Mybatis plus is a mybatis enhancement tool to simplify development and improve efficiency. The following uses the abbreviation mp to simplify the representation of mybatis plus. This article mainly introduces the use of mp with SpringBoot.
Note: the mp version used in this article is the latest version 3.4.2. Please refer to the documentation for the differences between earlier versions
Official website: baomidou.com/
quick get start
-
Create a SpringBoot project
-
Import dependency
<!-- pom.xml --> <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.4.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>mybatis-plus</artifactId> <version>0.0.1-SNAPSHOT</version> <name>mybatis-plus</name> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project> Copy code -
Configuration database
# application.yml spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai username: root password: root mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #Enable SQL statement printing Copy code -
Create an entity class
package com.example.mp.po; import lombok.Data; import java.time.LocalDateTime; @Data public class User { private Long id; private String name; private Integer age; private String email; private Long managerId; private LocalDateTime createTime; } Copy code -
Create a mapper interface
package com.example.mp.mappers; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.example.mp.po.User; public interface UserMapper extends BaseMapper<User> { } Copy code -
Configure the scan path of the mapper interface on the SpringBoot boot class
package com.example.mp; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication @MapperScan("com.example.mp.mappers") public class MybatisPlusApplication { public static void main(String[] args) { SpringApplication.run(MybatisPlusApplication.class, args); } } Copy code -
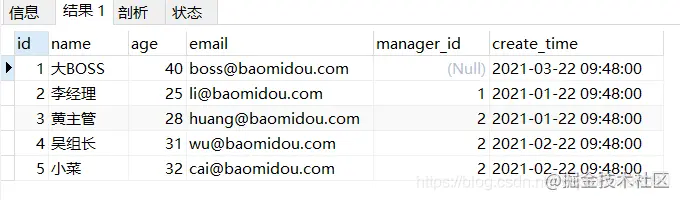
Create a table in the database
DROP TABLE IF EXISTS user; CREATE TABLE user ( id BIGINT(20) PRIMARY KEY NOT NULL COMMENT 'Primary key', name VARCHAR(30) DEFAULT NULL COMMENT 'full name', age INT(11) DEFAULT NULL COMMENT 'Age', email VARCHAR(50) DEFAULT NULL COMMENT 'mailbox', manager_id BIGINT(20) DEFAULT NULL COMMENT 'Direct superior id', create_time DATETIME DEFAULT NULL COMMENT 'Creation time', CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user (id) ) ENGINE=INNODB CHARSET=UTF8; INSERT INTO user (id, name, age ,email, manager_id, create_time) VALUES (1, 'large BOSS', 40, 'boss@baomidou.com', NULL, '2021-03-22 09:48:00'), (2, 'Manager Li', 40, 'boss@baomidou.com', 1, '2021-01-22 09:48:00'), (3, 'Supervisor Huang', 40, 'boss@baomidou.com', 2, '2021-01-22 09:48:00'), (4, 'Group leader Wu', 40, 'boss@baomidou.com', 2, '2021-02-22 09:48:00'), (5, 'side dish', 40, 'boss@baomidou.com', 2, '2021-02-22 09:48:00') Copy code
-
Write a SpringBoot test class
package com.example.mp; import com.example.mp.mappers.UserMapper; import com.example.mp.po.User; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.util.List; import static org.junit.Assert.*; @RunWith(SpringRunner.class) @SpringBootTest public class SampleTest { @Autowired private UserMapper mapper; @Test public void testSelect() { List<User> list = mapper.selectList(null); assertEquals(5, list.size()); list.forEach(System.out::println); } } Copy code
Preparation completed
The database is as follows
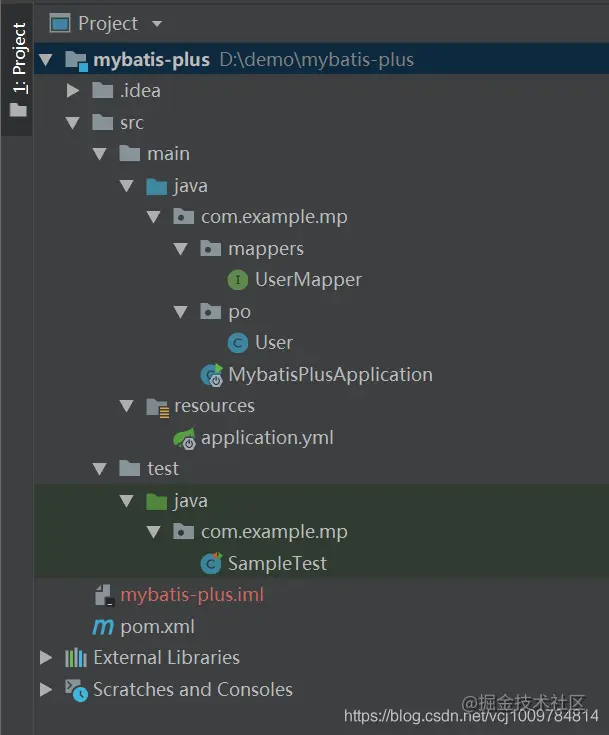
The project directory is as follows
Run test class
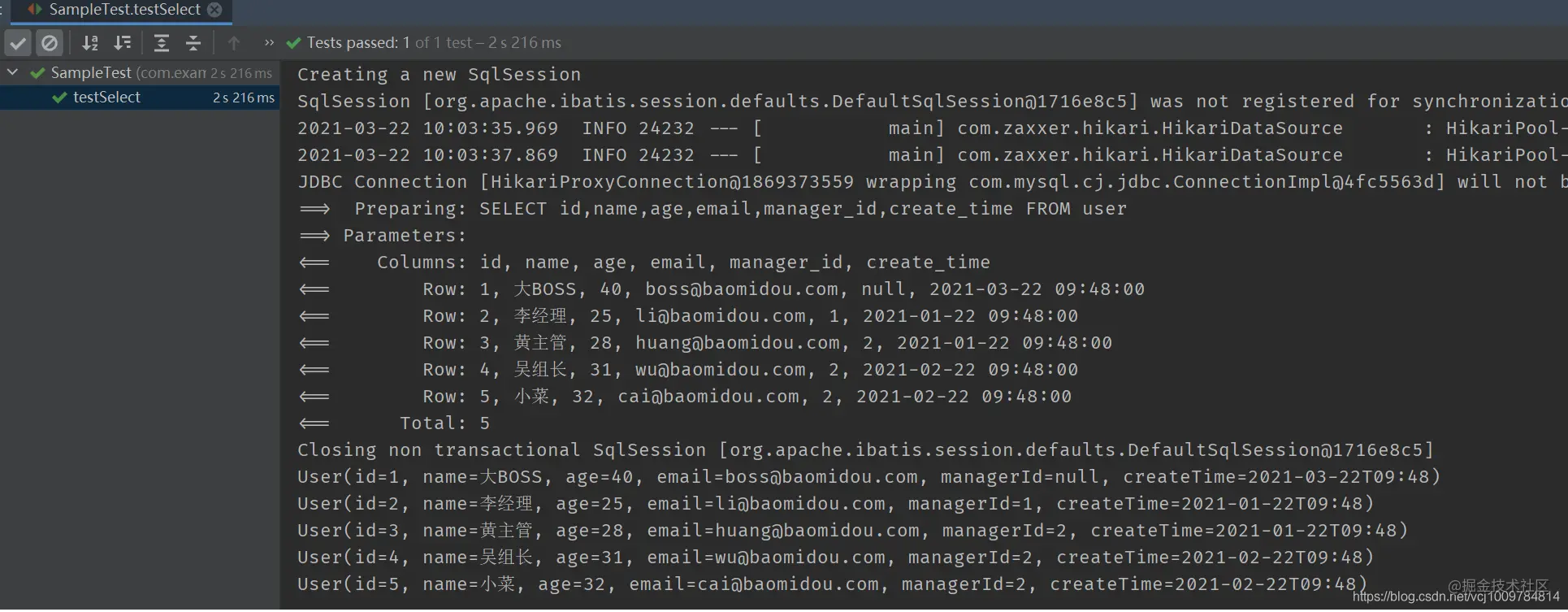
You can see that for the basic CRUD operation of a single table, you only need to create an entity class and an interface inherited from BaseMapper. It is very concise. Also, we notice that the managerId and createTime attributes in the User class are automatically associated with the manager in the database table_ id,create_time corresponds to time, because mp automatically converts the database underline naming to the hump naming of Java classes.
Core functions
annotation
mp provides a total of 8 annotations, which are used on Java entity classes.
-
@TableName
Annotation specifies the mapping relationship between the class and the database table on the class. If the class name (converted to lowercase) of the entity class is the same as the database table name, the annotation may not be specified.
-
@TableId
The annotation is on a field of the entity class, indicating that this field corresponds to the primary key of the database table. When the primary key name is id (the column name in the table is id and the field name in the entity class is id), there is no need to explicitly specify the primary key using this annotation, and mp will be automatically associated. If field name of the class is inconsistent with the column name of the table, column name of the table can be specified with the value attribute. In addition, this annotation has an important attribute type, which is used to specify the primary key policy. See Primary key policy section
-
@TableField
Annotation specifies the mapping relationship between the fields of the Java entity class and the columns of the database table on a field. This annotation has the following application scenarios.
-
Exclude non table fields
If a field in the Java entity class does not correspond to any column in the table, but is only used to save some additional or assembled data, you can set the exist property to false, so that this field will be ignored when inserting the entity object. Excluding non table fields can also be done in other ways, such as using static or transient keywords, but I don't think it is very reasonable, so I won't repeat it
-
Field validation policy
By configuring the insertStrategy, updatestategy and whereStrategy attributes, you can control how the fields in the object are assembled into the SQL statement when the entity object is inserted, updated or used as a WHERE condition. See Configuration section
-
Field fill policy
Specified by the fill attribute, the field will be automatically filled when it is empty
-
-
@Version
Note on optimistic lock, see Optimistic lock section
-
@EnumValue
Annotation on enumeration field
-
@TableLogic
Logical deletion, see Logical deletion section
-
KeySequence
Sequence primary key policy (oracle)
-
InterceptorIgnore
Plug in filtering rules
CRUD interface
mp encapsulates some of the most basic CRUD methods. You only need to directly inherit the interface provided by mp without writing any SQL. mp provides two sets of interfaces, Mapper CRUD interface and Service CRUD interface. In addition, mp also provides a condition constructor Wrapper, which can easily assemble WHERE conditions in SQL statements. See Conditional constructor section
Mapper CRUD interface
Just define the entity class, then create an interface and inherit the BaseMapper provided by mp. mp will automatically resolve the mapping relationship between entity classes and tables when mybatis starts, and inject mapper with general CRUD methods. Some of the methods provided in BaseMapper are listed as follows:
- insert(T entity) inserts a record
- deleteById(Serializable id) deletes a record according to the primary key id
- Delete (wrapper < T > wrapper) deletes according to the conditional constructor wrapper
- selectById(Serializable id) searches based on the primary key id
- selectBatchIds(Collection idList) performs Batch Search Based on the primary key id
- Selectbymap (map < string, Object > map) performs equivalent matching search according to the column name and column value specified in the map
- Selectmaps (wrapper < T > wrapper) queries the records according to the wrapper conditions, encapsulates the query results into a Map, the key of the Map is the column of the result, and the value is the value
- Selectlist (wrapper < T > wrapper) queries according to the condition constructor wrapper
- Update (t entity, wrapper < T > wrapper) updates according to the conditional constructor wrapper
- updateById(T entity)
- ...
A simple example of eating is shown above Quick start section , here are some special methods
selectMaps
The BaseMapper interface also provides a selectMaps method, which encapsulates the query results into a Map. The key of the Map is the column of the result and the value is the value
The usage scenarios of this method are as follows:
-
Query only partial columns
When there are many columns in a table, and only individual columns need to be selected during SELECT, and the query results do not need to be encapsulated into Java entity class objects (when only some columns are queried, many attributes in the entity object will be null after being encapsulated into entities), you can use selectMaps to obtain the specified columns and process them by yourself
such as
@Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.select("id","name","email").likeRight("name","yellow"); List<Map<String, Object>> maps = userMapper.selectMaps(wrapper); maps.forEach(System.out::println); } Copy code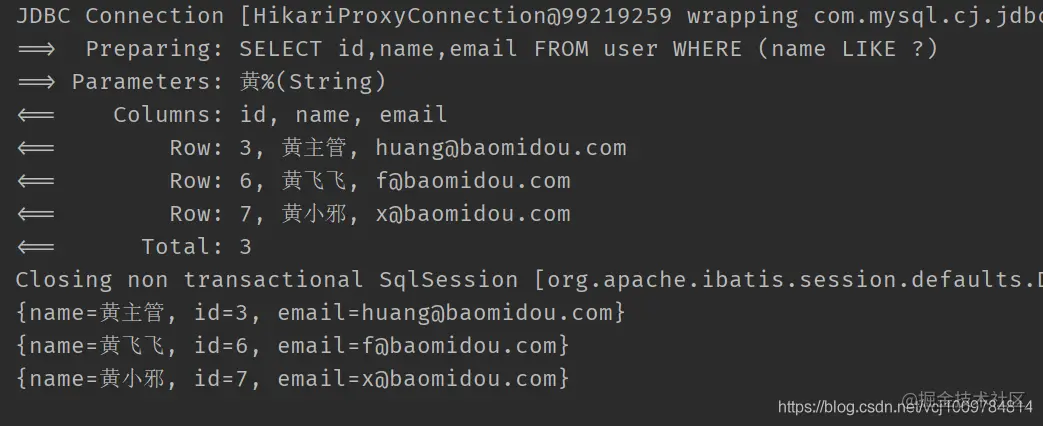
-
Conduct data statistics
such as
// Group according to the immediate superior, and query the average age, maximum age and minimum age of each group /** select avg(age) avg_age ,min(age) min_age, max(age) max_age from user group by manager_id having sum(age) < 500; **/ @Test public void test3() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.select("manager_id", "avg(age) avg_age", "min(age) min_age", "max(age) max_age") .groupBy("manager_id").having("sum(age) < {0}", 500); List<Map<String, Object>> maps = userMapper.selectMaps(wrapper); maps.forEach(System.out::println); } Copy code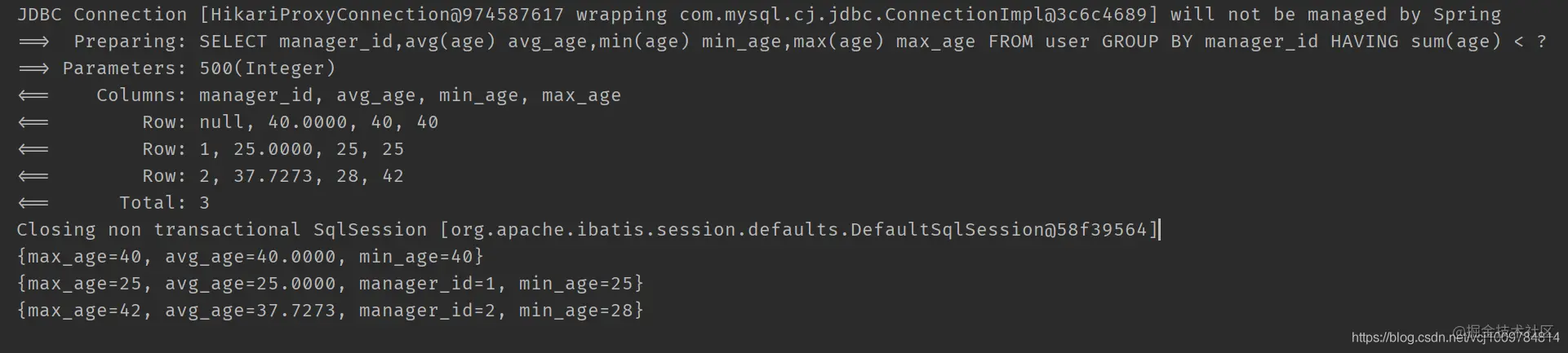
selectObjs
Only the value of the first field (first column) will be returned, and other fields will be discarded
such as
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.select("id", "name").like("name", "yellow");
List<Object> objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}
Copy codeThe result obtained encapsulates only the id of the first column
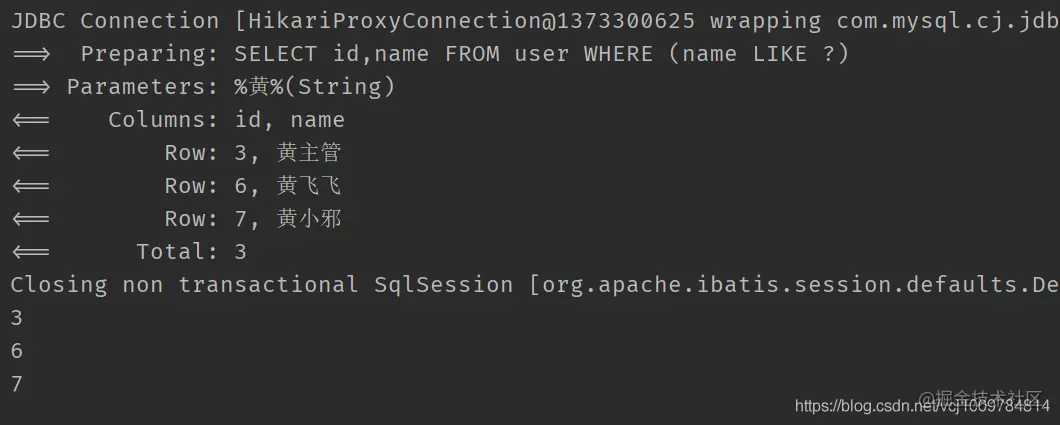
selectCount
The total number of conditions satisfied by the query. Note that using this method, you cannot call the select method of QueryWrapper to set the columns to be queried. This method will automatically add select count(1)
such as
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like("name", "yellow");
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
}
Copy code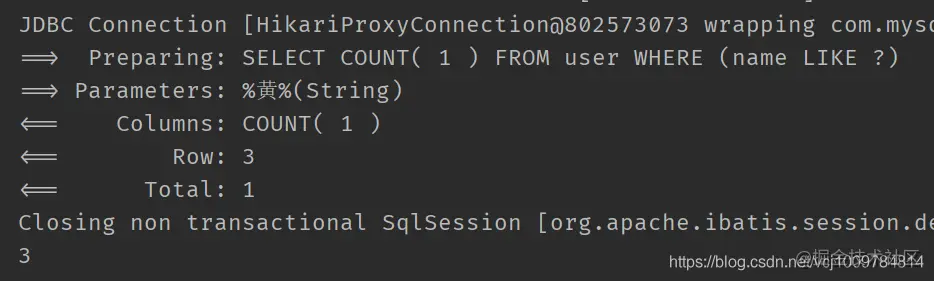
Service CRUD interface
Another set of CRUD is the Service layer. You only need to write an interface, inherit IService, and create an interface implementation class. (the CRUD method provided by this interface is similar to the function provided by Mapper interface. The obvious difference is that IService supports more batch operations, such as saveBatch, saveOrUpdateBatch and other methods.
Examples of consumption are as follows
-
First, create a new interface and inherit IService
package com.example.mp.service; import com.baomidou.mybatisplus.extension.service.IService; import com.example.mp.po.User; public interface UserService extends IService<User> { } Copy code -
Create the implementation class of this interface, inherit ServiceImpl, mark @ Service annotation, and register in the Spring container
package com.example.mp.service.impl; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.example.mp.mappers.UserMapper; import com.example.mp.po.User; import com.example.mp.service.UserService; import org.springframework.stereotype.Service; @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { } Copy code -
Test code
package com.example.mp; import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper; import com.baomidou.mybatisplus.core.toolkit.Wrappers; import com.example.mp.po.User; import com.example.mp.service.UserService; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @SpringBootTest public class ServiceTest { @Autowired private UserService userService; @Test public void testGetOne() { LambdaQueryWrapper<User> wrapper = Wrappers.<User>lambdaQuery(); wrapper.gt(User::getAge, 28); User one = userService.getOne(wrapper, false); // The second parameter is specified as false, so that when multiple rows of records are found, the first record is returned without throwing an exception System.out.println(one); } } Copy code -
result
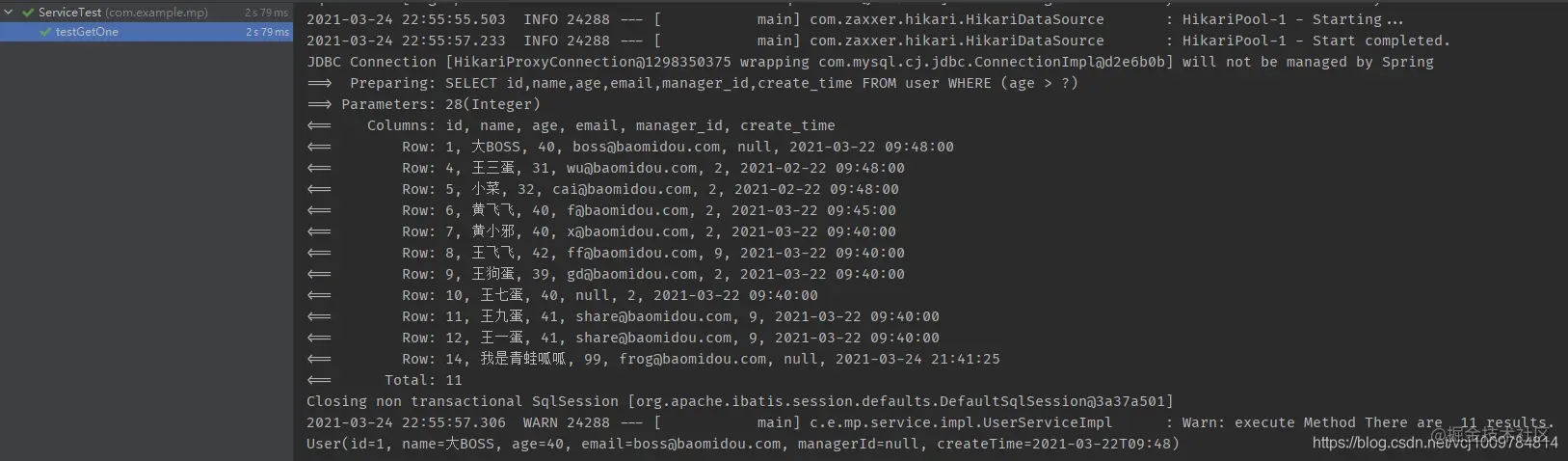
In addition, IService also supports chain calls. The code is very concise. The query example is as follows
@Test
public void testChain() {
List<User> list = userService.lambdaQuery()
.gt(User::getAge, 39)
.likeRight(User::getName, "king")
.list();
list.forEach(System.out::println);
}
Copy code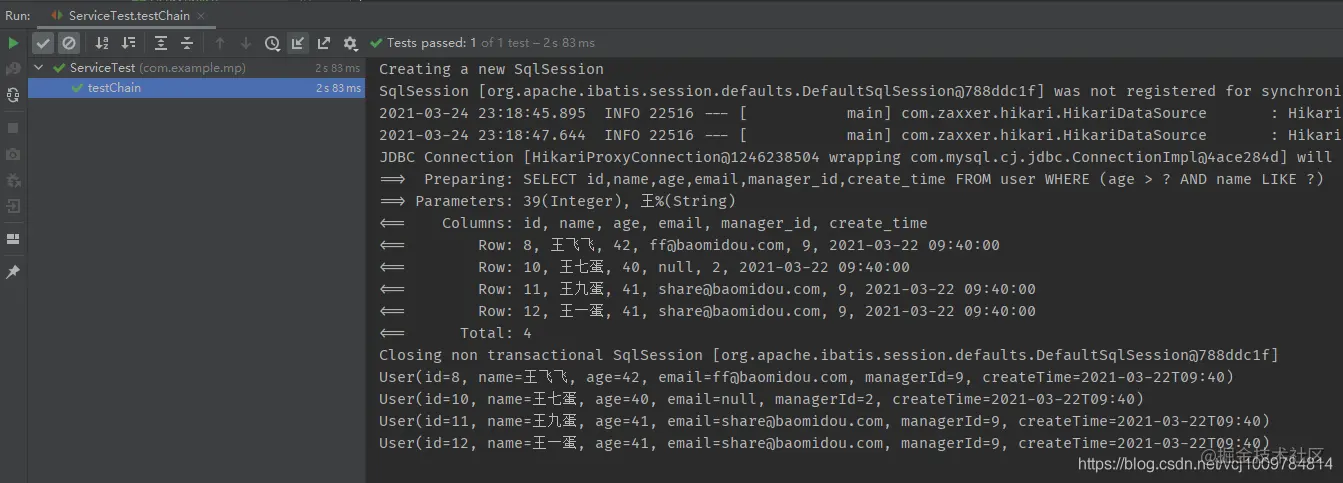
Examples of updates are as follows
@Test
public void testChain() {
userService.lambdaUpdate()
.gt(User::getAge, 39)
.likeRight(User::getName, "king")
.set(User::getEmail, "w39@baomidou.com")
.update();
}
Copy code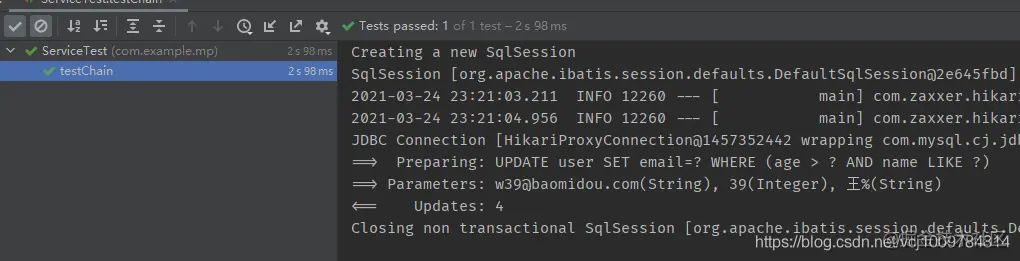
Examples of deletion are as follows
@Test
public void testChain() {
userService.lambdaUpdate()
.like(User::getName, "frog")
.remove();
}
Copy code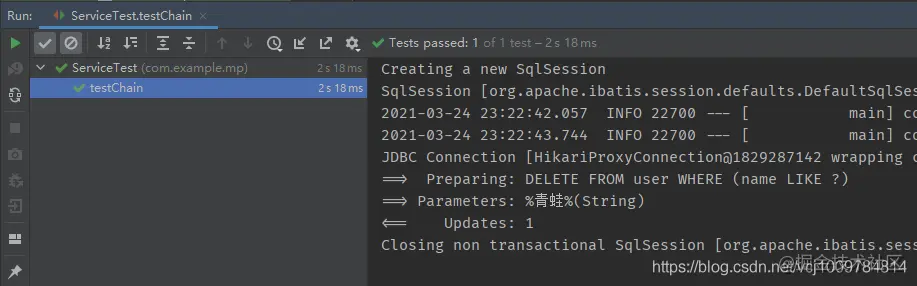
Conditional constructor
mp makes me feel extremely convenient because it provides a powerful condition constructor Wrapper, which can easily construct WHERE conditions. The conditional constructor mainly involves three classes, AbstractWrapper. QueryWrapper and UpdateWrapper have the following class relationships
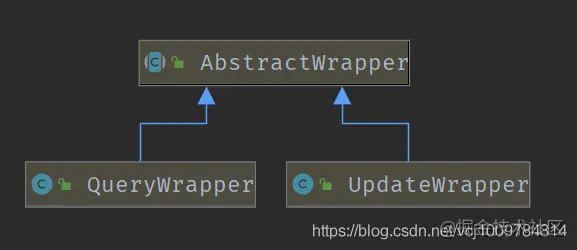
AbstractWrapper provides many methods for constructing WHERE conditions. QueryWrapper provides a select() method for SELECT statements to customize the columns to be queried. UpdateWrapper provides a set() method for UPDATE statements to construct set statements. The conditional constructor also supports lambda expressions, which is very comfortable to write.
The following is a partial enumeration of the methods used to build WHERE conditions in SQL statements in AbstractWrapper
- eq: equals, equal to
- allEq: all equals
- ne: not equals, not equal to
- gt: greater than, greater than >
- ge: greater than or equals, greater than or equal to ≥
- lt: less than<
- le: less than or equal, less than or equal to ≤
- Between: equivalent to between in SQL
- notBetween
- Like: fuzzy matching. like("name", "yellow"), equivalent to SQL's name like '% yellow%'
- Likereight: blur matches the right half. Likereight ("name", "yellow"), which is equivalent to SQL's name like 'yellow%'
- likeLeft: blur matches the left half. likeLeft("name", "yellow"), equivalent to SQL's name like '% yellow'
- notLike: notLike("name", "yellow"), equivalent to SQL's name not like '% yellow%'
- isNull
- isNotNull
- in
- And: SQL connector and
- Or: SQL connector or
- apply: used to splice SQL. This method can be used for database functions and can dynamically transfer parameters
- .......
Use example
Let's practice the use of conditional constructors through some specific cases. (use the user table created earlier)
// The case first shows the SQL statement to be completed, and then shows the writing method of Wrapper
// 1. The name contains Jia, and the age is less than 25
// SELECT * FROM user WHERE name like '%' and age < 25
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like("name", "good").lt("age", 25);
List<User> users = userMapper.selectList(wrapper);
// When SQL is displayed below, only the WHERE condition is displayed; When presenting code, only the Wrapper build part is presented
// 2. The name is surnamed Huang, the age is greater than or equal to 20, less than or equal to 40, and the email field is not empty
// name like 'yellow%' AND age BETWEEN 20 AND 40 AND email is not null
wrapper.likeRight("name","yellow").between("age", 20, 40).isNotNull("email");
// 3. If the name is Huang surname, or if the age is greater than or equal to 40, it shall be arranged in descending order of age, and if the age is the same, it shall be arranged in ascending order of id
// name like 'yellow%' or age > = 40 order by age DESC, ID ASC
wrapper.likeRight("name","yellow").or().ge("age",40).orderByDesc("age").orderByAsc("id");
// 4. The creation date is March 22, 2021, and the name of the immediate superior is surnamed Li
// date_format(create_time,'%Y-%m-%d') = '2021-03-22' AND manager_id IN (SELECT id FROM user WHERE name like 'Li%')
wrapper.apply("date_format(create_time, '%Y-%m-%d') = {0}", "2021-03-22") // It is recommended to use {index} to dynamically transfer parameters to prevent SQL injection
.inSql("manager_id", "SELECT id FROM user WHERE name like 'Lee%'");
// For the above apply, you can also directly use the following method for string splicing, but when the date is an external parameter, this method has the risk of SQL injection
wrapper.apply("date_format(create_time, '%Y-%m-%d') = '2021-03-22'");
// 5. The first name is Wang, and (the age is less than 40, or the email address is not empty)
// name like 'Wang%' and (age < 40 or email is not null)
wrapper.likeRight("name", "king").and(q -> q.lt("age", 40).or().isNotNull("email"));
// 6. The first name is Wang, or (the age is less than 40 and older than 20, and the email is not empty)
// name like 'Wang%' or (age < 40 and age > 20 and email is not null)
wrapper.likeRight("name", "king").or(
q -> q.lt("age",40)
.gt("age",20)
.isNotNull("email")
);
// 7. (the age is less than 40 or the email address is not empty) and the first name is Wang
// (age < 40 or email is not null) and name like 'Wang%'
wrapper.nested(q -> q.lt("age", 40).or().isNotNull("email"))
.likeRight("name", "king");
// 8. Age: 30, 31, 34, 35
// age IN (30,31,34,35)
wrapper.in("age", Arrays.asList(30,31,34,35));
// or
wrapper.inSql("age","30,31,34,35");
// 9. If the age is 30, 31, 34, 35, return the first record that meets the conditions
// age IN (30,31,34,35) LIMIT 1
wrapper.in("age", Arrays.asList(30,31,34,35)).last("LIMIT 1");
// 10. Select only the ID and name columns (unique to QueryWrapper)
// SELECT id, name FROM user;
wrapper.select("id", "name");
// 11. Selecting ID, name, age and email is equivalent to excluding manager_id and create_time
// When there are too many columns and only individual columns need to be excluded, many columns may need to be written in the above method. You can use the overloaded select method to specify the columns to be excluded
wrapper.select(User.class, info -> {
String columnName = info.getColumn();
return !"create_time".equals(columnName) && !"manager_id".equals(columnName);
});
Copy codeCondition
In many methods of the condition constructor, you can specify a boolean parameter condition to determine whether the condition is added to the last generated WHERE statement, such as
String name = "yellow"; // Suppose the name variable is an externally passed in parameter
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like(StringUtils.hasText(name), "name", name);
// This like statement will be spliced into WHERE only when StringUtils.hasText(name) is true
// In fact, it is a simplification of the following code
if (StringUtils.hasText(name)) {
wrapper.like("name", name);
}
Copy codeEntity object as condition
When you call the constructor to create a Wrapper object, you can pass in an entity object. When this Wrapper is used later, the WHERE condition will be constructed based on the non empty attribute in the entity object (the equivalent matching WHERE condition will be constructed by default. This behavior can be changed through the condition attribute in the @ TableField annotation on each field in the entity class)
Examples are as follows
@Test
public void test3() {
User user = new User();
user.setName("Supervisor Huang");
user.setAge(28);
QueryWrapper<User> wrapper = new QueryWrapper<>(user);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy codeThe results are as follows. It can be seen that the equivalent matching query is performed according to the non empty attributes in the entity object.

If you want to change the behavior of equivalence matching for some attributes, you can configure it in the entity class with the @ TableField annotation, as shown in the following example
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE) // Configure this field to use like for splicing
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
Copy codeRun the following test code
@Test
public void test3() {
User user = new User();
user.setName("yellow");
QueryWrapper<User> wrapper = new QueryWrapper<>(user);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy codeFrom the results obtained in the following figure, like is used to splice the name field in the entity object

@The condition property configured in TableField is actually a string. Some strings are predefined in the SqlCondition class for selection
package com.baomidou.mybatisplus.annotation;
public class SqlCondition {
//In the following string,% s is a placeholder, the first% s is the column name, and the second% s is the value of the column
public static final String EQUAL = "%s=#{%s}";
public static final String NOT_EQUAL = "%s<>#{%s}";
public static final String LIKE = "%s LIKE CONCAT('%%',#{%s},'%%')";
public static final String LIKE_LEFT = "%s LIKE CONCAT('%%',#{%s})";
public static final String LIKE_RIGHT = "%s LIKE CONCAT(#{%s},'%%')";
}
Copy codeThe configurations provided in SqlCondition are relatively limited. When we need splicing methods such as < or >, we need to define them ourselves. such as
package com.example.mp.po;
import com.baomidou.mybatisplus.annotation.SqlCondition;
import com.baomidou.mybatisplus.annotation.TableField;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User {
private Long id;
@TableField(condition = SqlCondition.LIKE)
private String name;
@TableField(condition = "%s > #{% s} ") / / this is equivalent to greater than, where & gt; is a character entity
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
}
Copy codeThe tests are as follows
@Test
public void test3() {
User user = new User();
user.setName("yellow");
user.setAge(30);
QueryWrapper<User> wrapper = new QueryWrapper<>(user);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy codeFrom the results obtained in the figure below, we can see that the name attribute is spliced with like, while the age attribute is spliced with >

allEq method
The allEq method passes in a map for equivalence matching
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
Map<String, Object> param = new HashMap<>();
param.put("age", 40);
param.put("name", "Fei Fei Huang");
wrapper.allEq(param);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy code
When there is an element with null value in the Map passed in by the allEq method, it will be set to is null by default
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
Map<String, Object> param = new HashMap<>();
param.put("age", 40);
param.put("name", null);
wrapper.allEq(param);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy code
If you want to ignore the element with null value in the map, you can set the parameter boolean null2IsNull to false when calling allEq
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
Map<String, Object> param = new HashMap<>();
param.put("age", 40);
param.put("name", null);
wrapper.allEq(param, false);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy code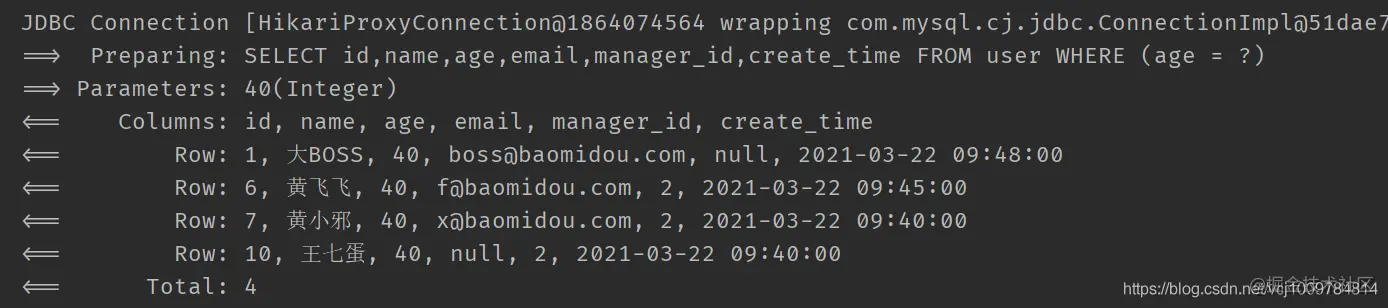
If you want to filter out some elements in the Map when allEq is executed, you can call allEq's overloaded method allEq (bipredicate < R, V > filter, Map < R, V > params)
@Test
public void test3() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
Map<String, Object> param = new HashMap<>();
param.put("age", 40);
param.put("name", "Fei Fei Huang");
wrapper.allEq((k,v) -> !"name".equals(k), param); // Filter out the elements whose key is name in the map
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy code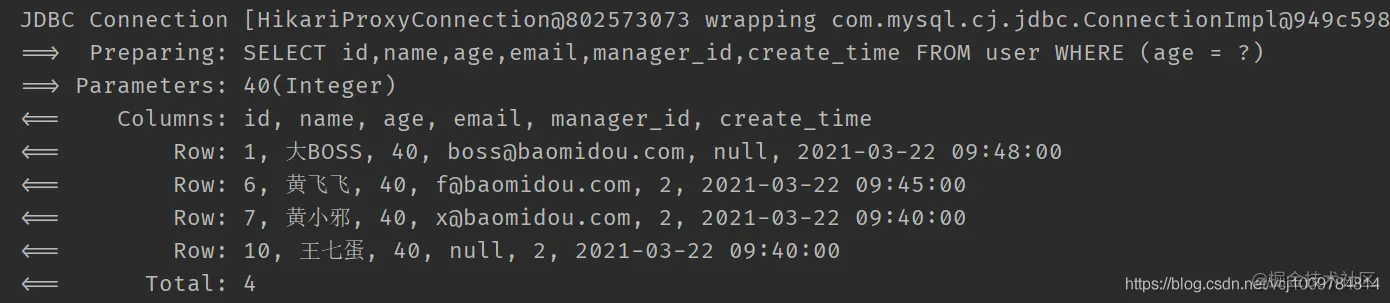
lambda conditional constructor
The lambda conditional constructor supports lambda expressions. It is not necessary to specify column names in the form of strings like ordinary conditional constructors. It can directly specify columns with method references of entity classes. Examples are as follows
@Test
public void testLambda() {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.like(User::getName, "yellow").lt(User::getAge, 30);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
Copy code
Like an ordinary conditional constructor, the column name is specified in the form of a string. The validity of the column name cannot be checked at compile time, which is not as elegant as the lambda conditional constructor.
In addition, there is a chained lambda conditional constructor. The use example is as follows
@Test
public void testLambda() {
LambdaQueryChainWrapper<User> chainWrapper = new LambdaQueryChainWrapper<>(userMapper);
List<User> users = chainWrapper.like(User::getName, "yellow").gt(User::getAge, 30).list();
users.forEach(System.out::println);
}
Copy code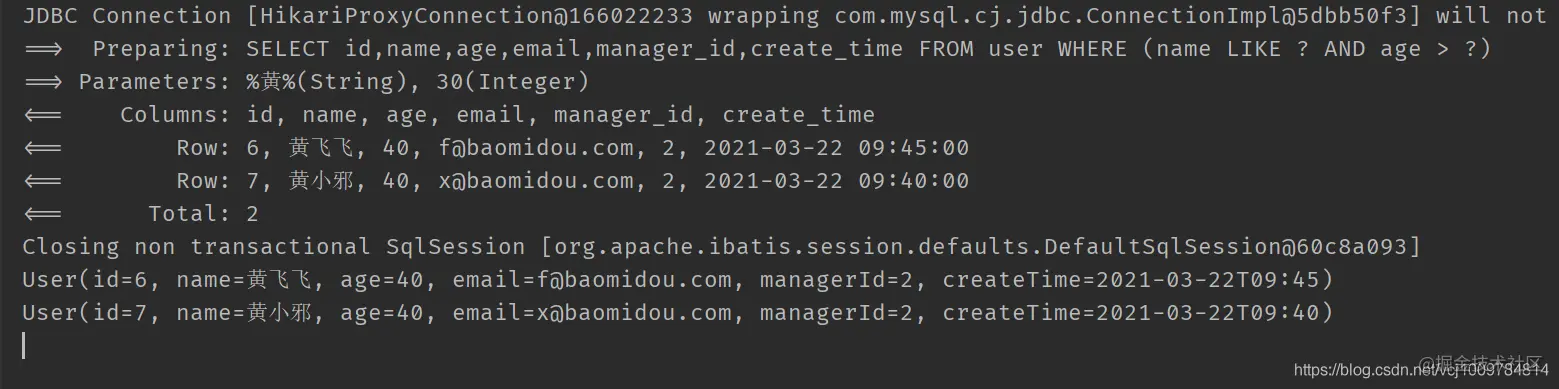
update operation
The above descriptions are all query operations. Now let's talk about update and delete operations.
Two update methods are provided in BaseMapper
-
updateById(T entity)
UPDATE according to the id (primary key) of the input parameter entity. Non empty attributes in entity will appear after SET in the UPDATE statement, that is, non empty attributes in entity will be updated to the database, as shown in the following example
@RunWith(SpringRunner.class) @SpringBootTest public class UpdateTest { @Autowired private UserMapper userMapper; @Test public void testUpdate() { User user = new User(); user.setId(2L); user.setAge(18); userMapper.updateById(user); } } Copy code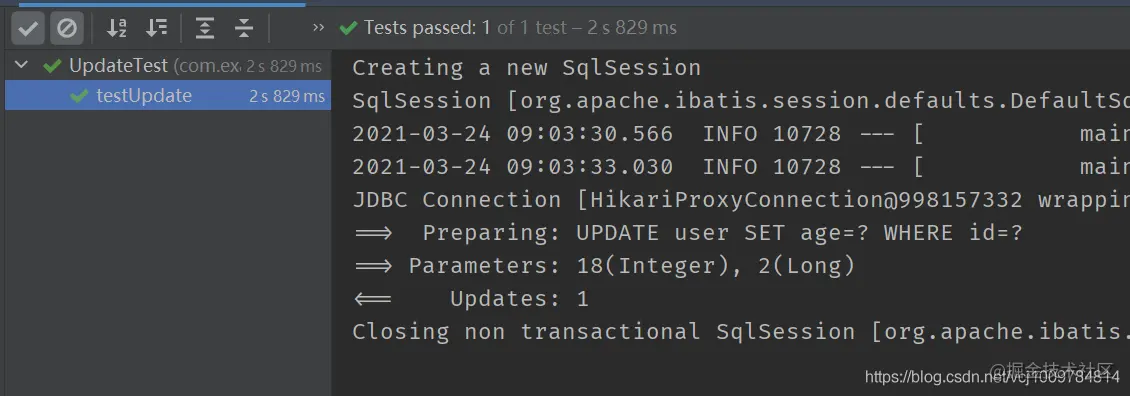
-
update(T entity, Wrapper<T> wrapper)
Update according to entity entity and condition constructor wrapper, as shown in the following example
@Test public void testUpdate2() { User user = new User(); user.setName("Son of a bitch"); LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>(); wrapper.between(User::getAge, 26,31).likeRight(User::getName,"Wu"); userMapper.update(user, wrapper); } Copy code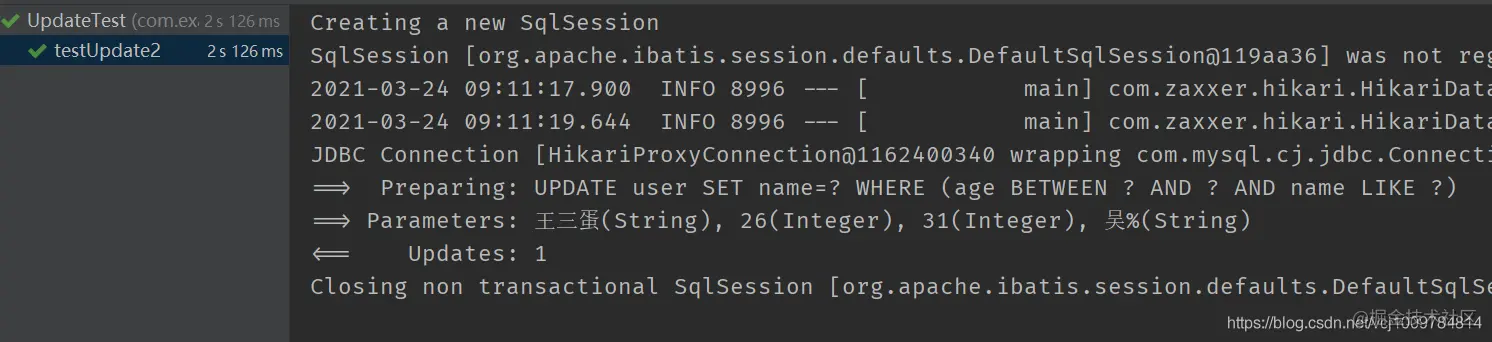
For an additional demonstration, pass the entity object into the Wrapper, that is, use the entity object to construct the WHERE condition
@Test public void testUpdate3() { User whereUser = new User(); whereUser.setAge(40); whereUser.setName("king"); LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>(whereUser); User user = new User(); user.setEmail("share@baomidou.com"); user.setManagerId(10L); userMapper.update(user, wrapper); } Copy codeNote that in our User class, the name attribute and age attribute are set as follows
@Data public class User { private Long id; @TableField(condition = SqlCondition.LIKE) private String name; @TableField(condition = "%s > #{%s}") private Integer age; private String email; private Long managerId; private LocalDateTime createTime; } Copy coderesults of enforcement
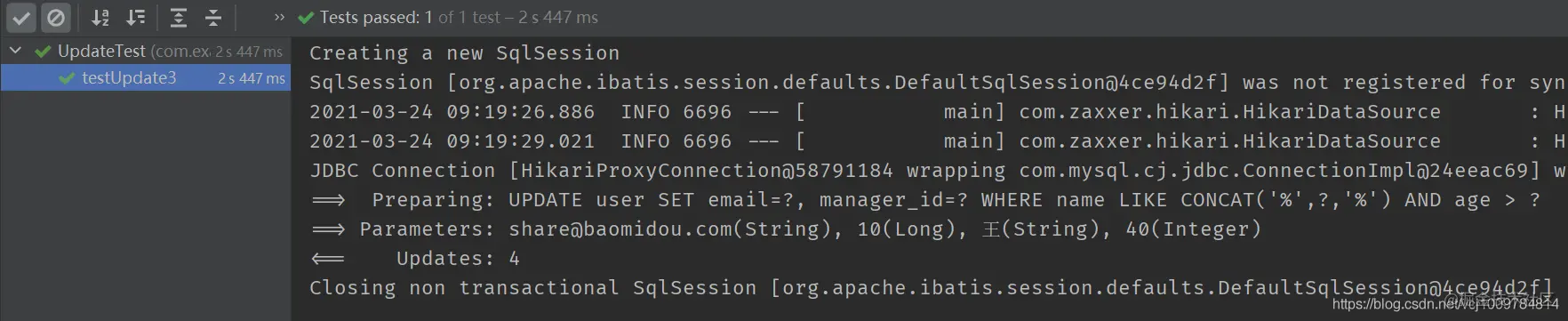
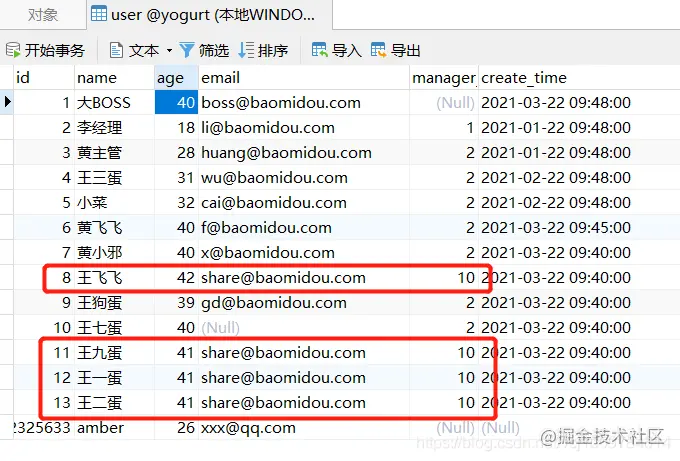
As an additional demonstration, the use of chained lambda conditional constructors
@Test public void testUpdate5() { LambdaUpdateChainWrapper<User> wrapper = new LambdaUpdateChainWrapper<>(userMapper); wrapper.likeRight(User::getEmail, "share") .like(User::getName, "Feifei") .set(User::getEmail, "ff@baomidou.com") .update(); } Copy code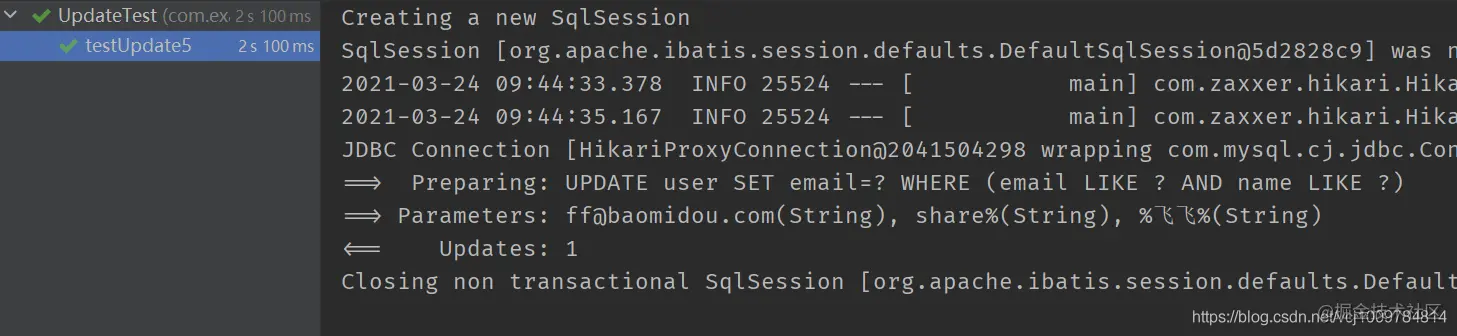
reflect
Because the two update methods provided by BaseMapper pass in an entity object to perform the update, which is good when there are many columns to be updated. If there is only one column or two columns to be updated, it is a little troublesome to create an entity object. In this case, UpdateWrapper provides a set method to manually splice set statements in SQL. At this time, it is not necessary to pass in entity objects. An example is as follows
@Test
public void testUpdate4() {
LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>();
wrapper.likeRight(User::getEmail, "share").set(User::getManagerId, 9L);
userMapper.update(null, wrapper);
}
Copy code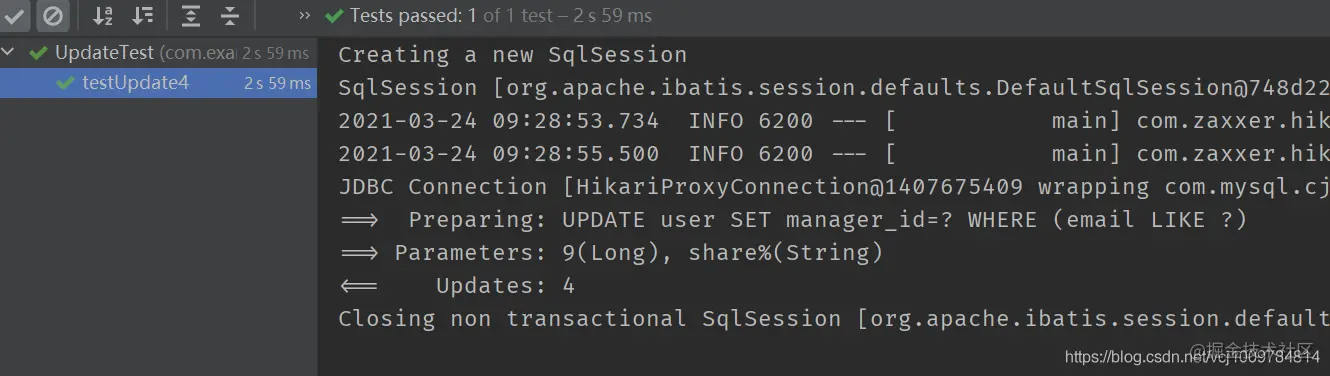
Delete operation
BaseMapper provides the following methods for deletion
- deleteById deletes according to the primary key id
- deleteBatchIds batch deletes according to the primary key id
- deleteByMap deletes according to the Map (key in the Map is the column name, value is the value, and equivalent matching is performed according to the column and value)
- Delete (Wrapper < T > Wrapper) deletes according to the conditional constructor Wrapper
It is similar to the previous query and update operations and will not be repeated
Custom SQL
When the method provided by mp cannot meet the requirements, you can customize SQL.
Native mybatis
Examples are as follows
- Annotation method
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* @Author yogurtzzz
* @Date 2021/3/18 11:21
**/
public interface UserMapper extends BaseMapper<User> {
@Select("select * from user")
List<User> selectRaw();
}
Copy code- xml mode
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mp.mappers.UserMapper">
<select id="selectRaw" resultType="com.example.mp.po.User">
SELECT * FROM user
</select>
</mapper>
Copy codepackage com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper<User> {
List<User> selectRaw();
}
Copy codeWhen using XML, if the XML file is not in the same directory as the mapper interface file, you need to configure the storage path of mapper.xml in application.yml
mybatis-plus: mapper-locations: /mappers/* Copy code
If there are multiple places to store mapper, configure it in the form of array
mybatis-plus: mapper-locations: - /mappers/* - /com/example/mp/* Copy code
The test code is as follows
@Test
public void testCustomRawSql() {
List<User> users = userMapper.selectRaw();
users.forEach(System.out::println);
}
Copy coderesult
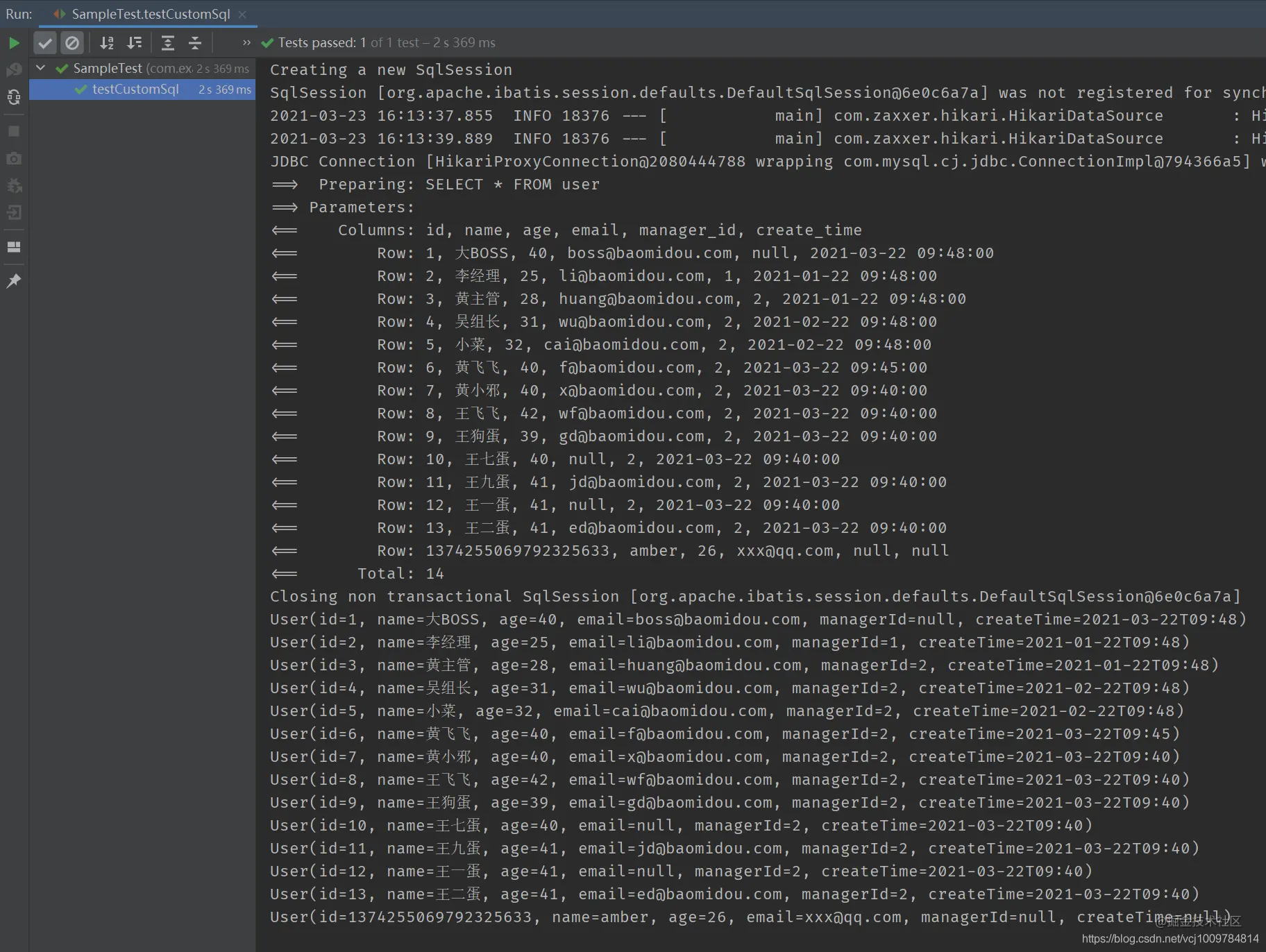
mybatis-plus
You can also use the Wrapper condition constructor provided by mp to customize SQL
Examples are as follows
- Annotation method
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.toolkit.Constants;
import com.example.mp.po.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper<User> {
// WHERE keyword is not written in SQL, and ${ew.customSqlSegment} is fixed
@Select("select * from user ${ew.customSqlSegment}")
List<User> findAll(@Param(Constants.WRAPPER)Wrapper<User> wrapper);
}
Copy code- xml mode
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.conditions.Wrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User;
import java.util.List;
public interface UserMapper extends BaseMapper<User> {
List<User> findAll(Wrapper<User> wrapper);
}
Copy code<!-- UserMapper.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mp.mappers.UserMapper">
<select id="findAll" resultType="com.example.mp.po.User">
SELECT * FROM user ${ew.customSqlSegment}
</select>
</mapper>
Copy codePaging query
BaseMapper provides two methods for paging query, namely selectPage and selectMapsPage. The former encapsulates the query results into Java entity objects, and the latter encapsulates into map < string, Object >. An example of a paging query is as follows
-
Create mp's paging interceptor and register it in the Spring container
package com.example.mp.config; import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MybatisPlusConfig { /** New mp**/ @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); return interceptor; } /** PaginationInterceptor for old mp**/ } Copy code -
Execute paging query
@Test public void testPage() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.ge(User::getAge, 28); // Set paging information and check page 3, with 2 data on each page Page<User> page = new Page<>(3, 2); // Execute paging query Page<User> userPage = userMapper.selectPage(page, wrapper); System.out.println("Total records = " + userPage.getTotal()); System.out.println("PageCount = " + userPage.getPages()); System.out.println("Current page number = " + userPage.getCurrent()); // Get paging query results List<User> records = userPage.getRecords(); records.forEach(System.out::println); } Copy code -
result
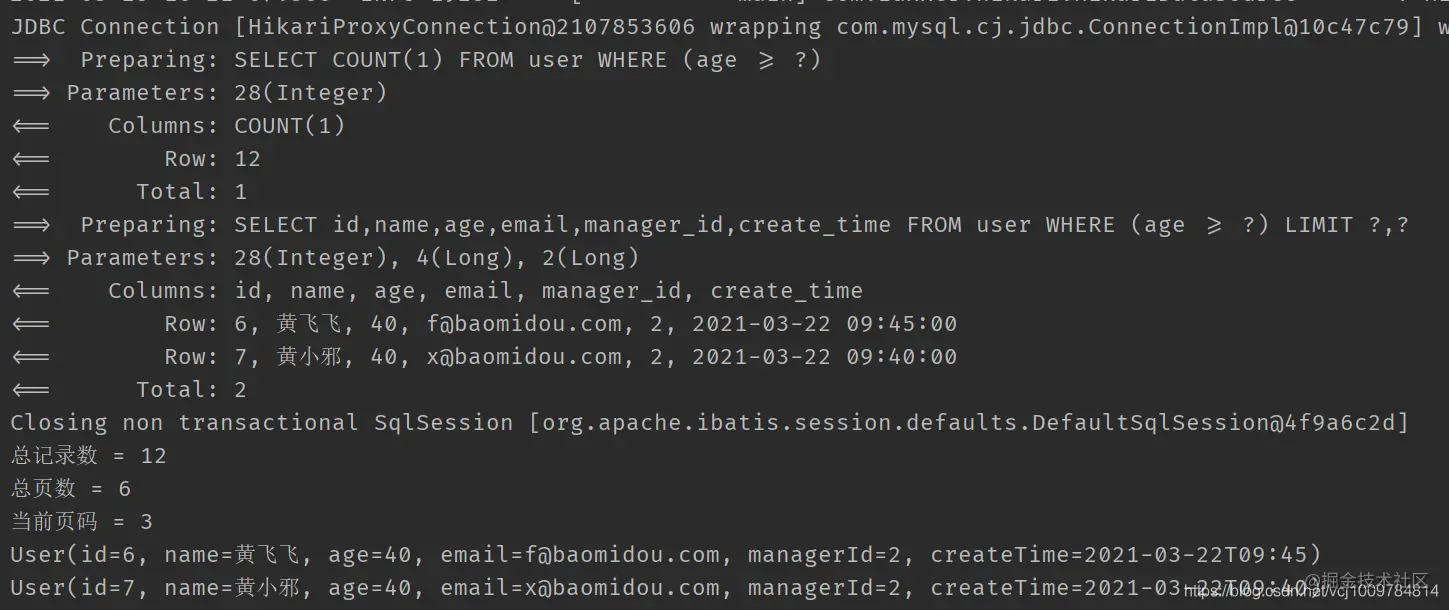
-
other
-
Note that the paging query sends out two SQL queries in total, one for the total number of records and one for the specific data. If you don't want to check the total records, only the paging results. You can specify isSearchCount as false through the overloaded constructor of Page
public Page(long current, long size, boolean isSearchCount) Copy code
-
In the actual development, you may encounter the scenario of multi table associated query. At this time, the method of single table paging query provided in BaseMapper cannot meet the requirements, and you need to customize the SQL. An example is as follows (use the SQL of single table query for demonstration. In the actual multi table associated query, you can modify the SQL statement)
-
Define a function in the mapper interface, receive a Page object as a parameter, and write custom SQL
// Pure annotation is used here. Of course, if SQL is complex, XML is recommended @Select("SELECT * FROM user ${ew.customSqlSegment}") Page<User> selectUserPage(Page<User> page, @Param(Constants.WRAPPER) Wrapper<User> wrapper); Copy code -
Execute query
@Test public void testPage2() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.ge(User::getAge, 28).likeRight(User::getName, "king"); Page<User> page = new Page<>(3,2); Page<User> userPage = userMapper.selectUserPage(page, wrapper); System.out.println("Total records = " + userPage.getTotal()); System.out.println("PageCount = " + userPage.getPages()); userPage.getRecords().forEach(System.out::println); } Copy code -
result
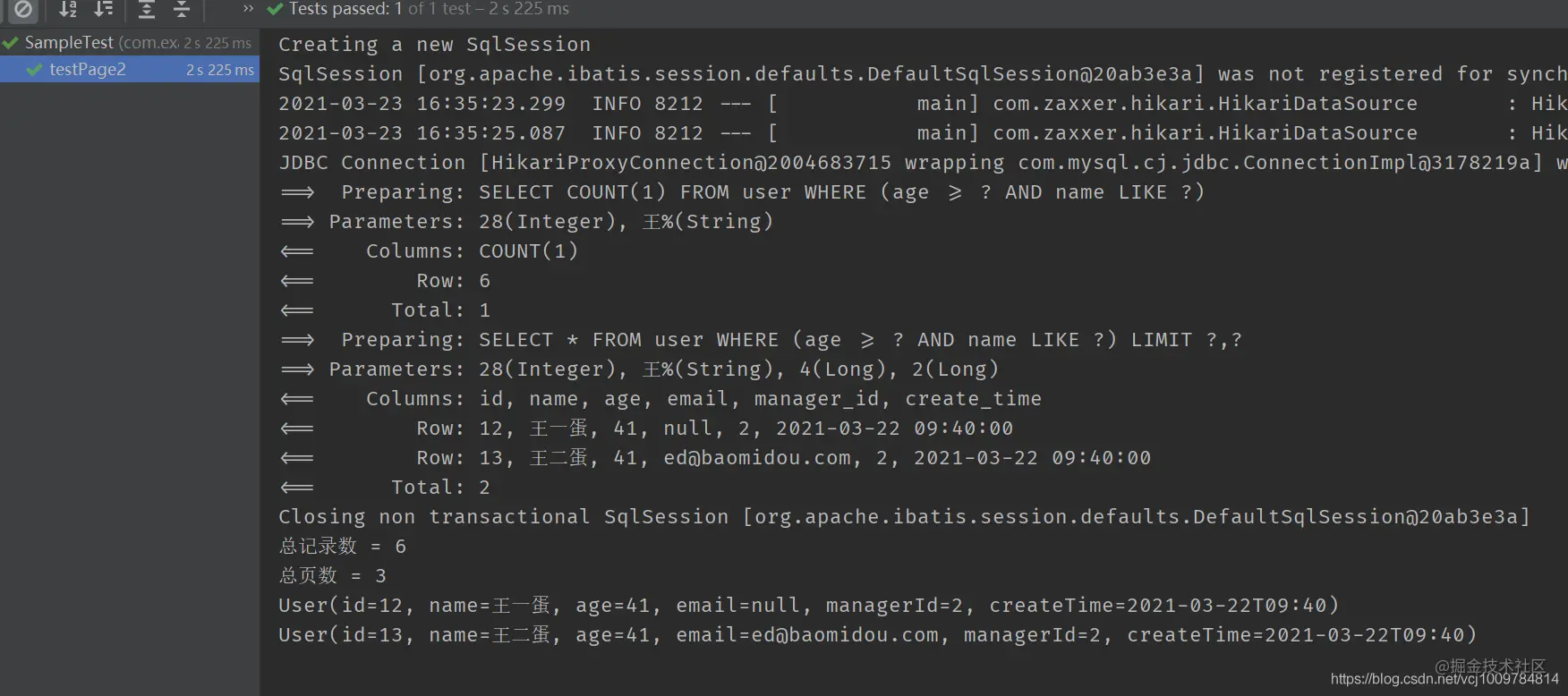
-
-
AR mode
ActiveRecord mode directly operates database tables by operating entity objects. Similar to ORM.
Examples are as follows
-
Let entity class User inherit from Model
package com.example.mp.po; import com.baomidou.mybatisplus.annotation.SqlCondition; import com.baomidou.mybatisplus.annotation.TableField; import com.baomidou.mybatisplus.extension.activerecord.Model; import lombok.Data; import lombok.EqualsAndHashCode; import java.time.LocalDateTime; @EqualsAndHashCode(callSuper = false) @Data public class User extends Model<User> { private Long id; @TableField(condition = SqlCondition.LIKE) private String name; @TableField(condition = "%s > #{%s}") private Integer age; private String email; private Long managerId; private LocalDateTime createTime; } Copy code -
Directly call methods on entity objects
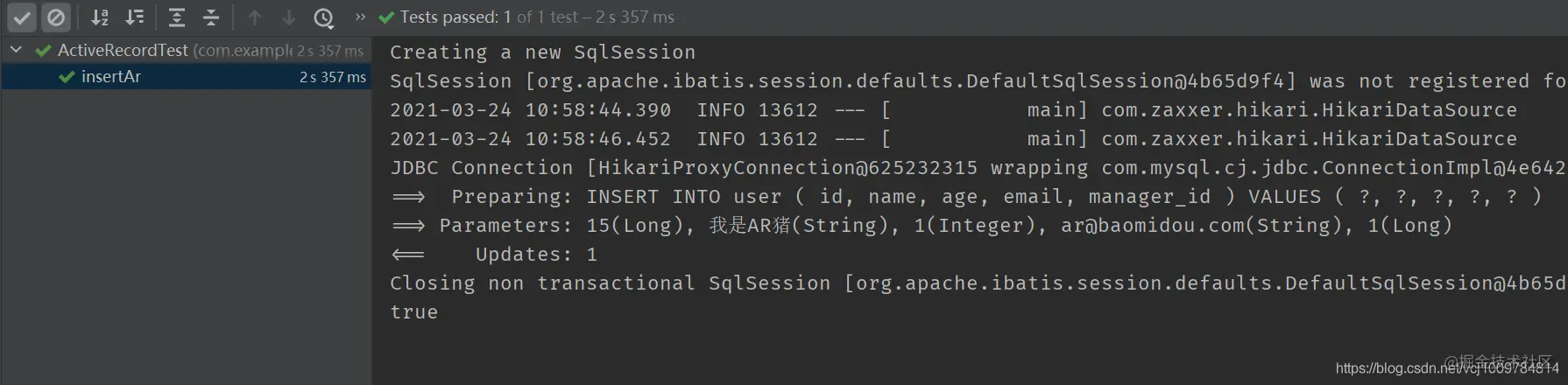
@Test public void insertAr() { User user = new User(); user.setId(15L); user.setName("I am AR pig"); user.setAge(1); user.setEmail("ar@baomidou.com"); user.setManagerId(1L); boolean success = user.insert(); // insert System.out.println(success); } Copy code -
result
Other examples
// query
@Test
public void selectAr() {
User user = new User();
user.setId(15L);
User result = user.selectById();
System.out.println(result);
}
// to update
@Test
public void updateAr() {
User user = new User();
user.setId(15L);
user.setName("Son of a bitch");
user.updateById();
}
//delete
@Test
public void deleteAr() {
User user = new User();
user.setId(15L);
user.deleteById();
}
Copy codePrimary key policy
When defining an entity class, use @ TableId to specify the primary key, and its type attribute to specify the primary key policy.
mp supports multiple primary key policies. The default policy is self incrementing id based on snowflake algorithm. All primary key policies are defined in the enumeration class IdType. IdType has the following values
-
AUTO
The database ID increases automatically and depends on the database. When an insert operation generates an SQL statement, the primary key column is not inserted
-
NONE
The primary key type is not set. If the primary key is not manually set in the code, it will be automatically generated according to the global policy of the primary key (the default global policy of the primary key is the self increment ID based on the snowflake algorithm)
-
INPUT
You need to set the primary key manually, if not. When the insert operation generates an SQL statement, the value of the primary key column will be null. oracle's sequence primary key needs to use this method
-
ASSIGN_ID
When the primary key is not set manually, that is, the primary key attribute in the entity class is empty, it will be filled automatically. The snowflake algorithm is used
-
ASSIGN_UUID
When the primary key attribute of the entity class is empty, it will be filled automatically, and UUID will be used
-
... (there are several out of date, so I won't list them)
For each entity class, the @ TableId annotation can be used to specify the primary key policy of the entity class, which can be understood as a local policy. If you want to use the same primary key policy for all entity classes and configure each entity class one by one, it is too troublesome. At this time, you can use the global policy of primary key. You only need to configure it in application.yml. For example, the global auto increment primary key policy is configured
# application.yml
mybatis-plus:
global-config:
db-config:
id-type: auto
Copy codeThe following is a demonstration of the behavior of different primary key policies
-
AUTO
Annotate the id attribute on the user, and then modify the user table of MYSQL to auto increment its primary key.
@EqualsAndHashCode(callSuper = false) @Data public class User extends Model<User> { @TableId(type = IdType.AUTO) private Long id; @TableField(condition = SqlCondition.LIKE) private String name; @TableField(condition = "%s > #{%s}") private Integer age; private String email; private Long managerId; private LocalDateTime createTime; } Copy codetest
@Test public void testAuto() { User user = new User(); user.setName("I'm frog quack"); user.setAge(99); user.setEmail("frog@baomidou.com"); user.setCreateTime(LocalDateTime.now()); userMapper.insert(user); System.out.println(user.getId()); } Copy coderesult
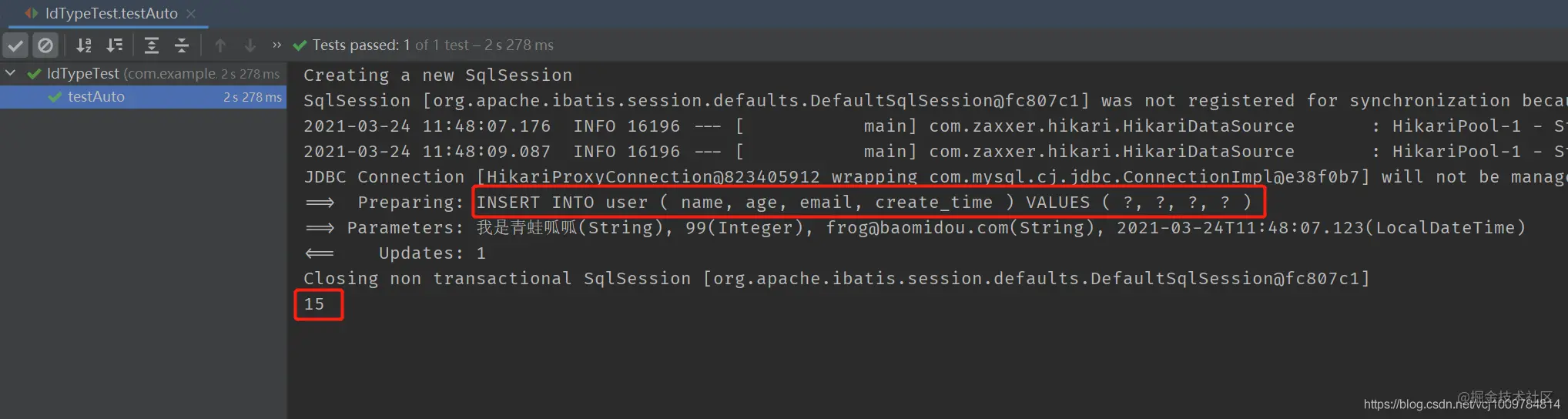
You can see that the primary key ID is not set in the code, nor is it set in the issued SQL statement, and the primary key ID will be written back to the entity object after insertion.
-
NONE
In the user table of MYSQL, remove the primary key and auto increment. Then modify the user class (if the @ TableId annotation is not configured, the default primary key policy is NONE)
@TableId(type = IdType.NONE) private Long id; Copy code
When inserting, if the primary key ID of the entity class has a value, it is used; If the primary key ID is empty, the global primary key policy is used to generate an ID.
-
Other strategies are similar and will not be repeated
Summary
AUTO depends on the self incrementing primary key of the database. When inserting, the entity object does not need to set the primary key. After the insertion is successful, the primary key will be written back to the entity object.
INPUT is completely dependent on user INPUT. The primary key ID in the entity object is set when it is inserted into the database. If there is a value, set the value. If it is null, set null
The other strategies are generated automatically when the primary key ID in the entity object is empty.
NONE will follow the global policy, ASSIGN_ID adopts snowflake algorithm, ASSIGN_UUID adopts UUID
Global configuration in application.yml; For the local configuration of a single entity class, use @ TableId. For an entity class, if it has a local primary key policy, it will be adopted; otherwise, it will follow the global policy.
to configure
mybatis plus has many configurable items, which can be configured in application.yml, such as the global primary key policy above. Some configuration items are listed below
Basic configuration
- configLocation: if there is a separate mybatis configuration, use this annotation to specify the mybatis configuration file (global configuration file of mybatis)
- Maperlocations: the location of the xml file corresponding to mybatis mapper
- typeAliasesPackage: alias package scanning path of mybatis
- .....
Advanced configuration
-
mapUnderscoreToCamelCase: whether to enable automatic hump naming rule mapping. (on by default)
-
dbTpe: database type. Generally, it does not need to be configured. It will be automatically identified according to the database connection url
-
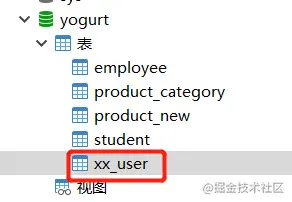
tablePrefix: add table name prefix
mybatis-plus: global-config: db-config: table-prefix: xx_ Copy code
Then modify the table in MYSQL. However, the Java entity class remains unchanged (still User).
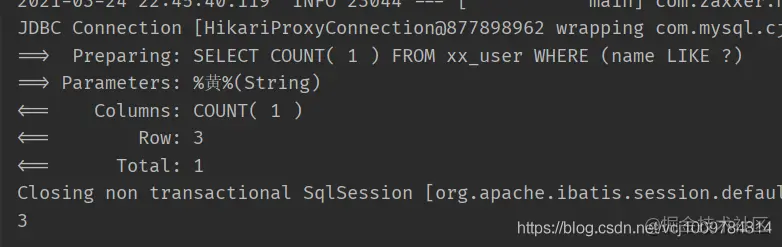
@ Test public void test3() {querywrapper < user > wrapper = new querywrapper < > (); wrapper.like ("name", "yellow"); Integer count = userMapper.selectCount(wrapper); System.out.println(count);} copy code
You can see the spliced SQL with a prefix added in front of the table name
For complete configuration, please refer to mp's official website = = > Portal
Code generator
mp provides a generator that can quickly generate a full set of codes such as Entity class, Mapper interface, Service, Controller, etc.
Examples are as follows
public class GeneratorTest {
@Test
public void generate() {
AutoGenerator generator = new AutoGenerator();
// Global configuration
GlobalConfig config = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
// Set the directory to export to
config.setOutputDir(projectPath + "/src/main/java");
config.setAuthor("yogurt");
// Open folder after generation
config.setOpen(false);
// Add global configuration to generator
generator.setGlobalConfig(config);
// Data source configuration
DataSourceConfig dataSourceConfig = new DataSourceConfig();
dataSourceConfig.setUrl("jdbc:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai");
dataSourceConfig.setDriverName("com.mysql.cj.jdbc.Driver");
dataSourceConfig.setUsername("root");
dataSourceConfig.setPassword("root");
// Add data source configuration to generator
generator.setDataSource(dataSourceConfig);
// Package configuration, under which package is the generated code placed
PackageConfig packageConfig = new PackageConfig();
packageConfig.setParent("com.example.mp.generator");
// Add package configuration to generator
generator.setPackageInfo(packageConfig);
// Policy configuration
StrategyConfig strategyConfig = new StrategyConfig();
// Underline hump naming conversion
strategyConfig.setNaming(NamingStrategy.underline_to_camel);
strategyConfig.setColumnNaming(NamingStrategy.underline_to_camel);
// Open lombok
strategyConfig.setEntityLombokModel(true);
// Start RestController
strategyConfig.setRestControllerStyle(true);
generator.setStrategy(strategyConfig);
generator.setTemplateEngine(new FreemarkerTemplateEngine());
// Start build
generator.execute();
}
}
Copy codeAfter running, you can see that a complete set of code is generated as shown in the following figure
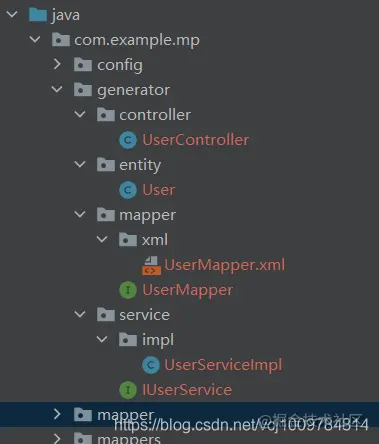
Advanced features
The demonstration of advanced functions requires a new table user2
DROP TABLE IF EXISTS user2; CREATE TABLE user2 ( id BIGINT(20) PRIMARY KEY NOT NULL COMMENT 'Primary key id', name VARCHAR(30) DEFAULT NULL COMMENT 'full name', age INT(11) DEFAULT NULL COMMENT 'Age', email VARCHAR(50) DEFAULT NULL COMMENT 'mailbox', manager_id BIGINT(20) DEFAULT NULL COMMENT 'Direct superior id', create_time DATETIME DEFAULT NULL COMMENT 'Creation time', update_time DATETIME DEFAULT NULL COMMENT 'Modification time', version INT(11) DEFAULT '1' COMMENT 'edition', deleted INT(1) DEFAULT '0' COMMENT 'Logical deletion ID,0-Not deleted,1-Deleted', CONSTRAINT manager_fk FOREIGN KEY(manager_id) REFERENCES user2(id) ) ENGINE = INNODB CHARSET=UTF8; INSERT INTO user2(id, name, age, email, manager_id, create_time) VALUES (1, 'boss', 40 ,'boss@baomidou.com' ,NULL, '2021-03-28 13:12:40'), (2, 'Son of a bitch', 40 ,'gd@baomidou.com' ,1, '2021-03-28 13:12:40'), (3, 'Wang egg', 40 ,'jd@baomidou.com' ,2, '2021-03-28 13:12:40'), (4, 'Bastard', 40 ,'yd@baomidou.com' ,2, '2021-03-28 13:12:40'), (5, 'Bastard', 40 ,'zd@baomidou.com' ,2, '2021-03-28 13:12:40'), (6, 'Son of a bitch', 40 ,'rd@baomidou.com' ,2, '2021-03-28 13:12:40'), (7, 'Iron bastard', 40 ,'td@baomidou.com' ,2, '2021-03-28 13:12:40') Copy code
And create the corresponding entity class User2
package com.example.mp.po;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class User2 {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Integer version;
private Integer deleted;
}
Copy codeMapper interface
package com.example.mp.mappers;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.mp.po.User2;
public interface User2Mapper extends BaseMapper<User2> { }
Copy codeLogical deletion
First of all, why should there be logical deletion? Can't you just delete it? Of course, but if you want to restore or need to view these data in the future, you can't do it. Logical deletion is a scheme to facilitate data recovery and protect the value of data itself.
In daily life, after deleting a file from the computer, we just put the file in the recycle bin, and we can view or restore it if necessary in the future. When we determine that we no longer need a file, we can completely delete it from the recycle bin. This is a similar truth.
The logical deletion provided by mp is very simple to implement
You only need to configure the logical deletion in application.yml
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # Global logically deleted entity field name
logic-delete-value: 1 # Logical deleted value (default is 1)
logic-not-delete-value: 0 # Logical undeleted value (0 by default)
# If the deleted and undeleted values are the same as the default values, these two items can not be configured
Copy codeTest code
package com.example.mp;
import com.example.mp.mappers.User2Mapper;
import com.example.mp.po.User2;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class LogicDeleteTest {
@Autowired
private User2Mapper mapper;
@Test
public void testLogicDel() {
int i = mapper.deleteById(6);
System.out.println("rowAffected = " + i);
}
}
Copy coderesult
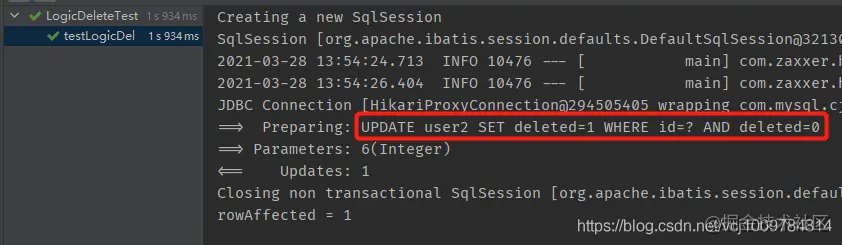
You can see that the issued SQL is no longer DELETE, but UPDATE
At this point, we execute SELECT again
@Test
public void testSelect() {
List<User2> users = mapper.selectList(null);
}
Copy code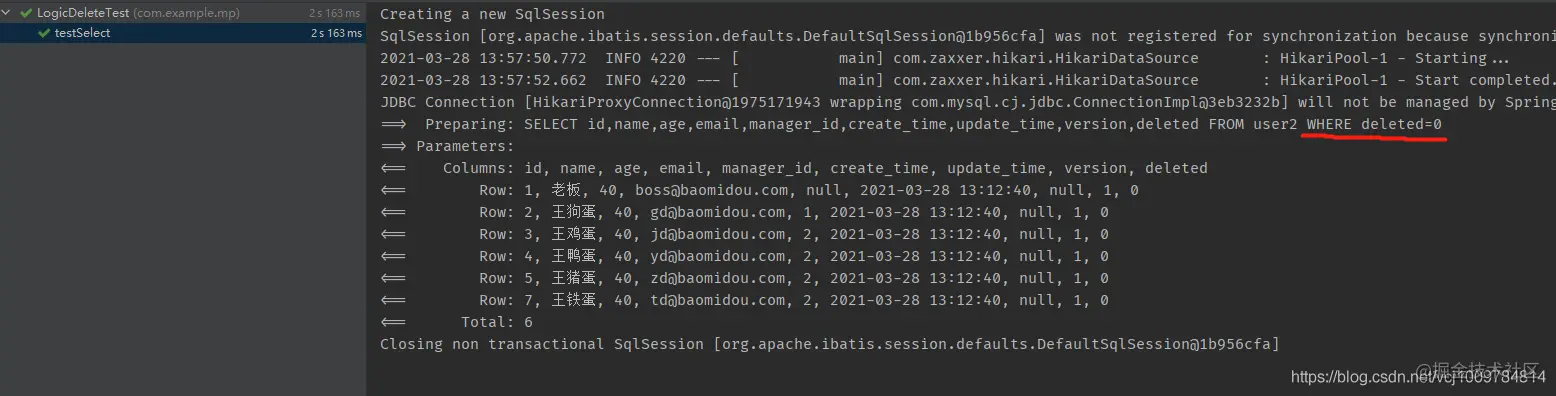
You can see that the issued SQL statement will automatically splice the conditions that have not been deleted logically after WHERE. In the query results, there is no Wang soft egg with id 6.
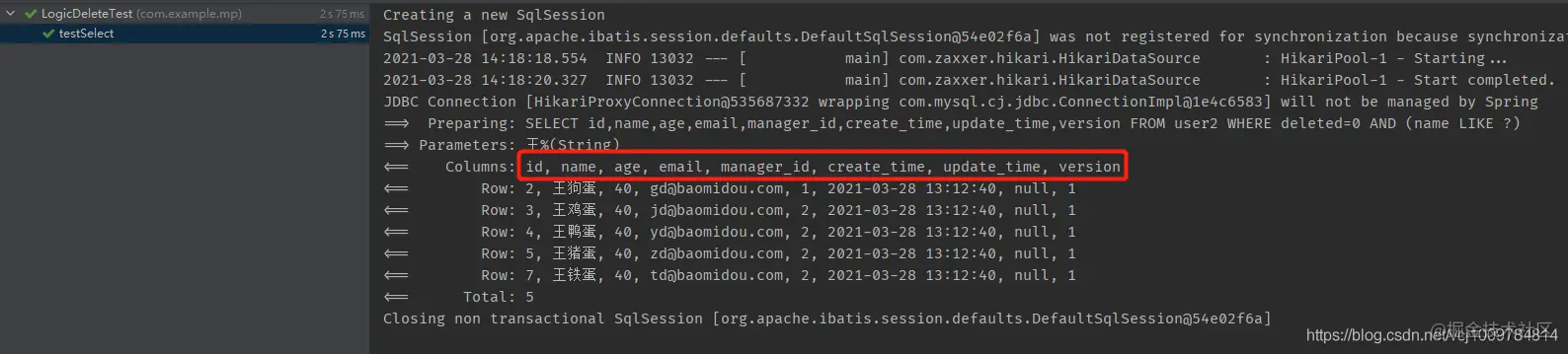
If you want to SELECT a column, excluding the logically deleted column, you can configure it through @ TableField in the entity class
@TableField(select = false) private Integer deleted; Copy code
You can see that in the execution result in the figure below, the column deleted is no longer included in the SELECT
The previous configuration in application.yml is global. Generally speaking, for multiple tables, we will also unify the names of logically deleted fields and the deleted and undeleted values, so global configuration is enough. Of course, if you want to configure some tables separately, you can use @ TableLogic on the corresponding fields of the entity class
@TableLogic(value = "0", delval = "1") private Integer deleted; Copy code
Summary
After the logical deletion of mp is enabled, it will have the following effects on SQL
- INSERT statement: no effect
- SELECT statement: append WHERE condition to filter out deleted data
- UPDATE statement: append a WHERE condition to prevent updating to deleted data
- DELETE statement: change to UPDATE statement
**Note that the above effects are only effective for mp automatically injected SQL** If you manually add custom SQL, it will not take effect. such as
public interface User2Mapper extends BaseMapper<User2> {
@Select("select * from user2")
List<User2> selectRaw();
}
Copy codeIf this selectRaw is called, the logical deletion of mp will not take effect.
In addition, logical deletion can be globally configured in application.yml or locally configured in entity class with @ TableLogic.
Auto fill
There are often fields such as "add time", "modify time" and "operator" in the table. The original method is to set manually each time you insert or update. mp can automatically fill in some fields through configuration. An example is as follows
-
On some fields in the entity class, auto fill is set by @ TableField
public class User2 { private Long id; private String name; private Integer age; private String email; private Long managerId; @TableField(fill = FieldFill.INSERT) // Auto fill on insertion private LocalDateTime createTime; @TableField(fill = FieldFill.UPDATE) // Auto fill on update private LocalDateTime updateTime; private Integer version; private Integer deleted; } Copy code -
Implement auto fill processor
package com.example.mp.component; import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler; import org.apache.ibatis.reflection.MetaObject; import org.springframework.stereotype.Component; import java.time.LocalDateTime; @Component //You need to register in the Spring container public class MyMetaObjectHandler implements MetaObjectHandler { @Override public void insertFill(MetaObject metaObject) { // Auto fill on insertion // Note that the second parameter needs to fill in the field name in the entity class, not the column name of the table strictFillStrategy(metaObject, "createTime", LocalDateTime::now); } @Override public void updateFill(MetaObject metaObject) { // Auto fill on update strictFillStrategy(metaObject, "updateTime", LocalDateTime::now); } } Copy code
test
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName("Son of a bitch");
user.setAge(29);
user.setEmail("yd@baomidou.com");
user.setManagerId(2L);
mapper.insert(user);
}
Copy codeAccording to the results in the following figure, you can see that createTime is automatically populated

Note that auto fill takes effect only when the field is empty. If the field is not empty, the existing value will be used directly. as follows
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName("Son of a bitch");
user.setAge(29);
user.setEmail("yd@baomidou.com");
user.setManagerId(2L);
user.setCreateTime(LocalDateTime.of(2000,1,1,8,0,0));
mapper.insert(user);
}
Copy code
The automatic filling during update is tested as follows:
@Test
public void test() {
User2 user = new User2();
user.setId(8L);
user.setName("Son of a bitch");
user.setAge(99);
mapper.updateById(user);
}
Copy code
Optimistic lock plug-in
When concurrent operations occur, it is necessary to ensure that each user's operations on data do not conflict. At this time, a concurrency control method is needed. The pessimistic locking method is to directly lock a record in the database (the locking mechanism of the database), lock the data, and then operate; The optimistic lock, as its name implies, assumes that there is no conflict, and then checks whether there is a conflict during actual data operations. A common implementation of optimistic locking is version number, which is also called MVCC in MySQL.
In the scenario of more reads and less writes, optimistic locking is more applicable, which can reduce the performance overhead caused by locking and improve the system throughput.
In the scenario of more writes and less reads, pessimistic locks are used. Otherwise, optimistic locks will continue to fail and retry, resulting in performance degradation.
The implementation of optimistic lock is as follows:
- When fetching records, get the current version
- When updating, bring this version
- When updating, set version = newVersion where version = oldVersion
- If the oldVersion is inconsistent with the version in the database, the update fails
This idea is very similar to CAS (Compare And Swap).
The implementation steps of optimistic lock are as follows
-
Configure optimistic lock plug-in
package com.example.mp.config; import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MybatisPlusConfig { /** 3.4.0 The following configuration method is recommended for future mp versions**/ @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); return interceptor; } /** The old version mp can be used in the following ways. Note that in the old and new versions, the name of the new version of the class has Inner, and the old version does not. Don't make a mistake**/ /* @Bean public OptimisticLockerInterceptor opLocker() { return new OptimisticLockerInterceptor(); } */ } Copy code -
Add the annotation @ Version on the field representing the Version in the entity class
@Data public class User2 { private Long id; private String name; private Integer age; private String email; private Long managerId; private LocalDateTime createTime; private LocalDateTime updateTime; @Version private Integer version; private Integer deleted; } Copy code
Test code
@Test
public void testOpLocker() {
int version = 1; // Suppose this version is obtained from the previous query
User2 user = new User2();
user.setId(8L);
user.setEmail("version@baomidou.com");
user.setVersion(version);
int i = mapper.updateById(user);
}
Copy codeTake a look at the database before executing
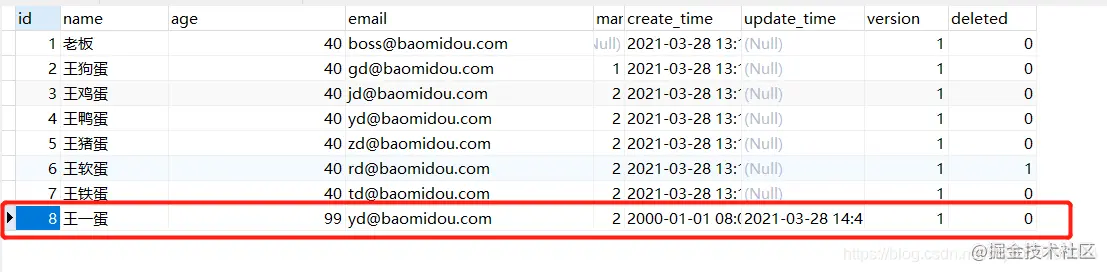
According to the execution results in the figure below, you can see that version related operations are added to the SQL statement
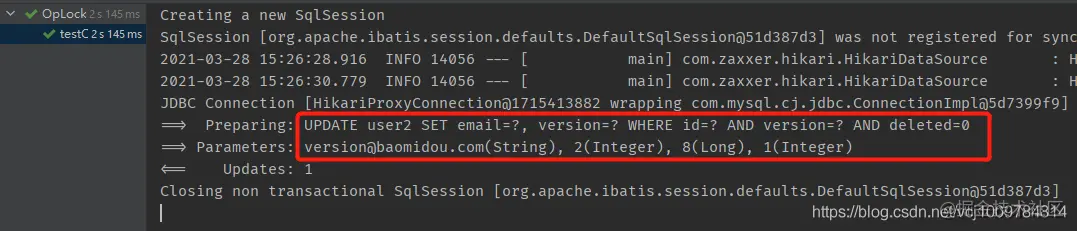
When the UPDATE returns 1, it indicates that the number of affected rows is 1, and the UPDATE is successful. On the contrary, because the version after WHERE is inconsistent with that in the database, and no records can be matched, the number of affected rows is 0, indicating that the UPDATE failed. After the UPDATE is successful, the new version will be encapsulated back into the entity object.
The version field in the entity class only supports int, long, Date, Timestamp and LocalDateTime
Note that the optimistic lock plug-in only supports updateById(id) and update(entity, wrapper) methods
**Note: if the wrapper is used, the wrapper cannot be reused** Examples are as follows
@Test
public void testOpLocker() {
User2 user = new User2();
user.setId(8L);
user.setVersion(1);
user.setAge(2);
// First use
LambdaQueryWrapper<User2> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User2::getName, "Son of a bitch");
mapper.update(user, wrapper);
// Second multiplexing
user.setAge(3);
mapper.update(user, wrapper);
}
Copy code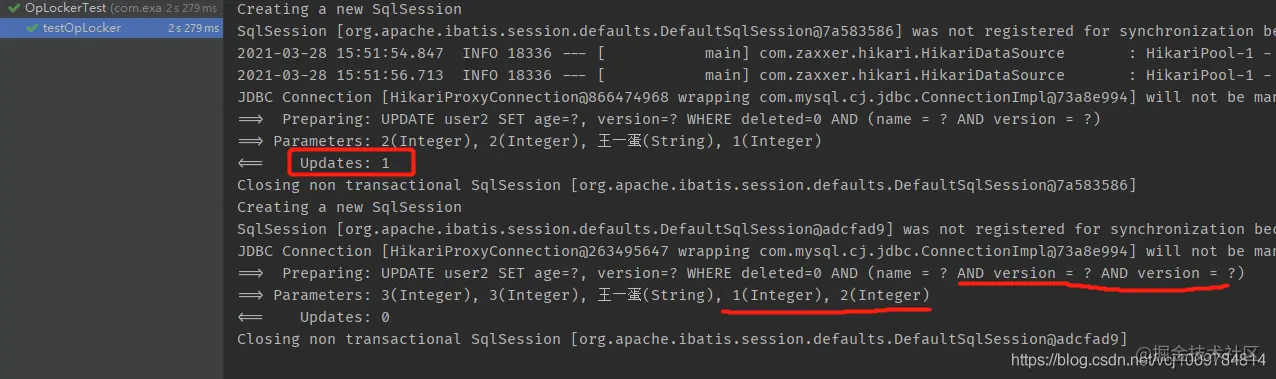
It can be seen that when the wrapper is reused for the second time, in the spliced SQL, there are two version s in the following WHERE statement, which is problematic.
Performance analysis plug-in
The plug-in will output the execution time of SQL statements for performance analysis and tuning of SQL statements.
Note: after version 3.2.0, the performance analysis plug-in of mp has been officially removed, and the third-party performance analysis plug-in is recommended
Eating steps
-
Introducing maven dependency
<dependency> <groupId>p6spy</groupId> <artifactId>p6spy</artifactId> <version>3.9.1</version> </dependency> Copy code -
Modify application.yml
spring: datasource: driver-class-name: com.p6spy.engine.spy.P6SpyDriver #Replace with p6spy's drive url: jdbc:p6spy:mysql://localhost:3306/yogurt?serverTimezone=Asia/Shanghai #url modification username: root password: root Copy code -
Add spy.properties in the src/main/resources resource directory
#spy.properties #3.2.1 use of the above modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory # Real JDBC driver s, multiple of which are separated by commas, are empty by default. Because the modulelist is set above, you can not set the driverlist here #driverlist=com.mysql.cj.jdbc.Driver # Custom log printing logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger #Log output to console appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger #To output the log to a file, comment out the above appnder, or use the following appender, and then add the logfile configuration #When an appender is not configured, it is output to a file by default #appender=com.p6spy.engine.spy.appender.FileLogger #logfile=log.log # Set p6spy driver agent deregisterdrivers=true # Remove JDBC URL prefix useprefix=true # Log exceptions are configured. The result sets that can be removed include error,info,batch,debug,statement,commit,rollback,result,resultset excludecategories=info,debug,result,commit,resultset # Date format dateformat=yyyy-MM-dd HH:mm:ss # Enable slow SQL logging outagedetection=true # Slow SQL record standard 2 seconds outagedetectioninterval=2 # Set the execution time. Only those exceeding this execution time will be recorded. The default value is 0. The unit is milliseconds executionThreshold=10 Copy code
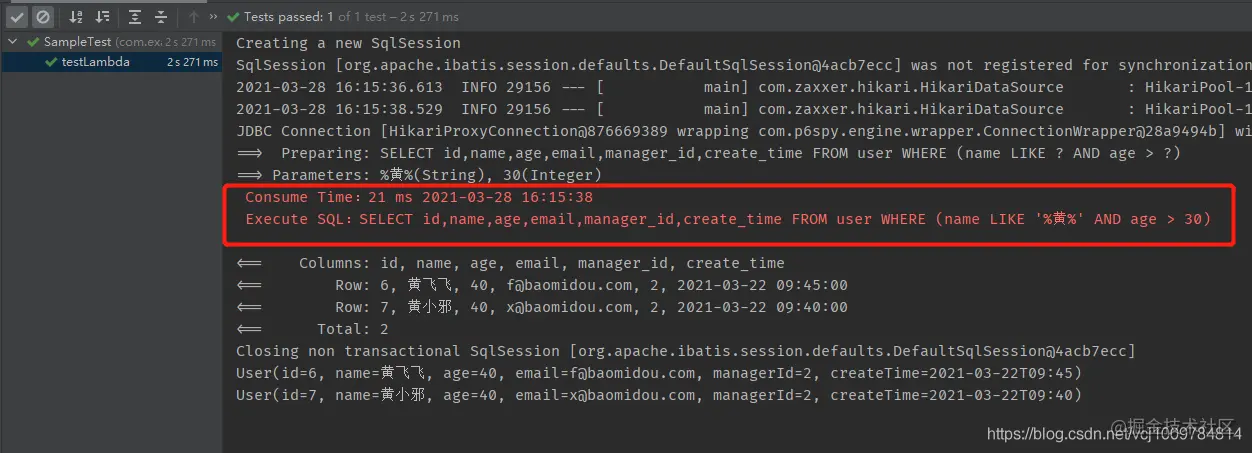
Run a test case casually, and you can see that the execution time of the SQL is recorded
Multi tenant SQL parser
Multi tenant concept: multiple users share a system, but their data needs to be relatively independent and maintain a certain degree of isolation.
Multi tenant data isolation generally has the following methods:
-
Different tenants use different database servers
The advantages are: different tenants have different independent databases, which is conducive to expansion, and provide better personalization for different tenants. It is relatively simple to recover data in case of failure.
The disadvantages are: the number of databases is increased, the purchase cost and maintenance cost are higher
-
Different tenants use the same database server, but use different databases (different schema s)
The advantage is that the purchase and maintenance costs are lower. The disadvantage is that data recovery is more difficult because the data of different tenants are put together
-
Different tenants use the same database server, use the same database, share data tables, and add tenant id to the table to distinguish
The advantages are the lowest purchase and maintenance cost and the most users supported. The disadvantages are the lowest isolation and the lowest security
Edible examples are as follows
Add a multi tenant interceptor configuration. After adding the configuration, when CRUD is executed, the conditions of tenant id will be spliced at the end of SQL statement automatically
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TenantLineHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.TenantLineInnerInterceptor;
import net.sf.jsqlparser.expression.Expression;
import net.sf.jsqlparser.expression.LongValue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new TenantLineInnerInterceptor(new TenantLineHandler() {
@Override
public Expression getTenantId() {
// Returns the value of the tenant id, which is fixed to 1
// Generally, a tenant id is taken from the current context
return new LongValue(1);
}
/**
** Usually, the column name representing the tenant id and the table excluding the tenant id are encapsulated into a configuration class (such as TenantConfig)
**/
@Override
public String getTenantIdColumn() {
// Returns the column name representing the tenant id in the table
return "manager_id";
}
@Override
public boolean ignoreTable(String tableName) {
// Multi tenant conditions are not spliced for tables whose table name is not user2
return !"user2".equals(tableName);
}
}));
// If the paging plug-in is used, please add TenantLineInnerInterceptor first and then paginationinnerinterceptor
// If paging plug-in is used, MybatisConfiguration#useDeprecatedExecutor = false must be set
return interceptor;
}
}
Copy codeTest code
@Test
public void testTenant() {
LambdaQueryWrapper<User2> wrapper = new LambdaQueryWrapper<>();
wrapper.likeRight(User2::getName, "king")
.select(User2::getName, User2::getAge, User2::getEmail, User2::getManagerId);
user2Mapper.selectList(wrapper);
}
Copy code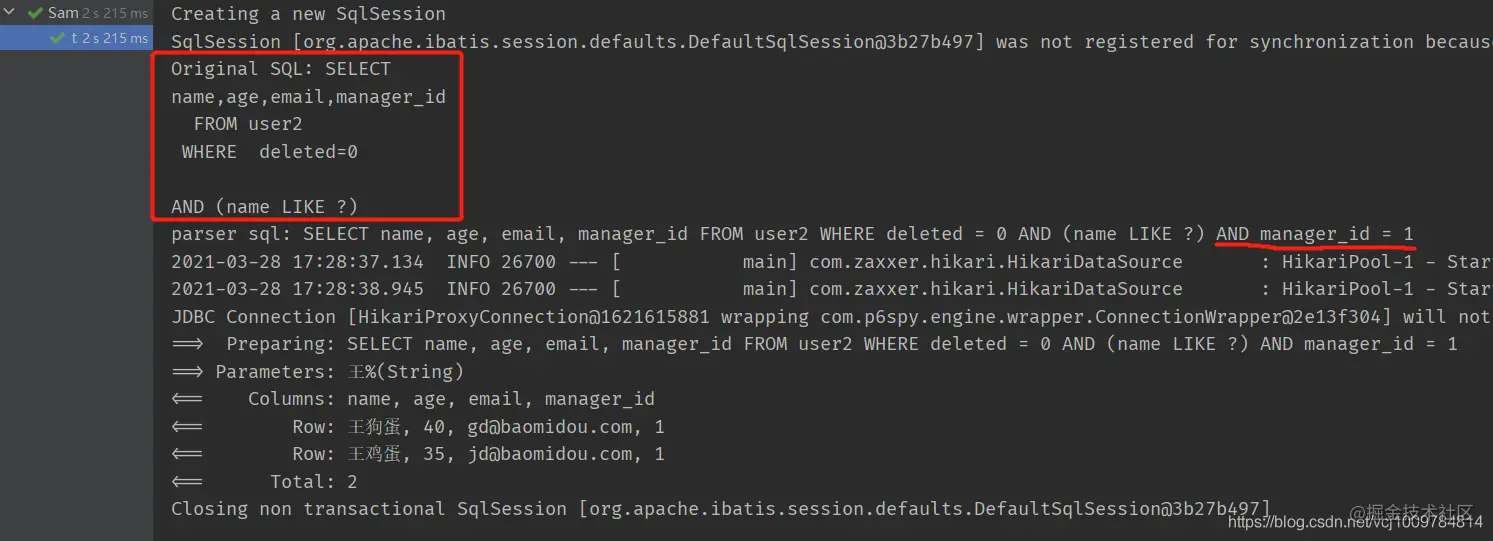
Dynamic table name SQL parser
When the amount of data is very large, we usually use sub database and sub table. At this time, there may be multiple tables with the same table structure but different table names. For example, order_1,order_2,order_3. When querying, we may need to dynamically set the table name to be queried. mp provides a dynamic table name SQL parser. An example is as follows
First copy the user2 table in mysql
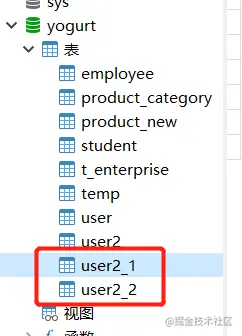
Configure dynamic table name interceptor
package com.example.mp.config;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.handler.TableNameHandler;
import com.baomidou.mybatisplus.extension.plugins.inner.DynamicTableNameInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Random;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
DynamicTableNameInnerInterceptor dynamicTableNameInnerInterceptor = new DynamicTableNameInnerInterceptor();
HashMap<String, TableNameHandler> map = new HashMap<>();
// For user2 table, set the dynamic table name
map.put("user2", (sql, tableName) -> {
String _ = "_";
int random = new Random().nextInt(2) + 1;
return tableName + _ + random; // If null is returned, dynamic table name replacement will not be performed, and user2 will still be used
});
dynamicTableNameInnerInterceptor.setTableNameHandlerMap(map);
interceptor.addInnerInterceptor(dynamicTableNameInnerInterceptor);
return interceptor;
}
}
Copy codetest
@Test
public void testDynamicTable() {
user2Mapper.selectList(null);
}
Copy code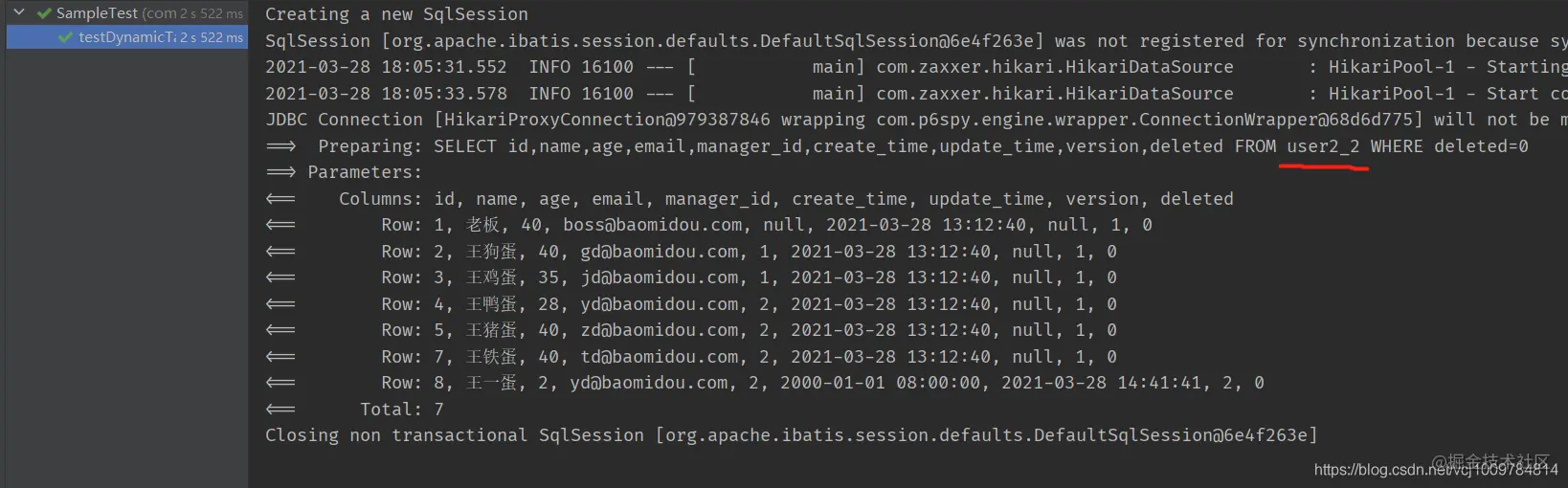
summary
-
The condition constructor AbstractWrapper provides multiple methods to construct WHERE conditions in SQL statements, while its subclass QueryWrapper additionally provides a select method to select only specific columns, and its subclass UpdateWrapper additionally provides a set method to set set statements in SQL. In addition to ordinary wrappers, there are also wrappers based on lambda expressions, such as LambdaQueryWrapper and LambdaUpdateWrapper. When constructing a WHERE condition, they directly specify the columns in the WHERE condition by method reference, which is more elegant than ordinary wrappers by string. In addition, there are chain wrappers, such as LambdaQueryChainWrapper, which encapsulates BaseMapper and makes it easier to obtain results.
-
The condition constructor uses chain calls to splice multiple conditions, which are connected by AND by default
-
When the conditions after AND OR need to be wrapped in parentheses, the conditions in parentheses are passed into and() OR or() as parameters in the form of lambda expression
In particular, when () needs to be placed at the beginning of the WHERE statement, you can use the nested() method
-
When you need to pass in a custom SQL statement or call a database function in a conditional expression, you can use the apply() method for SQL splicing
-
Each method in the condition constructor can flexibly splice WHERE conditions as needed through a boolean variable condition (SQL statements will be spliced only when the condition is true)
-
Using the lambda conditional constructor, you can directly use the attributes in the entity class for conditional construction through the lambda expression, which is more elegant than the ordinary conditional constructor
-
If the method provided by mp is not enough, it can be extended in the form of custom SQL (native mybatis)
-
When using mp for paging query, you need to create a paging Interceptor and register it in the Spring container. Then, you can query by passing in a paging object (Page object). When querying a single table, you can use the selectPage or selectMapsPage methods provided by BaseMapper. In complex scenarios (such as multi table associated query), user-defined SQL is used.
-
AR mode can directly operate the database by operating entity classes. Let the entity class inherit from the Model
(end)
Author: yogurtzzz
Link: https://juejin.cn/post/6961721367846715428