Preface
After a noisy day, problems such as too many redirects to visit the Druid login interface and no login interface can be seen are finally solved.
Let's go through how to integrate Druid on native JDBC.
1, Create a new project integrating JDBC data sources
[1] Introduction of starter
[2] Configure application.yml (please refer to datasourceproperties. Class for data source configuration)
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://192.168.31.122:3306/jdbc
driver-class-name: com.mysql.jdbc.Driver
[3] Write a test class (check whether the native jdbc is connected)
package com.gs.springboot;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
@SpringBootTest
class Springboot06DataJabcApplicationTests {
@Autowired
DataSource dataSource;
@Test
void contextLoads() throws SQLException {
//com.zaxxer.hikari.HikariDataSource
System.out.println(dataSource.getClass());
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
}
}
Resolution: we can know that the default system is com.zaxxer.hikari.HikariDataSource as the data source
2, Integrate Druid on the original jdbc
[1] Introducing druid data source into pom.xml
<!--Introduce druid data source-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.8</version>
</dependency>
[2] Introducing druid configuration into application.yml
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://192.168.31.122:3306/jdbc
driver-class-name: com.mysql.jdbc.Driver
initialization-mode: always
# Using druid data sources
type: com.alibaba.druid.pool.DruidDataSource
# Data source other configuration
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# Configure the filters intercepted by monitoring statistics. After the filters are removed, the monitoring interface sql cannot be counted. The 'wall' is used for the firewall
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# Modify the access path of database file
# schema:
# - classpath:department.sql
If you just write the above configuration in the yml file, spring boot can't read druid's related configuration. Because it is not like our native jdbc, the system uses DataSourceProperties to bind its properties by default. So we should write a class to bind its properties
[3] Write the configuration class DruidConfig for druid integration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
}
When I finished writing the above class happily to test, I suddenly found that the console reported an error. It was found in the yml file after searching
filters: stat,wall,log4j
Because the log framework we used after spring boot 2.0 no longer uses log4j. The corresponding adapter should be introduced at this time. We can add it to pom.xml file
<!--Lead in adapter-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</dependency>
At this time, it's OK to carry out relevant tests. However, we just introduce relevant data sources, and we haven't configured Druid monitoring, so we can't access its corresponding login interface and monitoring management content. Continue to improve the DruidConfig class
package com.gs.springboot.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
//Configure Druid monitoring
//1. Configure a management background Servlet
@Bean
public ServletRegistrationBean statViewServlet(){
// Remember to add "/ druid / *", otherwise there are too many redirects on the login page to access (remember that this error will be reported in Google browser)
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(),"/druid/*");
Map<String,String> initParams = new HashMap<>();
initParams.put("loginUsername","admin");
initParams.put("loginPassword","123456");
//All access is allowed by default
//initParams.put("allow","");
// initParams.put("deny","192.168.31.30");
bean.setInitParameters(initParams);
return bean;
}
//2. Configure a filter for web Monitoring
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String,String> initParams = new HashMap<>();
//Configure requests to be excluded when intercepting
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
Error resolution: when we write the method of Servlet in the management background, we must add the corresponding address, otherwise the number of redirects will be reported when we visit the corresponding page
// Remember to add "/ druid / *", otherwise there are too many redirects on the login page to access (remember that this error will be reported in Google browser) ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(),"/druid/*");
[4] If you visit http://localhost:8080/druid in the above way, you will find that you can see the login page. Don't be too happy too early. You will find that you can't go to the main page no matter how you log in. Because it is intercepted by csrf, we have to write a security configuration class to filter the intercepted addresses
package com.gs.springboot.config;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
//Filter and intercept the / druid / * we visited
http.csrf().ignoringAntMatchers("/druid/*");
}
}
So it's finally sunny. When we visit http://localhost:8080/druid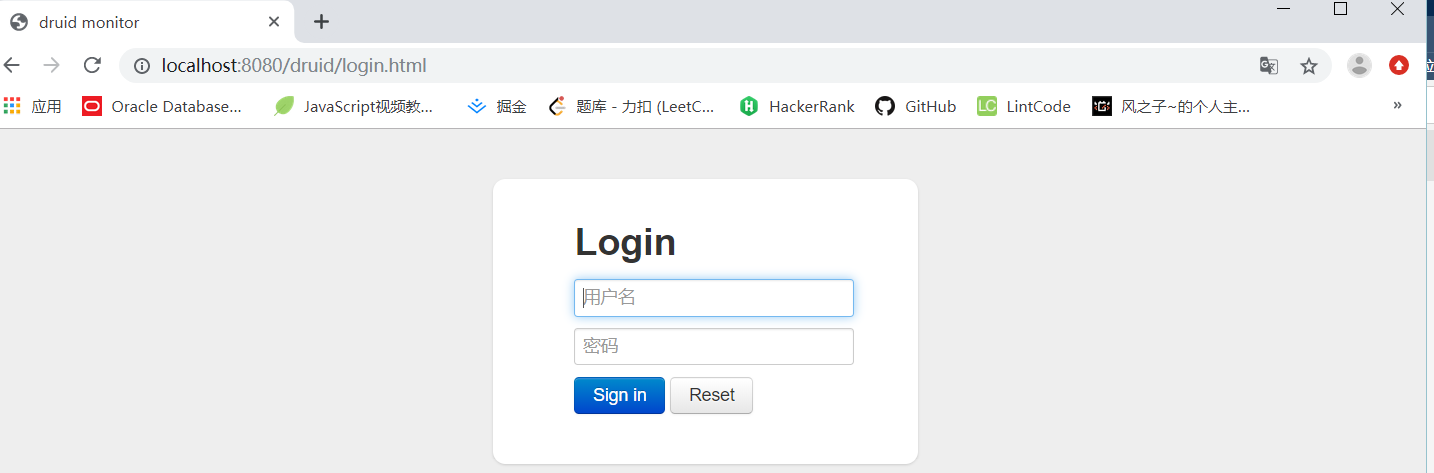
After login
How delightful two pages. Since then, spring boot 2.0 has integrated Druid. I'd like to make a summary of the pits I stepped on:
[1] If you can use Google for relevant tests, you must use Google. For example, I've been troubleshooting the redirection problem for a long time, and other browsers will only 404, and the rest will have nothing
[2] To integrate the logging framework, we need to see the version we are currently adapting. If it is out of date, we can introduce the corresponding adapter.
[3] Some pages can't log in all the time. Maybe some paths are blocked. We should go to find out what's blocked and what's the address.
OK, so much for today's sharing. I would be very honored if I could let you guys less step on the pit today. If it helps you, I can like it and pay attention. If you have any questions, we can discuss them in the message area.

