preface
Teach you how to use sharding JDBC to realize the database sub database and sub table.
1, Concept
Sub database and sub table
Database and table splitting is a reasonable splitting of databases and tables when the amount of data is large to a certain extent. Take MySQL as an example: it is recommended that the maximum amount of data in a single table should not exceed ten million levels, and the index tree should not exceed three levels. Otherwise, you need to split the table horizontally.
Due to the limited performance of the high parallel distribution single database and the performance of the server, in order to provide better services, the data also needs to be stored in pieces. That is, sub database. In sharding JDBC, sub database is called data slicing.
There are two common ways to divide databases and tables
- Proxy proxy methods: mycat, sharding proxy, etc. the main logic of the proxy method is to configure database and table rules on the proxy client, connect the application to the proxy client, connect the proxy client to mysql, intercept and reorganize the application's sql requests and send them to mysql for execution. And return to the application
- jdbc enhancement method: sharding jdbc. The main logic of jdbc enhancement method is to configure database and table rules on the application side, intercept sql requests according to the configuration rules and send them to mysql
split horizon
Split the data horizontally. For example, a single order table contains 10 million data. At this time, query, insert and update operations on this table will be very slow. But when I split this order table into 10 order{0... 9} tables according to the rules (a field name), each order table stores 1 million data. In this way, query, insert and update will be much faster. This is the horizontal split
Split Vertically
According to the business splitting method, it is called vertical splitting, also known as vertical splitting. The core concept is dedicated to special database and special table. Vertical splitting can alleviate the problems caused by data volume and access volume, but it can not cure them
2, Use steps
1. Preparation
- Prepare a springboot+mybatisplus+mysql integrated project (normal addition, deletion, modification and query)
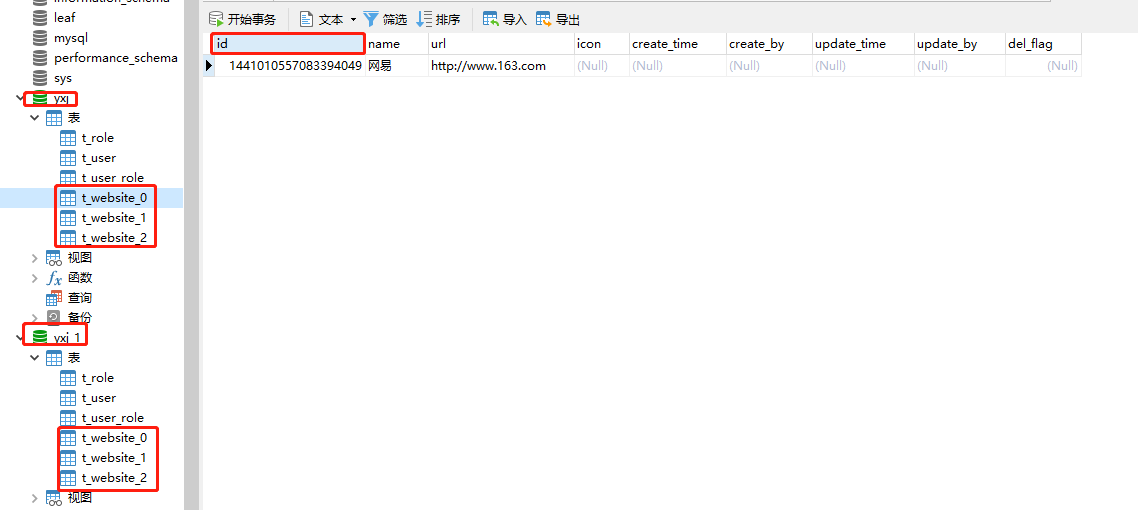
- Create two new libraries: yxj and yxj_ one
- Three t-sheets are built in each library_ website_ Table 0, 1 and 2
2. Dependence
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<!-- You can change to another database connection pool -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
</dependency>
3. Configuration
Configuration is the core of the whole sharding JDBC. Sharding JDBC needs to split data through configuration rules. Sharding JDBC provides four configuration modes for different usage scenarios.

Here we mainly introduce the configuration of spring boot mode:
spring:
shardingsphere:
datasource:
names: yxj0,yxj1 #Data source name. Multiple data sources are separated by commas
yxj0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://127.0.0.1:3306/yxj
yxj1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://127.0.0.1:3306/yxj_1
sharding:
default-database-strategy: #Default sub database policy
inline:
sharding-column: id #Sub database column name, and the rule sub database is performed according to this data column
algorithm-expression: yxj$->{id % 2} #Sub database rule: generally, n databases take the remainder of n
tables: #Table splitting strategy
t_website:
#It consists of data source name + table name, separated by decimal point. Multiple tables are separated by commas, and inline expressions are supported. The default is to generate data nodes using known data sources and logical table names for broadcast tables (i.e. each library needs the same table for association queries, mostly dictionary tables) or when there are only databases and no tables, and the table structures of all libraries are completely consistent
actual-data-nodes: yxj$->{0..1}.t_website_$->{0..2}
table-strategy:
inline:
sharding-column: id #The name of the sub table column. The table is divided according to the rules according to this column
#According to the table splitting rule, generally n tables are used to extract the remainder of n
algorithm-expression: t_website_$->{id % 3}
key-generator:
column: id #Primary key field
type: SNOWFLAKE #Primary key generation policy, optional SNOWFLAKE/UUID
broadcast-tables: t_role #Public tables, each library has. Changing the table will update the table of other libraries
props:
sql:
show: true #Console log display
4. Verification
Using postman to t_ N pieces of data are inserted into the website table. Before inserting into the database, sharding JDBC will intercept them and calculate the specific database and table of the inserted data according to the configured rules.
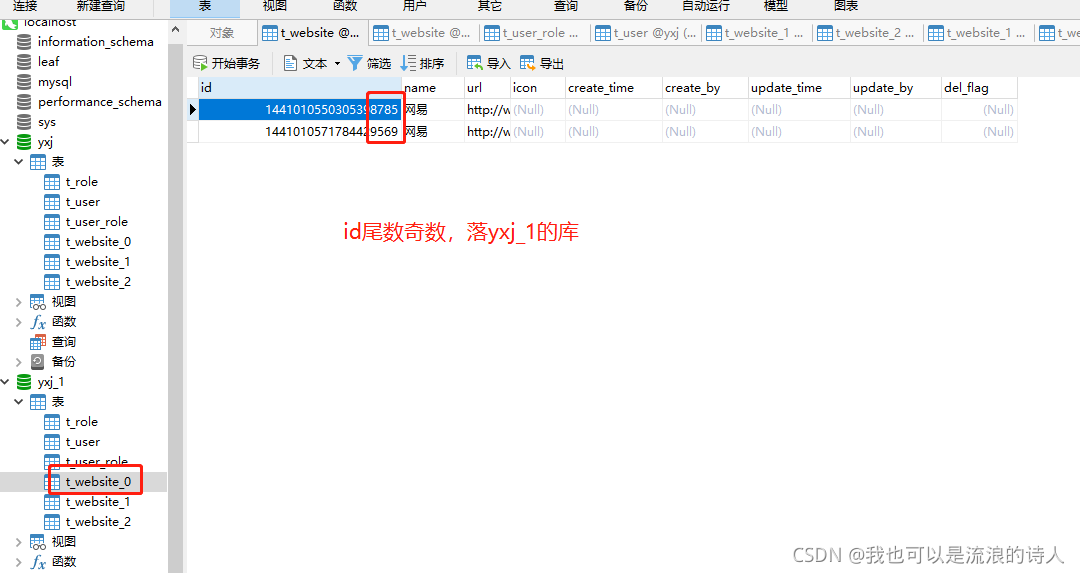
For example, in the above example: when two libraries are built and the rule is to take the remainder of 2, if the mantissa of the library partition column id is an odd number, it will be saved yxj_1 library
Even numbers are saved yxj in the library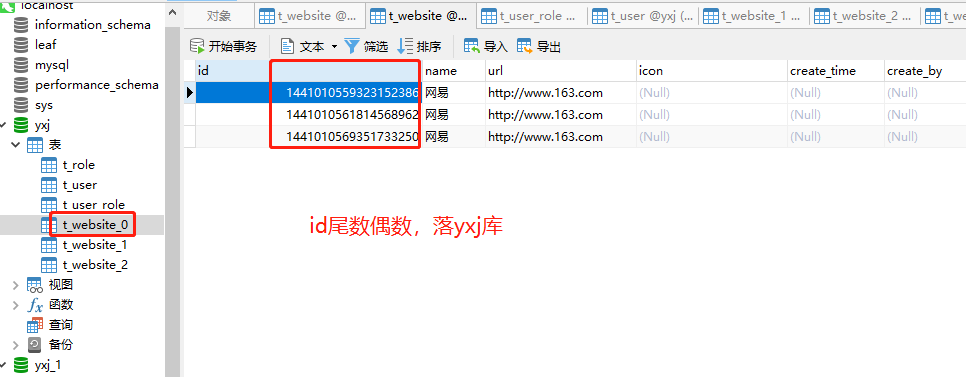
After determining which library, continue to judge which table to store according to the table fragmentation rules
summary
Using sharding JDBC to implement database and table segmentation is actually very simple. It can be used mainly by understanding the rule configuration. Please refer to the specific configuration rules Official documents