
preface
LSM tree is the underlying implementation of many NoSQL database engines, such as LevelDB, Hbase, etc. Based on the design idea of LSM tree database in data intensive application system design, combined with code implementation, this paper completely expounds a mini database with about 500 lines of core code, and better understands the principle of database through theory and practice.
An SSTable (sort string table)
Previously, a database was implemented based on hash index. Its limitation is that the hash table needs to be put into memory, and the efficiency of interval query is not high.
In the log of the hash index database, the storage order of keys is its writing order, and the keys that appear after the same key take precedence over the previous keys. Therefore, the order of keys in the log is not important. The advantage of this is that it is easy to write, but there is no control over key duplication. The problem is that it wastes storage space and increases the time-consuming of initialization loading.
Now simply change the log writing requirements: the keys to be written are in order, and the same key can only appear once in a log. This kind of log is called SSTable, which has the following advantages over hash indexed logs:
1) Merging multiple log files is simpler and more efficient.
Because the logs are ordered, you can use the file merge sorting algorithm, that is, read multiple input files concurrently, compare the first key of each file, and copy them to the output file in order. If there are duplicate keys, only the key values in the latest log will be retained and the old ones will be discarded.

2) When querying keys, you do not need to save the indexes of all keys in memory.
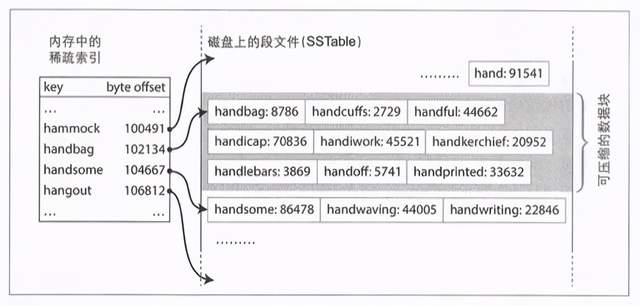
As shown in the figure below, suppose we need to find the handiwork, and the location of the key is not recorded in memory, but because SSTable is orderly, we can know that if handiwork exists, it must be between handbag and handsome, and then scan the log from handbag to the end of handsome. There are three benefits:
- Only sparse indexes need to be recorded in memory, which reduces the size of memory indexes.
- The query operation does not need to read the entire log, reducing file IO.
- Interval query is supported.
II. Build and maintain SSTable
We know that keys will appear in any order when writing, so how to ensure that the keys in SSTable are orderly? A simple and convenient way is to save it to the red black tree in memory. The red black tree is orderly, and then write it to the log file.
The basic workflow of the storage engine is as follows:
- When writing, it is first added to the red black tree in memory, which is called the memory table.
- When the memory table is greater than a certain threshold, it is written to the disk as an SSTable file. Because the tree is orderly, it can be written directly to the disk in order. In order to avoid database crash when the memory table is not written to the file, you can write the data to another log (WAL) while saving to the memory table, so that even if the database crashes, it can be recovered from the WAL. This log writing is similar to the log of hash index. It does not need to ensure the order, because it is used to recover data.
- When processing a read request, first try to find the key in the memory table, and then query the SSTable log from new to old until the data is found or empty.
- The background process periodically performs log merging and compression, discarding the overwritten or deleted values.
The above algorithm is the implementation of LSM tree (log structured merge tree based on log structure). The storage engine based on the principle of merging and compressing sorting files is usually called LSM storage engine, which is also the underlying principle of Hbase, LevelDB and other databases.
Third, implement a database based on LSM
Previously, we have known the implementation algorithm of LSM tree. There are still many design problems to be considered in the specific implementation. Let me pick some key designs for analysis.
1 memory table storage structure
What does the value of the memory table store? Store raw data directly? Or store write commands (including set and rm)? This is the first design problem we face. Let's not make a judgment here. Let's look at the next question first.
After the memory is expressed to a certain size, it should be written to the log file for persistence. This process is very simple if you directly disable writing. But what if you want to ensure that the memory table can handle read and write requests normally while writing files?
One solution is: while persisting memory table A, you can switch the current memory table pointer to the new memory table instance B. at this time, we should ensure that after switching, A is read-only and only B is writable. Otherwise, we cannot ensure that the persistence process of memory table A is atomic operation.
- get request: query B first, then A, and finally SSTable.
- set request: write directly to A
- rm request: suppose rm's key1 only appears in A and not in B. Here, if the memory table stores original data, the rm request cannot be processed because A is read-only, which will lead to rm failure. If we store commands in the memory table, this problem is solvable. Write the rm command in B, so that when querying key1, we can find that key1 has been deleted in B.
Therefore, if we disable writing when persisting the memory table, value can directly store the original data, but if we want to write when persisting the memory table, the value must store the command. We definitely want to pursue high performance, so we can't help writing, so what the value value needs to save is the command. Hbase is also designed in this way, which is the reason behind it.
In addition, when the memory table has exceeded the threshold to be persisted, it is found that the previous persistence has not been completed, so you need to wait for the previous persistence to complete before this persistence. In other words, memory table persistence can only be done serially.
2. File format of sstable
In order to achieve efficient file reading, we need to design the file format well.
The following is the SSTable log format I designed:
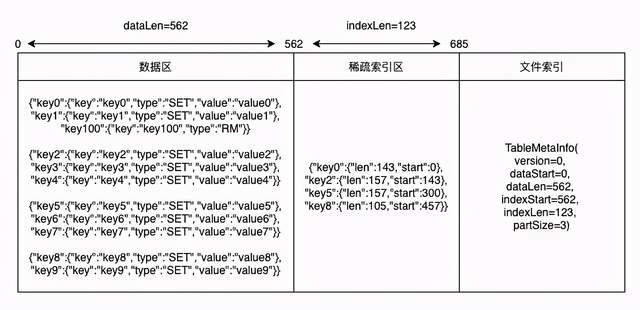
- Data area: the data area is mainly used to store write commands. At the same time, in order to facilitate segmented reading, it is segmented according to a certain number and size.
- Sparse index area: the sparse index stores the position index of each data segment in the file. When reading SSTable, only the sparse index will be loaded into memory. When querying, the corresponding data segment will be loaded according to the sparse index for query.
- File index area: the location where the data area is stored.
The above log format is a mini implementation. Compared with the log format of Hbase, it is relatively simple, which is convenient to understand the principle. At the same time, I also use JSON format to write files for easy reading. The production implementation is efficiency first. In order to save storage, compression will be done.
IV. code implementation analysis
The code I wrote is implemented in TinyKvStore. Let's analyze the key code. There are a lot of codes, and they are quite detailed. If you only care about the principle, you can skip this part. If you want to understand the code implementation, you can continue to read it.
1 SSTable
Memory table persistence
To persist the memory table to SSTable is to write the data of the memory table to the file according to the log format mentioned earlier. For SSTable, the data written is the data command, including set and rm. As long as we know the latest command of the key, we can know the status of the key in the database.
/**
* Convert from memory table to ssTable
* @param index
*/
private void initFromIndex(TreeMap< String, Command> index) {
try {
JSONObject partData = new JSONObject(true);
tableMetaInfo.setDataStart(tableFile.getFilePointer());
for (Command command : index.values()) {
//Process set command
if (command instanceof SetCommand) {
SetCommand set = (SetCommand) command;
partData.put(set.getKey(), set);
}
//Processing RM commands
if (command instanceof RmCommand) {
RmCommand rm = (RmCommand) command;
partData.put(rm.getKey(), rm);
}
//When the number of segments is reached, start writing data segments
if (partData.size() >= tableMetaInfo.getPartSize()) {
writeDataPart(partData);
}
}
//After traversal, if there is any remaining data (the tail data does not necessarily meet the segmentation conditions) written to the file
if (partData.size() > 0) {
writeDataPart(partData);
}
long dataPartLen = tableFile.getFilePointer() - tableMetaInfo.getDataStart();
tableMetaInfo.setDataLen(dataPartLen);
//Save sparse index
byte[] indexBytes = JSONObject.toJSONString(sparseIndex).getBytes(StandardCharsets.UTF_8);
tableMetaInfo.setIndexStart(tableFile.getFilePointer());
tableFile.write(indexBytes);
tableMetaInfo.setIndexLen(indexBytes.length);
LoggerUtil.debug(LOGGER, "[SsTable][initFromIndex][sparseIndex]: {}", sparseIndex);
//Save file index
tableMetaInfo.writeToFile(tableFile);
LoggerUtil.info(LOGGER, "[SsTable][initFromIndex]: {},{}", filePath, tableMetaInfo);
} catch (Throwable t) {
throw new RuntimeException(t);
}
}The write format is based on the read backward push, mainly to facilitate reading. For example, if tableMetaInfo is written from front to back, it should be read from back to front. This is why version should be written last, because it is the first one to read when reading, which is convenient for upgrading the log format. If these trick s are not tried, it is difficult to understand why they do so.
/**
* Write data to a file
* @param file
*/
public void writeToFile(RandomAccessFile file) {
try {
file.writeLong(partSize);
file.writeLong(dataStart);
file.writeLong(dataLen);
file.writeLong(indexStart);
file.writeLong(indexLen);
file.writeLong(version);
} catch (Throwable t) {
throw new RuntimeException(t);
}
}
/**
* Read meta information from the file and read it backwards in writing order
* @param file
* @return
*/
public static TableMetaInfo readFromFile(RandomAccessFile file) {
try {
TableMetaInfo tableMetaInfo = new TableMetaInfo();
long fileLen = file.length();
file.seek(fileLen - 8);
tableMetaInfo.setVersion(file.readLong());
file.seek(fileLen - 8 * 2);
tableMetaInfo.setIndexLen(file.readLong());
file.seek(fileLen - 8 * 3);
tableMetaInfo.setIndexStart(file.readLong());
file.seek(fileLen - 8 * 4);
tableMetaInfo.setDataLen(file.readLong());
file.seek(fileLen - 8 * 5);
tableMetaInfo.setDataStart(file.readLong());
file.seek(fileLen - 8 * 6);
tableMetaInfo.setPartSize(file.readLong());
return tableMetaInfo;
} catch (Throwable t) {
throw new RuntimeException(t);
}
}Load SSTable from file
When loading SSTable from file, only sparse index needs to be loaded, which can save memory. When querying the data area, just read it on demand.
/**
* Restore ssTable from file to memory
*/
private void restoreFromFile() {
try {
//Read index first
TableMetaInfo tableMetaInfo = TableMetaInfo.readFromFile(tableFile);
LoggerUtil.debug(LOGGER, "[SsTable][restoreFromFile][tableMetaInfo]: {}", tableMetaInfo);
//Read sparse index
byte[] indexBytes = new byte[(int) tableMetaInfo.getIndexLen()];
tableFile.seek(tableMetaInfo.getIndexStart());
tableFile.read(indexBytes);
String indexStr = new String(indexBytes, StandardCharsets.UTF_8);
LoggerUtil.debug(LOGGER, "[SsTable][restoreFromFile][indexStr]: {}", indexStr);
sparseIndex = JSONObject.parseObject(indexStr,
new TypeReference< TreeMap< String, Position>>() {
});
this.tableMetaInfo = tableMetaInfo;
LoggerUtil.debug(LOGGER, "[SsTable][restoreFromFile][sparseIndex]: {}", sparseIndex);
} catch (Throwable t) {
throw new RuntimeException(t);
}
}SSTable query
To query data from SSTable, first find the interval where the key is located from the sparse index. After finding the interval, read the data of the interval according to the position of the index record, and then query. If there is data, return it. If there is no data, return null.
/**
* Query data from ssTable
* @param key
* @return
*/
public Command query(String key) {
try {
LinkedList< Position> sparseKeyPositionList = new LinkedList<>();
Position lastSmallPosition = null;
Position firstBigPosition = null;
//Find the last position less than the key and the first position greater than the key from the sparse index
for (String k : sparseIndex.keySet()) {
if (k.compareTo(key) <= 0) {
lastSmallPosition = sparseIndex.get(k);
} else {
firstBigPosition = sparseIndex.get(k);
break;
}
}
if (lastSmallPosition != null) {
sparseKeyPositionList.add(lastSmallPosition);
}
if (firstBigPosition != null) {
sparseKeyPositionList.add(firstBigPosition);
}
if (sparseKeyPositionList.size() == 0) {
return null;
}
LoggerUtil.debug(LOGGER, "[SsTable][restoreFromFile][sparseKeyPositionList]: {}", sparseKeyPositionList);
Position firstKeyPosition = sparseKeyPositionList.getFirst();
Position lastKeyPosition = sparseKeyPositionList.getLast();
long start = 0;
long len = 0;
start = firstKeyPosition.getStart();
if (firstKeyPosition.equals(lastKeyPosition)) {
len = firstKeyPosition.getLen();
} else {
len = lastKeyPosition.getStart() + lastKeyPosition.getLen() - start;
}
//If the key exists, it must be in the interval, so you only need to read the data in the interval to reduce io
byte[] dataPart = new byte[(int) len];
tableFile.seek(start);
tableFile.read(dataPart);
int pStart = 0;
//Read partition data
for (Position position : sparseKeyPositionList) {
JSONObject dataPartJson = JSONObject.parseObject(new String(dataPart, pStart, (int) position.getLen()));
LoggerUtil.debug(LOGGER, "[SsTable][restoreFromFile][dataPartJson]: {}", dataPartJson);
if (dataPartJson.containsKey(key)) {
JSONObject value = dataPartJson.getJSONObject(key);
return ConvertUtil.jsonToCommand(value);
}
pStart += (int) position.getLen();
}
return null;
} catch (Throwable t) {
throw new RuntimeException(t);
}
}2 LsmKvStore
Initialize load
- dataDir: the data directory stores log data, so you need to read the previous persistent data from the directory when starting.
- storeThreshold: the persistence threshold. When the memory table exceeds a certain size, it should be persisted.
- partSize: data partition threshold of SSTable.
- indexLock: read / write lock of memory table.
- ssTables: an ordered list of ssTables, sorted from new to old.
- wal: write log sequentially, which is used to save the data of the memory table for data recovery.
The startup process is very simple, that is, load the data configuration, initialize the content, and restore the data to the memory table if necessary.
/**
* initialization
* @param dataDir Data directory
* @param storeThreshold Persistence threshold
* @param partSize Data partition size
*/
public LsmKvStore(String dataDir, int storeThreshold, int partSize) {
try {
this.dataDir = dataDir;
this.storeThreshold = storeThreshold;
this.partSize = partSize;
this.indexLock = new ReentrantReadWriteLock();
File dir = new File(dataDir);
File[] files = dir.listFiles();
ssTables = new LinkedList<>();
index = new TreeMap<>();
//The directory is empty. No need to load ssTable
if (files == null || files.length == 0) {
walFile = new File(dataDir + WAL);
wal = new RandomAccessFile(walFile, RW_MODE);
return;
}
//Load ssTable from large to small
TreeMap< Long, SsTable> ssTableTreeMap = new TreeMap<>(Comparator.reverseOrder());
for (File file : files) {
String fileName = file.getName();
//To recover data from the temporary WAL, walTmp is usually left only when an exception occurs during the persistence of ssTable
if (file.isFile() && fileName.equals(WAL_TMP)) {
restoreFromWal(new RandomAccessFile(file, RW_MODE));
}
//Load ssTable
if (file.isFile() && fileName.endsWith(TABLE)) {
int dotIndex = fileName.indexOf(".");
Long time = Long.parseLong(fileName.substring(0, dotIndex));
ssTableTreeMap.put(time, SsTable.createFromFile(file.getAbsolutePath()));
} else if (file.isFile() && fileName.equals(WAL)) {
//Load WAL
walFile = file;
wal = new RandomAccessFile(file, RW_MODE);
restoreFromWal(wal);
}
}
ssTables.addAll(ssTableTreeMap.values());
} catch (Throwable t) {
throw new RuntimeException(t);
}
}Write operation
The write operation first adds a write lock, and then saves the data to the memory table and WAL. In addition, it also needs to make a judgment: if the threshold is exceeded, it will be persisted. For the sake of simplicity, I directly execute in series without using thread pool, but it does not affect the overall logic. The codes of set and rm are similar, so they will not be repeated here.
@Override
public void set(String key, String value) {
try {
SetCommand command = new SetCommand(key, value);
byte[] commandBytes = JSONObject.toJSONBytes(command);
indexLock.writeLock().lock();
//Save the data to WAL first
wal.writeInt(commandBytes.length);
wal.write(commandBytes);
index.put(key, command);
//The memory table size exceeds the threshold for persistence
if (index.size() > storeThreshold) {
switchIndex();
storeToSsTable();
}
} catch (Throwable t) {
throw new RuntimeException(t);
} finally {
indexLock.writeLock().unlock();
}
}Memory table persistence process
Switch the memory table and its associated WAL: lock the memory table first, then create a new memory table and WAL, temporarily store the old memory table and WAL, and release the lock. In this way, the new memory table can be written, and the old memory table becomes read-only.
Execute the persistence process: write the old memory table into a new ssTable in order, and then delete the temporary memory table and the temporarily saved WAL.
/**
* Switch the memory table, create a new memory table, and temporarily store the old one
*/
private void switchIndex() {
try {
indexLock.writeLock().lock();
//Switch memory tables
immutableIndex = index;
index = new TreeMap<>();
wal.close();
//After switching the memory table, you should also switch the WAL
File tmpWal = new File(dataDir + WAL_TMP);
if (tmpWal.exists()) {
if (!tmpWal.delete()) {
throw new RuntimeException("Failed to delete file: walTmp");
}
}
if (!walFile.renameTo(tmpWal)) {
throw new RuntimeException("Rename file failed: walTmp");
}
walFile = new File(dataDir + WAL);
wal = new RandomAccessFile(walFile, RW_MODE);
} catch (Throwable t) {
throw new RuntimeException(t);
} finally {
indexLock.writeLock().unlock();
}
}
/**
* Save data to ssTable
*/
private void storeToSsTable() {
try {
//ssTable is named according to time, which ensures that the name is incremented
SsTable ssTable = SsTable.createFromIndex(dataDir + System.currentTimeMillis() + TABLE, partSize, immutableIndex);
ssTables.addFirst(ssTable);
//Persistence is completed. Delete the temporary memory table and WAL_TMP
immutableIndex = null;
File tmpWal = new File(dataDir + WAL_TMP);
if (tmpWal.exists()) {
if (!tmpWal.delete()) {
throw new RuntimeException("Failed to delete file: walTmp");
}
}
} catch (Throwable t) {
throw new RuntimeException(t);
}
}Query operation
The operation of query is the same as that described in the algorithm:
- Get from the memory table first. If it cannot be obtained and there is an immutable memory table, get from the immutable memory table.
- If the query cannot be found in the memory table, query from the new SSTable to the old SSTable in turn.
@Override
public String get(String key) {
try {
indexLock.readLock().lock();
//Get from the index first
Command command = index.get(key);
//Try to fetch from the immutable index again. At this time, it may be in the process of persisting the sstable
if (command == null && immutableIndex != null) {
command = immutableIndex.get(key);
}
if (command == null) {
//There is no attempt to get from ssTable in the index. Find the old ssTable from the new ssTable
for (SsTable ssTable : ssTables) {
command = ssTable.query(key);
if (command != null) {
break;
}
}
}
if (command instanceof SetCommand) {
return ((SetCommand) command).getValue();
}
if (command instanceof RmCommand) {
return null;
}
//Description not found does not exist
return null;
} catch (Throwable t) {
throw new RuntimeException(t);
} finally {
indexLock.readLock().unlock();
}
}summary
The unity of knowledge and practice leads to true knowledge. If we don't implement a database, it's hard to understand why it's designed like this. For example, why the log format is designed like this, why the database stores data operations rather than the data itself, and so on.
The database function implemented in this paper is relatively simple, and there are many places that can be optimized, such as data persistence, asynchronization, log file compression, and query using Bloom filter. Interested readers can continue to study in depth.
reference material
Data intensive application system design
Related links
https://github.com/x-hansong/TinyKvStore
Author Xiao Kai
This article is the original content of Alibaba cloud and cannot be reproduced without permission.