brief introduction
Broadcast variables allow us to keep a read-only variable on each computer instead of making a copy for each task. For example, they can be used to provide a copy of a large input dataset for each compute node in an efficient manner. Spark also tries to use effective broadcast algorithms to distribute broadcast variables to reduce communication costs. In addition, the Spark action operation will be divided into a series of stages to execute. These stages are divided according to whether the shuffle operation is generated. Spark will automatically broadcast the general data required for each stage task. These broadcast data are cached in the form of serialization, and then deserialized before the task runs. That is, the create broadcast variable displayed is useful only in the following two cases:
1) When tasks span multiple stage s and require the same data;
2) When data is cached in the form of deserialization.
Broadcast variables are used to efficiently distribute large objects. Sends a large read-only value to all work nodes for use by one or more Spark operations. For example, if your application needs to send a large read-only query table to all nodes, broadcast variables are easy to use. The same variable is used in multiple parallel operations, but Spark will send it separately for each task.
characteristic
1) The broadcast variable keeps a copy on each worker node instead of a copy for each Task. What are the benefits? It is conceivable that a worker sometimes runs several tasks at the same time. If a variable containing large data is copied as a Task and needs to be transmitted through the network, the processing efficiency of the application will be greatly affected.
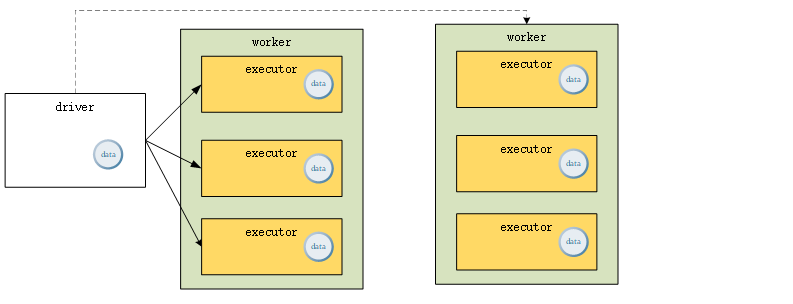
2) Spark will distribute broadcast variables through a broadcast algorithm, which can reduce the communication cost. Spark uses a data distribution algorithm similar to BitTorrent protocol to distribute the data of broadcast variables, which will be analyzed later.
3) Broadcast variables have certain application scenarios: when tasks span multiple stage s and require the same data, or when data is cached in the form of deserialization.
Broadcast variable usage
Not applicable to broadcast variables
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2: RDD[(String, Int)] = sc.parallelize(List(("a", 11), ("b", 22), ("c", 33)))
// There will be shuffle s when join ing data. We try to avoid them when programming
val resRDD1: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
// The join logic is implemented in this way. The map function called here is not generated by shuffle
// 1 collect data to the driver side
val mp: Map[String, Int] = rdd2.collect().toMap
// The logical distributed execution of the map function is in different tasks, so our mp data exists in each Task
val resRDD2: RDD[(String, (Int, Int))] = rdd1.map {
case (k, v) => {
val i: Int = mp.getOrElse(k, -1)
(k, (v, i))
}
}
resRDD2.foreach(println)
sc.stop()Using broadcast variables
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2: RDD[(String, Int)] = sc.parallelize(List(("a", 11), ("b", 22), ("c", 33)))
val mp: Map[String, Int] = rdd2.collect().toMap
// Broadcast data
val bc: Broadcast[Map[String, Int]] = sc.broadcast(mp)
val resRDD: RDD[(String, (Int, Int))] = rdd1.map {
case (k, v) => {
// Get broadcast data
val i: Int = bc.value.getOrElse(k, -1)
(k, (v, i))
}
}
resRDD.foreach(println)
sc.stop()
}Destroy broadcast variables
// Destroy broadcast variables
bc.unpersist()Send a RemoveBroadcast message from the driver side. When the BlockManager service on the Executor receives the message, it will delete the broadcast variable from the BlockManager. If removeFromDriver is set to True, the data of the variable will also be deleted from the driver.
Creation principle
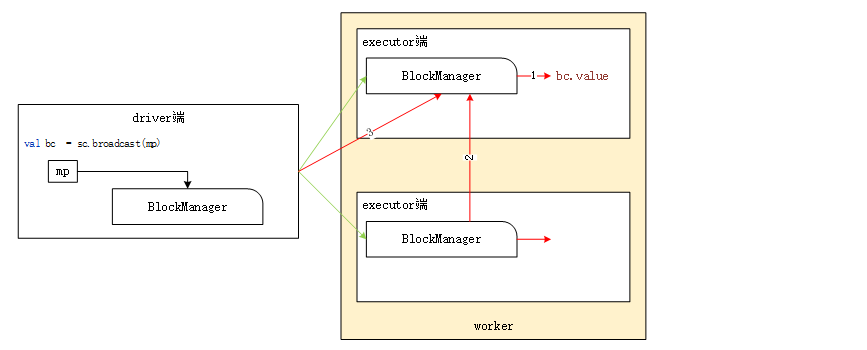
The creation of broadcast variables takes place on the driver side, as shown in the figure. When calling SparkContext#broadcast to create broadcast variables, the data of the variables will be divided into multiple data blocks and saved to BlockManger on the driver side. The storage level used is MEMORY_AND_DISK_SER.
Therefore, the reading of broadcast variables is also lazy loading. It will be obtained only when the Executor needs to obtain broadcast variables. At this time, the data of broadcast variables only exists at the Driver end.
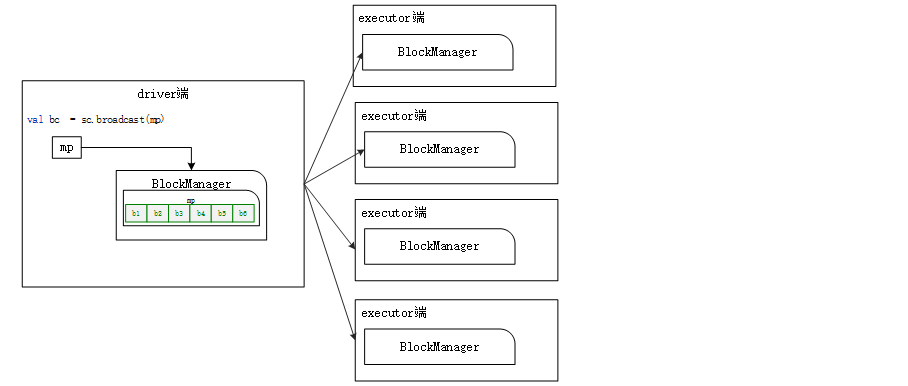
The broadcast variable is saved locally, and the value of the broadcast variable will be cut into multiple data blocks for saving. The default size of broadcast variable data block is 4M. Data block too large or too small is not conducive to data transmission.
Reading principle
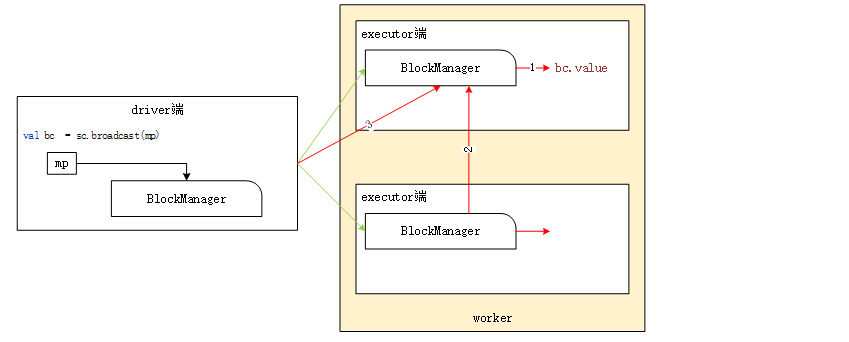
1) Step 1 (red line 1): first read the data of broadcast variables from the BlockManager local to the Executor. If it exists, get it directly and return it. Steps 2 and 3 are not being performed. If not, proceed to step 2.
2) Step 2 (red line 2): obtain the status and location information of broadcast variables from the Driver end (because all BlockManager slave ends will report the data block status to the Master end).
3) Step 3: preferentially read the broadcast variable data block from the local directory (the data block is local) or other executors of the same host. If it does not exist in this Executor or other executors of the same host, data can only be obtained from the remote end. The principle of obtaining data from the remote end is to obtain data from the Executor end of the host in the same rack. If broadcast variables cannot be obtained from other executors, they will be obtained directly from the Driver side.
As can be seen from the above acquisition process, when executing spark application, as long as the Executor of one worker node obtains the data of broadcast variables from the Driver, other executors do not need to obtain the data from the Driver.
BT protocol
When a data block on an Executor is deleted, you can directly obtain the data block from other executors, and then save the data block to your Executor's BlockManager.
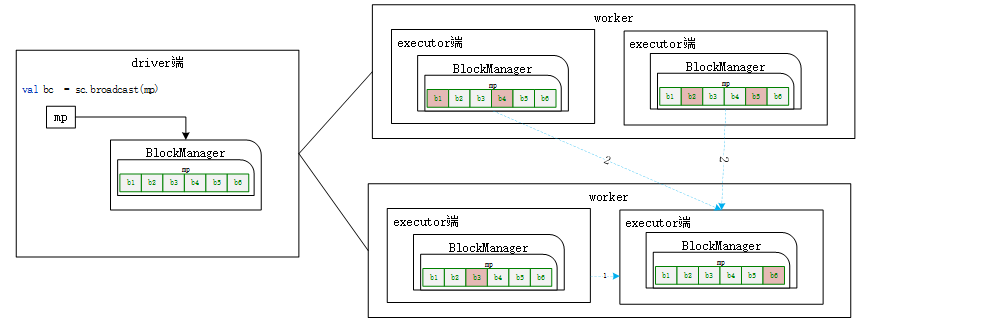
The task in Executor4 needs to use the broadcast variable, but it only has the b4 data block of the variable. At this time, it first obtains data from the of the same host (worker2 node) and obtains the data block; Then read the data blocks from Executor1 and Executor2 of different hosts respectively. At this point, Executor4 obtains all the data blocks of variable b, and then saves a copy of these data blocks in its own BlockManager. At this point, other executors can read data from Executor4.
After these operations are completed, the BlockManager (slave side) on each Executor side will report the status of the data block to the BlockManager (master side) on the Driver side.
matters needing attention
1. Can you broadcast an RDD variable?
No, because RDD does not store data. The results of RDD can be broadcast.
2. Broadcast variables can only be defined on the Driver side, not on the Executor side.
3. The value of the broadcast variable can be modified on the Driver side, but not on the Executor side.
4. If the Driver variable is used on the executor side, if the broadcast variable is not used, there will be as many Driver side variable copies as there are task s in the executor.
5. If the Driver variable is used on the Executor side, and if the broadcast variable is used, there is only one copy of the Driver side variable in each Executor.
Order and user join
Join operator can realize join Association, but it usually produces shuffle, which is not efficient
object _02Join {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getSparkContext()
// Read user data
// u001,benge,18,male,angelababy
val userDataRDD: RDD[String] = sc.textFile("data/order/user.txt")
val userTupleRDD = userDataRDD.map(line=>{
val arr: Array[String] = line.split(",")
(arr(0),(arr(1),arr(2),arr(3),arr(4)))
})
// Read order data
//order033 u005
val orderDataRDD: RDD[String] = sc.textFile("data/order/order.txt")
val orderTupleRDD = orderDataRDD.map(line=>{
val arr: Array[String] = line.split("\\s+")
(arr(1),arr(0))
})
// Mode 2 broadcast variable encapsulation List is inappropriate
val mp: Map[String, (String, String, String, String)] = userTupleRDD.collect().toMap
val bc: Broadcast[Map[String, (String, String, String, String)]] = sc.broadcast(mp)
// val ls: List[(String, String, String, String, String)] = userTupleRDD.collect().toList
// val bc: Broadcast[List[(String, String, String, String, String)]] = sc.broadcast(ls)
val res: RDD[String] = orderTupleRDD.map(order => {
// Get value from broadcast variable
val mp: Map[String, (String, String, String, String)] = bc.value
val uid: String = order._1
val oid: String = order._2
// Get user information from the collection according to uid
val tuple: (String, String, String, String) = mp.getOrElse(uid, ("null", "null", "null", "null"))
oid + "," + uid + "," + tuple._1 + "," + tuple._2 + "," + tuple._3 + "," + tuple._4
})
res.foreach(println)
sc.stop()
}
}