
Above The implementation of double God factor is recorded, and the implementation of candidate factor is recorded in this paper. When the candidate factor value is True, the stock will enter the candidate stock pool to monitor whether to buy.
Main code analysis
Create a new source file named data_center_v5.py, see the end of the text for all contents. v5 mainly involves five changes:
New calculation mean square factor function
def ma(df, n=5, factor='close'):
This function is used to calculate the mean square factor, where:
- Parameter df is the DataFrame of the expansion factor to be calculated
- Parameter n is the period of the moving average to be calculated. The 5-day moving average is calculated by default
- The parameter factor is the factor of the moving average to be calculated. It is the closing price by default
- The return value is the DataFrame containing the extension factor
name = '{}ma_{}'.format('' if 'close' == factor else factor + '_', n)
Set the name of the moving average factor. For example, the name of the 5-day moving average of the closing price is ma_5. The name of the 5-day moving average of trading volume is volume_ma_5.
s = pd.Series(df[factor], name=name, index=df.index)
Take the factor column of the moving average to be calculated.
s = s.rolling(center=False, window=n).mean()
Using rolling and mean to calculate the moving average data.
df = df.join(s)
Add the moving average data to the original DataFrame.
df[name] = df[name].apply(lambda x: round(x + 0.001, 2))
The average value shall be kept to two decimal places.
return df
Returns the DataFrame containing the moving average factor.
Add multiple mean square factor functions
def mas(df, ma_list=None, factor='close'):
This function is used to calculate multiple moving average factors, and internally call ma to calculate a single moving average, where:
- Parameter df is the DataFrame of the expansion factor to be calculated
- Parameter ma_list: the period list of the moving average to be calculated. The default is None
- The parameter factor is the factor of the moving average to be calculated. It is the closing price by default
- The return value is the DataFrame containing the extension factor
if ma_list is None:
ma_list = []
for i in ma_list:
df = ma(df, i, factor)
return df
Call the function ma circularly to calculate multiple moving average factors.
New function for calculating average crossing factor
def cross_mas(df, ma_list=None):
This function is used to calculate the average crossing factor, where:
- Parameter df is the DataFrame of the expansion factor to be calculated
- Parameter ma_list is the cycle list of the moving average, and the default is None
- The return value is the DataFrame containing the extension factor
If the lowest price of the day is not higher than the moving average price and the closing price of the day is not lower than the moving average price, the moving average factor value of the day is True, otherwise it is False.
if ma_list is None:
ma_list = []
for i in ma_list:
df['cross_{}'.format(i)] = (df['low'] <= df['ma_{}'.format(i)]) & (
df['ma_{}'.format(i)] <= df['close'])
return df
Cycle through multiple moving average factors.
New calculation candidate factor function
def candidate(df):
This function is used to calculate candidate factors, where:
- Parameter df is the DataFrame of the expansion factor to be calculated
- The return value is the DataFrame containing the extension factor
If the following three conditions are met at the same time, the stock is taken as a candidate on the current day, and the factor value is True, otherwise it is False
- The daily line of the day crosses the 5, 10, 20 and 30 day moving average at the same time
- The 30 day moving average is above the 60 day moving average
- Double gods are formed on that day
ma_list = [5, 10, 20, 30, 60]
List of moving average periods.
temp_df = mas(df, ma_list)
Calculate the factor of the moving average and save it to the temporary DataFrame.
temp_df = cross_mas(temp_df, ma_list)
Calculate the multi thread factor and save it to the temporary DataFrame.
column_list = ['cross_{}'.format(x) for x in ma_list[:-1]]
List of column names for threading factors.
df['candidate'] = temp_df[column_list].all(axis=1) & (temp_df['ma_30'] >= temp_df['ma_60']) & df['ss']
Calculate the candidate factor. If True, it is a candidate.
return df
Returns a DataFrame containing candidate factors. Taking 603358 Huada technology as an example, the printing results on November 24, 2021 are as follows:
date open high low ... isST zt ss candidate 0 2017-01-25 12.280496 14.735282 12.280496 ... 0 True False False 1 2017-01-26 16.208810 16.208810 16.208810 ... 0 True False False 2 2017-02-03 17.830019 17.830019 17.830019 ... 0 True False False 3 2017-02-06 19.612037 19.612037 17.902219 ... 0 True False False 4 2017-02-07 19.474201 20.501405 18.968804 ... 0 False False False ... ... ... ... ... ... ... ... ... ... 1169 2021-11-18 21.300000 21.390000 20.680000 ... 0 False False False 1170 2021-11-19 20.660000 20.660000 19.060000 ... 0 False False False 1171 2021-11-22 19.940000 20.420000 19.920000 ... 0 False False False 1172 2021-11-23 19.800000 20.200000 19.650000 ... 0 False False False 1173 2021-11-24 19.870000 21.660000 19.390000 ... 0 True True True [1174 rows x 20 columns]
It can be seen that on November 24, 2021, the candidate factor of the stock is True, which is verified in combination with the following K-line diagram:
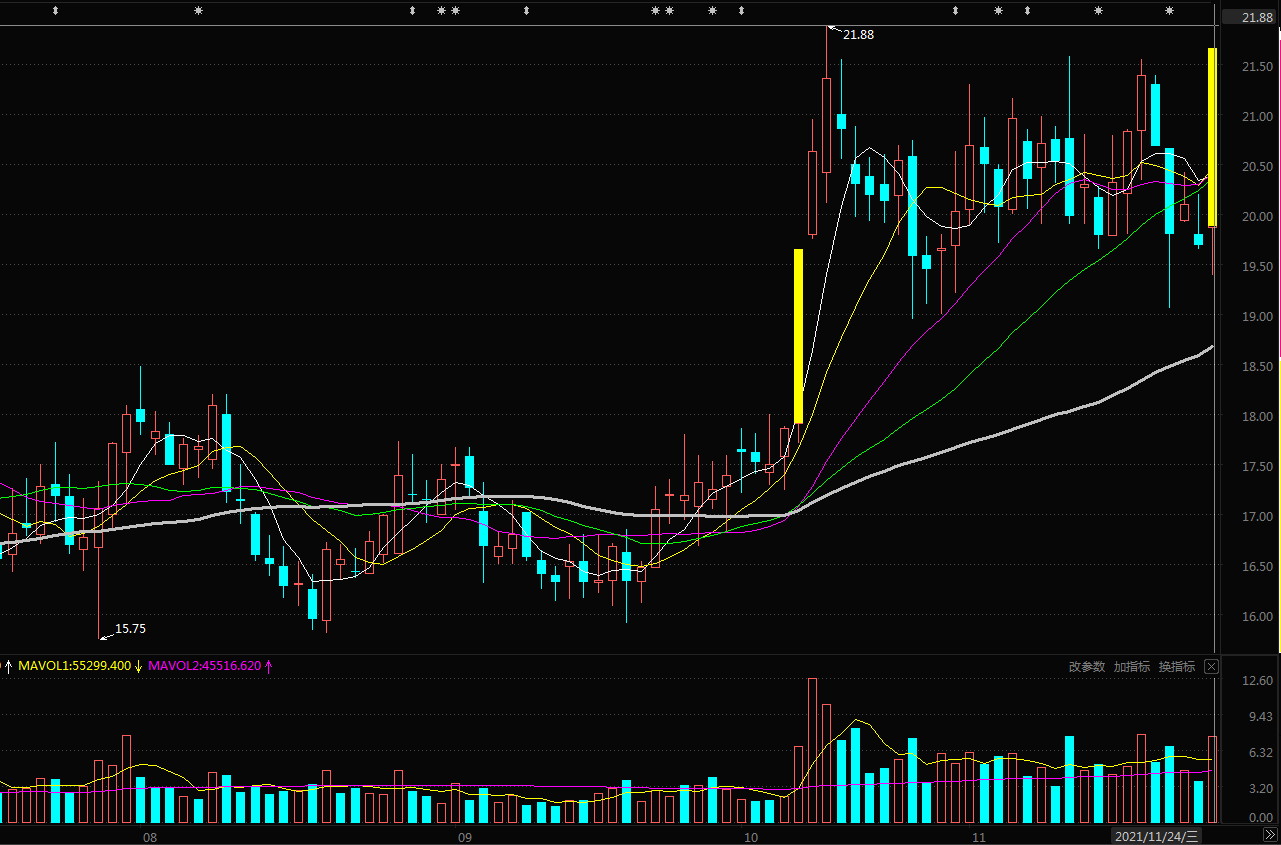
On November 24, 2021, the daily line crosses the 5, 10, 20 and 30 day moving average at the same time. The 30 day moving average is above the 60 day moving average, and a double God is formed on that day, which meets the candidate conditions of the strategy.
Modify the calculation expansion factor function
def extend_factor(df):
df = df.pipe(zt).pipe(ss, delta_days=30).pipe(candidate)
return df
Use pipe to calculate the daily limit, double God and whether it is a candidate stock.
Summary
So far, we have completed the calculation of the main strategy factors, and we can use these factors to calculate the strategy winning rate in the future.
So far, the created data is only used for printing, and storage is not realized. Therefore, as long as the program can run normally, there is no need to wait for the program to run. Before the strategy winning rate calculation and backtesting, we first record the multi-threaded calculation and the process of saving data to MySQL in subsequent articles.
data_ center_ All codes of v5.py are as follows:
import baostock as bs
import datetime
import sys
import numpy as np
import pandas as pd
# Available daily line quantity constraints
g_available_days_limit = 250
# BaoStock daily data field
g_baostock_data_fields = 'date,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,peTTM,pbMRQ, psTTM,pcfNcfTTM,isST'
def get_stock_codes(date=None):
"""
Gets the of the specified date A Stock code list
If parameter date If it is blank, the date of the last trading day will be returned A Stock code list
If parameter date If it is not empty and is a trading day, return date Current day A Stock code list
If parameter date If it is not empty but not a trading day, the non trading day information will be printed and the program will exit
:param date: date
:return: A List of stock codes
"""
# Log in to biostock
bs.login()
# Query stock data from BaoStock
stock_df = bs.query_all_stock(date).get_data()
# If the length of the acquired data is 0, it means that the date is not a trading day
if 0 == len(stock_df):
# If the parameter date is set, the print message indicates that date is a non trading day
if date is not None:
print('The currently selected date is a non trading day or there is no trading data, please set it date Is the date of a historical trading day')
sys.exit(0)
# If the parameter date is not set, the latest trading day will be found from the history. When the length of stock data obtained is not 0, the latest trading day will be found
delta = 1
while 0 == len(stock_df):
stock_df = bs.query_all_stock(datetime.date.today() - datetime.timedelta(days=delta)).get_data()
delta += 1
# Logout login
bs.logout()
# Through stock data screening, the stock codes of Shanghai Stock Exchange and Shenzhen Stock Exchange are between sh.600000 and sz.39900
stock_df = stock_df[(stock_df['code'] >= 'sh.600000') & (stock_df['code'] < 'sz.399000')]
# Return to stock list
return stock_df['code'].tolist()
def create_data(stock_codes, from_date='1990-12-19', to_date=datetime.date.today().strftime('%Y-%m-%d'),
adjustflag='2'):
"""
Download the daily data of the specified stock within the specified date and calculate the expansion factor
:param stock_codes: Stock code of data to be downloaded
:param from_date: Daily line start date
:param to_date: Daily line end date
:param adjustflag: Option 1: Post reinstatement option 2: pre reinstatement option 3: no reinstatement option, default to pre reinstatement option
:return: None
"""
# Download stock cycle
for code in stock_codes:
print('Downloading{}...'.format(code))
# Log in to BaoStock
bs.login()
# Download daily data
out_df = bs.query_history_k_data_plus(code, g_baostock_data_fields, start_date=from_date, end_date=to_date,
frequency='d', adjustflag=adjustflag).get_data()
# Logout login
bs.logout()
# Eliminate stop disk data
if out_df.shape[0]:
out_df = out_df[(out_df['volume'] != '0') & (out_df['volume'] != '')]
# If the data is empty, it is not created
if not out_df.shape[0]:
continue
# Delete duplicate data
out_df.drop_duplicates(['date'], inplace=True)
# Daily data is less than g_available_days_limit, do not create
if out_df.shape[0] < g_available_days_limit:
continue
# Convert numerical data to float type for subsequent processing
convert_list = ['open', 'high', 'low', 'close', 'preclose', 'volume', 'amount', 'turn', 'pctChg']
out_df[convert_list] = out_df[convert_list].astype(float)
# Reset index
out_df.reset_index(drop=True, inplace=True)
# Calculate expansion factor
out_df = extend_factor(out_df)
print(out_df)
def extend_factor(df):
"""
Calculate expansion factor
:param df: Expansion factor to be calculated DataFrame
:return: With expansion factor DataFrame
"""
# Use pipe to calculate the daily limit, double God and whether it is a candidate stock
df = df.pipe(zt).pipe(ss, delta_days=30).pipe(candidate)
return df
def zt(df):
"""
Calculate the limit factor
If the limit rises, the factor is True,Otherwise False
The closing price of the current day was 9% higher than the closing price of the previous day.8%And above as the trading judgment standard
:param df: Expansion factor to be calculated DataFrame
:return: With expansion factor DataFrame
"""
df['zt'] = np.where((df['close'].values >= 1.098 * df['preclose'].values), True, False)
return df
def shift_i(df, factor_list, i, fill_value=0, suffix='a'):
"""
Calculate the movement factor for obtaining the front i Later or later i Daily factor
:param df: Expansion factor to be calculated DataFrame
:param factor_list: List of factors to be moved
:param i: Steps moved
:param fill_value: For filling NA The default value is 0
:param suffix: Value is a(ago)When, it means that the historical data obtained by the mobile is used to calculate the index; Value is l(later)When, it means to obtain future data for calculating income
:return: With expansion factor DataFrame
"""
# Select the column that needs to be shifted to form a new DataFrame for shift operation
shift_df = df[factor_list].shift(i, fill_value=fill_value)
# Rename the new DataFrame column
shift_df.rename(columns={x: '{}_{}{}'.format(x, i, suffix) for x in factor_list}, inplace=True)
# Merge the renamed DataFrame into the original DataFrame
df = pd.concat([df, shift_df], axis=1)
return df
def shift_till_n(df, factor_list, n, fill_value=0, suffix='a'):
"""
Calculation range shift factor
Used to get pre/after n The correlation factor within the day is called internally shift_i
:param df: Expansion factor to be calculated DataFrame
:param factor_list: List of factors to be moved
:param n: Move steps range
:param fill_value: For filling NA The default value is 0
:param suffix: Value is a(ago)When, it means that the historical data obtained by the mobile is used to calculate the index; Value is l(later)When, it means to obtain future data for calculating income
:return: With expansion factor DataFrame
"""
for i in range(n):
df = shift_i(df, factor_list, i + 1, fill_value, suffix)
return df
def ss(df, delta_days=30):
"""
Calculate the double God factor, that is, the two trading limits of the interval
If double gods are formed on that day, the factor is True,Otherwise False
:param df: Expansion factor to be calculated DataFrame
:param delta_days: The time between two daily limits cannot exceed this value, otherwise it will not be judged as double God, and the default value is 30
:return: With expansion factor DataFrame
"""
# Move the limit factor to get the near Delta_ The daily limit within days is saved in a temporary DataFrame
temp_df = shift_till_n(df, ['zt'], delta_days, fill_value=False)
# Generate a list for subsequent retrieval from day 2 to delta_ Are there any daily limit days ago
col_list = ['zt_{}a'.format(x) for x in range(2, delta_days + 1)]
# To calculate double gods, three conditions shall be met at the same time:
# 1. Day 2 to delta_days days ago, there was at least one daily limit
# 2. 1 day ago was not the daily limit (otherwise, it was the continuous daily limit, not the interval daily limit)
# 3. The day is the daily limit
df['ss'] = temp_df[col_list].any(axis=1) & ~temp_df['zt_1a'] & temp_df['zt']
return df
def ma(df, n=5, factor='close'):
"""
Calculate mean square factor
:param df: Expansion factor to be calculated DataFrame
:param n: The period of the moving average to be calculated. The 5-day moving average is calculated by default
:param factor: The factor of the moving average to be calculated is the closing price by default
:return: With expansion factor DataFrame
"""
# The name of the moving average, for example, the name of the 5-day moving average of the closing price is ma_5. The name of the 5-day moving average of trading volume is volume_ ma_ five
name = '{}ma_{}'.format('' if 'close' == factor else factor + '_', n)
# Take the factor column of the moving average to be calculated
s = pd.Series(df[factor], name=name, index=df.index)
# Using rolling and mean to calculate the moving average data
s = s.rolling(center=False, window=n).mean()
# Add the moving average data to the original DataFrame
df = df.join(s)
# The average value shall be kept to two decimal places
df[name] = df[name].apply(lambda x: round(x + 0.001, 2))
return df
def mas(df, ma_list=None, factor='close'):
"""
Calculate multiple moving average factors, internal call ma Calculate a single moving average
:param df: Expansion factor to be calculated DataFrame
:param ma_list: The period list of the moving average to be calculated. The default is None
:param factor: The factor of the moving average to be calculated is the closing price by default
:return: With expansion factor DataFrame
"""
if ma_list is None:
ma_list = []
for i in ma_list:
df = ma(df, i, factor)
return df
def cross_mas(df, ma_list=None):
"""
Calculate the average crossing factor
If the lowest price of the day is not higher than the moving average price
And the closing price of the day shall not be lower than the moving average price
Then the daily moving average factor value is True,Otherwise False
:param df: Expansion factor to be calculated DataFrame
:param ma_list: The period list of the moving average. The default is None
:return: With expansion factor DataFrame
"""
if ma_list is None:
ma_list = []
for i in ma_list:
df['cross_{}'.format(i)] = (df['low'] <= df['ma_{}'.format(i)]) & (
df['ma_{}'.format(i)] <= df['close'])
return df
def candidate(df):
"""
Calculate whether it is a candidate
If the daily line crosses the 5, 10, 20 and 30 day moving average at the same time
And the 30 day moving average is above the 60 day moving average
And form double gods on that day
Then the current day is the candidate, and the factor value is True,Otherwise False
:param df: Expansion factor to be calculated DataFrame
:return: With expansion factor DataFrame
"""
# Moving average period list
ma_list = [5, 10, 20, 30, 60]
# Calculate the factor of the moving average and save it to the temporary DataFrame
temp_df = mas(df, ma_list)
# Calculate the multi thread factor and save it to the temporary DataFrame
temp_df = cross_mas(temp_df, ma_list)
# List of column names of threading factors
column_list = ['cross_{}'.format(x) for x in ma_list[:-1]]
# Calculate whether it is a candidate
df['candidate'] = temp_df[column_list].all(axis=1) & (temp_df['ma_30'] >= temp_df['ma_60']) & df['ss']
return df
if __name__ == '__main__':
stock_codes = get_stock_codes()
create_data(stock_codes)
Blog content is only used for communication and learning, does not constitute investment suggestions, and is responsible for its own profits and losses!
Personal blog: https://coderx.com.cn/ (priority update)
Welcome to forward and leave messages. Wechat group has been established for learning and communication. Group 1 is full and group 2 has been created. Interested readers please scan the code and add wechat!
