Original title: Spring certified China Education Management Center - Spring Data Neo4j tutorial IV (spring China Education Management Center)

6.3.3. General recommendations
- Try to stick with immutable objects -- immutable objects are easy to create because the implementation object only needs to call its constructor. In addition, this prevents your domain object from being littered by setter methods that allow client code to manipulate the object state. If you need these, it's best to package them so that they can only be called by a limited number of collocated types. Constructor only implementation is 30% faster than property padding.
- Provide a full parameter constructor -- even if you can't or don't want to model your entity as an immutable value, providing a constructor that takes all the attributes of the entity as parameters (including variable attributes) is still valuable, because it allows object mapping to skip attribute filling for best performance.
- Use factory methods instead of overloaded constructors to avoid @ PersistenceConstructor - use the all parameter constructors required for best performance. We usually want to expose more application use case specific constructors that omit automatically generated identifiers and so on. This is an established pattern, rather than using static factory methods to expose variations of these all parameter constructors.
- Ensure compliance with the constraints that allow the use of generated instantiator and property accessor classes
- For the identifier to be generated, the final field is still used in combination with the with method
- Use Lombok to avoid template code - since persistence operations usually require a constructor to obtain all parameters, their declaration becomes cumbersome repetition of template parameters assigned to fields. Using Lombok can best avoid this situation @ AllArgsConstructor.
Description of immutable mapping
Although we recommend using immutable mapping and construction as much as possible, there are some limitations in mapping. Given A two-way relationship, where A has A constructor that references B and B, A reference A, or A more complex scenario. Spring Data Neo4j can't solve this first come, then come situation. In its instantiation process, A urgently needs A fully instantiated, B on the other hand, it needs A fully instantiated SDN usually allows such A model, but will throw an AMappingException. If the data returned from the database contains the above constellation, it will be thrown at runtime. In this case, you can't predict what the returned data will be like, and you are more suitable to use variable fields to deal with relationships.
6.3.4.Kotlin support
Spring Data tweaks the details of Kotlin to allow object creation and mutation.
Kotlin object creation
Kotlin classes support instantiation. By default, all classes are immutable. Explicit attribute declarations are required to define variable attributes. Consider the following data class Person:
data class Person(val id: String, val name: String)
The above class is compiled into a typical class with an explicit constructor. We can customize this class by adding another constructor, and indicate the constructor preference with the annotation @ PersistenceConstructor:
data class Person(var id: String, val name: String) {
@PersistenceConstructor
constructor(id: String) : this(id, "unknown")
}Kotlin supports parameter selectability by allowing default values when no parameters are provided. When Spring Data detects a constructor with parameter default values, if the data store does not provide values (or simply returns null), it will make these parameters nonexistent, so kotlin can apply parameter default values. Consider the following class name that applies the default value of the parameter
data class Person(var id: String, val name: String = "unknown")
Name defaults to unknown every time the name parameter is not part of the result or its value is null.
Overall properties of Kotlin data class
In Kotlin, all classes are immutable by default, and explicit attribute declarations are required to define variable attributes. Consider the following data class Person:
data class Person(val id: String, val name: String)
This class is actually immutable. It allows the creation of new instances because Kotlin generates a copy(...) method to create new object instances, which copies all attribute values from existing objects and applies the attribute values provided as parameters to the method.
7. Use Spring data repository
The goal of Spring Data repository abstraction is to significantly reduce the amount of boilerplate code required to implement the data access layer for various persistent stores.
Spring Data repository documentation and your modules
This chapter introduces the core concepts and interfaces of the Spring Data repository. The information in this chapter comes from the Spring Data Commons module. It uses the configuration and code examples of the Java Persistence API (JPA) module. You should adjust the XML namespace declaration and the type to be extended to accommodate the equivalents of the specific module you use. “ [ repositories. Namespace reference] "covers the XML configuration, which is supported by all Spring Data modules that support repository API s. Appendix A covers the query method keywords generally supported by repository abstractions.
7.1 core concepts
The central interface in the Spring Data Repository abstraction is Repository It requires the domain class to manage and the ID type of the domain class as the type parameter. This interface is primarily used as a tag interface to capture the types to use and help you discover the interfaces that extend this interface. The CrudRepository interface provides complex CRUD functions for managed entity classes.
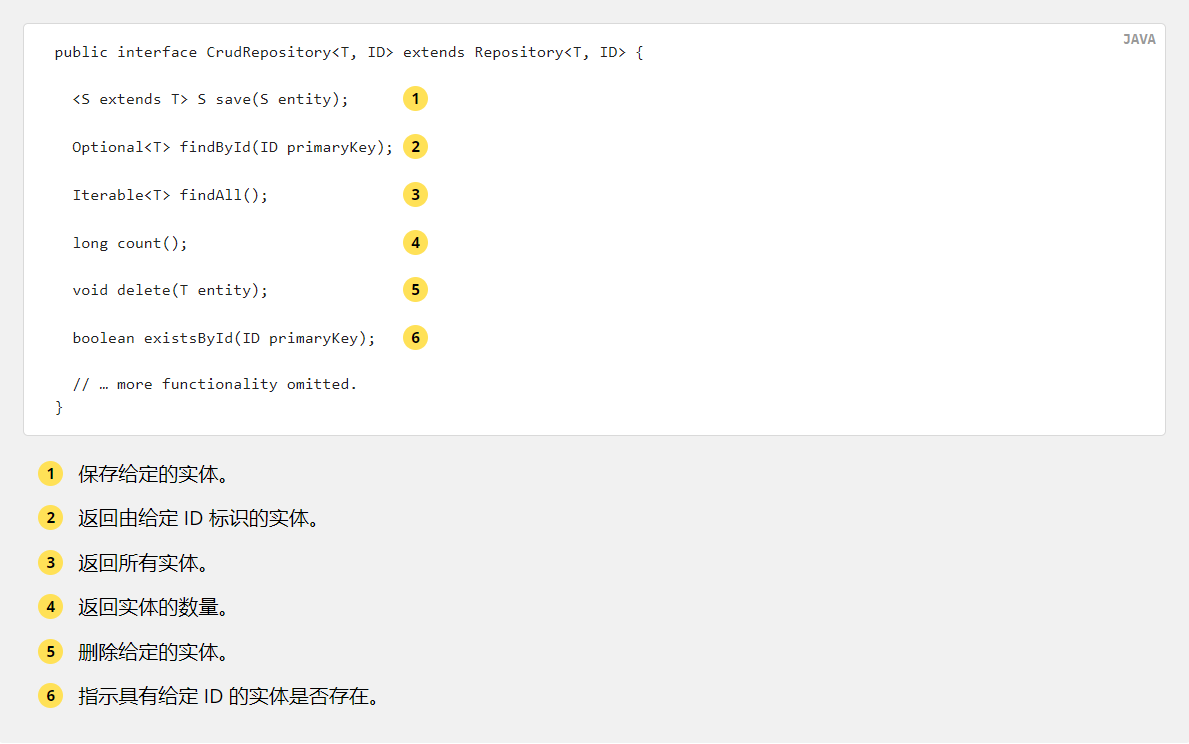
Example 13 Crudrepository interface
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
Optional<T> findById(ID primaryKey);
Iterable<T> findAll();
long count();
void delete(T entity);
boolean existsById(ID primaryKey);
// ... more functionality omitted.
}Save the given entity.
Returns the entity identified by the given ID.
Returns all entities.
Returns the number of entities.
Delete the given entity.
Indicates whether an entity with the given ID exists.
We also provide abstractions specific to persistence technologies, such as JpaRepository or MongoRepository. CrudRepository, in addition to the fairly general interface independent of Persistence Technology (such as CrudRepository
On top of the CrudRepository, there is another Pagingandsortingreposition abstraction, which adds additional methods to simplify paging access to entities:
Example 14.PagingAndSortingRepository interface
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}To access the second page with a User page size of 20, you can do the following:
PagingAndSortingRepository<User, Long> repository = // ... get access to a bean Page<User> users = repository.findAll(PageRequest.of(1, 20));
In addition to query methods, you can also use count and query derivation of delete queries. The following list shows the interface definitions for derived count queries:
Example 15 Derived count query
interface UserRepository extends CrudRepository<User, Long> {
long countByLastname(String lastname);
}The following listing shows the interface definition for the derived delete query:
Example 16 Derived delete query
interface UserRepository extends CrudRepository<User, Long> {
long deleteByLastname(String lastname);
List<User> removeByLastname(String lastname);
}7.2. Query method
Standard CRUD function repositories typically query the underlying data store. Using Spring Data, declaring these queries becomes a four step process:
1. Declare an interface that extends the Repository or one of its sub interfaces, and type it into the domain class and ID type that should be processed, as shown in the following example:
interface PersonRepository extends Repository<Person, Long> { ... }2. Declare the query method on the interface.
interface PersonRepository extends Repository<Person, Long> {
List<Person> findByLastname(String lastname);
}3. Set Spring to create proxy instances for these interfaces using JavaConfig or XML configuration.
a. To use Java configuration, create a class similar to the following:
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@EnableJpaRepositories
class Config { ... }b. To use XML configuration, define a bean similar to the following:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
https://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.acme.repositories"/>
</beans>The jpa namespace is used in this example. If you use the repository abstraction for any other storage, you need to change it to the appropriate namespace declaration for the enclosure. In other words, you should swap jpas, for example, mongodb. Also note that the JavaConfig variant does not explicitly configure the package because the package of annotated classes is used by default. To customize the packages to scan, use one of the basePackage... Properties of - annotation for the repository specific to the data store@ Enable${store}Repositories
4. Inject the repository instance and use it, as shown in the following example:
class SomeClient {
private final PersonRepository repository;
SomeClient(PersonRepository repository) {
this.repository = repository;
}
void doSomething() {
List<Person> persons = repository.findByLastname("Matthews");
}
}3.3. Define repository interface
To define a Repository interface, you first need to define a domain class specific Repository interface. The interface must extend the Repository and enter the domain class and ID type. If you want to expose CRUD methods for this domain type, extend CrudRepository instead of Repository
7.3.1. Fine tuning repository definitions
Typically, your Repository interface extends Repository, CrudRepository, or PagingAndSortingRepository. Alternatively, if you don't want to extend the Spring Data interface, you can also use @ RepositoryDefinition Extending CrudRepository exposes a complete set of methods for operating entities. If you want to be selective about exposed methods, copy the methods to be exposed to the CrudRepository into your domain repository.
This allows you to define your own abstractions on top of the Spring Data Repositories functionality provided.
The following example shows how to selectively expose CRUD methods (findById and save in this case):
Example 17 The CRUD method is selectively disclosed
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends Repository<T, ID> {
Optional<T> findById(ID id);
<S extends T> S save(S entity);
}
interface UserRepository extends MyBaseRepository<User, Long> {
User findByEmailAddress(EmailAddress emailAddress);
}In the previous example, you defined a common basic interface for all domain repositories and exposed findById(...) and save(...) methods. These methods are routed to the basic repository implementation of the repository of your choice provided by Spring Data (for example, if you use JPA, the implementation is SimpleJpaRepository), because they are different from CrudRepository So the UserRepository can now save Users, find individual Users by ID, and trigger a query to find Users by e-mail address.
The intermediate repository interface uses @ NoRepositoryBean Make sure to add this comment to all repository interfaces for which Spring Data should not create an instance at run time.
7.3.2. Use the repository with multiple Spring data modules
Using a unique Spring Data module in an application makes things easier because all repository interfaces within the scope of the definition are bound to the Spring Data module. Sometimes, applications need to use multiple Spring Data modules. In this case, the repository definition must distinguish between persistence technologies. When multiple repository factories are detected on the classpath, Spring Data enters a strict repository configuration mode. Strict configuration uses the details of the repository or domain class to determine the Spring Data module binding defined by the repository:
- If the repository definition extends a module specific repository, it is a valid candidate for a specific Spring Data module.
- If a domain class is annotated with module specific type annotations, it is a valid candidate for a specific Spring Data module. The Spring Data module accepts third-party annotations (such as JPA's @Entity) or provides its own annotations (such as @ DocumentSpring Data MongoDB and Spring Data Elasticsearch).
The following example shows a repository using a module specific interface (JPA in this case):
Example 18 Repository definitions using module specific interfaces
interface MyRepository extends JpaRepository<User, Long> { }
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends JpaRepository<T, ID> { ... }
interface UserRepository extends MyBaseRepository<User, Long> { ... }MyRepository and extend UserRepository in their type hierarchy. They are valid candidates for the Spring Data JPA module.
The following example shows a repository using a common interface:
Example 19 Repository definitions using common interfaces
interface AmbiguousRepository extends Repository<User, Long> { ... }
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends CrudRepository<T, ID> { ... }
interface AmbiguousUserRepository extends MyBaseRepository<User, Long> { ... }AmbiguousRepository and extends AmbiguousUserRepository only in its type hierarchy. Although this is good when using a unique Spring Data module, multiple modules cannot distinguish which specific Spring Data repositories should be bound to. RepositoryCrudRepository
The following example shows a repository that uses annotated domain classes:
Example 20 Repository definitions using annotated domain classes
interface PersonRepository extends Repository<Person, Long> { ... }
@Entity
class Person { ... }
interface UserRepository extends Repository<User, Long> { ... }
@Document
class User { ... }Personrepository references, using JPA@Entity Annotation, so this repository obviously belongs to Spring Data JPA. Userrepository references user, annotate @ Document with the annotation of Spring Data MongoDB.
The following error example shows a repository that uses domain classes with mixed annotations:
Example 21 Repository definitions using domain classes with mixed annotations
interface JpaPersonRepository extends Repository<Person, Long> { ... }
interface MongoDBPersonRepository extends Repository<Person, Long> { ... }
@Entity
@Document
class Person { ... }This example shows a domain class annotated with JPA and Spring Data MongoDB. It defines two repositories, JPA person repository and MongoDBPersonRepository One for JPA and the other for MongoDB. Spring Data can no longer distinguish between repositories, which leads to undefined behavior.
Repository type details and domain specific class annotations are used for strict repository configuration to identify repository candidates for specific spring data modules. It is possible to use multiple Persistence technology specific annotations on the same domain type, and domain types can be reused across multiple persistence technologies. The first mock exam of the binding repository is not yet possible by Spring Data.
The last way to differentiate a repository is to determine the scope of the repository base package. The base package defines the starting point for scanning the repository interface definition, which means putting the repository definition in the appropriate package. By default, annotation driven configuration uses the package of configuration classes. A base package in an XML based configuration is required.
The following example shows the annotation driven configuration of the base package:
Example 22 Annotation driven configuration of base package
@EnableJpaRepositories(basePackages = "com.acme.repositories.jpa")
@EnableMongoRepositories(basePackages = "com.acme.repositories.mongo")
class Configuration { ... }