"Stones from other mountains can attack jade". Standing on the shoulders of giants can see higher and go further. On the road of scientific research, we need the help of the east wind to move forward faster. To this end, we have specially collected and sorted out some practical code links, data sets, software, programming skills, etc., and opened a "stone from other mountains" column to help you ride the wind and waves and move forward bravely all the way. Please pay attention.
By Benedikt Droste
Compile VK
Source: Towards Data Science
Original link: https://towardsdatascience.com/
Natural language processing is one of the most exciting areas of deep learning.
In the field of computer vision, we have used transfer learning for several years, and have very powerful pre training models, such as VGG, Resnet or EfficientNet.
With the publication of the famous Attention Is All You Need, breakthroughs have also been made in the field of natural language processing.
There are thousands of pre trained NLP task models on Huggingface, enabling us to create state-of-the-art models with less data than ever before.
01
About the game
The host of the competition is CommonLit, a non-profit educational technology organization. They offer free reading and writing courses.
In education, it is very important to provide students with texts suitable for their reading level. Teachers should not directly let a 10-year-old child read Goethe's Faust, because these texts are still challenging.
This is why CommonLit often requires teachers and scholars to rank certain texts according to readability:
The target value is the result of Bradley Terry's pairwise comparison of 111000 extracts. Teachers in grades 3-12 (mostly between grades 6-10) act as raters for these comparisons.
The result is a score ranging from - 4 to + 2. The larger the number, the stronger the readability. Each excerpt is graded by several people at a time. Then take the average as the final score.
In the challenge, there is a training data set containing text and corresponding scores. The model should learn the score and then predict the score of the new text.
02
Common approach
The pre trained HuggingFace model has been very popular in any type of NLP task: classification, regression, summarization, text generation and so on.
Obviously, at the beginning of the competition, the performance of transformer architecture is significantly better than the traditional machine learning method or LSTM architecture. Therefore, most participants will focus on the fine-tuning of transformer.
Since the process of generating labeled training data requires a lot of resources, there are relatively few examples available, about 2800.
Most people initially use Roberta base, a transformer with 12 layers, 12 headers and 125 million parameters. This transformer has produced good results without too much fine tuning.
However, we have identified several areas that can significantly improve performance, which I will briefly explain later:
- Large model
- Discriminant learning rate
- Custom header
- Bagging and Stacking
- Pseudo tag
- Infrastructure
03
Large model
As can be seen from other competitions, the larger version of the pre training model usually performs better.
Some architectures usually have small, basic, and large versions (such as RoBERTa). These differences are mainly reflected in the number of hidden layers, the size of hidden states and the number of heads.
This connection has intuitive significance: more parameters can better map the pattern, that is, the model can understand more and more in-depth information. The larger model also performed better in this competition.
However, due to limited data, many teams failed to converge the model, or they only fitted the model on the training data. For us, the breakthrough lies in the learning rate and customized head.
04
Discriminant learning rate
In transfer learning, it is no secret that it is not always meaningful to train all levels at the same learning rate.
Sometimes all embedded layers are frozen, the head is trained at a higher learning rate, and then all layers are trained again at a lower learning rate.
The idea is that the first layer of neural network learns general concepts, and then each layer learns more task specific information.
For this reason, we have to adjust the first layer, for example, the new header, which contains random weights during initialization.
Therefore, we implemented a custom optimizer. We use a linearly increasing learning rate for the basic architecture of RoBERTa and a fixed 1e-3 or 2e-4 (depending on the pre trained model) learning rate for the head. The learning rate starts from 1e-5 of the first layer and ends at 5e-5 of the last layer.
def create_optimizer(model,adjust_task_specific_lr=False):
named_parameters = list(model.named_parameters())
roberta_parameters = named_parameters[:388]
attention_parameters = named_parameters[388:392]
regressor_parameters = named_parameters[392:]
attention_group = [params for (name, params) in attention_parameters]
regressor_group = [params for (name, params) in regressor_parameters]
parameters = []
if adjust_task_specific_lr:
for layer_num, (name, params) in enumerate(attention_parameters):
weight_decay = 0.0 if "bias" in name else 0.01
parameters.append({"params": params,
"weight_decay": weight_decay,
"lr": Config.task_specific_lr})
for layer_num, (name, params) in enumerate(regressor_parameters):
weight_decay = 0.0 if "bias" in name else 0.01
parameters.append({"params": params,
"weight_decay": weight_decay,
"lr": Config.task_specific_lr})
else:
parameters.append({"params": attention_group})
parameters.append({"params": regressor_group})
increase_lr_every_k_layer = 1
lrs = np.linspace(1, 5, 24 // increase_lr_every_k_layer)
for layer_num, (name, params) in enumerate(roberta_parameters):
weight_decay = 0.0 if "bias" in name else 0.01
splitted_name = name.split('.')
lr = Config.lr
if len(splitted_name) >= 4 and str.isdigit(splitted_name[3]):
layer_num = int(splitted_name[3])
lr = lrs[layer_num // increase_lr_every_k_layer] * Config.lr
parameters.append({"params": params,
"weight_decay": weight_decay,
"lr": lr})
return AdamW(parameters)
05
Custom header
When you fine tune a pre trained model, you usually remove the last layer of the neural network (such as the classification header) and replace it with a new one.
The transformer usually outputs the last hidden state. This contains all the last hidden states of all words in each sequence.
At the beginning, there is always a special CLS tag, which can be used for downstream tasks (or classification without further fine-tuning), according to the author of the BERT paper. The idea is that the tag is already the representation of the whole sequence. This marker is often used as a regression in this competition. Another possibility is the additional output pool state. It contains the last hidden state of CLS tag, which is further processed by linear layer and Tanh activation function. These outputs can also be used as inputs to the regression head. There are countless other possibilities. A very comprehensive summary can be found here:
https://www.kaggle.com/rhtsingh/utilizing-transformer-representations-efficiently
We tried different expressions. Finally, we also use CLS tags and a form of attention pool. In one of their tests, the authors of the BERT paper showed that connecting on multiple layers can produce better results than using only the last layer.
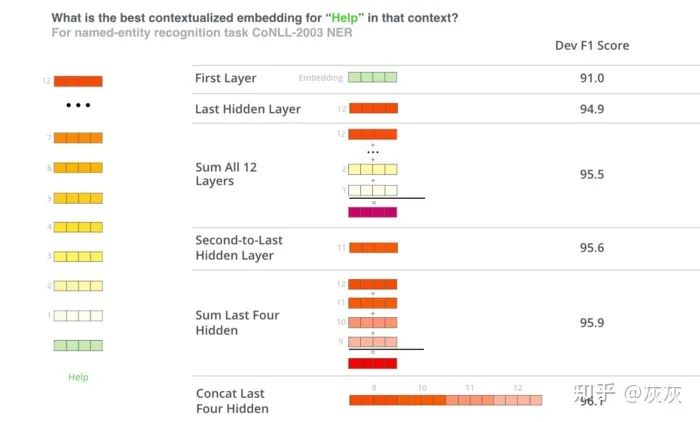
The idea behind this is that different layers contain different information. Therefore, we connected the CLS tags of the last four layers. In addition, we also generated attention weights for the last four layers. Then we connect the results and pass them through the last linear layer. The following is the implementation plan:
class AttentionHead(nn.Module):
def __init__(self, h_size, hidden_dim=512):
super().__init__()
self.W = nn.Linear(h_size, hidden_dim)
self.V = nn.Linear(hidden_dim, 1)
def forward(self, features):
att = torch.tanh(self.W(features))
score = self.V(att)
attention_weights = torch.softmax(score, dim=1)
context_vector = attention_weights * features
context_vector = torch.sum(context_vector, dim=1)
return context_vector
class CLRPModel(nn.Module):
def __init__(self,transformer,config):
super(CLRPModel,self).__init__()
self.h_size = config.hidden_size
self.transformer = transformer
self.head = AttentionHead(self.h_size*4)
self.linear = nn.Linear(self.h_size*2, 1)
self.linear_out = nn.Linear(self.h_size*8, 1)
def forward(self, input_ids, attention_mask):
transformer_out = self.transformer(input_ids, attention_mask)
all_hidden_states = torch.stack(transformer_out.hidden_states)
cat_over_last_layers = torch.cat(
(all_hidden_states[-1], all_hidden_states[-2], all_hidden_states[-3], all_hidden_states[-4]),-1
)
cls_pooling = cat_over_last_layers[:, 0]
head_logits = self.head(cat_over_last_layers)
y_hat = self.linear_out(torch.cat([head_logits, cls_pooling], -1))
return y_hat06
Bagging and Stacking
As mentioned earlier, we don't have so much training data in this competition. The training of more than two epoch s resulted in over fitting.
We use 50% discount to train data and create a model for each discount. We created an evaluation program to evaluate more frequently as scores increased (in the case of lower RMSE). Save the model with the highest verification score in the two epoch s. We try to relate closely to the leaderboard: the lower the cv, the better our lb score.
This is one of the most important things in every challenge:
If possible, you should try to narrow the gap between local cv and leaderboard.
07
Pseudo tag
As mentioned earlier, the training data set is very small. We used new, unmarked text, such as Wikipedia articles (available free of charge through the api), and adjusted the length of the text according to the length of the training example. Then, we use the existing set to predict the score of new data, and retrain the model with new data and old data.
An important finding is that recalculating pseudo tags with a better set does not significantly improve scores. Aggregating more data is always more important than improving the quality of pseudo tags.
08
infrastructure
We combine Kaggle infrastructure (kernel, data storage) and Google drive with Google colab.
We are more flexible because we can train on multiple instances, and each account can access up to 3 GPU s on Colab. A well structured workspace helps to organize and track experiments. By using the Kaggle api, you can easily push data from Colab to Kaggle and return it. We also use a relaxed channel to discuss our ideas and track our experiments.
09
Incredible teammates
My teammate Eugene shared his notebook with the community, wrote custom headers and created training programs. His method is widely used, and he also released his truly effective Roberta large training notebook. Congratulations on his first gold medal in the first competition.
10
conclusion
HuggingFace is an excellent platform for various NLP tasks and provides a large number of pre training models.
However, in this game, it becomes very clear how to further adjust the model to obtain better results. If there is no pre trained model, the result will be worse, and there is still the potential for optimization.
Kaggle participants said that there was room for improvement in all areas, from model architecture to optimizer to training program. These methods can also be transferred to other tasks. I hope CommonLit can use these results to make it easier for teachers to provide students with correct texts in the future.
The purpose of this paper is to exchange academic opinions, which does not mean that the official account is in favor of its views or is responsible for the authenticity of its contents. Copyright is owned by the original author. If there is any infringement, please inform the deletion.