1, eureka use
https://www.cnblogs.com/yxth/p/10845640.html
Access address: http://127.0.0.1:8761/
2, Chaos monkey spring boot
1. What is the goal of chaos monkey
Inspired by the principles of chaos engineering and the distributed system based on springboot, I want to test and know the best performance of the application, especially the use of the production environment.
Although many unit tests and integration tests have been written, and the coverage can reach 70% to 80%, I still feel that the tests are insufficient. What is the behavior of our program in the production environment?
Many questions are unanswered:
Is our emergency plan effective?
What is the behavior of our application when the network is unstable?
What if one of the services hangs up?
Service discovery is normal, but does our client load balancing work?
As you said, we still have many problems and topics to deal with.
Because of this, we went deep into the chaos project and opened a project area to share our ideas and experiences.
How to use:
See: https://codecentric.github.io/chaos-monkey-spring-boot/2.3.0/
give an example:
pom.xml
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>chaos-monkey-spring-boot</artifactId>
<version>2.0.0</version>
</dependency>application.properties
spring.profiles.active=chaos-monkey chaos.monkey.enabled=true
chaos.monkey.enabled is an optional configuration that you can modify when the service is running.
Spring Boot Actuator Endpoints
Chaos monkey spring boot provides interface access through jmx and http
application.properties:
management.endpoint.chaosmonkey.enabled=true management.endpoint.chaosmonkeyjmx.enabled=true # inlcude all endpoints management.endpoints.web.exposure.include=* # include specific endpoints management.endpoints.web.exposure.include=health,info,chaosmonkey
Detailed interface
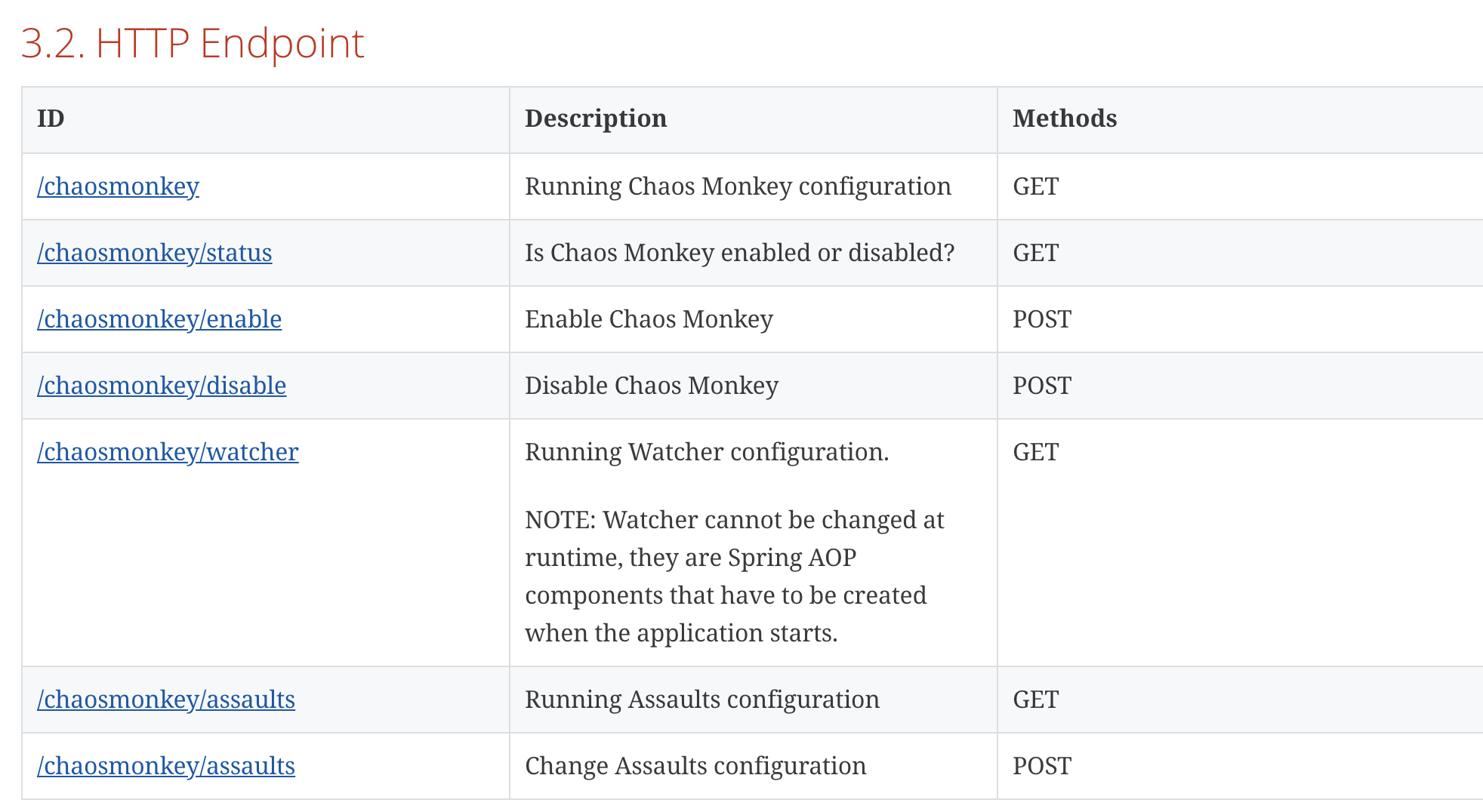
View interface http://127.0.0.1:8080/actuator ; Find the chaomonkey interface entry (there is a pit here. According to the interface document, I don't know that the entry is under / actor)
{
"_links": {
"self": {
"href": "http://127.0.0.1:8080/actuator",
"templated": false
},
"health-component": {
"href": "http://127.0.0.1:8080/actuator/health/{component}",
"templated": true
},
"health-component-instance": {
"href": "http://127.0.0.1:8080/actuator/health/{component}/{instance}",
"templated": true
},
"health": {
"href": "http://127.0.0.1:8080/actuator/health",
"templated": false
},
"info": {
"href": "http://127.0.0.1:8080/actuator/info",
"templated": false
},
"chaosmonkey": {
"href": "http://127.0.0.1:8080/actuator/chaosmonkey",
"templated": false
}
}
}There are detailed instructions in the official documents, which only describe the use of specific scenarios:
First, chaos monkey spring boot only supports the following spring boot annotation listening; Realized by spring aop, it can only recognize the pulbic method and does not perform any action or launch one of the attacks; These attacks support automation.
@Controller @RestController @Service @Repository @Component
Notes for setting listening: (for example, listening controller and restController)
Set via interface /actuator/chaosmonkey/watchers
{
"controller": true,
"restController": true,
"service": false,
"repository": false,
"component": false
}
1. Latency attack
Request to add random delay
Set / Actor / chaosmonkey / defaults through the interface
{
"level": 5,
"latencyRangeStart": 2000,
"latencyRangeEnd": 5000,
"latencyActive": true,
"watchedCustomServices": [ "xxx.TestController.getV2"]
}
feign configuration timeout:
#connection timed out feign.client.config.default.connectTimeout=1000 #Read timeout feign.client.config.default.readTimeout=2000 #The number of retries for the current instance is 0 by default. Note that the user-defined FeignApiBuilder should add retries by itself ribbon.MaxAutoRetries=0 #The number of retries for switching instances. The default is 1 ribbon.MaxAutoRetriesNextServer=0
2. Exception attack
Throw exception randomly
{
"level": 5,
"latencyActive": false,
"exceptionsActive": true,
"watchedCustomServices": [ "xxx.TestController.getV2"],
"exception": {
"type": "java.lang.IllegalArgumentException",
"arguments": [{
"className": "java.lang.String",
"value": "custom illegal argument exception"}] }
}3. AppKiller Assault (kill application attack)
You can schedule Chaos Monkey Runtime Assaults (Memory, AppKiller) using cron expressions.
{
"level": 5,
"killApplicationActive": true,
"runtimeAssaultCronExpression": "*/1 * * * * ?"
}4. Memory attack
To be added
Documentation:
Chaos monkey spring boot official user manual
https://codecentric.github.io/chaos-monkey-spring-boot/2.3.0
Chaos monkey spring boot kill application and memory growth methods must use cron expressions
You can schedule Chaos Monkey Runtime Assaults (Memory, AppKiller) using cron expressions.
https://codecentric.github.io/chaos-monkey-spring-boot/2.3.0/#_chaos_monkey_assault_scheduler
3, Service fault tolerance (current limiting, fusing and degradation)
Background: in the field of high concurrency, in distributed systems, small functions may not be available due to pressure, such as timeout and error reporting; This leads to timeout and error reporting of other services, and the final effect is that the whole system is unavailable. The impact of this situation is too large. In a small part of the time, the user experience is poor and can not provide normal use. In a serious way, it will lead to serious economic losses of the company.
Objective: from the perspective of service availability and reliability, taking the distributed system as an example, to prevent the overall slowness and collapse of the system due to a small part of abnormal functions; How to avoid this problem technically, the industry has adopted the solution of fusing and degradation.
Technical reasons: complex distributed architectures usually have a lot of dependencies. When an application is highly coupled with other services, it is very easy to fail. This failure not only hurts the service callers, but also leads to the wrong connection one by one, and the application itself is at risk of being dragged down; In a high traffic system, the delay of a certain back-end service will lead to the consumption of all system resources in a few seconds. A large number of calls to microservices may block the thread pool of remote services due to slow requests. If the thread pool is not isolated from the thread pool of application services, the whole service will hang up.
Technical solution: hystrix is officially described as a delay and fault-tolerant library, which aims to isolate remote systems, services and third-party libraries, prevent cascading failures and realize recovery capability in complex systems. Hystrix uses its own thread pool and application thread pool for isolation. If the call takes too long, it will stop calling. Different request tasks and task groups configure their respective thread pools to isolate different services.
Hystrix fuse degradation effect:
a. For the user experience, some functions are temporarily inaccessible and unavailable.
b. The granularity of the control is a service. The fuse is automatically triggered based on the strategy. The degradation can be manually intervened, but it is obviously unreliable to rely on manual intervention. The scientific way is to configure through the switch preset and configuration center.
c. Degradation starts with peripheral services and is handled on a framework, which is required for each service.
Basic fault tolerance mode
1. Active timeout: Http requests to actively set a timeout, and the timeout will be returned directly without causing service accumulation
2. Current limit: limit the maximum concurrent number
3. Fusing: when the number of errors exceeds the threshold, it fails quickly and does not call the back-end service. At the same time, it puts several requests at a certain time to try whether the back-end service can be called normally. If it succeeds, it turns off the fusing state. If it fails, it continues to fail quickly and returns directly. (there is a retry here, which is the ability of elastic recovery)
4. Isolation: isolate each dependent or invoked service to prevent overall service unavailability caused by cascading failure
5. Degradation: return the specified default information after service failure or exception
Flowchart of Hystrix fault tolerance: (in case of fusing, timeout, exception, thread pool / queue / semaphore full, it will be degraded, and the operation error timeout will be fed back to Calculate Circuit Health to judge whether the fusing is triggered)
Official documents: https://github.com/Netflix/Hystrix/wiki
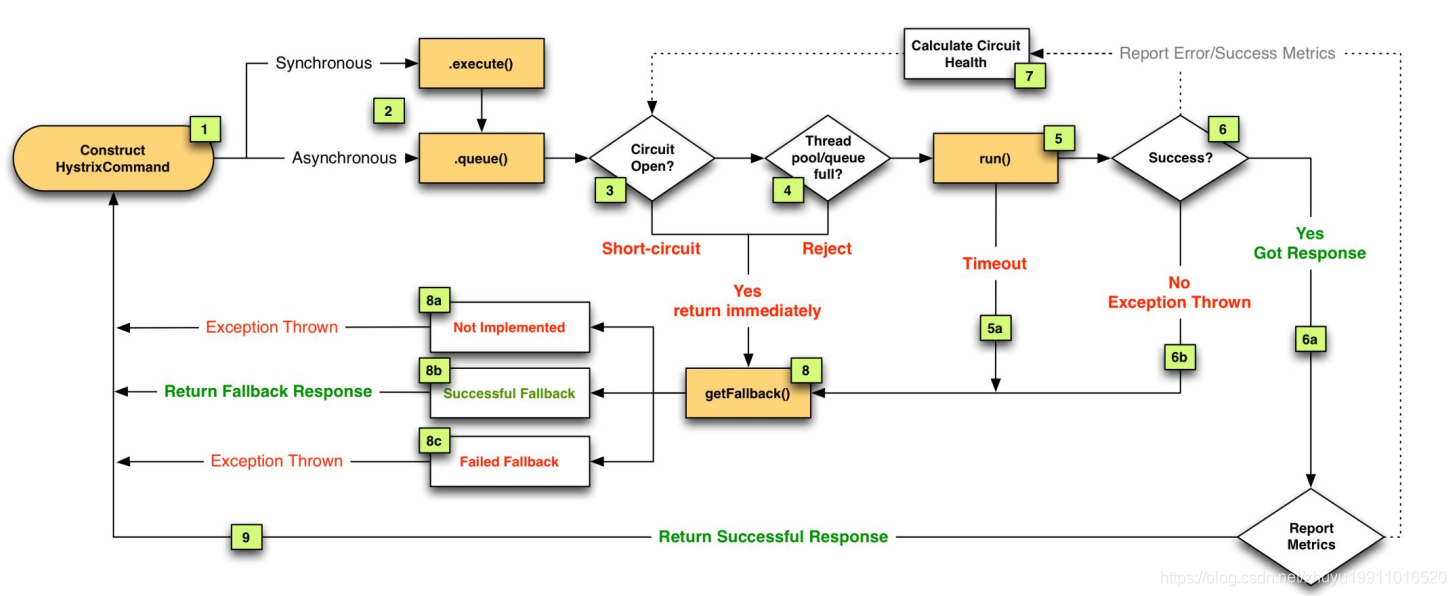
There are 9 steps above, and each step is explained below:
1. Each request will be encapsulated in HystrixCommand
2. The request will be called synchronously or asynchronously
3. Judge whether the fuse is open. If it is open, it will directly jump to 8 for degradation
4. Judge whether the thread pool / queue / semaphore is full. If it is full, enter step 8 of degradation
5. If there is no previous error, call the run method to run the dependency logic
5. The running method may time out. After the timeout, it will be degraded from 5a to 8
6. In case of any abnormality during operation, it will be degraded from 6b to 8
6. If the operation is normal, it will enter 6a, return to normal, and tell 7 (Calculate Circuit Health) of the error or normal call result
7.Calculate Circuit Health is the brain of Hystrix. Whether to fuse is calculated by the number of errors and successful calls
8. Degradation method (8a does not realize degradation, 8b realizes degradation and runs successfully, 8c realizes degradation method, but there are exceptions)
8a. The degradation method is not implemented, and the exception information is returned directly
8b. If the downgrade method is implemented and the downgrade method runs successfully, the default information after downgrade will be returned
8c. If the method goes back, the degraded information may also occur, but the implementation may return exceptions
Fusing concept:
All dependencies can fail
All resources are limited (cpu, memory, IO and thread pool)
Unreliable network
Delay is the biggest killer of application (delay leads to the collapse of the whole microservice. Set a timeout for the service to solve the problem caused by delay)
1. Business feign timeout configuration (Note: it is applicable to the case defined by Feign.Builder)
Case 1:
feign.Feign.Builder sets the default value; The code is required to modify the default parameters
feign.Feign.Builder
public Builder() {
this.logLevel = Level.NONE;
this.contract = new Default();
this.client = new feign.Client.Default((SSLSocketFactory)null, (HostnameVerifier)null);
this.retryer = new feign.Retryer.Default();
this.logger = new NoOpLogger();
this.encoder = new feign.codec.Encoder.Default();
this.decoder = new feign.codec.Decoder.Default();
this.queryMapEncoder = new feign.QueryMapEncoder.Default();
this.errorDecoder = new feign.codec.ErrorDecoder.Default();
this.options = new Options();
this.invocationHandlerFactory = new feign.InvocationHandlerFactory.Default();
this.closeAfterDecode = true;
}
feign.Request.Options#Options()
public Options() {
this(10000, 60000);
}Situation 2: org springframework. cloud. netflix. feign. ribbon. FeignLoadBalancer. Feign. In execute() Options is the default configuration
public FeignLoadBalancer.RibbonResponse execute(FeignLoadBalancer.RibbonRequest request, IClientConfig configOverride) throws IOException {
Options options;
if (configOverride != null) {
RibbonProperties override = RibbonProperties.from(configOverride);
options = new Options(override.connectTimeout(this.connectTimeout), override.readTimeout(this.readTimeout));
} else {
options = new Options(this.connectTimeout, this.readTimeout);
}
Response response = request.client().execute(request.toRequest(), options);
return new FeignLoadBalancer.RibbonResponse(request.getUri(), response);
}public static class Options {
private final int connectTimeoutMillis;
private final int readTimeoutMillis;
private final boolean followRedirects;
public Options(int connectTimeoutMillis, int readTimeoutMillis, boolean followRedirects) {
this.connectTimeoutMillis = connectTimeoutMillis;
this.readTimeoutMillis = readTimeoutMillis;
this.followRedirects = followRedirects;
}
public Options(int connectTimeoutMillis, int readTimeoutMillis) {
this(connectTimeoutMillis, readTimeoutMillis, true);
}
public Options() {
this(10000, 60000);
}
public int connectTimeoutMillis() {
return this.connectTimeoutMillis;
}
public int readTimeoutMillis() {
return this.readTimeoutMillis;
}
public boolean isFollowRedirects() {
return this.followRedirects;
}
}Solution:
https://github.com/spring-cloud/spring-cloud-netflix/issues/696
https://blog.csdn.net/varyall/article/details/105282678
#connection timed out feign.client.config.default.connectTimeout=1000 #Read timeout feign.client.config.default.readTimeout=2000
https://www.pianshen.com/article/187038775/
ribbon: OkToRetryOnAllOperations: false #Retry all operation requests. The default is false ReadTimeout: 2000 #Load balancing timeout, default value 5000 ConnectTimeout: 1000 #Timeout time of ribbon request for connection. The default value is 2000 MaxAutoRetries: 0 #The number of retries for the current instance. The default is 0 MaxAutoRetriesNextServer: 1 #The number of retries for switching instances. The default is 1
ribbon.MaxAutoRetries=0
ribbon.MaxAutoRetriesNextServer=0
Set retry times:
feign. Feign. This. Of builder # retryer = new feign. Retryer. Default(); The default number of retries is set, and the feign instantiation code needs to be modified.
Modify the value of maxAttempts
feign.Feign.Builder#Builder
public Builder() {
this.logLevel = Level.NONE;
this.contract = new Default();
this.client = new feign.Client.Default((SSLSocketFactory)null, (HostnameVerifier)null);
this.retryer = new feign.Retryer.Default();
this.logger = new NoOpLogger();
this.encoder = new feign.codec.Encoder.Default();
this.decoder = new feign.codec.Decoder.Default();
this.queryMapEncoder = new feign.QueryMapEncoder.Default();
this.errorDecoder = new feign.codec.ErrorDecoder.Default();
this.options = new Options();
this.invocationHandlerFactory = new feign.InvocationHandlerFactory.Default();
this.closeAfterDecode = true;
}Modify the code (perfect solution after testing):
@Bean
@Autowired
public FeignApiBuilder feignApiBuilder(Decoder decoder, Encoder encoder, Client client,
Contract contract, Optional<List<RequestInterceptor>> requestInterceptors) {
Request.Options options = new Request.Options(connectTimeout, readTimeout);
Retryer retryer = new Retryer.Default(100L, TimeUnit.SECONDS.toMillis(1L), maxAutoRetries);
return new FeignApiBuilder(decoder, encoder, client, contract, requestInterceptors.orElse(null), options, retryer);
}
2. feign + Hystrix fuse configuration (using @ FeignClient annotation)
The premise feign is to use @ FeignClient annotation for service invocation
Access Description:
SpringBootApplication startup:
@EnableCircuitBreaker
Profile:
feign.hystrix.enabled=true
feign configuration
feign.client.config.default.connectTimeout=1000
feign.client.config.default.readTimeout=2000
Dependency:
compile('org.springframework.cloud:spring-cloud-starter-netflix-hystrix')
Call third-party services
@RestController
public class InfoController {
@Autowired
private InfoApi infoApi;
@GetMapping(value = "/service-a/getV2Test")
public Response getV2Test() {
return infoApi.getV2Test();
}
}Call FeignClient, a third-party service, to instantiate InfoApi:
@FeignClient(name = "service-b", qualifier = "serviceB", fallback = InfoApiFallback.class)
public interface InfoApi {
@GetMapping(value = "/service-b/getV2Test")
Response getV2Test();
}@Component
public class InfoApiFallback implements InfoApi {
@Override
public Response getV2Test() {
return Response.fail(-1,"Trigger fuse");
}
}Pit 1:
Error reason:
SpringMvc found that the RequestMapping was repeated during mapping
Caused by: java.lang.IllegalStateException: Ambiguous mapping. Cannot map 'com.thoughtworks.demo.consumer.service.ConsumerFeignService' method
Solution:
Remove @ RequestMapping from feign interface
Pit II. Closed by default
feign: hystrix: enabled: true
Pit 3: HystrixCommand cannot be used in method
https://github.com/Netflix/Hystrix/issues/1458
Data list:
feign fused pit: https://www.jb51.net/article/138758.htm
feign uses Hystrix: https://www.cnblogs.com/linjiqin/p/10195442.html
Explanation of springcloud hystrix: https://blog.csdn.net/mamamalululu00000000/article/details/105188914
threadPoolKey default value and thread pool initialization of springcloud HystrixCommand: https://www.cnblogs.com/trust-freedom/p/9956427.html
Hystrix quick start: https://www.cnblogs.com/xiong2ge/p/hystrix_faststudy.html
4, Example execution effect:
Demo source code: https://gitee.com/kekefish/feign-hystrix-chaos-monkey-demo.git
| modular | describe |
| service-a | Service a |
| service-b | Service b |
| service-b-api | Service B defines the interface feign and callback |
| eureka-server | Registration Center |
Calling relationship: Service-A - > service-b
Pressure measuring interface: http://127.0.0.1:8080/service-a/getV2Test
Configure chaos monkey timeout
http://127.0.0.1:8081/actuator/chaosmonkey/assaults
"latencyRangeStart": 5000,
"latencyRangeEnd": 10000,
"latencyActive": true,
postman script: https://download.csdn.net/download/kekefisht/16810627
It can be seen from the jmeter voltage measurement result that the trigger is blown:
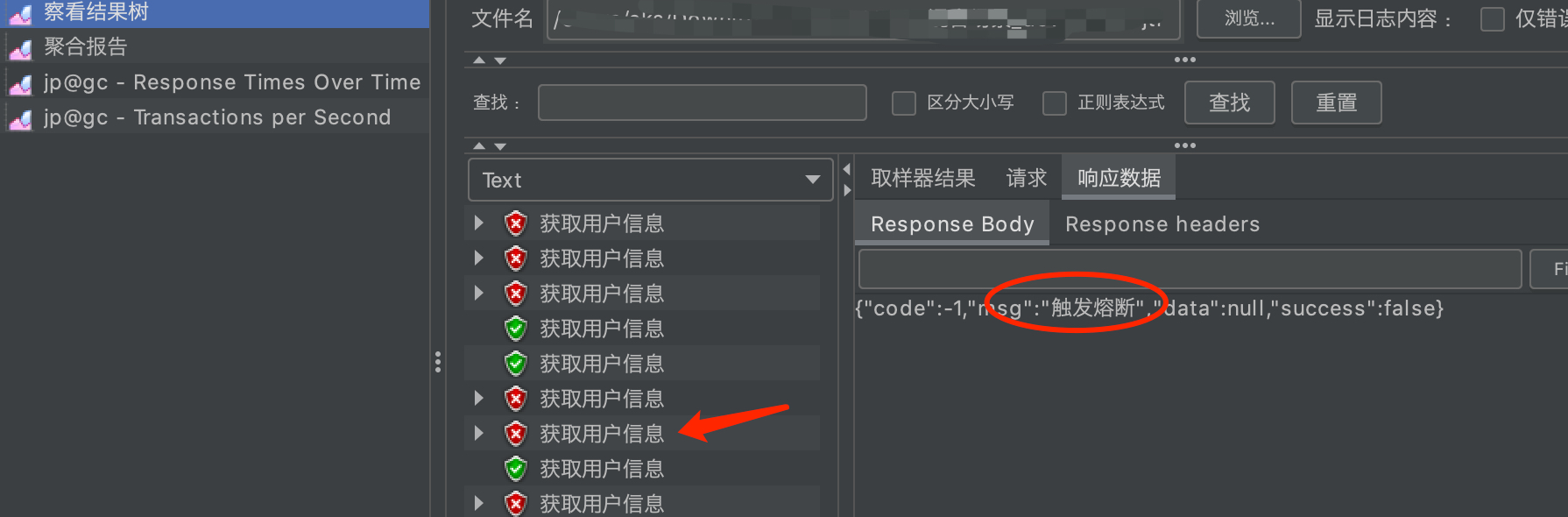
jmeter steps: https://download.csdn.net/download/kekefisht/16810607