catalogue
Under what circumstances can circular dependencies be handled?
Basic introduction and the essence of circular dependency
what? The essence of the problem is actually two sum!
How to get to getSingleton method
Simple circular dependency (no AOP)
Call getSingleton(beanName, singletonFactory)
Call the addSingletonFactory method
Combined with the circular dependency of AOP
Does L3 caching really improve efficiency?
Note: This article refers to
Interview must kill skill: talk about circular dependency in Spring
Cousin let me talk: Spring circular dependency
The female colleague asked Ao Bing what is Spring circular dependency? I...
Spring circular dependency
What is circular dependency?
Literally, A depends on B, while B also depends on A, as shown below

This is what it looks like at the code level
@Component
public class A {
// B is injected into A
@Autowired
private B b;
}
@Component
public class B {
// A is also injected into B
@Autowired
private A a;
}
Of course, this is the most common kind of circular dependency, and there are some special ones
// Rely on yourself
@Component
public class A {
// A is injected into a
@Autowired
private A a;
}Although the forms are different, they are actually the same problem - > circular dependency
Under what circumstances can circular dependencies be handled?
Before answering this question, it should be clear that Spring has preconditions for solving circular dependencies
1. The Bean with cyclic dependency must be a singleton
2. The dependency injection method cannot be all constructor injection (many blogs say that it can only solve the circular dependency of setter method, which is wrong)
The first point should be well understood. The second point: what does it mean not to be all constructor injection? Let's still talk in code
@Component
public class A {
// @Autowired
// private B b;
public A(B b) {
}
}
@Component
public class B {
// @Autowired
// private A a;
public B(A a){
}
}In the above example, the way to inject B into A is through the constructor, and the way to inject A into B is also through the constructor. At this time, the circular dependency cannot be solved. If there are two such interdependent beans in your project, the following error will be reported during startup:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
In order to test the relationship between the solution of circular dependency and the injection method, we do the following four tests
| Dependency | Dependency injection mode | Are circular dependencies resolved |
|---|---|---|
| AB interdependence (cyclic dependence) | setter method is used for injection | yes |
| AB interdependence (cyclic dependence) | All are injected by constructor | no |
| AB interdependence (cyclic dependence) | The method of injecting B into A is setter method, and the method of injecting A into B is constructor | yes |
| AB interdependence (cyclic dependence) | The method of injecting A into B is setter method, and the method of injecting B into A is constructor | no |
Fourth reference

In this case, Spring will create beans according to natural order, and A will create beans before B
It is not only in the case of setter method injection that the circular dependency can be solved. Even in the case of constructor injection, the circular dependency can still be handled normally.
So why? How does Spring deal with circular dependencies? Don't worry, let's keep looking down
Introduction to the essence and cycle of dependence
First, Spring internally maintains three maps, which are commonly referred to as the three-level cache.
Looking through the Spring documentation, I didn't find the concept of three-level cache, which may also be a local vocabulary for ease of understanding.
In the DefaultSingletonBeanRegistry class of Spring, you will find these three maps hanging above the class:
singletonObjects is our most familiar friend, commonly known as "Singleton pool" and "container". It is the place where the cache creates the singleton Bean.
singletonFactories map the original factory that created the Bean
earlySingletonObjects is the early reference of mapping Bean, that is to say, the Bean in this Map is not complete, it can't even be called "Bean", it's just an Instance
The last two maps are actually at the "stepping stone" level, but they are used for help when creating beans, and are cleared after creation.
Therefore, I was confused about the word "L3 cache" in the previous article, probably because the comments start with Cache of.
Why become the last two maps as stepping stones? Suppose the Bean finally placed in singletonObjects is a cup of "cool and white" you want.
Then Spring prepared two cups, singleton factories and earlySingletonObjects, to "toss" back and forth several times, and put the hot water in the singleton objects in a "cool and white" way.
No gossip, all concentrated in the picture.

After understanding how Spring handles circular dependencies, let's jump out of the thinking of "reading the source code". Suppose you were asked to implement a function with the following characteristics, what would you do?
Take some specified class instances as singletons
The fields in the class are also singletons
Support circular dependency
For example, suppose there is class A:
public class A {
private B b;
}
class B:
public class B {
private A a;
}To put it bluntly, let you imitate Spring: pretend that A and B are decorated by @ Component,
And the fields in the class pretend to be decorated with @ Autowired, and put them into the Map after processing.
In fact, it is very simple. I wrote a rough code for reference:
/**
* Place the created bean Map
*/
private static Map<String, Object> cacheMap = new HashMap<>(2);
public static void main(String[] args) {
// Fake scanned objects
Class[] classes = {A.class, B.class};
// Pretend project initialization instantiates all bean s
for (Class aClass : classes) {
getBean(aClass);
}
// check
System.out.println(getBean(B.class).getA() == getBean(A.class));
System.out.println(getBean(A.class).getB() == getBean(B.class));
}
@SneakyThrows
private static <T> T getBean(Class<T> beanClass) {
// In this paper, the naming rules of bean s are simply replaced by lowercase class names
String beanName = beanClass.getSimpleName().toLowerCase();
// If it is already a bean, it will be returned directly
if (cacheMap.containsKey(beanName)) {
return (T) cacheMap.get(beanName);
}
// Instantiate the object itself
Object object = beanClass.getDeclaredConstructor().newInstance();
// Put in cache
cacheMap.put(beanName, object);
// Treat all fields as beans to be injected, and create and inject them into the current bean
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
// Get the class of the field to be injected
Class<?> fieldClass = field.getType();
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
// If the bean to be injected is already in the cache Map, inject the value in the cache Map into the field
// If the cache does not continue to be created
field.set(object, cacheMap.containsKey(fieldBeanName)
? cacheMap.get(fieldBeanName) : getBean(fieldClass));
}
// Property filling is completed, return
return (T) object;
}The effect of this code is to handle the circular dependency, and after the processing is completed, the complete "Bean" will be placed in the cacheMap
This is the essence of "circular dependency", not "how Spring solves circular dependency".
The reason to give this example is to find that a small number of basin friends have fallen into the "quagmire of reading source code" and forgot the essence of the problem.
Looking at the source code in order to see the source code, I can't understand it all the time, but I forget what the essence is.
If you really don't understand it, it's better to write the basic version first and push back why Spring should be implemented in this way. The effect may be better.
what? The essence of the problem is actually two sum!
After reading the code just now, do you have deja vu? Yes, it is similar to the problem solving of two sum.
I don't know what the stem of two sum is. Let me introduce it to you:
two sum is the question with No. 1 of leetcode on the website, which is the first question for most people to get started with the algorithm.
Often ridiculed by people, the company with algorithmic face was appointed by the interviewer and came together. Let's go for a walk with two sum.
The content of the problem is: give an array and a number. Returns two indexes in the array that can be added to get the specified number.
For example: given num = [2, 7, 11, 15], target = 9
Then return [0, 1], because 2 + 7 = 9
The optimal solution of this problem is to traverse + HashMap at one time:
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
map.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
}First go to the Map to find the required number. If not, save the current number in the Map. If you find the required number, return it together.
Is it the same as the code above?
First find the Bean in the cache. If not, instantiate the current Bean and put it into the Map. If you need to rely on the current Bean, you can get it from the Map.
How to get to getSingleton method
There is a key method refresh() in spring IOC, which contains 13 core sub methods. Students who don't know about it can review the spring IOC startup process mentioned earlier.
Among the 13 sub methods, there is a finishBeanFactoryInitialization(beanFactory); Initialize the remaining single instance (non lazy loaded) methods. This is the entrance
public void refresh() throws BeansException, IllegalStateException {
// Add a synchronized to prevent refresh. Other operations (start or destroy) have not been completed yet
synchronized (this.startupShutdownMonitor) {
// 1. Preparation
// Record the start-up time of the container
// Mark the "started" status, and the closed status is false
// Load the current system properties into the environment object
// Prepare a series of listeners and event collection objects
prepareRefresh();
// 2. Create a container object: DefaultListableBeanFactory, which loads the attributes of the XML configuration file into the current factory (parsed by namespace by default), that is, the BeanDefinition (bean definition information) mentioned above has not been initialized here, but the configuration information has been extracted (the value value contained in it is actually just a placeholder)
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 3. Preparation of BeanFactory, setting the class loader of BeanFactory, adding several beanpostprocessors, manually registering several special beans, etc
prepareBeanFactory(beanFactory);
try {
// 4. The coverage methods of subclasses do additional processing, that is, the beanfactoryprocessor we just mentioned at the beginning. For specific subclasses, you can add some special beanfactoryprocessor to modify or extend beanFactory at this step.
// When we get here, all beans have been loaded and registered, but they have not yet been initialized
postProcessBeanFactory(beanFactory);
// 5. Call the postProcessBeanFactory(factory) method of each implementation class of beanfactoryprocessor
invokeBeanFactoryPostProcessors(beanFactory);
// 6. Register the BeanPostProcessor processor. Here is only the registration function. The real call is the getBean method
registerBeanPostProcessors(beanFactory);
// 7. Initialize the MessageSource of the current ApplicationContext, that is, internationalization processing
initMessageSource();
// 8. Initialize the event broadcaster of the current ApplicationContext,
initApplicationEventMulticaster();
// 9. From the name of the method, you can know that the typical template method (hook method), interested students can also review the template method mode in the design mode written before
// Specific subclasses can initialize some special beans here (before initializing singleton beans)
onRefresh();
// 10. Register the event listener. The listener needs to implement the ApplicationListener interface. This is not our focus, too
registerListeners();
// 11. Initialize all singleton beans (except lazy init), and focus on
finishBeanFactoryInitialization(beanFactory);
// 12. Broadcast events, ApplicationContext initialization completed
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// 13. Destroy the initialized singleton Beans to prevent some Beans from occupying resources all the time
destroyBeans();
cancelRefresh(ex);
// Throw the anomaly out
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}1. Because IOC is the container of Spring, and the default is singleton, we will go to getBean before creating bean s to judge whether there is one at present. When there is no one, we will create it.
So go to the finishBeanFactoryInitialization method and find beanfactory preInstantiateSingletons();
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// Omit other interference codes (judgment logic)...
// Instantiate all remaining (non-lazy-init) singletons.
// Instantiate all the remaining singleton objects (not lazily loaded)
beanFactory.preInstantiateSingletons();
}When you enter the preInstantiateSingletons method, you can see that the bean information to be created is determined by bean definitionnames (bean definition information), so you start the creation process through the bean name loop.
Because we will create the most common instance of getan bean (so we will go to the bottom); Method, as shown in the following code
@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// Determine whether it is a factory bean
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
// If the bean corresponding to the current beanName is not a factory bean, obtain the bean instance through beanName
getBean(beanName);
}
}
}
}Enter the getBean(beanName); There is a doGetBean method in the method. In the Spring source code, those who really start to work and do things will be prefixed with the do method.
@Override
public Object getBean(String name) throws BeansException {
// Method of getting dependency, method of actually triggering injection
return doGetBean(name, null, null, false);
}
Therefore, in the doGetBean method, you will still get one by default. If not, you will start to create the createBean(beanName, mbd, args) method
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
final String beanName = transformedBeanName(name);
Object bean;
// Eagerly check singleton cache for manually registered singletons.
// Confirm whether the current bean instance already exists in the container
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
if (logger.isTraceEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.trace("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.trace("Returning cached instance of singleton bean '" + beanName + "'");
}
}
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
// Omit other logical codes...
// Create bean instance.
// Create an instance object of the Bean
if (mbd.isSingleton()) {
// Return the singleton object with beanName. If it is not registered, use singletonFactory to create and register one.
sharedInstance = getSingleton(beanName, () -> {
try {
// Create an instance of a Bean for a given BeanDefinition (and parameters)
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// Omit other logical codes...
return (T) bean;
}When the bean is not obtained above, the bean creation starts, so go directly to the createBean method. Because the container is initialized and started, it must not be. Gu will enter the createBean method, so go to the createBean method again.
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// Omit other relevant codes.....
try {
// Call focus of actually creating Bean
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isTraceEnabled()) {
logger.trace("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) {
// A previously detected exception with proper bean creation context already,
// or illegal singleton state to be communicated up to DefaultSingletonBeanRegistry.
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex);
}
}When you see the doCreateBean method, it means that you are about to start creating a real Bean.
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// Judge that if it is a singleton object, remove the definition information of the current Bean from the factoryBean instance cache summary
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// Create a new instance according to the corresponding policy used by the executed bean. You can also understand that instantiating objects always opens up space in memory
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Omit other relevant codes.....
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// Judge whether the current bean needs to be exposed in advance. Singleton & allow circular dependency & the current bean is being created. Detect circular dependency
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// Before the initialization of the bean is completed, the created instance is added to the ObjectFactory (adding a three-level cache), mainly to prevent cyclic dependency in the later stage.... a key
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
try {
// Fill in bean properties. Assuming that there are properties that depend on other beans, the dependent beans will be recursively initialized
populateBean(beanName, mbd, instanceWrapper);
//Execute initialization logic
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
return exposedObject;
}
When entering the doCreateBean, the first method you need to focus on is createBeanInstance. This method is the real example of creating a bean instance, that is, opening up space (instantiation) in memory. After that, you can start to focus on adding cache
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
Click this method to find that it can be added to the third level cache. The value value is a function method getEarlyBeanReference. Unfamiliar students can see jdk1 8 new features. It also indicates that the current bean is being registered.
After instantiating the bean, according to the bean life cycle process, it must be the beginning of initializing the bean, filling in the properties, and then looking down, there is a populateBean (filling in the bean properties)
populateBean(beanName, mbd, instanceWrapper);
There is a lot of logic in the process of populateBean, such as obtaining attribute name, attribute value and a series of operations. However, the core is to see the property assignment of the applyPropertyValues method, as shown below:
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
// Omit a bunch of other judgment verification logic codes and directly see the last...
if (pvs != null) {
// Apply the given property value to solve the call of other beans (that is, set the property value) when the bean factory runs
applyPropertyValues(beanName, mbd, bw, pvs);
}
}Similarly, enter the applyPropertyValues method.
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
// Omit some other verification codes.....
// Create a deep copy, resolving any references for values.
List<PropertyValue> deepCopy = new ArrayList<>(original.size());
boolean resolveNecessary = false;
// Convenience attribute, which converts the attribute to the corresponding attribute type of the corresponding class
for (PropertyValue pv : original) {
// Judge whether the current attribute has been resolved
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
// Get attribute layer
String propertyName = pv.getName();
// Get property value
Object originalValue = pv.getValue();
// valueResolver deals with the object encapsulated by the originalValue parsed by pv (whether it is necessary to start dealing with the attribute value)
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
// By default, the converted value is equal to the parsed value
Object convertedValue = resolvedValue;
// Judge conversion mark
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
// Omit other code logic....
}
In the applyPropertyValues method, note that valueresolver Resolvevalueifnecessary value processor
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
This step is mainly to judge whether the attribute value needs to be processed, because the previous value value is the storage method interface method
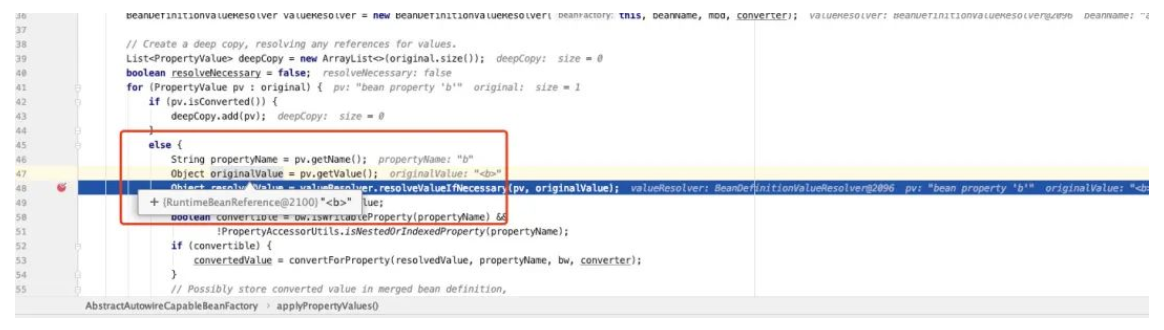
So we are executing valueresolver The resolvevalueifnecessary method must be handled. Let's see what logic is handled inside?
public Object resolveValueIfNecessary(Object argName, @Nullable Object value) {
// We must check each value to see whether it requires a runtime reference
// to another bean to be resolved.
// Processing if value is a RuntimeBeanReference instance
if (value instanceof RuntimeBeanReference) {
RuntimeBeanReference ref = (RuntimeBeanReference) value;
// Resolve the object of the Bean meta information (Bean name, Bean type) encapsulated by the corresponding ref
return resolveReference(argName, ref);
}
// Omit other logic codes
}The screenshot of the breakpoint on the surface can clearly see that the value value is the RuntimeBeanReference instance, so next, we will call the resolveReference method to parse the bean information encapsulated by ref, and then enter the resolveReference method to see what we have done?
@Nullable
private Object resolveReference(Object argName, RuntimeBeanReference ref) {
try {
Object bean;
String refName = ref.getBeanName();
refName = String.valueOf(doEvaluate(refName));
if (ref.isToParent()) {
if (this.beanFactory.getParentBeanFactory() == null) {
throw new BeanCreationException(
this.beanDefinition.getResourceDescription(), this.beanName,
"Can't resolve reference to bean '" + refName +
"' in parent factory: no parent factory available");
}
bean = this.beanFactory.getParentBeanFactory().getBean(refName);
}
else {
// Get the Bean object of resolvedName
bean = this.beanFactory.getBean(refName);
// Register the dependency between beanName and dependentBeanName in the Bean's work
this.beanFactory.registerDependentBean(refName, this.beanName);
}
if (bean instanceof NullBean) {
bean = null;
}
// Returns the Bean object encapsulated by the ref of the parsed pair
return bean;
}
catch (BeansException ex) {
throw new BeanCreationException(
this.beanDefinition.getResourceDescription(), this.beanName,
"Cannot resolve reference to bean '" + ref.getBeanName() + "' while setting " + argName, ex);
}
}The above has entered resolveReference to handle the Bean objects referenced in ref. since SpringIOC is a singleton Bean by default, it must still get the Bean in beanFactory
bean = this.beanFactory.getBean(refName);
At this point, the circular creation of circular dependent objects is started again. Assuming that it is still the first two objects A and B, when the A object is created at the beginning, there is no B attribute when setting the B attribute, so now it is just the beginning of creating the B attribute. The same B object starts filling in attribute A again.
Careful students should find the problem. Isn't this an infinite cycle? How to deal with the cycle? Isn't that bullshit?
In fact, it's not. In fact, when you want to create A B object, when you get the Bean information of A, because A is still being created, there will be A new discovery in the next process. Enter the cache to get the object, as shown below
bean = this.beanFactory.getBean(refName) -> doGetBean(name, null, null, false) -> sharedInstance = getSingleton(beanName) -> getSingleton(beanName, true)
// The specific point is the internal implementation of getSingleton method
// Enter the getSingleton method, issingletoncurrent yincreation. The current Bean is being created
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Get the singleton object corresponding to BeanName from the L1 cache
Object singletonObject = this.singletonObjects.get(beanName);
// If it is not obtained, but the singleton object corresponding to the current BeanName is being created
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// Get the singleton object corresponding to the current BeanName from the L2 cache
singletonObject = this.earlySingletonObjects.get(beanName);
// There is no in the L2 cache, but alloweerlyreference is true, which has been set in the doCreateBean method, so it is true here
if (singletonObject == null && allowEarlyReference) {
// Get from L3 cache
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// Here is the three-level cache function method, which creates a singleton object through Factory
singletonObject = singletonFactory.getObject();
// Add to L2 cache, semi-finished object
this.earlySingletonObjects.put(beanName, singletonObject);
// Delete L3 cache at the same time
this.singletonFactories.remove(beanName);
}
}
}
}
// Returns the current semi-finished product object
return singletonObject;
}Now an object of semi-finished product A has been stored in the L2 cache in the whole process. Therefore, when creating the B object, get the filling value of attribute A, and you can get the singleton Bean of object A from the container cache. For object B, it is actually A complete singleton Bean instance. Therefore, you will have A judgment when getSingleton Bean again, If there is A new completed singleton Bean, it will be added to the L1 cache. The source code is as follows:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
if (logger.isDebugEnabled()) {
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
}
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// Omit other code logic
//Judge that a new singleton object is generated
if (newSingleton) {
// Add BeanName and singletonObject to the L1 cache
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}As mentioned above, when a new singleton object is generated, the addSingleton method will be called again
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// Add to L1 cache
this.singletonObjects.put(beanName, singletonObject);
// Remove content from L2 cache
this.singletonFactories.remove(beanName);
// Remove content from L3 cache
this.earlySingletonObjects.remove(beanName);
// Add the completed BeanName to the registered singleton collection
this.registeredSingletons.add(beanName);
}
}Since then, the whole Spring circular dependency process has ended.
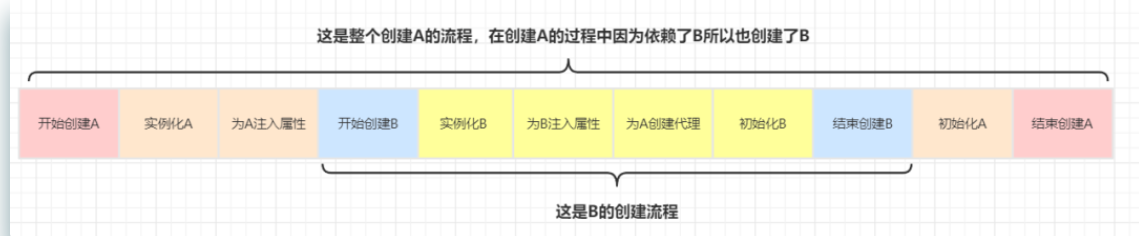
Let's use the first two objects A and B to summarize A process
When you start to create an object A, after instantiation, add A one-step three-level cache and assign values to the attributes. Because there is no instance of object B at this time, the ref reference object B obtained from the value of attribute B of object A triggers the creation of object B. therefore, after the instantiation of object B, the ref reference object of attribute A is obtained during attribute assignment, Because the A object has been instantiated and added to the L3 cache before, when the B attribute is created and the A attribute is being created, the value can be obtained from the L3 cache, the obtained value can be added to the L2 cache, and the A object of the L3 cache can be deleted at the same time.
The A attribute value (semi-finished product) can be obtained in the creation of B object, so B object can complete the assignment state and become A complete instance of B object. Therefore, when A new singleton object is generated, it will call the addSingleton method to add it to the L1 cache and delete the values of the L2 and L3 caches. Therefore, when object A gets the value of attribute B, it can be obtained in the L1 cache. Therefore, the attribute assignment can be completed, and the circular dependency is fully opened.
We have finished talking about circular dependency. In the process of looking at the source code, we must pay attention to the following six methods:
Simple circular dependency (no AOP)
Let's first analyze the simplest example, which is the demo mentioned above
@Component
public class A {
// B is injected into A
@Autowired
private B b;
}
@Component
public class B {
// A is also injected into B
@Autowired
private A a;
}From the above, we know that the circular dependency in this case can be solved. What is the specific process? We analyze it step by step
First of all, we need to know that Spring creates beans according to natural order by default, so in the first step, Spring will create A.
At the same time, we should know that Spring has three steps in the process of creating beans
1 instantiation, corresponding method: createBeanInstance method in AbstractAutowireCapableBeanFactory
2. Attribute injection, corresponding method: populateBean method of AbstractAutowireCapableBeanFactory
3. Initialization, corresponding method: initializeBean of AbstractAutowireCapableBeanFactory
These methods have been explained in detail in previous articles on source code analysis. If you haven't read my article before, you just need to know
1 instantiation, the simple understanding is that new creates an object
2. Attribute injection: fill in attributes for the new object in instantiation
3 initialization, execute the method in the aware interface, initialize the method, and complete the AOP agent
Based on the above knowledge, we begin to interpret the whole process of circular dependency processing. The whole process should start with the creation of A. as mentioned earlier, the first step is to create a!

The process of creating A is actually to call the getBean method, which has two meanings
1 create a new Bean
2 get the created object from the cache
We are now analyzing the meaning of the first layer, because there is no A in the cache at this time!
Call getSingleton(beanName)
First, call getSingleton(a) method, which will call getSingleton(beanName, true). I omitted this step in the figure above
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}getSingleton(beanName, true) is actually trying to get beans in the cache. The whole cache is divided into three levels
For example, the singleton object 1 cache is created. OK
2 earlySingletonObjects, objects that have completed instantiation but have not yet been injected and initialized
3 singletonFactories, a singleton factory exposed in advance. The objects obtained from this factory are stored in the L2 cache
Because A is created for the first time, it must not be in any cache. Therefore, it will enter another overloaded method getSingleton(beanName, singletonFactory) of getSingleton.
Call getSingleton(beanName, singletonFactory)
This method is used to create beans. Its source code is as follows:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// ....
// Omit exception handling and log
// ....
// Make a tag before creating an object
// Put beanName into the singletonsCurrentlyInCreation collection
// This indicates that the singleton Bean is being created
// If the same singleton Bean is created multiple times, an exception will be thrown here
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// The lambda passed in from the upstream will be executed here. Call the createBean method to create a Bean and return
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// ...
// Omit catch exception handling
// ...
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// After creation, remove the corresponding beanName from singletonsCurrentlyInCreation
afterSingletonCreation(beanName);
}
if (newSingleton) {
// Add to singletonObjects in L1 cache
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}In the above code, we mainly grasp one point. The Bean returned through the createBean method is finally put into the first level cache, that is, the singleton pool.
So here we can draw a conclusion: the first level cache stores the single instance beans that have been completely created
Call the addSingletonFactory method
As shown in the figure below:

After the instantiation of the Bean is completed and before the attribute injection, Spring wraps the Bean into a factory and adds it to the three-level cache. The corresponding source code is as follows:
// The parameter passed in here is also a lambda expression, () - > getearlybeanreference (beanname, MBD, bean)
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// Add to L3 cache
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}Here is just a factory added. An object can be obtained through the getObject method of the factory (ObjectFactory), and the object is actually created through the getEarlyBeanReference method. So, when will you call the getObject method of this factory? At this time, it is time to create the process of B.
When a completes the instantiation and adds it to the L3 cache, it is necessary to start property injection for A. when it is found that a depends on B during injection, Spring will go to getBean(b) and then call setter method to complete property injection.
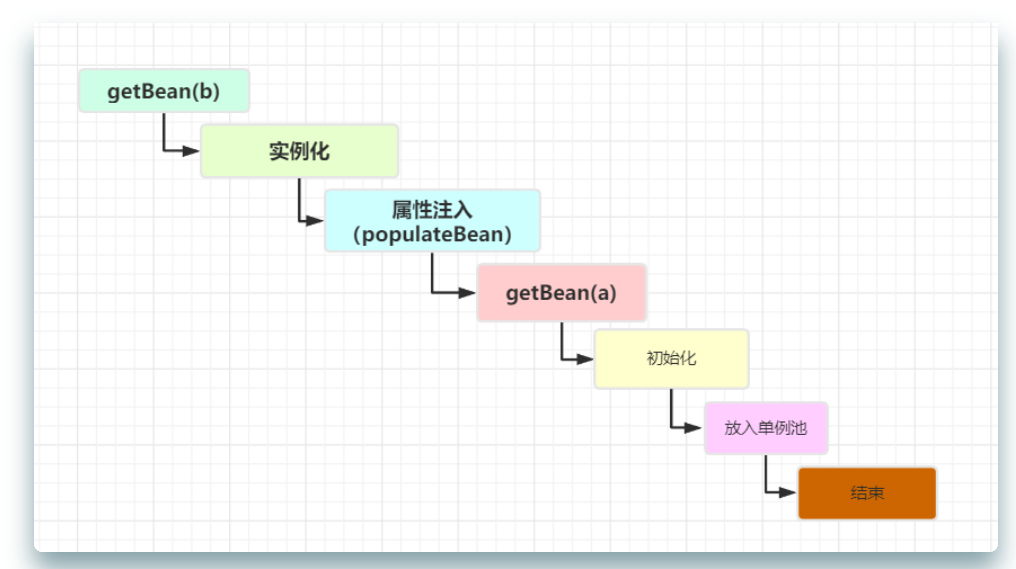
Because B needs to inject A, when creating B, it will call getBean(a). At this time, it will return to the previous process. However, the difference is that the previous getBean is to create A Bean. At this time, the call to getBean is not to create it, but to get it from the cache, because A has put it into the three-level cache singletonFactories after instantiation, So this is the process of getBean(a)
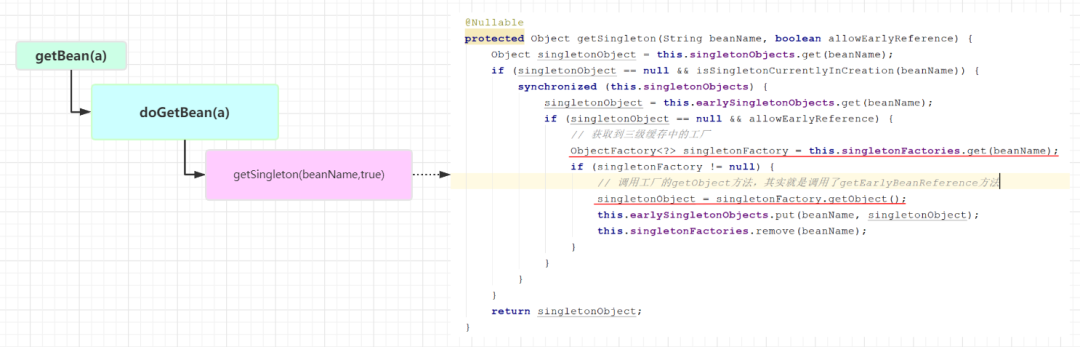
From here, we can see that A injected into B is an object exposed in advance through the getEarlyBeanReference method. It is not A complete Bean. What has getEarlyBeanReference done? Let's take A look at its source code
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}In fact, it calls the getEarlyBeanReference of the post processor, and there is only one post processor that really implements this method, which is the annotation awareaspectjautoproxycreator imported through the @ EnableAspectJAutoProxy annotation. That is, if AOP is not considered, the above code is equivalent to:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
return exposedObject;
}In other words, the factory did nothing and directly returned the objects created in the instantiation stage! So is L3 caching useful without considering AOP? Make sense. It's really useless. Isn't there no problem that I put this object directly into the L2 cache? If you say it improves efficiency, tell me where it improves efficiency?
So what is the role of L3 cache? Don't worry. Let's finish the whole process first. When analyzing circular dependency in combination with AOP below, you can experience the role of three-level cache!
I don't know if my friends will have any questions here. Won't there be any problem if an uninitialized type A object is injected into B in advance?
A: No
At this time, we need to finish the whole process of creating A Bean, as shown in the following figure:

We can see from the above figure that although an uninitialized A object will be injected into B in advance when creating B, the reference of the A object injected into B is always used in the process of creating A, and then A will be initialized according to this reference, so there is no problem.
Combined with the circular dependency of AOP
As we have said before, in the case of ordinary circular dependency, L3 cache has no effect. The L3 cache is actually related to AOP in Spring. Let's take another look at the code of getEarlyBeanReference:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}If AOP is enabled, call the getEarlyBeanReference method of AnnotationAwareAspectJAutoProxyCreator. The corresponding source code is as follows:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
// If you need a proxy, return a proxy object. If you don't need a proxy, directly return the current incoming bean object
return wrapIfNecessary(bean, beanName, cacheKey);
}Returning to the above example, if we AOP proxy a, then getEarlyBeanReference will return an object after proxy instead of the object created in the instantiation stage, which means that a injected into B will be a proxy object instead of the object created in the instantiation stage of A.

Seeing this picture, you may have the following questions
1 why inject a proxy object when injecting B?
A: when we AOP proxy a, it means that what we want to get from the container is the object after a proxy, not a itself. Therefore, when we inject a as a dependency, we should also inject its proxy object
2. When A object is initialized, where does Spring put the proxy object into the container?
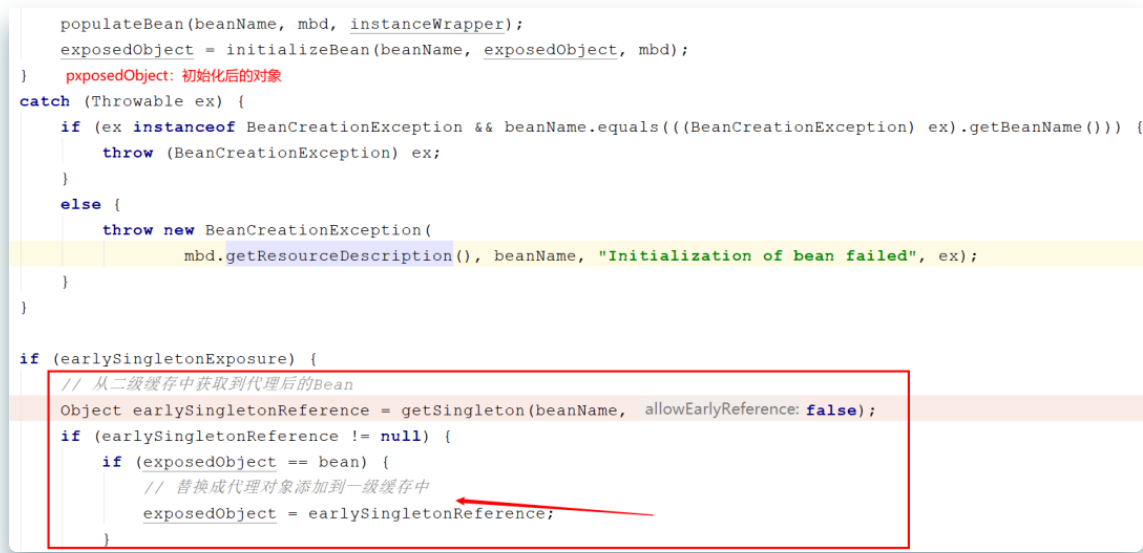
After completing the initialization, Spring calls the getSingleton method again, and the parameters passed in this time are different. false can be understood as disabling the L3 cache. As mentioned in the previous figure, when injecting A into B, the factory in the L3 cache has been taken out, and an object obtained from the factory has been put into the L2 cache, Therefore, the time for the getSingleton method here is to obtain the A object after the proxy from the L2 cache. exposedObject == bean can be considered to be valid unless you have to replace the Bean in the normal process in the post processor in the initialization stage, for example, add A post processor:
@Component
public class MyPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("a")) {
return new A();
}
return bean;
}
}However, please don't do this kind of coquettish operation, just add trouble!
3. When initializing, the A object itself is initialized, and the proxy objects in the container and injected into B are proxy objects. Won't there be A problem?
A: No, this is because no matter the proxy class generated by cglib proxy or jdk dynamic proxy, it holds a reference to the target class. When calling the method of the proxy object, it will actually call the method of the target object. A completes the initialization, which is equivalent to that of the proxy object itself
4 why should L3 cache use factory instead of direct reference? In other words, why do you need this L3 cache? Can't you expose a reference directly through L2 cache?
A: the purpose of this factory is to delay the proxy of the object generated in the instantiation stage. The proxy object will be generated in advance only when the circular dependency really occurs. Otherwise, only a factory will be created and put into the L3 cache, but the object will not be created through this factory
Let's consider A simple case. Take creating A separately as an example. Suppose there is no dependency between AB, but A is represented. At this time, when A completes the instantiation, it will still enter the following code:
// A is a single case, MBD Issingleton() condition is satisfied
// allowCircularReferences: this variable represents whether circular dependencies are allowed. It is on by default and the conditions are met
// Issingletoncurrentyincreation: A is being created, which is also satisfied
// So earlySingletonExposure=true
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// Or will it enter this code
if (earlySingletonExposure) {
// Or will a factory object be exposed in advance through the L3 cache
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}You see, even if there is no circular dependency, it will be added to the L3 cache, and it has to be added to the L3 cache, because so far, Spring is not sure whether this Bean has circular dependency with other beans.
Assuming that we use L2 cache directly here, it means that all beans must complete AOP proxy in this step. Is this necessary?
It is not only unnecessary, but also contrary to the design of Spring in the life cycle of combining AOP and Bean! The life cycle of Spring combining AOP with Bean is completed through the post processor AnnotationAwareAspectJAutoProxyCreator. In the post-processing postProcessAfterInitialization method, AOP proxy is completed for the initialized Bean. If there is a circular dependency, there is no way. We can only create an agent for the Bean first, but in the absence of circular dependency, the beginning of design is to let the Bean complete the agent at the last step of the life cycle, rather than immediately complete the agent after instantiation.
Does L3 caching really improve efficiency?
Now we know the real function of L3 cache, but this answer may not convince you, so let's finally summarize and analyze the wave. Has L3 cache really improved efficiency? The discussion is divided into two points:
1. Circular dependency between beans without AOP
As can be seen from the above analysis, the L3 cache is useless in this case! So there won't be any argument to improve efficiency
2. Cyclic dependency between AOP beans
Take A and B on our as an example, where A is represented by AOP. Let's first analyze the creation process of A and B when three-level cache is used
Assuming that L3 cache is not used, it is directly in L2 cache
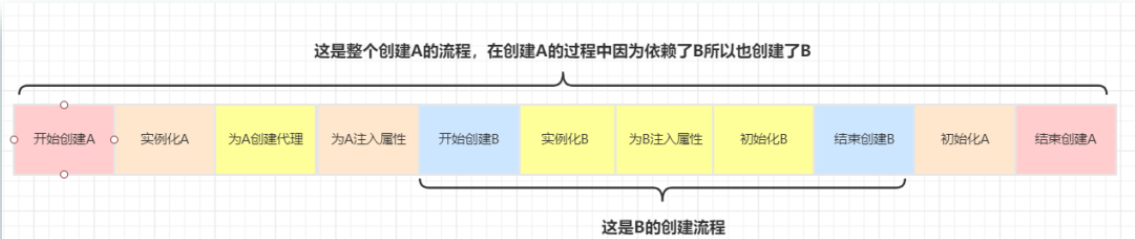
The only difference between the above two processes is that the time to create an agent for A object is different. When the L3 cache is used, the time to create an agent for A is when A needs to be injected into B. if the L3 cache is not used, you need to create an agent for A immediately after A is instantiated, and then put it into the L2 cache.
For the whole creation process of A and B, the time consumed is the same.
To sum up, in either case, the statement that L3 cache improves efficiency is wrong!
Answer template
A: Spring solves the circular dependency through three-level cache. The first level cache is singleton objects, the second level cache is earlySingletonObjects, and the third level cache is singleton factories.
When circular references occur to classes a and B, after a completes instantiation, it uses the instantiated object to create an object factory and add it to the three-level cache. If a is represented by AOP, the object obtained through this factory is the object after a proxy. If a is not represented by AOP, the object obtained by this factory is the object instantiated by A.
When a performs attribute injection, it will create B, and B depends on A. therefore, when creating B, it will call getBean(a) to obtain the required dependency. At this time, getBean(a) will get it from the cache:
The first step is to obtain the factory in the three-level cache;
The second step is to call the getObject method of the object factory to obtain the corresponding object, and then inject it into B. Then B will complete its life cycle process, including initialization, post processor, etc.
When B is created, B will be re injected into A, and A will complete its whole life cycle. At this point, the circular dependency ends!
Interviewer: "why use L3 cache? Can L2 cache solve circular dependency? “
A: if the L2 cache is used to solve the circular dependency, it means that all beans must complete the AOP proxy after instantiation, which is contrary to the principle of Spring design. At the beginning of the design, Spring uses the post processor AnnotationAwareAspectJAutoProxyCreator to complete the AOP proxy at the last step of the Bean life cycle, Instead of AOP proxy immediately after instantiation.
