Original Link: https://zzzzbw.cn/article/18
Recent concurrency problems have been encountered in the company's business, and it is still a very common concurrency problem. The company's business is the most common "order + account" problem, which is considered a low-level error. Since the company's business is relatively complex and unsuitable for publicity, here's a very common business to restore the scene, along with an introduction Pessimistic Lock And optimistic locks are how to solve such concurrency problems.
Business Restore
The first environment is: Spring Boot 2.1.0 + data-jpa + mysql + lombok
Database Design
For a blog system with commenting capabilities, there are usually two tables: 1. Article Table 2. Comment sheet. In addition to keeping some article information, the article table also has a field to hold the number of comments. We designed a minimal table structure to restore the business scenario.
article Article Table
| field | type | Remarks |
|---|---|---|
| id | INT | Self-increasing primary key id |
| title | varchar | Article Title |
| comment_count | INT | Number of comments on article |
Comment comment table
| field | type | Remarks |
|---|---|---|
| id | INT | Self-increasing primary key id |
| article_id | INT | Article id of comment |
| content | varchar | Comments |
When a user comments:
- Get articles based on article id
- Insert a comment record
- Increase and save comments on this article
code implementation
First introduce the corresponding dependency in maven
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
Then write the entity class for the corresponding database
@Data
@Entity
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private Long commentCount;
}
@Data
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long articleId;
private String content;
}
Next, create the Repository corresponding to these two entity classes. Since spring-jpa-data's CruRepository has helped us implement the most common CRUD operations, our Repository just needs to inherit the CrudRepository interface and do nothing else.
public interface ArticleRepository extends CrudRepository<Article, Long> {
}
public interface CommentRepository extends CrudRepository<Comment, Long> {
}
Next, we'll simply implement the Controller interface and the Service implementation class.
@Slf4j
@RestController
public class CommentController {
@Autowired
private CommentService commentService;
@PostMapping("comment")
public String comment(Long articleId, String content) {
try {
commentService.postComment(articleId, content);
} catch (Exception e) {
log.error("{}", e);
return "error: " + e.getMessage();
}
return "success";
}
}
@Slf4j
@Service
public class CommentService {
@Autowired
private ArticleRepository articleRepository;
@Autowired
private CommentRepository commentRepository;
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
if (!articleOptional.isPresent()) {
throw new RuntimeException("No corresponding article");
}
Article article = articleOptional.get();
Comment comment = new Comment();
comment.setArticleId(articleId);
comment.setContent(content);
commentRepository.save(comment);
article.setCommentCount(article.getCommentCount() + 1);
articleRepository.save(article);
}
}
Concurrency problem analysis
From the code implementation just now, you can see this simple process of commenting. When a user makes a request for comment, find the entity class Article of the corresponding article from the database, generate the corresponding comment entity class Comment from the article information, insert it into the database, then increase the number of comments on the article, and update the modified article to the database. The whole process is as follows.
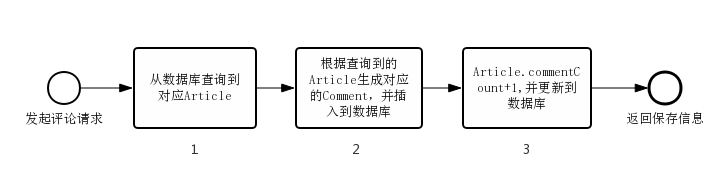
A problem with this process is that when multiple users concurrently comment, they go to Step 1 to get Article at the same time, insert the corresponding Comment, and finally update the number of comments in Step 3 to save to the database. Just because they both got Article at step 1, their Article. CommeCount has the same value, so the rticle saved in step 3. CommentCount+1 is the same, so the number of comments that should have been + 3 has only been added 1.
Let's try it with test case code
@RunWith(SpringRunner.class)
@SpringBootTest(classes = LockAndTransactionApplication.class, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class CommentControllerTests {
@Autowired
private TestRestTemplate testRestTemplate;
@Test
public void concurrentComment() {
String url = "http://localhost:9090/comment";
for (int i = 0; i < 100; i++) {
int finalI = i;
new Thread(() -> {
MultiValueMap<String, String> params = new LinkedMultiValueMap<>();
params.add("articleId", "1");
params.add("content", "Test Content" + finalI);
String result = testRestTemplate.postForObject(url, params, String.class);
}).start();
}
}
}
Here we have 100 threads and send a comment request with a corresponding article id of 1.
Before sending the request, the database data is
select * from article
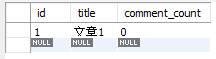
select count(*) comment_count from comment
After sending the request, the database data is
select * from article
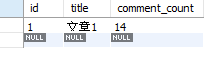
select count(*) comment_count from comment
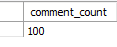
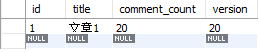
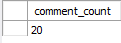
Obviously see comment_in the article table The value of count is not 100, which is not necessarily 14 in my chart, but must not be greater than 100, and the number of comment tables must be equal to 100.
This demonstrates the concurrency issues mentioned at the beginning of the article, which are very common and should be carefully avoided as long as there is a system of processes similar to the commenting functions mentioned above.
Here's an example of how to prevent concurrent data problems by using pessimistic and optimistic locks. Both the SQL and JPA built-in schemas are provided. The SQL schema can be universal "any system" or even language-independent. The JPA schema is fast, and if you happen to use JPA, you can simply use optimistic or pessimistic locks. Finally, there are some differences between optimistic and pessimistic locks based on business
Pessimistic Lock Solves Concurrency Problems
Pessimistic locks, as the name implies, are pessimistic because they think the data they manipulate will be manipulated by other threads, so they must be exclusive themselves, which can be interpreted as "exclusive locks". Locks such as synchronized and ReentrantLock in java are pessimistic locks, as are table locks, row locks, read-write locks in databases.
Solving concurrency problems with SQL
Row locks lock this row of data while manipulating it. Other threads must wait to read and write, but other data from the same table can still be manipulated by other threads. As long as you add for update after the sql you need to query, you can lock the rows of the query. It is important to note that the query condition must be an index column. If it is not an index, it becomes a table lock, locking the entire table.
Now modify the original code by adding a manual sql query method to ArticleRepository.
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Query(value = "select * from article a where a.id = :id for update", nativeQuery = true)
Optional<Article> findArticleForUpdate(Long id);
}
Then change the query method used in CommentService from findById to our custom method
public class CommentService {
public void postComment(Long articleId, String content) {
// Optional<Article> articleOptional = articleRepository.findById(articleId);
Optional<Article> articleOptional = articleRepository.findArticleForUpdate(articleId);
}
}
This way, the Article s we find cannot be modified by other threads until we commit them to a transaction, ensuring that only one thread can operate on the corresponding data at the same time.
Now try again with the test case, article. Comment_ The value of count must be 100.
Solving concurrency problems with JPA built-in row locks
JPA offers a more elegant way to add for update after sql just mentioned, the @Lock annotation, whose parameters can pass in the desired lock level.
Now add the JPA lock method, LockModeType, to ArticleRepository. PESSIMISTIC_ The WRITE parameter is a row lock.
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Transactional
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select a from Article a where a.id = :id")
Optional<Article> findArticleWithPessimisticLock(Long id);
}
Similarly, if you change the query method to findArticleWithPessimisticLock() in CommentService and test the case again, there will be no concurrency problems. And when I look at the console print information, I find that in fact the sql of the query has been added for update, but only JPA has helped us add it.

If @NameQuery, you can
@NamedQuery(,lockMode = PESSIMISTIC_READ) public class Article
If you are using entityManager, you can set LocakMode:
Query query = entityManager.createQuery("from Article where articleId = :id");
query.setParameter("id", id);
query.setLockMode(LockModeType.PESSIMISTIC_WRITE);
query.getResultList();
SQL using jpa method name, cannot customize sql, can only use @Lock
Optimistic Lock Solves Concurrency Problems
Optimistic locks, as the name implies, are particularly optimistic that the resources you get won't be locked by other threads, just check to see if the data has been modified when you insert it into the database. So the pessimistic lock is to limit other threads, while the optimistic lock is to limit itself. Although its name is locked, it's not actually a lock, but it's just to decide what to do at the end of the operation.
Optimistic locks are usually version number mechanisms or CAS algorithms
Solving concurrency problems by using version number in SQL
The version number mechanism is to add a field to the database as the version number, for example, we add a field version. Then when you get Article, you will take a version number with you, for example, version 1. Then you will operate on the Article and insert it into the database after that. I found out, oh, how come the version of Article in the database is 2, which is different from the version in my hand. That means the Article in my hand is not up to date, so I can't put it in the database. This avoids data conflicts in concurrency.
So now we'll add a field version to the article table
article Article Table
| field | type | Remarks |
|---|---|---|
| version | INT DEFAULT 0 | version number |
The corresponding entity class then adds the version field as well
@Data
@Entity
public class Article {
private Long version;
}
Then add an updated method to ArticleRepository, noting that this is a newer method than adding a query when pessimistic locks occur.
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Modifying
@Query(value = "update article set comment_count = :commentCount, version = version + 1 where id = :id and version = :version", nativeQuery = true)
int updateArticleWithVersion(Long id, Long commentCount, Long version);
}
You can see that where update has a condition to judge version, and set version = version + 1. This ensures that the data will only be updated if the version number in the database is the same as the version number of the entity class to be updated.
Next, modify the code a little in CommentService.
// CommentService
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
int count = articleRepository.updateArticleWithVersion(article.getId(), article.getCommentCount() + 1, article.getVersion());
if (count == 0) {
throw new RuntimeException("Server busy,Failed to update data");
}
// articleRepository.save(article);
}
The first query method for Article requires only the normal findById() method and does not require any locks.
Then use the new updateArticleWithVersion() method when updating Article. You can see that this method has a return value that represents the number of updated database rows, and that if the value is 0, there are no eligible rows to update.
After that, we can decide what to do. This is a direct rollback. spring will help us roll back previous data operations and cancel all operations to ensure data consistency.
Now test again with test cases
select * from article
select count(*) comment_count from comment
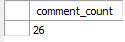
Now you see comment_in Article Neither count nor COMMENT is 100, but these two values must be the same. Because if the data of the Article table conflicts when we just processed it, it will not be updated to the database, and an exception will be thrown to roll back its transaction. This will ensure that Comment will not be inserted when Article is not updated, which solves the problem of data inconsistency.
This direct rollback process has a poor user experience, typically if you judge that the number of Article updates is zero, you try to retrieve information from the database and modify it again, try to update the data again, and query again if you can't, until you can update it. Of course, it is not a wireless looping operation. It will set an online operation, such as looping three queries to modify updates, which will throw an exception.
Solving concurrency problems with JPA@Version implementation version discovery
JPA implements pessimistic locks, and optimistic locks naturally exist. Now use JPA's own method to achieve optimistic locks.
First, add the @Version comment to the version field of the Article entity class. Let's go into the comment and look at the comment for the source code. You can see that part of it says:
The following types are supported for version properties: int, Integer, short, Short, long, Long, java.sql.Timestamp.
The note says that the version number type supports the basic data types int, short, long and their wrapper classes as well as Timestamp. We are now using the Long type.
@Data
@Entity
public class Article {
@Version
private Long version;
}
Then you just need to modify the comment process in CommentService back to the business code that we started with "Triggering Concurrency Issues". This shows that this optimistic lock implementation for JPA is non-intrusive.
// CommentService
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
...
article.setCommentCount(article.getCommentCount() + 1);
articleRepository.save(article);
}
As before, use test cases to test whether concurrency problems can be prevented.
select * from article

select count(*) comment_count from comment
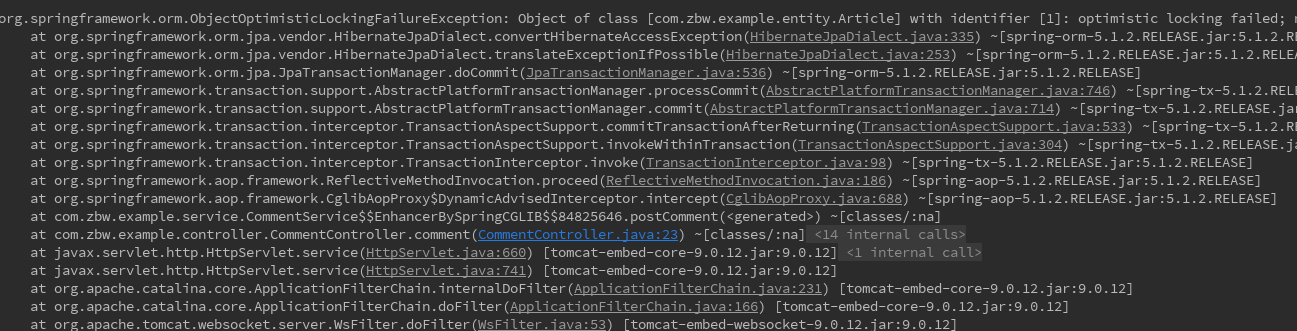
Comment_in the same Article The number of counts and COMMENTS is not 100 either, but they must be the same. Looking at IDEA's console, you can see that the system threw an exception to ObjectOptimisticLockingFailureException.
This is similar to the optimistic lock we just implemented ourselves, throwing an exception rollback if the data is not updated successfully to ensure data consistency. If you want to implement a retry process that captures the exception ObjectOptimisticLockingFailureException, you will typically use AOP+ custom annotations to implement a globally common retry mechanism, which is expanded to suit your specific business situation, and you can search for the solution yourself.
Comparison of Pessimistic Lock and Optimistic Lock
Pessimistic locks are good for situations where you write more and read less. Because this thread exclusively uses this resource when it is in use, for example, an id's article. If there are a lot of comments, a pessimistic lock is appropriate. Otherwise, if the user just browses the article without any comments, a pessimistic lock will often lock, increasing the resource consumption of unlocking.
Optimistic locks are good for situations where you write less and read more. Because optimistic locks roll back or retry when conflicts occur, conflicts often occur if there are a large number of write requests, and often rollback and retry, which can also be very costly for system resources.
Therefore, there is no absolute good or bad between pessimistic locks and optimistic locks, which must be combined with specific business situations to decide which way to use. It is also mentioned in the Alibaba development manual:
Optimistic locks are recommended if the probability of each access conflict is less than 20%, or pessimistic locks are recommended. Optimistic locks must be retried no less than three times.
Alibaba recommends that you use the 20% probability of conflict as a dividing line between optimistic and pessimistic locks. Although this value is not absolute, it is also a good reference for Alibaba's big guys to summarize.