- Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages.
This is because the dynamic table is not in the append only mode. It needs to be processed with to retrieve stream
tableEnv.toRetractStreamPerson.print()
- Today, when you start the Flink task, an error was reported as "Caused by: java.lang.RuntimeException: Couldn't deploy Yarn cluster". After a careful look, you can see that there is a saying "system times on machines may be out of sync", which means that the system time on the machine may not be synchronized
(1) Install ntpdate tool
yum -y install ntp ntpdate
(2) Set system time and network time synchronization
ntpdate cn.pool.ntp.org
Perform this task on three machines respectively. After starting the task, I found that it was OK
- Could not retrieve the redirect address of the current leader. Please try to refresh. After the Flink task has been running for some time, the process is still in progress but the UI interface refreshes to prompt an error. If you kill the job and restart it, the error will still be reported
The solution is to delete the files in this directory and restart them
high-availability.zookeeper.path.root: /flink
ZooKeeper node root directory, under which the namespace of all cluster nodes is placed.
- No data sinks have been created yet. A program needs at least one sink that consumes data. Examples are writing the data set or printing it.
This is because there is no Sink. The solution is to add Sink before execute. For example: writeAsText
- could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.TypeInformation[String]
This error is due to the implicit transformation of scala. Just import this package. Import org. Apache. Flick. Streaming. API. Scala_
-
Sometimes when you restart the Flink job, an exception will be thrown. Wrong / missing exception when submitting job, which is actually a BUG of Flink, has been fixed. See jira for details, https://issues.apache.org/jira/browse/FLINK-10312
-
When Flink starts, it sometimes reports this error,
2019-02-23 07:27:53,093 ERROR org.apache.flink.runtime.rest.handler.job.JobSubmitHandler - Implementation error: Unhandled exception. akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/dispatcher#1998075247]] after [10000 ms]. Sender[null] sent message of type "org.apache.flink.runtime.rpc.messages.LocalFencedMessage". at akka.pattern.PromiseActorRef$$anonfun$1.apply$mcV$sp(AskSupport.scala:604) at akka.actor.Scheduler$$anon$4.run(Scheduler.scala:126) at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:601) at scala.concurrent.BatchingExecutor$class.execute(BatchingExecutor.scala:109) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:599) at akka.actor.LightArrayRevolverScheduler$TaskHolder.executeTask(LightArrayRevolverScheduler.scala:329) at akka.actor.LightArrayRevolverScheduler$$anon$4.executeBucket$1(LightArrayRevolverScheduler.scala:280) at akka.actor.LightArrayRevolverScheduler$$anon$4.nextTick(LightArrayRevolverScheduler.scala:284) at akka.actor.LightArrayRevolverScheduler$$anon$4.run(LightArrayRevolverScheduler.scala:236) at java.lang.Thread.run(Thread.java:745) 2019-02-23 07:27:54,156 ERROR org.apache.flink.runtime.rest.handler.legacy.files.StaticFileServerHandler - Could not retrieve the redirect address. java.util.concurrent.CompletionException: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/dispatcher#1998075247]] after [10000 ms]. Sender[null] sent message of type "org.apache.flink.runtime.rpc.messages.LocalFencedMessage". at java.util.concurrent.CompletableFuture.internalComplete(CompletableFuture.java:205) at java.util.concurrent.CompletableFuture$ThenApply.run(CompletableFuture.java:723) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:193) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2361) at org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:772) at akka.dispatch.OnComplete.internal(Future.scala:258) at akka.dispatch.OnComplete.internal(Future.scala:256) at akka.dispatch.japi$CallbackBridge.apply(Future.scala:186) at akka.dispatch.japi$CallbackBridge.apply(Future.scala:183) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36) at org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:83) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252) at akka.pattern.PromiseActorRef$$anonfun$1.apply$mcV$sp(AskSupport.scala:603) at akka.actor.Scheduler$$anon$4.run(Scheduler.scala:126) at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:601) at scala.concurrent.BatchingExecutor$class.execute(BatchingExecutor.scala:109) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:599) at akka.actor.LightArrayRevolverScheduler$TaskHolder.executeTask(LightArrayRevolverScheduler.scala:329) at akka.actor.LightArrayRevolverScheduler$$anon$4.executeBucket$1(LightArrayRevolverScheduler.scala:280) at akka.actor.LightArrayRevolverScheduler$$anon$4.nextTick(LightArrayRevolverScheduler.scala:284) at akka.actor.LightArrayRevolverScheduler$$anon$4.run(LightArrayRevolverScheduler.scala:236) at java.lang.Thread.run(Thread.java:745)
- Today, when I ran Flink, I reported a warning. I didn't find the reason for it for a long time. Finally, I found an issues. In fact, this is a bug of Flink, which has been fixed in version 1.6.1
org.apache.flink.runtime.filecache.FileCache - improper use of releaseJob() without a matching number of createTmpFiles() calls for jobId b30ddc7e088eaf714e96a0630815440f
See the following connection for details: https://issues.apache.org/jira/browse/FLINK-10283
- Caused by: java.lang.RuntimeException: Rowtime timestamp is null. Please make sure that a proper TimestampAssigner is defined and the stream environment uses the EventTime time characteristic.
The rowtime timestamp is null. Ensure that the correct TimestampAssigner is defined and that the flow environment uses the EventTime time time attribute. That is to say, we need to extract the time stamp from the data source first, and then we can use rowtime. Just assign the watermark on it
- flink.table.TableJob$person$3(name: String, age: Integer, timestamp: Long)' must be static and globally accessible
This error is reported because the case class type we defined must be static and globally accessible, that is to say, it can be placed outside the main method
- The proctime attribute can only be appended to the table schema and not replace an existing field. Please move 'proctime' to the end of the schema
The translation of this error report is that the procctime attribute can only be attached to the table schema, and cannot replace the existing fields. Please move 'procime' to the end of the architecture. When we use procime, we need to put it in the last position of the field instead of other positions
- 12,No new data sinks have been defined since the last execution. The last execution refers to the latest call to 'execute()', 'count()', 'collect()', or 'print()'.
This error is reported because the print() method will automatically call the execute() method, causing an error, so comment out env.execute()
- 13,Operator org.apache.flink.streaming.api.datastream.KeyedStream@290d210d cannot set the parallelism
This error is reported because the concurrency of the operator is set after the keyedstream. This is not supported. The following writing method is wrong. Just delete the following line of code
.keyBy(_._1) .setParallelism(1)
- 14,Found more than one rowtime field: [order_time, pay_time] in the table that should be converted to a DataStream. Please select the rowtime field that should be used as event-time timestamp for the DataStream by casting all other fields to TIMESTAMP
This error report means that there are multiple rowtime fields in the table. Some fields should be cast to TIMESTAMP to select the row time field that should be used as the event TIMESTAMP of DataStream. The modification is as follows:
cast(o.order_time as timestamp) as order_time_timestamp
- 15. In standalone mode, the task manager hangs up after running for a period of time, and the error is reported as follows:
Task 'Source: Custom Source -> Map -> Map -> to: Row -> Map -> Sink: Unnamed (1/3)' did not react to cancelling signal for 30 seconds Task did not exit gracefully within 180 + seconds. Modify the configuration file flink-conf.yaml and add configuration task.cancellation.timeout: 0
The meaning of this configuration is timeout (in milliseconds), after which the task cancels the timeout and causes a fatal TaskManager error. A value of 0 disables watch dog
Task xxx did not react to cancelling signal in the last 30 seconds, but is stuck in method Two possibilities
The first is that the program fails to respond within 30 seconds, causing the task manager to hang up
Solution configure task.cancellation.timeout in flink-conf.yaml: 0
The second is that the task is blocked in a certain way
The solution is to look at the log and find the blocked method to solve it
- 16. When Flink consumes kafka locally, it reports an error as follows,
Unable to retrieve any partitions with KafkaTopicsDescriptor: Fixed Topics ([jason_flink])
In fact, kafka has been suspended. Check that kafka's process is still in progress, but it can't be connected. This is because kafka has a fake death. The specific cause of the fake death is still under investigation. Restart kafka cluster to consume
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:403) at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:318) at org.apache.flink.core.fs.Path.getFileSystem(Path.java:298) at org.apache.flink.runtime.state.filesystem.FsCheckpointStorage.<init>(FsCheckpointStorage.java:58) at org.apache.flink.runtime.state.filesystem.FsStateBackend.createCheckpointStorage(FsStateBackend.java:450) at org.apache.flink.contrib.streaming.state.RocksDBStateBackend.createCheckpointStorage(RocksDBStateBackend.java:458) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.<init>(CheckpointCoordinator.java:249) ... 19 more Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies. at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:64) at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:399) ... 25 more
This error report is due to the lack of hadoop dependency package in Flink. Download the corresponding version of hadoop package on the official website and put it in the lib directory of Flink
2019-11-25 17:43:11,739 WARN org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter - Failed to push metrics to PushGateway with jobName flink91fe8a52a4c95959ce33476c21975ba5. java.io.IOException: Response code from http://storm1:9091/metrics/job/flink91fe8a52a4c95959ce33476c21975ba5 was 200 at org.apache.flink.shaded.io.prometheus.client.exporter.PushGateway.doRequest(PushGateway.java:297) at org.apache.flink.shaded.io.prometheus.client.exporter.PushGateway.push(PushGateway.java:105) at org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter.report(PrometheusPushGatewayReporter.java:76) at org.apache.flink.runtime.metrics.MetricRegistryImpl$ReporterTask.run(MetricRegistryImpl.java:436) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
When using Flink 1.9.1 to configure prometheus monitoring and report metrics data to PushGateway 1.0.0, an error is reported. Finally, it is found that the version is incompatible. Just reduce the PushGateway version to 0.9.0
org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not allocate all requires slots within timeout of 300000 ms. Slots required: 12, slots allocated: 4, previous allocation IDs: [], execution status: completed: Attempt #0 (Source: kafka-source -> Filter -> Map -> Timestamps/Watermarks (1/6)) @ org.apache.flink.runtime.jobmaster.slotpool.SingleLogicalSlot@30a1906c - [SCHEDULED], completed: Attempt #0 (Source: kafka-source -> Filter -> Map -> Timestamps/Watermarks (2/6)) @ org.apache.flink.runtime.jobmaster.slotpool.SingleLogicalSlot@75a3181c - [SCHEDULED], completed: Attempt #0 (Source: kafka-source -> Filter -> Map -> Timestamps/Watermarks (3/6)) @ org.apache.flink.runtime.jobmaster.slotpool.SingleLogicalSlot@578caf - [SCHEDULED], completed: Attempt #0 (Source: kafka-source -> Filter -> Map -> Timestamps/Watermarks (4/6)) @ org.apache.flink.runtime.jobmaster.slotpool.SingleLogicalSlot@449ca9a8 - [SCHEDULED], completed exceptionally: java.util.concurrent.CompletionException: java.util.concurrent.CompletionException: java.util.concurrent.TimeoutException/java.util.concurrent.CompletableFuture@788263a7[Completed exceptionally], incomplete: java.util.concurrent.CompletableFuture@158ce753[Not completed, 1 dependents], incomplete: java.util.concurrent.CompletableFuture@290233b9[Not completed, 1 dependents], incomplete: java.util.concurrent.CompletableFuture@8f20ed8[Not completed, 1 dependents], incomplete: java.util.concurrent.CompletableFuture@6386cb3a[Not completed, 1 dependents], incomplete: java.util.concurrent.CompletableFuture@11c21e66[Not completed, 1 dependents], incomplete: java.util.concurrent.CompletableFuture@2965781c[Not completed, 1 dependents], incomplete: java.util.concurrent.CompletableFuture@31793726[Not completed, 1 dependents] at org.apache.flink.runtime.executiongraph.SchedulingUtils.lambda$scheduleEager$1(SchedulingUtils.java:194) at java.util.concurrent.CompletableFuture.uniExceptionally(CompletableFuture.java:870) at java.util.concurrent.CompletableFuture$UniExceptionally.tryFire(CompletableFuture.java:852) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.concurrent.FutureUtils$ResultConjunctFuture.handleCompletedFuture(FutureUtils.java:633) at org.apache.flink.runtime.concurrent.FutureUtils$ResultConjunctFuture.lambda$new$0(FutureUtils.java:656) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.jobmaster.slotpool.SchedulerImpl.lambda$internalAllocateSlot$0(SchedulerImpl.java:190) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.jobmaster.slotpool.SlotSharingManager$SingleTaskSlot.release(SlotSharingManager.java:700) at org.apache.flink.runtime.jobmaster.slotpool.SlotSharingManager$MultiTaskSlot.release(SlotSharingManager.java:484) at org.apache.flink.runtime.jobmaster.slotpool.SlotSharingManager$MultiTaskSlot.lambda$new$0(SlotSharingManager.java:380) at java.util.concurrent.CompletableFuture.uniHandle(CompletableFuture.java:822) at java.util.concurrent.CompletableFuture$UniHandle.tryFire(CompletableFuture.java:797) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.concurrent.FutureUtils$Timeout.run(FutureUtils.java:998) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:397) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:190) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at akka.actor.Actor$class.aroundReceive(Actor.scala:517) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) at akka.actor.ActorCell.invoke(ActorCell.scala:561) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) at akka.dispatch.Mailbox.run(Mailbox.scala:225) at akka.dispatch.Mailbox.exec(Mailbox.scala:235) at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
This error message is very obvious because the cluster resources are not enough. There are only four slot s, but the flow task needs 12. After scheduling several times, the task will report an error. It can't get up all the time. The status is displayed in the scheduling, as shown in the following figure
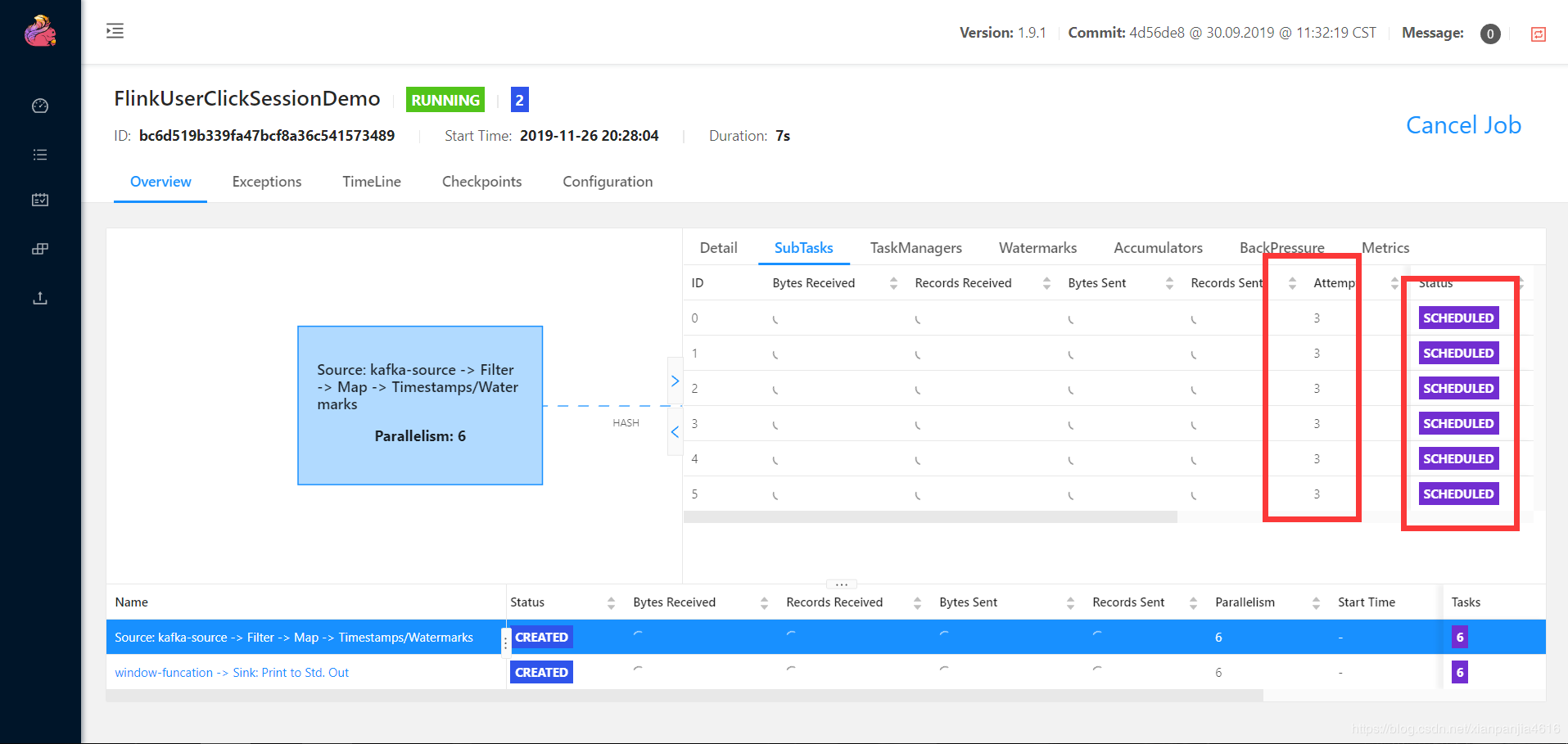
But I originally had two TMS, each of which has a slot of 4. I can start this task. I don't know why tm hung up one. The specific reason is still to be found, so I reported that this resource is not enough
- 20.java.lang.UnsupportedOperationException: Only supported for operators
This error is reported because Flink's name method can only be used on operators, not other methods
- 21.Checkpoint was declined (tasks not ready)
When the first checkpoint of a Flink task is started, an error is reported. This is because your ck time is too short. When the task is started and resources are being allocated, you have already started to do ck. Therefore, report task no ready. Set the time of ck a little longer. Especially when the parallelism of the operator is large, the allocation of resources is relatively slow. Set ck at the minute level as soon as possible
Caused by: org.apache.kafka.common.config.ConfigException: Must set acks to all in order to use the idempotent producer. Otherwise we cannot guarantee idempotence. at org.apache.kafka.clients.producer.KafkaProducer.configureAcks(KafkaProducer.java:501) at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:361) ... 14 more
When idempotence is turned on, acks is all. If acks is explicitly set to 0, - 1, the error must be set acks to all in order to use the identifier producer. Otherwise we cannot guarantee the identifier