1, Generator
(1) lamda python
lambda function is also called anonymous function, that is, the function has no specific name.
Compared with ordinary functions, lambda just omits the function name. At the same time, such anonymous functions cannot be shared and called elsewhere.
In fact, you're right. Lambda really doesn't play an earth shaking role in Python, a dynamic language, because there are many other ways to replace lambda.
1. When using Python to write some execution scripts, using lambda can save the process of defining functions and make the code more concise.
2. For some abstract functions that will not be reused elsewhere, sometimes it is a difficult problem to name the function. There is no need to consider the naming problem when using lambda.
3. Use lambda to make the code easier to understand at some time.
In a lambda statement, there can be multiple parameters before the colon, separated by commas, and the return value to the right of the colon. Lambda statements actually build a function object
(2)random.random() is used to generate a random number of characters from 0 to 1: 0 < = n < 1.0
(3) ImageFolder assumes that all files are saved according to folders, and pictures of the same category are stored under each folder. The folder name is class name. By default, your dataset has been consciously divided into different folders according to the type to be allocated. Only one type of pictures are stored under one type of folder.
(3)source: dataset: female17943 + male 10057 = 28000
(4) _make_balanced_sampler
np.bincount()
Graphic combination, image Here, it is used as the number of 0 and 1, that is, the number of pictures of female and male, that is, 17943 and 10057
This is class_counts

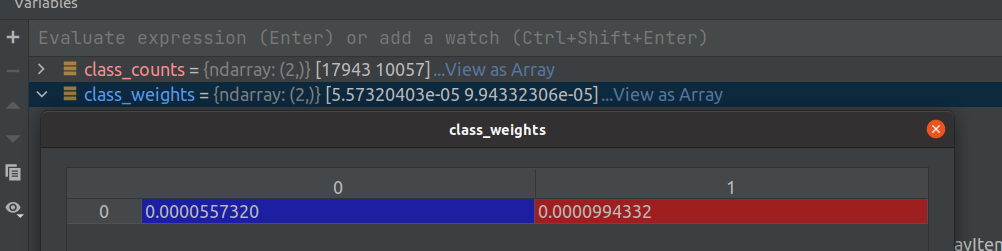
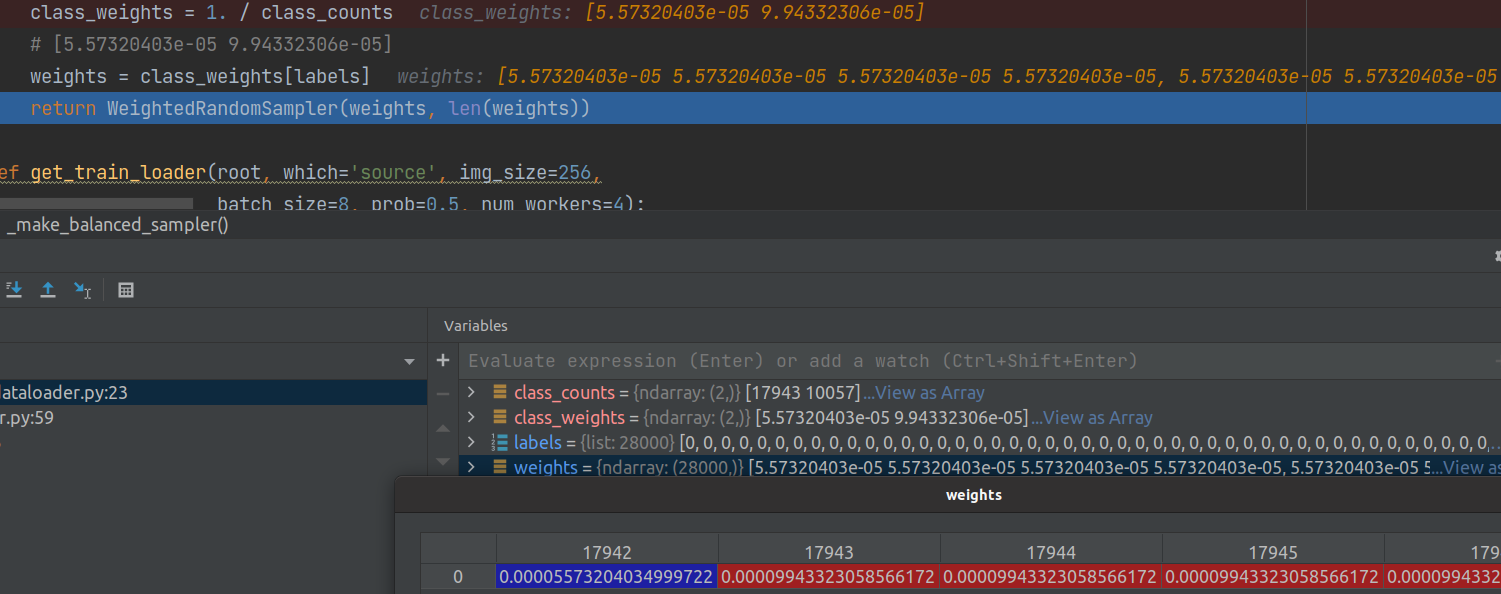 weights (list) the specific gravity of each picture, either 5.57320403e-05 or 9.94332306e-05
weights (list) the specific gravity of each picture, either 5.57320403e-05 or 9.94332306e-05
Function: the key is to look at the WeightRandomSampler function. Random sampling with weight in case of unbalanced samples: it roughly means that the samples that account for the least in the original number take the reciprocal of their number as the weight, so the smaller the weight, the greater the weight. When sampling, take it according to this weight, and you can achieve sample balance. See this link for details
(5)register_buffer
When defining a model in PyTorch, you sometimes encounter self register_ Buffer ('name ', tensor). This method is used to define a group of parameters. The special feature of this group of parameters is that the parameters will not be updated during model training (that is, after calling optimizer.step(), this group of parameters will not change, but their values can only be changed artificially). However, when saving the model, this group of parameters are saved as an indispensable part of the model parameters.
(6) tensor.repeat() just read this one
Pytorch Tensor. Simple usage of repeat()_ xiongxyowo's blog - CSDN blog
(7) Some tests for hpf
import torch
filter = torch.tensor([[-1, -1, -1],
[-1, 8., -1],
[-1, -1, -1]])/1
a = filter.unsqueeze(0) #Expand according to dimension 0, that is, line extension
b = filter.unsqueeze(0).unsqueeze(1)
c = filter.unsqueeze(0).unsqueeze(1).repeat(3, 1, 1, 1)
print("origin:", filter)
print("a: {}, a.shape = {}".format(a, a.shape))
print("b: {}, b.shape = {}".format(b, b.shape))
print("c: {}, c.shape = {}".format(c, c.shape))origin: tensor([[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]])
a: tensor([[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]]), a.shape = torch.Size([1, 3, 3])
b: tensor([[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]]]), b.shape = torch.Size([1, 1, 3, 3])
c: tensor([[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]],
[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]],
[[[-1., -1., -1.],
[-1., 8., -1.],
[-1., -1., -1.]]]]), c.shape = torch.Size([3, 1, 3, 3])
Process finished with exit code 0
It can be understood as follows: NN Converted is a 2D convolution layer, while F.conv2d is a 2D convolution operation.
import torch from torch.nn import functional as F """Manually define convolution kernel(weight)And bias""" w = torch.rand(16, 3, 5, 5) # 16 kinds of 3-channel 5 times 5 convolution kernels b = torch.rand(16) # Keep consistent with the number of convolution kernel types (different channels share a bias) """Define input samples""" x = torch.randn(1, 3, 28, 28) # 1 3-channel 28 by 28 image """2D Convolution output""" out = F.conv2d(x, w, b, stride=1, padding=1) # The step length is 1, plus 1 circle of padding, i.e. 1 circle of 0 is added up, down, left and right respectively, print(out.shape) out = F.conv2d(x, w, b, stride=2, padding=2) # The step size is 2, plus 2 rounds of padding print(out.shape) out = F.conv2d(x, w) # The step size is 1. It is not padded by default, which is not enough to be discarded. Therefore, for 28 * 28 pictures, it becomes 24 * 24 after calculation print(out.shape)
Conversion between numpy and tensor
view,squeeze,unsqueeze,
import torch
import torch.nn.functional as F
import torch.nn as nn
import cv2 as cv
from torchvision import transforms
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
class HighPass(nn.Module):
def __init__(self, w_hpf, device):
super(HighPass, self).__init__()
self.register_buffer('filter',
torch.tensor([[-1, -1, -1],
[-1, 8., -1],
[-1, -1, -1]]) / w_hpf)
def forward(self, x):
filter = self.filter.unsqueeze(0).unsqueeze(1).repeat(x.size(1), 1, 1, 1)
return F.conv2d(x, filter, padding=1, groups=x.size(1))
img_numpy = cv.imread('/home/zsq/D/stargan-v2-master/assets/representative/celeba_hq/ref/female/015248.jpg')
#[1024, 1024, 3] HWC BGR
img2 = cv.resize(img_numpy, (256, 256))
cv.imwrite("img2.jpg", img2)
img2 = torch.tensor(img2).float()
#[256, 256, 3]
img2 = img2.permute(2, 1, 0)
img2 = img2.unsqueeze(0)
hpf = HighPass(1,'gpu')
img3 = hpf(img2)
img3 = img3.squeeze(0).permute(2, 1, 0).numpy()
print(img3.shape)
cv.imwrite("img3.jpg", img3)

It can be seen that HighPass is an edge extraction network
F.interpolate -- array sampling operation
In other words, change the size of the array scientifically and reasonably to keep the data as complete as possible.
In computer vision, interpolate function is often used to enlarge the image (i.e. up sampling operation). For example, in the field of fine-grained recognition, attention map sometimes cuts the feature map to cut out the useful part. The size of the cut image is often smaller than the original feature map. At this time, if it is forcibly converted to the size of the original image, it is often invalid and some useful information will be lost. So at this time, we need to use the interpolate function to up sample it. Under the condition of ensuring that the image information is not lost, enlarge the image, so as to enlarge the details of the image, which is conducive to further feature extraction.
2, MappingNetwork
(1) Note the difference between out = [] out + = layer and out += [layer]
(2)torch. Usage of stack() torch. Official explanation, explanation and examples of stack()_ xinjieyuan's blog - CSDN blog_ torch.stack()
torch. Use of stack()_ Morning flower & evening gathering - CSDN blog_ torch.stack()
(3) Deep copy: our common sense of copy is deep copy, that is, the copied object is completely copied again and exists alone as an independent new individual. Therefore, changing the original copied object will not affect the copied new object.
3, Solver
(1) Munch inherited the dictionary
(2) When parameters in dictionary form are passed in, use * * kwargs.
(3) If you want to judge whether the two types are the same, isinstance() is recommended.
(4)Path().rglob() traverses the file recursively
fnames = list(chain(*[list(Path(dname).rglob('*.' + ext))
for ext in ['png', 'jpg', 'jpeg', 'JPG']]))4, dataloader
(1) About magic methods__ next__
① Magic method is a method in a class. The only difference from ordinary methods is that ordinary methods need to be called, while magic methods are automatically triggered at a specific time.
② The names of these magic methods are specific and cannot be changed, but the names of the entry parameters can be named by themselves.
Object oriented (3) | magic method of python class - Zhihu
-dataloader is essentially an iteratable object, which can be accessed by iter(), but not by next();
-Using ITER (data loader) returns an iterator, which can then be accessed using next;
-You can also use 'for inputs, labels in dataloaders' to access iteratable objects;
(2)ImageFolder
The dataset function of the corresponding source uses torchvision datasets. Imagefolder generation. The folder of the dataset CelebA HQ includes two folders: female and female. Under the folder is the corresponding file, so the dataset function returns (x,y) the corresponding extracted image and its corresponding domain label.
(3)class torchvision.transforms.ToTensor
Set the pixel value of shape=(H x W x C) to PIL of [0, 255] Image and numpy ndarray
Convert to torch with shape=(C x H x W) pixel value range of [0.0, 1.0] FloatTensor.
(4) The next(loader) in the code makes an error when debug ging. I can't understand what it means
5, Data loading
(1) source = > change all the pictures according to transforms, and then put them in the ImageFolder
(2) Reference = > in each field: the first is the sequential picture name, the second is the disordered picture name, and labels corresponds to the field
return img, img2, label
(3) Equalize sampling, make the sample balanced, and finally make it into a data set
def _make_balanced_sampler(labels):
class_counts = np.bincount(labels)
class_weights = 1. / class_counts
weights = class_weights[labels]
return WeightedRandomSampler(weights, len(weights))6, train code
(1)fill_value is given a value fill_value and a size to create a matrix element with all fill_ The size of value is size tensor
(2) logits is the final output of the full connection layer, not its original intention. Usually, the neural network has logits first, and then obtains the probability through sigmoid function or softmax function, so the expression of logit function is not needed in most cases.