- All the trees we use in this article are user JSON, as shown in the figure below
{"username": "zhangsan","age": 20}
{"username": "lisi","age": 21}
{"username": "wangwu","age": 19}
Custom UDF
Introduction to UDF
UDF: enter a line and return a result For one-to-one relationship, if you put a value into a function, you will return a value instead of multiple values. As can be seen from the following example:
(x: String) => "Name=" + x
In this function, the input parameter is one and the return is one, instead of returning multiple values
Concrete implementation
object UDF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("UTF")
.getOrCreate()
val df = spark.read
.json("data/user.json")
df.createOrReplaceTempView("user")
//Register udf
spark.udf.register("prefixName", (name: String) => {
"Name:" + name
})
spark.sql("select age,prefixName(username) from user").show()
spark.close()
}
}
Result display
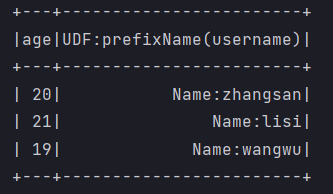
explain
- Before using UDF, you need to register spark udf. register
Customize UDAF
Introduction to UDAF
UDAF can be divided into strong type and weak type
- The main difference between strong and weak types is that strong types should pay attention to the type of data
Both strongly typed Dataset and weakly typed DataFrame provide related aggregation functions, such as count(), countDistinct(), avg(), max(), min(). In addition, users can set their own custom aggregation functions. Implement user-defined weakly typed aggregate functions by inheriting UserDefinedAggregateFunction. UserDefinedAggregateFunction is no longer recommended. The strongly typed aggregate function Aggregator can be used uniformly
Weak type UDAF
Customize UDAF
class MyAvgUDAF extends UserDefinedAggregateFunction {
/**
* For the structure of the input data, we find the average value of age, so the input data is age
* Because it is an aggregate function, when it is positive, enter an array of data, and finally return a data, that is, the average value
* Therefore, the input is an array, the category of data is age, and the type of data is longType
*/
override def inputSchema: StructType = {
StructType(
Array(
StructField("age", LongType)
)
)
}
/**
* buffer
* Buffer is used to temporarily store data. Data will be temporarily stored and calculated here before outputting data
* For example, average value: the data is summed in the buffer, the quantity is calculated, and the average value is output
*
* @return
*/
override def bufferSchema: StructType = {
StructType(
Array(
StructField("total", LongType),
StructField("count", LongType)
)
)
}
/**
* The data type of function output is the data type of calculation result
*
* @return
*/
override def dataType: DataType = LongType
/**
* Stability of function
*
* @return
*/
override def deterministic: Boolean = true
/**
* Initial conversion of buffer
*
* @param buffer
*/
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//Here is how to reset the data in the initial buffer (i.e. return to zero). There are two methods to return to zero
//Method 1
//buffer(0) = 0l
//buffer(1) = 0l
//Method 2
buffer.update(0, 0l)
buffer.update(1, 0l)
}
/**
* Update the data of the buffer according to the input data, that is, the calculation rules of the buffer
*
* @param buffer
* @param input
*/
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//The first data is summation, the data in the buffer plus the input data
buffer.update(0, buffer.getLong(0) + input.getLong(0))
//The second data is to calculate the total, adding one at a time
buffer.update(1, buffer.getLong(1) + 1)
}
/**
* Buffer data merge
* Reserved 1
*
* @param buffer1
* @param buffer2
*/
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1, buffer1.getLong(1) + buffer2.getLong(1))
}
/**
* Calculate average
*
* @param buffer
* @return
*/
override def evaluate(buffer: Row): Any = (buffer.getLong(0) / buffer.getLong(1))
}
Main steps:
- Inherits the UserDefinedAggregateFunction class
- Realize his method
What is the meaning of each method?
- inputSchema: structure of input data. Since it is aggregation, the input data must be an array
- bufferSchema: the structure of buffer data. The buffer is used to write calculation rules. If you choose to calculate the average value, you need to calculate the total number and sum in the buffer
- dataType: the data structure of the output, that is, the data structure of the output result
- deterministic: the stability of the function to ensure consistency. Generally, true is used
- initialize: the buffer is initialized to zero
- Update: update the data of the buffer according to the input data, that is, the calculation rules of the buffer
- Merge: merge of buffers
- evaluate: calculate average
Register and use
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("UDAF")
.getOrCreate()
val df = spark.read
.json("data/user.json")
df.createOrReplaceTempView("user")
//Register function
spark.udf.register("ageAvg",new MyAvgUDAF())
spark.sql("select ageAvg(age) from user").show()
spark.close()
}
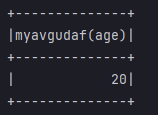
Operation results
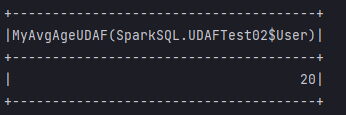
Strongly typed UDAF
Customize two sample classes
//Store buffer data case class Buff(var total: Long, var count: Long) //Store input data case class User(var username: String, var age: Long)
Custom strongly typed UDAF classes
class MyAvgAgeUDAF extends Aggregator[User, Buff, Long] {
/**
* Initial value or zero value
* Buffer initialization
*
* @return
*/
override def zero: Buff = {
Buff(0l, 0l)
}
/**
* Update the data of the buffer according to the input data
*
* @param b
* @param a
* @return
*/
override def reduce(b: Buff, a: User): Buff = {
b.total += a.age
b.count += 1
b
}
/**
* Merge buffer
*
* @param b1
* @param b2
* @return
*/
override def merge(b1: Buff, b2: Buff): Buff = {
b1.total += b2.total
b1.count += b2.count
b1
}
/**
* Calculation results
*
* @param reduction
* @return
*/
override def finish(reduction: Buff): Long = (reduction.total / reduction.count)
/**
* This is a fixed way of writing. If it is a user-defined class, it is: product
* Encoding operation of buffer
*
* @return
*/
override def bufferEncoder: Encoder[Buff] = Encoders.product
/**
* This is also a fixed way of writing. If scala exists, just select the corresponding class (such as long, int, string...)
* Output encoding operation
*
* @return
*/
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
explain
- Inherit the Aggregator class
- Implementation method
- Compared with weak types, you need to define generics for input, buffer and output data
Brief introduction of method
- zero: initialization of buffer
- reduce: update the data of the buffer according to the input data, that is, calculate the total number of data and the sum of data
- Merge: merge buffer data
- Fish: calculation results
- bufferEncoder and · outputEncoder: these two are the encoding formats of buffer and output respectively. In fact, they are in fixed format. If the data output in the next stage is user-defined, they are encoders Product, if the output data is scala's own, it is encoders The long after scalalong depends on the type of data you output
Register and use
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("UDAF")
.getOrCreate()
import spark.implicits._
val df = spark.read
.json("data/user.json")
df.createOrReplaceTempView("user")
val ds = df.as[User]
//Turn UDAF into a query column object
val udafCol = new MyAvgAgeUDAF().toColumn
ds.select(udafCol).show()
spark.close()
}
Result display