The previous article introduced Execution plan in TiDB , this article will continue to introduce the SQL optimization process in TiDB, and understand the implementation logic of TiDB optimizer from the two stages of logical optimization and physical optimization.
1. SQL optimization process
SQL optimization in TiDB is divided into two stages: logical optimization and physical optimization: in the process of logical optimization, traverse the optimization rules defined and implemented internally, constantly adjust the logical execution plan of SQL, and make some logical equivalent changes to queries, which is called rule-based optimization (RBO); Physical optimization is to turn the rewritten logical execution plan into an executable physical execution plan, which requires some statistical information. This process will determine the specific method of execution operations, such as what index to read the table and what algorithm to do the Join operation. It is called cost based optimization CBO (cost based optimization).
1.1 logic optimization
1.1.1 introduction to basic logic operators
The logic operators in TiDB mainly include the following:
- DataSource: data source, such as t in from t in SQL
- Selection: represents the corresponding filter conditions, such as where a = 5 in the where predicate sentence in SQL
- Projection: projection operation, which is also used for expression calculation. For example, select c, a + b from t. c and a + b are projection and expression calculation operations
- Join: join two tables, such as select T1 b, t2. c from t1 join t2 on t1. a = t2. T1 join T2 on T1 in a a = t2. A is the connection operation of two tables T1 and T2. Join has internal connection, left connection, right connection and other connection modes.
Selection, Projection and Join (SPJ for short) are the three most basic operators.
1.1.2 common logic optimization rules
Logical optimization is rule-based optimization. By applying optimization rules to the input logical execution plan in order, the whole logical execution plan becomes more efficient. These common logic optimization rules include:
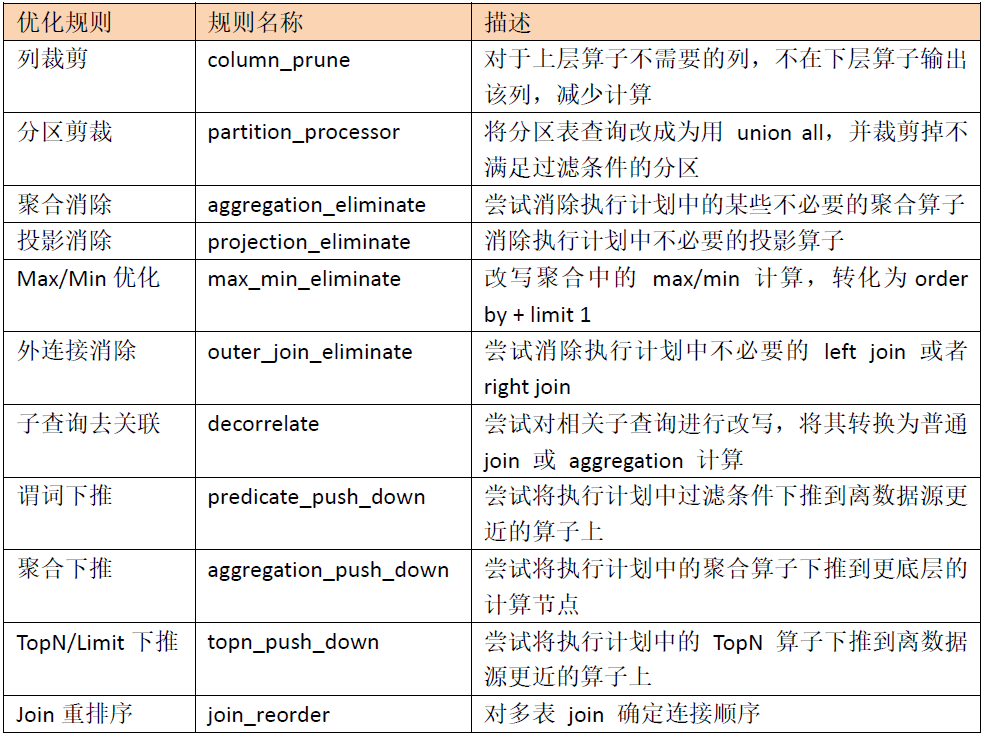
1) Column clipping
The basic idea of column clipping is that for the columns that are not actually used in the operator, the optimizer deletes these columns in the optimization process to reduce the occupation of I/O resources. Suppose there are four columns a, B, C, D in table t, execute the following statement:
select a from t where b > 5
In the process of this query, only columns a and b of the t table are actually used, and the data of C and D are not used. In the query plan of this statement, the Selection operator will use column b, the next DataSource operator will use columns a and b, and the remaining columns C and d do not need to be read in when reading data.
For the above considerations, TiDB will perform top-down scanning in the logic optimization stage to cut unnecessary columns and reduce resource waste. This scanning process is called "column pruning", which corresponds to the columnPruner in the logic optimization rule.
2) Partition clipping
Partition clipping is to optimize the partition table. By analyzing the filter conditions in the query statement, only the partitions that may meet the conditions are selected, so as to reduce the amount of calculated data.
- Scenes that can be cropped using partitions on the Hash partition table
Only the query criteria of equivalence comparison can support the clipping of Hash partition table, as shown below:
mysql> create table t1 (x int) partition by hash(x) partitions 4; mysql> explain select * from t1 where x = 1; +-------------------------+----------+-----------+------------------------+--------------------------------+ | id | estRows | task | access object | operator info | +-------------------------+----------+-----------+------------------------+--------------------------------+ | TableReader_8 | 10.00 | root | | data:Selection_7 | | └─Selection_7 | 10.00 | cop[tikv] | | eq(tango.t1.x, 1) | | └─TableFullScan_6 | 10000.00 | cop[tikv] | table:t1, partition:p1 | keep order:false, stats:pseudo | +-------------------------+----------+-----------+------------------------+--------------------------------+
In the above SQL, you can know that all results are on one partition by the condition x = 1. After Hash, the value 1 can be determined to be in partition p1. Therefore, it is only necessary to scan partition p1 without accessing partitions p2, p3 and p4 where relevant results will not appear. From the execution plan, there is only one TableFullScan operator, and p1 partition is specified in access object. Confirm that partition pruning takes effect.
- Scenes that cannot be cropped on a Hash partition
Scenario 1: using query criteria such as in, between, > < > = < = cannot determine that the query result is only on one partition, and the optimization of partition clipping cannot be used
mysql> explain select * from t1 where x >2; +------------------------------+----------+-----------+------------------------+--------------------------------+ | id | estRows | task | access object | operator info | +------------------------------+----------+-----------+------------------------+--------------------------------+ | Union_10 | 13333.33 | root | | | | ├─TableReader_13 | 3333.33 | root | | data:Selection_12 | | │ └─Selection_12 | 3333.33 | cop[tikv] | | gt(tango.t1.x, 2) | | │ └─TableFullScan_11 | 10000.00 | cop[tikv] | table:t1, partition:p0 | keep order:false, stats:pseudo | | ├─TableReader_16 | 3333.33 | root | | data:Selection_15 | | │ └─Selection_15 | 3333.33 | cop[tikv] | | gt(tango.t1.x, 2) | | │ └─TableFullScan_14 | 10000.00 | cop[tikv] | table:t1, partition:p1 | keep order:false, stats:pseudo | | ├─TableReader_19 | 3333.33 | root | | data:Selection_18 | | │ └─Selection_18 | 3333.33 | cop[tikv] | | gt(tango.t1.x, 2) | | │ └─TableFullScan_17 | 10000.00 | cop[tikv] | table:t1, partition:p2 | keep order:false, stats:pseudo | | └─TableReader_22 | 3333.33 | root | | data:Selection_21 | | └─Selection_21 | 3333.33 | cop[tikv] | | gt(tango.t1.x, 2) | | └─TableFullScan_20 | 10000.00 | cop[tikv] | table:t1, partition:p3 | keep order:false, stats:pseudo | +------------------------------+----------+-----------+------------------------+--------------------------------+
Scenario 2: because the rule optimization of partition clipping is in the generation stage of query plan, the optimization of partition clipping cannot be used for scenarios where the filter conditions can only be obtained in the execution stage. For example, the following scenarios:
mysql> explain select * from t2 where x = (select * from t1 where t2.x = t1.x and t2.x < 2); +--------------------------------------+----------+-----------+------------------------+------------------------------------------------+ | id | estRows | task | access object | operator info | +--------------------------------------+----------+-----------+------------------------+------------------------------------------------+ | Projection_20 | 39960.00 | root | | tango.t2.x | | └─Apply_22 | 39960.00 | root | | inner join, equal:[eq(tango.t2.x, tango.t1.x)] | | ├─Union_23(Build) | 39960.00 | root | | | | │ ├─TableReader_26 | 9990.00 | root | | data:Selection_25 | | │ │ └─Selection_25 | 9990.00 | cop[tikv] | | not(isnull(tango.t2.x)) | | │ │ └─TableFullScan_24 | 10000.00 | cop[tikv] | table:t2, partition:p0 | keep order:false, stats:pseudo | | │ ├─TableReader_29 | 9990.00 | root | | data:Selection_28 | | │ │ └─Selection_28 | 9990.00 | cop[tikv] | | not(isnull(tango.t2.x)) | | │ │ └─TableFullScan_27 | 10000.00 | cop[tikv] | table:t2, partition:p1 | keep order:false, stats:pseudo | | │ ├─TableReader_32 | 9990.00 | root | | data:Selection_31 | | │ │ └─Selection_31 | 9990.00 | cop[tikv] | | not(isnull(tango.t2.x)) | | │ │ └─TableFullScan_30 | 10000.00 | cop[tikv] | table:t2, partition:p2 | keep order:false, stats:pseudo | | │ └─TableReader_35 | 9990.00 | root | | data:Selection_34 | | │ └─Selection_34 | 9990.00 | cop[tikv] | | not(isnull(tango.t2.x)) | | │ └─TableFullScan_33 | 10000.00 | cop[tikv] | table:t2, partition:p3 | keep order:false, stats:pseudo | | └─Selection_36(Probe) | 0.80 | root | | not(isnull(tango.t1.x)) | | └─MaxOneRow_37 | 1.00 | root | | | | └─Union_38 | 2.00 | root | | | | ├─TableReader_41 | 2.00 | root | | data:Selection_40 | | │ └─Selection_40 | 2.00 | cop[tikv] | | eq(tango.t2.x, tango.t1.x), lt(tango.t2.x, 2) | | │ └─TableFullScan_39 | 2500.00 | cop[tikv] | table:t1, partition:p0 | keep order:false, stats:pseudo | | ├─TableReader_44 | 2.00 | root | | data:Selection_43 | | │ └─Selection_43 | 2.00 | cop[tikv] | | eq(tango.t2.x, tango.t1.x), lt(tango.t2.x, 2) | | │ └─TableFullScan_42 | 2500.00 | cop[tikv] | table:t1, partition:p1 | keep order:false, stats:pseudo | | ├─TableReader_47 | 2.00 | root | | data:Selection_46 | | │ └─Selection_46 | 2.00 | cop[tikv] | | eq(tango.t2.x, tango.t1.x), lt(tango.t2.x, 2) | | │ └─TableFullScan_45 | 2500.00 | cop[tikv] | table:t1, partition:p2 | keep order:false, stats:pseudo | | └─TableReader_50 | 2.00 | root | | data:Selection_49 | | └─Selection_49 | 2.00 | cop[tikv] | | eq(tango.t2.x, tango.t1.x), lt(tango.t2.x, 2) | | └─TableFullScan_48 | 2500.00 | cop[tikv] | table:t1, partition:p3 | keep order:false, stats:pseudo | +--------------------------------------+----------+-----------+------------------------+------------------------------------------------+
- Scenes that can be cropped using partitions on the Range partition table
- Query criteria for equivalence comparison, such as x=1 or x in (1,2)
- Query criteria for interval comparison, such as between, > < = > =<=
- The partition expression is a simple form of fn(col), the query condition is one of > < = > = < = and fn is a monotonic function
Take the second case as an example:
mysql> create table t_r1 (x int) partition by range (x) (
-> partition p0 values less than (5),
-> partition p1 values less than (10),
-> partition p2 values less than (15)
-> );
Query OK, 0 rows affected (1.11 sec)
mysql> explain select * from t_r1 where x between 7 and 14;
+-----------------------------+----------+-----------+--------------------------+-------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+----------+-----------+--------------------------+-------------------------------------------+
| Union_8 | 500.00 | root | | |
| ├─TableReader_11 | 250.00 | root | | data:Selection_10 |
| │ └─Selection_10 | 250.00 | cop[tikv] | | ge(tango.t_r1.x, 7), le(tango.t_r1.x, 14) |
| │ └─TableFullScan_9 | 10000.00 | cop[tikv] | table:t_r1, partition:p1 | keep order:false, stats:pseudo |
| └─TableReader_14 | 250.00 | root | | data:Selection_13 |
| └─Selection_13 | 250.00 | cop[tikv] | | ge(tango.t_r1.x, 7), le(tango.t_r1.x, 14) |
| └─TableFullScan_12 | 10000.00 | cop[tikv] | table:t_r1, partition:p2 | keep order:false, stats:pseudo |
+-----------------------------+----------+-----------+--------------------------+-------------------------------------------+
- The Range partition table cannot use the scene cropped by partition
Because the rule optimization of partition clipping is in the generation stage of query plan, the optimization of partition clipping cannot be used for scenarios where the filter conditions can only be obtained in the execution stage.
mysql> create table t_r2 (x int); mysql> explain select * from t_r2 where x < (select * from t_r1 where t_r2.x < t_r1.x and t_r2.x < 2); +--------------------------------------+----------+-----------+--------------------------+-----------------------------------------------------------------+ | id | estRows | task | access object | operator info | +--------------------------------------+----------+-----------+--------------------------+-----------------------------------------------------------------+ | Projection_14 | 9990.00 | root | | tango.t_r2.x | | └─Apply_16 | 9990.00 | root | | CARTESIAN inner join, other cond:lt(tango.t_r2.x, tango.t_r1.x) | | ├─TableReader_19(Build) | 9990.00 | root | | data:Selection_18 | | │ └─Selection_18 | 9990.00 | cop[tikv] | | not(isnull(tango.t_r2.x)) | | │ └─TableFullScan_17 | 10000.00 | cop[tikv] | table:t_r2 | keep order:false, stats:pseudo | | └─Selection_20(Probe) | 0.80 | root | | not(isnull(tango.t_r1.x)) | | └─MaxOneRow_21 | 1.00 | root | | | | └─Union_22 | 2.00 | root | | | | ├─TableReader_25 | 2.00 | root | | data:Selection_24 | | │ └─Selection_24 | 2.00 | cop[tikv] | | lt(tango.t_r2.x, 2), lt(tango.t_r2.x, tango.t_r1.x) | | │ └─TableFullScan_23 | 2.50 | cop[tikv] | table:t_r1, partition:p0 | keep order:false, stats:pseudo | | ├─TableReader_28 | 2.00 | root | | data:Selection_27 | | │ └─Selection_27 | 2.00 | cop[tikv] | | lt(tango.t_r2.x, 2), lt(tango.t_r2.x, tango.t_r1.x) | | │ └─TableFullScan_26 | 2.50 | cop[tikv] | table:t_r1, partition:p1 | keep order:false, stats:pseudo | | └─TableReader_31 | 2.00 | root | | data:Selection_30 | | └─Selection_30 | 2.00 | cop[tikv] | | lt(tango.t_r2.x, 2), lt(tango.t_r2.x, tango.t_r1.x) | | └─TableFullScan_29 | 2.50 | cop[tikv] | table:t_r1, partition:p2 | keep order:false, stats:pseudo | +--------------------------------------+----------+-----------+--------------------------+-----------------------------------------------------------------+
3) Max/Min optimization
When an SQL statement in TiDB contains a max/min function and the aggregate function does not have a corresponding group by statement, the query optimizer attempts to convert the max/min aggregate function into a TopN operator, so as to effectively use the index for query. For example:
select max(a) from t
At this time, the max/min elimination optimization rule will rewrite it as:
select max(a) from (select a from t where a is not null order by a desc limit 1) t
When there is an index in column a (or column A is the prefix of a joint index), this new SQL statement can use the index to scan only one row of data to get the maximum or minimum value, so as to avoid scanning the whole table.
mysql> create table tt1 (a int(11),b float,key idx1(a)); mysql> explain select max(a) from tt1; +------------------------------+---------+-----------+--------------------------+-------------------------------------+ | id | estRows | task | access object | operator info | +------------------------------+---------+-----------+--------------------------+-------------------------------------+ | StreamAgg_13 | 1.00 | root | | funcs:max(tango.tt1.a)->Column#4 | | └─Limit_17 | 1.00 | root | | offset:0, count:1 | | └─IndexReader_27 | 1.00 | root | | index:Limit_26 | | └─Limit_26 | 1.00 | cop[tikv] | | offset:0, count:1 | | └─IndexFullScan_25 | 1.00 | cop[tikv] | table:tt1, index:idx1(a) | keep order:true, desc, stats:pseudo | +------------------------------+---------+-----------+--------------------------+-------------------------------------+ 5 rows in set (0.01 sec)
If the group by statement is used:
mysql> explain select b,max(a) from tt1 group by b; +-----------------------------+----------+-----------+---------------+-----------------------------------------------------------------------------------------------+ | id | estRows | task | access object | operator info | +-----------------------------+----------+-----------+---------------+-----------------------------------------------------------------------------------------------+ | Projection_4 | 8000.00 | root | | tango.tt1.b, Column#4 | | └─HashAgg_9 | 8000.00 | root | | group by:tango.tt1.b, funcs:max(Column#5)->Column#4, funcs:firstrow(tango.tt1.b)->tango.tt1.b | | └─TableReader_10 | 8000.00 | root | | data:HashAgg_5 | | └─HashAgg_5 | 8000.00 | cop[tikv] | | group by:tango.tt1.b, funcs:max(tango.tt1.a)->Column#5 | | └─TableFullScan_8 | 10000.00 | cop[tikv] | table:tt1 | keep order:false, stats:pseudo | +-----------------------------+----------+-----------+---------------+-----------------------------------------------------------------------------------------------+
4) Predicate push down
Predicate push down is to push down the calculation of the filter expression in the query statement to the nearest place to the data source as far as possible, so as to complete the data filtering as soon as possible, so as to significantly reduce the overhead of data transmission or calculation.
- Predicate push down to storage tier
mysql> CREATE TABLE `tt01` (`id` int(11) NOT NULL AUTO_INCREMENT,a int,`city` varchar(20) NOT NULL DEFAULT '',PRIMARY KEY (`id`)); mysql> explain select * from tt01 where a<10 ; +-------------------------+----------+-----------+---------------+--------------------------------+ | id | estRows | task | access object | operator info | +-------------------------+----------+-----------+---------------+--------------------------------+ | TableReader_7 | 3323.33 | root | | data:Selection_6 | | └─Selection_6 | 3323.33 | cop[tikv] | | lt(tango.tt01.a, 10) | | └─TableFullScan_5 | 10000.00 | cop[tikv] | table:tt01 | keep order:false, stats:pseudo | +-------------------------+----------+-----------+---------------+--------------------------------+
In this query, the predicate ID < 10 is pushed down to the TiKV to filter the data, which can reduce the overhead caused by network transmission.
- The predicate is pushed down below the join
mysql> explain select * from tt01 join tt02 on tt01.a= tt02.a where tt01.a < 1; +------------------------------+----------+-----------+---------------+----------------------------------------------------+ | id | estRows | task | access object | operator info | +------------------------------+----------+-----------+---------------+----------------------------------------------------+ | HashJoin_8 | 4154.17 | root | | inner join, equal:[eq(tango.tt01.a, tango.tt02.a)] | | ├─TableReader_15(Build) | 3323.33 | root | | data:Selection_14 | | │ └─Selection_14 | 3323.33 | cop[tikv] | | lt(tango.tt02.a, 1), not(isnull(tango.tt02.a)) | | │ └─TableFullScan_13 | 10000.00 | cop[tikv] | table:tt02 | keep order:false, stats:pseudo | | └─TableReader_12(Probe) | 3323.33 | root | | data:Selection_11 | | └─Selection_11 | 3323.33 | cop[tikv] | | lt(tango.tt01.a, 1), not(isnull(tango.tt01.a)) | | └─TableFullScan_10 | 10000.00 | cop[tikv] | table:tt01 | keep order:false, stats:pseudo | +------------------------------+----------+-----------+---------------+----------------------------------------------------+
In this query, the predicate tt01 A < 1 is pushed down to the join for filtering, which can reduce the computational overhead during the join.
1.2 physical optimization
Physical optimization is cost based optimization (CBO). In this stage, the optimizer will select a specific physical implementation for each operator in the logical execution plan to convert the logical execution plan generated in the logical optimization stage into a physical execution plan. Different physical implementations of logical operators are also different in time complexity, resource consumption and physical attributes. In this process, the optimizer will determine the cost of different physical implementations according to the statistical information of the data, and select the physical execution plan with the lowest overall cost. Many decisions need to be made for physical optimization, such as:
- How to read data is to use full table scan or read data through index
- If there are multiple indexes, which index to select
- The physical implementation of logical operators, that is, the algorithm actually used
- Can operators be pushed down to the storage layer for execution to improve execution efficiency
1.2.1 index selection
When selecting an index, TiDB will estimate the cost of each table reading operator (TableReader/IndexReader/IndexLookUp). On this basis, it provides a heuristic rule "skyline pruning" to reduce the probability of wrong index selection caused by wrong estimation.
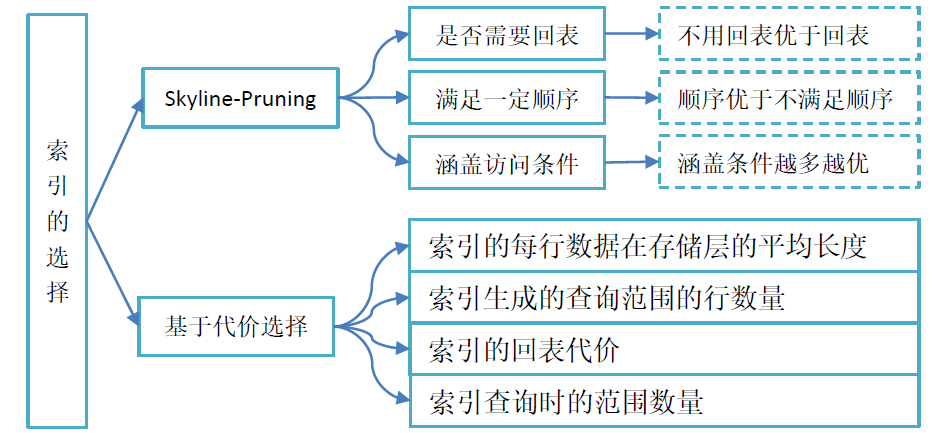
1)Skyline-Pruning
Skyline pruning is a heuristic filtering rule for indexes. The quality of an index needs to be measured from the following three dimensions:
- Whether to return to the table (that is, whether the plan generated by the index is IndexReader or IndexLookupReader). The index without returning to the table is better than the index requiring returning to the table in this dimension.
- Whether it can meet a certain order. Because the reading of the index can ensure the order of some column sets, the index that meets the query requirements is better than the index that does not meet the query requirements in this dimension.
- How many access conditions are covered by the columns of the index. "Access condition" refers to the where condition that can be converted into a column range. If the column set of an index covers more access conditions, it is better in this dimension.
2) Cost based selection
The following aspects need to be considered in the cost estimation of meter reading:
- The average length of each row of data in the storage layer of the index
- The number of rows in the query range generated by the index
- Back to table cost of index
- Number of ranges when indexing queries
According to these factors and cost models, the optimizer will select an index with the lowest cost to read the table.
1.2.2 collection and maintenance of statistical information
Statistics maintained in TiDB include the total number of rows in the table, the contour histogram of columns, count min sketch, the number of Null values, the average length, the number of different values, and so on.
1) Manual collection
The ANALYZE statement is used in TiDB to collect statistical information, which is divided into full collection and incremental collection.
- Full collection
#Collect statistics for all tables in TableNameList: ANALYZE TABLE TableNameList #Collect statistics of index columns in all indexnamelists in TableName ANALYZE TABLE TableName INDEX [IndexNameList] #Collect statistics of all partitions in PartitionNameList in TableName ANALYZE TABLE TableName PARTITION PartitionNameList #Collect index column statistics of all partitions in PartitionNameList in TableName ANALYZE TABLE TableName PARTITION PartitionNameList [IndexNameList]
- Incremental collection
After full collection, incremental collection can be used to analyze the newly added parts separately to improve the speed of analysis. At present, only index provides the function of incremental collection.
#Incrementally collect statistics of index columns in all indexnamelists in TableName ANALYZE INCREMENTAL TABLE TableName INDEX [IndexNameList] #Incrementally collect index column statistics of all partitions in PartitionNameList in TableName ANALYZE INCREMENTAL TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList]
2) Automatic update
When the DML statement is executed, TiDB will automatically update the total number of rows in the table and the number of modified rows. This information will be automatically persisted on a regular basis, and the update cycle is 1 minute by default (20 * stats lease). The default value of stats lease is 3s. If it is specified as 0, it will not be updated automatically. The three system variables related to the automatic update of statistical information are as follows:
mysql> show variables like 'tidb_auto_analyze%'; +------------------------------+-------------+ | Variable_name | Value | +------------------------------+-------------+ | tidb_auto_analyze_ratio | 0.5 | | tidb_auto_analyze_start_time | 00:00 +0000 | | tidb_auto_analyze_end_time | 23:59 +0000 | +------------------------------+-------------+
When the ratio of the number of modified rows to the total number of rows in a table TBL is greater than tidb_auto_analyze_ratio, and the current time is in tidb_auto_analyze_start_time and tidb_auto_analyze_end_time, TiDB will execute the ANALYZE TABLE tbl statement in the background to automatically update the statistics of this table.

3) Control analyze concurrency
When executing the ANALYZE statement, you can adjust the concurrency through some parameters to control the impact on the system
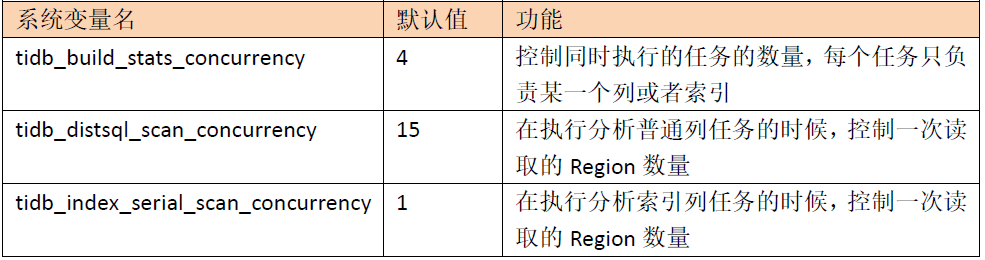
4) View the status of Analyze
mysql> show analyze status; +--------------+------------+----------------+--------------------------+----------------+---------------------+----------+ | Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | State | +--------------+------------+----------------+--------------------------+----------------+---------------------+----------+ | bikeshare | trips | | analyze index start_date | 340000 | 2021-03-14 13:59:38 | finished | | bikeshare | trips | | analyze columns | 340000 | 2021-03-14 13:59:38 | running | +--------------+------------+----------------+--------------------------+----------------+---------------------+----------+ 2 rows in set (0.00 sec)
5) Viewing statistics
- To view statistics and meta information of a table:
mysql> show stats_meta where table_name = 'trips'; +-----------+------------+----------------+---------------------+--------------+-----------+ | Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count | +-----------+------------+----------------+---------------------+--------------+-----------+ | bikeshare | trips | | 2021-03-14 22:23:19 | 0 | 340000 | +-----------+------------+----------------+---------------------+--------------+-----------+ 1 row in set (0.08 sec)
- Health information of table
Through show stats_ Health can view the statistical information health of the table and roughly estimate the accuracy of the statistical information on the table. When modify_ count >= row_ When count, the health degree is 0; When modify_ count < row_ When count, the health is (1 - modify_count/row_count) * 100.
mysql> show stats_healthy where table_name = 'trips'; +-----------+------------+----------------+---------+ | Db_name | Table_name | Partition_name | Healthy | +-----------+------------+----------------+---------+ | bikeshare | trips | | 100 | +-----------+------------+----------------+---------+ 1 row in set (0.00 sec)
- Through SHOW STATS_HISTOGRAMS to view information such as the number of different values and the number of nulls in a column
mysql> show stats_histograms where table_name = 'trips'; +-----------+------------+----------------+-------------+----------+---------------------+----------------+------------+--------------+-------------+ | Db_name | Table_name | Partition_name | Column_name | Is_index | Update_time | Distinct_count | Null_count | Avg_col_size | Correlation | +-----------+------------+----------------+-------------+----------+---------------------+----------------+------------+--------------+-------------+ | bikeshare | trips | | trip_id | 0 | 2021-03-14 13:59:45 | 340000 | 0 | 8 | 0 | | bikeshare | trips | | start_date | 1 | 2021-03-14 13:59:41 | 167954 | 0 | 0 | 0 | +-----------+------------+----------------+-------------+----------+---------------------+----------------+------------+--------------+-------------+ 2 rows in set (0.00 sec)
- Through SHOW STATS_BUCKETS to view the histogram information of each bucket
mysql> show stats_buckets where table_name='tt03'; +---------+------------+----------------+-------------+----------+-----------+-------+---------+-------------+-------------+ | Db_name | Table_name | Partition_name | Column_name | Is_index | Bucket_id | Count | Repeats | Lower_Bound | Upper_Bound | +---------+------------+----------------+-------------+----------+-----------+-------+---------+-------------+-------------+ | tango | tt03 | | a | 0 | 0 | 1 | 1 | 1 | 1 | | tango | tt03 | | idx_a | 1 | 0 | 1 | 1 | 1 | 1 | | tango | tt03 | | idx_b | 1 | 0 | 1 | 1 | 1 | 1 | +---------+------------+----------------+-------------+----------+-----------+-------+---------+-------------+-------------+ 3 rows in set (0.00 sec)
6) Delete statistics
Delete statistics by executing the DROP STATS statement
mysql> show stats_meta where table_name = 'tt03'; +---------+------------+----------------+---------------------+--------------+-----------+ | Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count | +---------+------------+----------------+---------------------+--------------+-----------+ | tango | tt03 | | 2021-03-13 23:44:43 | 1 | 2 | +---------+------------+----------------+---------------------+--------------+-----------+ 1 row in set (0.01 sec) mysql> drop stats tango.tt03; Query OK, 0 rows affected (0.18 sec) mysql> show stats_meta where table_name = 'tt03'; Empty set (0.00 sec)
7) Import and export of Statistics
- Statistics Export
The database can be obtained through the following interfaces d b n a m e in of surface Table in {db_name} Statistics of json format of table {table_name} in dbn} ame:
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}
For example, get the statistics of trips table in the bikeshare database:
curl -G "http://192.168.112.101:10080/stats/dump/bikeshare/trips" > trips.json
- Statistics Import
Import the json file obtained from the statistical information export interface into the database:
mysql> LOAD STATS 'file_name';
Execution control plan
When it is determined that there is a problem with the execution plan, the generation of the execution plan can be controlled by the following methods:
- Optimizer Hints uses hint to guide TiDB to generate execution plans. Hint will change SQL intrusively
- Execution plan management controls the generation of execution plans through SQL BINDING, and Baseline Evolution automatically performs execution plans in the background, so as to reduce the instability of execution plans caused by version upgrades and the degradation of cluster performance.
- Optimization rules and expressions push down the blacklist, and manually disable some optimization rules and expressions
1.3.1 use Hint to adjust the implementation plan of TiDB
When the optimizer selects an improper execution plan, it needs to use hint to bind the execution plan. List of hint syntax currently supported by TiDB:
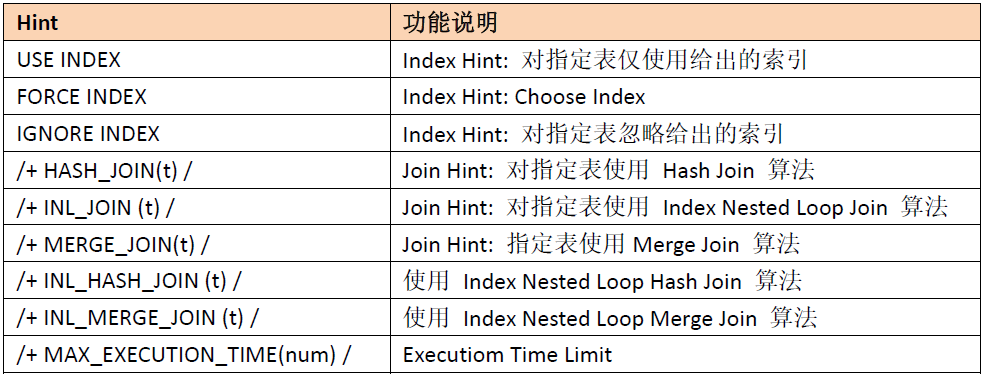
1)USE INDEX,FORCE INDEX,IGNORE INDEX
mysql> explain select count(*) from trips where trip_id>1; +-----------------------------+-----------+-----------+---------------+-----------------------------------+ | id | estRows | task | access object | operator info | +-----------------------------+-----------+-----------+---------------+-----------------------------------+ | StreamAgg_17 | 1.00 | root | | funcs:count(Column#13)->Column#11 | | └─TableReader_18 | 1.00 | root | | data:StreamAgg_9 | | └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#13 | | └─TableRangeScan_16 | 339999.00 | cop[tikv] | table:trips | range:(1,+inf], keep order:false | +-----------------------------+-----------+-----------+---------------+-----------------------------------+ 4 rows in set (0.01 sec) mysql> explain select count(*) from trips use index(start_date) where trip_id>1 ; +------------------------------+-----------+-----------+-------------------------------------------+-----------------------------------+ | id | estRows | task | access object | operator info | +------------------------------+-----------+-----------+-------------------------------------------+-----------------------------------+ | StreamAgg_20 | 1.00 | root | | funcs:count(Column#16)->Column#11 | | └─IndexReader_21 | 1.00 | root | | index:StreamAgg_9 | | └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#16 | | └─Selection_19 | 339999.00 | cop[tikv] | | gt(bikeshare.trips.trip_id, 1) | | └─IndexFullScan_18 | 340000.00 | cop[tikv] | table:trips, index:start_date(start_date) | keep order:false | +------------------------------+-----------+-----------+-------------------------------------------+-----------------------------------+ 5 rows in set (0.03 sec)
2)MAX_EXECUTION_TIME(N)
You can use Max in a SELECT statement_ EXECUTION_ Time (N), which will limit the execution time of the statement to no more than N milliseconds, otherwise the server will terminate the execution of the statement. For example, 1 second timeout is set:
mysql> SELECT /*+ MAX_EXECUTION_TIME(100) */ count(*) FROM trips; ERROR 1317 (70100): Query execution was interrupted
In addition, the environment variable MAX_EXECUTION_TIME also limits the execution time of statements. For highly available and time sensitive services, Max is recommended_ EXECUTION_ Time to avoid incorrect query plans or bug s affecting the performance and even stability of the entire TiDB cluster.
1.3.2 execution plan management SPM
Execution plan management, also known as SPM (SQL Plan Management), is a series of functions for human intervention in execution plan, including execution plan binding, automatic capture binding, automatic evolution binding, etc. Compared with Hint, SPM can intervene in the selection of execution plan without modifying SQL statements.
1) Execute plan binding SQL Binding
SQL Binding is the foundation of SPM. When the execution plan is poor, you can use SQL Binding to quickly repair the execution plan without changing the business.
- Create binding
CREATE [GLOBAL | SESSION] BINDING FOR SelectStmt USING SelectStmt;
This statement can execute the plan for SQL binding within the GLOBAL or SESSION scope. When no scope is specified, the default scope is SESSION. The bound SQL is parameterized and stored in the system table. When processing SQL queries, the corresponding optimizer Hint can be used as long as the parameterized SQL matches a bound SQL in the system table.
#Create a binding mysql> create binding for select count(*) from trips where trip_id>1 using select count(*) from trips use index(start_date) where trip_id>1; Query OK, 0 rows affected (0.11 sec)
- View binding bindings
mysql> show bindings; +-------------------------------------------------+------------------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------------+ | Original_sql | Bind_sql | Default_db | Status | Create_time | Update_time | Charset | Collation | +-------------------------------------------------+------------------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------------+ | select count ( ? ) from trips where trip_id > ? | select count(*) from trips use index(start_date) where trip_id>1 | bikeshare | using | 2021-03-15 18:49:43.069 | 2021-03-15 18:49:43.069 | utf8 | utf8_general_ci | +-------------------------------------------------+------------------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------------+
- Delete bindings
mysql> drop binding for select count(*) from trips where trip_id>1; Query OK, 0 rows affected (0.00 sec)
2) Baseline Capturing
Add tidb_ capture_ plan_ The value of baselines is set to on (the default value is off) to turn on the automatic capture binding function. The automatic binding function depends on the Statement Summary, so you need to turn on the Statement Summary switch before using automatic binding. After the automatic binding function is enabled, the historical SQL statements in the Statement Summary will be traversed every bind info leave (the default value is 3s), and the binding will be automatically captured for the SQL statements that occur at least twice.
# Open statement summary mysql> set tidb_enable_stmt_summary = 1; Query OK, 0 rows affected (0.00 sec) # Enable automatic binding function mysql> set tidb_capture_plan_baselines = 1; Query OK, 0 rows affected (0.01 sec) mysql> select count(*) from trips where trip_id>1; +----------+ | count(*) | +----------+ | 339999 | +----------+ 1 row in set (0.94 sec) # Run the following query twice in a row to automatically create a binding for it mysql> select count(*) from trips where trip_id>1; +----------+ | count(*) | +----------+ | 339999 | +----------+ 1 row in set (0.33 sec) # Check global bindings to find the automatically created bindings mysql> show global bindings; +-------------------------------------------------+---------------------------------------------------------------------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------+ | Original_sql | Bind_sql | Default_db | Status | Create_time | Update_time | Charset | Collation | +-------------------------------------------------+---------------------------------------------------------------------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------+ | select count ( ? ) from trips | SELECT /*+ use_index(@`sel_1` `bikeshare`.`trips` `start_date`), stream_agg(@`sel_1`)*/ COUNT(1) FROM `trips` | bikeshare | using | 2021-03-15 18:09:35.184 | 2021-03-15 18:09:35.184 | | | | select count ( ? ) from trips where trip_id > ? | SELECT /*+ use_index(@`sel_1` `bikeshare`.`trips` ), stream_agg(@`sel_1`)*/ COUNT(1) FROM `trips` WHERE `trip_id`>1 | bikeshare | using | 2021-03-15 18:09:49.584 | 2021-03-15 18:09:49.584 | | | | select * from trips limit ? | SELECT /*+ use_index(@`sel_1` `bikeshare`.`trips` )*/ * FROM `trips` LIMIT 1 | bikeshare | using | 2021-03-15 18:09:36.134 | 2021-03-15 18:09:36.134 | | | +-------------------------------------------------+---------------------------------------------------------------------------------------------------------------------+------------+--------+-------------------------+-------------------------+---------+-----------+ 3 rows in set (0.00 sec)
3) Baseline Evolution binding
After some data changes, the original bound execution plan may be a poor plan. To solve this problem, TiDB introduces the Baseline Evolution function to automatically optimize the bound execution plan. In addition, Baseline Evolution can also avoid the jitter on the implementation plan after the statistical information is changed to a certain extent.
By setting global tidb_evolve_plan_baselines = 1 enables the automatic evolution function. If the optimal execution plan selected by the optimizer is not in the previously bound execution plan, it will be recorded as the execution plan to be verified. Every bind info lease (the default value is 3s), an execution plan to be verified will be selected, and the actual running time will be compared with the least expensive execution plan already bound. If the runtime to be verified is better, it is marked as a usable binding.
In the actual implementation process, in order to reduce the impact of automatic evolution on the cluster, tidb can be used_ evolve_ plan_ task_ max_ Time to limit the maximum running time of each execution plan, and its default value is ten minutes; Through tidb_evolve_plan_task_start_time and tidb_evolve_plan_task_end_time can limit the time window for running evolution tasks. The default time window is all day.
reference material:
- https://book.tidb.io/session3/chapter1/optimizer-summary.html
- https://docs.pingcap.com/zh/tidb/stable/sql-logical-optimization
- https://docs.pingcap.com/zh/tidb/stable/sql-physica3-optimization
Please indicate the original address for Reprint: https://blog.csdn.net/solihawk/article/details/119270226
The article will be synchronized in the official account of "shepherd's direction". Interested parties can official account. Thank you!
