1, JDBC specification
1.1 introduction to JDBC
JDBC is the full name of Java Database Connectivity. Its original design intention is to provide a set of unified standards that can be applied to various databases. This set of standards needs to be observed by different database manufacturers, and provide their own implementation schemes for JDBC applications.
As a set of unified standards, JDBC specification has a complete architecture, as shown in the figure below:

As can be seen from the above figure, Java applications access data through the APIs provided by JDBC, and these APIs contain various core programming objects that developers need to master. Let's take a look at them together.
1.2 what are the core programming objects in the JDBC specification?
For daily development, the core programming objects in the JDBC specification include DriverManger, DataSource, Connection, Statement, and ResultSet.
As shown in the previous overall architecture diagram of JDBC specification, the DriverManager in JDBC is mainly responsible for loading various drivers and returning corresponding database connections to the application according to different requests, and then the application realizes the operation of the database by calling JDBC API.
The Driver in JDBC is defined as follows. The most important one is the first connect method to obtain Connection:
public interface Driver {
//Get database connection
Connection connect(String url, java.util.Properties info)
throws SQLException;
boolean acceptsURL(String url) throws SQLException;
DriverPropertyInfo[] getPropertyInfo(String url, java.util.Properties info)
throws SQLException;
int getMajorVersion();
int getMinorVersion();
boolean jdbcCompliant();
public Logger getParentLogger() throws SQLFeatureNotSupportedException;
}
For the Driver interface, different database suppliers provide their own implementation schemes. For example, the Driver implementation class in MySQL is as follows:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
// Register drivers through DriverManager
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
....
}
Here, the DriverManager is used. In addition to the registerDriver method for registering the Driver described above, the DriverManager also provides a getConnection method for obtaining a Connection object for a specific Driver.
1.3,DataSource
Through the previous introduction, we know that the Connection can be obtained directly through the DriverManager in the JDBC specification. We also know that the process of obtaining the Connection needs to establish a Connection with the database, and this process will incur large system overhead.
In order to improve performance, we usually first establish an intermediate layer to store the Connection generated by the DriverManager in the Connection pool, and then obtain the Connection from the pool.
We can think that DataSource is such an intermediate layer. It is introduced as an alternative to DriverManager and is the preferred method to obtain database connection.
DataSource represents a data source in JDBC specification, and its core function is to obtain the database Connection object Connection. In the daily development process, we usually obtain the Connection based on the DataSource. The DataSource interface is defined as follows:
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password)
throws SQLException;
}
As we can see from the above, the DataSource interface provides two overloaded methods for obtaining Connection and inherits the CommonDataSource interface. CommonDataSource is the root interface of the data source definition in JDBC. In addition to the DataSource interface, it also has two other sub interfaces, as shown in the following figure:
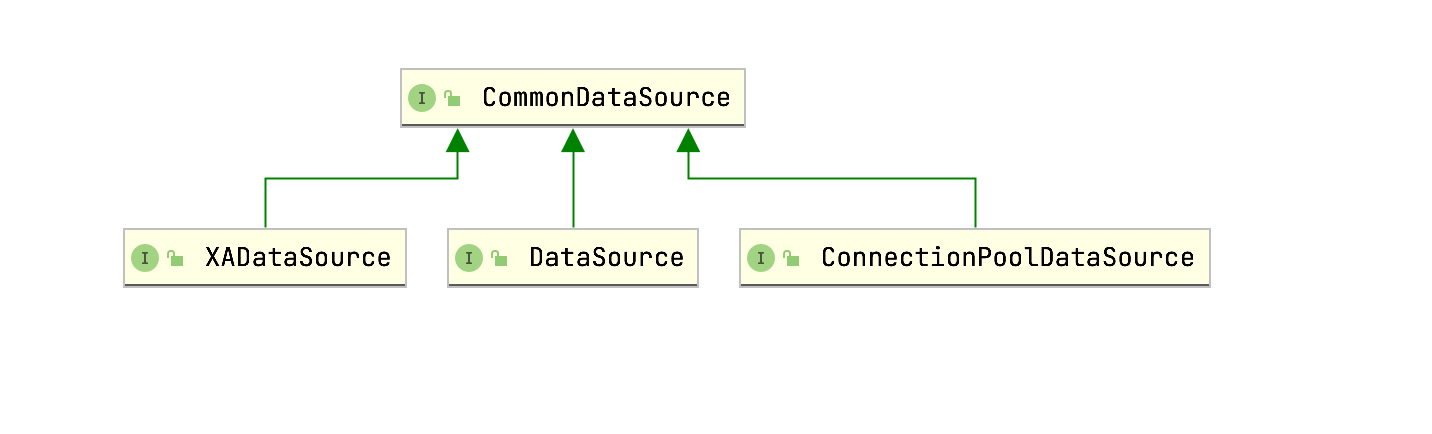
Among them, DataSource is the officially defined basic interface for obtaining Connection, XADataSource is used to obtain Connection in distributed transaction environment, and ConnectionPoolDataSource is the interface for obtaining Connection from ConnectionPool.
The so-called ConnectionPool is equivalent to generating a batch of connections in advance and storing them in the pool, so as to improve the efficiency of Connection acquisition.
In the JDBC specification, in addition to DataSource, core objects such as Connection, Statement and ResultSet also inherit the Wrapper interface.
As a basic component, it also does not need developers to implement DataSource themselves, because there are many excellent implementation schemes in the industry, such as DBCP, C3P0 and Druid.
The purpose of DataSource is to get the connection object. We can understand connection as a Session mechanism. Connection represents a database connection and is responsible for completing the communication with the database.
All SQL execution is carried out in a specific Connection environment. At the same time, it also provides a set of overloaded methods for creating Statement and PreparedStatement respectively. On the other hand, Connection also involves transaction related operations.
There are many methods defined in the Connection interface. The core methods are as follows:
public interface Connection extends Wrapper, AutoCloseable {
//Create Statement
Statement createStatement() throws SQLException;
//Create PreparedStatement
PreparedStatement prepareStatement(String sql) throws SQLException;
//Submit
void commit() throws SQLException;
//RollBACK
void rollback() throws SQLException;
//Close connection
void close() throws SQLException;
}
Statement/PreparedStatement
There are two types of statements in the JDBC specification. One is an ordinary Statement, and the other is a PreparedStatement that supports precompiling.
Precompiling means that the database compiler will compile SQL statements in advance, and then cache the precompiled results into the database. During the next execution, you can replace parameters and directly use the compiled statements, so as to greatly improve the execution efficiency of SQL.
Of course, this precompiling also requires a certain cost. Therefore, in daily development, if only one-time read and write operations are performed on the database, it is more appropriate to use the Statement object for processing; When multiple executions of SQL statements are involved, we can use PreparedStatement.
If we need to query the data in the database, we only need to call the executeQuery method of the Statement or PreparedStatement object.
This method takes the SQL Statement as a parameter and returns a JDBC ResultSet object after execution. Of course, Statement or PreparedStatement also provides a large number of overloaded methods to execute SQL updates and queries. We do not intend to expand them one by one.
Taking Statement as an example, its core method is as follows:
public interface Statement extends Wrapper, AutoCloseable {
//Execute query statement
ResultSet executeQuery(String sql) throws SQLException;
//Execute UPDATE statement
int executeUpdate(String sql) throws SQLException;
//Execute SQL statement
boolean execute(String sql) throws SQLException;
//Execute batch
int[] executeBatch() throws SQLException;
}
ResultSet
Once we execute the SQL Statement through Statement or PreparedStatement and obtain the ResultSet object, we can use a large number of tools and methods defined in the object to obtain the SQL execution result value, as shown in the following code:
public interface ResultSet extends Wrapper, AutoCloseable {
//Get next result
boolean next() throws SQLException;
//Gets the result value of a type
Value getXXX(int columnIndex) throws SQLException;
...
}
ResultSet provides the next() method to facilitate developers to traverse the entire result set. If the next() method returns true, it means that there is data in the result set. You can call a series of getXXX() methods of the ResultSet object to obtain the corresponding result value.
How to use JDBC specification to access database?
For developers, JDBC API is the main way for us to access the database. If we use JDBC to develop an execution process for accessing the database, the common code styles are as follows (exception handling is omitted):
// Create pooled data sources
PooledDataSource dataSource = new PooledDataSource ();
// Set MySQL Driver
dataSource.setDriver ("com.mysql.jdbc.Driver");
// Set the database URL, user name, and password
dataSource.setUrl ("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root");
// Get connection
Connection connection = dataSource.getConnection();
// Execute query
PreparedStatement statement = connection.prepareStatement ("select * from user");
// Get query results for processing
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
...
}
// close resource
statement.close();
resultSet.close();
connection.close();
This code completes the data access based on the core programming objects in the JDBC API described above. The above code is mainly for the query scenario. For the processing scenario for inserting data, we only need to replace a few lines of code in the above code, that is, replace the query operation code in the "execute query" and "obtain query results for processing" parts with the insertion operation code.
For the code examples described above, we clearly divide the operation of accessing relational database based on JDBC specification into two parts: one is to prepare and release resources and execute SQL statements, and the other is to process SQL execution results.
For any data access, the former is actually repeated. In the whole development process shown in the figure above, in fact, only the code of "processing ResultSet" needs to be customized by developers according to specific business objects. This abstraction provides optimization space for the whole execution process. Template tool classes such as JdbcTemplate in Spring framework came into being
2, JdbcTemplate
2.1 use
To use the JdbcTemplate in the application, we need to first introduce the dependency on it, as shown in the following code:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
JdbcTemplate provides a series of query, update and execute overloaded methods to deal with CRUD operations of data.
@Service
public class UserServiceImpl implements UserService {
final
JdbcTemplate jdbcTemplate;
final
SimpleJdbcInsert simpleJdbcInsert;
public UserServiceImpl(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
// user table specified here
this.simpleJdbcInsert = new SimpleJdbcInsert(jdbcTemplate).withTableName("user");
}
@Override
public List<User> listUser() {
String sql = "select id,name,age from user";
RowMapper<User> rowMapper =
new BeanPropertyRowMapper<>(User.class);
return jdbcTemplate.query(sql,rowMapper);
}
@Override
public int insertUser(User user) {
Map map = JSON.parseObject(JSON.toJSONString(user), Map.class);
return simpleJdbcInsert.execute(map);
}
@Override
public int updateUser(User user) {
String sql = "update user set name= ?, age = ? where id = ?";
return jdbcTemplate.update(sql,new Object[]{user.getName(),user.getAge(),user.getId()});
}
@Override
public int deleteUser(String id) {
String sql = "delete from user where id = ?";
return jdbcTemplate.update(sql,new Object[]{id});
}
}
2.2 principle analysis
The detailed implementation process of relational database access is completed by using the JdbcTemplate template tool class. The JdbcTemplate not only simplifies the database operation, but also avoids the code complexity and redundancy caused by using native JDBC.
So how does the JdbcTemplate implement encapsulation based on JDBC? Today, I will lead you to discuss the evolution process from JDBC API to JdbcTemplate from the design idea, and analyze some core source codes of JdbcTemplate.
Let's directly look at the execute(StatementCallback action) method of the JdbcTemplate, as shown in the following code:
public <T> T execute(StatementCallback<T> action) throws DataAccessException {
Assert.notNull(action, "Callback object must not be null");
Connection con = DataSourceUtils.getConnection(obtainDataSource());
Statement stmt = null;
try {
stmt = con.createStatement();
applyStatementSettings(stmt);
T result = action.doInStatement(stmt);
handleWarnings(stmt);
return result;
}
catch (SQLException ex) {
String sql = getSql(action);
JdbcUtils.closeStatement(stmt);
stmt = null;
DataSourceUtils.releaseConnection(con, getDataSource());
con = null;
throw translateException("StatementCallback", sql, ex);
}
finally {
JdbcUtils.closeStatement(stmt);
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
As can be seen from the above code, the execute method receives a StatementCallback callback interface, and then completes the execution of the SQL Statement by passing in the Statement object
StatementCallback callback interface definition code is as follows:
public interface StatementCallback<T> {
T doInStatement(Statement stmt) throws SQLException, DataAccessException;
}
public void execute(final String sql) throws DataAccessException {
if (logger.isDebugEnabled()) {
logger.debug("Executing SQL statement [" + sql + "]");
}
class ExecuteStatementCallback implements StatementCallback<Object>, SqlProvider {
@Override
@Nullable
public Object doInStatement(Statement stmt) throws SQLException {
stmt.execute(sql);
return null;
}
@Override
public String getSql() {
return sql;
}
}
execute(new ExecuteStatementCallback());
}