Spark Day11: Spark Streaming
01 - [understand] - yesterday's course content review
Main explanation: Spark Streaming module quick start
1,Streaming Overview of flow computing - Streaming Application scenario Real time report RealTime Report Real time increment ETL Real time early warning and monitoring Real time search recommendation wait - Big data architecture: Lambda framework Offline analysis, real-time calculation It is divided into three layers: - Batch layer, BatchLayer - Velocity layer, SpeedLayer - Service layer, ServingLayer - Streaming data processing mode The first mode: native stream processing native One piece of data, one piece of data The second mode: Micro batch processing Mirco-Batch The streaming data is divided into small batches, and each small batch is processed quickly - SparkStreaming Computational thought Streaming data at time intervals BatchInterval Divided into many batches Batch,Each batch of data as RDD,Conduct processing analysis DStream = Seq[RDD/Batch] 2,Quick start: word frequency statistics WordCount - Requirements: use SparkStreaming Convective data were analyzed from TCP Socket Read the data, make word frequency statistics for each batch of data, print the console, [note that word frequency statistics here are not global, but (local) of each batch] - Official case run-example - SparkStreaming Application development portal StreamingContext,Streaming context instance object Development steps: data source DStream,Data processing and output (call) DStream Start streaming application start,Waiting for termination await,Finally, close the resource stop - Programming development, similar RDD Chinese word frequency statistics, call function flatMap,map,redueByKey etc. - Flow application principle - When running the program, first create StreamingContext Object, underlying sparkContext - ssc.start,Start receiver Receivers,Each receiver in Task Mode runs in Executor in - Receiver The receiver begins to receive data from the data source at time intervals BlockInterval When dividing data Block,Default 200 ms,take Block Store to Executor In memory, if multiple copies are set, in other Executor Then store and finally send BlockReport to SSC - When reached BatchINterval A batch interval is generated Batch Batch, will Block Assigned to this batch, the bottom layer takes the data in the modification as RDD Conduct processing analysis 3,Data structure: DStream = Seq[RDD] Encapsulate the data flow, and the data is generated continuously, which is divided into many batches according to the time interval Batch,DStream = Seq[RDD] Functions: 2 types - Conversion function Transformation,similar RDD Medium conversion function - Output function Output 2 Two important functions are for each batch RDD Operate - Conversion function: tranform(rdd => rdd) - Output function: foreachRDD(rdd => Unit) Modify word frequency statistics code
02 - [understand] - outline of today's course content
It mainly explains three aspects: integration Kafka, application case (status, window) and offset management
1,integrate Kafka SparkStreaming In the actual project, it is basically from Kafka Real time processing of consumption data - 2 sets during integration API because Kafka Consumer API There are 2 sets, so there are also 2 sets for integration API - Write code How from Kafka Consumption data must be mastered - Get data offset information for each batch offset 2,Application case: Baidu search ranking Perform relevant initialization operations - Tool classes, creating StreamingContext Object and consumption Kafka data - The simulation data generator generates user search log data in real time and sends it to Kafka in - real time ETL((stateless) - Cumulative statistics (with status) - Window statistics 3,Offset management SparkStreaming A big failure requires user management from Kafka Consumption data offset, just know the knowledge points
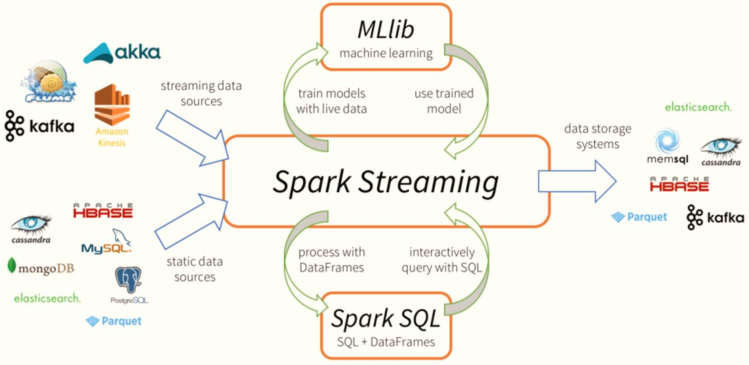
03 - [understand] - streaming application technology stack
In the actual project, whether Storm or Spark Streaming and Flink are used, Kafka real-time consumption data is mainly processed and analyzed. The technical architecture of streaming data real-time processing is roughly as follows:
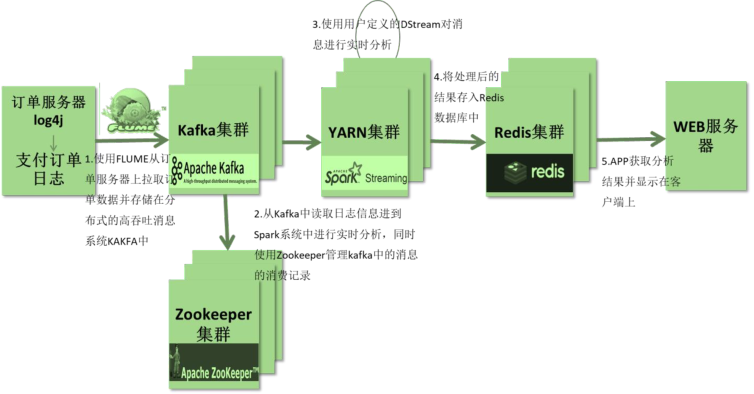
- data source Source Distributed message queue Kafka flume integrate Kafka call Producer API Write data Canal Real time MySQL Synchronize table data to Kafka In, data format JSON character string ..... - applications running At present, as long as time-flow applications in enterprises are basically running in Hadoop YARN colony - Data terminal Write data to NoSQL In the database, such as Redis,HBase,Kafka Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm -> Hadoop YARN -> Redis -> UI

04 - [understand] - Kafka review and integration of two sets of API s
Apache Kafka: the most primitive function [message queue], buffering data, has a publish subscribe function (similar to the official account of WeChat).
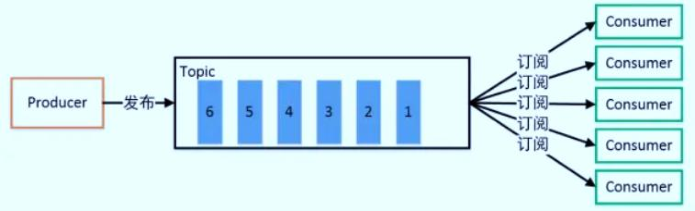
The framework diagram of Kafka is as follows:
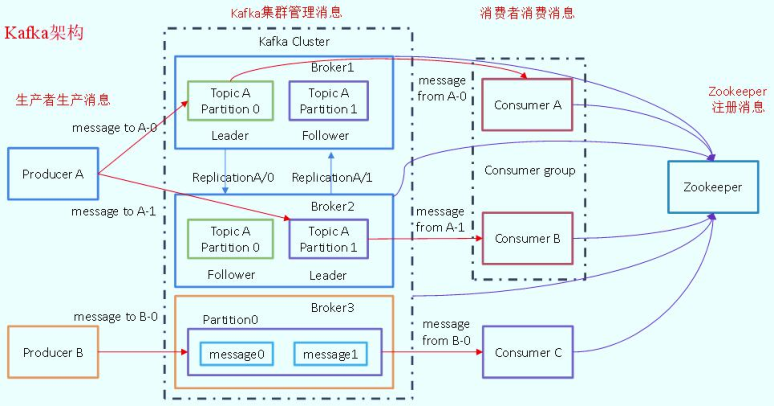
1,Services: Broker,Start service per machine One Kafka Cluster, at least 3 machines 2,rely on Zookeeper Configuration information is stored in ZK in 3,Producer producer towards Kafka Write data in 4,Consumer consumer from Kafka Subscription data 5,How data is stored and managed use Topic Subject, manage different types of data, and divide it into multiple partitions partition,Adopt replication mechanism leader Copy: read / write data, 1 follower Replica: synchronize data to ensure data reliability,1 Or more
Spark Streaming is integrated with Kafka and has two sets of APIs. The reason is that Kafka Consumer API has two sets, The New Consumer API has appeared since Kafka version 0.9, which is convenient for users. The consumption data from Kafka Topic is stable until version 0.10.
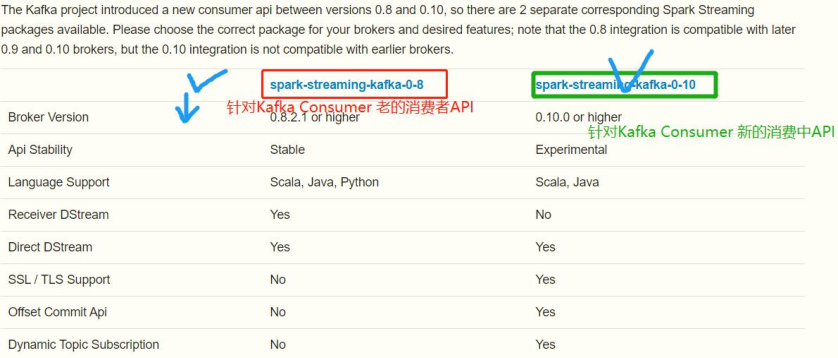
At present, it is basically used in enterprises Kafka New Consumer API consumption Kafka Data in. - Core class: KafkaConsumer,ConsumerRecorder
05 - [Master] - New Consumer API integrated programming
Use Kafka 0.10. + to provide a new version of Consumer API, integrate Streaming, consume Topic data in real time and process it.
- Add related Maven dependencies:
<!-- Spark Streaming And Kafka 0.10.0 Integration dependency-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
At present, enterprises basically use New Consumer API integration. The advantages are as follows:
- First, it is similar to the Direct mode in the Old Consumer API

- Second, the simple parallelism is 1:1

Instructions for using the createDirectStream function API in the tool class KafkaUtils (function declaration):

Official documents: http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html
First, start the Kafka service and create Topic: WC Topic
[root@node1 ~]# zookeeper-daemon.sh start [root@node1 ~]# kafka-daemon.sh start [root@node1 ~]# jps 2945 Kafka # Use KafkaTools to create Topic and set 1 copy and 3 partitions kafka-console-producer.sh --topic wc-topic --broker-list node1.itcast.cn:9092
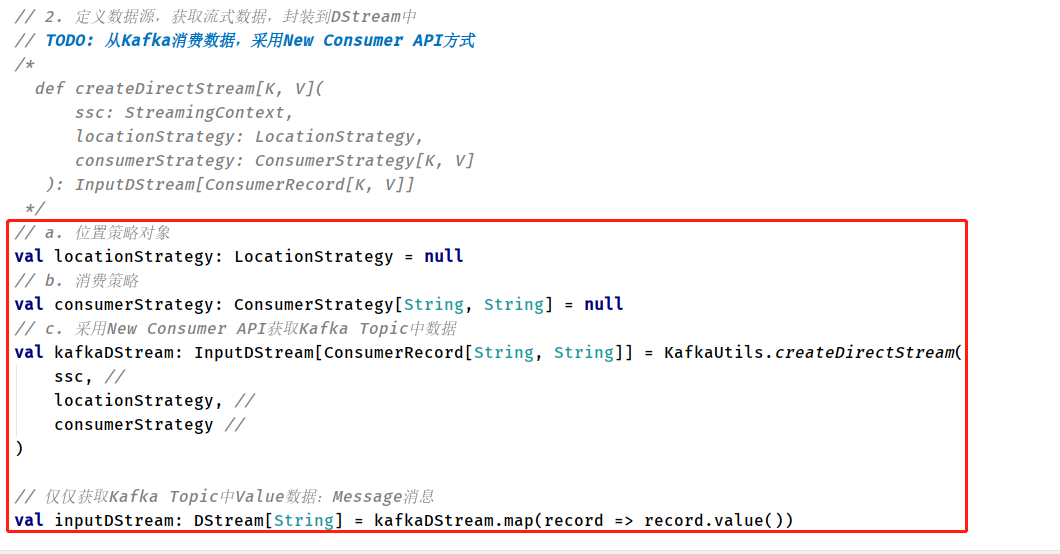
The specific implementation code needs to create location policy object and consumption policy object
package cn.itcast.spark.kafka
import java.util
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, ConsumerStrategy, KafkaUtils, LocationStrategies, LocationStrategy}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Streaming Get data through Kafka New Consumer API
*/
object _01StreamingSourceKafka {
def main(args: Array[String]): Unit = {
// 1. Build the StreamingContext instance object and pass the time interval BatchInterval
val ssc: StreamingContext = {
// a. Create a SparkConf object and set basic application information
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// Set the algorithm version of the data output file system to 2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b. Create an instance object and set BatchInterval
new StreamingContext(sparkConf, Seconds(5))
}
// 2. Define the data source, obtain the streaming data and package it into DStream
// TODO: from Kafka consumption data, New Consumer API is adopted
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// a. Location policy object
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// b. Consumption strategy
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "gui-1001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
Array("wc-topic"), //
kafkaParams //
)
// c. Use the New Consumer API to obtain the data in Kafka Topic
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, //
locationStrategy, //
consumerStrategy //
)
// Only get the Value data in Kafka Topic: Message message
val inputDStream: DStream[String] = kafkaDStream.map(record => record.value())
// 3. Call the conversion function in DStream (similar to the conversion function in RDD) according to business requirements
/*
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// Here RDD is the RDD data of each batch in DStream
val resultDStream: DStream[(String, Int)] = inputDStream.transform{ rdd =>
rdd
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
}
// 4. Define the data terminal and output the result data of each batch
/*
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
*/
resultDStream.foreachRDD((rdd, time) => {
//val xx: Time = time
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: ${format.format(time.milliseconds)}")
println("-------------------------------------------")
// Judge whether there is data in the RDD of each batch of results. If there is data, output it again
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
}
})
// 5. Start streaming application and wait for termination
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
06 - [understand] - obtain consumption offset information when integrating Kafka
When SparkStreaming integrates Kafka, the data of each batch is encapsulated in KafkaRDD, including the metadata information of each data, regardless of the data obtained by the Direct method in the Old Consumer API or the NewConsumer API.
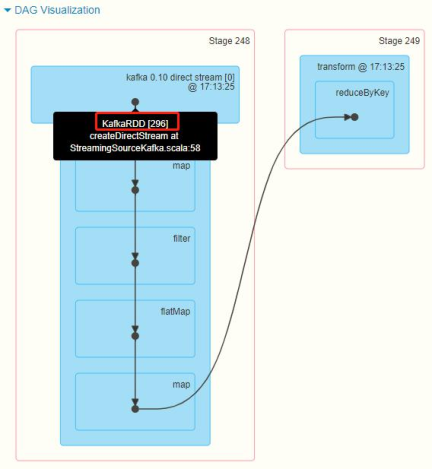
When the streaming application is running, you can see the offset range of each batch of consumption data in the WEB UI monitoring interface. Can you obtain data in the program??
Official documents: http://spark.apache.org/docs/2.2.0/streaming-kafka-0-10-integration.html#obtaining-offsets
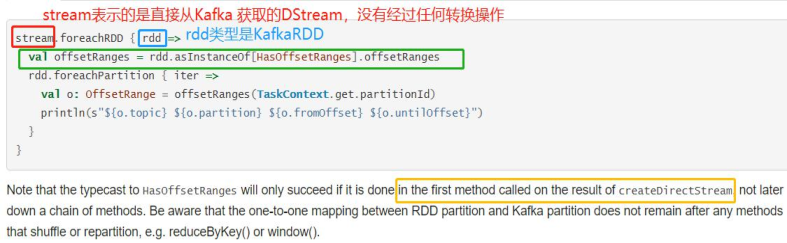
The code for obtaining offset information is as follows:
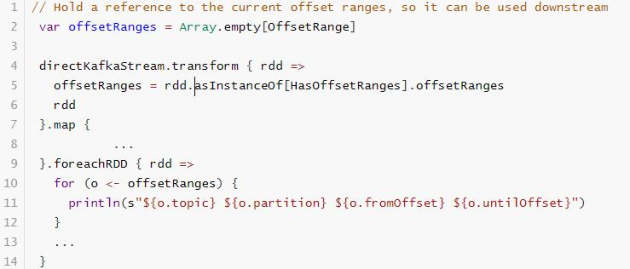
When modifying the previous code to obtain consumption Kafka data, the data offset range of each partition in each batch:
package cn.itcast.spark.kafka
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Streaming Obtain data through Kafka New Consumer API and obtain the OFFSET offset of each batch of processing data
*/
object _02StreamingKafkaOffset {
def main(args: Array[String]): Unit = {
// 1. Build the StreamingContext instance object and pass the time interval BatchInterval
val ssc: StreamingContext = {
// a. Create a SparkConf object and set basic application information
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// Set the algorithm version of the data output file system to 2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b. Create an instance object and set BatchInterval
new StreamingContext(sparkConf, Seconds(5))
}
// 2. Define the data source, obtain the streaming data and package it into DStream
// TODO: from Kafka consumption data, New Consumer API is adopted
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// step1. Indicates the location policy when consuming Topic data in Kafka
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// Step 2. Indicates the consumption policy and encapsulates the consumption configuration information when consuming topic data in Kafka
/*
def Subscribe[K, V](
topics: Iterable[jl.String],
kafkaParams: collection.Map[String, Object]
): ConsumerStrategy[K, V]
*/
val kafkaParams: collection.Map[String, Object] = Map(
"bootstrap.servers" -> "node1.itcast.cn:9092", //
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "groop_id_1001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe (
Array("wc-topic"), kafkaParams
)
// step3. Use Kafka New Consumer API to consume data
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// TODO: first, define an array to store offsets
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange] // The data offset information of each Kafka partition is encapsulated in the OffsetRange object
// 3. Call the conversion function in DStream (similar to the conversion function in RDD) according to business requirements
/*
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// Here RDD is the RDD data of each batch in DStream
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
// TODO: at this time, the conversion operation is directly performed for obtaining KafkaDStream. rdd belongs to KafkaRDD and contains relevant offset information
// TODO: second, convert KafkaRDD to HasOffsetRanges to obtain the offset range
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
.map(record => record.value())
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
}
// 4. Define the data terminal and output the result data of each batch
/*
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
*/
resultDStream.foreachRDD((rdd, time) => {
//val xx: Time = time
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: ${format.format(time.milliseconds)}")
println("-------------------------------------------")
// Judge whether there is data in the RDD of each batch of results. If there is data, output it again
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
}
// TODO: Third, when the current batch data processing is completed, print the data offset information in the current batch
offsetRanges.foreach{offsetRange =>
println(s"topic: ${offsetRange.topic} partition: ${offsetRange.partition} offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}")
}
})
// 5. Start streaming application and wait for termination
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
07 - [understand] - business scenario and requirement description of application case
Analyze the user's logs when using Baidu search by imitating the Baidu search billboard: [real time analysis of Baidu search logs]. The main business requirements are as follows:
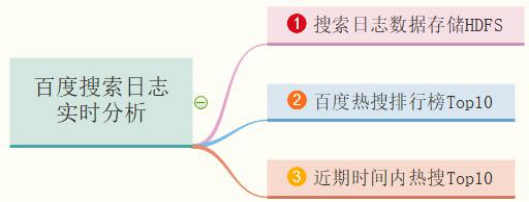
Business 1: search log data storage HDFS,Real time log data ETL Extract, transform, store HDFS File system; Business 2: Baidu hot search ranking Top10,Accumulate and count the number of search terms of all users to obtain Top10 Search terms and times; Business 3: Hot search in the near future Top10,Count the number of user search words in the latest period of time (for example, the last half hour or the last 2 hours) to obtain Top10 Search terms and times;
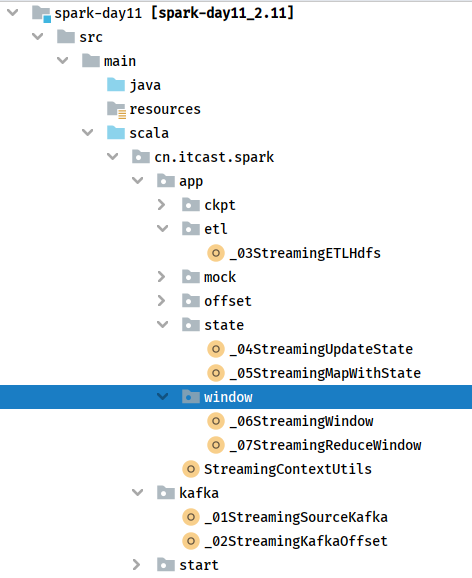
The directory structure in Maven Project development is as follows:
08 - [Master] - initialization environment and tool class of application case
Before programming the business, first write a program to simulate the generation of log data generated by users using Baidu search and the creation tool StreamingContextUtils to provide StreamingContext objects and methods to receive data from Kafka.
- Start the Kafka Broker service and create a Topic [search log Topic]. The command is as follows:
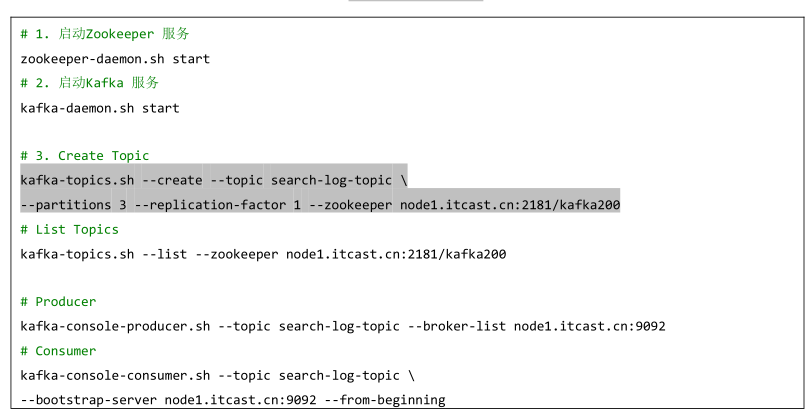
- Simulate log data
Simulate the user search log data, and the field information is encapsulated into the CaseClass sample class [SearchLog], with the following code:
package cn.itcast.spark.app.mock
/**
* User Baidu search log data encapsulation sample class CaseClass
* <p>
*
* @param sessionId Session ID
* @param ip IP address
* @param datetime Search date time
* @param keyword Search keywords
*/
case class SearchLog(
sessionId: String, //
ip: String, //
datetime: String, //
keyword: String //
) {
override def toString: String = s"$sessionId,$ip,$datetime,$keyword"
}
Simulate the generation of search log data class [MockSearchLogs], and the specific code is as follows:
package cn.itcast.spark.app.mock
import java.util.{Properties, UUID}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* When the simulated user uses Baidu search engine, the search query log data includes the following fields:
* uid, ip, search_datetime, search_keyword
*/
object MockSearchLogs {
def main(args: Array[String]): Unit = {
// Search keywords directly to Baidu hot search list
val keywords: Array[String] = Array(
"Wu Zunyou reminded may day not to attend large gatherings", "The shopping guide was punished for claiming that the child was not dead", "The twin sisters in the brush video are identical twins",
"Yunnan citizens pleaded guilty to bribery for more than 4 years.6 Hundred million", "The Indian man knelt down and begged the police not to take away the oxygen cylinder", "SARFT:Support the investigation and handling of Yin-Yang contracts and other issues",
"75 200 affiliated companies cancelled by first-line artists", "The space station's space and core modules were successfully launched", "Chinese navy ships warn to drive away US ships",
"Delhi, India changes dog crematorium to human crematorium", "The Ministry of public security sent a working group to Guangxi", "A beautiful man was kneeling and pressed by the police for 5 minutes and died",
"Legendary Wall Street fund manager jumped to death", "Apollo 11 astronaut Collins died", "Carina Lau apologized to Dou Xiao and he ChaoLian"
)
// Send Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "node1.itcast.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random: Random = new Random()
while (true){
// Randomly generate a search query log
val searchLog: SearchLog = SearchLog(
getUserId(), //
getRandomIp(), //
getCurrentDateTime(), //
keywords(random.nextInt(keywords.length)) //
)
println(searchLog.toString)
Thread.sleep(100 + random.nextInt(100))
val record = new ProducerRecord[String, String]("search-log-topic", searchLog.toString)
producer.send(record)
}
// Close connection
producer.close()
}
/**
* Randomly generated user SessionId
*/
def getUserId(): String = {
val uuid: String = UUID.randomUUID().toString
uuid.replaceAll("-", "").substring(16)
}
/**
* Gets the current date and time in the format yyyymmddhhmmssss
*/
def getCurrentDateTime(): String = {
val format = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
val nowDateTime: Long = System.currentTimeMillis()
format.format(nowDateTime)
}
/**
* Get random IP address
*/
def getRandomIp(): String = {
// ip range
val range: Array[(Int, Int)] = Array(
(607649792,608174079), //36.56.0.0-36.63.255.255
(1038614528,1039007743), //61.232.0.0-61.237.255.255
(1783627776,1784676351), //106.80.0.0-106.95.255.255
(2035023872,2035154943), //121.76.0.0-121.77.255.255
(2078801920,2079064063), //123.232.0.0-123.235.255.255
(-1950089216,-1948778497),//139.196.0.0-139.215.255.255
(-1425539072,-1425014785),//171.8.0.0-171.15.255.255
(-1236271104,-1235419137),//182.80.0.0-182.92.255.255
(-770113536,-768606209),//210.25.0.0-210.47.255.255
(-569376768,-564133889) //222.16.0.0-222.95.255.255
)
// Random number: IP address range subscript
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
//println(s"ipNumber = ${ipNumber}")
// Convert Int type IP address to IPv4 format
number2IpString(ipNumber)
}
/**
* Converts an Int type IPv4 address to a string type
*/
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// Return IPv4 address
buffer.mkString(".")
}
}
- All SparkStreaming applications need to build a StreamingContext instance object, consume Kafka data from the New KafkaConsumer API, and write a tool class [StreamingContextUtils], which provides two methods:
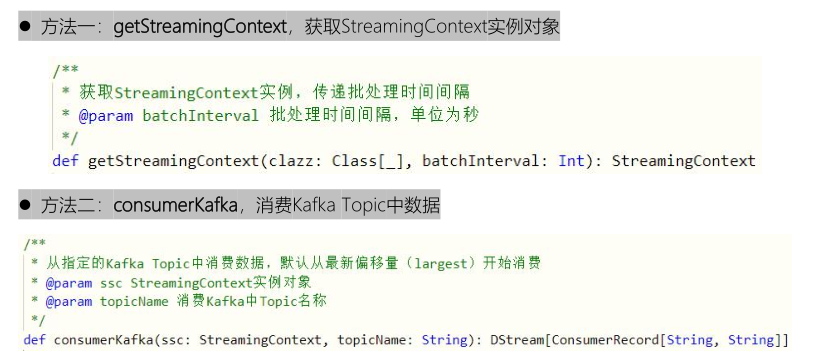
package cn.itcast.spark.app
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* The tool class provides: constructing streaming application context, StreamingContext instance object and consuming data from Kafka Topic
*/
object StreamingContextUtils {
/**
* Get the StreamingContext instance and pass the batch processing interval
* @param batchInterval Batch interval in seconds
*/
def getStreamingContext(clazz: Class[_], batchInterval: Int): StreamingContext = {
// i. Create a SparkConf object and set the application configuration information
val sparkConf = new SparkConf()
.setAppName(clazz.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// Set Kryo serialization
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[ConsumerRecord[String, String]]))
// Set the algorithm version when saving file data: 2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// ii. Create a streaming context object and pass the SparkConf object and time interval
val context = new StreamingContext(sparkConf, Seconds(batchInterval))
// iii. return
context
}
/**
* Consume data from the specified Kafka Topic, starting from the latest offset (largest) by default
* @param ssc StreamingContext Instance object
* @param topicName Topic name in consumption Kafka
*/
def consumerKafka(ssc: StreamingContext, topicName: String): DStream[ConsumerRecord[String, String]] = {
// i. Location strategy
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii. What Topic data are read
val topics = Array(topicName)
// iii. consumption Kafka data configuration parameters
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "gui_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv. consumption data strategy
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v. The new consumer API is adopted to obtain data, which is similar to the Direct method
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// vi. return DStream
kafkaDStream
}
}
09 - [Master] - ETL storage of real-time data of application cases
Extract the IP address field from the Kafka Topic consumption data in real time, call the [ip2Region] library to parse it into provinces and cities, store it in the HDFS file, and set the batch interval to 10 seconds.
package cn.itcast.spark.app.etl
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.lionsoul.ip2region.{DbConfig, DbSearcher}
/**
* The real-time consumption Kafka Topic data is saved to the HDFS file system after ETL (filtering and conversion). The BatchInterval is 10s
*/
object _03StreamingETLHdfs {
def main(args: Array[String]): Unit = {
// 1. Create a StreamingContext instance object
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 10)
// 2. Use New Consumer API from Kafka consumption data
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc, "search-log-topic")
// TODO: 3. Perform ETL conversion for the acquired data, and convert the IP address to province and city
val etlDStream: DStream[String] = kafkaDStream.transform { rdd =>
val etlRDD: RDD[String] = rdd
// Filter data
.filter(record => null != record.value() && record.value().trim.split(",").length == 4)
// For each partition operation, obtain the ip address in each data and convert it into province and city
.mapPartitions { iter =>
// a. Create DbSearch object
val dbSearcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
// b. Convert and analyze the IP value of the data in the partition
iter.map { record =>
// Get Message Value
val message: String = record.value()
// Get IP address value
val ipValue: String = message.split(",")(1)
// Resolve IP address
val region: String = dbSearcher.btreeSearch(ipValue).getRegion
val Array(_, _, province, city, _) = region.split("\\|")
// Splice string
s"${message},${province},${city}"
}
}
// Returns the converted RDD
etlRDD
}
etlDStream
// 4. Save data to HDFS file system
etlDStream.foreachRDD((rdd, batchTime) => {
if(!rdd.isEmpty()){
rdd.coalesce(1).saveAsTextFile(s"datas/streaming/search-logs-${batchTime}")
}
})
// Start the streaming application and wait for the termination to end
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
Run the simulation log data program and ETL application, view the real-time data and save the file after ETL. The screenshot is as follows:
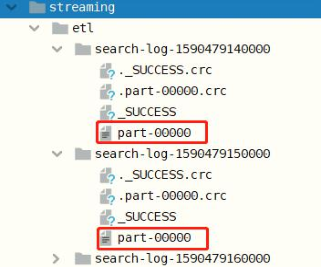
10 - [Master] - updateStateByKey function of application case
The number of occurrences of each search term is counted in real time. The function [updateStateByKey] is provided in SparkStreaming to realize cumulative statistics. Spark 1.6 provides [mapWithState] function status statistics, which has better performance and is also recommended in practical applications.
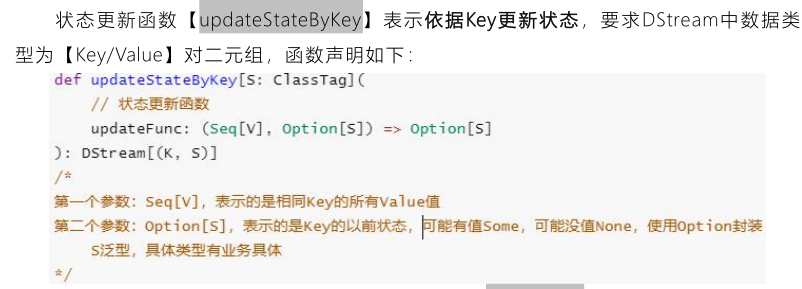
Update the status of each batch of data according to the Key and previous status, and use the definition function [updateFunc]. The schematic diagram is as follows:
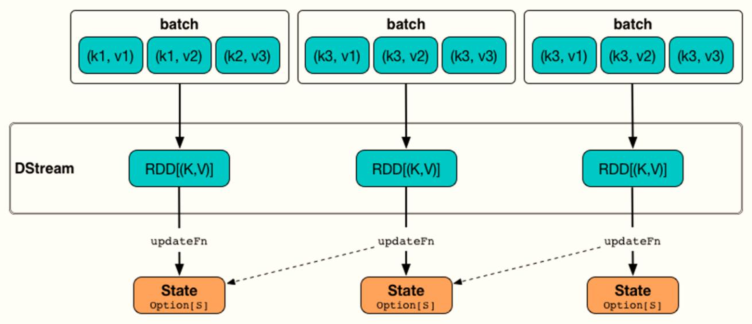
For WordCount, the status update logic diagram is as follows:
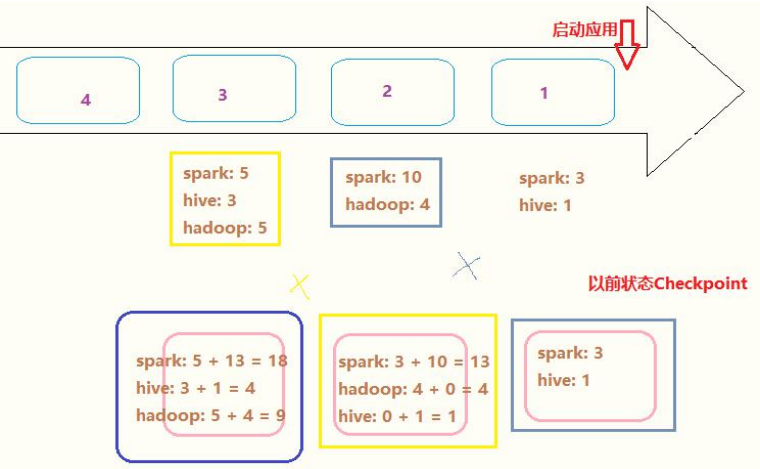
use updatStateByKey The key points of the status update function are as follows: - First, basis Key Update status Key Is the key field. For applications, Key It's a search term - Second, the principle of renewal step1,In the current batch, Key State of step2,obtain Key Previous status step3,Merge current batch status and previous status For this application, Key Search term, corresponding status State,Data type: Int,or Long
Programming, accumulate real-time statistics, and use updateStateByKey function
package cn.itcast.spark.app.state
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
/**
* Consume Kafka Topic data in real time, accumulate and count the search times of each search term, and realize Baidu search billboard
*/
object _04StreamingUpdateState {
def main(args: Array[String]): Unit = {
// 1. Create a StreamingContext instance object
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 10)
// TODO: set checkpoint directory
ssc.checkpoint("datas/streaming/ckpt-1001")
// 2. Use New Consumer API from Kafka consumption data
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc, "search-log-topic")
// 3. TODO: step1. Aggregate statistics for current batch data
val batchReduceDStream: DStream[(String, Int)] = kafkaDStream.transform{rdd =>
rdd
// Get Message information
.map(record => record.value())
.filter(msg => null != msg && msg.trim.split(",").length == 4)
// Extract the search term, indicating that it appears once
.map(msg => msg.trim.split(",")(3) -> 1)
// TODO: optimize and aggregate the data in the current batch once
.reduceByKey(_ + _)
}
// 3. TODO: step2. Aggregate the aggregation results of the current batch with the previous status data (status update)
/*
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)]
- Seq[V]Represents the value value set corresponding to the Key in the current batch
If the data in the current batch is aggregated by Key, there is only one value at this time
V Type: Int
- Option[S]): Indicates the previous status of the Key. If the Key has not appeared before, the status is None
S Type: Int
*/
val stateDStream: DStream[(String, Int)] = batchReduceDStream.updateStateByKey(
(values: Seq[Int], state: Option[Int]) => {
// a. Get previous status of Key
val previousState: Int = state.getOrElse(0)
// b. Gets the status of the Key in the current batch
val currentState: Int = values.sum
// c. What about the merge status
val latestState: Int = previousState + currentState
// Return to the latest status
Some(latestState)
}
)
// 4. Output the result data of each batch
stateDStream.foreachRDD((rdd, time) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: ${format.format(time.milliseconds)}")
println("-------------------------------------------")
// Judge whether there is data in the RDD of each batch of results. If there is data, output it again
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
}
})
// Start the streaming application and wait for the termination to end
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
11 - [Master] - mapWithState function of application case
Spark 1.6 provides a new status update function [mapWithState]. The mapWithState function will also count the status of global keys. However, if there is no data input, the status of previous keys will not be returned. It only cares about those keys that have changed. If there is no data input, the data of those keys that have not changed will not be returned.
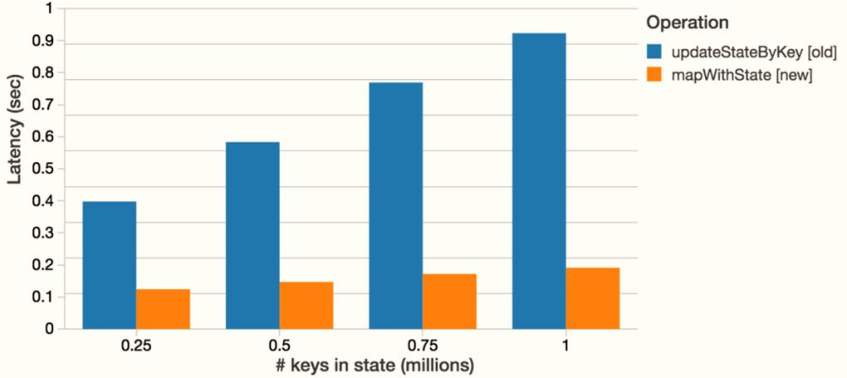
In this way, even if there is a large amount of data, checkpoint will not occupy too much storage like updateStateByKey, which is more efficient;

StateSpec objects need to be built to encapsulate the State, and related operations can be performed. The declaration definition of the class is as follows:

Description of the [mapWithState] parameter of the status function:

Modify the previous case code and use the mapWithState function to update the state,
package cn.itcast.spark.app.state
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.{State, StateSpec, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
/**
* Consume Kafka Topic data in real time, accumulate and count the search times of each search term, and realize Baidu search billboard
*/
object _05StreamingMapWithState {
def main(args: Array[String]): Unit = {
// 1. Create a StreamingContext instance object
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 5)
// TODO: set checkpoint directory
ssc.checkpoint("datas/streaming-ckpt-999999")
// 2. Use New Consumer API from Kafka consumption data
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc, "search-log-topic")
// 3. TODO: step1. Aggregate statistics for current batch data
val batchReduceDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
rdd
.filter(record => null != record && record.value().trim.split(",").length == 4)
.map{record =>
// Get each data Message of Kafka Topic
val msg: String = record.value()
// Get search keywords
val searchWord: String = msg.trim.split(",").last
// Returns a binary
searchWord -> 1
}
// Group by search terms, aggregate and count the occurrence times of each search term
.reduceByKey(_ + _) // This is performance optimization
}
// 3. TODO: step2. Aggregate the aggregation results of the current batch with the previous status data (status update)
/*
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType]
*/
// Building stateSpec objects
/*
def function[KeyType, ValueType, StateType, MappedType](
mappingFunction: (KeyType, Option[ValueType], State[StateType]) => MappedType
): StateSpec[KeyType, ValueType, StateType, MappedType]
*/
val spec: StateSpec[String, Int, Int, (String, Int)] = StateSpec.function(
(key: String, option: Option[Int], state: State[Int]) => {
// a. Get the name of the current Key
val currentState: Int = option.getOrElse(0)
// b. Get previous status
val previousState: Int = state.getOption().getOrElse(0)
// c. Merge status
val latestState: Int = currentState + previousState
// d. Update status
state.update(latestState)
// e. Returns the sum of key and status, encapsulated in a binary
key -> latestState
}
)
// Status update statistics by Key
val stateDStream: DStream[(String, Int)] = batchReduceDStream.mapWithState(spec)
// 4. Output the result data of each batch
stateDStream.foreachRDD((rdd, time) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: ${format.format(time.milliseconds)}")
println("-------------------------------------------")
// Judge whether there is data in the RDD of each batch of results. If there is data, output it again
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
}
})
// Start the streaming application and wait for the termination to end
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
12 - [Master] - real time window statistics of application cases
Some column window functions are provided in SparkStreaming to facilitate the analysis of window data. Document:
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#window-operations
In actual projects, it is often required to count the latest data status every once in a while, rather than all the data, which is called trend statistics or window statistics. SparkStreaming provides the implementation functions of relevant functions. The business logic is as follows:
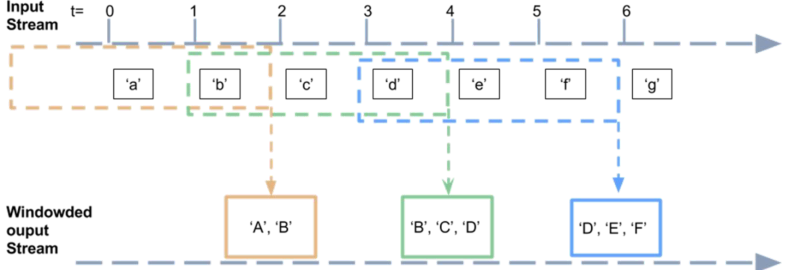
The window function [window] is declared as follows and contains two parameters: window size (WindowInterval, each statistical data range) and sliding size (how often to count), which must be an integer multiple of the batch interval.

package cn.itcast.spark.app.window
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
/**
* Consume Kafka Topic data in real time, and count the number of search words in the recent search log at regular intervals
* Batch interval: BatchInterval = 2s
* Window size interval: WindowInterval = 4s
* Sliding size interval: SliderInterval = 2s
*/
object _06StreamingWindow {
def main(args: Array[String]): Unit = {
// 1. Create a StreamingContext instance object
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 2)
// TODO: set checkpoint directory
ssc.checkpoint(s"datas/spark/ckpt-${System.nanoTime()}")
// 2. Use New Consumer API from Kafka consumption data
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc, "search-log-topic")
// TODO: setting window: size is 4 seconds, sliding is 2 seconds
/*
def window(windowDuration: Duration, slideDuration: Duration): DStream[T]
*/
val windowDStream: DStream[ConsumerRecord[String, String]] = kafkaDStream.window(
Seconds(4), // Window size
Seconds(2) // Sliding size
)
// 3. Aggregate the data in the window
val resultDStream: DStream[(String, Int)] = windowDStream.transform{rdd =>
// Here RDD is the RDD data in the window
rdd
// Get Message information
.map(record => record.value())
.filter(msg => null != msg && msg.trim.split(",").length == 4)
// Extract the search term, indicating that it appears once
.map(msg => msg.trim.split(",").last -> 1)
// TODO: aggregate the data in the current window once
.reduceByKey(_ + _)
}
// 4. Output the result data of each batch
resultDStream.foreachRDD((rdd, time) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: ${format.format(time.milliseconds)}")
println("-------------------------------------------")
// Judge whether there is data in the RDD of each batch of results. If there is data, output it again
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
}
})
// Start the streaming application and wait for the termination to end
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
SparkStreaming also provides a function to combine Window settings with aggregate reduceByKey for easier programming.

Modify the above code and write the aggregation function and window together:
package cn.itcast.spark.app.window
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
/**
* Consume Kafka Topic data in real time, and count the number of search words in the recent search log at regular intervals
* Batch interval: BatchInterval = 2s
* Window size interval: WindowInterval = 4s
* Sliding size interval: SliderInterval = 2s
*/
object _07StreamingReduceWindow {
def main(args: Array[String]): Unit = {
// 1. Create a StreamingContext instance object
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 2)
// TODO: set checkpoint directory
ssc.checkpoint(s"datas/spark/ckpt-${System.nanoTime()}")
// 2. Use New Consumer API from Kafka consumption data
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc, "search-log-topic")
// 3. TODO: convert batch data
val etlDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
rdd
.filter(record => null != record && record.value().trim.split(",").length == 4)
.map{record =>
// Get each data Message of Kafka Topic
val msg: String = record.value()
// Get search keywords
val searchWord: String = msg.trim.split(",").last
// Returns a binary
searchWord -> 1
}
}
// TODO: set the window size to 4 seconds, slide to 2 seconds, and aggregate the data in the window
/*
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration
): DStream[(K, V)]
*/
val resultDStream: DStream[(String, Int)] = etlDStream.reduceByKeyAndWindow(
(v1: Int, v2: Int) => v1 + v2, // After grouping the data in the window according to the Key, aggregate the Value
Seconds(4), //Window size
Seconds(2) // Sliding size
)
// 4. Output the result data of each batch
resultDStream.foreachRDD((rdd, time) => {
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: ${format.format(time.milliseconds)}")
println("-------------------------------------------")
// Judge whether there is data in the RDD of each batch of results. If there is data, output it again
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
}
})
// Start the streaming application and wait for the termination to end
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
Appendix I. creating Maven module
1) . Maven engineering structure
2) . POM file content
Contents in the POM document of Maven project (Yilai package):
<!-- Specify the warehouse location, in order: aliyun,cloudera and jboss Warehouse -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<kafka.version>2.0.0</kafka.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- rely on Scala language -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming integrate Kafka 0.8.2.1 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming And Kafka 0.10.0 Integration dependency-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client rely on -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client rely on -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- Kafka Client rely on -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!-- according to ip Convert to provincial and urban areas -->
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
<!-- MySQL Client rely on -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>