1. Traditional hash, consistency hash and hash slot
1.1 traditional hash (hard hash)
In the distributed system, it is assumed that there are n nodes, which is used in the traditional scheme mod(key, n) Map data and nodes.
When the capacity is expanded or reduced (even if only one node is increased or decreased), the mapping relationship becomes mod(key, n+1) / mod(key, n-1), the mapping relationship of most data will fail.
1.2 consistent hashing
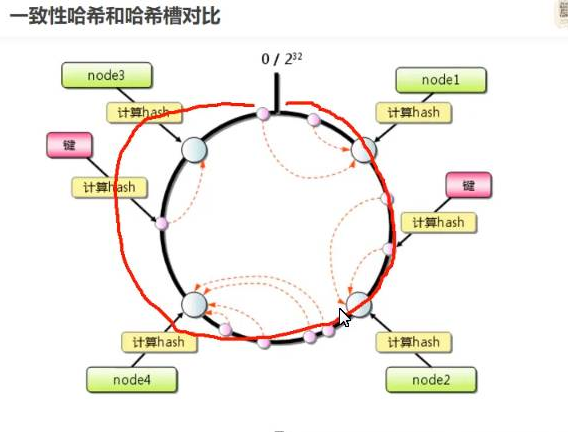
Consistent hash and random tree: a distributed caching protocol for alleviating hot spots on the World Wide Web). For the hash table with K keywords and n slots (nodes in the distributed system), after increasing or decreasing the slots, on average, only K/n keywords need to be remapped.
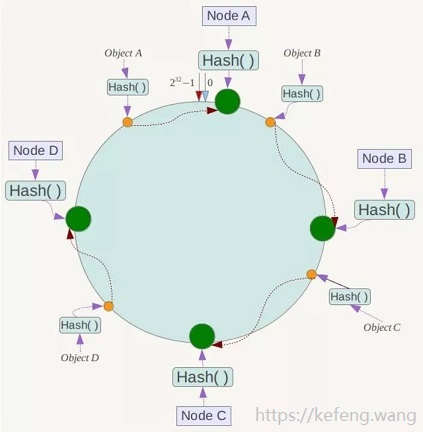
main points:
Common hash function and hash ring
The node is mapped to a hash ring
Object is mapped to a hash ring
Delete node: delete a node when the server shrinks, or a node goes down. Just modify the previous node
Add nodes; The service point adds Node X between Node B/C: it only affects the object between the node to be added (Node X) and the previous (clockwise is the forward direction) node (Node B) and, that is, Object C,
1.3 hash slot
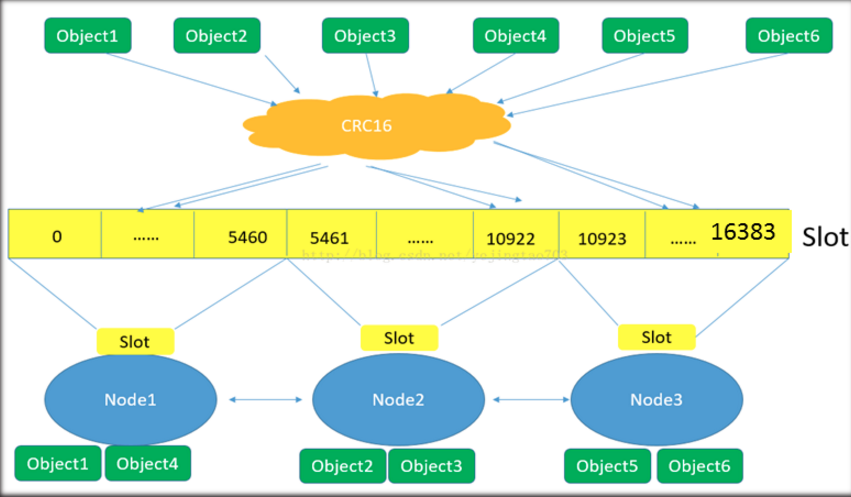
A redis cluster contains 16384 hash slots, and each data in the database belongs to one of the 16384 hash slots. The cluster uses the formula CRC16 (key)% 16384 to calculate which slot the key belongs to. Each node in the cluster is responsible for processing a part of the hash slot.
Slot returns detailed information about which cluster slot is mapped to which redis instance. This command is applicable to the redis cluster client library implementation to retrieve (or update when redirection is received) the mapping that associates the cluster hash slot with the actual node network coordinates (composed of ip address and tcp port), so that when a command is received, it can be sent to the correct instance of the key specified in the command.
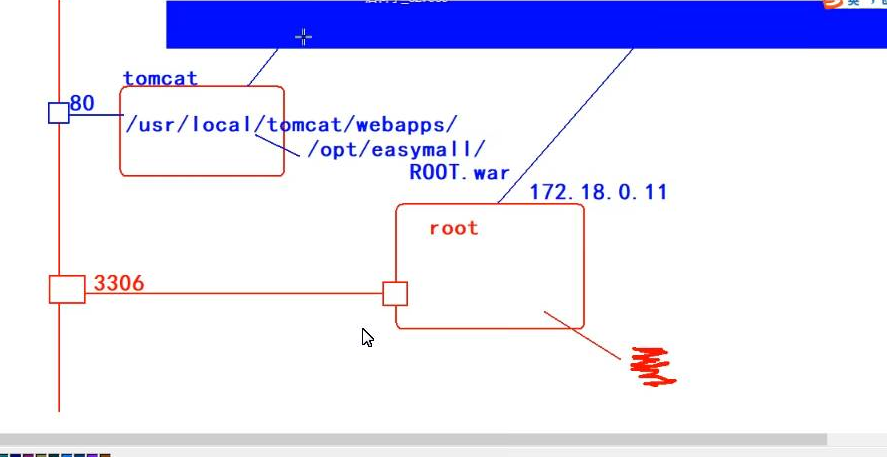
2. Connect Tomcat to mysql
Database connection mysql diagram
2..1 Preparation before connection
Delete all containers in docker and create network segments before connecting.
docker network rm my-net Delete previous network segment docker rm -f $(docker ps -aq) Delete all containers docker network create dockernet --subnet=172.18.0.0/24 Create network segment docker network ls ifconfig
two point two Start mysql container
Start the database in the virtual machine, mount the data volume, and import sql
docker volume create mysql-data Create a data volume (similar to a database in a computer) docker run -d --name mysql \ -p 3306:3306 \ --restart=always \ -v mysql-data: /var/lib/mysql \Database mount -e MYSQL_ROOT_PASSWORD=root \ Set administrator password --net=dockernet \ --ip=172.18.0.11 \ Manual assignment ip mariadb
Import sql file after connection
2.3 start tomcat container
docker run -d --name web \ --restart=always \ -v /opt/esaymall:/usr/local/tomcat/webapps \ -p 80:8080 --net=dockernet --ip=172.18.0.12 \ tomcat
2.4 access test
Visit the following website: http://192.168.64.150
3 .Elastic Search (ES)
It naturally supports distributed retrieval and can be used to store a large number of text caches. It is a non relational database like redis and mongodb
ES is often used to store a large amount of text information of commodities and deploy it in the distributed network.
3.1 ES server preparation
-
Clone docker base: es
-
The virtual machine memory is set to 2G or more
-
Modify the system bottom parameters - Description: it will be displayed in the following file cat
echo 'vm.max_map_count=262144' >>/etc/sysctl.conf
-
Restart the server: shutdown -r now is to restart the virtual machine
-
Setting ip: 192.168.64.181
-
Upload files to / root/
-
Perform the corresponding operation
3.2 ES installation and distributed deployment
3.2.1. Installing and starting the server
3.3 Ik Chinese word splitter and its internal mechanism
install server
1. Import elasticsearch-analysis-ik-7.9.3.zip from / root /
2. Copy the word breaker to three containers
# Copy ik participle to three es containers docker cp elasticsearch-analysis-ik-7.9.3.zip node1:/root/ docker cp elasticsearch-analysis-ik-7.9.3.zip node2:/root/ docker cp elasticsearch-analysis-ik-7.9.3.zip node3:/root/
3. Install word splitter
# Installing ik word breaker in node1 docker exec -it node1 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip # Installing ik word splitter in node2 docker exec -it node2 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip # Installing ik word splitter in node3 docker exec -it node3 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip # Restart the three es containers docker restart node1 node2 node3
4. View the installation results
Access in browser http://192.168.64.181:9200/_cat/plugins

Install client plug-ins
1. Add es-head.crx.zip to the web plugin
2. Developer mode operation
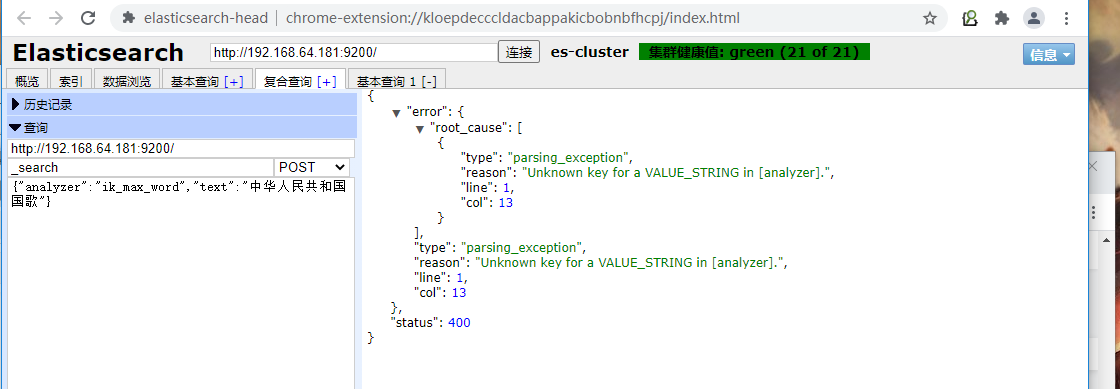
ik word segmentation test
ik_max_word granularity splitting
{
"analyzer":"ik_max_word",
"text":"National Anthem of the people's Republic of China"
}
ik_max_word: will split the text in the most fine-grained way. For example, will split the "National Anthem of the people's Republic of China" into "National Anthem of the people's Republic of China, the people's Republic of China, the Chinese, the people's Republic, the people, the people, the Republic, the Republic, and the Republic", and will exhaust all possible combinations, which is suitable for Term Query;
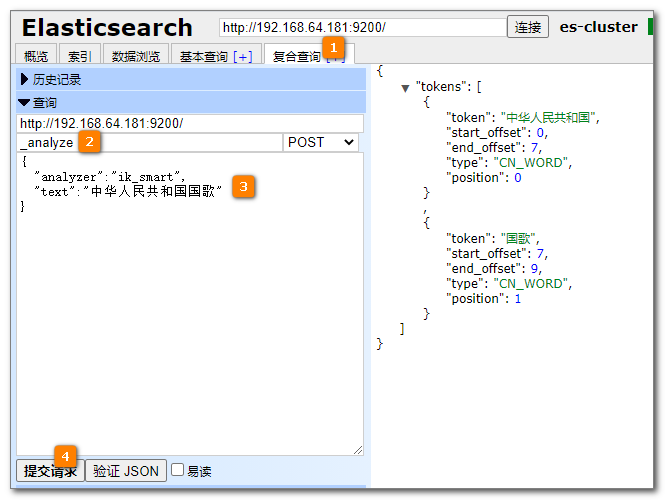
ik_smart Coarsest and finer granularity splitting
{
"analyzer":"ik_max_word",
"text":"National Anthem of the people's Republic of China"
}
ik_smart: it will split the "National Anthem of the people's Republic of China" into "National Anthem of the people's Republic of China", which is suitable for phase query.
three point four Operating ES with Kibana
Install kibana
1. Download Kibana image
docker pull kibana:7.9.3
2. Start Kibana container
docker run -d --name kibana \ --net es-net -p 5601:5601 \ -e ELASTICSEARCH_HOSTS='["http://node1:9200","http://node2:9200","http://node3:9200"]' \ --restart=always kibana:7.9.3
3. Access test
Visit Kibana via browser and enter Dev Tools:
http://192.168.64.181:5601/
Indexes, shards, and replicas
Index: elastic search index is used to store the data we want to search, which is stored in an inverted index structure.
Index fragmentation: storing a large amount of data in an index will cause performance degradation. At this time, the data can be stored in fragments.
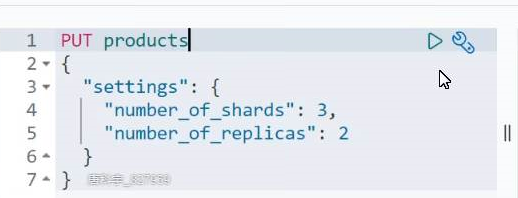
Example: setting index parameters
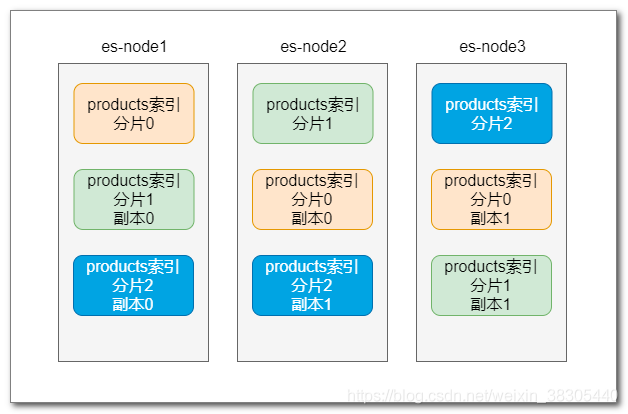
Index replica: create multiple replicas of Shards. Even if one node goes down, replica shards in other nodes can continue to work without making data unavailable.
Working mechanism of fragmentation:
- The data of the primary shard is copied to the replica shard
- When searching, it works in the way of load balancing to improve the processing capacity
- When the primary shard goes down, one of the replica shards will be automatically promoted to the primary shard
Mapping (data structure)
Similar to the database table structure, index data is also divided into multiple data fields, and data types and other attributes need to be set.
Mapping is the definition and description of the field structure in the index.
Data type of field
-
Number type:
- byte,short,integer,long
- float,double
- unsigned_long
-
String type:
- text: word segmentation
- keyword: no word segmentation, applicable to email, host address, zip code, etc
-
Date and time type:
- date
Type reference:
Field data types | Elasticsearch Guide [7.15] | Elastic
Create mapping
Word splitter settings:
analyzer: when adding a document to the index, the text type is segmented through the specified word splitter, and then inserted into the inverted index
search_analyzer: when using keyword retrieval, use the specified word splitter to segment keywords
When querying, search is preferred for keywords_ The word splitter set by analyzer, if search_ If the analyzer does not exist, use the analyzer word breaker.
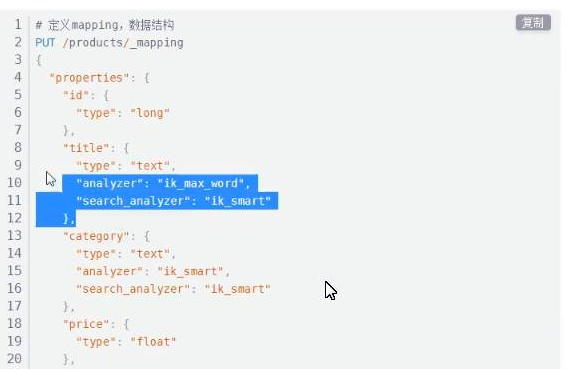
# Define mapping, data structure
PUT /products/_mapping
{
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"category": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"price": {
"type": "float"
},
"city": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"barcode": {
"type": "keyword"
}
}
}
Store document segmentation
Document operation
Add document: "the added document will have a name_ id, which can be automatically generated or manually specified. Generally, the id of the data can be used as the document id.
View document:
#View document GET /products/_doc/10037 #View the word segmentation results of the specified document title field GET /products/_doc/10037/_termvectors?fields=title
Modify document:
PUT: Complete replacement of documents
POST: Some fields can be modified
# Modify document - replace
PUT /products/_doc/10037
{
"id":"10037",
"title":"SONOS PLAY:1 Wireless intelligent sound system American original WiFi Connect home desktop speakers",
"category":"Chaoku digital venue",
"price":"9999.99",
"city":"Shanghai",
"barcode":"527783392239"
}
# Modify document - update some fields
POST /products/_update/10037
{
"doc": {
"price":"8888.88",
"city":"Shenzhen"
}
}Delete document:
#Delete message by id
DELETE /products/_doc/10037
#Empty queue
POST /products/_delete_by_query
{
"query": {
"match_all": {}
}
}
# Delete products index
DELETE /products