With the emergence of big data and a large number of data systems, data loading has become more and more important. Many jobs even need ETL skills. However, today, data loading is no longer a simple ETL, but also ELT, and even does not need data mobile computing.
This paper first focuses on the traditional ETL. This paper introduces the process and comparison of several kinds of data loading.
General data loading method
The essence of data loading is to insert data into a specific place. Usually, we focus on performance. To be clear, it is the time of completion of insertion and the space consumption caused.
this article and the next two articles will introduce and demonstrate several conventional insertion methods, including:
- INSERT SELECT WITH (TABLOCK)
- Nonclustered column storage index
- In memory with clustered column storage index
INSERT SELECT with(TABLOCK)
In this way, parallel insertion can be realized. The target table can be a clustered column storage index, but it can also be a heap table. But we will focus on the column storage index, because from the previous article, we can see that column storage index is indeed beneficial, and because I am currently using Azure SQL DB, which is already the function of SQL 2019 at the bottom, I will not discuss the heap table for now.
this parallel function has been introduced since SQL 2016, that is to say, 2014 does not have this parallel function. No matter how many cores there are, the index from insert into to clustered column storage is conducted with a single core. At first, the delta store is filled in order until the minimum number of available rows (1048576 rows) of the first available delta store is reached. Then start the next delta store.
in the process of INSERT SELECT, no matter how efficient the SELECT part is, the INSERT performance will become the slowest part. But this design is to ensure that the last delta store will not be completely filled, and then load more data later.
starting from SQL 2016 (compatibility level is 130 or above), when WITH (TABLOCK), parallel insertion can be implemented. According to the current CPU and memory resources, each CPU core corresponds to an independent delta store, which makes data loading faster. In theory, if the capacity and size of the disk is large enough, the more cores there are, the more performance there will be compared to 2014. But as mentioned earlier, in 2014, the last delta store needs to be reorganized. In 2016, there are N delta stores that need to be reorganized. This is its disadvantage, but it can be alleviated by some means, such as reorganizing indexes.
The above version differences also need to consider the compatibility level. If you install SQL 2016 but the compatibility level is less than 130, it is essentially equal to using a version lower than 2016.
Let's use the Contoso retail DW library to demonstrate. First, clean up the primary key and foreign key constraints of FactOnlineSales, and then create a clustered column storage index:
use ContosoRetailDW; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]; create clustered index PK_FactOnlineSales on dbo.FactOnlineSales( OnlineSalesKey ) with ( maxdop = 1); create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales with( drop_existing = on, maxdop = 1 );
then create a test table,
CREATE TABLE [dbo].[FactOnlineSales_CCI]( [OnlineSalesKey] [int] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, INDEX PK_FactOnlineSales_CCI CLUSTERED COLUMNSTORE );
set statistics time, io on; insert into [dbo].[FactOnlineSales_CCI] (OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey) select distinct top 10000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey FROM [dbo].[FactOnlineSales] sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey inner join dbo.DimStore store on sales.StoreKey = store.StoreKey where prod.ProductSubcategoryKey >= 10 and store.StoreManager >= 30 option (recompile);
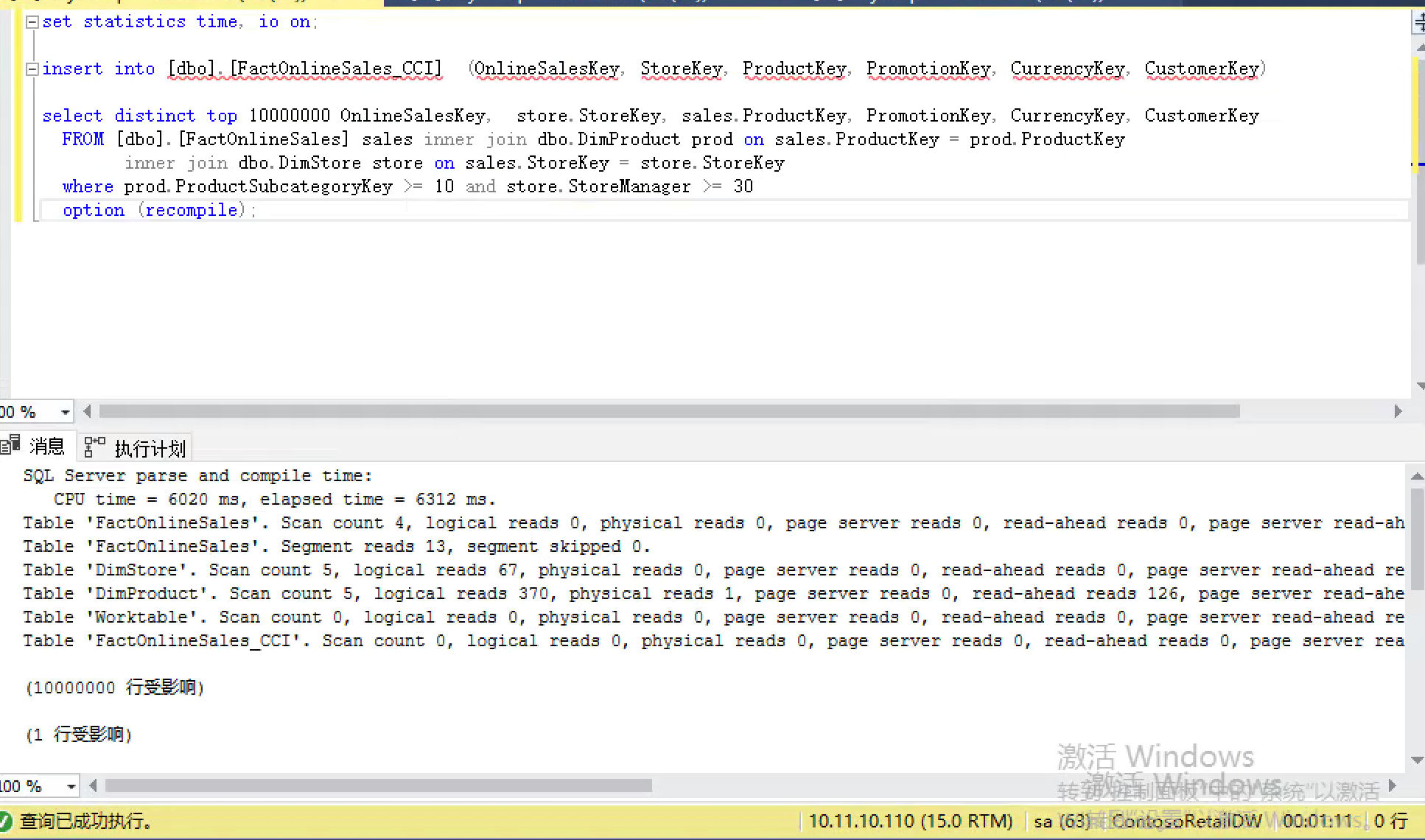
SQL Server parse and compile time: CPU time = 6020 ms, elapsed time = 6312 ms. Table 'FactOnlineSales'. Scan count 4, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 12023, lob physical reads 40, lob page server reads 0, lob read-ahead reads 30079, lob page server read-ahead reads 0. Table 'FactOnlineSales'. Segment reads 13, segment skipped 0. Table 'DimStore'. Scan count 5, logical reads 67, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'DimProduct'. Scan count 5, logical reads 370, physical reads 1, page server reads 0, read-ahead reads 126, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'FactOnlineSales_CCI'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
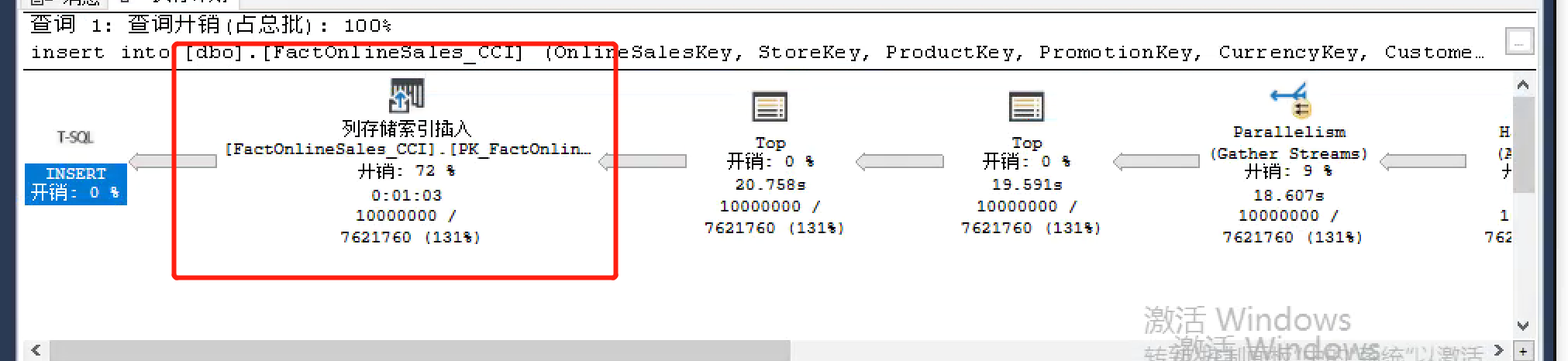
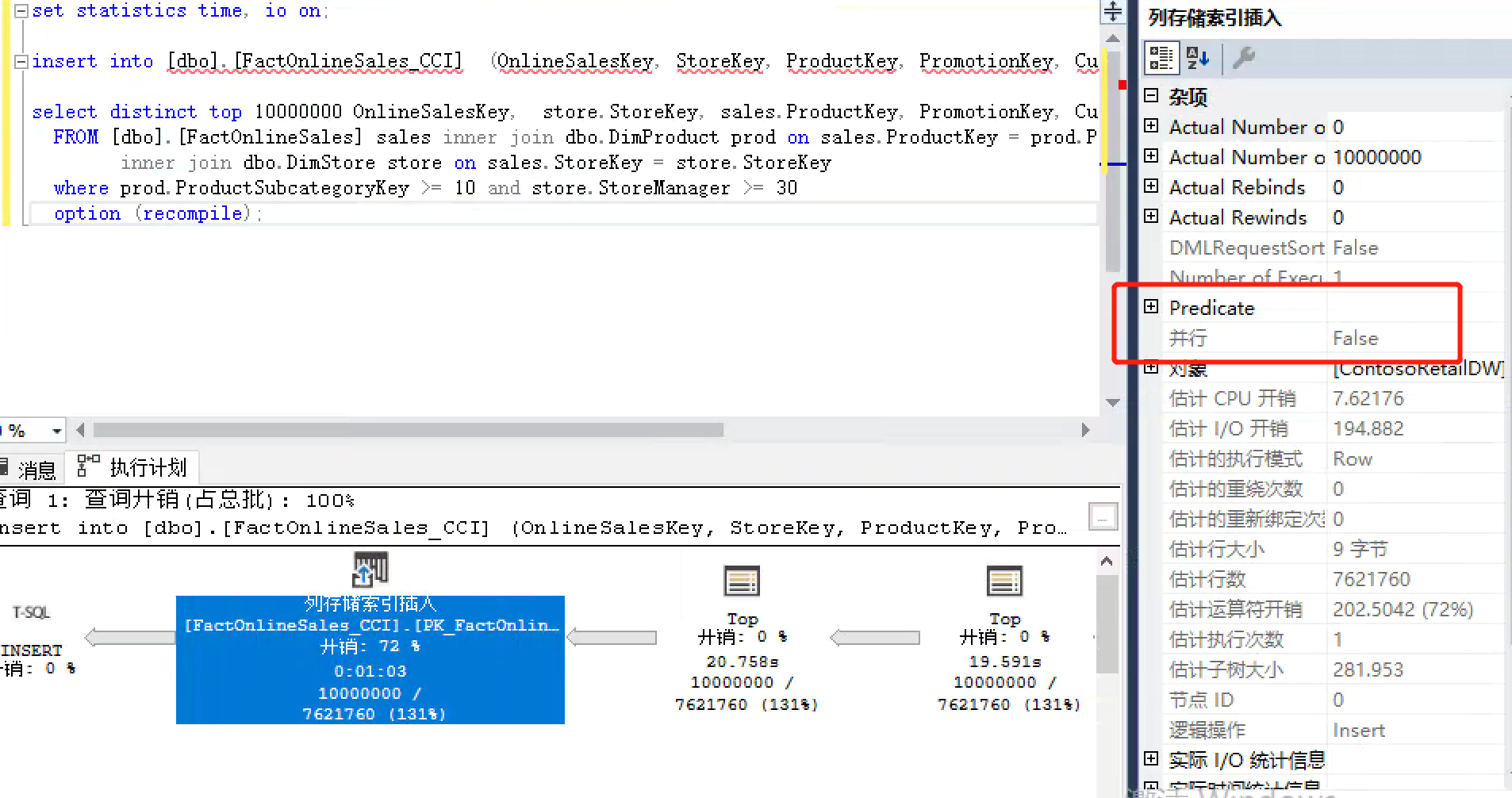
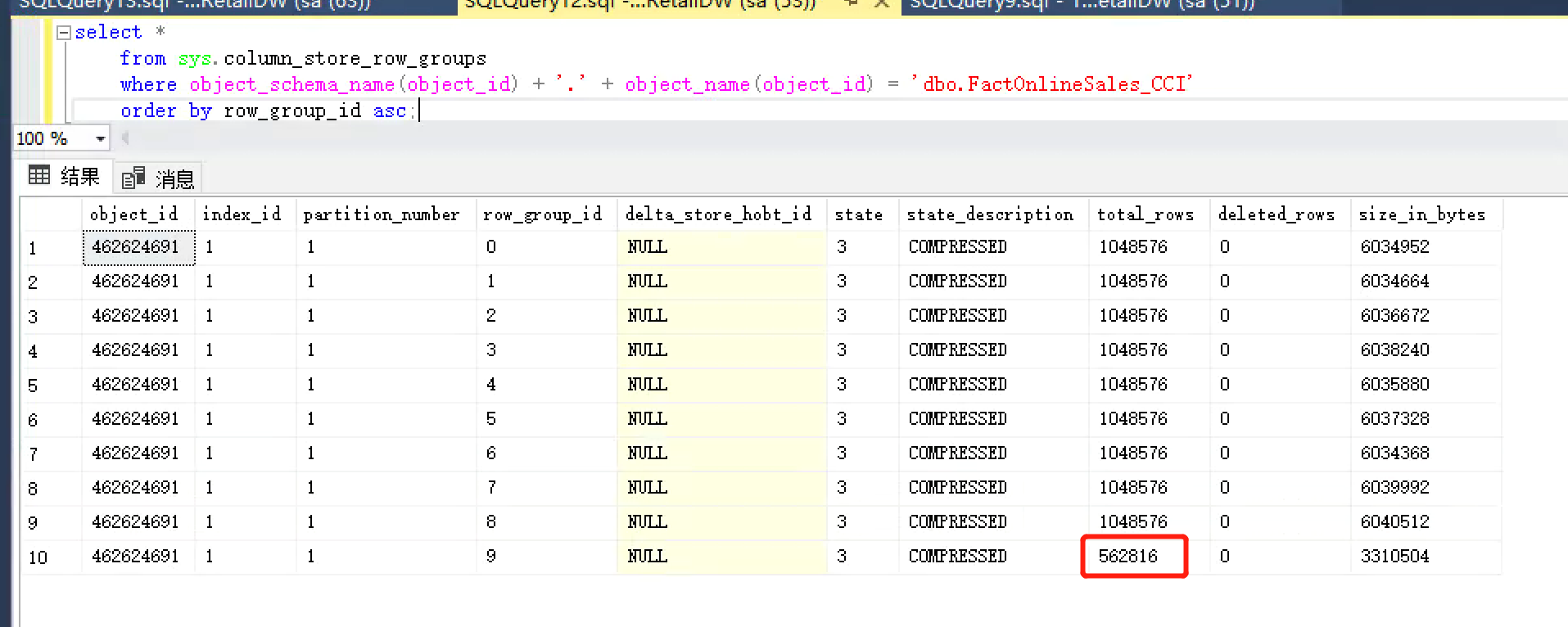
it took me about 71 seconds to complete the insertion in my environment, and the execution plan display was serial. This can be seen in the properties of the operator that there is only one thread to do this. We can also calculate that about (10 million divided by 1048576) row groups are used for storage, and the last row group is the extra unfilled data row. You can verify with the following statement:
select * from sys.column_store_row_groups where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI' order by row_group_id asc;
USE [master] GO ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130 GO
set statistics time, io on; insert into [dbo].[FactOnlineSales_CCI] with(TABLOCK) (OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey) select distinct top 10000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey FROM [dbo].[FactOnlineSales] sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey inner join dbo.DimStore store on sales.StoreKey = store.StoreKey where prod.ProductSubcategoryKey >= 10 and store.StoreManager >= 30 option (recompile);
.
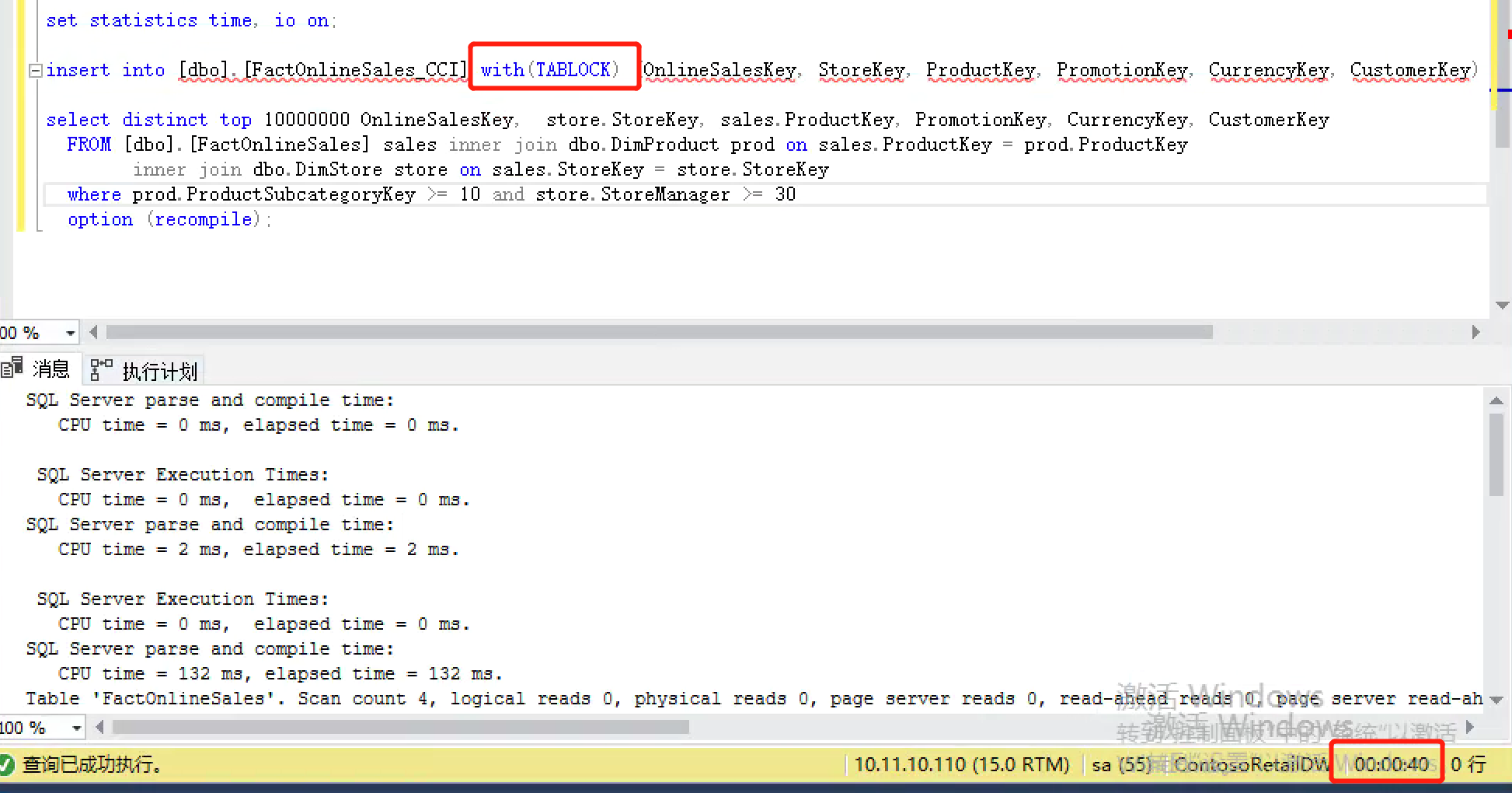
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 2 ms, elapsed time = 2 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 132 ms, elapsed time = 132 ms. Table 'FactOnlineSales'. Scan count 4, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 11237, lob physical reads 17, lob page server reads 0, lob read-ahead reads 26733, lob page server read-ahead reads 0. Table 'FactOnlineSales'. Segment reads 13, segment skipped 0. Table 'DimProduct'. Scan count 5, logical reads 370, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'DimStore'. Scan count 5, logical reads 67, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'FactOnlineSales_CCI'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. (10000000 Row affected) (1 Row affected) SQL Server Execution Times: CPU time = 101093 ms, elapsed time = 39771 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
. As you can see in the figure below, four threads are used, because my environment has only four core s, and then the behavior is "True".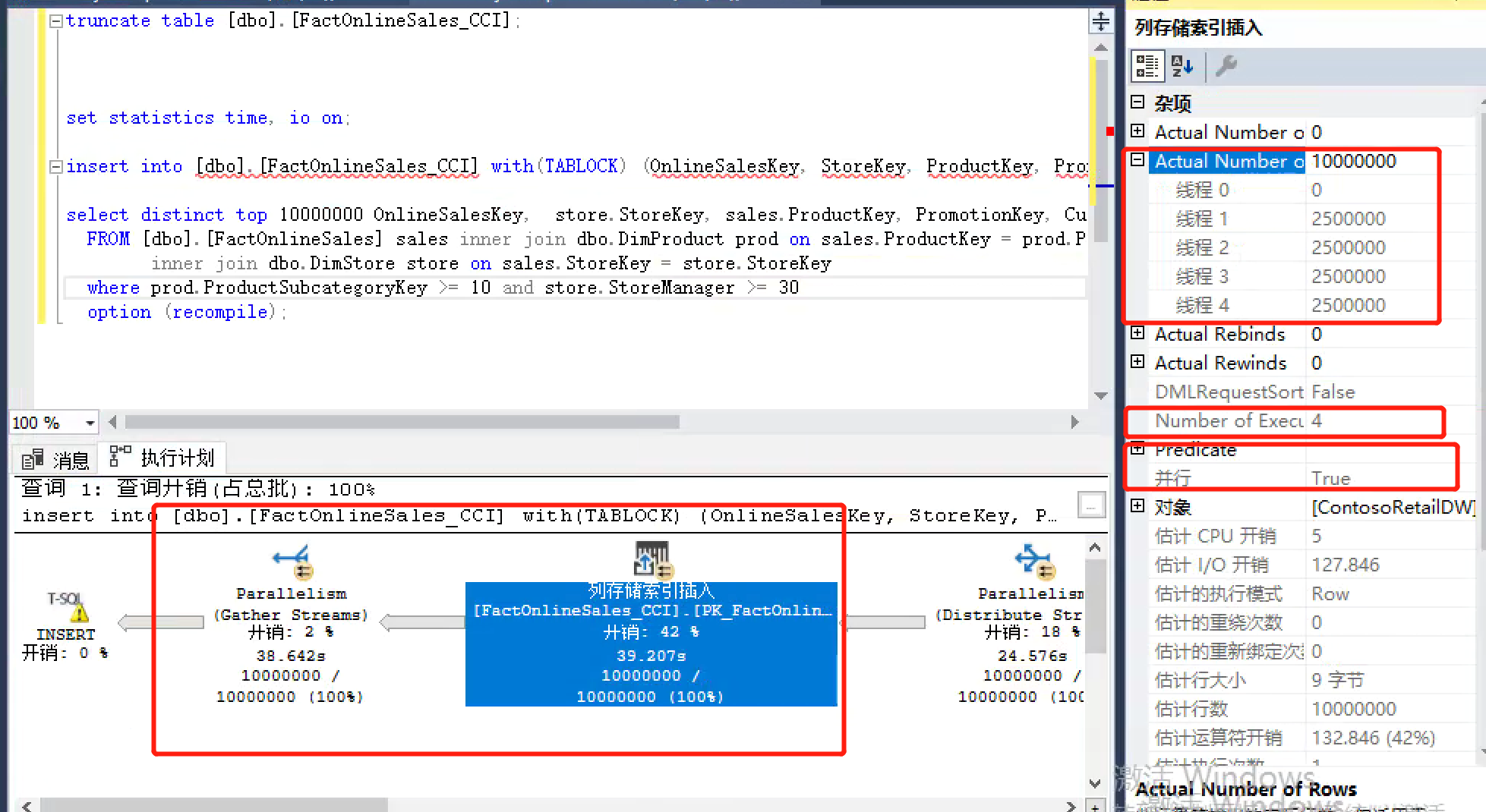
. The last four rows are evenly distributed in independent row groups for subsequent "pruning". As mentioned earlier, parallel will lead to more final row groups to be processed. Here are four rows. If you have many core s, there will be as many rows. These will affect performance, but if the overall performance is significantly improved, then this overhead is acceptable.
select * from sys.column_store_row_groups where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI' order by row_group_id asc;
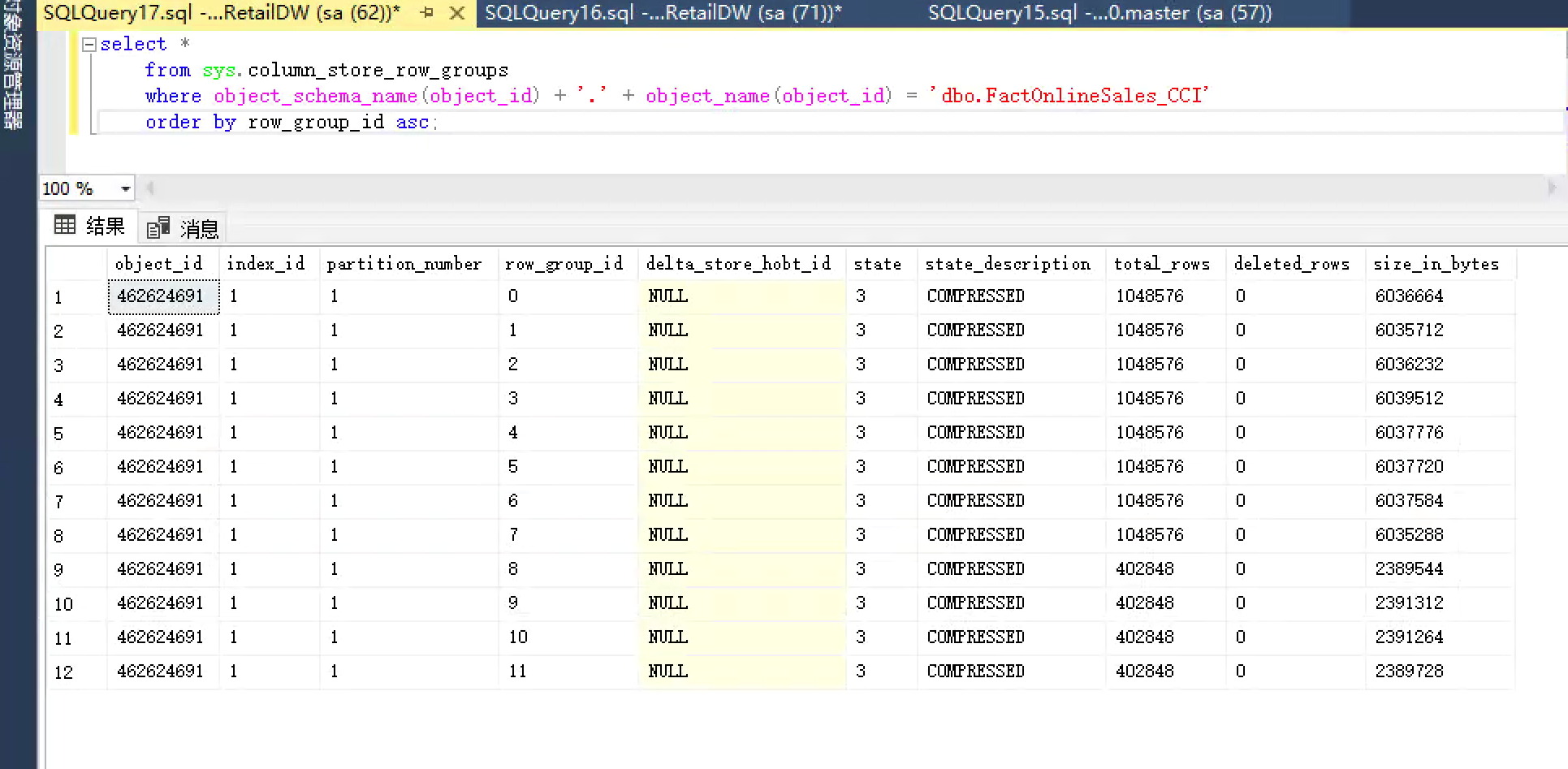
the maximum parallelizable number is the number of core s available - 1.
summary
.
.
.

