00 in front
Functions and adapter s come to the last part of the whole STL. Although these two parts are not many, they can be said together.
But as the two major components of the six major components of STL, they still have many design essences, which deserve our learning.
This is also the last summary note of [STL source code analysis].
01 Functors
Origin of imitative function
Imitation function, as the name suggests, is something similar to function. Before we talk about affine functions, let's see how they are generated.
We have seen a lot of algorithms before. Most algorithms provide a default version, but if users want to change the algorithm according to different application scenarios, it is also possible. For example, sort sorting algorithm is in ascending order by default, and we can change it to descending order according to different operations.
The "operation" here is the key to changing the algorithm.
First, the first method is to write the operation as a function, and then pass in the function pointer in the parameters of the algorithm. This can completely change the algorithm, but there will be a problem that it is not flexible enough to change at will.
For example, find the number of numbers greater than 10 in the array.
int RecallFunc(int *start, int *end, bool (*pf)(int)) {
int count=0;
for(int *i=start;i!=end+1;i++) {
count = pf(*i) ? count+1 : count;
}
return count;
}
bool IsGreaterThanTen(int num) {
return num>10 ? true : false;
}
int main() {
int a[5] = {10,100,11,5,19};
int result = RecallFunc(a,a+4,IsGreaterThanTen);
return 0;
}
We can write more than 10 as a function and pass it into the original algorithm.
However, if we want to implement greater than any number, let isgreaterthan (int Num) become IsGreaterThan(int num1,int num2), and pass in two parameters, it can not be implemented. (of course, it can also be defined as a global variable)
At this time, the imitation function comes in handy.
Another example is the common less for size comparison
template <class T>
struct less:public binary_function<T,T,bool>{
bool operator()(const T&x,const T&y)const{turn x<y};
};
After this definition, you can generate a functor object.
You can generate a functor entity and then call the entity:
less<int> less_obj; less_obj(3,5);
Or use temporary objects * * (common)**
less<int>()(3,5);
Of course, matching algorithm is the purpose of imitating function and only serves the algorithm.
sort(vi.begin(),vi.end(),less<int>());
###Imitation function and algorithm
As you may have noticed, affine functions need to overload parentheses.
Such overloading can make it well integrated into the algorithm.
For example, for the algorithm calculate, in the second version, pay attention to the third parameter
template <class InputIterator,class T,class BinaryOperation>
T accumulate(InputIterator first,InputIterator last,T init,BinaryOperation binary_op){
for(;first!=last;++first)
init=binary_op(init,*first);
return init;
}
The third parameter is binary_op, when an imitation function is passed in here, the operation of overloading parentheses can be directly applied to binary_ The parameters in op () are operated. If the passed in functor is plus, it can also be translated here as plus()(init,*first)
Inheritance of affine functions
Can we also design imitation functions? Of course.
such as
struct myclass{
bool operator()(int i,int j){
return i<j;
}
}myobj;
In this way, there seems to be no problem, and it can be called normally.
But by carefully comparing with the above less, you can find the difference.
less inherits a public binary_ function<T,T,bool>
This inheritance is the key to integrate the affine function into the STL system.
Matchability of affine functions
Under the inheritance relationship, there are two structures: unary_function and binary_function.
The definition is also very simple. It is mainly used to represent the parameter types and return value types of functions.
unary_function corresponds to unary operations, such as negation.
template <class Arg,class Result>
struct unary_function{
typedef Arg argument_type;
typedef Result sult_type;
};
binary_function corresponds to binary operations, such as addition and multiplication.
template <class Arg1,class Arg2,class Result>
struct binary_function{
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
};
If the functor inherits unary_function or binary_function, then the subsequent adapter can obtain various types of imitation functions.
This also makes the imitation function in STL have the same splicing ability as building blocks.
02 Adapter
What is the adapter
An Adapter, also known as an Adapter, actually changes the interface of an existing class. An application on a container is called a container adapter, a function adapter on an emulator, and an iterator adapter on an iterator
If A wants to realize the functions contained in B, there are two ways: A inherits B or A contains B.
This is the second implementation method for the adapter.
Container Adapters
We have seen the container adapter in the deque part, which is the implementation of queue and stack.
Their bottom layers are implemented by deque, so they are also called container adapters.
link
template <class T,class Sequence = deque<T>>
class stack{
protected:
Sequence c;
public:
bool empty() const{return c.empty()};
...
}
function adaptor
The function adapter is the highlight of the adapter. As we said earlier, the inheritance of imitation function is also to better cooperate with the adapter.
Use the example in the first article to illustrate the function adapter
cout<<count_if(vi.begin(),vi.end(),bind2nd(less<int>(),40));
bind2nd here is a typical function adapter.
Look at the code first
template <class Operation>
class binder2nd:public unary_function<typename Operation::first_agument_type,typename Operation::result_type>{
protected:
Operation op;
typename Operation::second_argument_type value;
public:
binder2nd(const Operation&x,const typename Operation::second_argument_type&y)
:op(x),value(y){}
typename Operation::result_type
operator(const typename Operation::first_agument_type &x )const{
return op(x,value);
}
};
This code contains a large amount of information. Let's say it bit by bit.
- First, understand the usage of typename. Typename can directly tell the compiler that the type behind is not a variable to prevent compilation failure.
- The function of bind2nd is to bind a value to the second parameter of the imitation function.
- Note that binder2nd is written here, which is the inner function of bind2nd.
- binder2nd did not call less() at first, but recorded it with op.
- Operation::second_argument_type is the link where the adapter asks questions about the functor, and then the functor tells the adapter the type of the second parameter (int for less())
- Finally, the parentheses are overloaded, and less() is really called
- The adapter is used to modify the imitation function. If the imitation function overloads the parentheses, the adapter needs to have the same effect after modification, so it also needs to overload the parentheses.
For binder2nd, users need to know what type of Operation is before they can use it. In the above example, Operation is actually less, but it is very troublesome to use, so STL provides the packaging of the outer interface.
template <class Operation,class T>
inline binder2nd<Operation>bind2nd(const Operation&op,const T&x){
typedef typename Operation::second_argument_type arg2_type;
return binder2nd<Operation>(op,arg2_type(x));
}
First ask the type of the second parameter, and then automatically deduce the type of op.
The function adapter is the same as the imitation function. If it is possible to continue to modify, it will inherit unary_function or binary_function.
iterator adaptor
reverse iterator
The most interesting of iterator adapters is the reverse iterator, or reverse iterator, which processes elements from end to end.
Our common iterators are as follows:
sort(vi.begin(),vi.end());
The inverse iterator is written as
sort(vi.rbegin(),vi.rend());
Let's look at the definitions of rbegin() and rend()
rbegin(){
return reverse_iterator(end());
}
rend(){
return reverse_iterator(begin());
}
It can be seen that the implementation is also reverse. The head takes the tail and the tail takes the head. However, there is still a difference in the actual overload implementation process.
Let's look at a picture first:
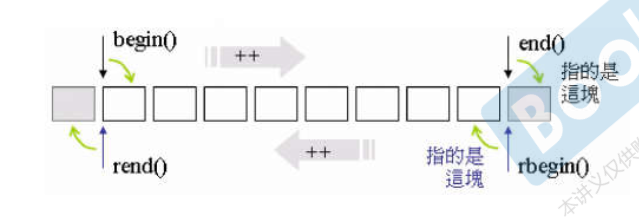
Because the front is closed and the back is open, we often use begin() as the starting position, corresponding to the first element, and end() as the next position of the last element.
So after reverse, rbegin() refers to the previous element of end(), and rend() refers to the previous element of begin().
So when overloading, you need to know what the previous element is (but the position of the pointer remains the same)
reference operator*()const{
Iterator tmp=current;
return *--tmp;
}
#### inserter
inserter is also an iterator adapter, which will change the assignment operation of iterator into insertion operation.
The implementation of inserter mainly depends on the cleverness of overloading.
Suppose there are two list s
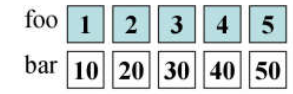
If executed:
list <int>::iterator it=foo.begin(); copy(bar.begin(),bar.end(),inserter(foo,it));
Changes from overlay to insert

For copy, the implementation is as follows:
template <class ImputIterator,class OutputIterator>
OutputIterator copy(InputIterator first,InputIterator last,OutputIterator result){
while(first!=last){
*result=*first;
++result;
++first;
}
return result;
}
The process is to copy the original value to get the result through the movement of first.
How does the inserter implement other operations here?
In fact, the implementation of inserter overloads "="
template <class Container>
class insert_iterator{
...
insert<Container>&operator=(const typename Container::value_type& value){
iter=container->insert(iter,value);
++iter;
return *this;
}
}
Is it very clever? In copy, when * result=*first, this = will call insert to insert the value, and then move the pointer to keep following.
In this way, the function of inserter is realized.
X adapter
The so-called X adapter refers to some special adapters that will also be used in addition to the classic types of adapters. Like ostream_iterator and istream_iterator
ostream_iterator
First, let's look at ostream. The commonly used is cout
Structurally by out_stream and separator.
class ostream_iterator:public iterator<output_iterator_tag,void,void,void,void>{
basic_ostream<charT,traits>*out_stream;
const chatT*delim;
...
}
Take a look at an example to realize its implementation:
std::vector<int>myvector;
for(int i=1;i<10;i++)
myvector.push_back(i*10);
std::ostream_iterator<int>out_it(std::cout,",");
std:copy(myvector.begin(),myvector.end(),out_it);
Here, when creating ostream, cout and the separator "," are passed in, which is equivalent to outputting a number first and then a comma.
The focus is on the call of the third parameter in copy.
We have also seen the implementation of copy in the previous inserter
template <class ImputIterator,class OutputIterator>
OutputIterator copy(InputIterator first,InputIterator last,OutputIterator result){
while(first!=last){
*result=*first;
++result;
++first;
}
return result;
}
For ostream, how to integrate itself into algorithms like copy is the key.
ostream_iterator cleverly overloaded "=" to make everything reasonable.
ostream_iterator<T,charT,traits>&operator=(const T& value){
*out_stream<<value;
if(delim!=0)out_stream<<delim;
return *this;
}
When =, first output value. If the separator exists, then output another separator.
istream_iterator
The opposite of ostream is istream, that is, operations such as cin.
Structurally, it is composed of instream and value.
class istream_iterator:public iterator<input_iterator_tag,T,Distance,const T*,const T&>{
basic_istream<charT,traits>*in_stream;
T value;
...
}
for instance
double value1,value2; std::istream_iterator<double>eos; std::istream_iterator<double>iit(std::cin); if(iit!=eos)value1=*iit; ++iit; if(iit!=eos)value2=*iit;
You can see that after creating iit, you can get the value of value. After moving iit, you can get the next value.
The implementation here is istream_ The essence of iterator.
Actually, istream_ The iterator has stored the value into value when it is created.
istream_iterator(istream_type& s):in_stream(&s){
++*this;
}
...
istream_iterator<T,charT,traits,Distance>& operator++(){
if(in_stream&&!(in_stream>>value)) in_stream=0;
return *this;
}
const T& operator*() const {
return value;
}
When it is created, it calls + +, and then overloads the + + operation to get the input value of value. Finally, * dereference to obtain the value value.
The operation to read the value immediately upon creation is istream_ Notable points in iterator.
03 summary
The above is all the contents of the summary notes of [STL source code analysis].
It involves all aspects of STL, which is not very detailed, but also has a certain reference. Small partners who need to prepare for work can be used as review materials to go over it from scratch and deepen their memory.
Thanks for reading.