO: 3. Call the conversion function in DStream (similar to the conversion function in RDD) according to business requirements
/*
spark hive hive spark spark hadoop
*/
val resultDStream: DStream[(String, Int)] = inputDStream
// Split word
.flatMap(line => line.trim.split("\\s+"))
// Convert to binary
.map(word => word -> 1)
// Group according to words and aggregate within the group
/*
(spark, 1)
(spark, 1) -> (spark, [1, 1]) (hive, [1]) -> (spark, 2) (hive, 1)
(hive, 1)
*/
.reduceByKey((tmp, itme) => tmp + itme)
// TODO: 4. Define the data terminal and output the result data of each batch
resultDStream.print()
// TODO: 5. Start streaming application and wait for termination
ssc.start() // Start the streaming application, start consuming data in real time from the data source, processing data and outputting results
// Streaming applications run as long as they are started, unless the program terminates abnormally or is considered terminated
ssc.awaitTermination()
// When the streaming application stops, the resource needs to be closed
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
Screenshot of operation result monitoring:
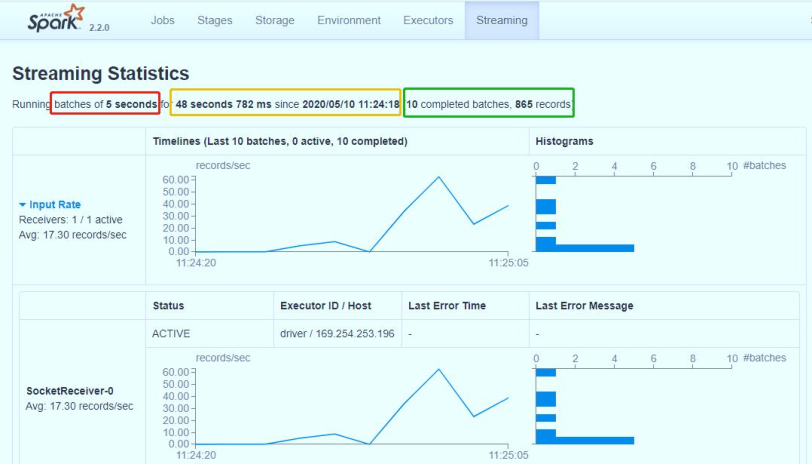
11 - [Master] - how SparkStreaming works in the introductory case
When SparkStreaming processes streaming data, it divides the data into micro batches according to the time interval, and each batch of data is treated as RDD for processing and analysis.

- Step 1: create StreamingContext
When the SparkStreaming streaming application starts (streamingContext.start), first create the StreamingContext streaming context instance object, build the whole streaming application environment, and the bottom layer is still SparkContext.

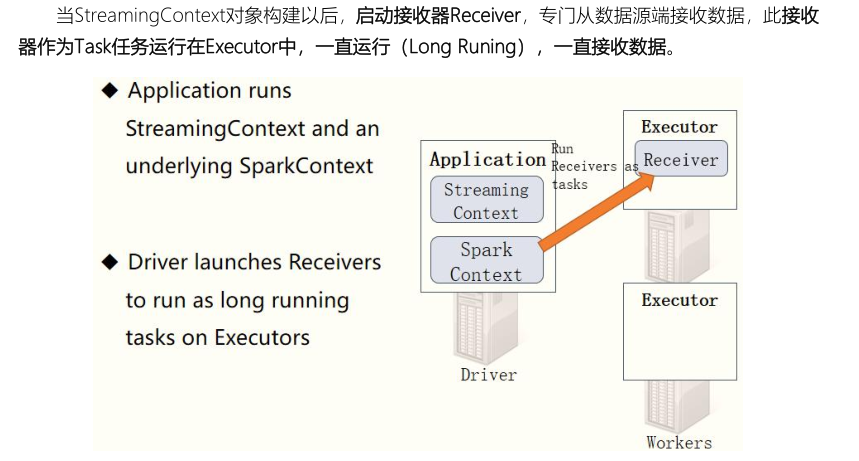
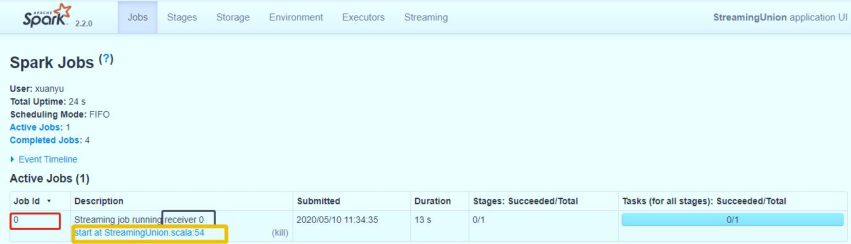
From the Jobs Tab on the WEB UI interface, you can see that Job-0 is a Receiver receiver that has been running. It runs in Task mode and requires 1Core CPU.
- Step 2: the receiver receives data
After each Receiver is started, it receives data from the data source in real time (such as TCP Socket), and also divides the received streaming data into many blocks (blocks) according to the time interval.
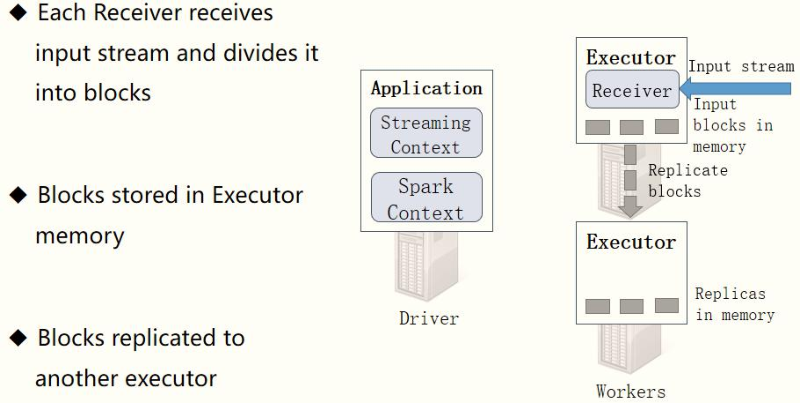
receiver Receiver Divide the time interval of streaming data BlockInterval , The default value is 200 ms , Pass attribute[ spark.streaming.blockInterval]set up. Hypothetical settings Batch Batch interval is 1 s,By default, there are several for each batch Block What about you??? 1s = 1000ms = 200ms * 5 So five block Treat the batch data as one RDD,here RDD The number of partitions is 5
- Step 3: receive the Block Report
The Receiver will report the block information corresponding to the received data in real time. When the BatchInterval time reaches, the StreamingContext will treat the data block within the corresponding time range as an RDD and load the SparkContext to process the data.
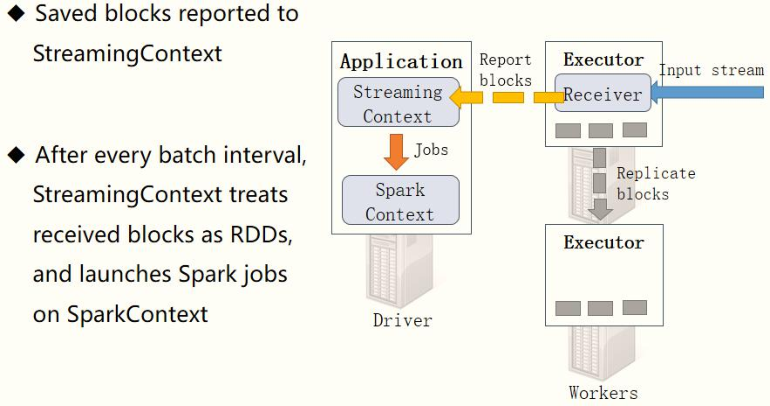
The streaming data is processed in this cycle, as shown in the following figure:
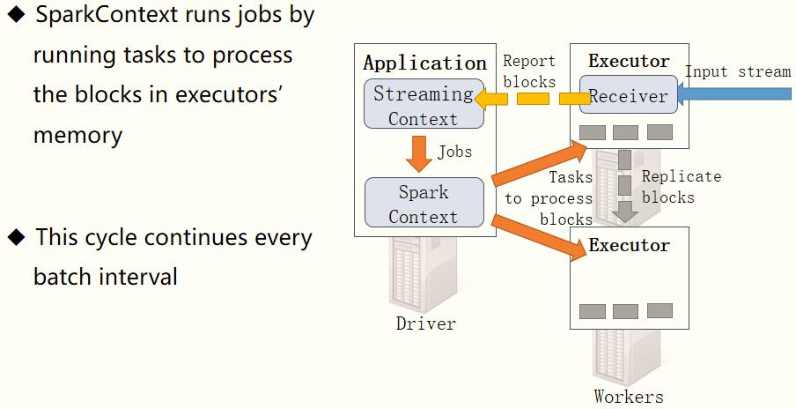
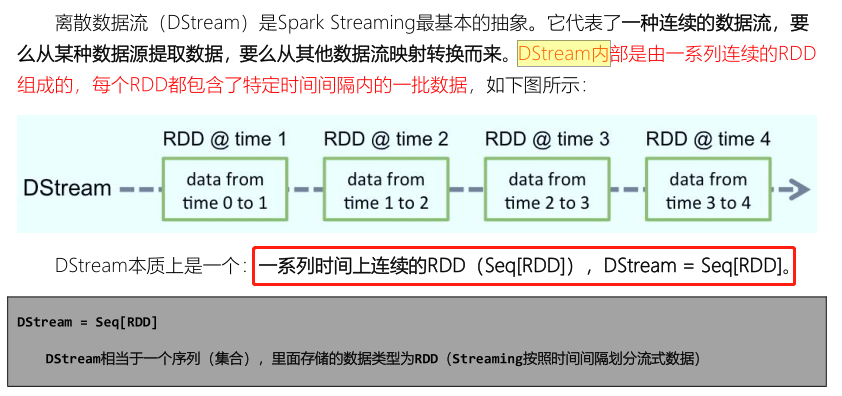
12 - [Master] - what is DStream
The SparkStreaming module encapsulates the data structure of streaming data: DStream (discrete stream, continuous data stream), which represents the continuous data stream and the result data stream after various Spark operators.
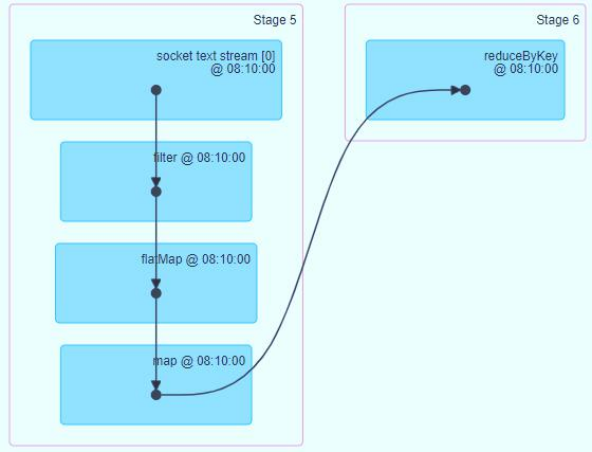
It can be seen from the WEB UI interface that when calling the function operation on DStream, the bottom layer is to operate on RDD. It is found that the functions in DStream are the same as those in RDD.
13 - [learn] - overview of DStream Operations function
DStream is similar to RDD. It contains many functions for data processing and output. It is mainly divided into two categories:

- First: Transformation function
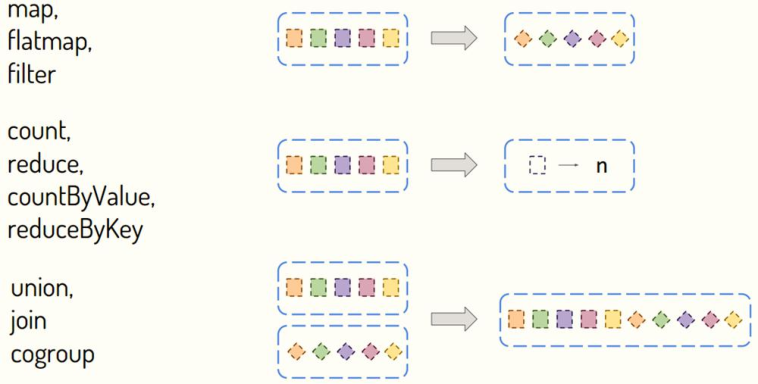
stay SparkStreaming There are three main conversion types for convection in: - Convert data in the stream map,flatMpa,filter - Data in convection involves aggregate statistics count reduce countByValue ... - Aggregate two streams union join cogroup
- Second: Output function [Output function]
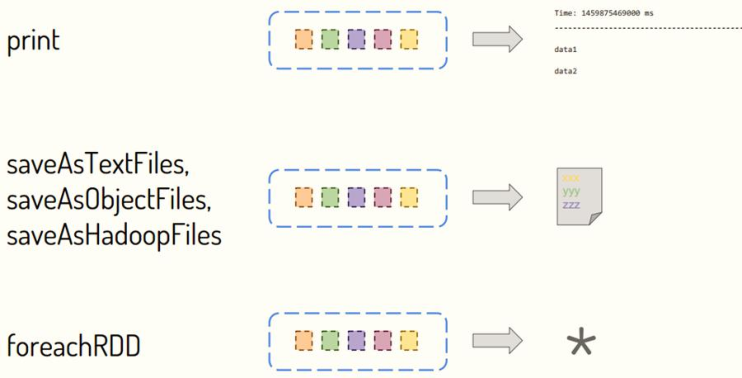
The foreachRDD function is used for the RDD output of each batch of results in DStream. The bottom layer of the print function used earlier also calls the foreachRDD function. The screenshot is as follows:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-1w2d8bg6-1638081078226)( https://gitee.com/the_efforts_paid_offf/picture-blog/raw/master/img/20211128142957.png )]
There are two important functions in DStream, which operate on RDD of each batch of data. They are closer to the bottom layer and have better performance. They are strongly recommended:

14 - [Master] - use of transform function in DStream
Understand the transform function through the source code. There are two method overloads. The declaration is as follows:

Next, use the transform function to modify the word frequency statistics program. The specific code is as follows:
package cn.itcast.spark.rdd
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Based on the IDEA integrated development environment, it is programmed to read streaming data in real time from TCP Socket and make word frequency statistics on the data in each batch.
*/
object _03StreamingTransformRDD {
def main(args: Array[String]): Unit = {
// TODO: 1. Build the StreamingContext instance object and pass the time interval BatchInterval
val ssc: StreamingContext = {
// a. Create a SparkConf object and set basic application information
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b. Create an instance object and set BatchInterval
new StreamingContext(sparkConf, Seconds(5))
}
// TODO: 2. Define data source, obtain streaming data, and package it into DStream
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: DStream[String] = ssc.socketTextStream(
"node1.itcast.cn",
9999,
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// TODO: 3. Call the conversion function in DStream (similar to the conversion function in RDD) according to business requirements
/*
TODO: If you can operate on RDD, do not operate on DStream. When calling a function in DStream also exists in RDD, use RDD operation
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// Here RDD is the RDD data of each batch in DStream
val resultDStream: DStream[(String, Int)] = inputDStream.transform{rdd =>
val resultRDD: RDD[(String, Int)] = rdd
// Split words by separator
.flatMap(line => line.split("\\s+"))
// Convert words to binary, indicating that each word occurs once
.map(word => word -> 1)
// Group according to words, aggregate reduce and sum the execution in the group
.reduceByKey((tmp, item) => tmp + item)
// RDD processing result of each batch returned
resultRDD
}
// TODO: 4. Define the data terminal and output the result data of each batch
resultDStream.print()
// TODO: 5. Start streaming application and wait for termination
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
View the DAG diagram of each Batch data execution Job in the WEB UI monitoring, and directly display the operation for RDD.
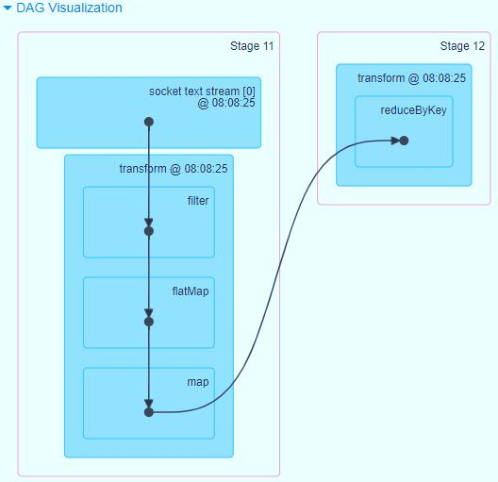
15 - [Master] - use of foreachRDD function in DStream
The foreachRDD function is an operation to output the result data RDD in DStream, similar to the transform function. For each batch of RDD data operation, the source code is declared as follows:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-gFQxcdhr-1638081078229)(/img/image-20210429113612287.png)]
Continue to modify the word frequency statistics code and customize the output data. The specific codes are as follows:
package cn.itcast.spark.output
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Based on the IDEA integrated development environment, it is programmed to read streaming data in real time from TCP Socket and make word frequency statistics on the data in each batch.
*/
object _04StreamingOutputRDD {
def main(args: Array[String]): Unit = {
// TODO: 1. Build the StreamingContext instance object and pass the time interval BatchInterval
val ssc: StreamingContext = {
// a. Create a SparkConf object and set basic application information
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// TODO: set the algorithm version of the data output file system to 2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b. Create an instance object and set BatchInterval
new StreamingContext(sparkConf, Seconds(5))
}
// TODO: 2. Define data source, obtain streaming data, and package it into DStream
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: DStream[String] = ssc.socketTextStream(
"node1.itcast.cn",
9999,
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// TODO: 3. Call the conversion function in DStream (similar to the conversion function in RDD) according to business requirements
/*
TODO: If you can operate on RDD, do not operate on DStream. When calling a function in DStream also exists in RDD, use RDD operation
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// Here RDD is the RDD data of each batch in DStream
val resultDStream: DStream[(String, Int)] = inputDStream.transform{ rdd =>
val resultRDD: RDD[(String, Int)] = rdd
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
// Return result RDD
resultRDD
}
// TODO: 4. Define the data terminal and output the result data of each batch
//resultDStream.print()
/*
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
rdd Represents the RDD of each batch processing result
time Indicates the time when the batch was generated, Long type
*/
resultDStream.foreachRDD((rdd, time) => {
// Print the generation time of each batch
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(time.milliseconds)
println("-------------------------------------------")
println(s"Batch Time: ${batchTime}")
println("-------------------------------------------")
// TODO: judge whether the result RDD has data. If there is data, output it. Otherwise, no operation will be performed
if(!rdd.isEmpty()){
// When outputting the result RDD: reduce the number of partitions, operate on each partition, and obtain connections through the sparkstreaming
val resultRDD: RDD[(String, Int)] = rdd.coalesce(1)
resultRDD.cache()
// Print results to RDD console
resultRDD.foreachPartition(iter => iter.foreach(println))
// Save the result RDD to a file
resultRDD.saveAsTextFile(s"datas/streaming-wc-${time.milliseconds}")
resultRDD.unpersist()
}
})
// TODO: 5. Start streaming application and wait for termination
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
16 - [understand] - three statuses of SparkStreaming streaming applications
When using SparkStreaming to process real-time application services, different functions need to be used according to different business requirements. SparkStreaming streaming streaming computing framework is mainly divided into three categories for specific services, and different functions are used for processing:
- Business 1: Stateless stateless
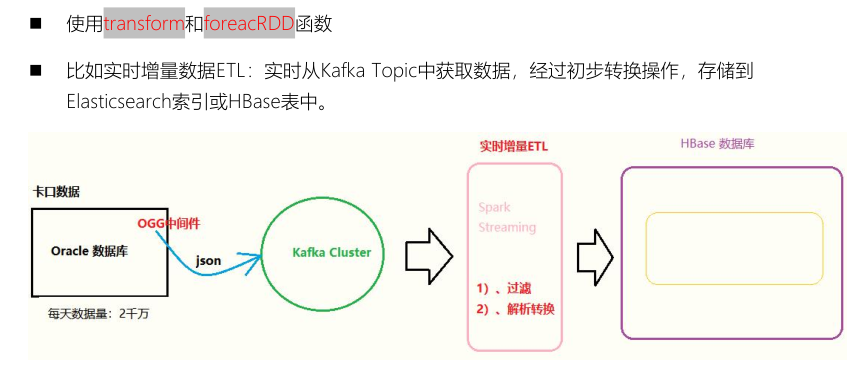
- Business 2: stateful State
- Business 3: window statistics
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-g0Xbre1z-1638081078231)(/img/image-20210429115034287.png)]
Appendix I. creating Maven module
1) . Maven engineering structure
2) . POM file content
Contents in the POM document of Maven project (Yilai package):
<!-- Specify the warehouse location, in order: aliyun,cloudera and jboss Warehouse -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<kafka.version>2.0.0</kafka.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- rely on Scala language -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming integrate Kafka 0.8.2.1 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming And Kafka 0.10.0 Integration dependency-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client rely on -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client rely on -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- Kafka Client rely on -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!-- according to ip Convert to provincial and urban areas -->
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
<!-- MySQL Client rely on -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>