Introduction to steganalysis process:
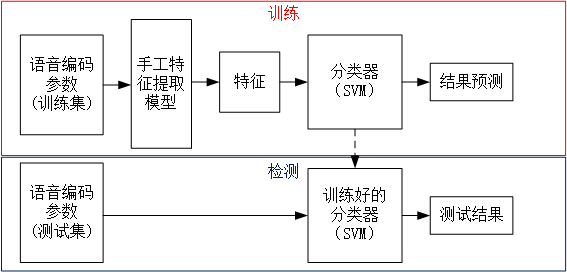
Steganalysis method based on "manual feature + Classifier":
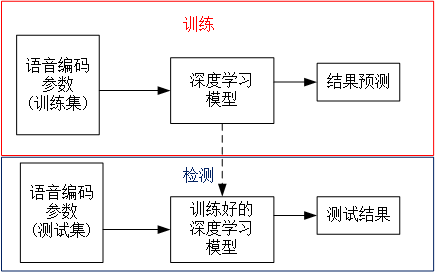
Steganalysis method based on deep learning: the deep learning model automatically extracts features and gives the classification results through the classification layer.
Basic knowledge
Steganography: hide the secret information in the multimedia carrier (image, audio, video, etc.) without affecting the quality of the carrier, and transmit it safely through the public channel. Except for the sender and receiver, the third party cannot detect the existence of the secret information.
Steganalysis: it is a binary classification task to detect whether there is secret information in this multimedia.
Embedding rate: E M R = Secret dense letter interest than special number load body than special number EMR=\frac {number of secret information bits} {number of carrier bits} EMR = number of carrier bits number of secret information bits
Evaluation index: accuracy ACC; False alarm rate FPR; Missing detection rate FNR.
- A C C = N T P + N T N N T P + N T N + N F P + N F N ACC{\rm{ }} = {\rm{ }}\frac{{{N_{TP\;}} + {N_{TN}}}}{{{N_{TP}} + {N_{TN}} + {N_{FP}} + {N_{FN}}}} ACC=NTP + NTN + NFP + NFN ^ NTP + NTN, which refers to the ratio of correctly classified samples to all samples. The higher the ACC, the better the detection performance. Among them, N T P N_{T P} NTP is the number of samples correctly classified as positive (steganographic); N T N N_{T N} NTN is the number of samples correctly classified as negative (not steganographic), N F P N_{F P} NFP ¢ is the number of negative (not steganographic) samples incorrectly classified as positive (steganographic) samples; N F N N_{F N} NFN is the number of positive (steganographic) samples incorrectly classified as negative (not steganographic) samples.
- F P R = N F P N T N + N F P FPR{\rm{ }} = \frac{{{N_{FP}}}}{{{N_{TN}} + {N_{FP}}}} FPR=NTN + NFP ÷ NFP, which refers to the rate of being wrongly judged as positive in all samples that are actually negative, which can reflect the situation of false detection.
- F N R = N F N N T P + N F N FNR{\rm{ }} = \frac{{{N_{FN}}}}{{{N_{TP}} + {N_{FN}}}} FNR=NTP + NFN ÷ NFN, which refers to the ratio of all samples that are actually positive to be wrongly judged as negative, which can reflect the situation of missed detection.
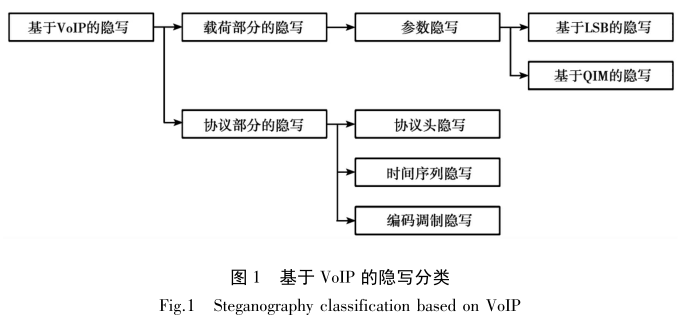
Steganography and steganography analysis based on network voice (VoIP) stream: VoIP coding is compression coding, and the voice file will become corresponding parameters after coding, and the steganography methods in the process of parameter coding can be divided into least significant bit (LSB) steganography and quantized index modulation (QIM) steganography according to the steganography method.
- LSB steganography: a steganography scheme based on the redundancy in the coding process of VoIP encoder. In the encoding, it is detected that some parameters belong to the least significant bit and are modified into secret information.
- QIM steganography: a method of dividing the hidden information of codebook by using the codebook coding characteristics of VoIP encoder, that is, dynamically selecting the quantization index value of the best excitation vector and minimizing the distortion of synthetic speech as much as possible to realize information hiding.
Most VoIP encoders use codebook excited linear prediction (CELP) coding rules. According to the implementation, the encoder is divided into linear prediction analysis, pitch search and fixed codebook search. Therefore, the most important parameters in the coding process are: linear predictive coefficients (LPC) parameters, fixed codebook (FCB) parameters, adaptive codebook (ACB) parameters and Gain parameters. The Gain parameter redundancy is too small to be suitable for steganography. The part of parameter steganography is basically the first three or mixed.
LPC, FCB and ACB parameter codes all use codebook parameter codes, so they can be steganographed by LSB or QIM. For steganography, the proposed steganography scheme focuses more on steganography methods, and its purpose is how to improve the concealment and hiding capacity of the proposed method. So it is classified according to steganography. However, for detection, no matter what method is used, it is important to detect it and it is best to know the location of steganography. Therefore, steganalysis will be classified according to the parameter location.
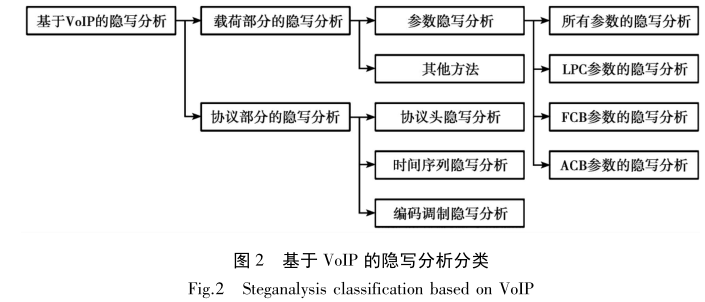
1. Data set preparation (speech coding parameters)
In order to carry out steganalysis, the first step is to extract speech coding parameters. We need to process the audio, such as wav processing, steganography processing (coding) and extracting parameters (decoding). After extracting the coding parameters, we can carry out steganalysis.
1.1 use ready-made speech coding parameters
There are only parameters of specific duration embedding rate. If more data needs to be prepared, refer to step 1.2.
Download link
Train Set: https://pan.baidu.com/share/init?surl=dJtBXQuZnG2eba13tbmnOA (a1xd)
Test Set: https://pan.baidu.com/share/init?surl=MREl-doUf2MG4-BuE91P0w (levg)
Data set introduction
| encoder | Steganography method | Use parameters | duration | Embedding rate | Number of samples |
|---|---|---|---|---|---|
| G.729a | CNV-QIM | LPC, linear prediction parameter | 1s | 0%~40% | 45000~50000 |
| G.729a | PMS | ACB, pitch delay parameter | 1s | 0%~40% | 45000~50000 |
-
CNV-QIM:Xiao B, Huang Y, Tang S. An approach to information hiding in low bit-rate speech stream[C]//IEEE GLOBECOM 2008-2008 IEEE Global Telecommunications Conference. IEEE, 2008: 1-5.
-
PMS: Huang Y, Liu C, Tang S, et al. Steganography integration into a low-bit rate speech codec[J]. IEEE transactions on information forensics and security, 2012, 7(6): 1865-1875.
With these data, we go directly to step 2.
1.2 prepare coding parameters by yourself

All you need is the encoding parameter (txt)
1.2.1 wav->pcm
wav voice data set
chinese: Chinese.tar.gz , 160 voice in wav format, 40 + hours.
English: English.tar.gz , 160 voice messages in wav format, 70 + hours.
wavsplit.py:
wav needs to be divided into 10s,9s,8s,... Duration, and then converted into pcm.
import os
import wave
import numpy as np
path = "E:/wav_path/"
pcm_path = "E:/pcm_path/"
CutTime=10 # Time of clipping
files = os.listdir(path)
files = [path + "\\" + f for f in files if f.endswith('.wav')]
if __name__ == '__main__':
for i in range(len(files)):
FileName = files[i]
f = wave.open(r"" + FileName, 'rb')
params = f.getparams() # Read audio file information
nchannels, sampwidth, framerate, nframes = params[:4] # Number of channels, quantization bits, sampling frequency, sampling points
str_data = f.readframes(nframes)
f.close()
# Convert audio according to the number of channels
wave_data = np.frombuffer(str_data, dtype=np.short)
if nchannels > 1:
wave_data.shape = -1, 2
wave_data = wave_data.T
temp_data = wave_data.T
else:
wave_data = wave_data.T
temp_data = wave_data.T
CutFrameNum = framerate * float(CutTime)
Cutnum = nframes / CutFrameNum # Number of audio clips
StepNum = int(CutFrameNum)
origin_name, _ = os.path.basename(FileName).split(".wav")
for j in range(int(Cutnum)):
FileName = pcm_path + os.path.basename(origin_name) + "_" + str(j) + ".wav"
print(FileName)
temp_dataTemp = temp_data[StepNum * j:StepNum * (j + 1)]
StepTotalNum = (j + 1) * StepNum
temp_dataTemp.shape = 1, -1
temp_dataTemp = temp_dataTemp.astype(np.short) # Open WAV document
f = wave.open(FileName, 'wb')
# Configure the number of channels, quantization bits and sampling frequency
f.setnchannels(nchannels)
f.setsampwidth(sampwidth)
f.setframerate(framerate)
f.writeframes(temp_dataTemp.tostring()) # Will wav_data is converted into binary data and written to a file
f.close()
wav2pcm.py:
#-*-coding:utf-8 -*-
import os
import numpy as np
path = "E:/wav_path/"
pcm_path = "E:/pcm_path/"
for file in os.listdir(path):
f = 0
data = 0
f = open(os.path.join(path,file))
f.seek(0)
f.read(44)
data = np.fromfile(f, dtype=np.int16)
dataname = file.rstrip('wav')+'pcm'
data.tofile(os.path.join(pcm_path, dataname))
Or use the ffmpeg tool and add ffmpeg to the system variable, using the following code:
import os
path = "E:/wav_path/"
pcm_path = "E:/pcm_path/"
files = os.listdir(path)
files = [pcm_path + "\\" + f for f in files if f.endswith('.wav')]
if __name__ == '__main__':
j = 0
for i in range(len(files)):
in_wav = files[i]
origin_name, _ = os.path.basename(in_wav).split(".wav")
out_pcm = os.path.join(pcm_path, "prefix_%05d.pcm" % (noise, j))
j += 1
cmd = "ffmpeg -i %s -f s16le %s" % (in_wav, out_pcm)
os.system(cmd)
1.2.2 pcm->dat
A variety of encoders, iLBC,G.723.1,G.729a,AMR, etc., can be used, reproduced according to the steganography method, and modified by finding the corresponding parameters in the encoding process. For example, the LPC parameter is the income after VQ quantization in the LSF search function, and the ACB parameter is the pitch in the closed-loop pitch delay search.
Here are the open source steganography tools: https://github.com/YangzlTHU/VStego800K/blob/main/Steganography/Stega_tool/StegCoder.exe
Two steganography methods are provided: CNV and PMS. CNV modifies the LPC parameter (VQ quantization index value) and PMS modifies the ACB parameter (pitch delay integer parameter).
-
CNV-QIM:Xiao B, Huang Y, Tang S. An approach to information hiding in low bit-rate speech stream[C]//IEEE GLOBECOM 2008-2008 IEEE Global Telecommunications Conference. IEEE, 2008: 1-5.
-
PMS: Huang Y, Liu C, Tang S, et al. Steganography integration into a low-bit rate speech codec[J]. IEEE transactions on information forensics and security, 2012, 7(6): 1865-1875.
usage method
- Use wav2pcm Py removes the wav file header and turns the wav file into a PCM file, which needs to be modified The path of wav file in py file and the saving path of PCM.
- Use stegcoder Exe for steganography (1) put the pcm file to be steganographed in a folder named input
(2) Create a new output folder to store the steganographic files
(3) If CNV-QIM steganography is used and the steganography embedding rate is 100%, enter in the command prompt
StegCoder.exe -i input -o output -a cnv -r 100
If the pitch steganography method is used and the steganography embedding rate is 100%, enter it at the command prompt
StegCoder.exe -i input -o output -a pitch -r 100 - Replacing the embedding rate 100 with other embedding rates can generate steganographic samples with different embedding rates.
1.2.3 dat->txt
According to the encoders iLBC,G.723.1,G.729a,AMR, etc., the corresponding coding parameters are extracted in the decoding step of the corresponding decoder.
Or use G729A encoding file parameter extraction tool: https://github.com/YangzlTHU/VStego800K/blob/main/Steganalysis/RSM/G729PreProcessor_CNV%2BPMS.py
parser.add_argument("--input", default="inputdir", help="input file /folder", type=str)
parser.add_argument("--output", default="outputdir", help="Output folder", type=str)
You can run directly after changing the default in the code, where outputdir is the folder for extracting features (txt) and inputdir is the folder for encoding audio (g.729a) with extraction.
Or enter Python g729preprocessor at the command prompt_ CNV+PMS. py --input inputdir --output outputdir
Finally, the feature txt will be output. Each frame contains five coding parameters, of which the first three are LPC parameters and the last two are ACB parameters.
def extract_frame(content):
if type(content) == str:
content_t = [int(item.encode('hex'), 16) for item in content]
else:
content_t = content
a = content_t[0] & 0x7f
b = (content_t[1] >> 3) & 0x1f
c = ((content_t[1] << 2) & 0x1c) | ((content_t[2] >> 6) & 0x03)
d = ((content_t[2] << 2) & 0xfc) | ((content_t[3] >> 6) & 0x03)
e = content_t[6] & 0x1f
return [a, b, c, d, e]
2. Steganalysis
https://github.com/YangzlTHU/VStego800K/tree/main/Steganalysis The following five steganalysis methods are provided.
-
SS-QCCN:Yang, H., Yang, Z., Bao, Y., & Huang, Y. (2019, December). Hierarchical representation network for steganalysis of qim steganography in low-bit-rate speech signals. In International Conference on Information and Communications Security (pp. 783-798). Springer, Cham.
-
CCN:Li, S. B., Jia, Y. Z., Fu, J. Y., & Dai, Q. X. (2014). Detection of pitch modulation information hiding based on codebook correlation network. Chinese Journal of Computers, 37(10), 2107-2117.
-
RSM:Lin, Z., Huang, Y., & Wang, J. (2018). RNN-SM: Fast steganalysis of VoIP streams using recurrent neural network. IEEE Transactions on Information Forensics and Security, 13(7), 1854-1868.
-
FSM:Yang, H., Yang, Z., Bao, Y., Liu, S., & Huang, Y. (2019). Fast steganalysis method for voip streams. IEEE Signal Processing Letters, 27, 286-290.
-
SFFN:Hu, Y., Huang, Y., Yang, Z., & Huang, Y. Detection of heterogeneous parallel steganography for low bit-rate VoIP speech streams. Neurocomputing, 419, 70-79.
CCN and SS-QCCN are steganalysis methods based on "manual feature + Classifier", which are used to detect CNB steganalysis. RSM, FSM and SFFN are steganalysis methods based on deep learning, which can be used to detect CNV and PMS steganalysis.
2.1 RSM
https://github.com/YangzlTHU/VStego800K/blob/main/Steganalysis/RSM/RSM.py
RNN-SM network is the first deep learning network applied in the steganalysis task of network voice stream.
It can be run by directly modifying the FOLDERS part. Category 1 represents the dataset directory of stego parameters, and 0 is the dataset directory of parameters with normal coding, i.e. embedding rate of 0(cover):
FOLDERS = [
{"class": 1, "folder": "/data/train/g729a_Steg_feat"},
# The folder that contains positive data files.
{"class": 0, "folder": "/data/train/g729a_0_feat"}
# The folder that contains negative data files.
]
It can be changed here or not: each extracted frame contains five coding parameters, of which the first three are LPC parameters and the last two are ACB parameters. If CNV steganography is used, because this steganography method only changes the LPC parameters, only the first three LPC parameters of each frame need to be used. If PMS steganography is used, because this steganography method only changes the Acb parameters, only the last two ACB parameters of each frame need to be used.
'''for CNV''' x_train,x_test=x_train[:,:,:3],x_test[:,:,:3] #Then you can put input_ Change 5 of dim to 3 model.add(LSTM(50, input_length=int(SAMPLE_LENGTH / 10), input_dim=3, return_sequences=True)) '''for PMS''' x_train,x_test=x_train[:,:,3:],x_test[:,:,3:] #Then you can put input_ Change 5 of dim to 2 model.add(LSTM(50, input_length=int(SAMPLE_LENGTH / 10), input_dim=2, return_sequences=True))
RSM network is composed of double-layer LSTM, and the classification layer is composed of full connection layer with sigmoid activation function. adam optimizer and binary classification cross entropy are used as loss function for training.
model = Sequential()
model.add(LSTM(50, input_length=int(SAMPLE_LENGTH / 10), input_dim=5, return_sequences=True)) # first layer, default input_dim is 5 and can be modified to 3 or 2
model.add(LSTM(50, return_sequences=True)) # second layer
model.add(Flatten()) # flatten the spatio-temporal matrix
model.add(Dense(1)) # output layer
model.add(Activation('sigmoid')) # activation function
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=["accuracy"])
Training part:
for i in range(ITER):
model.fit(x_train, y_train, batch_size=BATCH_SIZE, nb_epoch=1, validation_data=(x_test, y_test))
model.save('full_model_%d.h5' % (i + 1)) # Model saving
ACC, FPR and FNR evaluation indexes can be added to the training part:
y_pred = np.argmax(model.predict(x_test), axis=1) accuracy = accuracy_score(y_test, y_pred) tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel() fpr = fp / (fp + tn) fnr = fn / (fn + tp)
Other evaluation indicators:
from sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_score, accuracy_score y_pred = np.argmax(model.predict(x_test), axis=1) accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred) recall = recall_score(y_test, y_pred, average='binary') f1score = f1_score(y_test, y_pred, average='binary') MiF1 = f1_score(y_test, y_pred, average='micro') MaF1 = f1_score(y_test, y_pred, average='macro')
Reference:
https://github.com/YangzlTHU/VStego800K
https://github.com/fjxmlzn/RNN-SM
Liu Xiaokang, Tian Hui, Liu Jie, et al Research on IP voice steganography and steganalysis [J] Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2019