
This article tries to share the steps of SST writing in Nebula Exchange in a minimum way (stand-alone, containerized Spark, Hadoop and Nebula Graph). This article applies to v2 5 or above versions of Nebula Exchange.
Original link:
- Foreign visits: https://siwei.io/nebula-exchange-sst-2.x/
- Domestic visits: https://cn.siwei.io/nebula-exchange-sst-2.x/
What is Nebula Exchange?
I was there before Nebula Data Import Options As described in, Nebula Exchange Spark Applicaiton, an open source Spark Applicaiton of the Nebula Graph community, is specifically used to support batch or streaming data import into the Nebula Graph Database.
Nebula Exchange supports a variety of data sources (from Apache Parquet, ORC, JSON, CSV, HBase, Hive MaxCompute to Neo4j, MySQL, ClickHouse, Kafka and Pulsar, more data sources are also increasing).
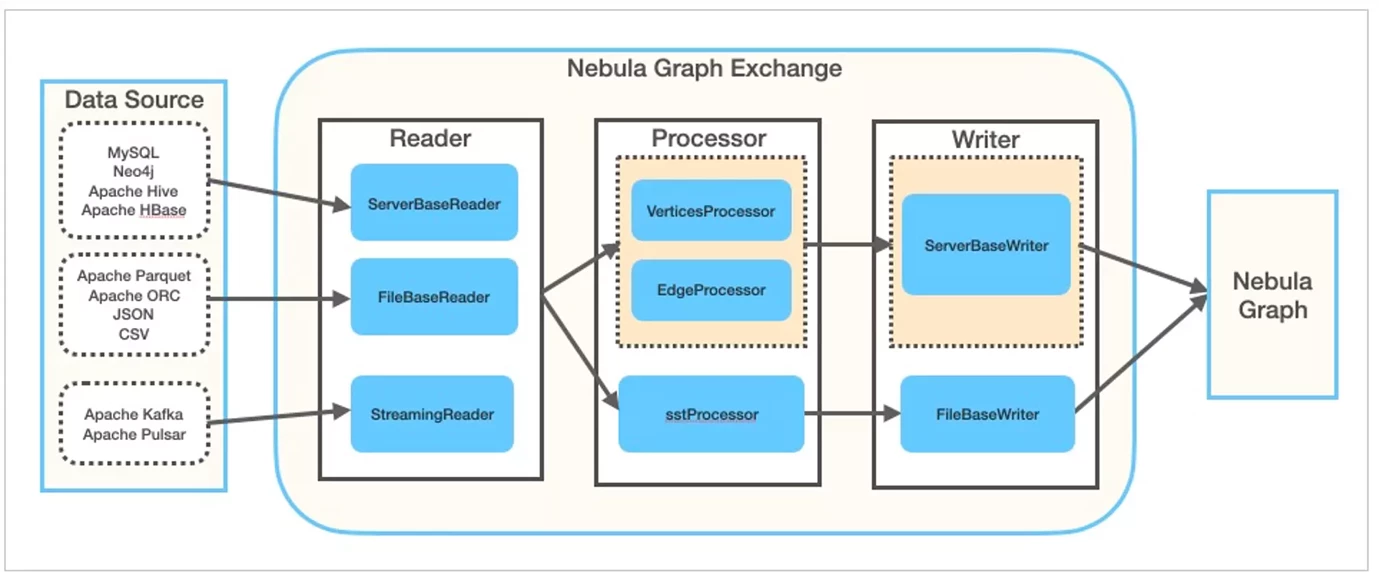
As shown in the above figure, in Exchange, in addition to reading different data sources from different readers, when the data is processed by the Processor and written to the Nebula Graph database through the Writer, it can bypass the whole writing process in addition to the normal writing process of ServerBaseWriter, Use Spark's computing power to generate the SST file of the underlying RocksDB in parallel, so as to realize ultra-high-performance data import. The scene of SST file import is the familiar part of this paper.
For details, see: Nebula Graph Manual: what is Nebula Exchange
Nebula Graph official blog There are also more practical articles on Nebula Exchange
Step overview
- Experimental environment
- Configure Exchange
- Generate SST file
- Write SST file to Nebula Graph
Experimental environment preparation
In order to minimize the use of the SST function of Nebula Exchange, we need to:
- Build a Nebula Graph cluster and create a Schema for importing data. We choose to use docker compose and use Nebula-Up Quickly deploy and simply modify its network to facilitate access by the same containerized Exchange program.
- Build a containerized Spark operating environment
- Building containerized HDFS
1. Build Nebula Graph cluster
With the help of Nebula-Up We can deploy a set of Nebula Graph clusters with one click in the Linux Environment:
curl -fsSL nebula-up.siwei.io/install.sh | bash
After the deployment is successful, we need to make some changes to the environment. The changes I made here are actually two points:
- Only one metaD service is reserved
- External network using Docker
Partial reference for detailed modification Appendix I
Apply the modification of docker compose:
cd ~/.nebula-up/nebula-docker-compose vim docker-compose.yaml # Refer to Appendix I docker network create nebula-net # External networks need to be created docker-compose up -d --remove-orphans
After that, let's create the graph space to be tested and the Schema of the graph. For this purpose, we can use the nebula console. Similarly, there is a containerized Nebula console in the nebula up.
- Enter the container where Nebula console is located
~/.nebula-up/console.sh / #
- Initiate a link to the graph database in the console container, where 192.168 x. Y is the first network card address of my Linux VM. Please change it to yours
/ # nebula-console -addr 192.168.x.y -port 9669 -user root -p password [INFO] connection pool is initialized successfully Welcome to Nebula Graph!
- Create a graph space (we call it sst) and a schema
create space sst(partition_num=5,replica_factor=1,vid_type=fixed_string(32)); :sleep 20 use sst create tag player(name string, age int);
Sample output
(root@nebula) [(none)]> create space sst(partition_num=5,replica_factor=1,vid_type=fixed_string(32)); Execution succeeded (time spent 1468/1918 us) (root@nebula) [(none)]> :sleep 20 (root@nebula) [(none)]> use sst Execution succeeded (time spent 1253/1566 us) Wed, 18 Aug 2021 08:18:13 UTC (root@nebula) [sst]> create tag player(name string, age int); Execution succeeded (time spent 1312/1735 us) Wed, 18 Aug 2021 08:18:23 UTC
2. Build a containerized Spark environment
Using the work done by big data europe, this process is very easy.
It is worth noting that:
- The current Nebula Exchange requires Spark version. In August 2021, I used spark-2.4.5-hadoop-2.7.
- For the convenience of me, nebucker runs on the same network as nebucker
docker run --name spark-master --network nebula-net \
-h spark-master -e ENABLE_INIT_DAEMON=false -d \
bde2020/spark-master:2.4.5-hadoop2.7
Then we can enter the environment:
docker exec -it spark-master bash
After entering the Spark container, you can install maven like this:
export MAVEN_VERSION=3.5.4 export MAVEN_HOME=/usr/lib/mvn export PATH=$MAVEN_HOME/bin:$PATH wget http://archive.apache.org/dist/maven/maven-3/$MAVEN_VERSION/binaries/apache-maven-$MAVEN_VERSION-bin.tar.gz && \ tar -zxvf apache-maven-$MAVEN_VERSION-bin.tar.gz && \ rm apache-maven-$MAVEN_VERSION-bin.tar.gz && \ mv apache-maven-$MAVEN_VERSION /usr/lib/mvn
You can also download the jar package of nebula exchange in the container as follows:
cd ~ wget https://repo1.maven.org/maven2/com/vesoft/nebula-exchange/2.1.0/nebula-exchange-2.1.0.jar
3. Build containerized HDFS
It's also very simple with the help of big data Euroupe, but we need to make a little modification to make its Docker compose In the YML file, the previously created Docker network, called Nebula net, is used.
Partial reference for detailed modification Appendix II
git clone https://github.com/big-data-europe/docker-hadoop.git cd docker-hadoop vim docker-compose.yml docker-compose up -d
Configure Exchange
This configuration is mainly filled with the information about the Nebula Graph cluster itself, the Space Name to be written to the data, and the configuration related to the data source (here we use csv as an example), and finally configure the output (sink) to sst
- Nebula Graph
- GraphD address
- MetaD address
- credential
- Space Name
- data source
- source: csv
- path
- fields etc.
- ink: sst
- source: csv
Detailed configuration reference Appendix II
Note that the address of the metadata can be obtained in this way. You can see that 0.0.0.0:49377 - > 9559 indicates that 49377 is an external address.
$ docker ps | grep meta 887740c15750 vesoft/nebula-metad:v2.0.0 "./bin/nebula-metad ..." 6 hours ago Up 6 hours (healthy) 9560/tcp, 0.0.0.0:49377->9559/tcp, :::49377->9559/tcp, 0.0.0.0:49376->19559/tcp, :::49376->19559/tcp, 0.0.0.0:49375->19560/tcp, :::49375->19560/tcp nebula-docker-compose_metad0_1
Generate SST file
1. Prepare source files and configuration files
docker cp exchange-sst.conf spark-master:/root/ docker cp player.csv spark-master:/root/
Including player Example of CSV:
1100,Tim Duncan,42 1101,Tony Parker,36 1102,LaMarcus Aldridge,33 1103,Rudy Gay,32 1104,Marco Belinelli,32 1105,Danny Green,31 1106,Kyle Anderson,25 1107,Aron Baynes,32 1108,Boris Diaw,36 1109,Tiago Splitter,34 1110,Cory Joseph,27 1111,David West,38
2. Execute the exchange program
Enter the spark master container and submit to execute the exchange application.
docker exec -it spark-master bash
cd /root/
/spark/bin/spark-submit --master local \
--class com.vesoft.nebula.exchange.Exchange nebula-exchange-2.1.0.jar\
-c exchange-sst.conf
Check execution results:
Spark submit output:
21/08/17 03:37:43 INFO TaskSetManager: Finished task 31.0 in stage 2.0 (TID 33) in 1093 ms on localhost (executor driver) (32/32) 21/08/17 03:37:43 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool 21/08/17 03:37:43 INFO DAGScheduler: ResultStage 2 (foreachPartition at VerticesProcessor.scala:179) finished in 22.336 s 21/08/17 03:37:43 INFO DAGScheduler: Job 1 finished: foreachPartition at VerticesProcessor.scala:179, took 22.500639 s 21/08/17 03:37:43 INFO Exchange$: SST-Import: failure.player: 0 21/08/17 03:37:43 WARN Exchange$: Edge is not defined 21/08/17 03:37:43 INFO SparkUI: Stopped Spark web UI at http://spark-master:4040 21/08/17 03:37:43 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
Verify the SST file generated on HDFS:
docker exec -it namenode /bin/bash root@2db58903fb53:/# hdfs dfs -ls /sst Found 10 items drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/1 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/10 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/2 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/3 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/4 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/5 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/6 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/7 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/8 drwxr-xr-x - root supergroup 0 2021-08-17 03:37 /sst/9
Write SST to Nebula Graph
The operations here are actually reference documents: SST import , come on. There are two steps from the console:
- Download
- Ingest
Download actually triggers Nebula Graph to initiate the download of HDFS Client from the server, obtain the SST file on HDFS, and then put it under the local path that storageD can access. Here, we need to deploy the dependency of HDFS on the server. Because we are the smallest practice, I was lazy and did the download manually.
1. Manual Download
When downloading manually here, we need to know the download path of the Nebula Graph server, which is actually / data / storage / Nebula / < space_ ID > / download /, the Space ID here needs to be obtained manually:
In this example, our Space Name is sst and our Space ID is 49.
(root@nebula) [sst]> DESC space sst +----+-------+------------------+----------------+---------+------------+--------------------+-------------+-----------+ | ID | Name | Partition Number | Replica Factor | Charset | Collate | Vid Type | Atomic Edge | Group | +----+-------+------------------+----------------+---------+------------+--------------------+-------------+-----------+ | 49 | "sst" | 10 | 1 | "utf8" | "utf8_bin" | "FIXED_STRING(32)" | "false" | "default" | +----+-------+------------------+----------------+---------+------------+--------------------+-------------+-----------+
Therefore, the next operation is to manually get the SST file from HDFS and then copy it to storageD.
docker exec -it namenode /bin/bash $ hdfs dfs -get /sst /sst exit docker cp namenode:/sst . docker exec -it nebula-docker-compose_storaged0_1 mkdir -p /data/storage/nebula/49/download/ docker exec -it nebula-docker-compose_storaged1_1 mkdir -p /data/storage/nebula/49/download/ docker exec -it nebula-docker-compose_storaged2_1 mkdir -p /data/storage/nebula/49/download/ docker cp sst nebula-docker-compose_storaged0_1:/data/storage/nebula/49/download/ docker cp sst nebula-docker-compose_storaged1_1:/data/storage/nebula/49/download/ docker cp sst nebula-docker-compose_storaged2_1:/data/storage/nebula/49/download/
2. SST file import
- Enter the container where Nebula console is located
~/.nebula-up/console.sh / #
- Initiate a link to the graph database in the console container, where 192.168 x. Y is the first network card address of my Linux VM. Please change it to yours
/ # nebula-console -addr 192.168.x.y -port 9669 -user root -p password [INFO] connection pool is initialized successfully Welcome to Nebula Graph!
- Execute INGEST to start letting StorageD read SST files
(root@nebula) [(none)]> use sst (root@nebula) [sst]> INGEST;
We can use the following methods to view the logs of the Nebula Graph server in real time
tail -f ~/.nebula-up/nebula-docker-compose/logs/*/*
Successful INGEST logs:
I0817 08:03:28.611877 169 EventListner.h:96] Ingest external SST file: column family default, the external file path /data/storage/nebula/49/download/8/8-6.sst, the internal file path /data/storage/nebula/49/data/000023.sst, the properties of the table: # data blocks=1; # entries=1; # deletions=0; # merge operands=0; # range deletions=0; raw key size=48; raw average key size=48.000000; raw value size=40; raw average value size=40.000000; data block size=75; index block size (user-key? 0, delta-value? 0)=66; filter block size=0; (estimated) table size=141; filter policy name=N/A; prefix extractor name=nullptr; column family ID=N/A; column family name=N/A; comparator name=leveldb.BytewiseComparator; merge operator name=nullptr; property collectors names=[]; SST file compression algo=Snappy; SST file compression options=window_bits=-14; level=32767; strategy=0; max_dict_bytes=0; zstd_max_train_bytes=0; enabled=0; ; creation time=0; time stamp of earliest key=0; file creation time=0; E0817 08:03:28.611912 169 StorageHttpIngestHandler.cpp:63] SSTFile ingest successfully
appendix
Appendix I
docker-compose.yaml
diff --git a/docker-compose.yaml b/docker-compose.yaml
index 48854de..cfeaedb 100644
--- a/docker-compose.yaml
+++ b/docker-compose.yaml
@@ -6,11 +6,13 @@ services:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --local_ip=metad0
- --ws_ip=metad0
- --port=9559
- --ws_http_port=19559
+ - --ws_storage_http_port=19779
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
@@ -34,81 +36,14 @@ services:
cap_add:
- SYS_PTRACE
- metad1:
- image: vesoft/nebula-metad:v2.0.0
- environment:
- USER: root
- TZ: "${TZ}"
- command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- - --local_ip=metad1
- - --ws_ip=metad1
- - --port=9559
- - --ws_http_port=19559
- - --data_path=/data/meta
- - --log_dir=/logs
- - --v=0
- - --minloglevel=0
- healthcheck:
- test: ["CMD", "curl", "-sf", "http://metad1:19559/status"]
- interval: 30s
- timeout: 10s
- retries: 3
- start_period: 20s
- ports:
- - 9559
- - 19559
- - 19560
- volumes:
- - ./data/meta1:/data/meta
- - ./logs/meta1:/logs
- networks:
- - nebula-net
- restart: on-failure
- cap_add:
- - SYS_PTRACE
-
- metad2:
- image: vesoft/nebula-metad:v2.0.0
- environment:
- USER: root
- TZ: "${TZ}"
- command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- - --local_ip=metad2
- - --ws_ip=metad2
- - --port=9559
- - --ws_http_port=19559
- - --data_path=/data/meta
- - --log_dir=/logs
- - --v=0
- - --minloglevel=0
- healthcheck:
- test: ["CMD", "curl", "-sf", "http://metad2:19559/status"]
- interval: 30s
- timeout: 10s
- retries: 3
- start_period: 20s
- ports:
- - 9559
- - 19559
- - 19560
- volumes:
- - ./data/meta2:/data/meta
- - ./logs/meta2:/logs
- networks:
- - nebula-net
- restart: on-failure
- cap_add:
- - SYS_PTRACE
-
storaged0:
image: vesoft/nebula-storaged:v2.0.0
environment:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --local_ip=storaged0
- --ws_ip=storaged0
- --port=9779
@@ -119,8 +54,8 @@ services:
- --minloglevel=0
depends_on:
- metad0
- - metad1
- - metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged0:19779/status"]
interval: 30s
@@ -146,7 +81,7 @@ services:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --local_ip=storaged1
- --ws_ip=storaged1
- --port=9779
@@ -157,8 +92,8 @@ services:
- --minloglevel=0
depends_on:
- metad0
- - metad1
- - metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged1:19779/status"]
interval: 30s
@@ -184,7 +119,7 @@ services:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --local_ip=storaged2
- --ws_ip=storaged2
- --port=9779
@@ -195,8 +130,8 @@ services:
- --minloglevel=0
depends_on:
- metad0
- - metad1
- - metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged2:19779/status"]
interval: 30s
@@ -222,17 +157,19 @@ services:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --port=9669
- --ws_ip=graphd
- --ws_http_port=19669
+ - --ws_meta_http_port=19559
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- - metad1
- - metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd:19669/status"]
interval: 30s
@@ -257,17 +194,19 @@ services:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --port=9669
- --ws_ip=graphd1
- --ws_http_port=19669
+ - --ws_meta_http_port=19559
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- - metad1
- - metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd1:19669/status"]
interval: 30s
@@ -292,17 +231,21 @@ services:
USER: root
TZ: "${TZ}"
command:
- - --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
+ - --meta_server_addrs=metad0:9559
- --port=9669
- --ws_ip=graphd2
- --ws_http_port=19669
+ - --ws_meta_http_port=19559
- --log_dir=/logs
- --v=0
- --minloglevel=0
+ - --storage_client_timeout_ms=60000
+ - --local_config=true
depends_on:
- metad0
- - metad1
- - metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd2:19669/status"]
interval: 30s
@@ -323,3 +266,4 @@ services:
networks:
nebula-net:
+ external: true
Appendix II
https://github.com/big-data-europe/docker-hadoop Docker compose yml
diff --git a/docker-compose.yml b/docker-compose.yml
index ed40dc6..66ff1f4 100644
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -14,6 +14,8 @@ services:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
+ networks:
+ - nebula-net
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
@@ -25,6 +27,8 @@ services:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
+ networks:
+ - nebula-net
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
@@ -34,6 +38,8 @@ services:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
+ networks:
+ - nebula-net
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
@@ -43,6 +49,8 @@ services:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
+ networks:
+ - nebula-net
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
@@ -54,8 +62,14 @@ services:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
+ networks:
+ - nebula-net
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:
+
+networks:
+ nebula-net:
+ external: true
Appendix III
nebula-exchange-sst.conf
{
# Spark relation config
spark: {
app: {
name: Nebula Exchange 2.1
}
master:local
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory:1G
}
cores:{
max: 16
}
}
# Nebula Graph relation config
nebula: {
address:{
graph:["192.168.8.128:9669"]
meta:["192.168.8.128:49377"]
}
user: root
pswd: nebula
space: sst
# parameters for SST import, not required
path:{
local:"/tmp"
remote:"/sst"
hdfs.namenode: "hdfs://192.168.8.128:9000"
}
# nebula client connection parameters
connection {
# socket connect & execute timeout, unit: millisecond
timeout: 30000
}
error: {
# max number of failures, if the number of failures is bigger than max, then exit the application.
max: 32
# failed import job will be recorded in output path
output: /tmp/errors
}
# use google's RateLimiter to limit the requests send to NebulaGraph
rate: {
# the stable throughput of RateLimiter
limit: 1024
# Acquires a permit from RateLimiter, unit: MILLISECONDS
# if it can't be obtained within the specified timeout, then give up the request.
timeout: 1000
}
}
# Processing tags
# There are tag config examples for different dataSources.
tags: [
# HDFS csv
# Import mode is sst, just change type.sink to client if you want to use client import mode.
{
name: player
type: {
source: csv
sink: sst
}
path: "file:///root/player.csv"
# if your csv file has no header, then use _c0,_c1,_c2,.. to indicate fields
fields: [_c1, _c2]
nebula.fields: [name, age]
vertex: {
field:_c0
}
separator: ","
header: false
batch: 256
partition: 32
}
]
}
If there are any errors or omissions in this article, please go to GitHub: https://github.com/vesoft-inc/nebula issue area to us or go to the official forum: https://discuss.nebula-graph.com.cn/ Make suggestions according to the classification of suggestions and feedback 👏; AC diagram database technology? Please join the Nebula communication group first Fill out your Nebula business card , Nebula's little assistant will pull you into the group~~