I RDD overview
1.1 what is RDD
RDD (Resilient Distributed Dataset) is called elastic distributed dataset. It is the most basic data abstraction in Spark.
Code is an abstract class, which represents an elastic, immutable, partitioned collection in which the elements can be calculated in parallel.
1.2 RDD features
(1) Flexibility
Elasticity of storage: automatic switching of memory to disk
Fault tolerant resilience: data loss can be recovered automatically
Computational flexibility: computational error retry mechanism
Elasticity of slicing: it can be sliced again as needed
(2) Distributed
Data is stored in different nodes of the big data cluster
(3) Dataset, no data stored
RDD encapsulates computing logic and does not save data
(4) Data abstraction
RDD is an abstract class, which needs the concrete implementation of subclasses
abstract class RDD
(5) Immutable
RDD encapsulates the computing logic and cannot be changed. If you want to change, you can only generate a new RDD. The computing logic is encapsulated in the new RDD
(6) Partitioned, parallel computing
1.3 five characteristics of RDD
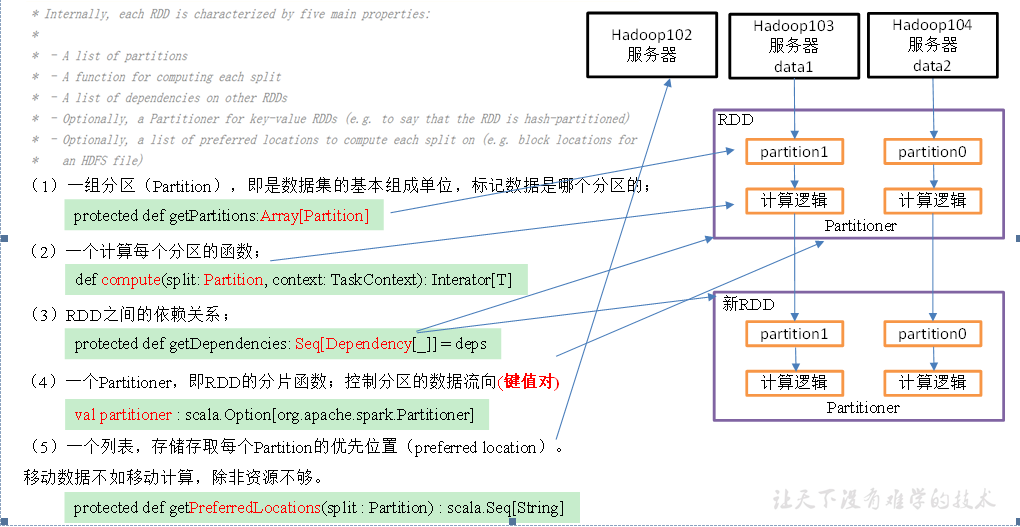
RDD programming
Add in pom file
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1 creation of RDD
There are three ways to create RDDS in Spark: create RDDS from collections, create RDDS from external storage, and create RDDS from other RDDS.
Add test dependency
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.junit.Test
class $01_RDDCreate {
val conf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("test")
val sc = new SparkContext(conf)
/**
* Create rdd from collection
* 1,makeRdd [The bottom layer is parallel]
* 2,parallelize
*/
@Test
def createRddByCollection(): Unit = {
val list: List[String] = List[String]("hello", "java", "spark", "scala", "python")
val rdd: RDD[String] = sc.makeRDD(list)
println(rdd.collect().toList)
val list2: List[(Int, List[String])] = List[(Int, List[String])](
(1, List("aa", "bb")),
(2, List("cc", "dd")),
(3, List("ee", "ff")),
(4, List("gg", "hh"))
)
val rdd2: RDD[(Int, List[String])] = sc.parallelize(list2)
println(rdd2.collect().toList)
}
/**
* Create rdd by reading external files
* sc.textFile File path in:
* 1,If spark_ env. Hadoop is configured in_ CONF_ Dir, the default is to read the HDFS file [generally configured during work]
* Read HDFS file
* sc.textFile("/input/wc.txt")
* sc.textFile("hdfs://hadoop102:8020/input/wc.txt")
* sc.textFile("hdfs:///input/wc.txt")
* Read local file:
* sc.textFile("file:///opt/module/wc.txt")
* 2,If spark_ env. Hadoop is not configured in_ CONF_ Dir, the default is to read the local file
* Read local file:
* sc.textFile("/opt/module/wc.txt")
* sc.textFile("file:///opt/module/wc.txt")
* Read HDFS file:
* sc.textFile("hdfs://hadoop102:8020/input/wc.txt")
*/
@Test
def createRddByFile(): Unit = {
println(sc.textFile("datas\\wc.txt").collect().toList)
println(sc.textFile("hdfs://node1:9820/input/wc.txt").collect().toList)
}
/**
* Derived from other RDDS
*/
@Test
def createRddByRdd(): Unit = {
val rdd1 = sc.textFile("datas/wc.txt")
val rdd2 = rdd1.flatMap(_.split(" "))
println(rdd2.collect().toList)
}
}
2.2 Transformation operator
RDD is generally divided into Value type, double Value type and key Value type
2.2.1 Value type
2.2. 1.1 map
4) Concrete implementation
object value01_map {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 call the map method and multiply each element by 2
val mapRdd: RDD[Int] = rdd.map(_ * 2)
// 3.3 print the data in the modified RDD
mapRdd.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.2.1.2 mapPartitions() executes Map by partition
4) Concrete implementation
object value02_mapPartitions {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 call mapPartitions method and multiply each element by 2
val rdd1 = rdd.mapPartitions(x=>x.map(_*2))
// 3.3 print the data in the modified RDD
rdd1.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.2. 1.3 difference between map() and mapPartitions()
2.3.1.4 mapPartitionsWithIndex() with area code
1) Function signature:
def mapPartitionsWithIndex[U: ClassTag](
f: (int, iterator [t]) = > iterator [u], / / int indicates the partition number
preservesPartitioning: Boolean = false): RDD[U]
2) Function Description: similar to mapPartitions, one integer parameter more than mapPartitions indicates the partition number
3) Requirement Description: create an RDD so that each element forms a tuple with the partition number to form a new RDD
4) Concrete implementation
object value03_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 create an RDD so that each element forms a tuple with the partition number to form a new RDD
val indexRdd = rdd.mapPartitionsWithIndex( (index,items)=>{items.map( (index,_) )} )
// 3.3 print the data in the modified RDD
indexRdd.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.1.5 flatMap() flattening
1) Function signature: def flatmap [u: classtag] (F: T = > traversableonce [u]): RDD [u]
2) Function description
Similar to the map operation, each element in the RDD is successively converted into a new element through the application f function and encapsulated in the RDD.
Difference: in the flatMap operation, the return value of the f function is a collection, and each element in the collection will be split and put into a new RDD.
3) Requirement Description: create a set. What is stored in the set is still a subset. Take out all the data in the subset and put it into a large set.
4) Specific implementation:
object value04_flatMap {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val listRDD=sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)), 2)
// 3.2 take out the data from all subsets and put them into a large set
listRDD.flatMap(list=>list).collect.foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.1.6 glom() partition conversion array
1) Function signature: def glom(): RDD[Array[T]]
2) Function description
This operation turns each partition in the RDD into an array and places it in the new RDD. The element types in the array are consistent with those in the original partition
3) Requirement Description: create an RDD with 2 partitions, put the data of each partition into an array, and calculate the maximum value of each partition
4) Concrete implementation
object value05_glom {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val rdd = sc.makeRDD(1 to 4, 2)
// 3.2 calculate the maximum value of each partition 0 - > 1,2,1 - > 3,4
val maxRdd: RDD[Int] = rdd.glom().map(_.max)
// 3.3 find the sum of the maximum values of all partitions 2 + 4
println(maxRdd.collect().sum)
//4. Close the connection
sc.stop()
}
}
2.3. 1.7 groupby
4) Concrete implementation
object value06_groupby {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val rdd = sc.makeRDD(1 to 4, 2)
// 3.2 put the data of each partition into an array and collect it to the Driver side for printing
rdd.groupBy(_ % 2).collect().foreach(println)
// 3.3 create an RDD
val rdd1: RDD[String] = sc.makeRDD(List("hello","hive","hadoop","spark","scala"))
// 3.4 group according to the first word of the first letter
rdd1.groupBy(str=>str.substring(0,1)).collect().foreach(println)
sc.stop()
}
}
There will be a shuffle process for groupBy
shuffle: the process of disrupting and reorganizing different partition data
shuffle will fall. You can execute the program in local mode and see the effect through 4040.
2.3. 1.8 WordCount of groupby
object value07_groupby_wordcount {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val strList: List[String] = List("Hello Scala", "Hello Spark", "Hello World")
val rdd = sc.makeRDD(strList)
// 3.2 splitting strings into words
val wordRdd: RDD[String] = rdd.flatMap(str => str.split(" "))
// 3.3 convert word results: word = > (word, 1)
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map(word => (word, 1))
// 3.4 grouping data after structure conversion
val groupRdd: RDD[(String, Iterable[(String, Int)])] = wordToOneRdd.groupBy(t => t._1)
// 3.5 structure conversion of grouped data
// val wordToSum: RDD[(String, Int)] = groupRdd.map(
// t => (t._1, t._2.toList.size)
// )
// val wordToSum: RDD[(String, Int)] = groupRdd.map {
// x =>
// x match {
// case (word, list) => {
// (word, list.size)
// }
// }
// }
val wordToSum: RDD[(String, Int)] = groupRdd.map {
case (word, list) => {
(word, list.size)
}
}
// 3.6 printout
wordToSum.collect().foreach(println)
// 4 close resources
sc.stop()
}
}
2.3. 1.9 filter
1) Function signature: def filter (F: T = > Boolean): RDD [t]
2) Function description
Receives a function with a Boolean return value as an argument. When an RDD calls the filter method, the f function will be applied to each element in the RDD. If the return value type is true, the element will be added to the new RDD.
3) Requirement Description: create an RDD to filter out the data with the remainder of 2 equal to 0
4) Code implementation
object value08_filter {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create an RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 2)
//3.1 filter out qualified data
val filterRdd: RDD[Int] = rdd.filter(_ % 2 == 0)
//3.2 collect and print data
filterRdd.collect().foreach(println)
//4 close the connection
sc.stop()
}
}
2.3. 1.10 sample
1) Function signature:
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
//withReplacement: true is the sample with return, and false is the sample without return;
//fraction means: the data with the number of fractions randomly sampled from the specified random seeds;
//Seed: Specifies the seed of the random number generator.
2) Function description
Sampling from large amounts of data
3) Requirement Description: create an RDD (1-10) from which you can select whether to put it back or not
4) Code implementation
object value09_sample {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3.1 create an RDD
val dataRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6))
// Extracted data is not put back (Bernoulli algorithm)
// Bernoulli algorithm: also known as 0 and 1 distribution. For example, flip a coin, either front or back.
// Specific implementation: calculate a number according to the seed and random algorithm and compare the probability of setting the second parameter. It is less than the second parameter and greater than not
// The first parameter: whether to put the extracted data back; false: not to put it back
// The second parameter: the probability of extraction, ranging from [0,1], 0: none; 1: Full access;
// Third parameter: random number seed
val sampleRDD: RDD[Int] = dataRDD.sample(false, 0.5)
sampleRDD.collect().foreach(println)
println("----------------------")
// Put the extracted data back (Poisson algorithm)
// The first parameter: whether to put the extracted data back. true: put back; false: do not put it back
// The second parameter: the probability of duplicate data. The range is greater than or equal to 0 Represents the number of times each element is expected to be extracted
// Third parameter: random number seed
val sampleRDD1: RDD[Int] = dataRDD.sample(true, 2)
sampleRDD1.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
5) Random number test
public class TestRandom {
public static void main(String[] args) {
// If the random algorithm is the same and the seeds are the same, the random number is the same
//Random r1 = new Random(100);
// Without inputting parameters, the seed takes the nanosecond value of the current time, so the random results are different
Random r1 = new Random();
for (int i = 0; i < 5; i++) {
System.out.println(r1.nextInt(10));
}
System.out.println("--------------");
//Random r2 = new Random(100);
Random r2 = new Random();
for (int i = 0; i < 5; i++) {
System.out.println(r2.nextInt(10));
}
}
}
Output results with the same seed:
5
0
4
8
5
0
4
8
1
2.3. 1.11 distinct weight removal
4) Code implementation
object value10_distinct {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val distinctRdd: RDD[Int] = sc.makeRDD(List(1,2,1,5,2,9,6,1))
// 3.2 print the new RDD generated after de duplication
distinctRdd.distinct().collect().foreach(println)
// 3.3 adopt multiple tasks for RDD to remove duplication and improve concurrency
distinctRdd.distinct(2).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.1.12 coalesce() merge partitions
Coalesce operator includes two ways: configure to execute Shuffle and configure not to execute Shuffle.
1. Do not execute Shuffle mode
1) Function signature:
def coalesce(numPartitions: Int, shuffle: Boolean = false, / / default false, shuffle is not executed
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null) : RDD[T]
2) Function Description: reduce the number of partitions to improve the execution efficiency of small data sets after filtering large data sets.
3) Requirements: 4 partitions are combined into 2 partitions
4) Partition source code
5) Code implementation
object value11_coalesce {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create an RDD
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 4)
//3.1 reduced zoning
//val coalesceRdd: RDD[Int] = rdd.coalesce(2)
//4. Create an RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//4.1 reduced zoning
val coalesceRDD: RDD[Int] = rdd.coalesce(2)
//5. View the corresponding partition data
val indexRDD: RDD[(Int, Int)] = coalesceRDD.mapPartitionsWithIndex(
(index, datas) => {
datas.map((index, _))
}
)
//6 print data
indexRDD.collect().foreach(println)
//8 delay for a period of time and observe http://localhost:4040 Page to view the Shuffle read and write time
Thread.sleep(100000)
//7. Close the connection
sc.stop()
}
}
2. Execute Shuffle mode
//3. Create an RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 execute shuffle
val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)
Output results:
(0,1)
(0,4)
(0,5)
(1,2)
(1,3)
(1,6)
3. Shuffle principle
2.3. 1.13 repartition (execute Shuffle)
1) Function signature: def replication (numpartitions: int) (implicit order: ordering [t] = null): RDD [t]
2) Function description
This operation is actually a coalesce operation, and the default value of the parameter shuffle is true. Whether you convert an RDD with a large number of partitions to an RDD with a small number of partitions, or convert an RDD with a small number of partitions to an RDD with a large number of partitions, the repartition operation can be completed, because it will go through the shuffle process anyway.
3) Requirement Description: create an RDD with 4 partitions and re partition it.
4) Code implementation
object value12_repartition {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create an RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 reduced zoning
//val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)
//3.2 re zoning
val repartitionRdd: RDD[Int] = rdd.repartition(2)
//4. Print and view the corresponding partition data
val indexRdd: RDD[(Int, Int)] = repartitionRdd.mapPartitionsWithIndex(
(index, datas) => {
datas.map((index, _))
}
)
//5 printing
indexRdd.collect().foreach(println)
//6. Close the connection
sc.stop()
}
}
2.3. 1.14 difference between coalesce and repartition
1) When the coalesce is repartitioned, you can choose whether to perform the shuffle process. Determined by the parameter shuffle: Boolean = false/true.
2) repartition is actually called coalesce to shuffle. The source code is as follows:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
3) coalesce is generally a reduced partition. If the partition is expanded, it is meaningless not to use shuffle. repartition expands the partition and executes shuffle.
2.3.1.15 sortBy() sort
1) Function signature:
def sortBy[K]( f: (T) => K,
ascending: Boolean = true, / / the default is positive order
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
2) Function description
This operation is used to sort data. Before sorting, the data can be processed through the f function, and then sorted according to the processing results of the f function. The default is positive order. After sorting, the number of partitions of the newly generated RDD is the same as that of the original RDD.
3) Requirement Description: create an RDD to sort in positive order and reverse order according to the number size
4) Code implementation:
object value13_sortBy {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
// 3.1 create an RDD
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4, 6, 5))
// 3.2 the default is ascending
val sortRdd: RDD[Int] = rdd.sortBy(num => num)
sortRdd.collect().foreach(println)
// 3.3 configuration is in reverse order
val sortRdd2: RDD[Int] = rdd.sortBy(num => num, false)
sortRdd2.collect().foreach(println)
// 3.4 create an RDD
val strRdd: RDD[String] = sc.makeRDD(List("1", "22", "12", "2", "3"))
// 3.5 sorting by int value of characters
strRdd.sortBy(num => num.toInt).collect().foreach(println)
// 3.5 create an RDD
val rdd3: RDD[(Int, Int)] = sc.makeRDD(List((2, 1), (1, 2), (1, 1), (2, 2)))
// 3.6 first sort according to the first value of tuple, and then sort according to the second value
rdd3.sortBy(t=>t).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.1.16 pipe() calling script
1) Function signature: def pipe(command: String): RDD[String]
2) Function description
The pipeline calls the shell script once for each partition and returns the output RDD.
Note: where the Worker node can access, the script needs to be placed
3) Requirement Description: write a script and use the pipeline to act on the RDD.
(1) Write a script and increase the execution permission
[atguigu@hadoop102 spark-local]$ vim pipe.sh
#!/bin/bash
echo "Start"
while read LINE; do
echo ">>>"${LINE}
done
[atguigu@hadoop102 spark-local]$ chmod 777 pipe.sh
(2) Create an RDD with only one partition
[atguigu@hadoop102 spark-local]$ bin/spark-shell
scala> val rdd = sc.makeRDD (List("hi","Hello","how","are","you"), 1)
(3) Apply the script to the RDD and print it
scala> rdd.pipe("/opt/module/spark-local/pipe.sh").collect()
res18: Array[String] = Array(Start, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
(4) Create an RDD with two partitions
scala> val rdd = sc.makeRDD(List("hi","Hello","how","are","you"), 2)
(5) Apply the script to the RDD and print it
scala> rdd.pipe("/opt/module/spark-local/pipe.sh").collect()
res19: Array[String] = Array(Start, >>>hi, >>>Hello, Start, >>>how, >>>are, >>>you)
Description: a partition calls a script once.
2.2. 2 double Value type interaction
1) Create package name: com atguigu. doublevalue
2.3. 2.1 intersection
1) Function signature: def intersection(other: RDD[T]): RDD[T]
2) Function description
Returns a new RDD after intersecting the source RDD and the parameter RDD
Intersection: only 3
3) Requirement Description: create two RDDS and find the intersection of the two RDDS
4) Code implementation:
object DoubleValue01_intersection {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 create a second RDD
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 calculate the intersection of the first RDD and the second RDD and print it
rdd1.intersection(rdd2).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.2.2 union() union
1) Function signature: def union(other: RDD[T]): RDD[T]
2) Function description
Returns a new RDD after combining the source RDD and the parameter RDD
Union: 1, 2 and 3 are all included
3) Requirement Description: create two RDD S and combine them
4) Code implementation:
object DoubleValue02_union {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 create a second RDD
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 calculate the union of two RDD S
rdd1.union(rdd2).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.2.3 subtract() difference set
1) Function signature: def subtract(other: RDD[T]): RDD[T]
2) Function description
A function to calculate the difference. Remove the same elements in two RDDS, and different RDDS will be retained
Difference set: only 1
3) Requirement Description: create two RDDS and find the difference set between the first RDD and the second RDD
4) Code implementation:
object DoubleValue03_subtract {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 create a second RDD
val rdd1: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 calculate the difference set between the first RDD and the second RDD and print it
rdd.subtract(rdd1).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3. 2.4 zip (zipper)
1) Function signature: def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
2) Function description
This operation can merge the elements in two RDDS in the form of Key Value pairs. Where, the Key in the Key Value pair is the element in the first RDD, and the Value is the element in the second RDD.
Combine the two RDDS into an RDD in the form of Key/Value. By default, the number of partition s and elements of the two RDDS are the same, otherwise an exception will be thrown.
3) Requirement Description: create two RDDS and combine them to form a (k,v)RDD
4) Code implementation:
object DoubleValue04_zip {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd1: RDD[Int] = sc.makeRDD(Array(1,2,3),3)
//3.2 create a second RDD
val rdd2: RDD[String] = sc.makeRDD(Array("a","b","c"),3)
//3.3 the first RDD combines the second RDD and prints
rdd1.zip(rdd2).collect().foreach(println)
//3.4 the second RDD combines the first RDD and prints it
rdd2.zip(rdd1).collect().foreach(println)
//3.5 create a third RDD (different from the number of partitions 1 and 2)
val rdd3: RDD[String] = sc.makeRDD(Array("a","b"), 3)
//3.6 the number of elements is different and cannot be zipped
// Can only zip RDDs with same number of elements in each partition
rdd1.zip(rdd3).collect().foreach(println)
//3.7 create the fourth RDD (different from the number of partitions 1 and 2)
val rdd4: RDD[String] = sc.makeRDD(Array("a","b","c"), 2)
//3.8 the number of partitions is different, and zippers cannot be used
// Can't zip RDDs with unequal numbers of partitions: List(3, 2)
rdd1.zip(rdd4).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.2. 3 key value type
1) Create package name: com atguigu. keyvalue
2.3.3.1 partitionBy() re partition according to K
1) Function signature: def partitionBy(partitioner: Partitioner): RDD[(K, V)]
2) Function description
Re partition K in RDD[K,V] according to the specified Partitioner;
If the original RDD is consistent with the new RDD, it will not be partitioned, otherwise a Shuffle process will be generated.
3) Requirement Description: create an RDD with three partitions and re partition it
4) Code implementation:
object KeyValue01_partitionBy {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3)
//3.2 repartition of RDD
val rdd2: RDD[(Int, String)] = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
//3.3 print and view the corresponding partition data (0, (2, BBB)) (1, (1, AAA)) (1, (3, CCC))
val indexRdd = rdd2.mapPartitionsWithIndex(
(index, datas) => datas.map((index,_))
)
indexRdd.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3. 3.2 user defined partition
1) Interpretation of HashPartitioner source code
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
2) Custom partition
To implement a custom partition, you need to inherit org apache. spark. Partitioner class and implement the following three methods.
(1) numPartitions: Int: returns the number of partitions created.
(2) getPartition(key: Any): Int: returns the partition number of the given key (0 to numPartitions-1).
(3) equals():Java's standard method for judging equality. The implementation of this method is very important. Spark needs to use this method to check whether your partition object is the same as other partition instances, so that spark can judge whether the partition methods of two RDD S are the same
object KeyValue01_partitionBy {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
//3.2 user defined partition
val rdd3: RDD[(Int, String)] = rdd.partitionBy(new MyPartitioner(2))
//4. Print and view the corresponding partition data
val indexRdd = rdd3.mapPartitionsWithIndex(
(index, datas) => datas.map((index,_))
)
indexRdd.collect()
//5. Close the connection
sc.stop()
}
}
// Custom partition
class MyPartitioner(num: Int) extends Partitioner {
// Number of partitions set
override def numPartitions: Int = num
// Specific partition logic
override def getPartition(key: Any): Int = {
if (key.isInstanceOf[Int]) {
val keyInt: Int = key.asInstanceOf[Int]
if (keyInt % 2 == 0)
0
else
1
}else{
0
}
}
}
2.3.3.3 reduceByKey() aggregates V according to K
1) Function signature:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
2) Function Description: this operation can aggregate the elements in RDD[K,V] to V according to the same K. There are many overload forms, and you can also set the number of partitions of the new RDD.
3) Requirement Description: count the number of words
4) Code implementation:
object KeyValue02_reduceByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 calculate the addition result of the corresponding value of the same key
val reduce: RDD[(String, Int)] = rdd.reduceByKey((v1,v2) => v1+v2)
//3.3 printing results
reduce.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.3.4 groupByKey() regroups by K
1) Function signature: def groupbykey(): RDD [(k, iteratable [v])]
2) Function description
groupByKey operates on each key, but only generates one seq without aggregation.
This operation can specify the partitioner or the number of partitions (HashPartitioner is used by default)
3) Requirement Description: count the occurrence times of words (redraw the figure below)
4) Code implementation:
object KeyValue03_groupByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 aggregate the corresponding values of the same key into a Seq
val group: RDD[(String, Iterable[Int])] = rdd.groupByKey()
//3.3 printing results
group.collect().foreach(println)
//3.4 calculate the addition result of the corresponding value of the same key
group.map(t=>(t._1,t._2.sum)).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3. 3.5 difference between reducebykey and groupByKey
1) reduceByKey: aggregate by key. There is a combine operation before shuffle. The returned result is RDD[K,V].
2) groupByKey: group by key and shuffle directly.
3) Development guidance: reduceByKey is preferred without affecting business logic. Summation does not affect business logic, and averaging affects business logic.
2.3.3.6 aggregateByKey() processes intra partition and inter partition logic according to K
2) Demand analysis
3) Code implementation:
object KeyValue04_aggregateByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8)), 2)
//3.2 take out the maximum value of the corresponding value of the same key in each partition and add it
rdd.aggregateByKey(0)(math.max(_, _), _ + _).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.3.7 foldByKey() the same aggregateByKey() in and between partitions
4) Code implementation:
object KeyValue05_foldByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val list: List[(String, Int)] = List(("a",1),("a",1),("a",1),("b",1),("b",1),("b",1),("b",1),("a",1))
val rdd = sc.makeRDD(list,2)
//3.2 wordcount
//rdd.aggregateByKey(0)(_+_,_+_).collect().foreach(println)
rdd.foldByKey(0)(_+_).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3. 3.8 intra partition and inter partition operations after combinebykey() structure conversion
1) Function signature:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
(1) createCombiner (structure of converted data): combineByKey() will traverse all elements in the partition, so the key of each element is either not encountered or the same as that of a previous element. If this is a new element, combinebykey () uses a function called createCombiner() to create the initial value of the accumulator corresponding to that key
(2) mergeValue (in partition): if this is a key that has been encountered before processing the current partition, it will use the mergeValue() method to merge the current value corresponding to the accumulator of the key with the new value
(3) mergeCombiners: since each partition is handled independently, there can be multiple accumulators for the same key. If two or more partitions have accumulators corresponding to the same key, you need to use the mergeCombiners() method provided by the user to merge the results of each partition.
2) Function description
Merge V into a set for the same K.
3) Requirement Description: create a pairRDD and calculate the average value of each key according to the key. (first calculate the number of occurrences of each key and the sum of the corresponding values, and then divide to get the result)
4) Demand analysis:
5) Code implementation
object KeyValue06_combineByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3.1 create the first RDD
val list: List[(String, Int)] = List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val input: RDD[(String, Int)] = sc.makeRDD(list, 2)
//3.2 add the values corresponding to the same key, record the number of occurrences of the key, and put it into a binary
val combineRdd: RDD[(String, (Int, Int))] = input.combineByKey(
(_, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
)
//3.3 print consolidated results
combineRdd.collect().foreach(println)
//3.4 calculate the average value
combineRdd.map {
case (key, value) => {
(key, value._1 / value._2.toDouble)
}
}.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.3.9 reduceByKey,foldByKey,aggregateByKey,combineByKey
2.3.3.10 sortByKey() sort by K
1) Function signature:
def sortByKey(
ascending: Boolean = true, / / default, ascending
numPartitions: Int = self.partitions.length) : RDD[(K, V)]
2) Function description
When called on a (K,V) RDD, K must implement the Ordered interface and return a (K,V) RDD sorted by key
3) Requirement Description: create a pairRDD and sort according to the positive and reverse order of key s
4) Code implementation:
object KeyValue07_sortByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//3.2 in the positive order of key s (default order)
rdd.sortByKey(true).collect().foreach(println)
//3.3 in reverse order of key s
rdd.sortByKey(false).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.3.11 mapValues() operates on V only
1) Function signature: def mapvalues [u] (F: v = > U): RDD [(k, U)]
2) Function Description: for the type of (K,V), only V is operated
3) Requirement Description: create a pairRDD and add value to the string "||"
4) Code implementation:
object KeyValue08_mapValues {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c")))
//3.2 add the string "|" to value
rdd.mapValues(_ + "|||").collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3. 3.12 join
1) Function signature:
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
2) Function description
Call on RDDS of types (K,V) and (K,W) to return the RDD of (K,(V,W)) of all element pairs corresponding to the same key
3) Requirement Description: create two pairrdds and aggregate the data with the same key into a tuple.
4) Code implementation:
object KeyValue09_join {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
//3.2 create a second pairRDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
//3.3 join operation and print results
rdd.join(rdd1).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3.3.13 cogroup() is similar to full connection, but it aggregates key s in the same RDD
1) Function signature: def cogroup [w] (other: RDD [(k, w)]): RDD [(k, (iteratable [v], iteratable [w])]
2) Function description
Called on RDDS of types (K,V) and (K,W), returns an RDD of type (k, (iteratable, iteratable))
Operate the KV elements in two RDDS, and the elements in the same key in each RDD are aggregated into a set.
3) Requirement Description: create two pairrdds and aggregate the data with the same key into an iterator.
4) Code implementation:
object KeyValue10_cogroup {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
//3.2 create a second RDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1,4),(2,5),(4,6)))
//3.3 cogroup two RDD S and print the results
// (1,(CompactBuffer(a),CompactBuffer(4)))
// (2,(CompactBuffer(b),CompactBuffer(5)))
// (3,(CompactBuffer(c),CompactBuffer()))
// (4,(CompactBuffer(),CompactBuffer(6)))
rdd.cogroup(rdd1).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.3. 4 case practice (the provincial advertisement was clicked on top 3)
0) data preparation: timestamps, provinces, cities, users, advertisements, and intermediate fields are separated by spaces.
3) Implementation process
object Demo_ad_click_top3 {
def main(args: Array[String]): Unit = {
//1. Initialize Spark configuration information and establish a connection with Spark
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkCoreTest")
val sc = new SparkContext(sparkConf)
//2. Read the log file and obtain the original data
val dataRDD: RDD[String] = sc.textFile("input/agent.log")
//3. Structure conversion of original data string = > (PRV adv, 1)
val prvAndAdvToOneRDD: RDD[(String, Int)] = dataRDD.map {
line => {
val datas: Array[String] = line.split(" ")
(datas(1) + "-" + datas(4), 1)
}
}
//4. Aggregate the data after structure conversion (PRV adv, 1) = > (PRV adv, sum)
val prvAndAdvToSumRDD: RDD[(String, Int)] = prvAndAdvToOneRDD.reduceByKey(_ + _)
//5. Convert the statistical results to structure (PRV adv, sum) = > (PRV, (adv, sum))
val prvToAdvAndSumRDD: RDD[(String, (String, Int))] = prvAndAdvToSumRDD.map {
case (prvAndAdv, sum) => {
val ks: Array[String] = prvAndAdv.split("-")
(ks(0), (ks(1), sum))
}
}
//6. Group data according to provinces: (PRV, (adv, sum)) = > (PRV, iterator [(adv, sum)])
val groupRDD: RDD[(String, Iterable[(String, Int)])] = prvToAdvAndSumRDD.groupByKey()
//7. Sort the advertisements in the same province (in descending order) and take the top three
val mapValuesRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues {
datas => {
datas.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(3)
}
}
//8. Print the results
mapValuesRDD.collect().foreach(println)
//9. Close the connection with spark
sc.stop()
}
}
2.3 Action operator
The action operator triggers the execution of the whole job. Because the conversion operators are lazy loading and will not be executed immediately.
1) Create package name: com atguigu. action
2.4.1 reduce() aggregation
1) Function signature: def reduce (F: (T, t) = > t): t
2) Function Description: the f function aggregates all elements in RDD, first aggregates data in partitions, and then aggregates data between partitions.
3) Requirement Description: create an RDD and aggregate all elements to get the result
object action01_reduce {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 aggregate data
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult)
//4. Close the connection
sc.stop()
}
}
2.4. 2. Collect() returns the data set as an array
1) Function signature: def collect(): Array[T]
2) Function Description: in the driver, all elements of the dataset are returned in the form of Array array.
Note: all data will be pulled to the Driver. Use with caution
3) Requirement Description: create an RDD and collect the RDD content to the Driver side for printing
object action02_collect {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 collect data to Driver
rdd.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.4.3 count() returns the number of elements in the RDD
1) Function signature: def count(): Long
2) Function Description: returns the number of elements in RDD
3) Requirement Description: create an RDD and count the number of RDDS
object action03_count {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 return the number of elements in RDD
val countResult: Long = rdd.count()
println(countResult)
//4. Close the connection
sc.stop()
}
}
2.4.4 first() returns the first element in the RDD
1) Function signature: def first(): T
2) Function Description: returns the first element in RDD
3) Requirement Description: create an RDD and return the first element in the RDD
object action04_first {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 return the number of elements in RDD
val firstResult: Int = rdd.first()
println(firstResult)
//4. Close the connection
sc.stop()
}
}
2.4.5 take() returns an array consisting of the first n RDD elements
1) Function signature: def take(num: Int): Array[T]
2) Function Description: returns an array composed of the first n elements of RDD
3) Requirement Description: create an RDD and count the number of RDDS
object action05_take {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 return the first two elements in RDD
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))
//4. Close the connection
sc.stop()
}
}
2.4.6 takeOrdered() returns an array of the first n elements after the RDD is sorted
1) Function signature: def takeordered (Num: int) (implicit order: ordering [t]): array [t]
2) Function Description: returns the array composed of the first n elements sorted by the RDD
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
...
if (mapRDDs.partitions.length == 0) {
Array.empty
} else {
mapRDDs.reduce { (queue1, queue2) =>
queue1 ++= queue2
queue1
}.toArray.sorted(ord)
}
}
3) Requirement Description: create an RDD and get the first two elements after the RDD is sorted
object action06_takeOrdered{
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
//3.2 return the first two elements after ordering in RDD
val result: Array[Int] = rdd.takeOrdered(2)
println(result.mkString(","))
//4. Close the connection
sc.stop()
}
}
2.4.7 aggregate() case
3) Requirement Description: create an RDD and add all elements to get the result
object action07_aggregate {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8)
//3.2 add all elements of the RDD to get the result
//val result: Int = rdd.aggregate(0)(_ + _, _ + _)
val result: Int = rdd.aggregate(10)(_ + _, _ + _)
println(result)
//4. Close the connection
sc.stop()
}
}
2.4.8 fold() case
3) Requirement Description: create an RDD and add all elements to get the result
object action08_fold {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//3.2 add all elements of the RDD to get the result
val foldResult: Int = rdd.fold(0)(_+_)
println(foldResult)
//4. Close the connection
sc.stop()
}
}
2.4. 9. Countbykey() counts the number of keys of each type
1) Function signature: def countByKey(): Map[K, Long]
2) Function Description: count the number of key s of each type
3) Requirement Description: create a PairRDD and count the number of key s of each type
object action09_countByKey {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
//3.2 count the number of key s of each type
val result: collection.Map[Int, Long] = rdd.countByKey()
println(result)
//4. Close the connection
sc.stop()
}
}
2.4.10 save correlation operator
1) saveAsTextFile(path) is saved as a Text file
(1) Function signature
(2) Function Description: save the elements of the dataset to the HDFS file system or other supported file systems in the form of textfile. For each element, Spark will call the toString method to replace it with the text in the file
2) saveAsSequenceFile(path) saves as a Sequencefile file
(1) Function signature
(2) Function Description: save the elements in the dataset to the specified directory in the format of Hadoop Sequencefile, which can enable HDFS or other file systems supported by Hadoop.
Note: only kv type RDD S have this operation, and single valued ones do not
3) saveAsObjectFile(path) serializes objects and saves them to a file
(1) Function signature
(2) Function Description: used to serialize elements in RDD into objects and store them in files.
4) Code implementation
object action10_save {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
//3.2 save as Text file
rdd.saveAsTextFile("output")
//3.3 saving serialized objects to files
rdd.saveAsObjectFile("output1")
//3.4 save as Sequencefile file
rdd.map((_,1)).saveAsSequenceFile("output2")
//4. Close the connection
sc.stop()
}
}
2.4.11 foreach(f) traverses every element in the RDD
3) Requirement Description: create an RDD and print each element
object action11_foreach {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
//3.1 create the first RDD
// val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 print after collection
rdd.collect().foreach(println)
println("****************")
//3.3 distributed printing
rdd.foreach(println)
//4. Close the connection
sc.stop()
}
}
RDD serialization
In actual development, we often need to define some RDD operations ourselves. At this time, it should be noted that the initialization is carried out on the Driver side, while the actual running program is carried out on the Executor side, which involves cross process communication and needs serialization. Here are some examples:
2.5. 1 closure check
0) create package name: com atguigu. serializable
1) Closure Introduction (serialization is required if there is a closure)
object serializable01_object {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create two objects
val user1 = new User()
user1.name = "zhangsan"
val user2 = new User()
user2.name = "lisi"
val userRDD1: RDD[User] = sc.makeRDD(List(user1, user2))
//3.1 print, ERROR report Java io. NotSerializableException
//userRDD1.foreach(user => println(user.name))
//3.2 print, RIGHT (because no object is transmitted to the Executor)
val userRDD2: RDD[User] = sc.makeRDD(List())
//userRDD2.foreach(user => println(user.name))
//3.3 printing, ERROR Task not serializable note: an error is reported if it is not executed
userRDD2.foreach(user => println(user1.name))
//4. Close the connection
sc.stop()
}
}
//class User {
// var name: String = _
//}
class User extends Serializable {
var name: String = _
}
2.5. 2 serialization methods and properties
1) Explain
Driver: code other than operators is executed on the driver side
Executor: the code in the operator is executed on the executor side
2) Code implementation
object serializable02_function {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create an RDD
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
//3.1 create a Search object
val search = new Search("hello")
// Driver: code other than operators is executed on the driver side
// Executor: the code in the operator is executed on the executor side
//3.2 function transfer and printing: ERROR Task not serializable
search.getMatch1(rdd).collect().foreach(println)
//3.3 attribute transfer and printing: ERROR Task not serializable
search.getMatche2(rdd).collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// Function serialization case
def getMatch1 (rdd: RDD[String]): RDD[String] = {
//rdd.filter(this.isMatch)
rdd.filter(isMatch)
}
// Property serialization case
def getMatche2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
rdd.filter(x => x.contains(query))
//val q = query
//rdd.filter(x => x.contains(q))
}
}
3) Question 1 Description
//Filter out RDD S containing strings
def getMatch1 (rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
(1) The method ismatch () called in this method is defined in the Search class, which actually calls this isMatch(), this represents the object of the Search class. The program needs to serialize the Search object and pass it to the Executor side during operation.
(2) Solution
Class inherits Scala Serializable.
class Search() extends Serializable{...}
4) Description of question 2
//Filter out RDD S containing strings
def getMatche2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
(1) In this method, the called method query is a field defined in the Search class. In fact, it calls this. query, which represents the object of the Search class. During the running process, the program needs to serialize the Search object and pass it to the Executor.
(2) Solution I
(a) Class can inherit scala.Serializable.
class Search() extends Serializable{...}
(b) Assign the class variable query to the local variable
Modify getmatch2 to
//Filter out RDD S containing strings
def getMatche2(rdd: RDD[String]): RDD[String] = {
val q = this.query / / assign class variables to local variables
rdd.filter(x => x.contains(q))
}
(3) Solution II
Turn the Search class into a sample class, which is serialized by default.
case class Search(query:String) {...}
2.5.3 Kryo serialization framework
Reference address: https://github.com/EsotericSoftware/kryo
Java serialization can serialize any class. However, it is heavy, and the volume of the serialized object is also large.
Spark for performance reasons, spark2 0 began to support another kryo serialization mechanism. Kryo is 10 times faster than Serializable. When RDD uses Shuffle data, simple data types, arrays and string types have been serialized with kryo inside spark.
Note: even if Kryo serialization is used, the Serializable interface should be inherited.
object serializable03_Kryo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// Replace the default serialization mechanism
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// Register custom classes that require kryo serialization
.registerKryoClasses(Array(classOf[Searche]))
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2)
val searche = new Searche("hello")
val result: RDD[String] = searche.getMatchedRDD1(rdd)
result.collect.foreach(println)
}
}
case class Searche(val query: String) {
def isMatch(s: String) = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]) = {
rdd.filter(isMatch)
}
def getMatchedRDD2(rdd: RDD[String]) = {
val q = query
rdd.filter(_.contains(q))
}
}
RDD dependencies
2.6. 1 view blood relationship
RDD only supports coarse-grained transformation, that is, a single operation performed on a large number of records. Record a series of lineages (lineages) of the created RDD to recover the lost partition. The Lineage of the RDD will record the metadata information and conversion behavior of the RDD. When some partition data of the RDD is lost, it can recalculate and recover the lost data partition according to this information.
0) create package name: com atguigu. dependency
1) Code implementation
object Lineage01 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
//4. Close the connection
sc.stop()
}
}
2) Print results
(2) input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 [] |
|---|
(2) MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []
| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 [] |
|---|
(2) MapPartitionsRDD[3] at map at Lineage01.scala:23 []
| MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []
| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 [] |
|---|
(2) ShuffledRDD[4] at reduceByKey at Lineage01.scala:27 []
±(2) MapPartitionsRDD[3] at map at Lineage01.scala:23 []
| MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []
| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
Note: the number in parentheses indicates the parallelism of RDD, that is, there are several partitions
2.6. 2 view dependencies
1) Code implementation
object Lineage02 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.dependencies)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.dependencies)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.dependencies)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.dependencies)
resultRDD.collect()
// Check the localhost:4040 page and observe the DAG diagram
Thread.sleep(10000000)
//4. Close the connection
sc.stop()
}
}
2) Print results
List(org.apache.spark.OneToOneDependency@f2ce6b)
List(org.apache.spark.OneToOneDependency@692fd26)
List(org.apache.spark.OneToOneDependency@627d8516)
List(org.apache.spark.ShuffleDependency@a518813)
3) Global search (ctrl+n) org.apache.spark.onetooonedependency
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependencyT {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
Note: to understand how RDDS works, the most important thing is to understand Transformations.
The relationship between RDDS can be understood from two dimensions: one is which RDDS are converted from, that is, what is the parent RDD(s) of RDD; The other is the Partition(s) of the parent RDD(s) that RDD depends on. This relationship is the dependency between RDDS.
There are two different types of relationships between RDD and its dependent parent RDD (s), namely narrow dependency and wide dependency.
2.6. 3 narrow dependence
Narrow dependency means that the Partition of each parent RDD is used by one Partition of the child RDD at most. Narrow dependency is figuratively compared to the only child.
2.6. 4 wide dependence
Wide dependency means that the Partition of the same parent RDD is dependent on the Partition of multiple child RDDS, which will cause Shuffle. Summary: wide dependency is compared to superbirth.
transformations with wide dependencies include sort, reduceByKey, groupByKey, join, and any operation that calls the rePartition function.
Wide dependency has a more important impact on Spark to evaluate a transformation, such as the impact on performance.
2.6.5 Stage task division (interview focus)
1) DAG directed acyclic graph
DAG (Directed Acyclic Graph) is a topological graph composed of points and lines. The graph has direction and will not be closed-loop. For example, DAG records the conversion process of RDD and the stage of task.
2) Overall process of task operation
3) RDD Task segmentation is divided into Application, Job, Stage and Task
(1) Application: initialize a SparkContext to generate an application;
(2) Job: an Action operator will generate a job;
(3) Stage: stage is equal to the number of wide dependencies plus 1;
(4) Task: in a Stage, the number of partitions of the last RDD is the number of tasks.
Note: each layer of application - > job - > stage - > task has a 1-to-n relationship.
4) Code implementation
object Stage01 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Application: initialize a SparkContext to generate an application;
val sc: SparkContext = new SparkContext(conf)
//3. Create RDD
val dataRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4,1,2),2)
//3.1 polymerization
val resultRDD: RDD[(Int, Int)] = dataRDD.map((_,1)).reduceByKey(_+_)
// Job: an Action operator will generate a job;
//3.2 job1 printing to console
resultRDD.collect().foreach(println)
//3.3 job2 output to disk
resultRDD.saveAsTextFile("output")
Thread.sleep(1000000)
//4. Close the connection
sc.stop()
}
}
5) View the number of jobs
see http://localhost:4040/jobs/ , I found that Job has two.
6) View the number of stages
View the Stage of Job0. Since there is only one Shuffle Stage, the number of stages is 2.
View Job1's Stage. Since there is only one Shuffle Stage, the number of stages is 2.
7) Number of tasks
View the number of tasks in Stage0 of Job0
View the number of tasks in Stage1 of Job0
View the number of tasks in Stage2 of Job1
View the number of tasks in Stage3 of Job1
Note: if there is a shuffle process, the system will automatically cache it, and the UI interface displays the skipped part
2.6.6 Stage task division source code analysis
RDD persistence
2.7.1 RDD Cache
RDD caches the previous calculation results through Cache or Persist methods. By default, it caches the data in the heap memory of the JVM in the form of serialization. However, these two methods are not cached immediately when called, but when the subsequent action is triggered, the RDD will be cached in the memory of the computing node and reused later.
0) create package name: com atguigu. cache
1) Code implementation
object cache01 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create an RDD and read the specified location file: hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1. Business logic
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {
word => {
println("************")
(word, 1)
}
}
//3.5 cache operation will increase blood relationship without changing the original blood relationship
println(wordToOneRdd.toDebugString)
//3.4 data cache.
wordToOneRdd.cache()
//3.6 storage level can be changed
// wordToOneRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
//3.2 trigger execution logic
wordToOneRdd.collect()
println("-----------------")
println(wordToOneRdd.toDebugString)
//3.3 trigger execution logic again
wordToOneRdd.collect()
Thread.sleep(1000000)
//4. Close the connection
sc.stop()
}
}
2) Source code analysis
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
Note: the default storage level is to store only one copy in memory. Adding "_2" at the end of the storage level means that the persistent data is saved in two copies. SER: indicates serialization.
The cache may be lost, or the data stored in the memory may be deleted due to insufficient memory. The cache fault tolerance mechanism of RDD ensures the correct execution of the calculation even if the cache is lost. Through a series of transformations based on RDD, the lost data will be recalculated. Because each Partition of RDD is relatively independent, only the lost part needs to be calculated, and it is not necessary to recalculate all partitions.
3) Built in cache operator
Spark will automatically perform persistent operations on the intermediate data of some Shuffle operations (such as reduceByKey). The purpose of this operation is to avoid recalculating the entire input when a node Shuffle fails. However, in actual use, if you want to reuse data, it is still recommended to call persist or cache.
object cache02 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Create an RDD and read the specified location file: hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1. Business logic
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {
word => {
println("************")
(word, 1)
}
}
// reduceByKey with built-in cache
val wordByKeyRDD: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)
//3.5 cache operation will increase blood relationship without changing the original blood relationship
println(wordByKeyRDD.toDebugString)
//3.4 data cache.
//wordByKeyRDD.cache()
//3.2 trigger execution logic
wordByKeyRDD.collect()
println("-----------------")
println(wordByKeyRDD.toDebugString)
//3.3 trigger execution logic again
wordByKeyRDD.collect()
Thread.sleep(1000000)
//4. Close the connection
sc.stop()
}
}
visit http://localhost:4040/jobs/ Page to view the DAG diagram of the first and second jobs. Note: after adding the cache, the blood dependency still exists. However, the data obtained by the second job is obtained from the cache.
2.7.2 RDD CheckPoint
1) Checkpoint: by writing RDD intermediate results to disk.
2) Why checkpoint?
Because the blood dependency is too long, the cost of fault tolerance will be too high. Therefore, it is better to do checkpoint fault tolerance in the intermediate stage. If there is a node problem after the checkpoint, you can redo the blood from the checkpoint to reduce the overhead.
3) Checkpoint storage path: checkpoint data is usually stored in fault-tolerant and highly available file systems such as HDFS
4) The storage format of checkpoint data is binary file
5) Checkpoint cut blood relationship: in the process of checkpoint, all the information in the parent RDD that depends on the RDD will be removed.
6) Checkpoint trigger time: the checkpoint operation on RDD will not be executed immediately, and the Action operation must be executed to trigger. However, for data security, checkpoints will be executed from the beginning of blood relationship.
7) To set checkpoints
(1) Set checkpoint data storage path: sc.setCheckpointDir("./checkpoint1")
(2) Call checkpoint method: wordToOneRdd.checkpoint()
8) Code implementation
object checkpoint01 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
// The path needs to be set, otherwise an exception is thrown: Checkpoint directory has not been set in the SparkContext
sc.setCheckpointDir("./checkpoint1")
//3. Create an RDD and read the specified location file: hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1. Business logic
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
//3.5 increase the cache to avoid running another job as a checkpoint
// wordToOneRdd.cache()
//3.4 data checkpoint: perform checkpoint calculation for wordToOneRdd
wordToOneRdd.checkpoint()
//3.2 trigger execution logic
wordToOneRdd.collect().foreach(println)
// A new job will be started immediately to perform checkpoint operations
//3.3 trigger execution logic again
wordToOneRdd.collect().foreach(println)
wordToOneRdd.collect().foreach(println)
Thread.sleep(10000000)
//4. Close the connection
sc.stop()
}
}
9) Execution results
visit http://localhost:4040/jobs/ Page to view the DAG diagram of four jobs. The second figure is the DAG diagram of job running of checkpoint. Figures 3 and 4 show that checkpoints cut off blood dependence.
(1)Only increase checkpoint,No increase Cache Cache printing 1st job After execution, it is triggered checkpoint,2nd job function checkpoint,And store the data on the checkpoint. 3rd and 4th job,The data is read directly from the checkpoint.
(hadoop,1577960215526)
. . . . . .
(hello,1577960215526)
(hadoop,1577960215609)
. . . . . .
(hello,1577960215609)
(hadoop,1577960215609)
. . . . . .
(hello,1577960215609)
(2) Add checkpoint and Cache print
After the first job is executed, the data is saved in the Cache. The second job runs checkpoint to directly read the data in the Cache and store the data on the checkpoint. In the 3rd and 4th jobs, the data is directly read from the checkpoint.
(hadoop,1577960642223)
. . . . . .
(hello,1577960642225)
(hadoop,1577960642223)
. . . . . .
(hello,1577960642225)
(hadoop,1577960642223)
. . . . . .
(hello,1577960642225)
2.7. 3. Difference between cache and checkpoint
1) The Cache only saves the data without cutting off the blood dependency. Checkpoint checkpoint cuts off blood dependence.
2) Cache data is usually stored in disk, memory and other places, with low reliability. Checkpoint data is usually stored in fault-tolerant and highly available file systems such as HDFS, with high reliability.
3) It is recommended to use the Cache cache Cache for the RDD of checkpoint(), so that the job of checkpoint only needs to read data from the Cache cache, otherwise the RDD needs to be calculated from scratch.
4) If you are finished using the cache, you can release the cache through the persist () method
2.7. 4 checkpoint storage to HDFS cluster
If the checkpoint data is stored in the HDFS cluster, pay attention to configuring the user name to access the cluster. Otherwise, an access permission exception will be reported.
object checkpoint02 {
def main(args: Array[String]): Unit = {
// Set the user name to access the HDFS cluster
System.setProperty("HADOOP_USER_NAME","atguigu")
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
// The path needs to be set You need to create a / checkpoint path on the HDFS cluster in advance
sc.setCheckpointDir("hdfs://hadoop102:8020/checkpoint")
//3. Create an RDD and read the specified location file: hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1. Business logic
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
//3.4 increase the cache to avoid running another job as a checkpoint
wordToOneRdd.cache()
//3.3 data checkpoint: perform checkpoint calculation for wordToOneRdd
wordToOneRdd.checkpoint()
//3.2 trigger execution logic
wordToOneRdd.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2.8 key value pair RDD data partition
Spark currently supports Hash partition, Range partition and user-defined partition. The Hash partition is the current default partition. The partition directly determines the number of partitions in RDD, which partition each data in RDD enters after shuffling, and the number of Reduce.
1) Note:
(1) Only RDD of key value type has a partition. The value of RDD partition of non key value type is None
(2) The partition ID range of each RDD: 0~numPartitions-1, which determines which partition this value belongs to.
2) Get RDD partition
(1) Create package name: com.atguigu.partitioner
(2) Code implementation
object partitioner01_get {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3 Create RDD
val pairRDD: RDD[(Int, Int)] = sc.makeRDD(List((1,1),(2,2),(3,3)))
//3.1 print divider
println(pairRDD.partitioner)
//3.2 repartition of RDD using HashPartitioner
val partitionRDD: RDD[(Int, Int)] = pairRDD.partitionBy(new HashPartitioner(2))
//3.3 print divider
println(partitionRDD.partitioner)
//4. Close the connection
sc.stop()
}
}
2.8.1 Hash partition
2.8.2 Ranger partition
2.8. 3 custom partition
See 2.3.1 for details 3.2.
Data reading and saving
Spark Data reading and data saving can be distinguished from two dimensions: file format and file system.
File formats include: Text file, Json file, Csv file, Sequence file and Object file;
File system is divided into local file system, HDFS and database.
3.1 file data reading and saving
1) Create package name: com atguigu. readAndSave
3.1.1 Text file
1) Basic grammar
(1) Data reading: textFile(String)
(2) Data saving: saveAsTextFile(String)
2) Code implementation
object Operate_Text {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3.1 reading input files
val inputRDD: RDD[String] = sc.textFile("input/1.txt")
//3.2 saving data
inputRDD.saveAsTextFile("output")
//4. Close the connection
sc.stop()
}
}
4) Note: if it is a cluster path: hdfs://hadoop102:8020/input/1.txt
3.1.2 Sequence file
Sequencefile file is a flat file designed by Hadoop to store key value pairs in binary form. In the SparkContext, you can call sequencefile keyClass, valueClass.
1) Code implementation
object Operate_Sequence {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3.1 creating rdd
val dataRDD: RDD[(Int, Int)] = sc.makeRDD(Array((1,2),(3,4),(5,6)))
//3.2 save data as SequenceFile
dataRDD.saveAsSequenceFile("output")
//3.3 reading SequenceFile file
sc.sequenceFile[Int,Int]("output").collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
2) Note: the SequenceFile file is only for PairRDD
3.1.3 Object object file
Object file is a file saved after serializing objects, which adopts Java serialization mechanism. You can use objectFile k,v The function receives a path, reads the object file and returns the corresponding RDD. You can also call saveAsObjectFile() to output the object file. Because it is serialization, the type should be specified.
1) Code implementation
object Operate_Object {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3.1 create RDD
val dataRDD: RDD[Int] = sc.makeRDD(Array(1,2,3,4))
//3.2 saving data
dataRDD.saveAsObjectFile("output")
//3.3 reading data
sc.objectFile[(Int)]("output").collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
3.2 file system data reading and saving
The whole ecosystem of Spark is fully compatible with Hadoop, so Spark also supports the file types or database types supported by Hadoop. In addition, because Hadoop API has both old and new versions, Spark also provides two sets of creation operation interfaces in order to be compatible with all versions of Hadoop. For example, TextInputFormat, the old and new versions refer to org apache. hadoop. mapred. InputFormat,org.apache.hadoop.mapreduce.InputFormat(NewInputFormat)
accumulator
Accumulator: distributed shared write only variables. (data cannot be read between Executor and Executor)
The accumulator is used to aggregate the variable information on the Executor side to the Driver side. For the variables defined in the Driver program, each task on the Executor side will get a new copy of this variable. After each task updates the values of these copies, it will be returned to the Driver side for merge.
4.1 system accumulator
Accumulator usage
(1) Accumulator definition (SparkContext.accumulator(initialValue) method)
val sum: LongAccumulator = sc.longAccumulator("sum")
(2) Accumulator add data (accumulator. Add method)
sum.add(count)
(3) Accumulator get data (accumulator. value)
sum.value
code implementation
import org.apache.spark.{SparkConf, SparkContext}
object $01_Accumulator {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test"))
val rdd = sc.parallelize(List(10, 20, 30, 40))
var sum = 0
rdd.foreach(x => sum = sum + x)
println(sum)
//The built-in accumulator can only accumulate long type
val acc = sc.longAccumulator("acc")
rdd.foreach(x => acc.add(x))
println(acc.value)
//You can view the spark page and the accumulator information
Thread.sleep(100000)
}
}
Note: tasks on the Executor side cannot read the value of the accumulator (for example, sum.value is called on the Executor side, and the obtained value is not the final value of the accumulator). From the perspective of these tasks, the accumulator is a write only variable.
3) The accumulator is placed in the action operator
For accumulators to be used in action operations, Spark will only apply the changes to each accumulator for each task once. Therefore, if we want an accumulator that is absolutely reliable in both failure and repeated calculation, we must put it in an action operation such as foreach(). The accumulator may be updated more than once during the conversion operation.
4.2 user defined accumulator
The function of custom accumulator type is in 1 It has been provided in version x, but it is troublesome to use. After version 2.0, the ease of use of the accumulator has been greatly improved, and a new abstract class, accumulator V2, has been officially provided to provide a more friendly implementation of user-defined type accumulators.
1) To customize an accumulator
(1) Inherit accumulator V2 and set input and output generics
(2) Rewrite method
2) Code implementation
import org.apache.spark.{SparkConf, SparkContext}
/**
* Accumulator: spark provides a distributed Global accumulation variable. In the follow-up, each task will be accumulated first. After the task accumulation is completed, the data will be summarized to the Driver, and the Driver will perform global consolidation again
You can use an accumulator to reduce the number of shuffle s
*/
object $02_Accumulator {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test"))
//new an accumulator
val acc = new $13_WordCountAccumulator
//Register timer in sparkcontext
sc.register(acc)
val rdd = sc.textFile("datas/wc.txt")
val rdd2 = rdd.flatMap(x => x.split(" "))
val rdd3 = rdd2.map((_, 1))
rdd3.foreach(x => acc.add(x))
println(acc.value)
}
}
Custom accumulator
import org.apache.spark.util.AccumulatorV2
/**
* Custom accumulator
* 1,Define a class and inherit accumulator V2 [int, out]
* IN: Cumulative data type
* OUT: End result type of accumulator
* 2,override method
* 3,Register accumulator
* 4,Realize accumulation
* 5,Get final results
*/
class WordCountAccumulator extends AccumulatorV2[(String,Int),Map[String,Int]]{
//Container for word number
var result = Map[String,Int]()
/**
* Judge whether the current accumulator is empty
* @return
*/
override def isZero: Boolean = result.isEmpty
/**
* Copy an accumulator
* @return
*/
override def copy(): AccumulatorV2[(String, Int), Map[String, Int]] = {
new WordCountAccumulator
}
/**
* Reset accumulator
*/
override def reset(): Unit = {
result = Map[String,Int]()
}
/**
* Accumulate elements in task
* @param v
*/
override def add(v: (String, Int)): Unit = {
//Judge whether the current word exists in the container. If it exists, it will be accumulated at this time
if(result.contains(v._1)){
//Retrieve the number of times the current word already exists
val num = result.get(v._1).get
result = result.updated(v._1,num+v._2)
}else{
//If it does not exist, the current element is added directly to the container
result = result.updated(v._1,v._2)
}
}
/**
* Merge the results of the task in the Driver
* @param other
*/
override def merge(other: AccumulatorV2[(String, Int), Map[String, Int]]): Unit = {
//Get the result of task accumulator
val accResult = other.value
val taskReslt = result.toList ::: accResult.toList
val acc = taskReslt.groupBy(_._1)
.map(x=>{
(x._1,x._2.map(_._2).sum)
})
result = acc
//Map[
// Word - > list ((word, task1 times), (word, task2 times),..)
// ]
}
/**
* Get final results
* @return
*/
override def value: Map[String, Int] = result
}
Broadcast variable
Broadcast variable: distributed shared read-only variable.
Broadcast variables are used to efficiently distribute large objects. Sends a large read-only value to all work nodes for use by one or more Spark operations. For example, if your application needs to send a large read-only query table to all nodes, broadcast variables are easy to use. The same variable is used in multiple parallel operations, but Spark will send it separately for each task.
1) To use broadcast variables:
(1) Call SparkContext.broadcast (broadcast variable) to create a broadcast object. Any serializable type can be implemented in this way.
(2) Access the value of the object by broadcasting the variable. Value.
(3) The variable will only be sent to each node once and processed as a read-only value (modifying this value will not affect other nodes).
2) Principle description
3) Create package name: com atguigu. broadcast
4) Code implementation
object broadcast01 {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Implement the join of rdd1 and list in the way of collection
val rdd: RDD[String] = sc.makeRDD(List("WARN:Class Not Find", "INFO:Class Not Find", "DEBUG:Class Not Find"), 4)
val list: String = "WARN"
// Declare broadcast variables
val warn: Broadcast[String] = sc.broadcast(list)
val filter: RDD[String] = rdd.filter {
// log=>log.contains(list)
log => log.contains(warn.value)
}
filter.foreach(println)
//4. Close the connection
sc.stop()
}
}