
The message sending posture of rabbitmq was introduced before. Since there is sending, there must be consumers. In the spring boot environment, consumption is relatively simple. With @ RabbitListener annotation, you can basically meet more than 90% of your business development needs
Let's take a look at @ RabbitListener's most commonly used posture
<!-- more -->
I. configuration
First, create a spring boot project for subsequent demonstrations
- springboot version is 2.2.1.RELEASE
- rabbitmq version is 3.7.5 (refer to: [MQ Series] springboot + rabbitmq initial experience)
Dependent configuration file pom.xml
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.1.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> <!-- Note that this is not necessary--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies> <build> <pluginManagement> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </pluginManagement> </build> <repositories> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/libs-snapshot-local</url> <snapshots> <enabled>true</enabled> </snapshots> </repository> <repository> <id>spring-milestones</id> <name>Spring Milestones</name> <url>https://repo.spring.io/libs-milestone-local</url> <snapshots> <enabled>false</enabled> </snapshots> </repository> <repository> <id>spring-releases</id> <name>Spring Releases</name> <url>https://repo.spring.io/libs-release-local</url> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories>
In the application.yml configuration file, add the related properties of rabbitmq
spring: rabbitmq: virtual-host: / username: admin password: admin port: 5672 host: 127.0.0.1
2. Consumption posture
The goal of this article is to demonstrate the usage posture of @ RabbitListener in combination with specific scenarios. Therefore, after reading this article, you still don't understand some attributes in this annotation. Please don't worry. The next article will come together
0. mock data
How to consume without data? So the first step is to create a message producer who can write data to exchange for subsequent consumer testing
The consumption of this article is mainly explained by topic mode (the use of other modes is not different, if there is demand, it will be supplemented later)
@RestController public class PublishRest { @Autowired private RabbitTemplate rabbitTemplate; @GetMapping(path = "publish") public boolean publish(String exchange, String routing, String data) { rabbitTemplate.convertAndSend(exchange, routing, data); return true; } }
Provide a simple rest interface, which can specify which exchange to push data to, and formulate routing key
1. case1: exchange, queue already exists
For consumers, there is no need to manage the creation / destruction of exchange, which is defined by the sender. Generally speaking, consumers pay more attention to their own queue, including defining queue and binding with exchange. This set of process can be directly operated through the control console of rabbitmq
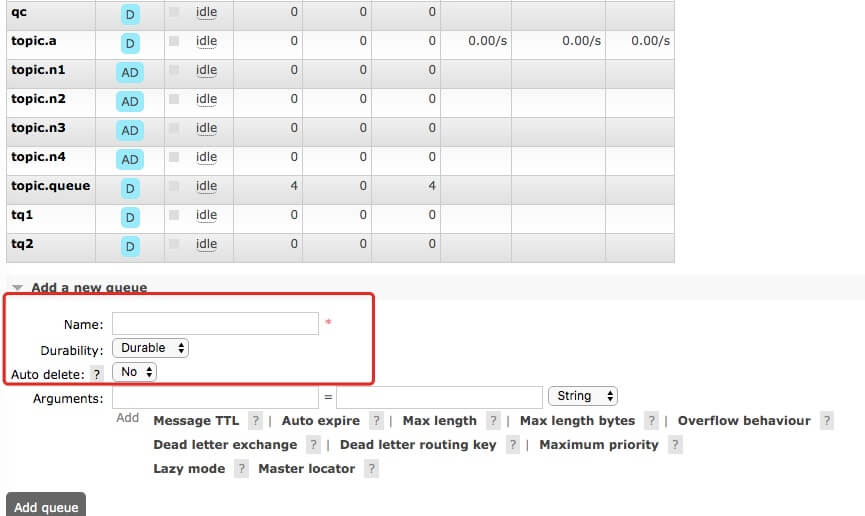
Therefore, in the actual development process, there is a high possibility that the exchange and queue and the corresponding binding relationship already exist, and there is no need for additional processing in the code;
In this scenario, the consumption data is very simple, as follows:
/** * When the queue already exists, it is consumed by specifying the queue name directly * * @param data */ @RabbitListener(queues = "topic.a") public void consumerExistsQueue(String data) { System.out.println("consumerExistsQueue: " + data); }
Just specify the queues parameter in the annotation directly. The parameter value is the queue name
2. Case 2: queue does not exist
When the autoDelete attribute of the queue is false, the above usage scenario is more appropriate; however, when the attribute is true, no consumer queue will be deleted automatically. At this time, the above pose may be used to get the following exception
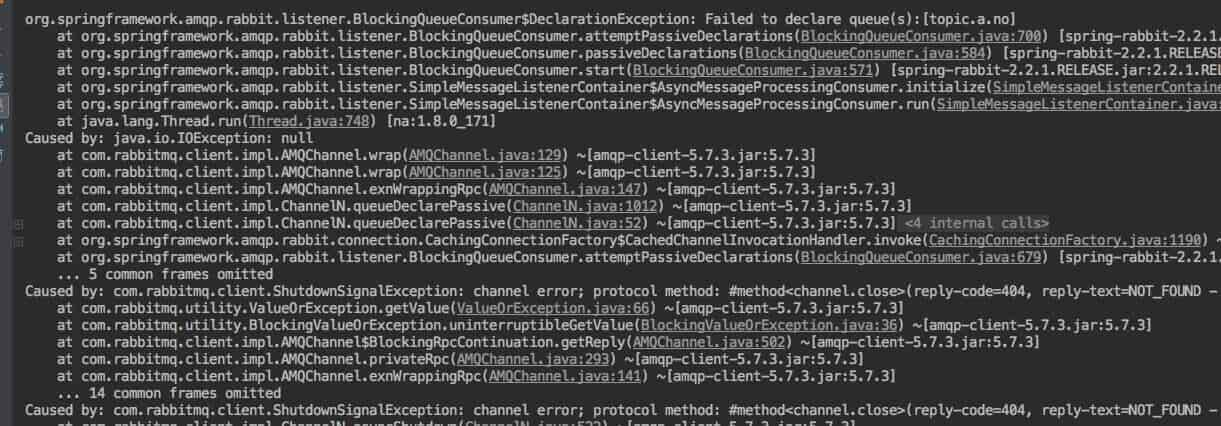
Usually, in this scenario, we need to actively create a Queue and establish a binding relationship with Exchange. Here is the recommended use posture of @ RabbitListener
/** * When the queue does not exist, a queue needs to be created and bound with exchange */ @RabbitListener(bindings = @QueueBinding( value = @Queue(value = "topic.n1", durable = "false", autoDelete = "true"), exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r")) public void consumerNoQueue(String data) { System.out.println("consumerNoQueue: " + data); }
An annotation, internal declaration of the queue, and establish a binding relationship, is so amazing!!!
Note the three properties of the @ QueueBinding annotation:
- value: @Queue Annotation, used to declare the queue. The value is queueName, durable indicates whether the queue is persistent, and autoDelete indicates whether the queue is automatically deleted after there is no consumer
- exchange: @Exchange Annotation, which is used to declare exchange and type to specify the message delivery policy. The topic method we use here
- key: in the topic mode, this is the familiar routingKey
The above is the use posture when the queue does not exist. It does not look complicated
3. case3: ack
In the previous learning process of rabbitmq's core knowledge points, we will know that in order to ensure data consistency, there is a message confirmation mechanism;
The ACK here is mainly for the consumer. When we want to change the default ack mode (noack, auto, manual), we can do the following
/** * When manual ack is required, but no ack is required * * @param data */ @RabbitListener(bindings = @QueueBinding(value = @Queue(value = "topic.n2", durable = "false", autoDelete = "true"), exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r"), ackMode = "MANUAL") public void consumerNoAck(String data) { // Ask for manual ACK, what happens if there is no ack here? System.out.println("consumerNoAck: " + data); }
The above implementation is also relatively simple, setting ackMode=MANUAL, manual ack
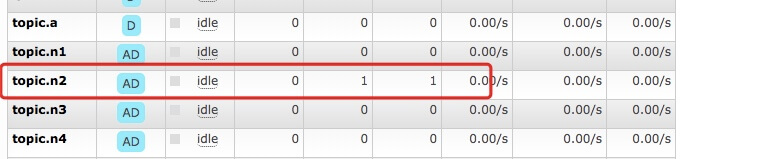
However, please note that in our implementation, there is no manual ack in any place, which is equivalent to no ACK at all. In the later tests, we can see that when this kind of no ack happens, we will find that the data is always in the column of Unacked. When the number of Unacked exceeds the limit, we will not consume new data
4. case4: manual ack
Although the ACK mode is selected above, there is still a lack of logic of ack. Next, let's see how to complete it
/** * Manual ack * * @param data * @param deliveryTag * @param channel * @throws IOException */ @RabbitListener(bindings = @QueueBinding(value = @Queue(value = "topic.n3", durable = "false", autoDelete = "true"), exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r"), ackMode = "MANUAL") public void consumerDoAck(String data, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag, Channel channel) throws IOException { System.out.println("consumerDoAck: " + data); if (data.contains("success")) { // In the ack mechanism of RabbitMQ, the second parameter returns true, indicating that the message needs to be delivered to other consumers for re consumption channel.basicAck(deliveryTag, false); } else { // The third parameter, true, indicates that the message will re-enter the queue channel.basicNack(deliveryTag, false, true); } }
Note that the method has two more parameters
- deliveryTag: the unique identifier of the message, used by mq to identify which message is ack/nak
- Channel: the pipeline between MQ and consumer, through which ack/nak
When we consume correctly, we can call the basicAck method
// In the ack mechanism of RabbitMQ, the second parameter returns true, indicating that the message needs to be delivered to other consumers for re consumption channel.basicAck(deliveryTag, false);
When we fail to consume, we need to put the message back into the queue and wait for it to be consumed again, we can use basicNack
// The third parameter, true, indicates that the message will re-enter the queue channel.basicNack(deliveryTag, false, true);
5. Case 5: concurrent consumption
When there is a lot of information, a consumer's consumption is too slow, but my machine performance is very poor. At this time, I want to consume in parallel, which is equivalent to having multiple consumers to process data at the same time
To support parallel consumption, set
@RabbitListener(bindings = @QueueBinding(value = @Queue(value = "topic.n4", durable = "false", autoDelete = "true"), exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC), key = "r"), concurrency = "4") public void multiConsumer(String data) { System.out.println("multiConsumer: " + data); }
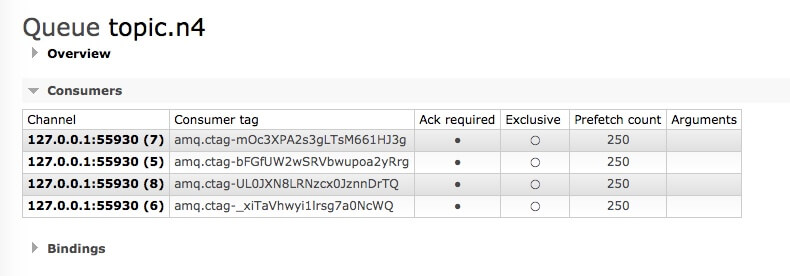
Please note that the concurrency = "4" attribute in the annotation indicates fixed 4 consumers;
In addition to the above assignment method, there is also an m-n format, which represents m parallel consumers, with a maximum of n consumers
(Note: the explanation of this parameter is in the scenario of SimpleMessageListenerContainer. The next article will introduce the difference between it and DirectMessageListenerContainer.)
6. test
Through the previously reserved message sending interface, we request in the browser: http: / / localhost: 8080 / publish? Exchange = topic. E & routing = R & data = Wahaha
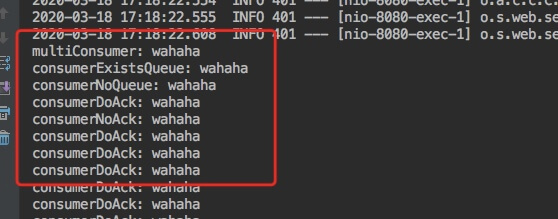
Then look at the output. All five consumers have received the message, especially the active nak consumer;
(since the log has been printed, restart the application and start the next test.)
Then send a successful message to verify that the ack is correct manually. If the above situation still occurs, request the command: http: / / localhost: 8080 / publish? Exchange = topic. E & routing = R & data = successmsg

Then pay attention to the queue without ack. There is always a message of unack
II. other
Series of blog posts
- [MQ Series] springboot + rabbitmq initial experience
- [MQ Series] RabbitMq core knowledge summary
- [MQ Series] SprigBoot + RabbitMq basic use posture for sending messages
- [MQ Series] usage posture of RabbitMq message confirmation / transaction mechanism
Project source code
- Works: https://github.com/liuyueyi/spring-boot-demo
- Source code: https://github.com/liuyueyi/spring-boot-demo/tree/master/spring-boot/302-rabbitmq-consumer
1. A grey Blog: https://liuyueyi.github.io/hexblog
A grey personal blog, recording all the learning and working blog, welcome to visit
2. statement
The best letter is not as good as the above. It's just a one-of-a-kind remark. Due to my limited ability, there are inevitably omissions and mistakes. If you find a bug or have better suggestions, you are welcome to criticize and correct. Thank you very much
- Microblog address: Little ash Blog
- QQ: Yihui / 3302797840
3. Scanning attention
A grey blog
