return ProxySQL series: http://www.cnblogs.com/f-ck-need-u/p/7586194.html
1. Different types of read-write separation
The most basic function of database middleware is to realize the separation of reading and writing. Of course, ProxySQL also supports it. Moreover, the routing rules supported by ProxySQL are very flexible. It can not only realize the simplest separation of reading and writing, but also disperse the reading / writing to multiple different groups and realize sub database sharding (the rules of sub table sharding are difficult to write, but can also be realized).
This paper only describes the statement level read-write separation through rule making, and does not discuss the read-write separation through IP / port, client, username and schema.
The following describes the common types of read-write separation that ProxySQL can achieve.
1.1 the simplest separation of reading and writing
As shown in the figure.

The read-write separation of this mode strictly distinguishes the back-end master and slave nodes, and the slave node must set the option read_only=1. ProxySQL is divided into two groups, one write group HG=10 and the other read group HG=20. At the same time, open the read of monitor module on ProxySQL_ The only monitoring function allows ProxySQL to monitor the read_only value to automatically adjust whether the node is placed in HG=10(master will be placed in this group) or HG=20(slave will be placed in this group).
This mode of read-write separation is the simplest, just in mysql _ In the users table, set the default routing group of users as write group HG=10, and in MySQL_ query_ Add two simple rules (one select for update and one select) to the rules.
For example, this read-write separation mode is implemented below.
mysql_replication_hostgroups: +------------------+------------------+----------+ | writer_hostgroup | reader_hostgroup | comment | +------------------+------------------+----------+ | 10 | 20 | cluster1 | +------------------+------------------+----------+ mysql_servers: +--------------+----------+------+--------+--------+ | hostgroup_id | hostname | port | status | weight | +--------------+----------+------+--------+--------+ | 10 | master | 3306 | ONLINE | 1 | | 20 | slave1 | 3306 | ONLINE | 1 | | 20 | slave2 | 3306 | ONLINE | 1 | +--------------+----------+------+--------+--------+ mysql_users: +----------+-------------------+ | username | default_hostgroup | +----------+-------------------+ | root | 10 | +----------+-------------------+ mysql_query_rules: +---------+-----------------------+----------------------+ | rule_id | destination_hostgroup | match_digest | +---------+-----------------------+----------------------+ | 1 | 10 | ^SELECT.*FOR UPDATE$ | | 2 | 20 | ^SELECT | +---------+-----------------------+----------------------+
I only heard the voice of the architect from the architect's office: The sound of the partridge and the cuckoo cut. Who will match the first couplet or the second couplet?
This read-write separation mode can meet most needs in a small environment. However, when the requirements are complex and the environment is large, this mode is too rigid, because everything is controlled by the monitor module.
1.2 separation mode of multiple read or write groups
In the previous read-write separation mode, read is monitored through the monitor module_ Only, so each back-end cluster must be divided into one write group and one read group.
However, if you want to distinguish different select ions and route them to different nodes. For example, the overhead of some query statements is very large. How to realize if you want them to monopolize a node / group and other queries to share a node / group?
For example, the following pattern.

It looks very simple. But it can adapt to various needs. For example, the back-end makes a sub database, and the query of a database should be routed to a specific host group (this situation will be specially analyzed later).
As for whether each group of units is the same master-slave cluster (on the left of the figure below) or independent master-slave cluster environment (on the right of the figure below), it depends on the specific requirements, but this read-write separation mode can cope with it.
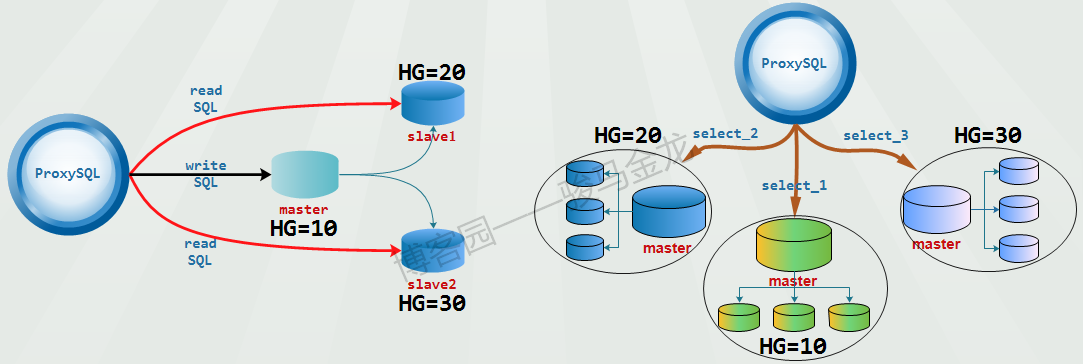
When implementing this mode, the premise is that the read of the monitor module cannot be turned on_ Only monitoring function, and do not set mysql_replication_hostgroup table.
For example, the following configuration implements the structure on the left of the figure above: write requests are routed to HG=10, select statements for test1 library are routed to HG=20, and other select statements are routed to HG=30.
This code is by Java Architect must see network-Structure Sorting mysql_servers: +--------------+----------+------+--------+--------+ | hostgroup_id | hostname | port | status | weight | +--------------+----------+------+--------+--------+ | 10 | host1 | 3306 | ONLINE | 1 | | 20 | host2 | 3306 | ONLINE | 1 | | 30 | host3 | 3306 | ONLINE | 1 | +--------------+----------+------+--------+--------+ mysql_users: +----------+-------------------+ | username | default_hostgroup | +----------+-------------------+ | root | 10 | +----------+-------------------+ mysql_query_rules: +---------+-----------------------+----------------------+ | rule_id | destination_hostgroup | match_digest | +---------+-----------------------+----------------------+ | 1 | 10 | ^SELECT.*FOR UPDATE$ | | 2 | 20 | ^SELECT.*test1\..* | | 3 | 30 | ^SELECT | +---------+-----------------------+----------------------+
1.3 read write separation after sharding
ProxySQL's support for sharding is relatively weak. It's really a little cumbersome to write sharding routing rules. However, ProxySQL can realize simple sharding by customizing routing rules. This is also a case of read-write separation.
As shown in the figure below, the library where the course is located is divided into three libraries: "MySQL", "Python" and "Linux". When the filter condition in the query condition is mysql, it is routed to the host group where the MySQL database is located HG=20. When the filter condition is python, it is routed to HG=10, the same as HG=30.

The specific details of how ProxySQL implements sharding will be introduced in my later articles.
2. Find out the SQL statements that need special treatment
Some SQL statements need special treatment because of their high execution times, high performance overhead, long execution time and so on. For example, route them to separate node / host groups, or enable caching for them.
For details, please refer to an article in the official manual, which I have translated: ProxySQL Read Write Split (HOWTO).
This paper uses sysbench to simulate in order to provide a test environment for this article in the official manual. Of course, if you know sysbench or other performance testing tools, you can ignore them.
1. First create the test database sbtest. Here, I directly connect to the MySQL node on the back end to create libraries and tables.
mysqladmin -h192.168.100.22 -uroot -pP@ssword1! -P3306 create sbtest;
2. Prepare the test table. Suppose taking two tables as an example, 10W rows of data in each table. After filling, the two tables are named sbtest1 and sbtest2.
This code is by Java Architect must see network-Structure Sorting
SYSBENCH=/usr/share/sysbench/
sysbench --mysql-host=192.168.100.22 \
--mysql-port=3306 \
--mysql-user=root \
--mysql-password=P@ssword1! \
$SYSBENCH/oltp_common.lua \
--tables=1 \
--table_size=100000 \
prepareTest the connection from proxybench to sql.sys3. Note that the following option -- DB PS mode must be set to disable, which means that ProxySQL is prohibited from using prepare statement. At present, ProxySQL does not support caching of prepare statements. However, the author of ProxySQL has put this function on the agenda.
sysbench --threads=4 \
--time=20 \
--report-interval=5 \
--mysql-host=127.0.0.1 \
--mysql-port=6033 \
--mysql-user=root \
--mysql-password=P@ssword1! \
--db-ps-mode=disable \
$SYSBENCH/oltp_read_only.lua \
--skip_trx=on \
--tables=1 \
--table_size=100000 \
runSince the routing of sysbench test statements has not been set at this time, they will all be routed to the same host group, such as the default group.
4. Check stats_ mysql_ query_ The digest table is sorted according to various test index conditions, for example, according to the total execution time field sum_time in descending order to find the most time-consuming statements, according to count_star descending sort finds out the statements that are executed the most times, and can also be sorted in descending order according to the average execution time, etc. Please refer to the official manual articles listed above.
For example, here according to sum_time descending sort:
Admin> SELECT count_star,sum_time,digest,digest_text
FROM stats_mysql_query_digest
ORDER BY sum_time DESC
LIMIT 4;
+------------+----------+--------------------+---------------------------------------------+
| count_star | sum_time | digest | digest_text |
+------------+----------+--------------------+---------------------------------------------+
| 72490 | 17732590 | 0x13781C1DBF001A0C | SELECT c FROM sbtest1 WHERE id=? |
| 7249 | 9629225 | 0x704822A0F7D3CD60 | SELECT DISTINCT c FROM sbtest1 XXXXXXXXXXXX |
| 7249 | 6650716 | 0xADF3DDF2877EEAAF | SELECT c FROM sbtest1 WHERE id XXXXXXXXXXXX |
| 7249 | 3235986 | 0x7DD56217AF7A5197 | SELECT c FROM sbtest1 WHERE id yyyyyyyyyyyy |
+------------+----------+--------------------+---------------------------------------------+5. For those expensive statements, formulate independent routing rules, and decide whether to turn on the query cache and the cache expiration time. 6. Test after writing the rules.