1, Repository interface and query method
Spring Data is an open source framework dedicated to data access in the spring family. Its core idea is to support resource configuration for all storage media to realize data access. We know that data access needs to complete the mapping between domain objects and stored data, and provide external access. Spring Data abstracts a set of unified data access methods to realize this mode based on the Repository architecture mode.
Spring Data abstracts the data access process mainly in two aspects: ① it provides a set of Repository interface definition and implementation; ② Various query supports have been realized. Next, let's take a look at them respectively.
Repository interface and its implementation
The Repository interface is the highest level abstraction of data access in Spring Data. The interface definition is as follows:
public interface Repository<T, ID> {
}
In the above code, we can see that the Repository interface is just an empty interface, which specifies the type and ID of the domain entity object through generics. In Spring Data, there are a large number of sub interfaces and implementation classes of Repository interface. Some class layer structures of this interface are as follows:

It can be seen that the CrudRepository interface is the most common extension to the Repository interface, adding the CRUD operation function for domain entities. The specific definitions are as follows:
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
These methods are self explanatory. We can see that the CrudRepository interface provides common operations such as saving a single entity, saving a set, finding entities according to id, judging whether entities exist according to id, querying all entities, querying the number of entities, deleting entities according to id, deleting a set of entities, and deleting all entities, Let's look at the implementation process of several methods.
Diversified query support
In the daily development process, the number of operations of data Query is much higher than that of data addition, data deletion and data modification. Therefore, in Spring Data, in addition to providing default CRUD operations for domain objects, we also need to highly abstract the Query scenario. In real business scenarios, the most typical Query operations are @ Query annotation and method name derivation Query mechanism.
@Query annotation
We can directly embed Query statements and conditions in the code through @ Query annotation, so as to provide powerful functions similar to that of ORM framework.
The following is a typical example of Query using @ Query annotation:
public interface AccountRepository extends JpaRepository<Account,Long> {
@Query("select a from Account a where a.userName = ?1")
Account findByUserName(String userName);
}
Note that the @ Query annotation here uses a syntax similar to SQL statements, which can automatically map the domain object Account to the database data. Because we use JpaRepository, the syntax similar to SQL statement is actually a JPA Query language, that is, the so-called JPQL (Java Persistence Query Language).
The basic syntax of JPQL is as follows:
-
SELECT clause FROM clause
-
[WHERE clause]
-
[GROUP BY clause]
-
[HAVING clause]
-
[ORDER BY clause]
Are JPQL statements very similar to native SQL statements? The only difference is that JPQL FROM statements are followed by objects, while native SQL statements correspond to fields in the data table.
Method name derived query
Method name derived query is also one of the query features of Spring Data. By directly using query fields and parameters in method naming, Spring Data can automatically identify the corresponding query conditions and assemble the corresponding query statements. Typical examples are as follows:
public interface AccountRepository extends JpaRepository<Account,Long> {
List<Account> findByFirstNameAndLastName(String firstName, String,lastName);
}
In the above example, Spring Data can automatically assemble SQL statements by using method names that conform to common semantics, such as findByFirstNameAndLastname, and passing in the corresponding parameters in the parameter list according to the order and name of the parameters in the method name (that is, the first parameter is firstname and the second parameter lastName), so as to realize derivative queries. Isn't it amazing?
If we want to use the method name to implement the derived query, we need to restrict the method name defined in the Repository.
First, we need to specify some query keywords. The common keywords are as follows:
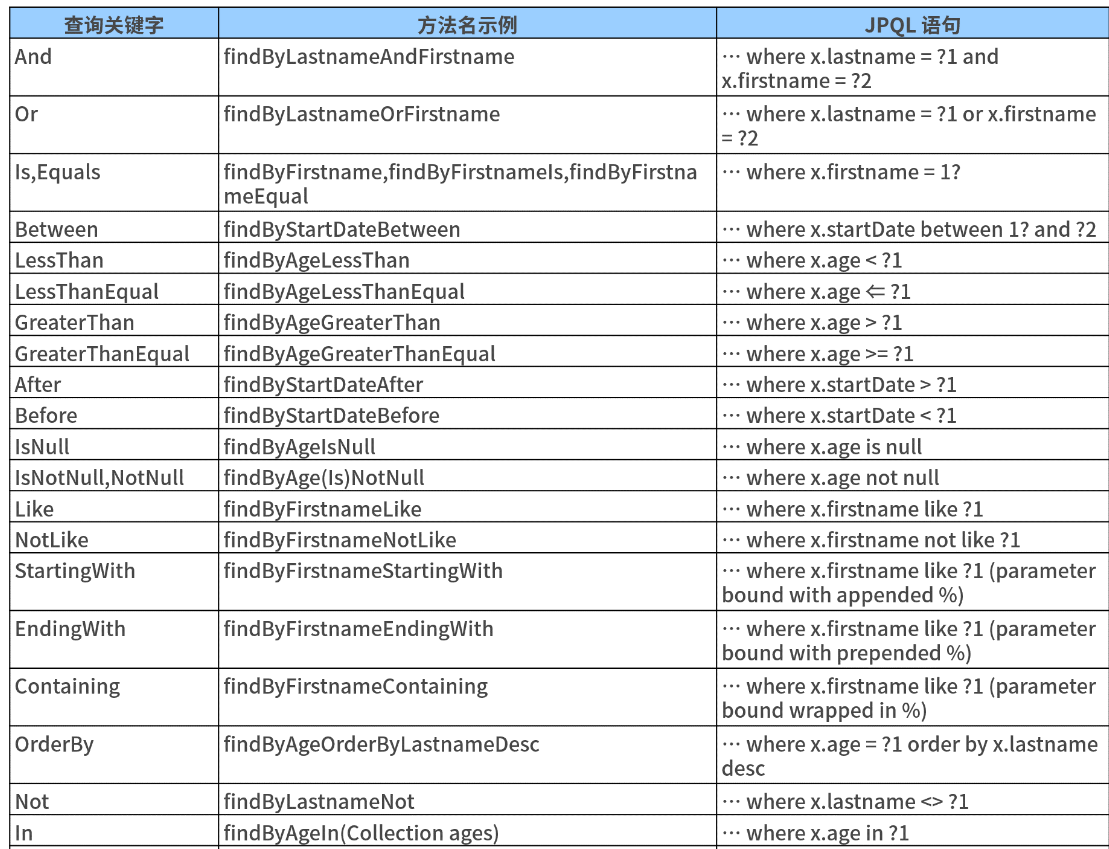

Note that Spring Data uses create by default_ IF_ NOT_ The found strategy, that is, the system will first find the @ Query annotation. If not, it will find the Query matching the method name.
2, ORM integration: steps to access relational databases using Spring Data JPA
(1) Introducing Spring Data JPA
If you want to use Spring Data JPA in your application, you need to first introduce the spring boot starter data JPA dependency into the pom file, as shown in the following code:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
Before introducing the usage of this component, it is necessary for us to have a certain understanding of JPA specification.
The full name of JPA is JPA Persistence API, that is, Java persistence API. It is a Java application program interface specification, which is used to act as a bridge between object-oriented domain model and relational database system. It belongs to ORM (Object Relational Mapping) technology.
The JPA specification defines some established concepts and conventions, which are contained in javax In the persistence package, common definitions, such as Entity definition, Entity identification definition, association relationship definition between entities, and JPQL definition introduced in lecture 09, will be described in detail later.
Like the JDBC specification, the JPA specification also has a large number of implementation tools and frameworks, such as the old Hibernate and the Spring Data JPA we will introduce today.
In order to demonstrate the whole development process based on Spring Data JPA, we will specially design and implement a set of independent domain objects and Repository in the case of spring CSS. Next, let's take a look.
(2) Entity class annotation
Entity class refers to the mapping table corresponding to the data table.
Let's first look at the relatively simple JpaGoods. Here we list the references of relevant classes of JPA specification. The definition of JpaGoods is as follows:
@Entity
@Table(name="goods")
public class JpaGoods {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String goodsCode;
private String goodsName;
private Float price;
//Omit getter/setter
}
JPA goods uses several annotations used to define entities in JPA specification: the most important @ Entity annotation, the @ Table annotation used to specify the Table name, the @ Id annotation used to identify the primary key, and the @ GeneratedValue annotation used to identify self incremented data. These annotations are straightforward and can be used directly on the Entity class.
Next, let's take a look at the more complex JpaOrder, which is defined as follows:
@Entity
@Table(name="`order`")
public class JpaOrder implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String orderNumber;
private String deliveryAddress;
@ManyToMany(targetEntity=JpaGoods.class)
@JoinTable(name = "order_goods", joinColumns = @JoinColumn(name = "order_id", referencedColumnName = "id"), inverseJoinColumns = @JoinColumn(name = "goods_id", referencedColumnName = "id"))
private List<JpaGoods> goods = new ArrayList<>();
//Omit getter/setter
}In addition to some common annotations, the @ ManyToMany annotation is also introduced here, which represents the association between the data in the order table and the goods table.
In the JPA specification, there are four mapping relationships: one-to-one, one-to-many, many to one and many to many, which are used to deal with one-to-one, one to many, many to one and many to many correlation scenarios respectively.
For the business scenario of order service, we designed an order_ The goods intermediate table stores the primary key relationship between order and the goods table. The @ ManyToMany annotation is used to define the many to many relationship, and the @ JoinTable annotation is also used to specify order_goods intermediate table, and specify the field names in the intermediate table and the foreign key names in the reference two main tables respectively through the joinColumns and inverseJoinColumns annotations.
(3) The custom class implements the sub interface of the Repository interface
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>{}After implementing the interface, the custom class will bring many crud methods inherited from the Repository interface, or you can write new methods yourself.
Use @ Query annotation
An example of Query using @ Query annotation is shown in the following code:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>
{
@Query("select o from JpaOrder o where o.orderNumber = ?1")
JpaOrder getOrderByOrderNumberWithQuery(String orderNumber);
}Here, we use JPQL to query the order information according to the OrderNumber. The syntax of JPQL is very similar to that of SQL statements.
When it comes to the @ Query annotation, JPA also provides an @ NamedQuery annotation to name the statements in the @ Query annotation@ The NamedQuery annotation is used as follows:
@Entity
@Table(name = "`order`")
@NamedQueries({ @NamedQuery(name = "getOrderByOrderNumberWithQuery", query = "select o from JpaOrder o where o.orderNumber = ?1") })
public class JpaOrder implements Serializable {}In the above example, we added an @ NamedQueries annotation on the entity class JpaOrder, which can integrate a batch of @ NamedQuery annotations. At the same time, we also use the @ NamedQuery annotation to define a "getOrderByOrderNumberWithQuery" query and specify the corresponding JPQL statement.
If you want to use this named query, define a method consistent with the name in OrderJpaRepository.
Derived query using method name
Deriving queries from method names is the most convenient way to customize queries. In this process, the only thing developers need to do is to define a method that conforms to the query semantics in the JpaRepository interface.
For example, if we want to query order information through OrderNumber, we can provide the interface definition shown in the following code:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>
{
JpaOrder getOrderByOrderNumber(String orderNumber);
}
After using the getOrderByOrderNumber method, we can automatically obtain the order details according to the OrderNumber.
Using QueryByExample mechanism
Next, we will introduce another powerful query mechanism, query by example (QBE).
For the JpaOrder object, if we want to query according to one or more conditions in OrderNumber and DeliveryAddress, after constructing the query method according to the method name derivation query, we can get the method definition shown in the following code:
List<JpaOrder> findByOrderNumberAndDeliveryAddress (String orderNumber, String deliveryAddress);
If many fields are used in the query criteria, the above method name may be very long, and a number of parameters need to be set. This query method definition is obviously flawed.
Because no matter how many query conditions there are, we need to fill in all parameters, even if some parameters are not used. Moreover, if we need to add a new query condition in the future, the method must be adjusted, and there are design defects in terms of scalability. To solve these problems, we can introduce the QueryByExample mechanism.
QueryByExample can be translated into query by example, which is a user-friendly query technology. It allows us to dynamically create queries without writing query methods containing field names, that is, according to the example query, we do not need to write query statements in a specific database query language.
Structurally speaking, QueryByExample includes three basic components: Probe, ExampleMatcher and Example. Among them, the Probe contains the instance object of the corresponding field. The ExampleMatcher carries detailed information about how to match a specific field, which is equivalent to the matching condition. The Example is composed of the Probe and ExampleMatcher, which are used to build specific query operations.
Now, we reconstruct the implementation process of querying orders according to OrderNumber based on QueryByExample mechanism.
First, we need to inherit the QueryByExampleExecutor interface in the definition of OrderJpaRepository interface, as shown in the following code:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>, QueryByExampleExecutor<JpaOrder> {}
Then, we implement the getOrderByOrderNumberByExample method shown in the following code in JpaOrderService:
public JpaOrder getOrderByOrderNumberByExample(String orderNumber) {
JpaOrder order = new JpaOrder();
order.setOrderNumber(orderNumber);
ExampleMatcher matcher = ExampleMatcher.matching().withIgnoreCase()
.withMatcher("orderNumber", GenericPropertyMatchers.exact()).withIncludeNullValues();
Example<JpaOrder> example = Example.of(order, matcher);
return orderJpaRepository.findOne(example).orElse(new JpaOrder());
}
In the above code, we first build an ExampleMatcher object to initialize the matching rules, then build an Example object by passing in a JpaOrder object instance and an ExampleMatcher instance, and finally implement the QueryByExample mechanism through the findOne() method in the QueryByExampleExecutor interface.
Using Specification mechanism
The query mechanism we want to introduce at the end of this class is the Specification mechanism.
Consider a scenario first. For example, we need to query an entity, but the given query conditions are not fixed. What should we do now? At this time, we can dynamically build the corresponding query statements, and in Spring Data JPA, such queries can be implemented through the jpaspecifieexecutor interface. Compared with using JPQL, the advantage of using Specification mechanism is type safety.
The OrderJpaRepository definition that inherits the jpaspecification executor is as follows:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>, JpaSpecificationExecutor<JpaOrder>{}
For the JpaSpecificationExecutor interface, the Specification interface is used behind it, and the core method of the Specification interface is one. We can simply understand that the function of the interface is to build query conditions, as shown in the following code:
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder);
The Root object represents the Root object to be queried. We can obtain the attributes of the entity through the Root. CriteriaQuery represents a top-level query object to implement custom query, and CriteriaBuilder is used to build query conditions.
Based on the Specification mechanism, we also reconstruct the implementation process of querying orders according to OrderNumber. The reconstructed getOrderByOrderNumberBySpecification method is as follows:
public JpaOrder getOrderByOrderNumberBySpecification(String orderNumber) {
JpaOrder order = new JpaOrder();
order.setOrderNumber(orderNumber);
@SuppressWarnings("serial")
Specification<JpaOrder> spec = new Specification<JpaOrder>() {
@Override
public Predicate toPredicate(Root<JpaOrder> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Path<Object> orderNumberPath = root.get("orderNumber");
Predicate predicate = cb.equal(orderNumberPath, orderNumber);
return predicate;
}
};
return orderJpaRepository.findOne(spec).orElse(new JpaOrder());
}As can be seen from the above example, in the toPredicate method, we first obtain the "orderNumber" attribute from the root object, and then use CB The equal method compares the attribute with the passed in orderNumber parameter, so as to realize the construction process of query conditions.
(4) Accessing the database using Spring Data JPA
With the JpaOrder and JpaGoods entity classes defined above and the OrderJpaRepository interface, we can already implement many operations.
For example, if we want to obtain the Order object through Id, we can first build a JpaOrderService and directly inject it into the OrderJpaRepository interface, as shown in the following code:
@Service
public class JpaOrderService {
@Autowired
private OrderJpaRepository orderJpaRepository;
public JpaOrder getOrderById(Long orderId) {
return orderJpaRepository.getOne(orderId);
}
}