Integrated Druid
Introduction to Druid
A large part of Java programs need to operate the database. In order to improve the performance, they have to use the database connection pool when operating the database.
Druid is a database connection pool implementation on Alibaba's open source platform. It combines the advantages of C3P0, DBCP and other DB pools, and adds log monitoring.
Druid can well monitor the DB pool connection and SQL execution. It is naturally a DB connection pool for monitoring.
Druid has deployed more than 600 applications in Alibaba, which has been severely tested by large-scale deployment in the production environment for more than a year.
Hikari data source is used by default above Spring Boot 2.0. It can be said that Hikari and Driud are the best data sources on the current Java Web. Let's focus on how Spring Boot integrates Druid data source and how to realize database monitoring.
Github address: https://github.com/alibaba/druid/
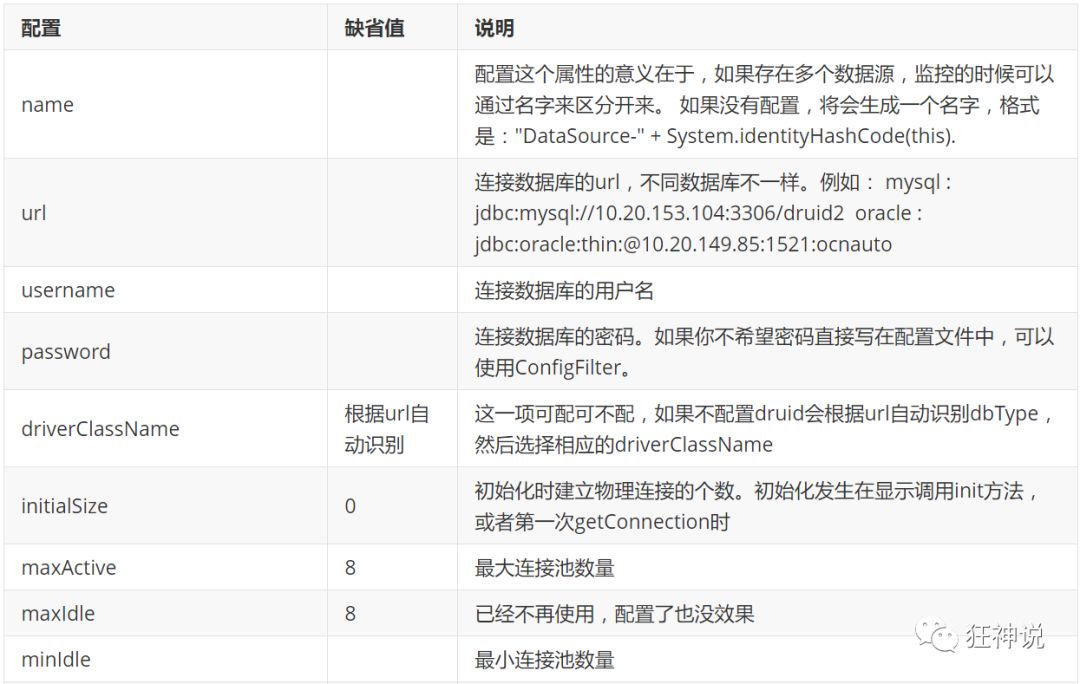
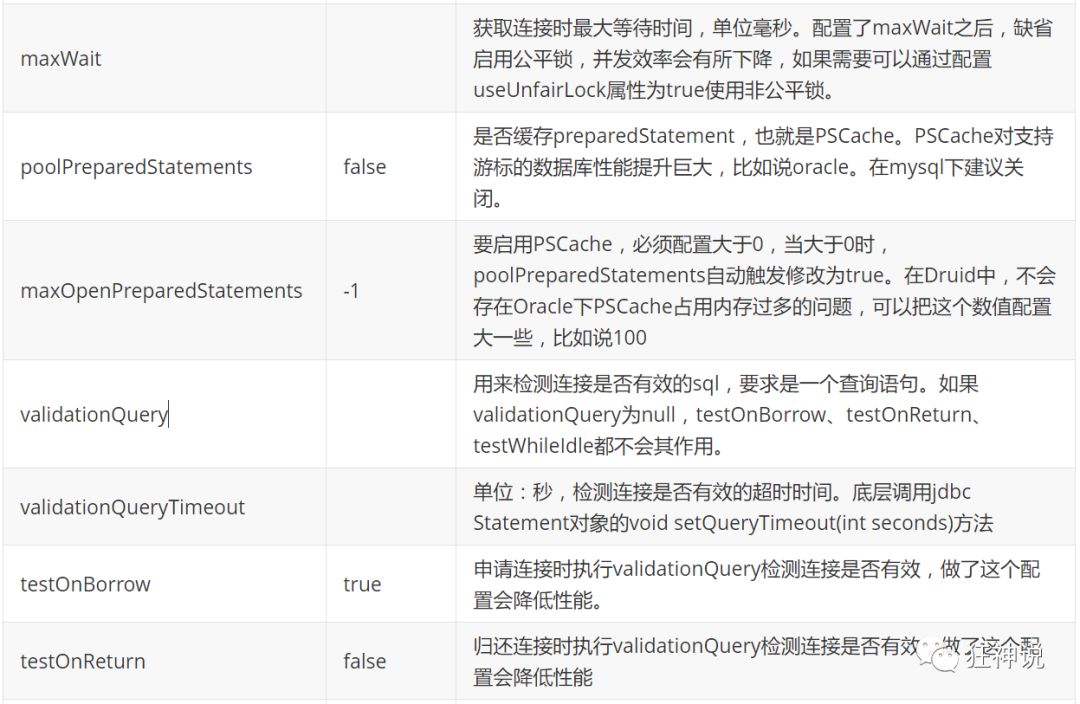
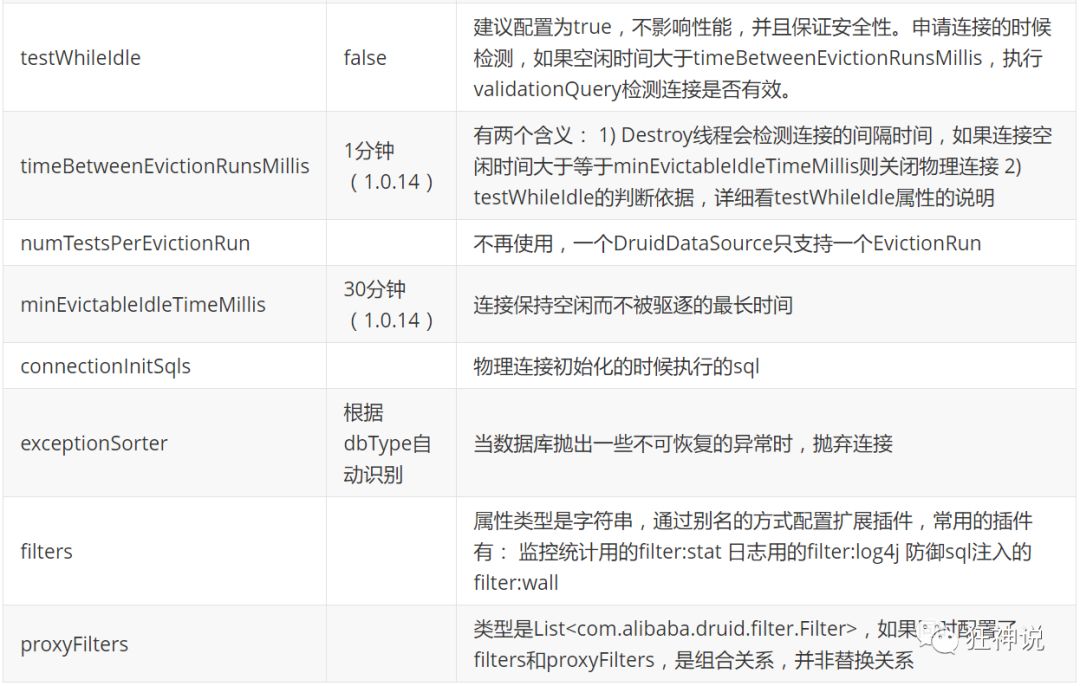
com. alibaba. druid. pool. The basic configuration parameters of druiddatasource are as follows:
Configure data source
1. Add Druid data source dependency on.
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.21</version></dependency>
2. Switching data sources; As mentioned before, com.com is used by default for Spring Boot 2.0 and above zaxxer. hikari. Hikaridatasource data source, but it can be accessed through spring datasource. Type specifies the data source.
spring: datasource: username: root password: 123456 url: jdbc:mysql://localhost:3306/springboot? serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8 driver-class-name: com. mysql. cj. jdbc. Driver type: com. alibaba. druid. pool. Druiddatasource # custom data source
3. After data source switching, inject DataSource into the test class, then obtain it, and output to see whether the switching is successful;

4. Switching succeeded! Now that the switch is successful, you can set the initialization size, maximum number of connections, waiting time, minimum number of connections and other settings of the data source connection; You can view the source code
spring: datasource: username: root password: 123456 #? Servertimezone = address the error URL of UTC time zone: JDBC: mysql://localhost:3306/springboot?serverTimezone=UTC&useUnicode=true&characterEncoding=utf -8 driver-class-name: com. mysql. cj. jdbc. Driver type: com. alibaba. druid. pool. DruidDataSource
#Spring Boot By default, these attribute values are not injected, and you need to bind them yourself #druid data source specific configuration initialsize: 5 miniidle: 5 maxactive: 20 maxwait: 60000 timebetweenevictionrunsmillis: 60000 minevictableidletimmllis: 300000 validationquery: select 1 from dual testwhiteidle: true testonmirror: false testonreturn: false poolpreparedstatements: true
#Configure the of monitoring statistics interception filters,stat:Monitoring statistics log4j: Logging wall: defense sql injection #Report errors if allowed java.lang.ClassNotFoundException: org.apache.log4j.Priority #Then import log4j dependency. Maven address: https://mvnrepository.com/artifact/log4j/log4j filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid. stat.mergeSql=true; druid. stat.slowSqlMillis=500
5. Dependency of import Log4j
<!-- https://mvnrepository.com/artifact/log4j/log4j --><dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version></dependency>
6. Now programmers need to bind the parameters in the global configuration file for DruidDataSource and add them to the container instead of using the automatic generation of Spring Boot; We need to add the DruidDataSource component to the container and bind the attribute;
package com.kuang.config;
import com.alibaba.druid.pool.DruidDataSource;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configurationpublic class DruidConfig {
/* Add the customized Druid data source to the container, and no longer let Spring Boot automatically create and bind the Druid data source attribute in the global configuration file to com alibaba. druid. pool. Druiddatasource to make them effective @ ConfigurationProperties(prefix = "spring.datasource"): the function is to prefix the global configuration file with spring Inject the attribute value of datasource into com alibaba. druid. pool. Druiddatasource is in a parameter with the same name */ @ConfigurationProperties(prefix = "spring.datasource") @Bean public DataSource druidDataSource() { return new DruidDataSource(); }
}
7. Test in the test class; See if it succeeds!
@SpringBootTestclass SpringbootDataJdbcApplicationTests {
//DI injection data source @ Autowired datasource;
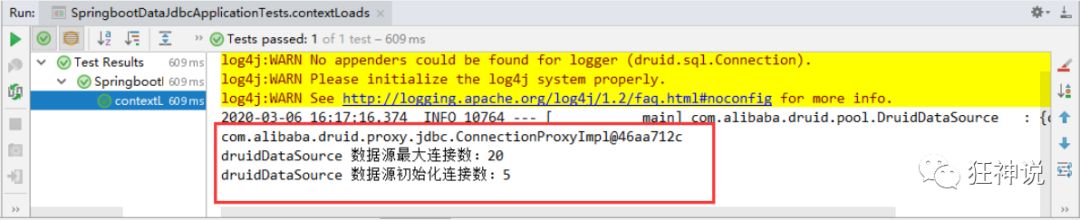
@Test public void contextLoads() throws SQLException { //Take a look at the default data source system out. println(dataSource.getClass()); // Get connection connection = datasource getConnection(); System. out. println(connection);
DruidDataSource druidDataSource = (DruidDataSource) dataSource; System.out.println("druidDataSource Maximum connections to data source:" + druidDataSource.getMaxActive()); System.out.println("druidDataSource Number of data source initialization connections:" + druidDataSource.getInitialSize());
//Close the connection close(); }}
Output result: it can be seen that the configuration parameters have taken effect!
Configure Druid data source monitoring
Druid data source has the function of monitoring and provides a web interface for users to view. Similarly, when installing a router, people also provide a default web page.
Therefore, the first step is to set Druid's background management page, such as login account, password, etc; Configure background management
//Configure the Servlet of Druid monitoring and management background// There is no web when the Servlet container is built in XML file, so use the Servlet registration method of Spring Boot @ beanpublic servletregistrationbean statviewservlet() {servletregistrationbean bean = new servletregistrationbean (New statviewservlet(), "/ Druid / *");
// These parameters can be found on COM alibaba. druid. support. http. The parent class of statviewservlet / / com alibaba. druid. support. http. Find map < string, string > initparams = new HashMap < > () in resourceservlet; initParams. put("loginUsername", "admin"); // Login account initparams in the background management interface put("loginPassword", "123456"); // Login password of background management interface
//Who is allowed to access / / initparams. In the background Put ("allow", "localhost"): indicates that only the local machine can access / / initparams When "allow". Params "is null, all access is allowed put("allow", ""); // Deny: Druid who is denied access in the background / / initparams put("kuangshen", "192.168.1.20"); Indicates that this ip access is prohibited
//Set initialization parameter bean setInitParameters(initParams); return bean;}
After configuration, we can choose to access: http://localhost:8080/druid/login.html
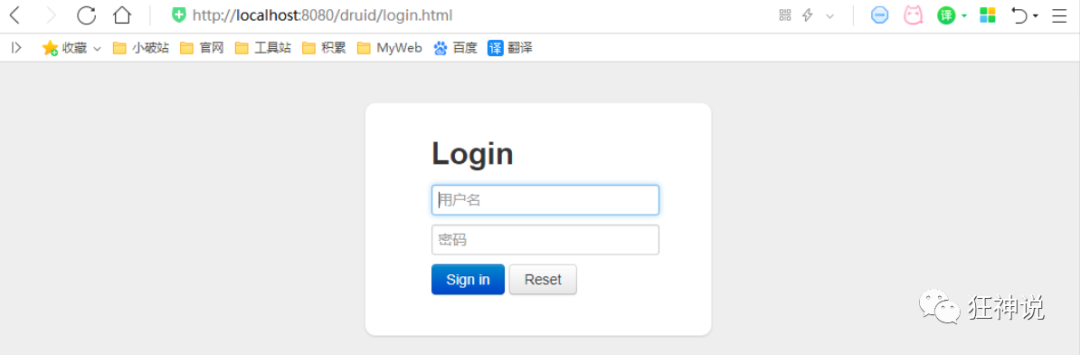
After entering
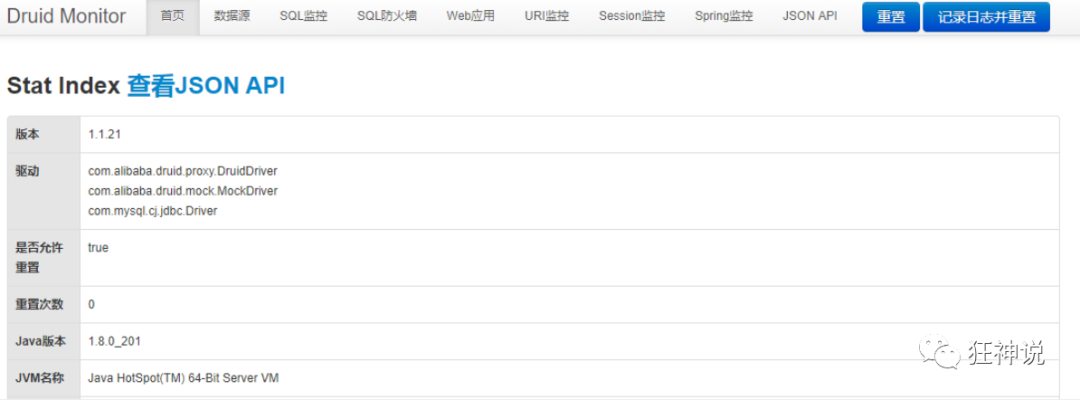
Configure Druid web monitoring filter
//filter//WebStatFilter for configuring Web monitoring of Druid monitoring: used to configure management association between Web and Druid data sources. Monitoring statistics @ beanpublic filterregistrationbean webstatfilter() {filterregistrationbean bean = new filterregistrationbean(); bean. Setfilter (New webstatfilter());
//Exclusions: set which requests are filtered and excluded so that statistics are not performed. Map < string, string > initparams = new HashMap < > (); initParams. put("exclusions", "*.js,*.css,/druid/*,/jdbc/*"); bean. setInitParameters(initParams);
//"/ *" means to filter all request beans setUrlPatterns(Arrays.asList("/*")); return bean;}
At ordinary times, it can be configured according to the needs during work, which is mainly used for monitoring!