Introduction
Spring Batch is a framework for handling large amounts of data operations. It is mainly used to read large amounts of data and then output the specified form after certain processing. For example, we can insert batch processing of data in csv files (millions or even tens of millions of data are not a problem) into the database and use the framework, but whether it is data or online data, I see very few such detailed explanations. So the main purpose of this blog is to explain the actual combat at the same time (the codes are all practiced). Similarly, start with Spring Boot's support for the Batch framework, and then proceed to code practice step by step.
1. Spring Boot Support for Batch Framework
1. Components of Spring Batch Framework
1) JobRepository: Used to register Job containers and set database-related properties.
2) Job Launcher: The interface used to start Job
3) Job: The task we are going to actually perform consists of one or more tasks
4) Step: That is, steps, including: ItemReader - > ItemProcessor - > ItemWriter
5) ItemReader: Used for reading data and mapping between entity classes and data fields. For example, read the personnel data in the csv file, and then mapper the fields corresponding to the entity person
6) ItemProcessor: The interface used to process data, and can do data validation (setting up validators, using JSR-303(hibernate-validator) annotations), such as changing Chinese gender male/female to M/F. At the same time, check whether the age field meets the requirements, etc.
7) ItemWriter: The interface used to output data and set up the database source. Writing Pre-Processing SQL Insert Statement
The above seven components only need to be registered one by one in the configuration class, and the configuration class needs to open the @EnableBatchProcessing annotation.
@Configuration @EnableBatchProcessing // Open batch processing support @Import(DruidDBConfig.class) // injection datasource public class CsvBatchConfig { }
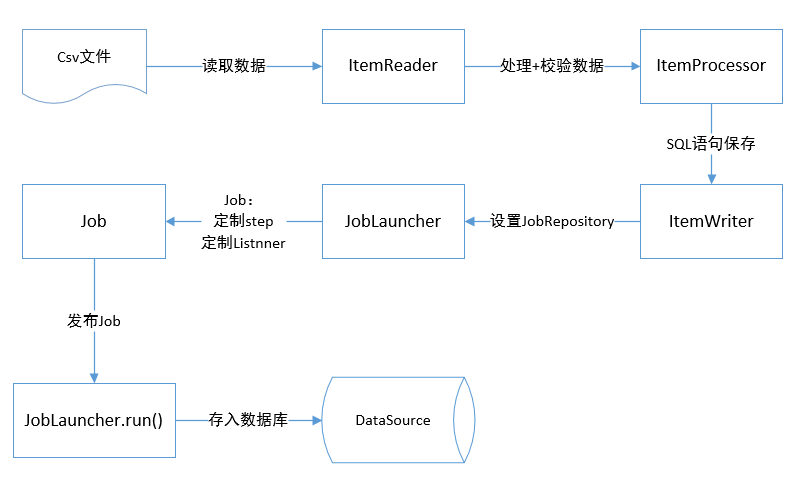
2. Batch Flow Chart
The following flow chart can explain why such a definition is needed in the configuration class. See the code in the actual part for details.
Two, actual combat
1. Adding dependencies
1) spring batch dependence
<!-- spring batch --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency>
2) Checker Dependence
<!-- hibernate validator --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-validator</artifactId> <version>6.0.7.Final</version> </dependency>
3) mysql+druid dependency
<!-- mysql connector--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.35</version> </dependency> <!-- alibaba dataSource --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.12</version> </dependency>
4) test test dependency
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency>
2. application.yml configuration
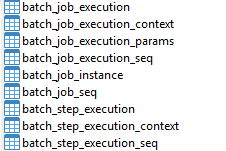
When job publishing starts executing tasks, spring batch automatically generates related batch start tables. These tables didn't exist at first! Relevant settings need to be made in the application configuration file.
# batch
batch:
job:
# The default automatic execution definition of Job(true) is changed to false, requiring jobLaucher.run to execute
enabled: false
# spring batch creates default tables in the database, and if it's not always, it prompts that the tables do not exist
initialize-schema: always
# Setting the prefix of the batch table
# table-prefix: csv-batch
3. Data Source Configuration
datasource: username: root password: 1234 url: jdbc:mysql://127.0.0.1:3306/db_base?useSSL=false&serverTimezone=UTC&characterEncoding=utf8 driver-class-name: com.mysql.jdbc.Driver
Register the DBConfig configuration class: Then import the batch configuration class through import
/** * @author jian * @dete 2019/4/20 * @description Customize DataSource * */ @Configuration public class DruidDBConfig { private Logger logger = LoggerFactory.getLogger(DruidDBConfig.class); @Value("${spring.datasource.url}") private String dbUrl; @Value("${spring.datasource.username}") private String username; @Value("${spring.datasource.password}") private String password; @Value("${spring.datasource.driver-class-name}") private String driverClassName; /* @Value("${spring.datasource.initialSize}") private int initialSize; @Value("${spring.datasource.minIdle}") private int minIdle; @Value("${spring.datasource.maxActive}") private int maxActive; @Value("${spring.datasource.maxWait}") private int maxWait; @Value("${spring.datasource.timeBetweenEvictionRunsMillis}") private int timeBetweenEvictionRunsMillis; @Value("${spring.datasource.minEvictableIdleTimeMillis}") private int minEvictableIdleTimeMillis; @Value("${spring.datasource.validationQuery}") private String validationQuery; @Value("${spring.datasource.testWhileIdle}") private boolean testWhileIdle; @Value("${spring.datasource.testOnBorrow}") private boolean testOnBorrow; @Value("${spring.datasource.testOnReturn}") private boolean testOnReturn; @Value("${spring.datasource.poolPreparedStatements}") private boolean poolPreparedStatements; @Value("${spring.datasource.maxPoolPreparedStatementPerConnectionSize}") private int maxPoolPreparedStatementPerConnectionSize; @Value("${spring.datasource.filters}") private String filters; @Value("{spring.datasource.connectionProperties}") private String connectionProperties;*/ @Bean @Primary // Injected has the highest priority public DataSource dataSource() { DruidDataSource dataSource = new DruidDataSource(); logger.info("-------->dataSource[url="+dbUrl+" ,username="+username+"]"); dataSource.setUrl(dbUrl); dataSource.setUsername(username); dataSource.setPassword(password); dataSource.setDriverClassName(driverClassName); /* //configuration datasource.setInitialSize(initialSize); datasource.setMinIdle(minIdle); datasource.setMaxActive(maxActive); datasource.setMaxWait(maxWait); datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis); datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis); datasource.setValidationQuery(validationQuery); datasource.setTestWhileIdle(testWhileIdle); datasource.setTestOnBorrow(testOnBorrow); datasource.setTestOnReturn(testOnReturn); datasource.setPoolPreparedStatements(poolPreparedStatements); datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize); try { datasource.setFilters(filters); } catch (SQLException e) { logger.error("druid configuration initialization filter", e); } datasource.setConnectionProperties(connectionProperties);*/ return dataSource; } @Bean public ServletRegistrationBean druidServletRegistrationBean() { ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(); servletRegistrationBean.setServlet(new StatViewServlet()); servletRegistrationBean.addUrlMappings("/druid/*"); return servletRegistrationBean; } /** * Register DruidFilter Interception * * @return */ @Bean public FilterRegistrationBean duridFilterRegistrationBean() { FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(); filterRegistrationBean.setFilter(new WebStatFilter()); Map<String, String> initParams = new HashMap<String, String>(); //Setting Ignore Request initParams.put("exclusions", "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*"); filterRegistrationBean.setInitParameters(initParams); filterRegistrationBean.addUrlPatterns("/*"); return filterRegistrationBean; } }
4. Writing batch configuration classes
In the configuration class, just register the components of Spring Batch, some of which are annotated in the code.
/** * * @author jian * @date 2019/4/28 * @description spring batch cvs File batch configuration needs to be injected into the following components of Spring Batch * spring batch Form: * 1)JobRepository Containers for registering job * 2)JonLauncher The interface used to start job * 3)Job Actual tasks, including one or more steps * 4)Step Step Steps include ItemReader, ItemProcessor and ItemWrite * 5)ItemReader Interface for reading data * 6)ItemProcessor Interface for Data Processing * 7)ItemWrite Interface for Output Data * * */ @Configuration @EnableBatchProcessing // Open batch processing support @Import(DruidDBConfig.class) // injection datasource public class CsvBatchConfig { private Logger logger = LoggerFactory.getLogger(CsvBatchConfig.class); /** * ItemReader Definition: Read file data + entity mapping * @return */ @Bean public ItemReader<Person> reader(){ // Use FlatFileItemReader To read cvs A file, a line, a piece of data FlatFileItemReader<Person> reader = new FlatFileItemReader<>(); // Set the file to be in the path reader.setResource(new ClassPathResource("person.csv")); // entity and csv Data mapping reader.setLineMapper(new DefaultLineMapper<Person>() { { setLineTokenizer(new DelimitedLineTokenizer() { { setNames(new String[]{"id", "name", "age", "gender"}); } }); setFieldSetMapper(new BeanWrapperFieldSetMapper<Person>() { { setTargetType(Person.class); } }); } }); return reader; } /** * Register ItemProcessor: Processing Data + Checking Data * @return */ @Bean public ItemProcessor<Person, Person> processor(){ CvsItemProcessor cvsItemProcessor = new CvsItemProcessor(); // Setting Checker cvsItemProcessor.setValidator(csvBeanValidator()); return cvsItemProcessor; } /** * Register Checker * @return */ @Bean public CsvBeanValidator csvBeanValidator(){ return new CsvBeanValidator<Person>(); } /** * ItemWriter Definition: specify data source, set batch insertion sql statement, write to database * @param dataSource * @return */ @Bean public ItemWriter<Person> writer(DataSource dataSource){ // Use jdbcBcatchItemWrite Write data to database JdbcBatchItemWriter<Person> writer = new JdbcBatchItemWriter<>(); // Parametric sql Sentence writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<Person>()); String sql = "insert into person values(:id,:name,:age,:gender)"; writer.setSql(sql); writer.setDataSource(dataSource); return writer; } /** * JobRepository Definition: Set up database, register Job container * @param dataSource * @param transactionManager * @return * @throws Exception */ @Bean public JobRepository cvsJobRepository(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{ JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean(); jobRepositoryFactoryBean.setDatabaseType("mysql"); jobRepositoryFactoryBean.setTransactionManager(transactionManager); jobRepositoryFactoryBean.setDataSource(dataSource); return jobRepositoryFactoryBean.getObject(); } /** * jobLauncher Definition: * @param dataSource * @param transactionManager * @return * @throws Exception */ @Bean public SimpleJobLauncher csvJobLauncher(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{ SimpleJobLauncher jobLauncher = new SimpleJobLauncher(); // Set up jobRepository jobLauncher.setJobRepository(cvsJobRepository(dataSource, transactionManager)); return jobLauncher; } /** * Define job * @param jobs * @param step * @return */ @Bean public Job importJob(JobBuilderFactory jobs, Step step){ return jobs.get("importCsvJob") .incrementer(new RunIdIncrementer()) .flow(step) .end() .listener(csvJobListener()) .build(); } /** * Register job Monitor * @return */ @Bean public CsvJobListener csvJobListener(){ return new CsvJobListener(); } /** * step Definition: The steps include ItemReader - > ItemProcessor - > ItemWriter that is to read data - > process validation data - > write data * @param stepBuilderFactory * @param reader * @param writer * @param processor * @return */ @Bean public Step step(StepBuilderFactory stepBuilderFactory, ItemReader<Person> reader, ItemWriter<Person> writer, ItemProcessor<Person, Person> processor){ return stepBuilderFactory .get("step") .<Person, Person>chunk(65000) // Chunk Mechanism(That is, read one data at a time, process another data, accumulate to a certain amount, and then give it to the user at one time. writer Write) .reader(reader) .processor(processor) .writer(writer) .build(); } }
5. Defining Processors
Simply implement the ItemProcessor interface and rewrite the process method. The input parameters are the data read from the ItemReader and the data returned to the ItemWriter.
/** * @author jian * @date 2019/4/28 * @description * CSV Data Processing and Verification of Documents * Simply implement the ItemProcessor interface and rewrite the process method. The input parameters are the data read from the ItemReader and the data returned to the ItemWriter. */ public class CvsItemProcessor extends ValidatingItemProcessor<Person> { private Logger logger = LoggerFactory.getLogger(CvsItemProcessor.class); @Override public Person process(Person item) throws ValidationException { // implement super.process()To call a custom validator logger.info("processor start validating..."); super.process(item); // Data processing, such as setting Chinese gender to M/F if ("male".equals(item.getGender())) { item.setGender("M"); } else { item.setGender("F"); } logger.info("processor end validating..."); return item; } }
6. Define the Checker
Define a validator: Use JSR-303(hibernate-validator) annotations to verify that the data read by ItemReader meets the requirements. If not, the next batch task will not be performed.
/** * * @author jian * @date 2019/4/28 * @param <T> * @description Define a validator: Use JSR-303(hibernate-validator) annotations to verify that the data read by ItemReader meets the requirements. */ public class CsvBeanValidator<T> implements Validator<T>, InitializingBean { private javax.validation.Validator validator; /** * Initialization of JSR-303 Validator * @throws Exception */ @Override public void afterPropertiesSet() throws Exception { ValidatorFactory validatorFactory = Validation.buildDefaultValidatorFactory(); validator = validatorFactory.usingContext().getValidator(); } /** * validator method for data validation * @param value * @throws ValidationException */ @Override public void validate(T value) throws ValidationException { Set<ConstraintViolation<T>> constraintViolations = validator.validate(value); if (constraintViolations.size() > 0) { StringBuilder message = new StringBuilder(); for (ConstraintViolation<T> constraintViolation: constraintViolations) { message.append(constraintViolation.getMessage() + "\n"); } throw new ValidationException(message.toString()); } } }
7. Define listeners:
To monitor Job execution, a class is defined to implement JobExecutorListener, and the listener is bound to Job's Bean.
/** * @author jian * @date 2019/4/28 * @description * To monitor Job execution, a class is defined to implement JobExecutorListener, and the listener is bound to Job's Bean. */ public class CsvJobListener implements JobExecutionListener { private Logger logger = LoggerFactory.getLogger(CsvJobListener.class); private long startTime; private long endTime; @Override public void beforeJob(JobExecution jobExecution) { startTime = System.currentTimeMillis(); logger.info("job process start..."); } @Override public void afterJob(JobExecution jobExecution) { endTime = System.currentTimeMillis(); logger.info("job process end..."); logger.info("elapsed time: " + (endTime - startTime) + "ms"); } }
Three, test
1. person.csv file
Comma-separated data representation fields for csv files and one line (bar) data record for carriage return
1,Zhangsan,21, male 2,Lisi,22, female 3,Wangwu,23, male 4,Zhaoliu,24, male 5,Zhouqi,25, female
Put it under resources and read the path in ItemReader.
2. person Entities
The field in person.csv corresponds to it, and a check annotation can be added to the entity, such as @Size indicating the length range of the field if it exceeds the specified limit. It will be checked and detected, batch processing will not be carried out!
public class Person implements Serializable { private final long serialVersionUID = 1L; private String id; @Size(min = 2, max = 8) private String name; private int age; private String gender; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } @Override public String toString() { return "Person{" + "id='" + id + '\'' + ", name='" + name + '\'' + ", age=" + age + ", gender='" + gender + '\'' + '}'; } }
3. Data sheet
CREATE TABLE `person` ( `id` int(11) NOT NULL, `name` varchar(10) DEFAULT NULL, `age` int(11) DEFAULT NULL, `gender` varchar(2) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
Initially, tables had no data.

4. Test class
You need to inject the publisher with job tasks. At the same time, the post-parameters can be used to process flexibly, and finally the JobLauncher.run method can be called to perform batch tasks.
@RunWith(SpringRunner.class) @SpringBootTest public class BatchTest { @Autowired SimpleJobLauncher jobLauncher; @Autowired Job importJob; @Test public void test() throws Exception{ // Postparameters: Use JobParameters Medium Binding Parameters JobParameters jobParameters = new JobParametersBuilder().addLong("time", System.currentTimeMillis()) .toJobParameters(); jobLauncher.run(importJob, jobParameters); } }
5. Test results
....
2019-05-09 15:23:39.576 INFO 18296 --- [ main] com.lijian.test.BatchTest : Started BatchTest in 6.214 seconds (JVM running for 7.185) 2019-05-09 15:23:39.939 INFO 18296 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=importCsvJob]] launched with the following parameters: [{time=1557386619763}] 2019-05-09 15:23:39.982 INFO 18296 --- [ main] com.lijian.config.batch.CsvJobListener : job process start... 2019-05-09 15:23:40.048 INFO 18296 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [step] 2019-05-09 15:23:40.214 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.282 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.284 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.525 INFO 18296 --- [ main] com.lijian.config.batch.CsvJobListener : job process end... 2019-05-09 15:23:40.526 INFO 18296 --- [ main] com.lijian.config.batch.CsvJobListener : elapsed time: 543ms 2019-05-09 15:23:40.548 INFO 18296 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=importCsvJob]] completed with the following parameters: [{time=1557386619763}] and the following status: [COMPLETED] 2019-05-09 15:23:40.564 INFO 18296 --- [ Thread-5] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} closed
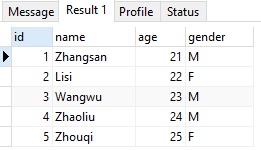
Look at the data in the table: select * from person;
If you continue to insert data and test whether the validator is in effect, change person.csv to the following:
6, spring batch, 24, male 7, spring boot, 23, female
Because JSR check annotations in entity classes check the name length range, they add @Size(min=2, max=8) annotations. Therefore, the error report shows that the check is not passed and the batch processing will not be carried out.
... Started BatchTest in 5.494 seconds (JVM running for 6.41) 2019-05-09 15:30:02.147 INFO 20368 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=importCsvJob]] launched with the following parameters: [{time=1557387001499}] 2019-05-09 15:30:02.247 INFO 20368 --- [ main] com.lijian.config.batch.CsvJobListener : job process start... 2019-05-09 15:30:02.503 INFO 20368 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [step] 2019-05-09 15:30:02.683 INFO 20368 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:30:02.761 ERROR 20368 --- [ main] o.s.batch.core.step.AbstractStep : Encountered an error executing step step in job importCsvJob org.springframework.batch.item.validator.ValidationException: size must be between 2 and 8 ...