Java client access Kafka
- Introducing maven dependency
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.1.41</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>1.1.3</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.1.1</version> </dependency>
- Message sender code
package com.tuling.kafka.kafkaDemo;
import com.alibaba.fastjson.JSON;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
public class MsgProducer {
private final static String TOPIC_NAME = "my-replicated-topic";
public static void main(String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.104:9092,192.168.1.104:9093,192.168.1.104:9094");
/*
Issue message persistence mechanism parameters
(1)acks=0: It means that the producer can continue to send the next message without waiting for any broker to confirm the reply of the message. Highest performance, but most likely to lose messages.
(2)acks=1: At least wait until the leader has successfully written data to the local log, but do not wait for all follower s to write successfully. You can continue to send the next message
Message. In this case, if the follower fails to successfully back up the data and the leader hangs up, the message will be lost.
(3)acks=-1 Or all: you need to wait for min.insync.replicas (the default is 1, and the recommended configuration is greater than or equal to 2). The number of replicas configured by this parameter is successfully written to the log
It will ensure that as long as one backup survives, there will be no data loss. This is the strongest data guarantee. Generally, this configuration is only used in financial level or scenarios dealing with money.
*/
props.put(ProducerConfig.ACKS_CONFIG, "1");
/*
Retrying occurs when sending fails. The default retry interval is 100ms. Retrying can ensure the reliability of message sending, but it may also cause repeated message sending, such as network jitter, so it is necessary to
The receiver handles the idempotency of message reception
*/
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//Retry interval setting
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
//Set the local buffer for sending messages. If this buffer is set, messages will be sent to the local buffer first, which can improve message sending performance. The default value is 33554432, or 32MB
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
/*
kafka The local thread will fetch data from the buffer and send it to the broker in batches,
Set the size of batch messages. The default value is 16384, or 16kb, which means that a batch is sent when it is full of 16kb
*/
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
/*
The default value is 0, which means that the message must be sent immediately, but this will affect performance
Generally, it is set to about 10ms, which means that after the message is sent, it will enter a local batch. If the batch is full of 16kb within 10ms, it will be sent together with the batch
If the batch is not full within 10 milliseconds, the message must also be sent. The message sending delay cannot be too long
*/
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
//Serialize the sent key from the string into a byte array
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//Serialize the sent message value from a string into a byte array
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int msgNum = 5;
final CountDownLatch countDownLatch = new CountDownLatch(msgNum);
for (int i = 1; i <= msgNum; i++) {
Order order = new Order(i, 100 + i, 1, 1000.00);
//Specify send partition
/*ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, 0, order.getOrderId().toString(), JSON.toJSONString(order));*/
//No sending partition is specified. The specific sending partition calculation formula is: hash(key)%partitionNum
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, order.getOrderId().toString(), JSON.toJSONString(order));
//Synchronization blocking method waiting for successful message sending
RecordMetadata metadata = producer.send(producerRecord).get();
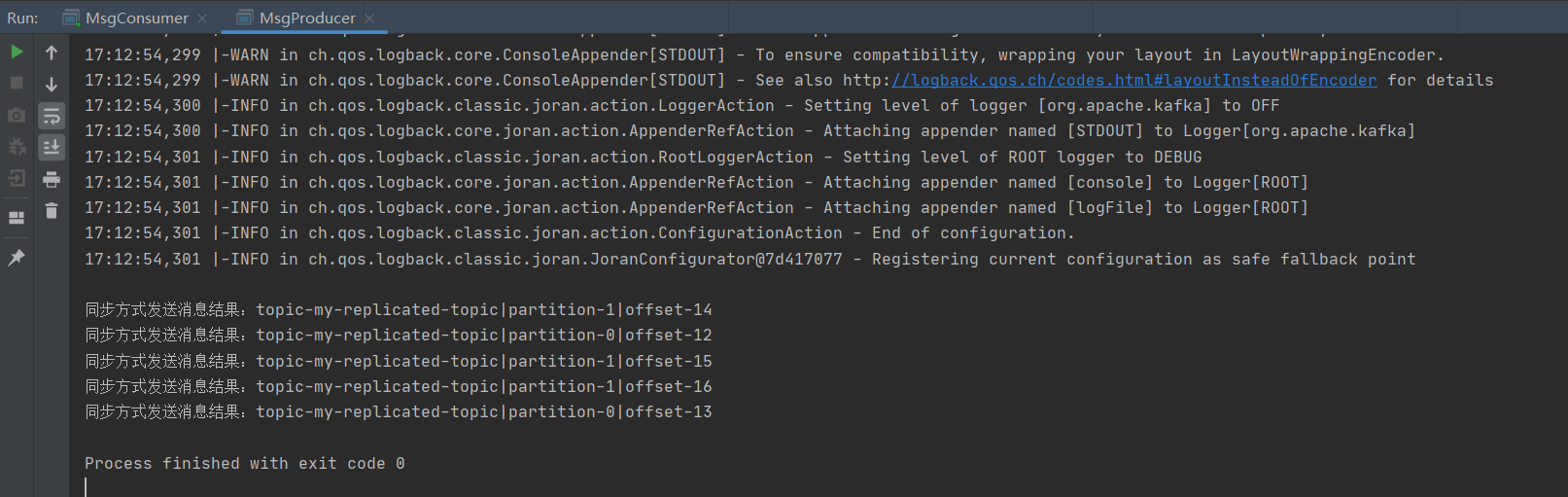
System.out.println("Send message result in synchronization mode:" + "topic-" + metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" + metadata.offset());
//Send message in asynchronous callback mode
/*producer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Failed to send message: "+ exception.getStackTrace());
}
if (metadata != null) {
System.out.println("Sending message results asynchronously: "+" topic - + metadata. Topic() + "|partition-“
+ metadata.partition() + "|offset-" + metadata.offset());
}
countDownLatch.countDown();
}
});*/
//Send points TODO
}
countDownLatch.await(5, TimeUnit.SECONDS);
producer.close();
}
}
- Message receiver code
package com.tuling.kafka.kafkaDemo;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class MsgConsumer {
private final static String TOPIC_NAME = "my-replicated-topic";
private final static String CONSUMER_GROUP_NAME = "testGroup";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.104:9092,192.168.1.104:9093,192.168.1.104:9094");
// Consumer group name
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
// Whether to automatically submit offset. The default is true
/*props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// Interval between auto commit offset s
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");*/
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
/*
When the consumption theme is a new consumption group, or the consumption method of offset is specified, and the offset does not exist, how should it be consumed
latest(Default): only consume the messages sent to the topic after you start
earliest: It is necessary to start consumption from scratch for the first time and continue consumption according to the consumption offset record later. This need is different from consumer.seektobegining (start consumption from scratch every time)
*/
//props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
/*
consumer The interval between sending a heartbeat to the broker. If the broker receives a heartbeat, it will respond through the heartbeat
rebalance The scheme is distributed to the consumer. This time can be a little shorter
*/
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
/*
How often does the service broker think that a consumer fails when it doesn't feel the heartbeat, and it will kick it out of the consumer group,
The corresponding Partition will also be reassigned to other consumer s. The default is 10 seconds
*/
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
//The maximum number of messages pulled by a poll. If the consumer processes quickly, it can be set to be larger. If the processing speed is average, it can be set to be smaller
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50);
/*
If the interval between two poll operations exceeds this time, the broker will think that the processing capacity of the consumer is too weak,
It will be kicked out of the consumption group and the partition will be allocated to other consumer s
*/
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// Consumption specified partition
//consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//Message backtracking consumption
/*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));*/
//Specify offset consumption
/*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);*/
//Start consumption from a specified point in time
/*List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME);
//Consumption started 1 hour ago
long fetchDataTime = new Date().getTime() - 1000 * 60 * 60;
Map<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo par : topicPartitions) {
map.put(new TopicPartition(TOPIC_NAME, par.partition()), fetchDataTime);
}
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) continue;
Long offset = value.offset();
System.out.println("partition-" + key.partition() + "|offset-" + offset);
System.out.println();
//Determine the offset according to the timestamp in the consumption
if (value != null) {
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
}*/
while (true) {
/*
* poll() API Is a long poll to pull messages
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
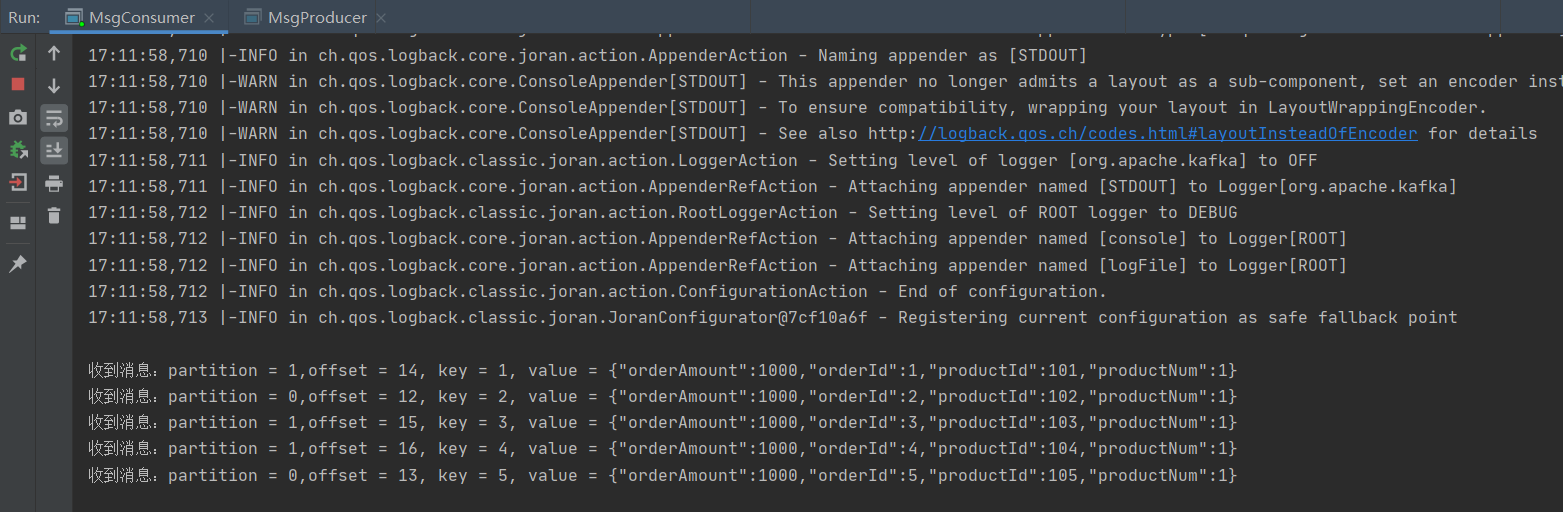
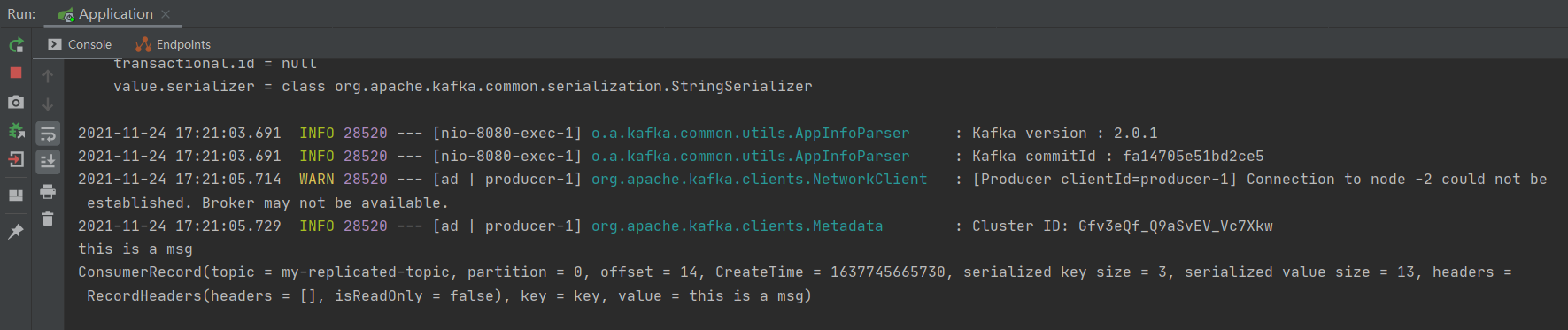
System.out.printf("Message received: partition = %d,offset = %d, key = %s, value = %s%n", record.partition(),
record.offset(), record.key(), record.value());
}
if (records.count() > 0) {
// If the offset is submitted manually, the current thread will block until the offset is submitted successfully
// Synchronous submission is generally used because there is generally no logic code after submission
//consumer.commitSync();
// Manually and asynchronously submit offset. The offset submitted by the current thread will not be blocked. You can continue to process the following program logic
/*consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for " + offsets);
System.err.println("Commit failed exception: " + exception.getStackTrace());
}
}
});*/
}
}
}
}
Spring Boot integration Kafka
- Introducing spring boot kafka dependency
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>
- application.yml is configured as follows:
server:
port: 8080
spring:
kafka:
bootstrap-servers: 192.168.1.104:9092,192.168.1.104:9093,192.168.1.104:9094
producer: # producer
retries: 3 # If a value greater than 0 is set, the client will resend the failed records
batch-size: 16384
buffer-memory: 33554432
acks: 1
# Specifies the encoding and decoding method of the message key and message body
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# When each record is processed by the consumer listener, it is submitted
# RECORD
# Submit after each batch of poll() data is processed by the listener consumer
# BATCH
# After each batch of poll() data is processed by the listener consumer, it is submitted when the last submission TIME is greater than TIME
# TIME
# After each batch of poll() data is processed by the listener consumer, it is submitted when the number of processed record s is greater than or equal to COUNT
# COUNT
# TIME | COUNT is submitted when one condition is met
# COUNT_TIME
# After each batch of poll() data is processed by the consumer listener, manually call acknowledge. Acknowledge () and submit it
# MANUAL
# Commit immediately after manually calling acknowledge. Acknowledge()
# MANUAL_IMMEDIATE
ack-mode: MANUAL_IMMEDIATE
- Sender Code:
package com.kafka;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class KafkaController {
private final static String TOPIC_NAME = "my-replicated-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public void send() {
kafkaTemplate.send(TOPIC_NAME, 0, "key", "this is a msg");
}
}
- Consumer code:
package com.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
@Component
public class MyConsumer {
/**
* @KafkaListener(groupId = "testGroup", topicPartitions = {
* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),
* @TopicPartition(topic = "topic2", partitions = "0",
* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
* },concurrency = "6")
* //concurrency It is the number of consumers in the same group, that is, the number of concurrent consumption. It must be less than or equal to the total number of partitions
* @param record
*/
@KafkaListener(topics = "my-replicated-topic",groupId = "zhugeGroup")
public void listenZhugeGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//Manually submit offset
//ack.acknowledge();
}
//Configure multiple consumption groups
/*@KafkaListener(topics = "my-replicated-topic",groupId = "tulingGroup")
public void listenTulingGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
ack.acknowledge();
}*/
}
Detailed explanation of Kafka design principle
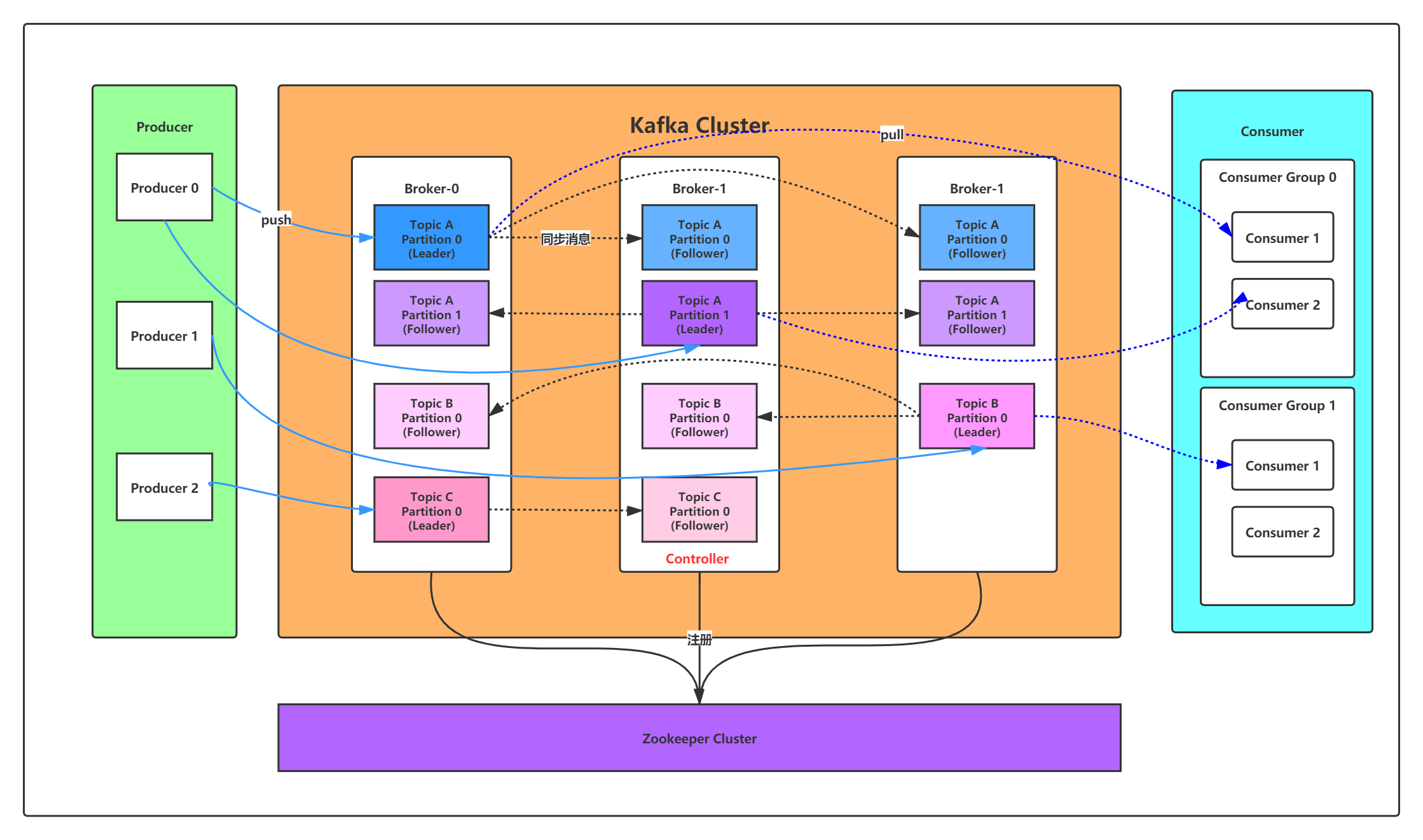
Kafka core general Controller
In the Kafka cluster, there will be one or more broker s, one of which will be elected as the controller (Kafka Controller), which is responsible for managing the status of all partitions and replicas in the whole cluster.
- When the leader copy of a partition fails, the controller is responsible for electing a new leader copy for the partition.
- When the ISR set of a partition is detected to change, the controller is responsible for notifying all broker s to update their metadata information.
- When the kafka-topics.sh script is used to increase the number of partitions for a topic, the controller is also responsible for making the new partition perceived by other nodes.
Independent election mechanism
When the kafka cluster is started, a broker will be automatically selected as the controller to manage the whole cluster. The election process is that each broker in the cluster will try to create a / controller temporary node on zookeeper. Zookeeper will ensure that there is and only one broker can be created successfully, and this broker will become the general controller of the cluster.
When the broker of the controller role goes down, the zookeeper temporary node will disappear. Other brokers in the cluster will always listen to the temporary node. If they find that the temporary node has disappeared, they will compete to create the temporary node again, which is the above-mentioned election mechanism. Zookeeper will ensure that a broker will become a new controller.
A broker with controller identity needs more responsibilities than other ordinary brokers. The details are as follows:
- Monitor broker related changes. Add a BrokerChangeListener to the / brokers/ids / node in Zookeeper to handle changes in brokers.
- Listen for changes related to topic. Add TopicChangeListener to the / brokers/topics node in Zookeeper to handle the change of topic increase or decrease; For / admin / delete in Zookeeper_ The topics node adds a TopicDeletionListener to handle the action of deleting topics.
- Read and obtain all current information related to topic, partition and broker from Zookeeper and manage them accordingly. For the / brokers/topics/[topic] node in Zookeeper corresponding to all topics, add PartitionModificationsListener to listen for partition allocation changes in topics.
- Update the metadata information of the cluster and synchronize it to other common broker nodes.
Partition replica election Leader mechanism
The controller senses that the broker where the partition leader is located is hung (the controller listens to many zk nodes and can perceive that the broker is alive). The controller will select the first broker from the ISR list (on the premise that the parameter unclean. Leader. Selection. Enable = false) as the leader (the first broker is first placed in the ISR list, which may be the replica with the most synchronized data), If the parameter unclean.leader.selection.enable is true, it means that when all replicas in the ISR list are hung, leaders can be selected from replicas outside the ISR list. This setting can improve availability, but the selected new leaders may have much less data.
There are two conditions for a replica to enter the ISR list:
- The replica node cannot generate partitions. It must be able to maintain a session with zookeeper and connect to the leader replica network
- The replica can replicate all writes on the leader, and can't lag too much. (the replica that lags behind the leader replica is determined by the replica.lag.time.max.ms configuration. The replica that has not been synchronized with the leader for more than this time will be removed from the ISR list.)
offset recording mechanism of consumer consumption message
Each consumer will regularly submit the offset of its own consumption partition to kafka's internal topic:__ consumer_offsets: when submitting the past, the key is the consumerGroupId+topic + partition number, and the value is the current offset value. kafka will regularly clean up the messages in the topic, and finally retain the latest data
Because__ consumer_offsets may receive highly concurrent requests. kafka allocates 50 partitions by default (which can be set through offsets.topic.num.partitions), so that it can resist concurrency by adding machines.
The offset consumed by the consumer can be selected through the following formula to be submitted to__ consumer_ Which partition of offsets
Formula: hash (consumergroupid)%__ consumer_ Offsets the number of partitions for the topic
Consumer Rebalance mechanism
rebalance means that if the number of consumers in the consumption group changes or the number of consumption zones changes, kafka will redistribute the relationship between consumers and consumption zones. For example, if a consumer in the consumer group hangs up, the partition assigned to him will be automatically handed over to other consumers. If he restarts again, some partitions will be handed back to him.
Note: rebalance is only used for subscribing without specifying partitions. If partitions are specified through assign, kafka will not rebalance.
The following situations may trigger consumer rebalance
- Consumers in the consumer group increased or decreased
- Dynamically add partitions to topic
- The consumer group subscribed to more topic s
During the rebalancing process, consumers cannot consume messages from kafka, which will have an impact on kafka TPS. If there are many nodes in kafka cluster, such as hundreds of nodes, rebalancing may take a lot of time, so rebalancing in the peak period of the system should be avoided as far as possible.
Consumer Rebalance partition allocation policy:
There are three rebalance strategies: range, round robin and sticky.
Kafka provides the consumer client parameter partition.assignment.strategy to set the partition allocation policy between consumers and subscription topics. The default is range allocation policy.
Suppose a topic has 10 partitions (0-9), and now there are three consumer s:
-
The range strategy is sorted according to the partition number. Assuming n = number of partitions / number of consumers = 3, M = number of partitions% number of consumers = 1, the first m consumers are allocated n+1 partitions, and the following (number of consumers - M) consumers are allocated n partitions.
For example, partitions 0 ~ 3 give a consumer, partitions 4 ~ 6 give a consumer, and partitions 7 ~ 9 give a consumer. -
The round robin strategy is polling allocation. For example, partitions 0, 3, 6 and 9 are given to a consumer, partitions 1, 4 and 7 are given to a consumer, and partitions 2, 5 and 8 are given to a consumer
-
The sticky strategy is similar to the round robin strategy at the beginning, but the following two principles need to be guaranteed during rebalancing.
- 1) The distribution of partitions should be as uniform as possible.
- 2) As far as possible, the allocation of partitions shall remain the same as that of the last allocation.
When the two conflict, the first goal takes precedence over the second goal. In this way, the original partition allocation policy can be maintained to the greatest extent.
For example, for the allocation of the first range, if the third consumer hangs, the results of re allocation with the sticky policy are as follows:
consumer1 will allocate another 7 in addition to the original 0 ~ 3
Consumer 2 will redistribute 8 and 9 in addition to the original 4 ~ 6
The Rebalance process is as follows
When a consumer joins a consumer group, the consumer, consumer group and group Coordinator will go through the following stages.
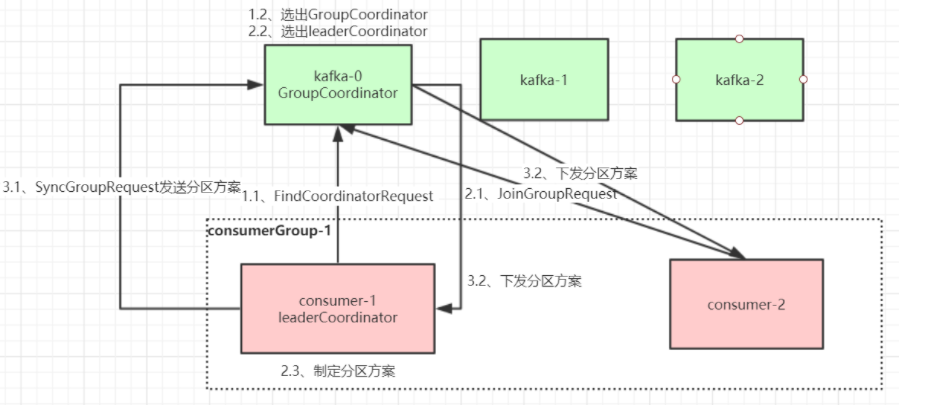
Stage 1: select group Coordinator
Group coordinator: each consumer group selects a broker as its own group coordinator, which is responsible for monitoring the heartbeat of all consumers in the consumer group, judging whether it is down, and then starting consumer rebalance.
When each consumer in the consumer group starts, it will send a findcoordinator request to a node in the kafka cluster to find the corresponding group coordinator GroupCoordinator and establish a network connection with it.
Group coordinator selection method:
The offset consumed by the consumer should be submitted to__ consumer_ Which partition of offsets? The broker corresponding to the partition leader is the coordinator of the consumer group
Stage 2: join the consumption group
After successfully finding the GroupCoordinator corresponding to the consumption group, enter the stage of joining the consumption group. Consumers in this stage will send a JoinGroupRequest request to the GroupCoordinator and process the response. Then, the GroupCoordinator selects the first consumer to join the group from a consumer group as the leader (consumer group Coordinator), sends the consumer group information to the leader, and then the leader will be responsible for formulating the partition scheme.
Phase III (SYNC GROUP)
The consumer leader sends a SyncGroupRequest to the GroupCoordinator, and then the GroupCoordinator sends the partition scheme to each consumer. They will make network connection and message consumption according to the leader broker of the specified partition.
Analysis of producer's message publishing mechanism
1. Write mode
producer uses the push mode to publish messages to the broker, and each message is append ed to the partition, which belongs to sequential write disk (the efficiency of sequential write disk is higher than random write memory, ensuring kafka throughput).
2. Message routing
When the producer sends a message to the broker, it will select which partition to store it according to the partition algorithm. Its routing mechanism is:
- If the partition is specified, it is used directly;
- If you do not specify a partition but specify a key, select a partition by hash ing the value of the key
- Neither the partition nor the key is specified. Use polling to select a partition.
3. Write process
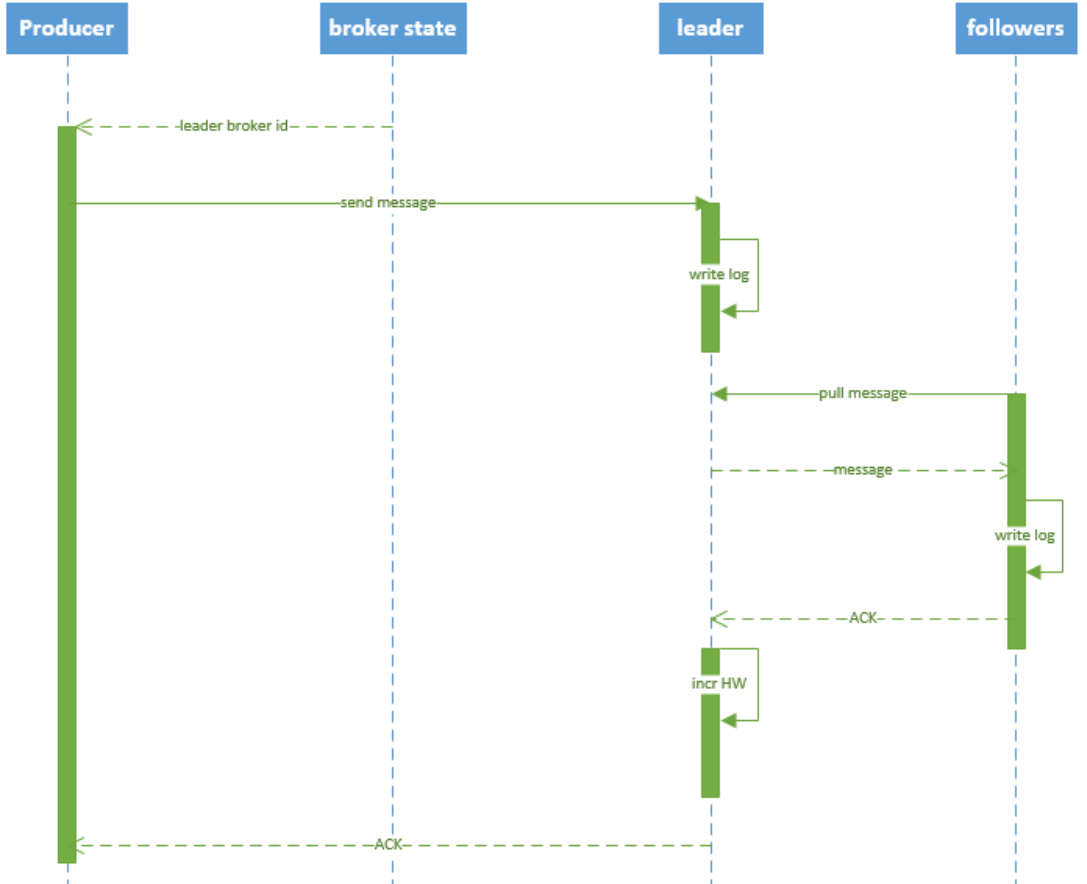
- producer first finds the leader of the partition from the "/ brokers /... / state" node of zookeeper
- The producer sends a message to the leader
- The leader writes the message to the local log
- followers pull the message from the leader, write it to the local log, and then send an ACK to the leader
- After receiving acks from replica s in all ISR s, the leader adds HW (high watermark, the offset of the last commit) and sends an ACK to the producer
HW and LEO details
HW, commonly known as high water level, is the abbreviation of high watermark. Take the smallest Leo (log end offset) in ISR corresponding to a partition As HW, the consumer can only consume the HW at most. In addition, each replica has HW, and the leader and follower are respectively responsible for updating their own HW status. For a message newly written by the leader, the consumer cannot consume it immediately, and the leader will wait for the message to be synchronized by replicas in all ISRs before updating the HW. At this time, the message can be consumed by the consumer. This ensures that if the leader When the broker fails, the message can still be obtained from the newly elected leader. There is no HW restriction on the read request from the internal broker.
The following figure illustrates in detail the flow process of ISR, HW and LEO after the producer sends the production message to the broker:
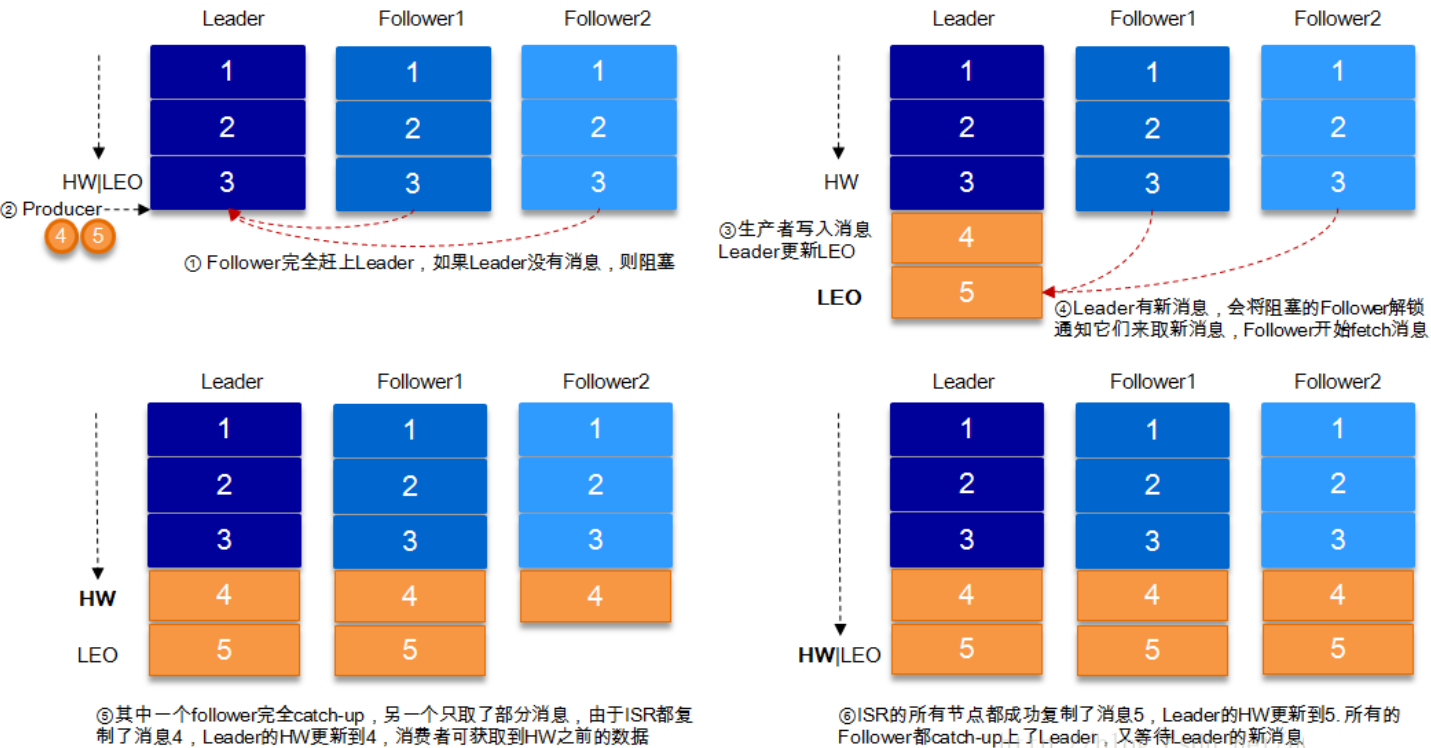
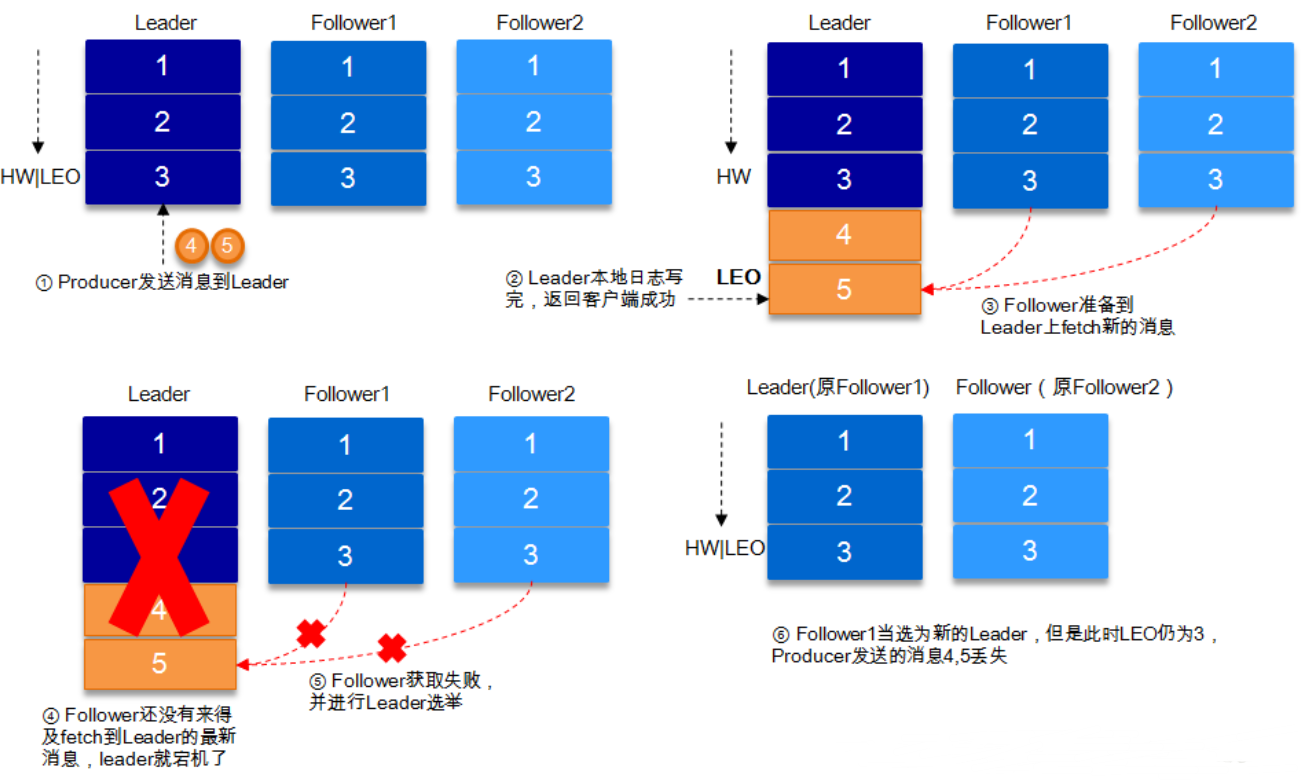
It can be seen that Kafka's replication mechanism is neither complete synchronous replication nor simple asynchronous replication. In fact, synchronous replication requires all working followers to copy before this message is committed. This replication method greatly affects the throughput. In the asynchronous replication mode, the follower asynchronously copies data from the leader, and as long as the data is written to the log by the leader It is considered to have committed. In this case, if the follower has not finished copying and the leader suddenly goes down when it lags behind the leader, the data will be lost. Kafka's method of using ISR can well balance the data loss and throughput. Then review the settings of the message persistence mechanism parameter acks at the message sender. Let's look at the ACK in combination with HW and LEO S = 1
Consider acks=1 in combination with HW and LEO
Log segmented storage
The message data of a partition in kafka is correspondingly stored in a folder, named after topic name + partition number. The message in the partition is segment Storage. The messages of each segment are stored in different log files. This feature facilitates the rapid deletion of old segment file s. kafka specifies that the maximum log file of a segment is 1G. The purpose of this limit is to facilitate the loading of log files into memory:
# Offset index file of some messages. Each time kafka sends 4K (configurable) messages to the partition, it will record the offset of the current message to the index file, # If you want to locate the offset of the message, you will quickly locate it in this file, and then find the specific message in the log file 00000000000000000000.index # The message storage file mainly stores offset and message body 00000000000000000000.log # The sending time index file of the message. Each time kafka sends 4K (configurable) messages to the partition, it will record the sending time stamp of the current message and the corresponding offset to the timeindex file, # If you need to locate the offset of the message according to time, you will find it in this file first 00000000000000000000.timeindex 00000000000005367851.index 00000000000005367851.log 00000000000005367851.timeindex 00000000000009936472.index 00000000000009936472.log 00000000000009936472.timeindex
This number like 9936472 represents the starting Offset contained in the log segment file, which means that at least nearly 10 million pieces of data have been written in this partition.
Kafka Broker has a parameter, log.segment.bytes, which limits the size of each log segment file. The maximum is 1GB.
When a log segment file is full, it will automatically open a new log segment file to write, so as to avoid that a single file is too large and affects the file reading and writing performance. This process is called log rolling. The log segment file being written is called active log segment.
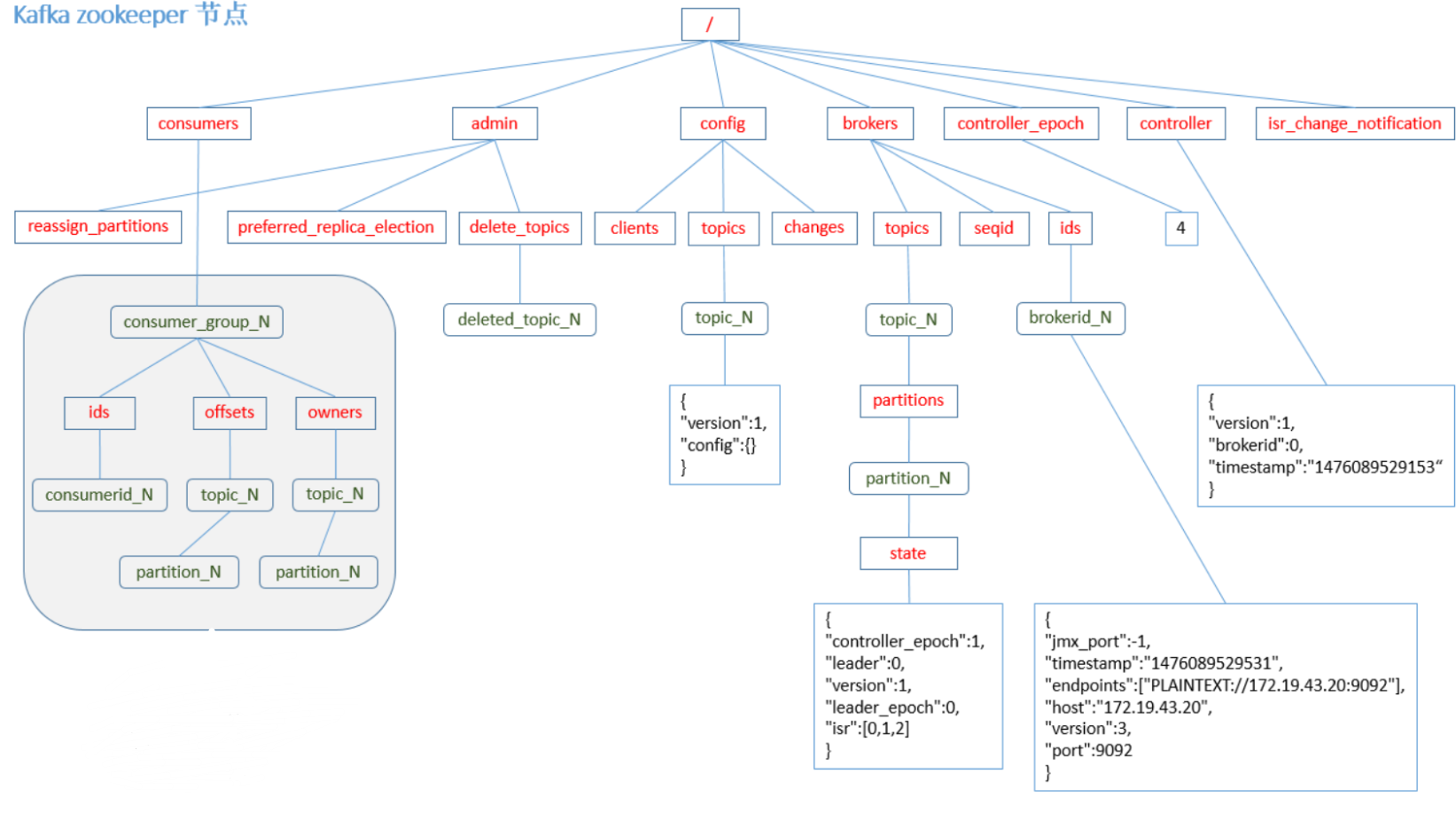
Zoomeeper node data graph: