Click on "end of life", pay attention to the official account.
Daily delivery, dry time!
1. Background
-
Use the flowable UI that comes with flowable to make the flow chart
-
Use the interface used by the springboot development process to complete the business functions of the process
2. Deployment and operation of flowable UI
flowable-6.6.0 run the official demo
Reference documents: https://flowable.com/open-source/docs/bpmn/ch14-Applications/
1. Download flowable-6.6.0 from the official website: https://github.com/flowable/flowable-engine/releases/download/flowable-6.6.0/flowable-6.6.0.zip
2. Compress the flowable-6.6.0 \ wars \ flowable UI in the package War dropped into Tomcat and ran
3. Open http://localhost:8080/flowable-ui login with account: admin/test

4. Enter app Model creates a process, which can be exported to the project for use or configured
apache-tomcat-9.0.37\webapps\flowable-ui\WEB-INF\classes\flowable-default.properties connect to the local database
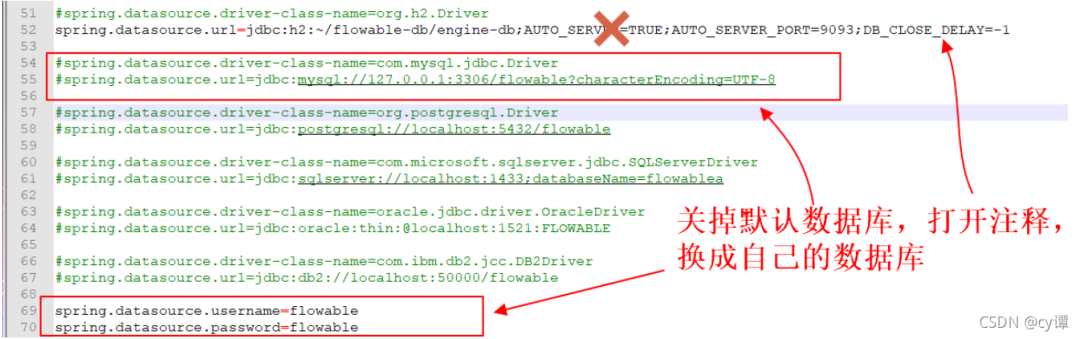
Note: you need to copy the Java driver jar (mysql-connector-java-5.1.45.jar) to apache-tomcat-9.0.37 \ webapps \ flowable rest \ WEB-INF \ lib, so that the created process backend can be used directly
3. Draw flow chart
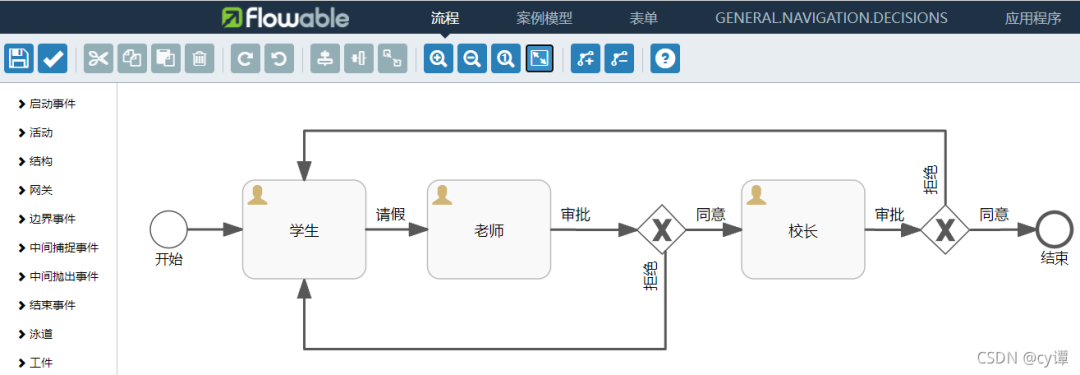
According to business needs, click flowable UI > app The flow chart of model is shown in the figure above. First explain some concepts.
-
Events are usually used to model what happens in the process life cycle. In the diagram, there are two circles: start and end.
-
A sequence flow is a connector between two elements in a process. In the picture is [arrow line segment].
-
The gateway is used to control the flow of execution. In the picture is [diamond (with X in the middle)]
-
user task is used to model tasks that need to be executed manually. In the picture is [rectangle].
These are probably the elements of a simple workflow (many of which are not extended here). The following describes how workflow flows.
First, after the workflow is started, it will automatically flow from the start node to the student node and wait for the task to be executed. After the assigned student user executes the task, it flows to the [teacher] node and waits for the task to be executed again. The assigned teacher user flows to the [gateway] after execution. The gateway checks each exit and flows to the qualified task. For example, if the teacher agrees to execute the task, it flows to the [principal] node and waits for the task to be executed. The execution is similar to that of the teacher. After approval, it flows to the end node, and the whole process ends here.
Drawing details:
1. Retention process model

2. For sequential flow, flow conditions can be set to restrict flow. For example, the above gateway exit has set conditions

3. Task execution users who need to be assigned tasks can be assigned to candidate groups or directly to candidates

Finally, export the workflow file
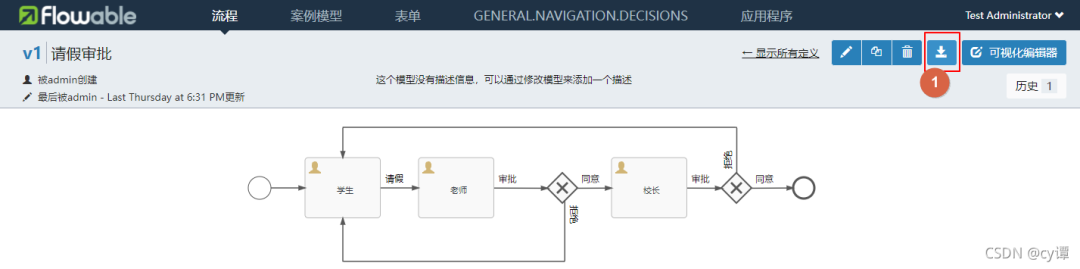
Document content
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" xmlns:xsi="http://www.w3.org/2001/XMLSchema-insmtece" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:flowable="http://flowable.org/bpmn" xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI" xmlns:omgdc="http://www.omg.org/spec/DD/20100524/DC" xmlns:omgdi="http://www.omg.org/spec/DD/20100524/DI" typeLanguage="http://www.w3.org/2001/XMLSchema" expressionLanguage="http://www.w3.org/1999/XPath" targetNamespace="http://www.flowable.org/processdef">
<process id="leave_approval" name="Leave approval" isExecutable="true">
<startEvent id="start" name="start" flowable:initiator="startuser" flowable:formFieldValidation="true"></startEvent>
<userTask id="stu_task" name="student" flowable:candidateGroups="stu_group" flowable:formFieldValidation="true"></userTask>
<sequenceFlow id="flow1" sourceRef="start" targetRef="stu_task"></sequenceFlow>
<userTask id="te_task" name="teacher" flowable:candidateGroups="te_group" flowable:formFieldValidation="true"></userTask>
<exclusiveGateway id="getway1" name="Gateway 1"></exclusiveGateway>
<userTask id="mte_task" name="principal" flowable:candidateGroups="mte_group" flowable:formFieldValidation="true"></userTask>
<exclusiveGateway id="getway2" name="Gateway 2"></exclusiveGateway>
<endEvent id="end" name="end"></endEvent>
<sequenceFlow id="flow1" name="leave" sourceRef="stu_task" targetRef="te_task" skipExpression="${command=='agree'}"></sequenceFlow>
<sequenceFlow id="flow3_1" name="agree" sourceRef="getway1" targetRef="mte_task">
<conditionExpression xsi:type="tFormalExpression"><![CDATA[${command=='agree'}]]></conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow2" name="Examine and approve" sourceRef="te_task" targetRef="getway1"></sequenceFlow>
<sequenceFlow id="flow3_2" name="refuse" sourceRef="getway1" targetRef="stu_task">
<conditionExpression xsi:type="tFormalExpression"><![CDATA[${command=='refuse'}]]></conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow4" name="Examine and approve" sourceRef="mte_task" targetRef="getway2"></sequenceFlow>
<sequenceFlow id="flow4_1" name="agree" sourceRef="getway2" targetRef="end" skipExpression="${command=='free'}">
<conditionExpression xsi:type="tFormalExpression"><![CDATA[${command=='agree'}]]></conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow4_2" name="refuse" sourceRef="getway2" targetRef="stu_task">
<conditionExpression xsi:type="tFormalExpression"><![CDATA[${command=='refuse'}]]></conditionExpression>
</sequenceFlow>
</process>
<bpmndi:BPMNDiagram id="BPMNDiagram_leave_approval">
Omit here first
</bpmndi:BPMNDiagram>
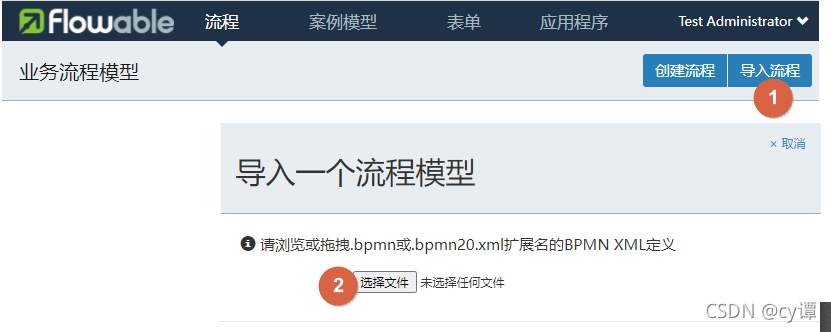
</definitions>4. bpmn file import
If necessary, you can download this process file and directly import it for use
4. Background project construction
The background project is based on jdk8 and uses the springboot framework
spring version
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.0.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent>
The project depends on POM xml
<dependency> <groupId>org.flowable</groupId> <artifactId>flowable-spring-boot-starter</artifactId> <version>6.6.0</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.45</version> </dependency>
Project configuration application yml
spring: datasource: url: jdbc:mysql://localhost:3306/flowable?useSSL=false&characterEncoding=UTF-8&serverTimezone=GMT%2B8 driver-class-name: com.mysql.jdbc.Driver username: root password: 123456
5. Database
1. All database tables of Flowable are represented by ACT_ start. The second part is the two character identifier that explains the purpose of the table. The naming of service API s also roughly conforms to this rule.
2,ACT_RE_: 'RE 'stands for repository. The table with this prefix contains "static" information, such as process definitions and process resources (pictures, rules, etc.).
3,ACT_RU_: 'RU 'stands for runtime. These tables store runtime information, such as process instance, user task, variable, job, and so on. Flowable saves run-time data only in the running process instance, and deletes records at the end of the process instance. This ensures that the runtime table is small and fast.
4,ACT_ HI_: ' 'Hi' stands for history. These tables store historical data, such as completed process instances, variables, tasks, and so on.
5,ACT_GE_: General data. Use in multiple places.
1)General data sheet (2) act_ge_bytearray: Binary data table, such as byte stream file of process definition, process template and flow diagram; act_ge_property: Attribute data sheet (not commonly used); 2)History table (8), HistoryService Table of interface operations) act_hi_actinst: History node table, which stores the node information of process instance operation (including start, end and other non task nodes); act_hi_attachment: The historical attachment table stores the attachment information uploaded by the historical node (not commonly used); act_hi_comment: Historical opinion form; act_hi_detail: History detail table, which stores some information of node operation (not commonly used); act_hi_identitylink: The historical process personnel table stores the candidate and handling personnel information of each node of the process, which is often used to query the completed tasks of a person or department; act_hi_procinst: The historical process instance table stores the historical data of process instances (including running process instances); act_hi_taskinst: Historical process task table, which stores historical task nodes; act_hi_varinst: The process history variable table stores the variable information of the process history node; 3)User related tables (4, IdentityService Table of interface operations) act_id_group: The user group information table selects candidate group information corresponding to the node; act_id_info: A user extension information table for storing user extension information; act_id_membership: User and user group relationship table; act_id_user: The user information table selects the handler or candidate information in the corresponding node; 4)Process definition, process template and related tables (3), RepositoryService Table of interface operations) act_re_deployment: The subordinate information table stores the process definition and template deployment information; act_re_procdef: The process definition information table stores the description information related to the process definition, but its real content is stored in act_ge_bytearray In the table, it is stored in bytes; act_re_model: The process template information table stores the description information related to the process template, but its real content is stored in act_ge_bytearray In the table, it is stored in bytes; 5)Process runtime tables (6, RuntimeService Table of interface operations) act_ru_task: The runtime process task node table stores the task node information of the running process. It is important and is often used to query the to-do tasks of personnel or departments; act_ru_event_subscr: Monitoring information table, not commonly used; act_ru_execution: The runtime process execution instance table records the branch information of the running process (when there is no sub process, its data is the same as act_ru_task Table data is one-to-one correspondence); act_ru_identitylink: The run-time process personnel table is important and is often used to query the to-do tasks of personnel or departments; act_ru_job: The runtime scheduled task data table stores the scheduled task information of the process; act_ru_variable: The runtime process variable data table stores the variable information of each node of the running process;
6. Process engine API and service
Engine API is the most commonly used means to interact with Flowable. The main entry point is ProcessEngine.
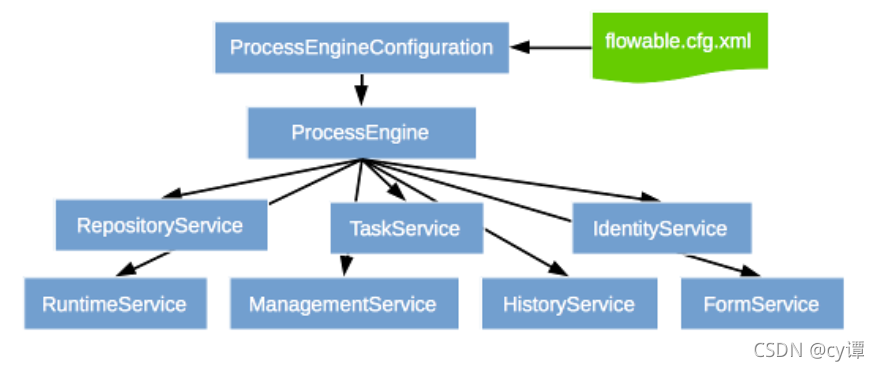
1. The repository service is likely to be the first service to use the Flowable engine. This service provides management and control deployment and process definition
definitions). Manage static information. 2. RuntimeService is used to start a new process instance of the process definition.
3. IdentityService is simple. It is used to manage (create, update, delete, query...) groups and users.
4. FormService is an optional service. In other words, Flowable can run well without it without sacrificing any functions.
5. The HistoryService exposes all historical data collected by the Flowable engine. To provide the ability to query historical data.
6. ManagementService is usually not used when writing user applications with Flowable. It can read the information of the database table and the original data of the table, and also provide the query and management operation of the job.
7. Dynamic bpmnservice can be used to modify parts of the process definition without redeploying it. For example, you can modify the handler setting of a user task in the process definition, or modify the class name in a service task.
Next, use the previous leave flow chart and add the code
@Slf4j
public class TestFlowable {
@Autowired
private RepositoryService repositoryService;
@Autowired
private RuntimeService runtimeService;
@Autowired
private HistoryService historyService;
@Autowired
private org.flowable.engine.TaskService taskService;
@Autowired
private org.flowable.engine.IdentityService identityService;
public void createDeploymentZip() {
/*
* Step 1: Deploy xml (compressed to zip format, direct xml needs to configure relative path, which is troublesome and not needed for the time being)
*/
try {
File zipTemp = new File("f:/leave_approval.bpmn20.zip");
ZipInputStream zipInputStream = new ZipInputStream(new FileInputStream(zipTemp));
Deployment deployment = repositoryService
.createDeployment()
.addZipInputStream(zipInputStream)
.deploy();
log.info("Deployment successful:{}", deployment.getId());
} catch (FileNotFoundException e) {
e.printStackTrace();
}
/*
* Step 2: Query the deployed process definition
*/
List<ProcessDefinition> list = repositoryService.createProcessDefinitionQuery().processDefinitionKey("leave_approval").list();
List<ProcessDefinition> pages = repositoryService.createProcessDefinitionQuery().processDefinitionKey("leave_approval").listPage(1, 30);
/*
* Step 3: Start the process and create an instance
*/
String processDefinitionKey = "leave_approval";//The key of the process definition corresponds to the flow chart of asking for leave
String businessKey = "schoolleave";//Business code, used according to your own business
Map<String, Object> variablesDefinition = new HashMap<>();//Process variables can be customized and extended
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey(processDefinitionKey, businessKey, variablesDefinition);
log.info("Start successful:{}", processInstance.getId());
/*
* Step 4: Query the list of all started instances of the specified process
* List, or page delete
*/
List<Execution> executions = runtimeService.createExecutionQuery().processDefinitionKey("leave_approval").list();
List<Execution> executionPages = runtimeService.createExecutionQuery().processDefinitionKey("leave_approval").listPage(1, 30);
// runtimeService.deleteProcessInstance(processInstanceId, deleteReason); // Delete instance
/*
* Step 5: Students can query the operational tasks and complete the tasks
*/
String candidateGroup = "stu_group"; //flowable:candidateGroups="stu_group" in candidate group xml file
List<Task> taskList = taskService.createTaskQuery().taskCandidateGroup(candidateGroup).orderByTaskCreateTime().desc().list();
for (Task task : taskList) {
// Claim task
taskService.claim(task.getId(), "my");
// complete
taskService.complete(task.getId());
}
/*
* Step 6: The teacher inquires about the tasks that can be operated and completes the tasks
*/
String candidateGroupTe = "te_group"; //flowable:candidateGroups="te_group" in candidate group xml file
List<Task> taskListTe = taskService.createTaskQuery().taskCandidateGroup(candidateGroupTe).orderByTaskCreateTime().desc().list();
for (Task task : taskListTe) {
// Claim task
taskService.claim(task.getId(), "myte");
// complete
Map<String, Object> variables = new HashMap<>();
variables.put("command","agree"); //Carry variables, which are used to determine the conditions of the gateway process. The condition here is consent
taskService.complete(task.getId(), variables);
}
/*
* Step 7: History query, because once the process is completed, the activity data will be cleared, and the data can not be found in the above query interface, but the history query interface is provided
*/
// Historical process instance
List<HistoricProcessInstance> historicProcessList = historyService.createHistoricProcessInstanceQuery().processDefinitionKey("leave_approval").list();
// Historical task
List<HistoricTaskInstance> historicTaskList = historyService.createHistoricTaskInstanceQuery().processDefinitionKey("leave_approval").list();
// Instance history variable
// historyService.createHistoricVariableInstanceQuery().processInstanceId(processInstanceId);
// historyService.createHistoricVariableInstanceQuery().taskId(taskId);
// *****************************************************Separator********************************************************************
// *****************************************************Separator********************************************************************
// API may also be required
// Mobile task, human jump task
// runtimeService.createChangeActivityStateBuilder().processInstanceId(processInstanceId)
// .moveActivityIdTo(currentActivityTaskId, newActivityTaskId).changeState();
// If grouping and users are configured in the database, it will also be used
List<User> users = identityService.createUserQuery().list(); //User query. The user id corresponds to the user configured in xml
List<Group> groups = identityService.createGroupQuery().list(); //Grouping query. The grouping id corresponds to the grouping configured in xml, such as stu_group,te_group is the value of id in the table
// In addition, you can spell conditions behind each query. There are so many built-in queries, including fuzzy queries, and size comparison
}
}reference material
[1] Share cattle Flowable documents in Chinese: https://github.com/qiudaoke/flowable-userguide
[2] Cat seven girl flowable-6.6.0 runs the official demo
[3] Wageresa https://www.cnblogs.com/yangjiming/p/10938515.html
PS: in case you can't find this article, you can collect some likes for easy browsing and searching