preface
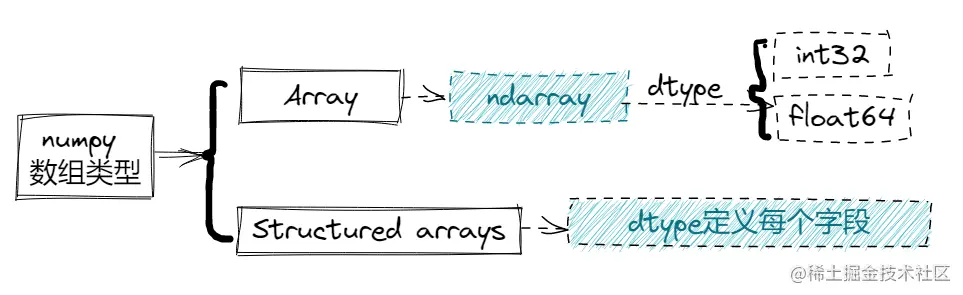
As we all know, numpy library is the basic library of scientific computing. We learned earlier that the numpy ndarray object requires the homogeneity of data elements in the array. At the same time, the memory space of numpy array element values is the same, and the bottom layer adopts two storage methods: C-order (row first storage) or FORTRAN order (column first storage). Compared with Python list, numpy array has more advantages in computing speed and memory.
In numpy index and slice and numpy advanced index, we know that arrays also support indexes like Python list. Numpy array index is realized by non negative integer tuples, Boolean values, other arrays or integers.
Everyone must be the same as me. numpy data requires that all data types must be homogeneous. How to calculate different types of data?
We all know that if we use the built-in Python library, we all know that the data types that can support the key value dictionary can easily realize our above scenario.
If numpy doesn't support this scenario, we'll give it up. How can it be the core of scientific Python and PyData ecosystem?
After consulting on the Internet, ha ha, we finally found that numpy array also has a concept called structured array.
In this issue, we will learn about the structured array of numpy library, Let's go~
1. Overview of numpy structured array
-
What is a structured array?
numpy structured array is a group of ndarray arrays composed of fields defined by dtype.
Using dict in Python, we can easily define the following data in the form of key value, list or tuple.

Python dict Dictionary implementation:
```
stu1 = {"name":"Tom","age":10,"weight":50}
stu2 = {"name":"Anne","age":12,"weight":42}
stu_list = [stu1,stu2]
Copy code
```
Python list+tuple realization
```
stu_list = [("Tom",10,50),("Anne",12,42)]
Copy code
```
about numpy Structured array, through dtype Define the data type of each field as follows
```
>>> stu_list = np.array([("Tom",10,50),("Anne",12,42)],dtype=[("name","U10"),("age","i4"),("weight","i8")])
>>> stu_list
array([('Tom', 10, 50), ('Anne', 12, 42)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<i8')])
>>>
Copy code
```
numpy In the array, we can dtype Query the data type of the element in the array.
In the above case, we define name The field data type is Unicode,age Field is int32,weight Field is int64
numpy Supported data types and C The data types of languages correspond to each other. The common ones are as follows and the corresponding built-in codes
| data type | Built in code | significance |
| --- | --- | --- |
| int8 | i1 | Byte(-128 to 127) |
| int16 | i2 | integer,16 Bit byte |
| int32 | i4 | integer,32 Bit byte |
| int64 | i8 | integer,64 Bit byte |
| float16 | f2 | Floating point, 16 bit byte |
| float32 | f4 | Floating point, 32-bit byte |
| float64 | f8 | Floating point, 64 bit byte |
| bool_ | b | Boolean type |
| Unicode | U | Unicode code |
| String | S | character string |
-
Structured array features
- Structured data types are created from C language data structures and can share memory space
- numpy structured array is a low-level operation to solve C code interface and structured buffer
- Structured arrays support data nesting and association, and allow control of their memory layout
- Associative arrays are not suitable for manipulating table data because of the memory layout based on C structure, resulting in poor cache behavior
2. Structured data type
From the above, we know that the main difference between numpy structured array and ordinary array is that the data field types in the array need to be defined through dtype during creation.
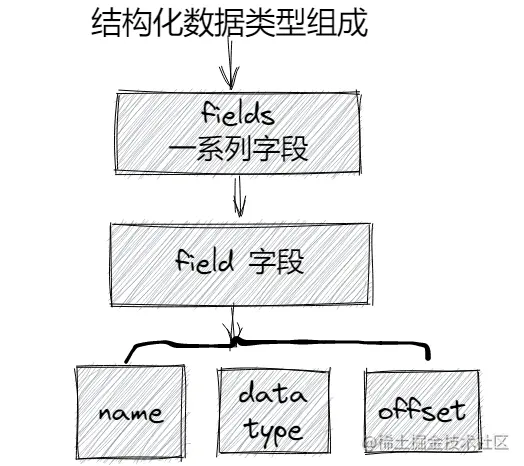
Therefore, structured data types can be regarded as a certain length of byte sequence (itemsize), which is usually interpreted as a collection of fields.
Generally, the field is mainly composed of three parts: field name, data type and byte offset (optional)
3. Creation of structured data type
In the numpy library, we can use numpy Dtypej to create structured data types.
-
Method 1: tuple list form
When creating structured data types, they can be defined in the form of tuples.
-
Each tuple represents a field in the form of (name,datatype,shape)
-
The shape field in the tuple is optional
-
datatype can be defined as any type
>>> np.dtype([("address","S5"),("family","U10",(2,2))]) dtype([('address', 'S5'), ('family', '<U10', (2, 2))]) >>> Copy code -
-
Method 2: separated by commas
In the numpy library, you can support comma separated basic format strings to define dtype.
-
Comma separated basic format string, such as: "i7,f4,U10"
-
The name in the field is automatically generated by the system, such as f0,f1 and other forms
-
The deviation in the field is automatically confirmed by the system
>>> np.dtype("i8,S4,f4") dtype([('f0', '<i8'), ('f1', 'S4'), ('f2', '<f4')]) >>> np.dtype("i8,S4,(5,3)f4") dtype([('f0', '<i8'), ('f1', 'S4'), ('f2', '<f4', (5, 3))]) >>> Copy code -
-
Method 3: express the parameters in dictionary form
Define the parameter type of each field in the form of Python dictionary key value.
- Dictionary form defines field forms, such as: {"name": [], "formats": [], "offset": [], "itemsize":}
- name: the list of field names with the same length
- formats: dtype basic format list
- offsets: offset list, optional fields.
- itemsize: describes the total size of dtype. Optional fields
The dictionary form represents the field content, which allows you to control the field deviation and itemsize
>>> np.dtype({"names":["name","age"],"formats":["S6","i4"]}) dtype([('name', 'S6'), ('age', '<i4')]) >>> np.dtype({"names":["name","age"],"formats":["S6","i4"],"offsets":[2,3],"itemsize":12}) dtype({'names':['name','age'], 'formats':['S6','<i4'], 'offsets':[2,3], 'itemsize':12}) >>> Copy code -
Method 4: represent the field name in dictionary form
This method represents the field name with the key value of the dictionary, and the value value represents the specified type and deviation in the form of tuple.
In Python version 3.6, the sequential operation of dictionaries is not preserved, but the order of fields in numpy structured dtype is meaningful. Therefore, the official of this method does not recommend using this method to create
>>> np.dtype({"name":("S6",0),"age":("i8",1)}) dtype({'names':['name','age'], 'formats':['S6','<i8'], 'offsets':[0,1], 'itemsize':9}) >>>
