ElasticSearch installation
Statement: JDK1.8! ElasticSearch client, interface tool!
Based on Java development, the version of ElasticSearch corresponds to the core jar package of java!
Download address
Official website: https://www.elastic.co/cn/
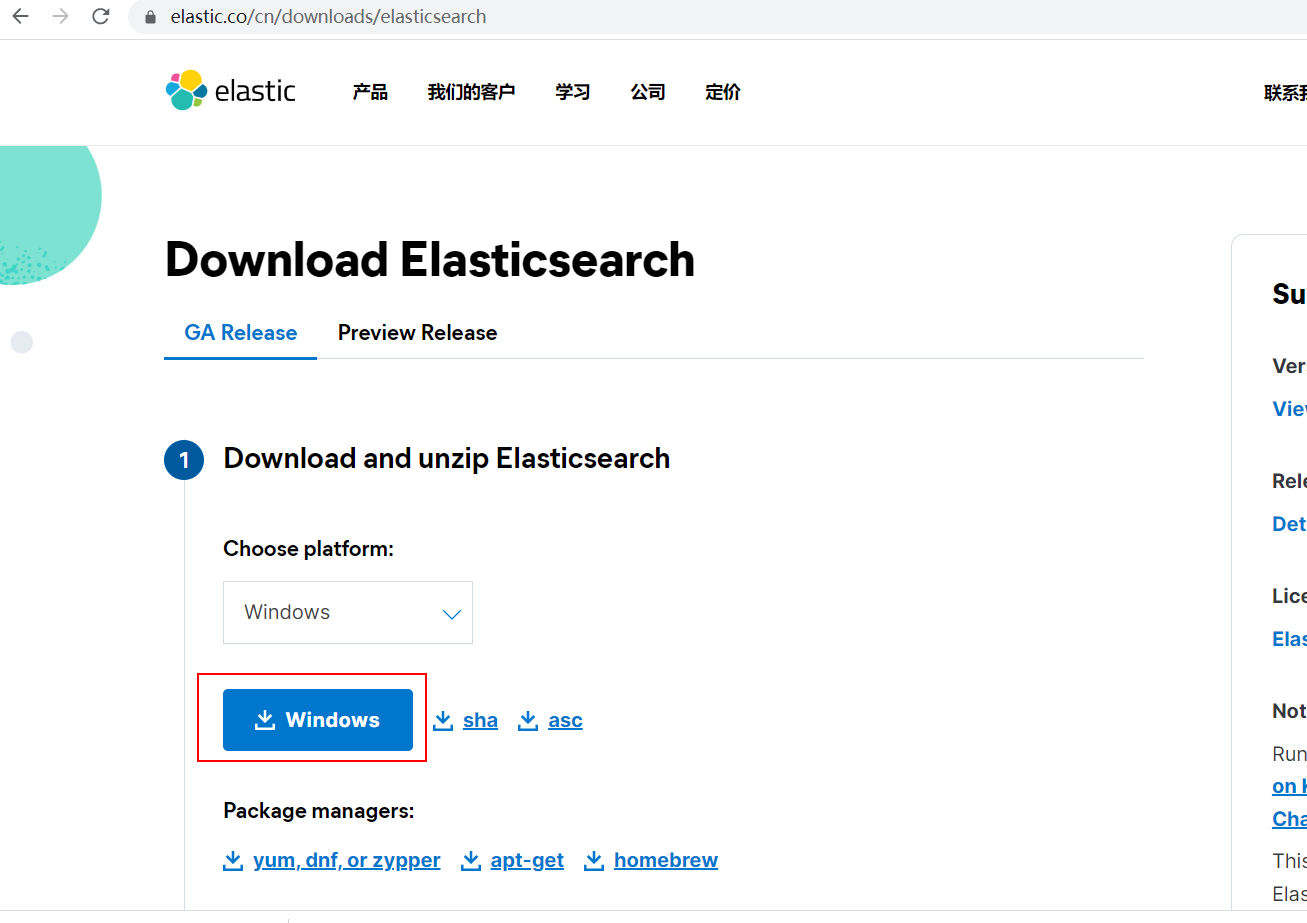
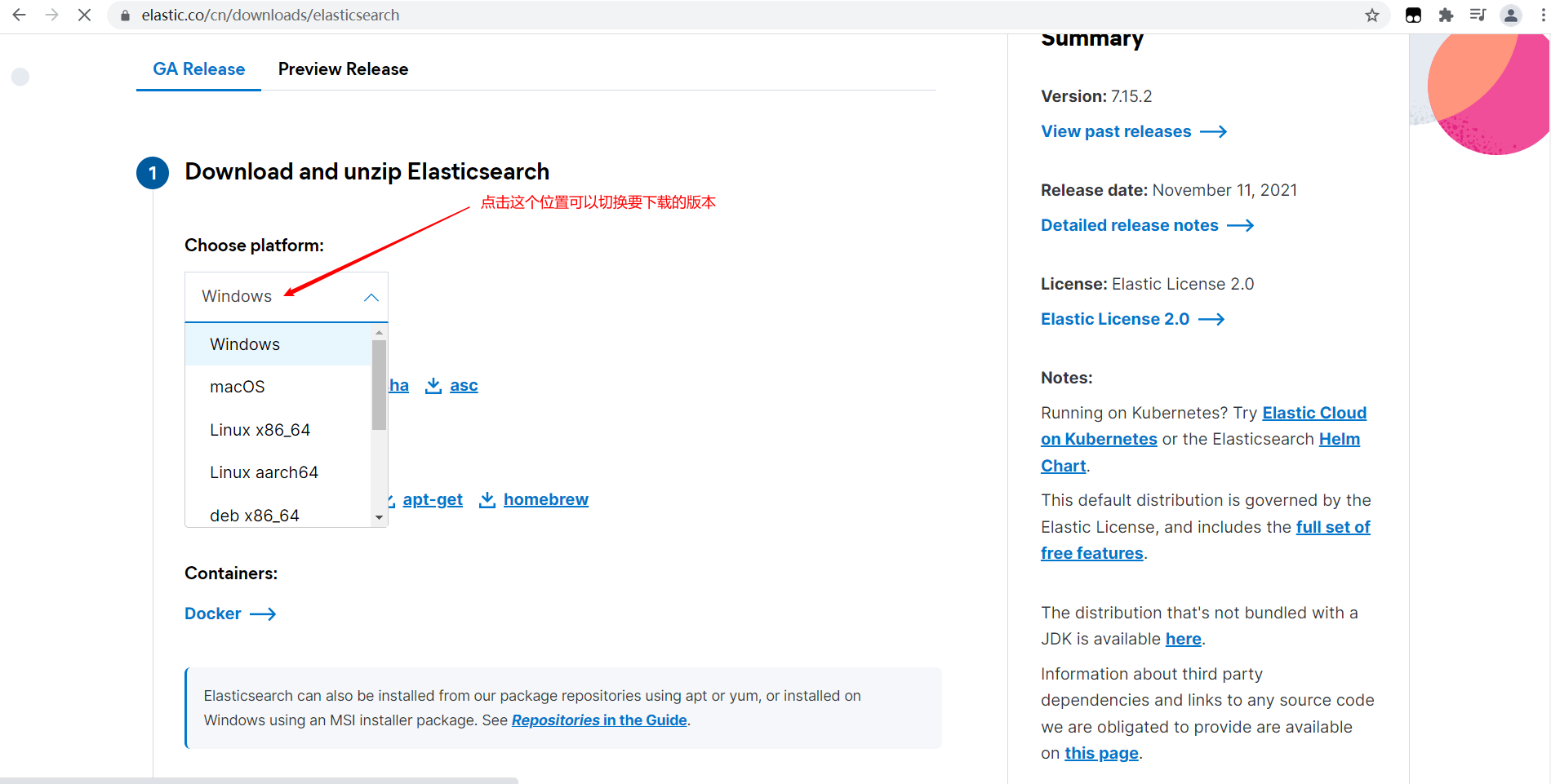
Download address: https://www.elastic.co/cn/downloads/elasticsearch
Here is to install the windows version
1. Decompress
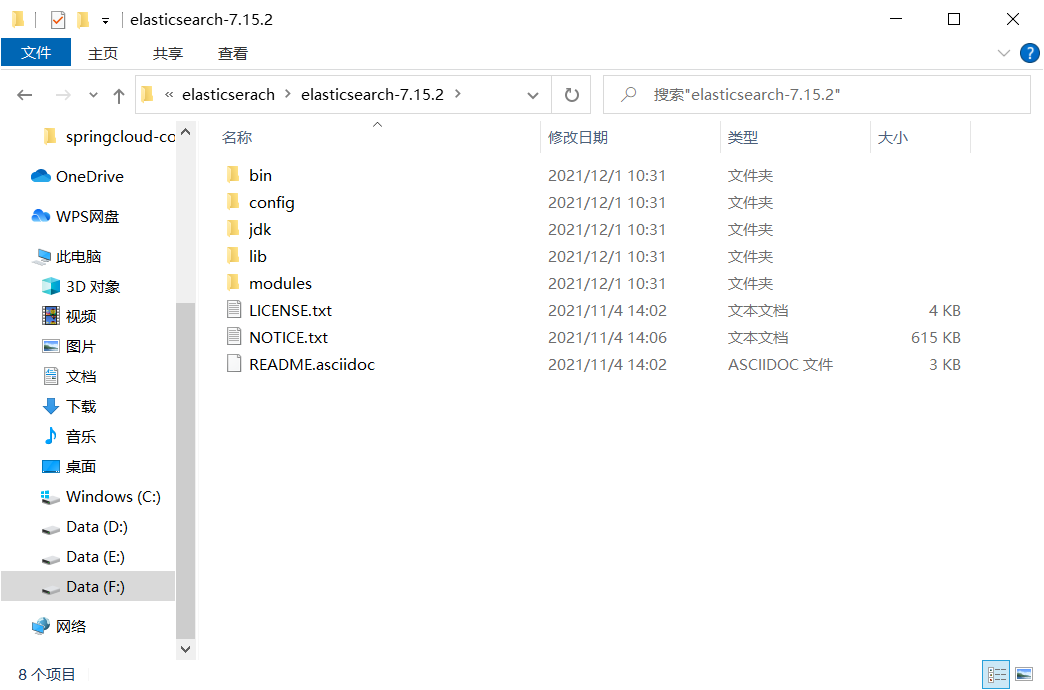
2. Familiar with directory
bin Startup file config configuration file log4j2.properties Log profile jvm.options java Virtual machine related configuration elasticsearch.yml elasticsearch Configuration file! Default port 9200 lib mutually jar package logs journal modules functional module plugins plug-in unit
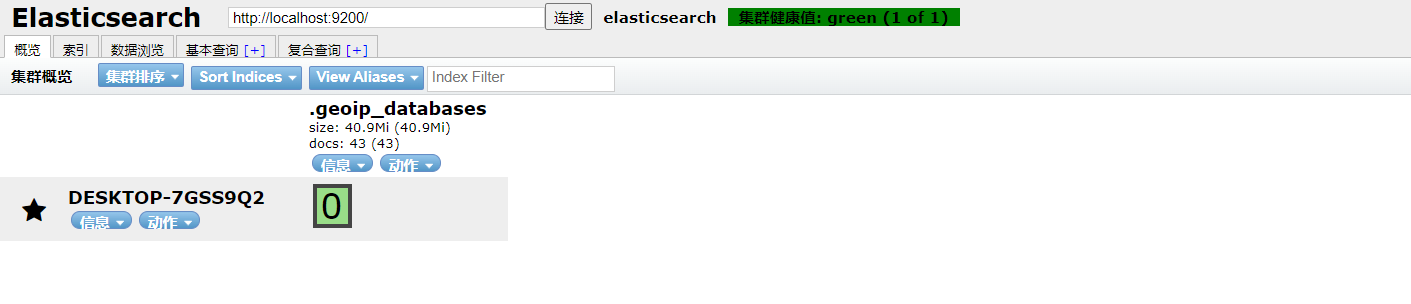
3. Start, access 9200

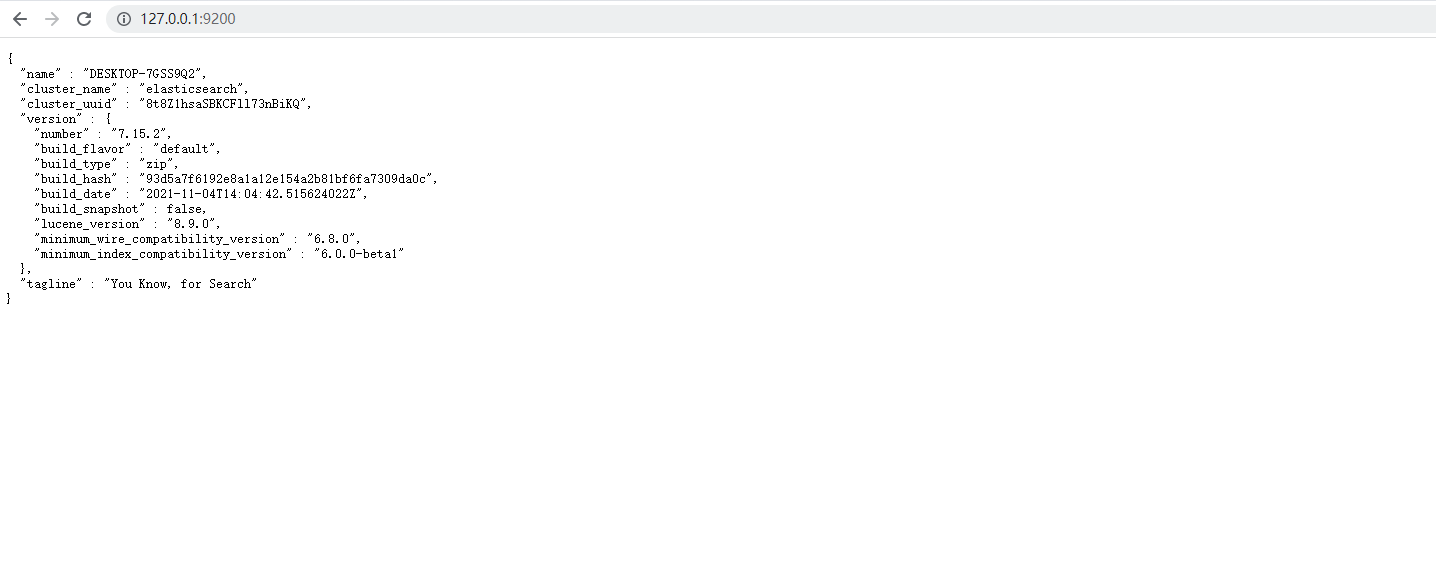
4. Access test
Install the visual interface elasticsearch head
1. Download address: https://github.com/NavyShu/Elasticsearch-Head
node environment needs to be configured
2. Start
npm install npm run start
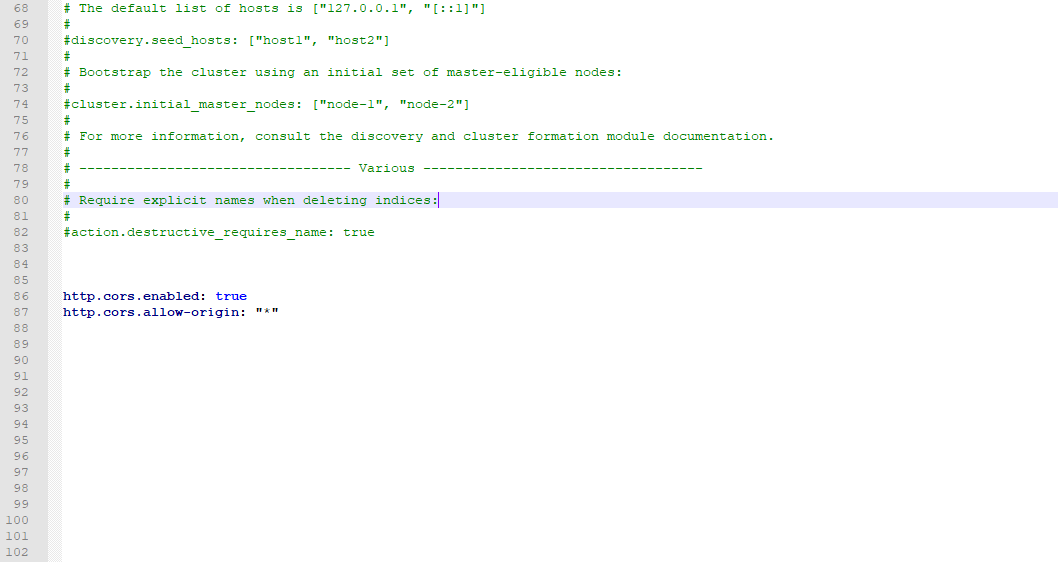
3. The connection test found that there is a cross domain problem: configure ElasticSearch
http.cors.enabled: true http.cors.allow-origin: "*"
4. Restart Elasticserach and connect again
Install kibana
Official website: https://www.elastic.co/cn/kibana/
Kibana version should be consistent with ElasticSearch!
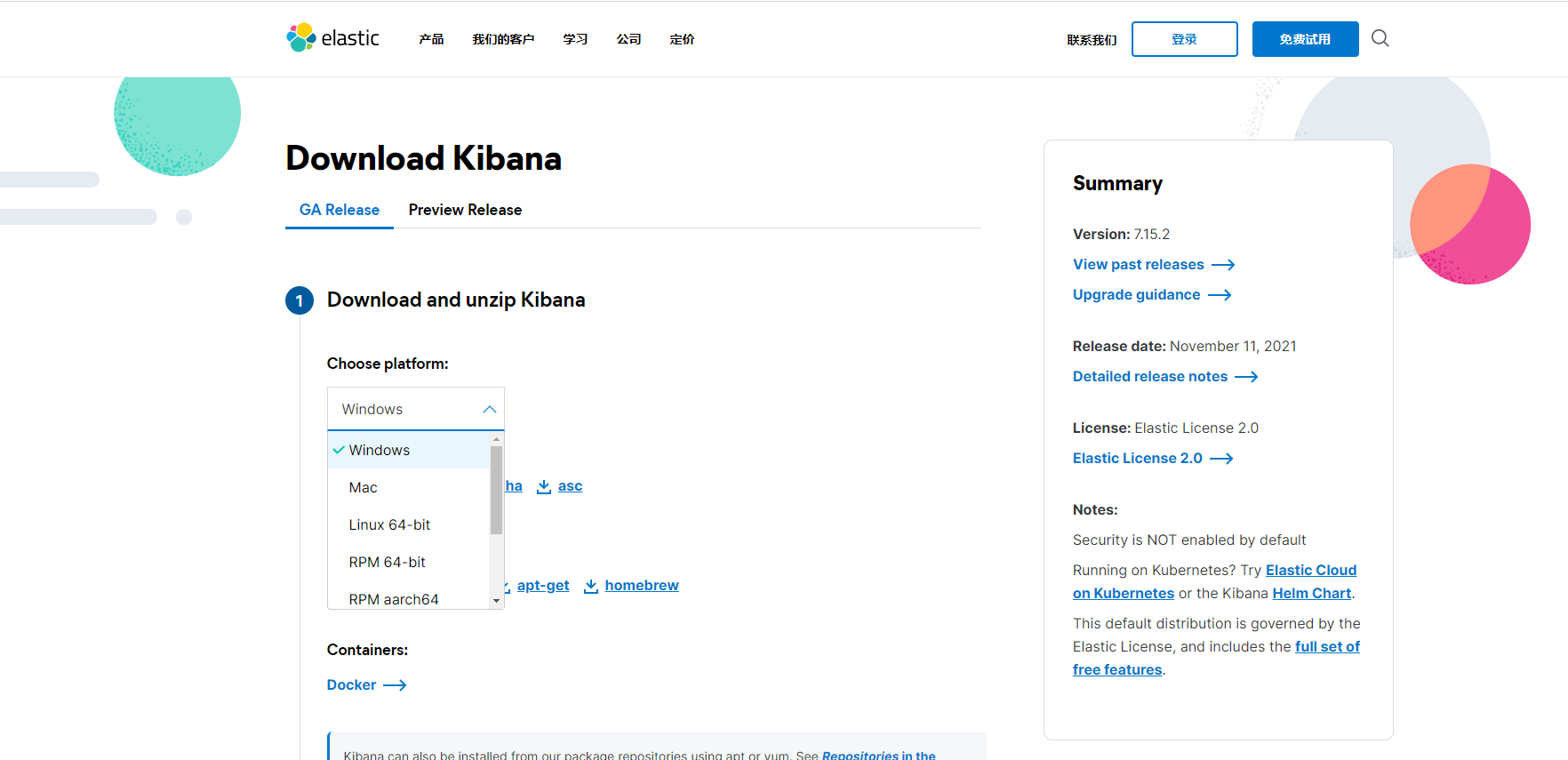
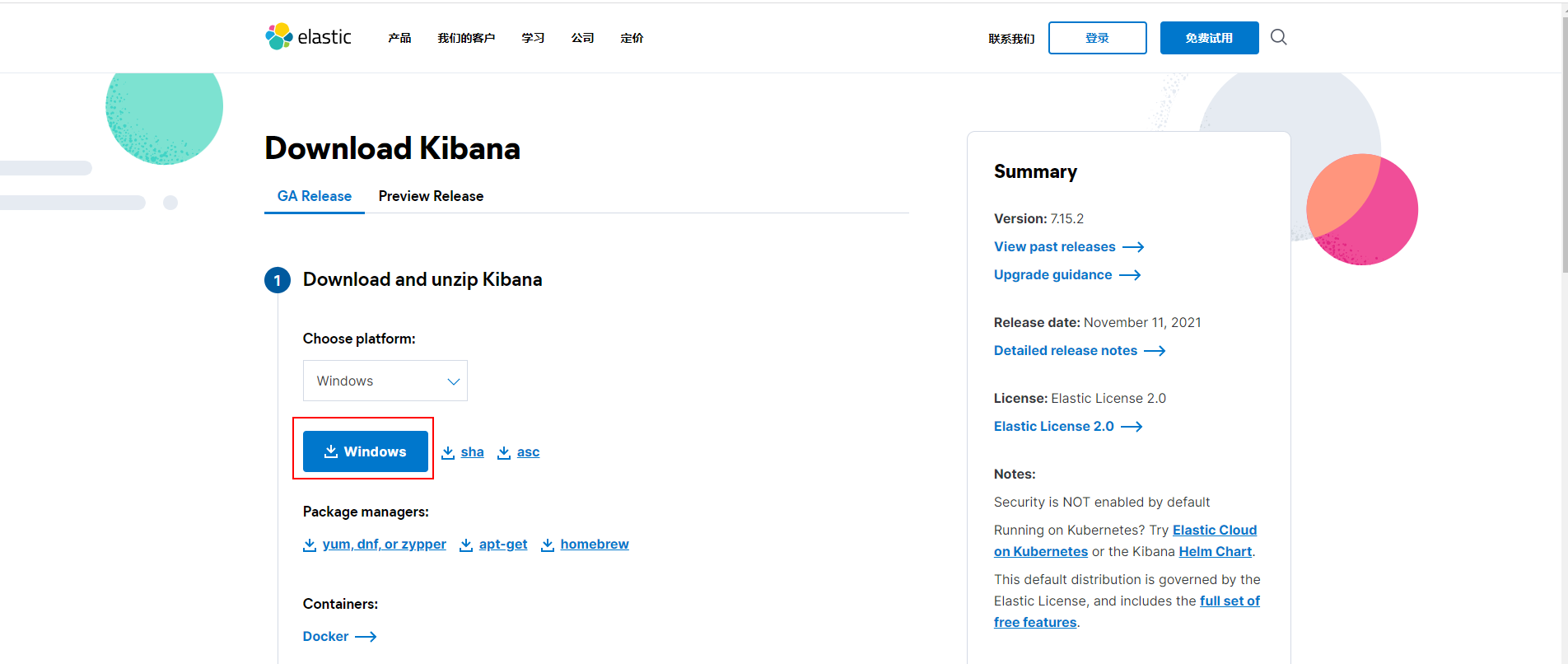
After downloading, decompression will take some time!
Benefits: ELK is basically unpacked and ready to use!
Start test:
1. Unzipped directory
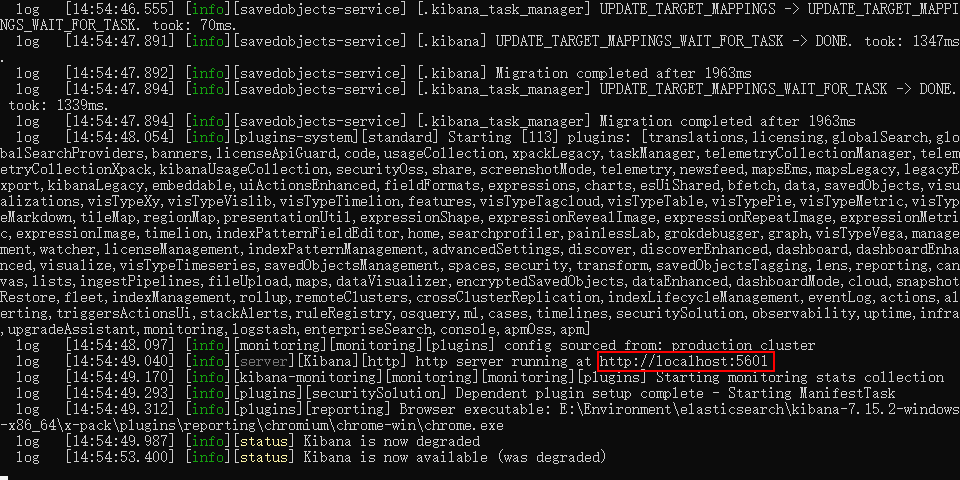
2. Start
3. Visit
4. Development tools! (Post, curl, head, Google Browser Test!)
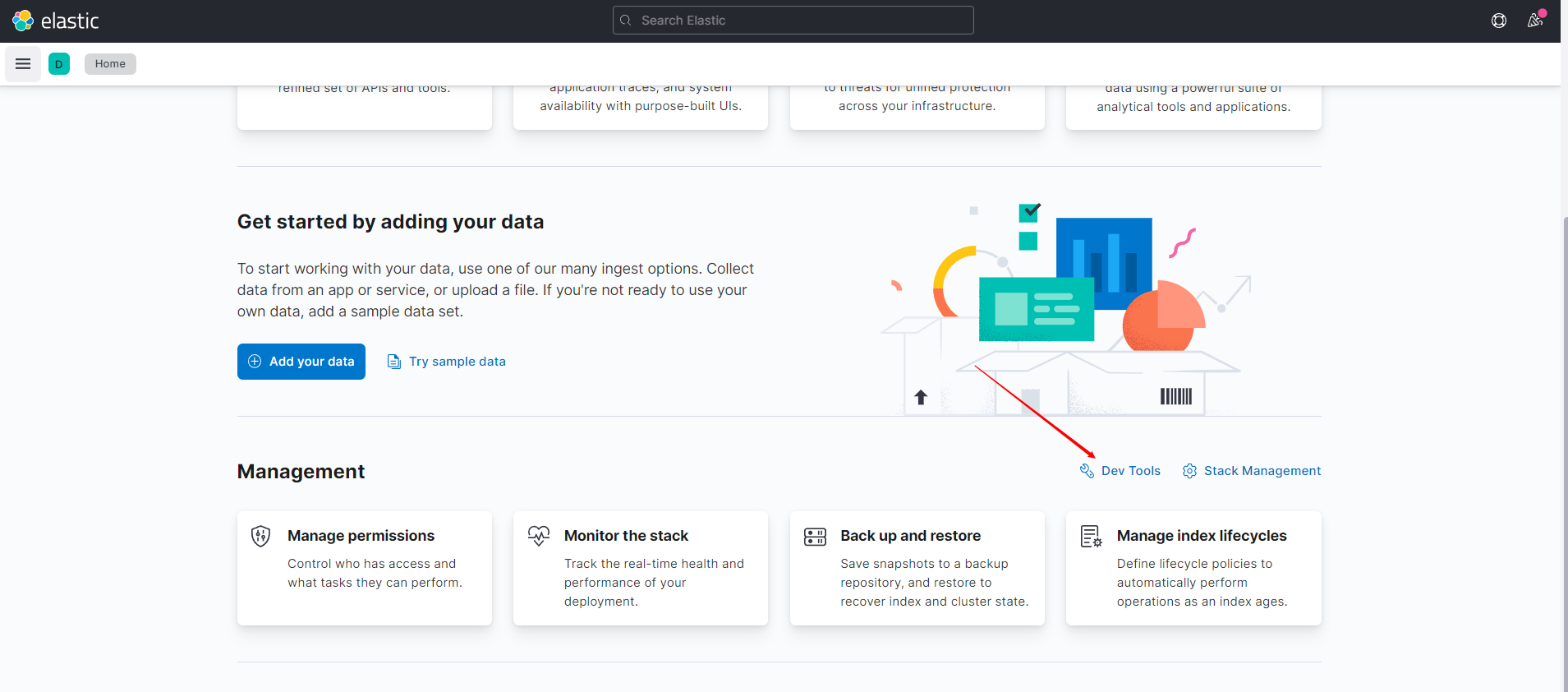
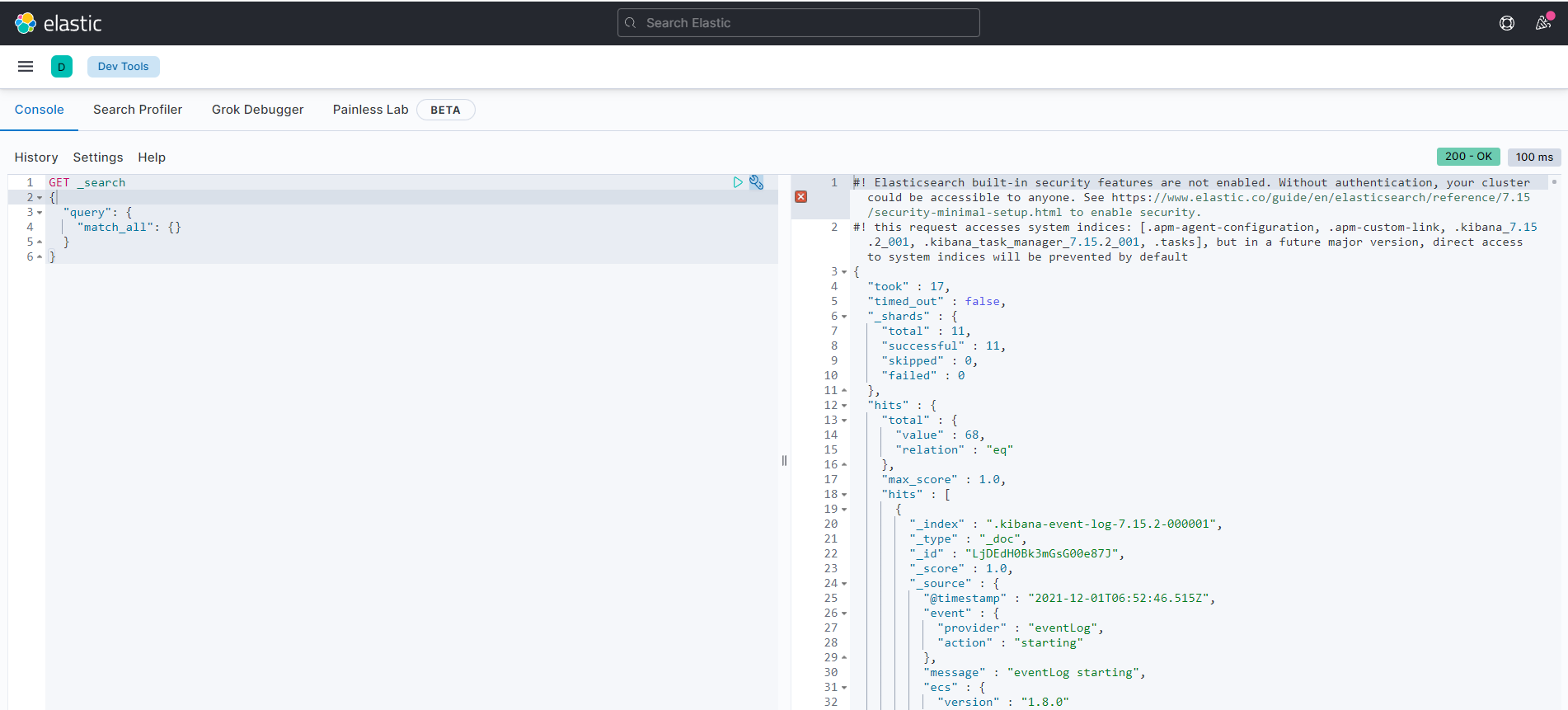
All our subsequent operations are written here!
5. Sinicization!
i18n.locale: "zh-CN"
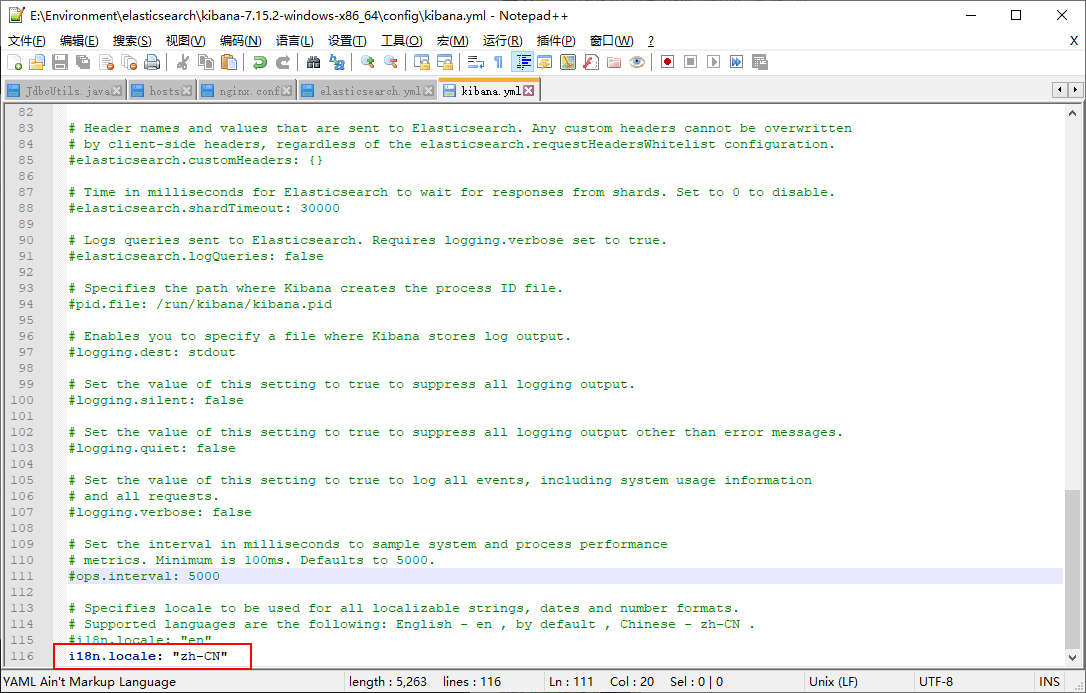
Restart Kibana
IK word breaker plug-in
1. Download address: https://github.com/medcl/elasticsearch-analysis-ik/releases
2. After downloading, put it into our elasticsearch plug-in!
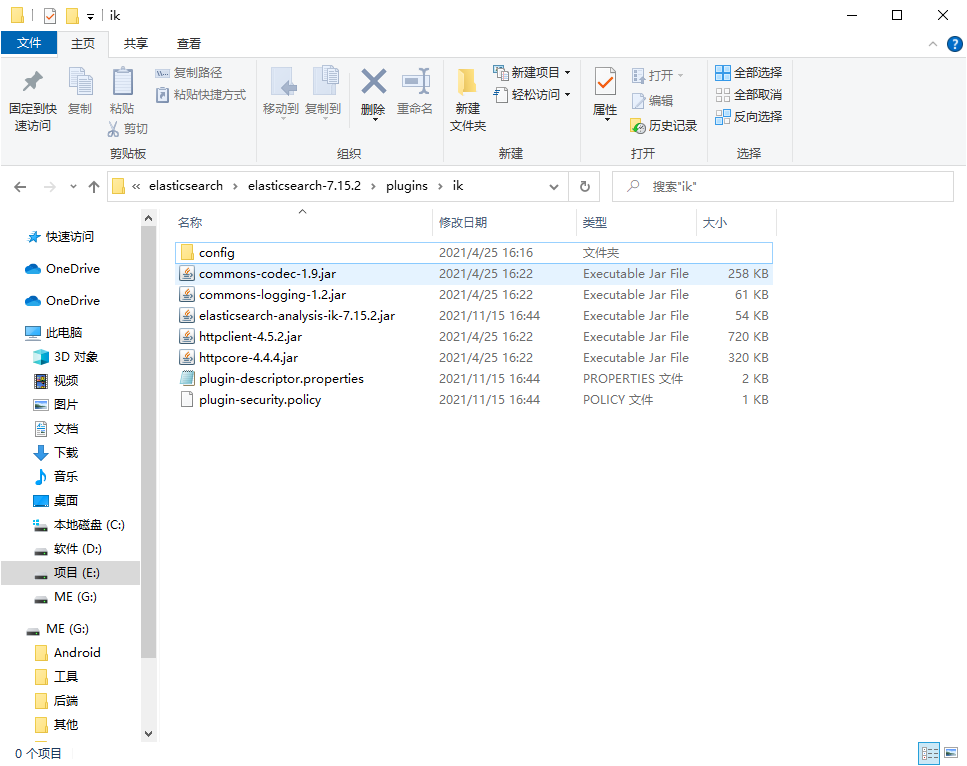
3. Restart the elastic search and you can see that the ik word breaker is loaded!

4. Elastic search plugin can use this command to view the recorded plug-ins

5. Test with kibana!
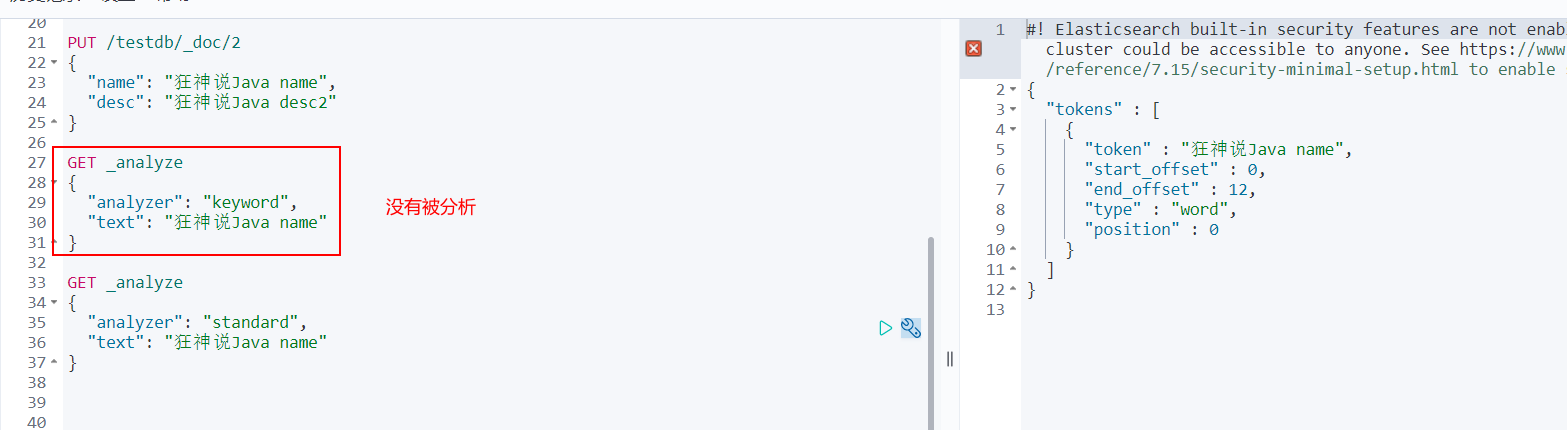
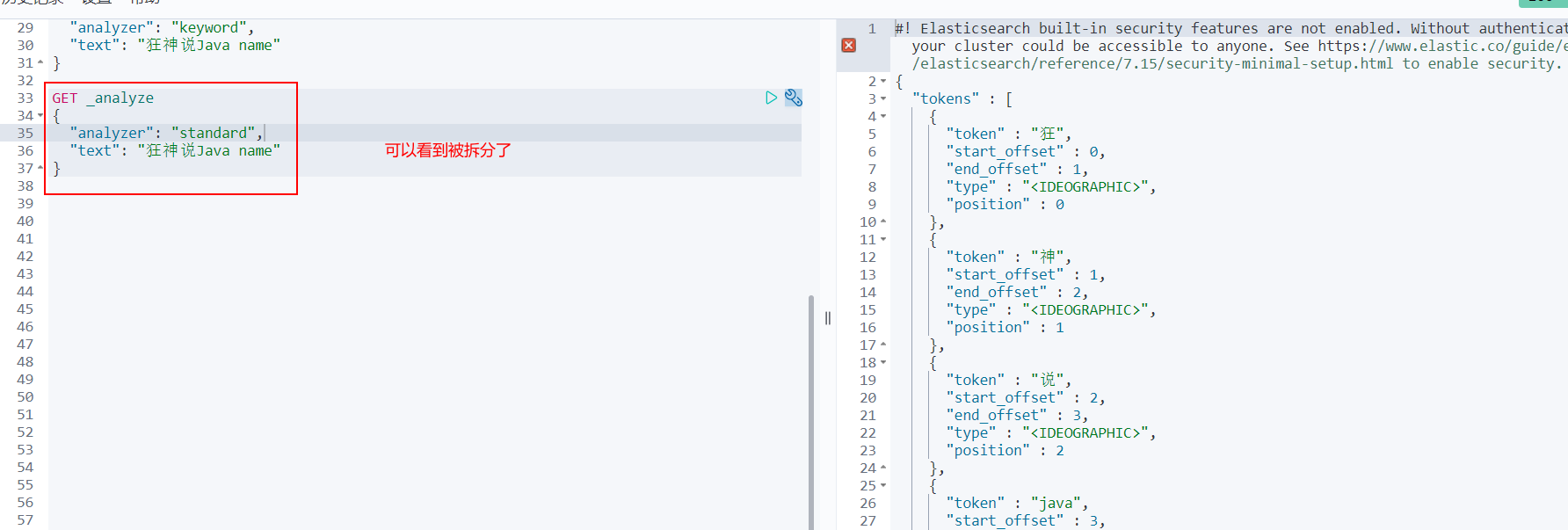
View different word segmentation effects
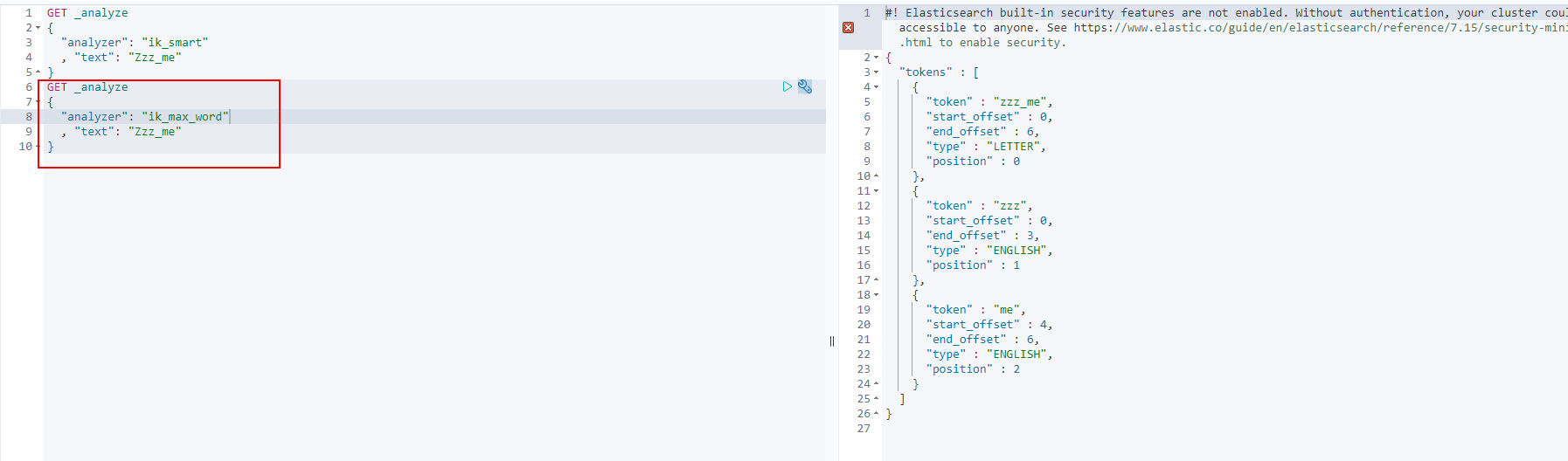
Where ik_smart is the least segmentation
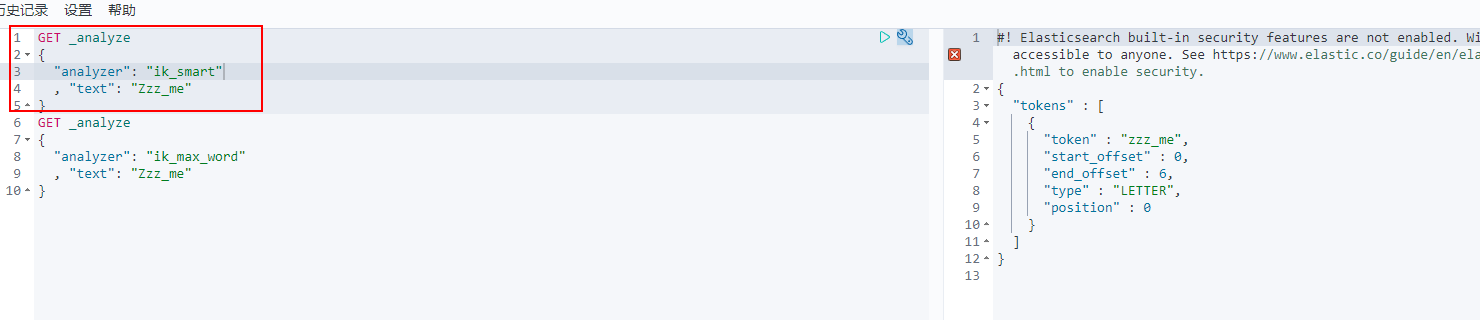
ik_max_word is the most fine-grained division! Exhaust the possibility of thesaurus! Dictionaries
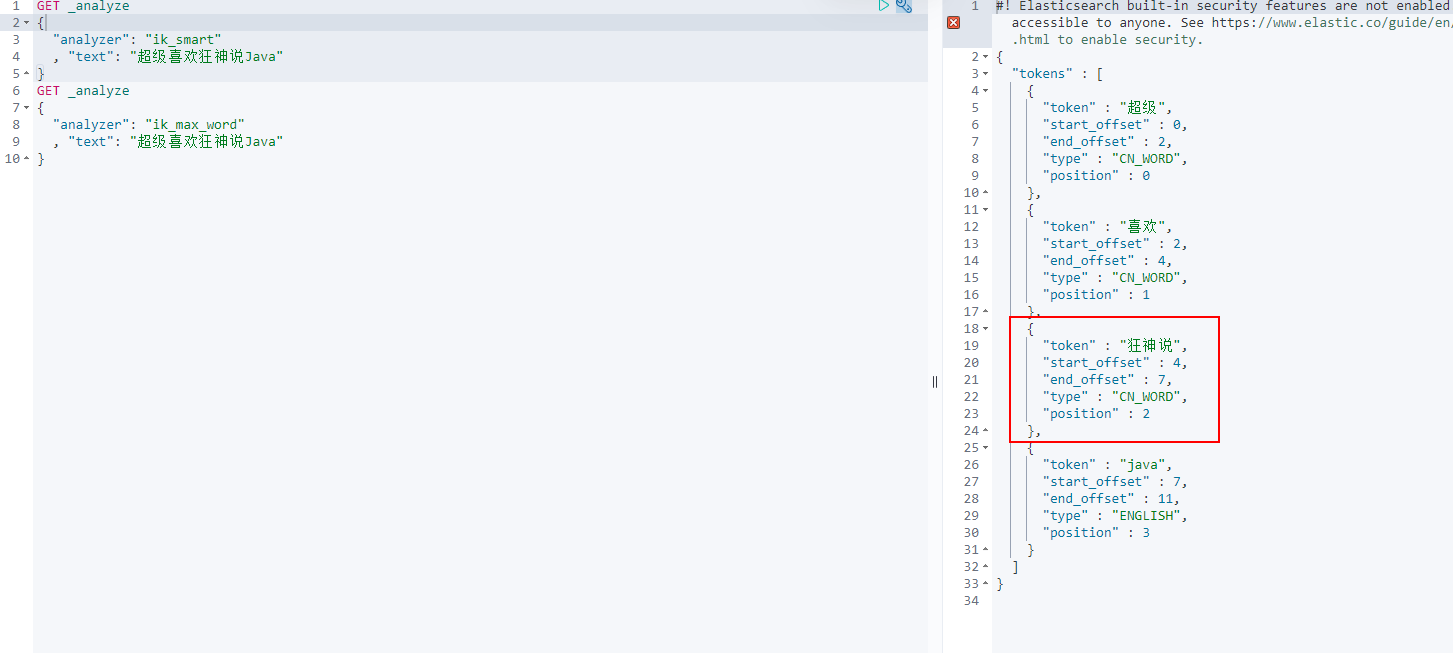
We like crazy God to say Java
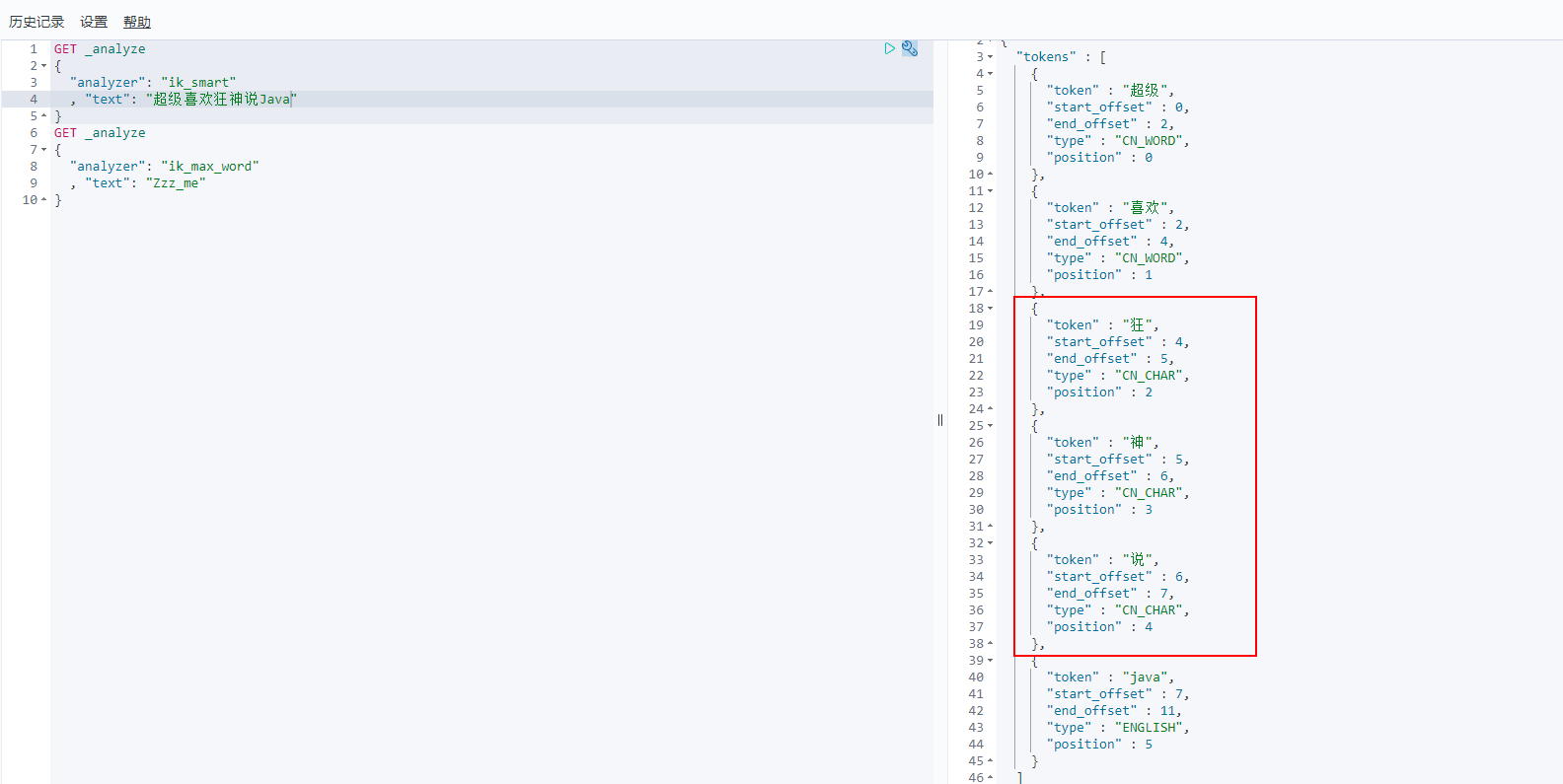
Discovery problem: the madness theory has been disassembled
This kind of word we need needs to be added to our word splitter's dictionary!
ik word splitter adds its own configuration!
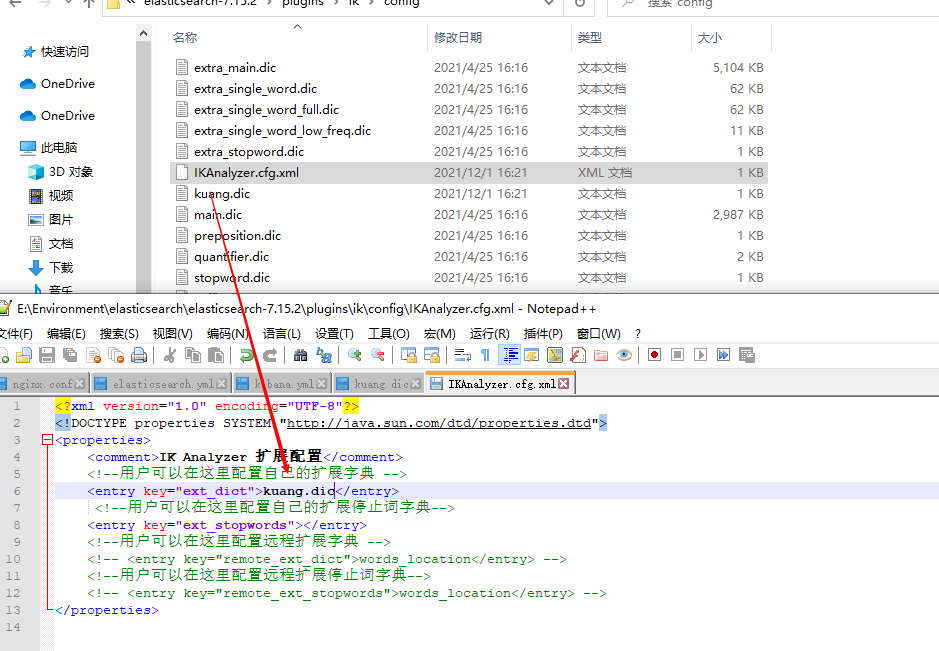
Restart elasticsearch

Test it again. The crazy God said, look at the effect!
When we need to configure word segmentation by ourselves, we can customize the dic file and configure it!
Rest style description
A software architecture style, not a standard, only provides a set of design principles and constraints. It is mainly used for the interaction between client and server. The software designed based on this style is more concise, more hierarchical, and easier to implement caching and other mechanisms.
| method | url address | describe |
|---|---|---|
| PUT | localhost:9200 / index name / type name / document id | Create document (specify document id) |
| POST | localhost:9200 / index name / type name | Create document (random document id) |
| POST | localhost:9200 / index name / type name / document id/_update | Modify document |
| DELETE | localhost:9200 / index name / type name / document id | Delete document id |
| GET | localhost:9200 / index name / type name / document id | Query document (by document id) |
| POST | localhost:9200 / index name / type name/_ search | Query all data |
Basic operation of index
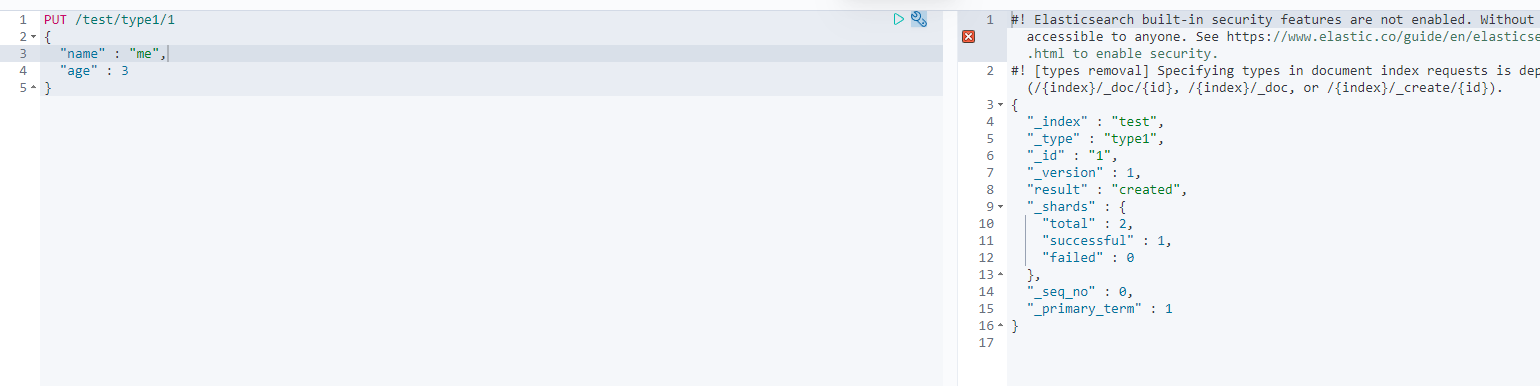
1. Create an index!
PUT /Index name/~Type name~/file id
{Request body}
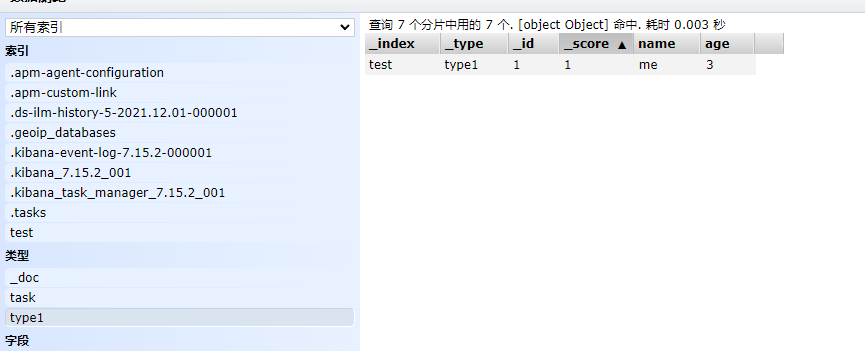
Finished automatically adding index! The data has also been successfully added!
3. Field type
- String type: text, keyword
- Value types: long, integer, short, byte, double, float, half float, scaled float
- date type: date
- te boolean type: Boolean
- Binary type: binary
Wait
4. Specifies the type of field
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
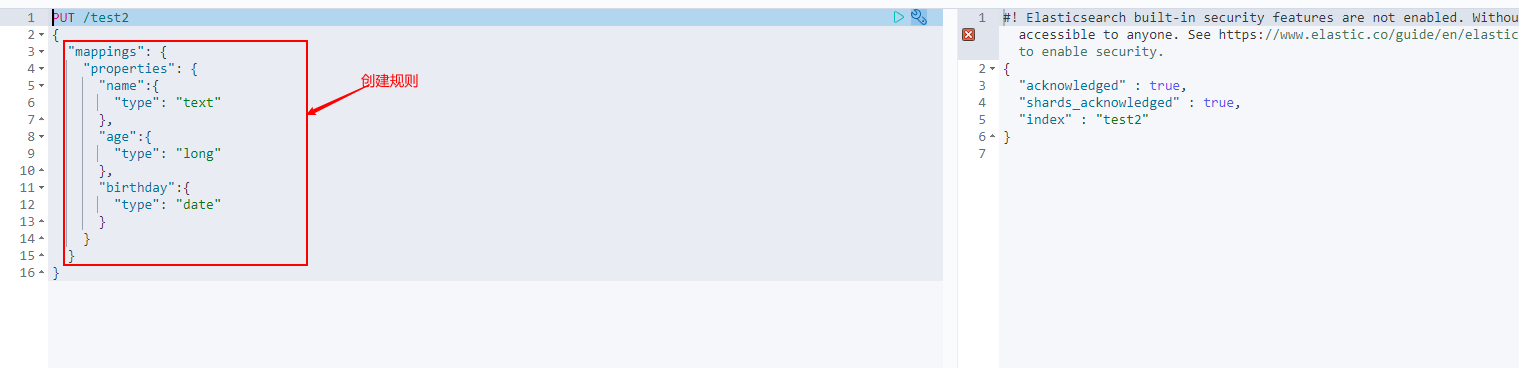
GET this rule! You can obtain specific information through GET request!
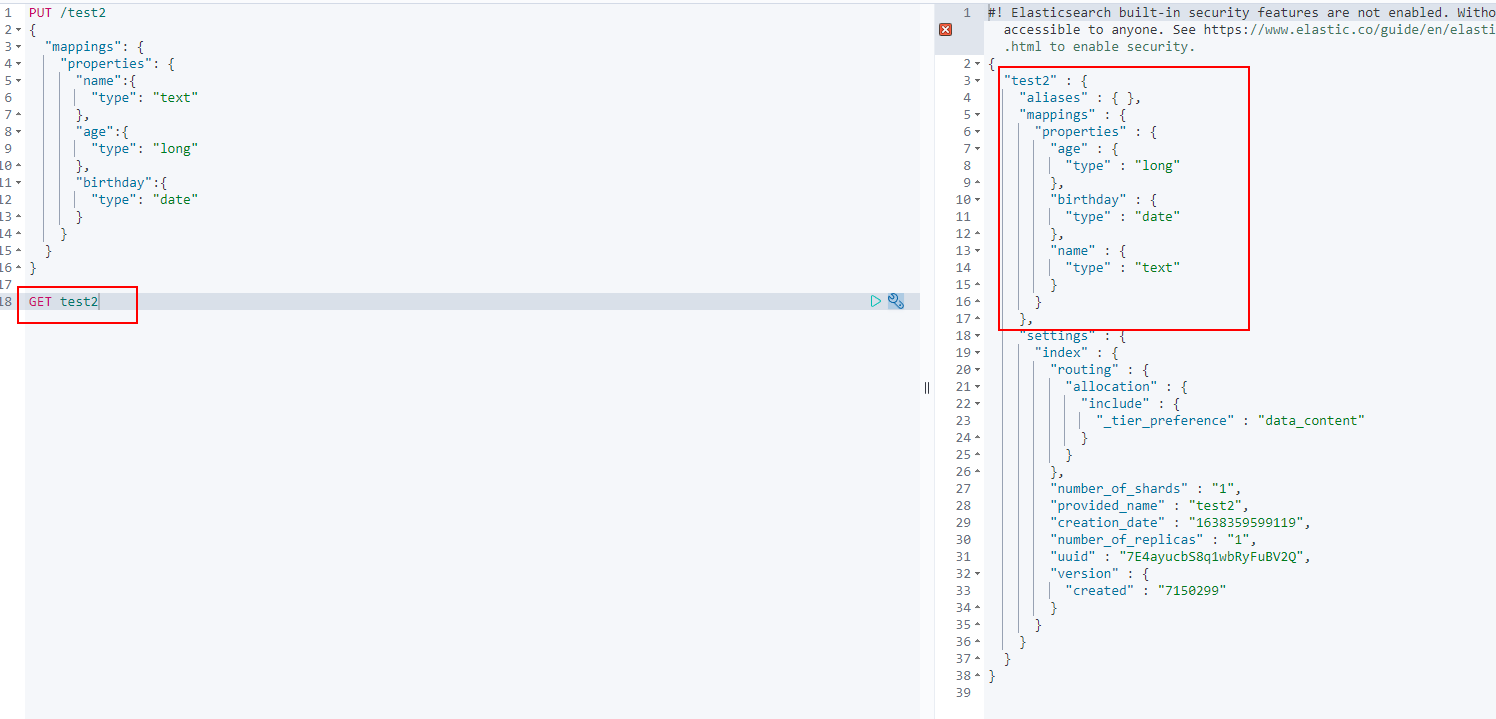
5. View default information!
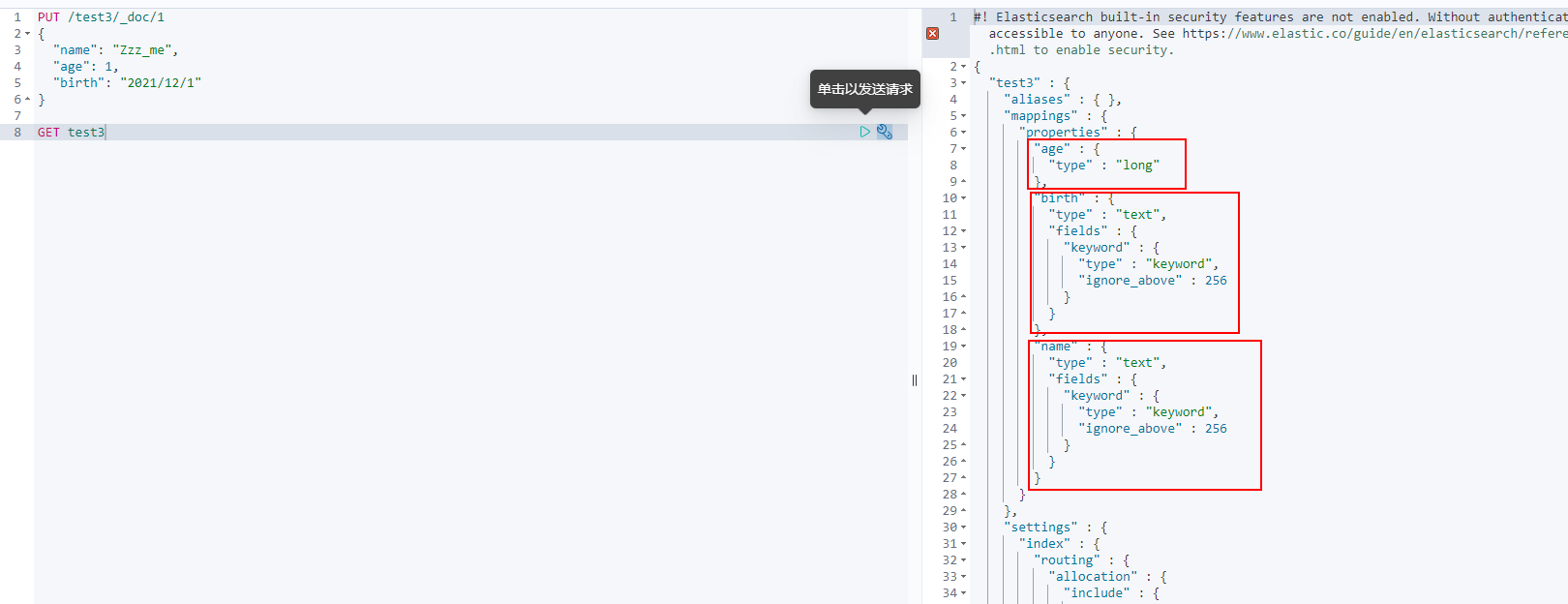
If your document field is not specified, elasticsearch will give me the default configuration field type!
Extension: use the command elasticsearch to index the situation! By get_ Cat can get a lot of current information about elasticsearch!
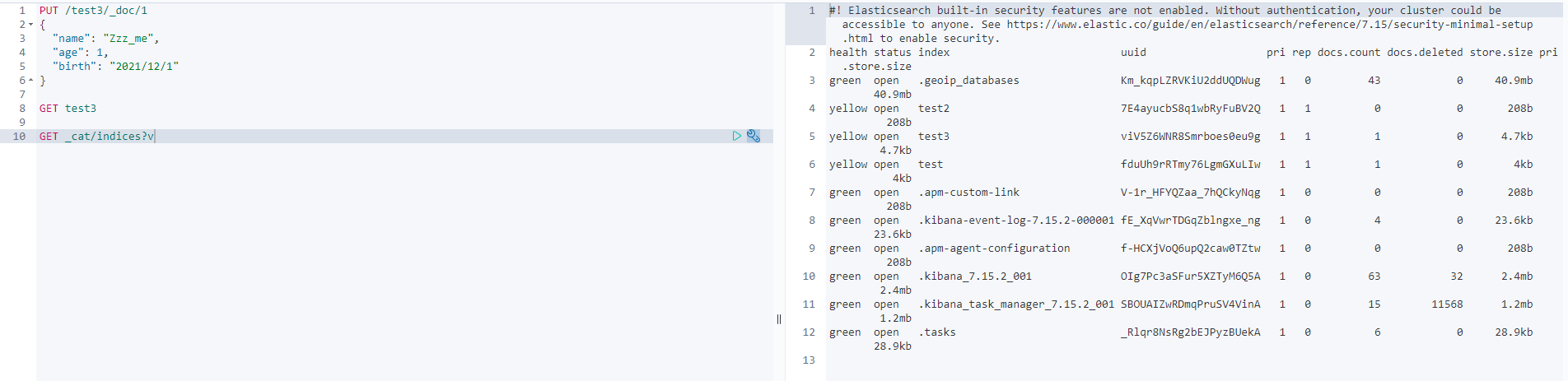
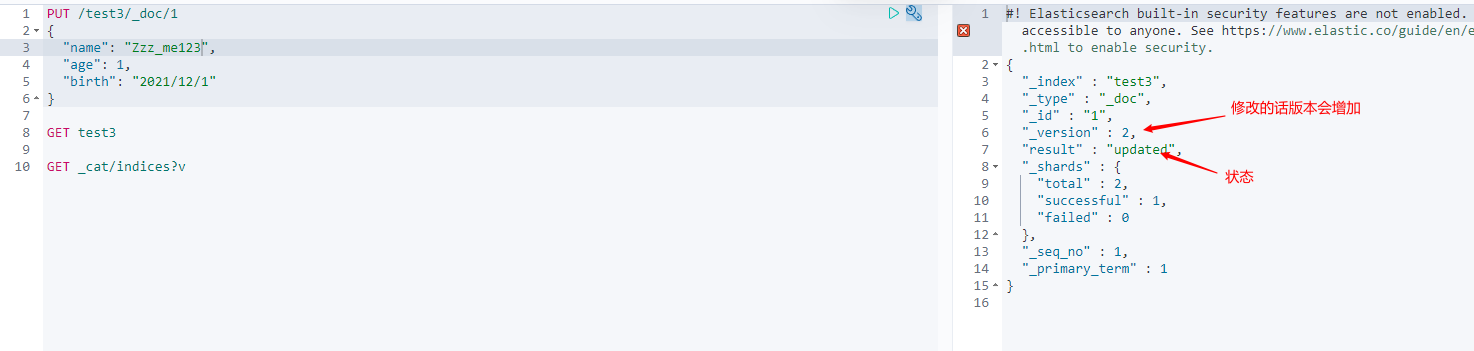
Modify the submission, use PUT to overwrite the value, or use POST to modify!
Method of using PUT overlay
How to modify using POST
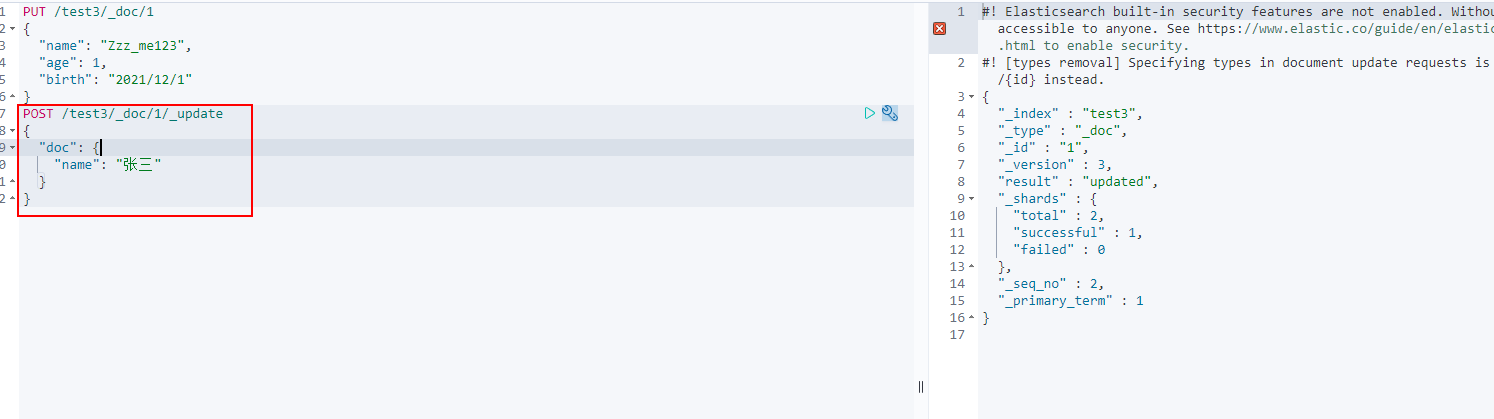
Delete index!

DELETE through the DELETE command. Judge whether to DELETE the document record or not according to your request!
#Delete index DELETE /Index name #Delete document record DELETE /Index name/Type name/file id
RESTFUL style is recommended by Elasticsearch!
Basic operation of documents (key points)
basic operation
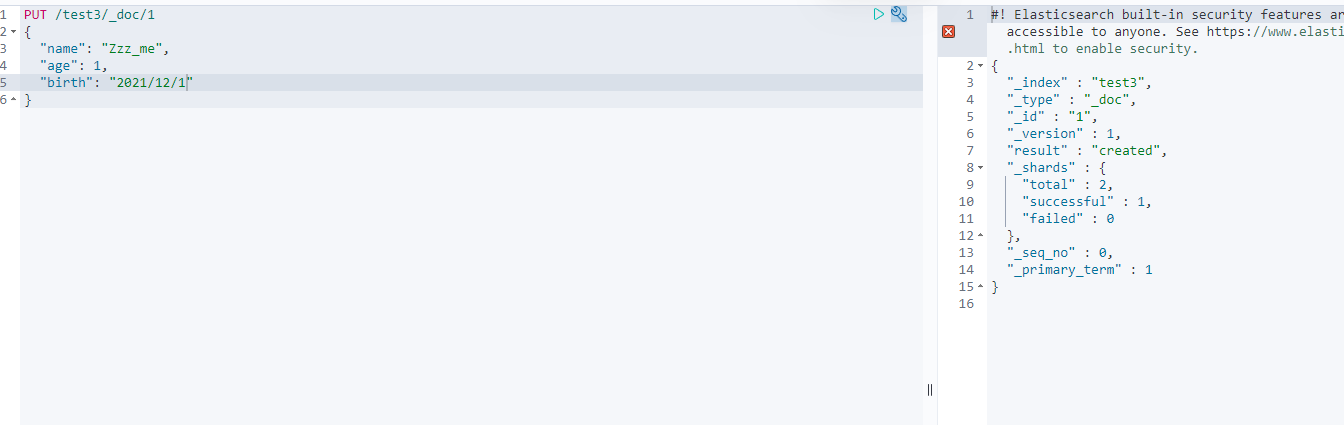
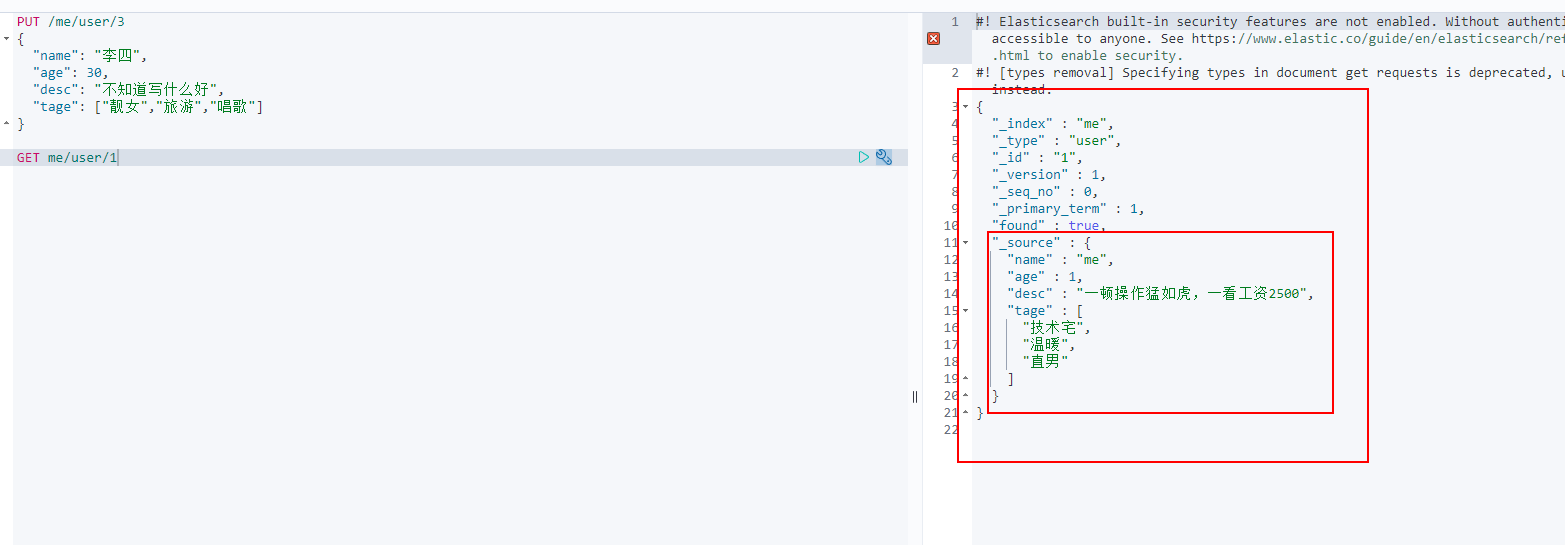
1. Add data
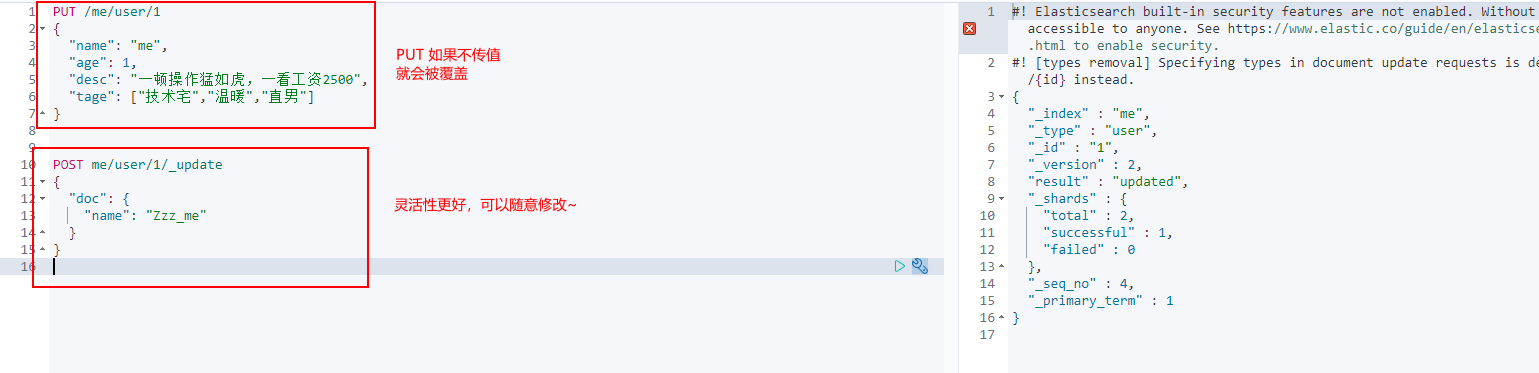
PUT /me/user/1
{
"name": "me",
"age": 1,
"desc": "A meal is as fierce as a tiger. At a glance, the salary is 2500",
"tage": ["technical nerd","warm","Straight man"]
}

2. GET data GET
3. Update data PUT
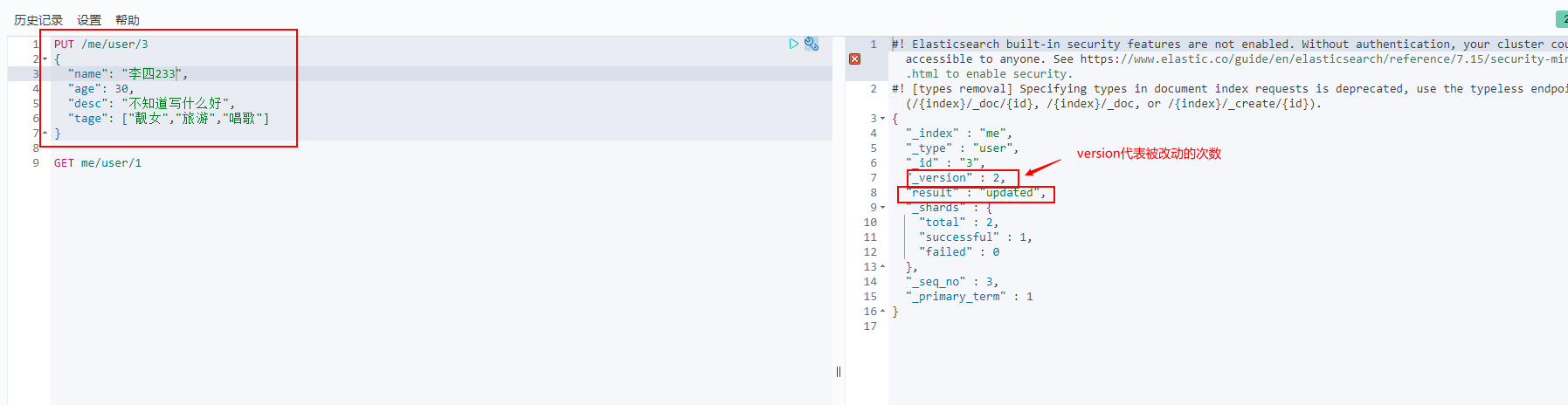
4,POST _update, this update method is recommended!
Simple search!
GET me/user/1
Simple condition query!
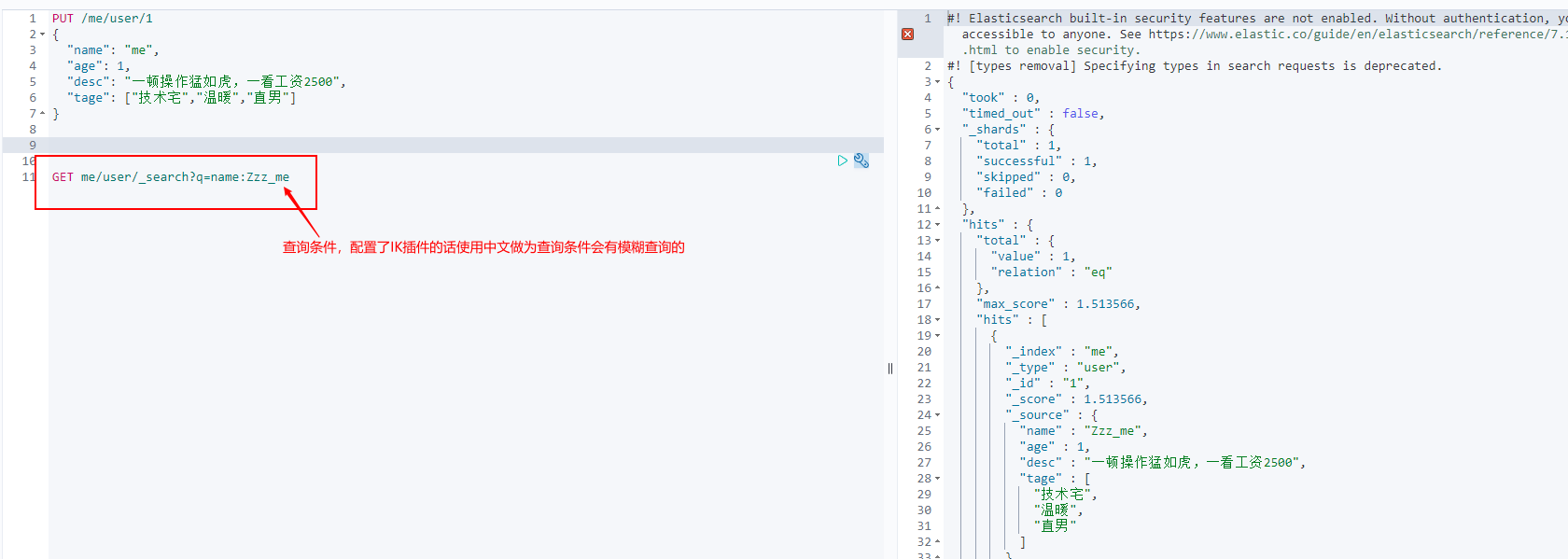
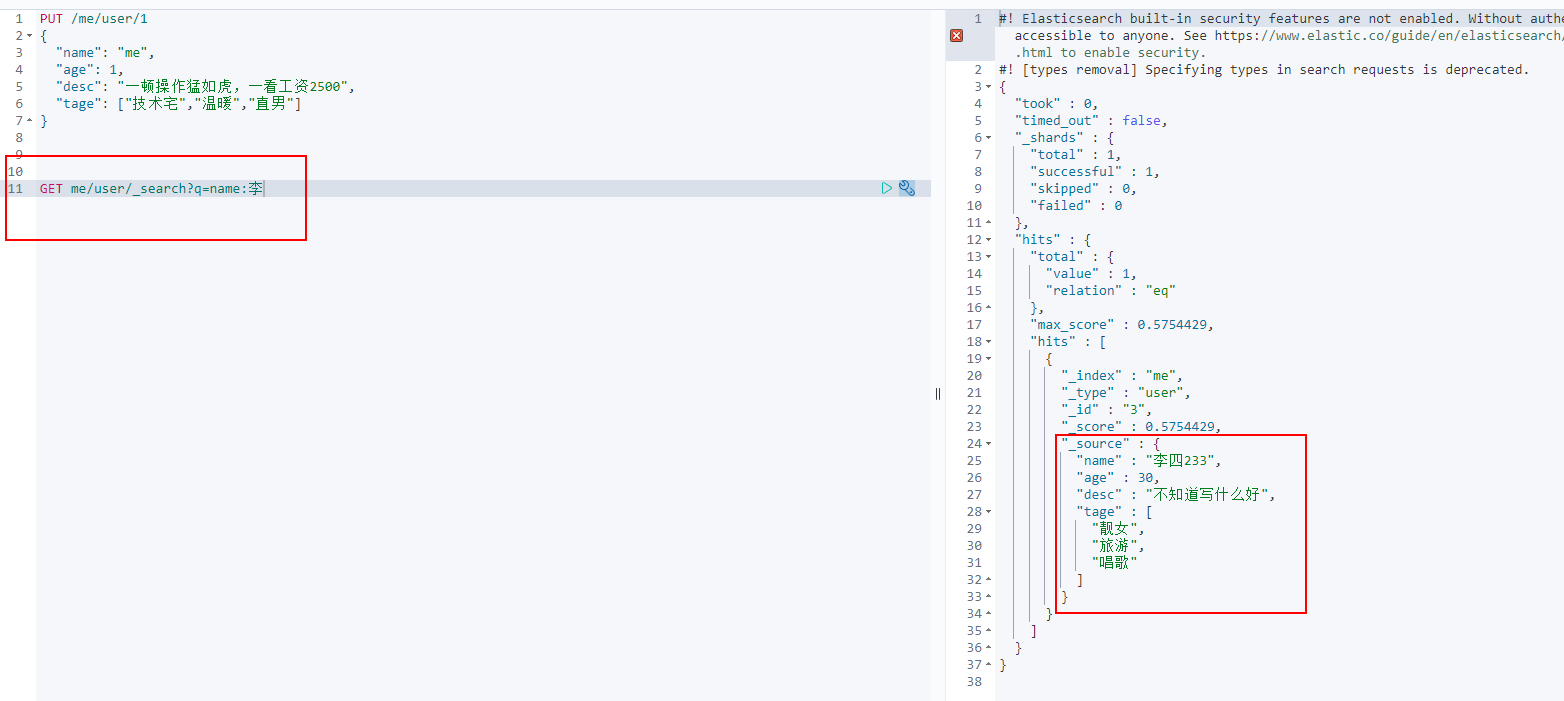
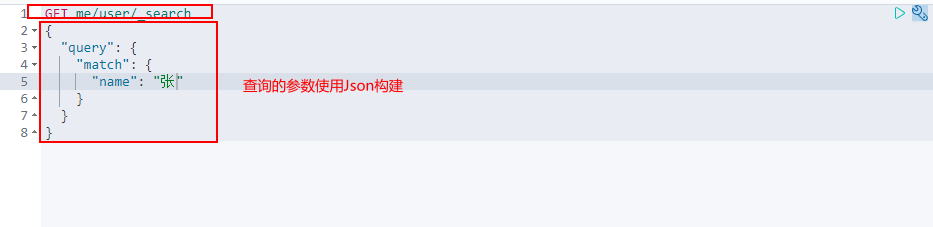
Complex operation search select (sorting, paging, highlighting, fuzzy query, accurate query!)
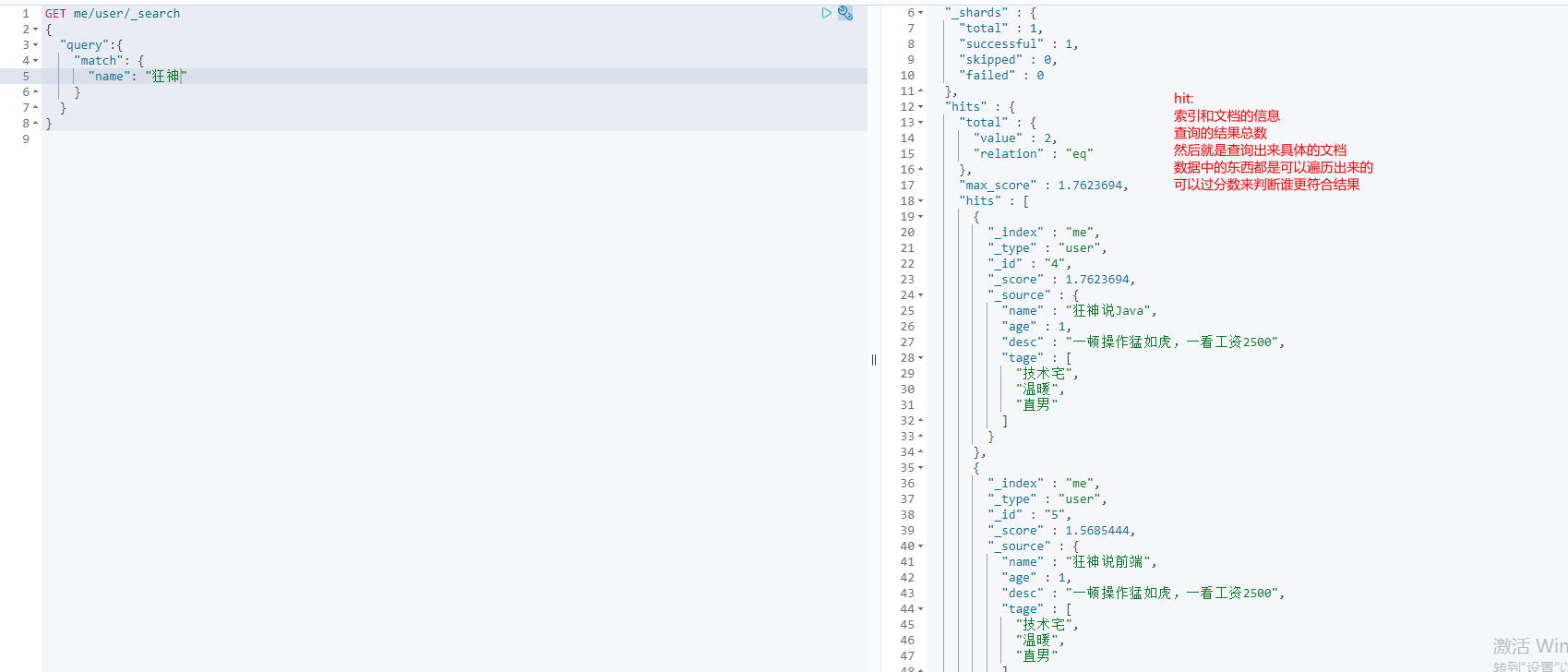
Output results, do not want so much!
GET me/user/_search
{
"query": {
"match_phrase": {
"name": "Mad God"
}
},
"_source": ["name","desc"]
}
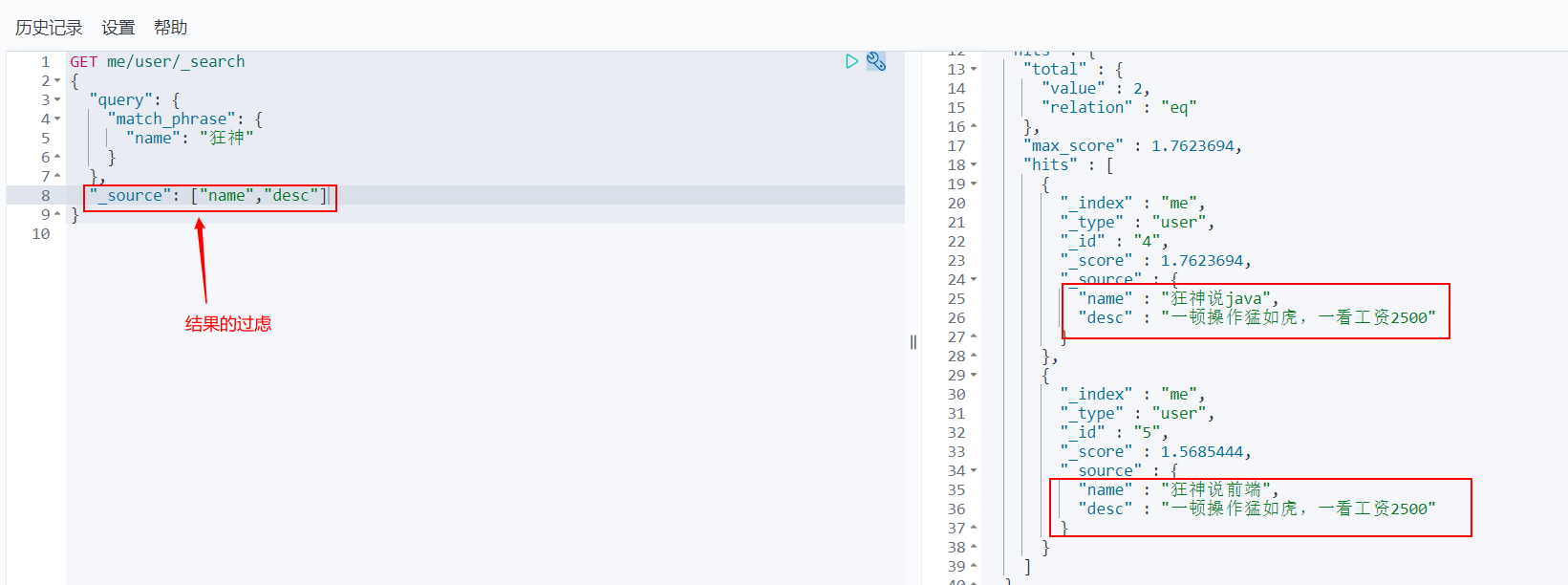
After that, we use Java to operate ElasticSearch. All methods and objects are key s in it!
sort
- asc: descending order
- desc: ascending order
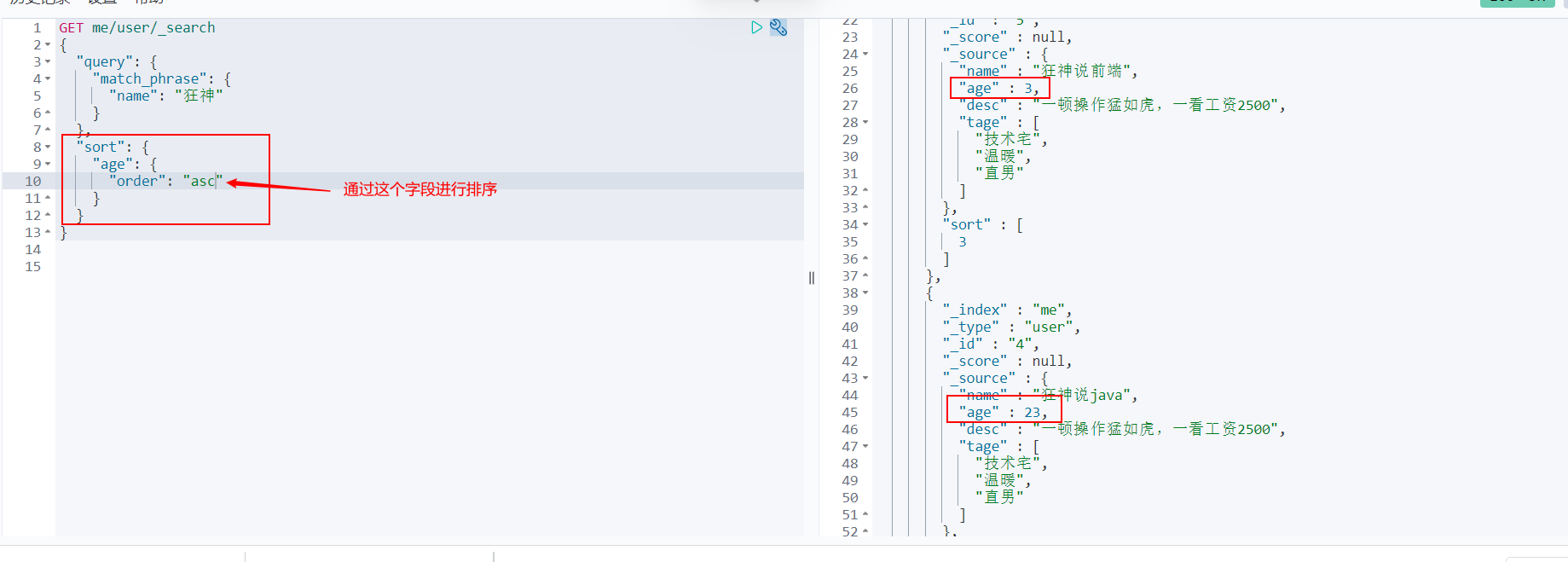
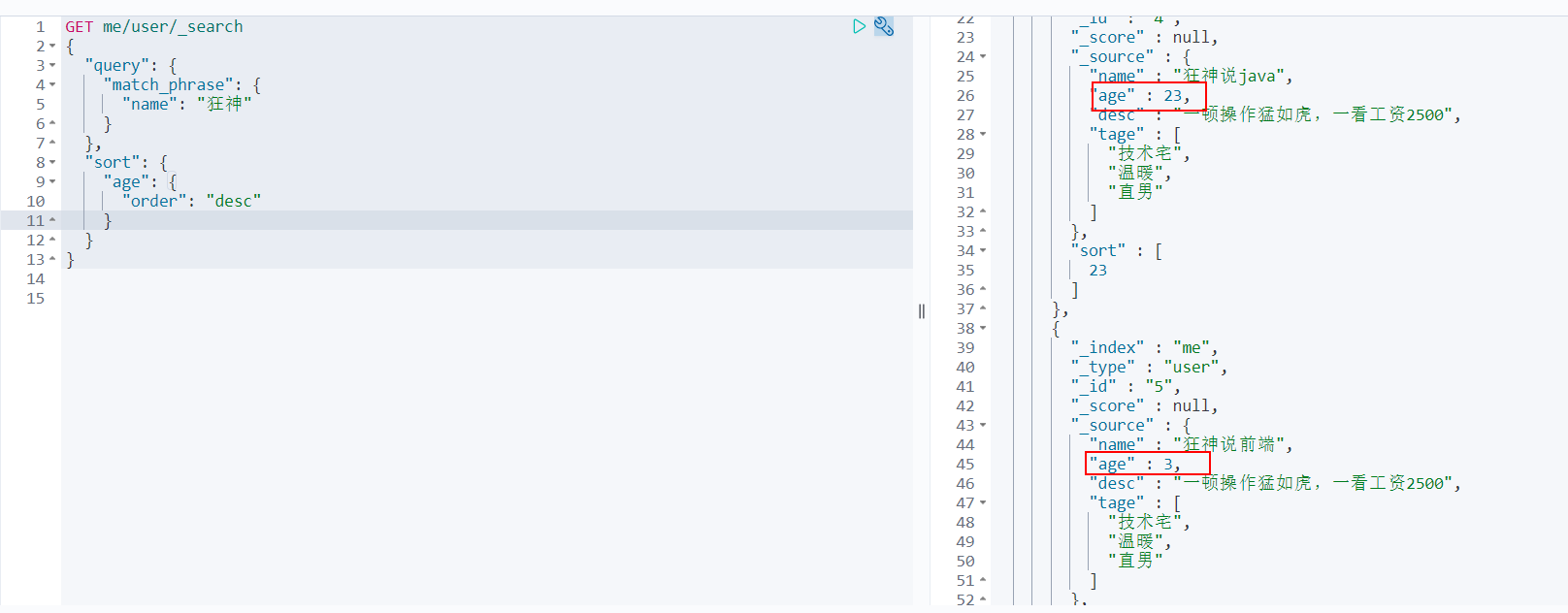
Paging query
"from": Start with the number of data "size": How many data (single page data) are returned
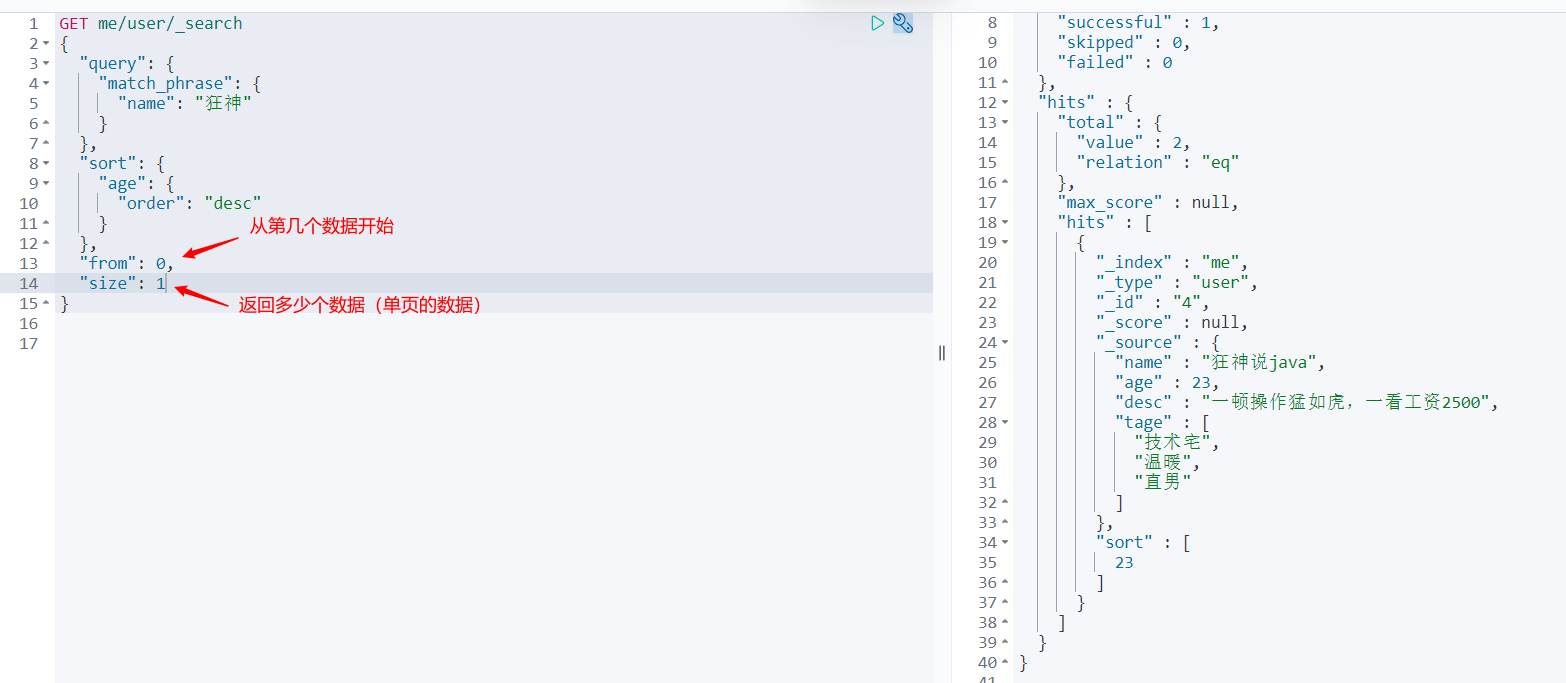
The data subscript starts from 0, which is the same as all the data structures learned!!!
/search/{current}/{pagesize}
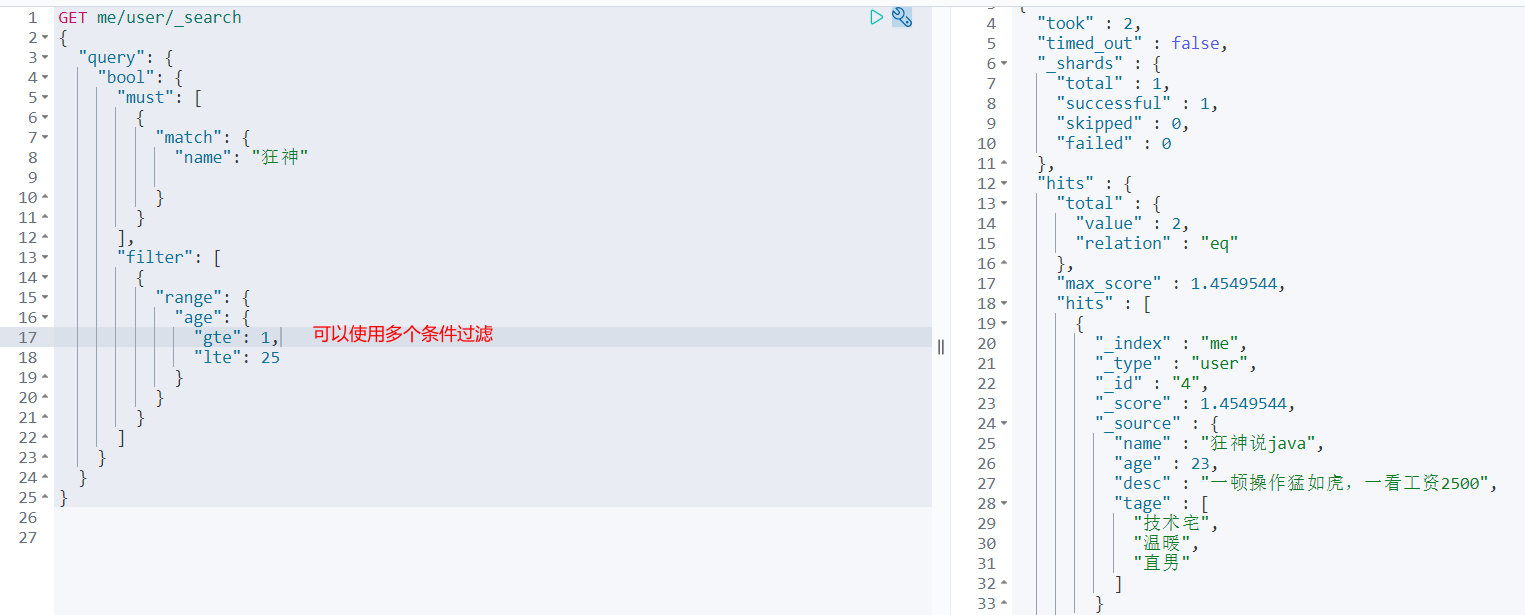
Boolean query
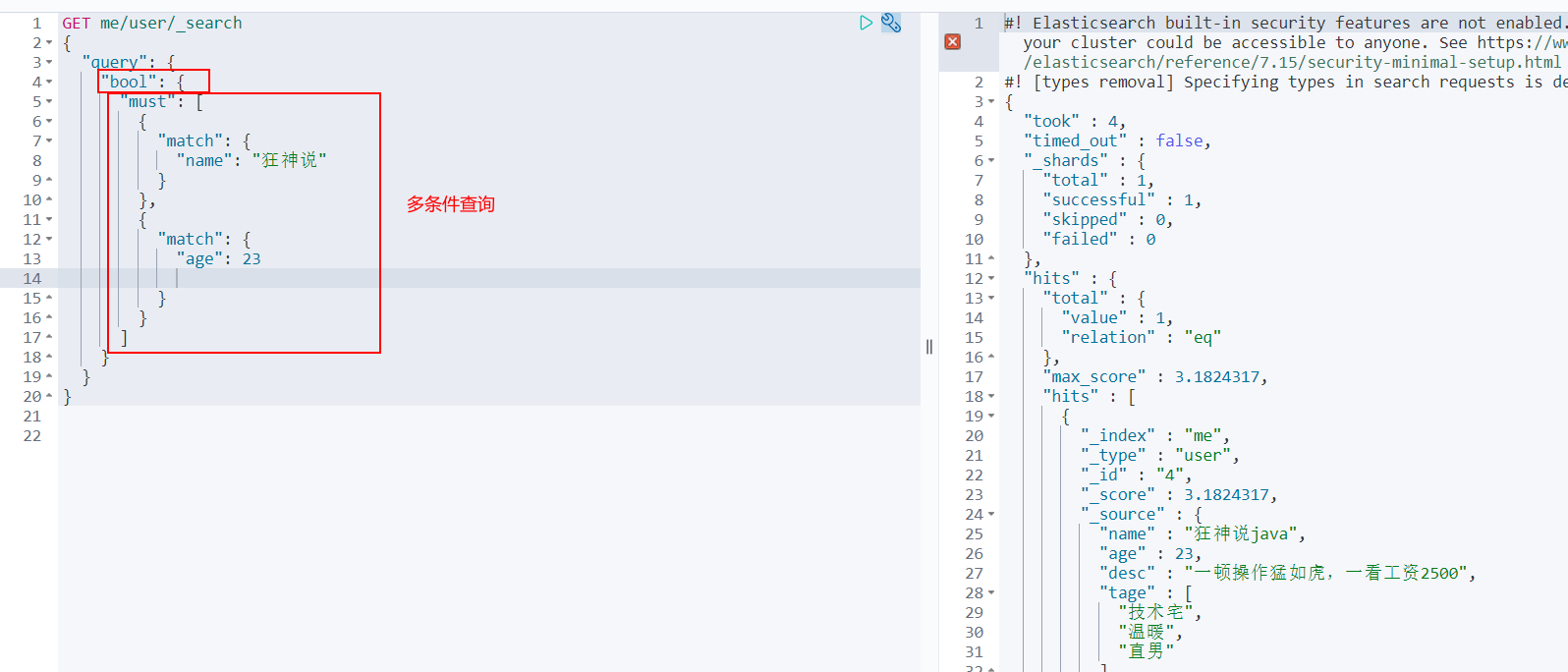
GET me/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Madness theory"
}
},
{
"match": {
"age": 23
}
}
]
}
}
}
Must (and), all conditions must be met, such as where id = 1 and name = xxx in Sql statement
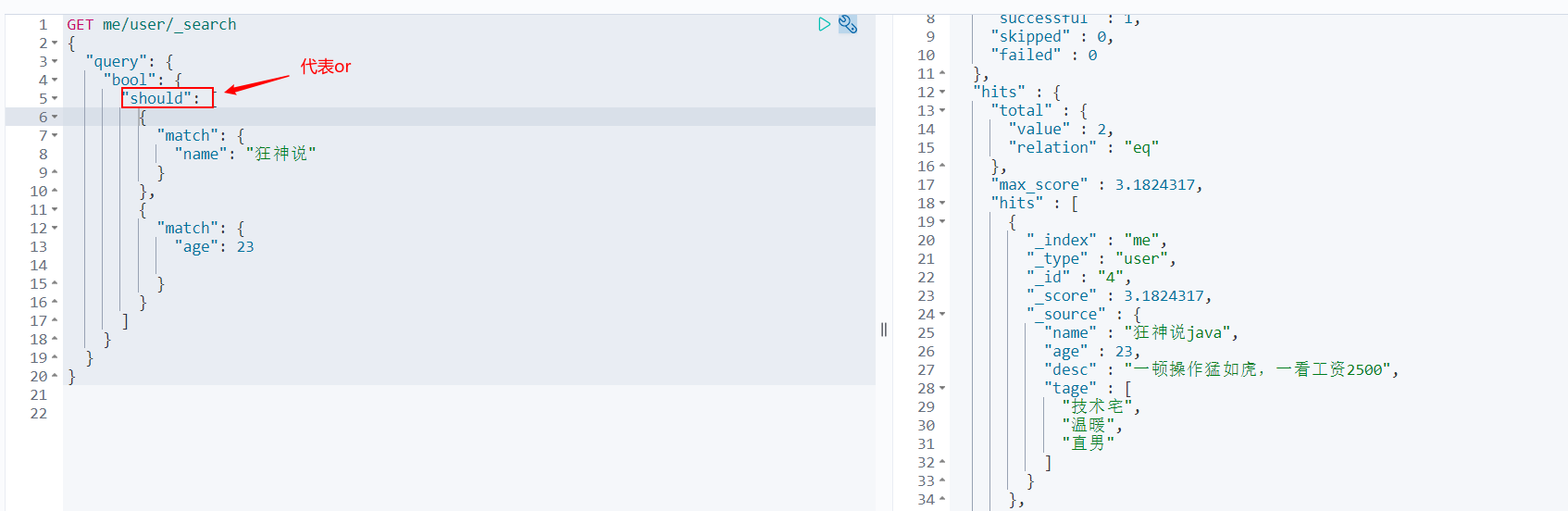
should (or), all conditions must be met, such as where id = 1 or name = xxx in Sql statement
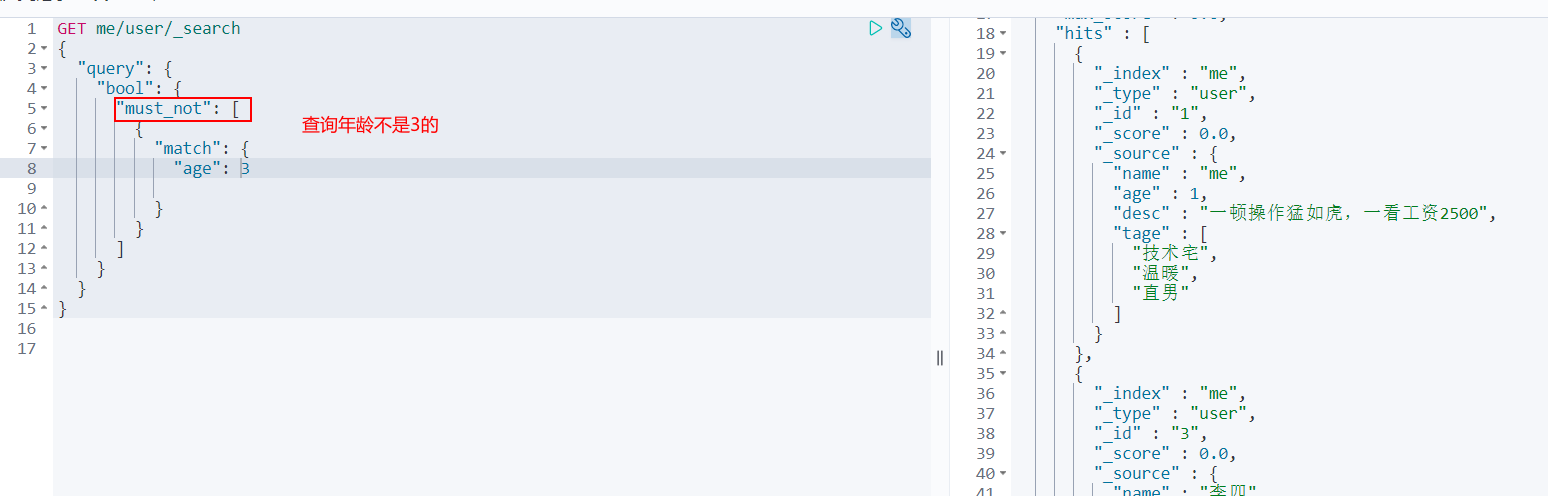
must_not (not)
filter
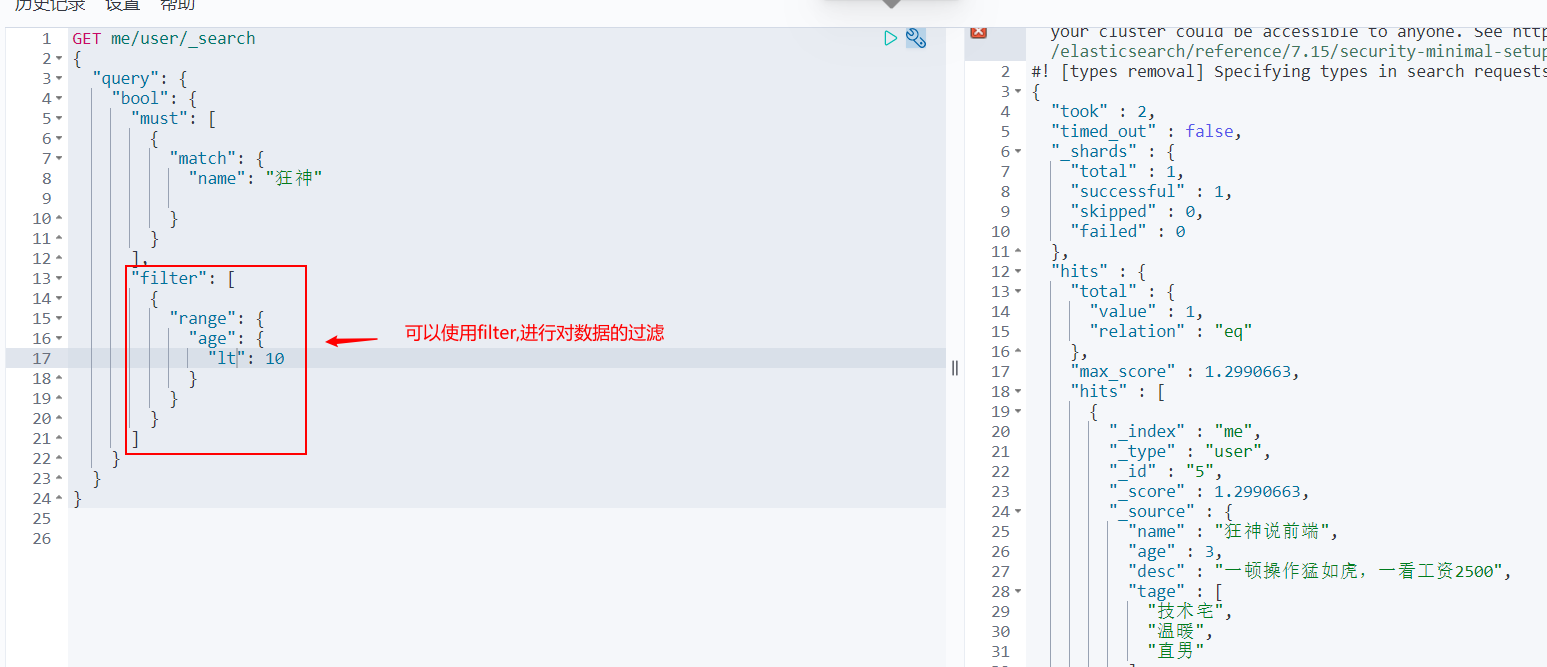
- gt greater than
- gte is greater than or equal to
- lt less than
- lte less than or equal to
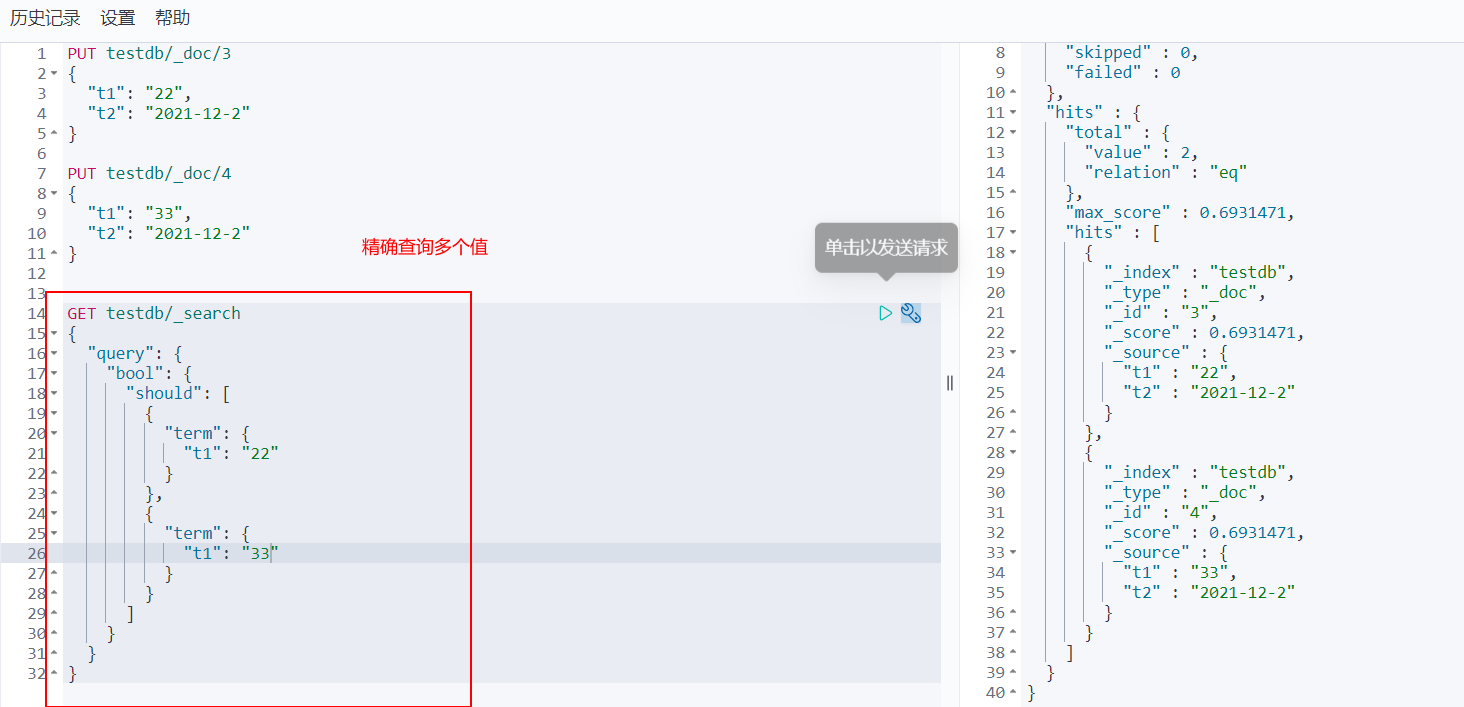
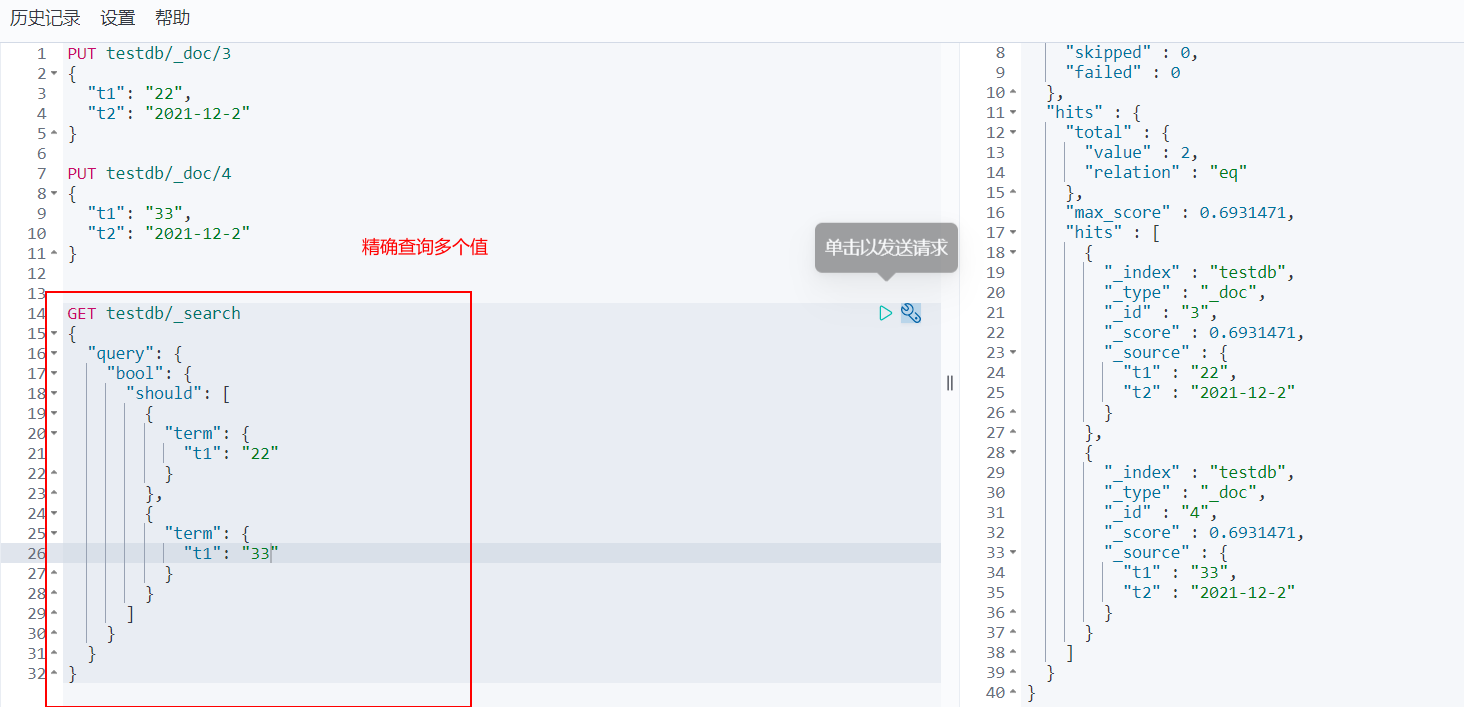
Match multiple criteria
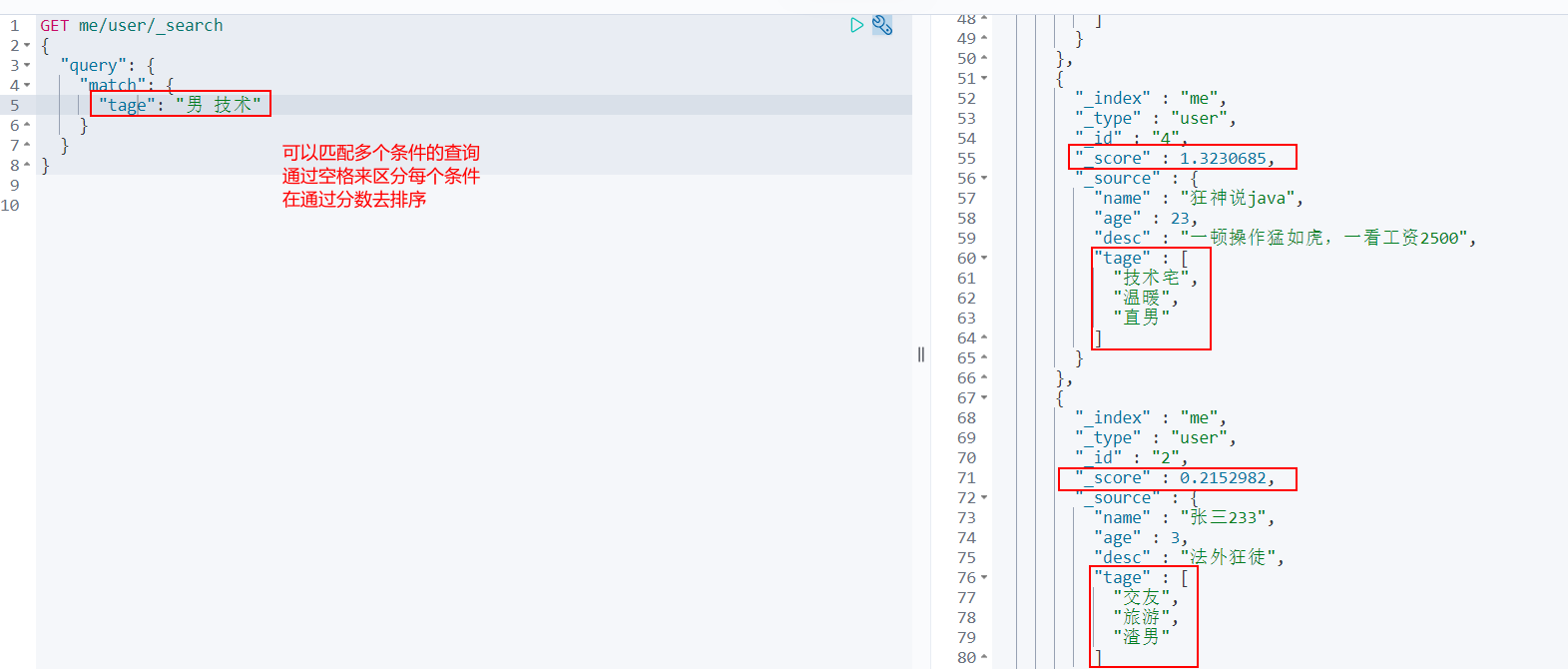
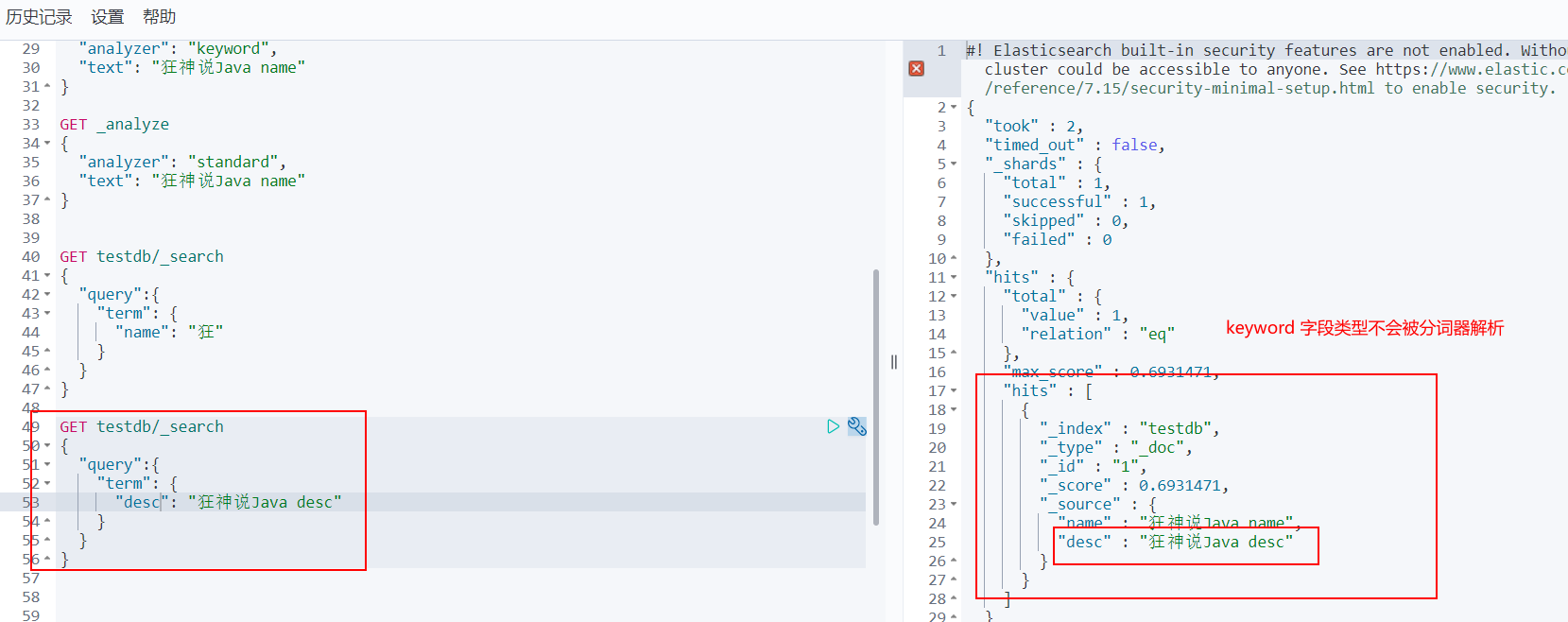
Precise query
Term query is directly through the term entry process specified by the inverted index to find accurately!
About participle:
- term, direct query, accurate
- match, will use the word splitter to parse! (first analyze the document, and then query through the analyzed document!)
Two types of text keyword
Exact query of multiple value matching
Highlight query
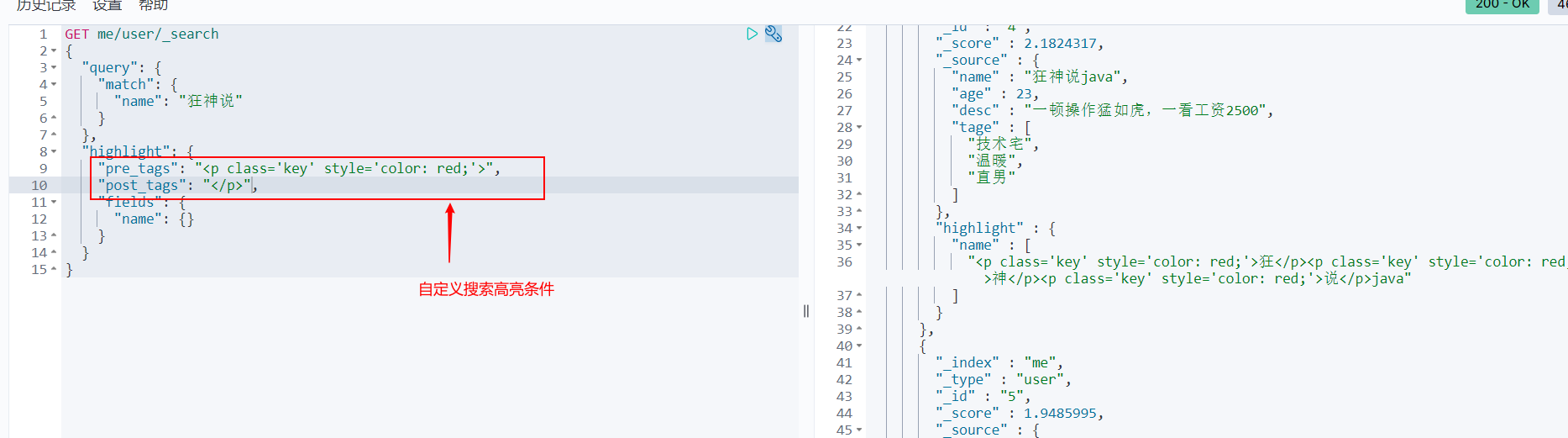
In fact, these MySQL pages can be done, but MySQL efficiency is relatively low!
- matching
- Match by criteria
- Exact match
- Interval range matching
- Matching field filtering
- Multi condition query
- Highlight query
Integrated SpringBoot
Find official documents
1. Find native dependencies
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.15.2</version>
</dependency>
2. Find object
3. Analyze the methods in this class!
Configure basic items
Make sure that the dependencies we import are consistent with our es version
The SpringBoot version I use is 2.6.1 and the elasticsearch version is 7.15.2
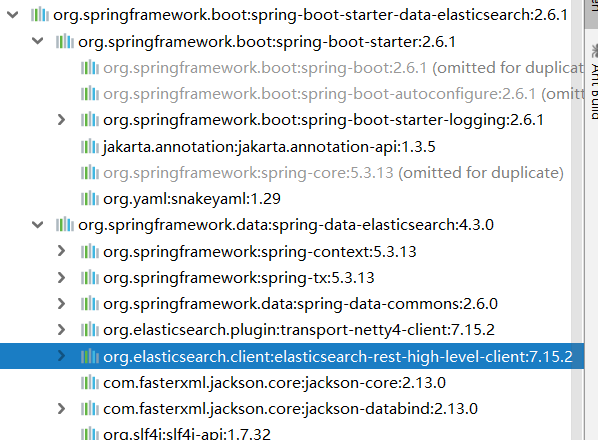
If the version is inconsistent, you need to customize the version to make it consistent with the ElasticSearch version
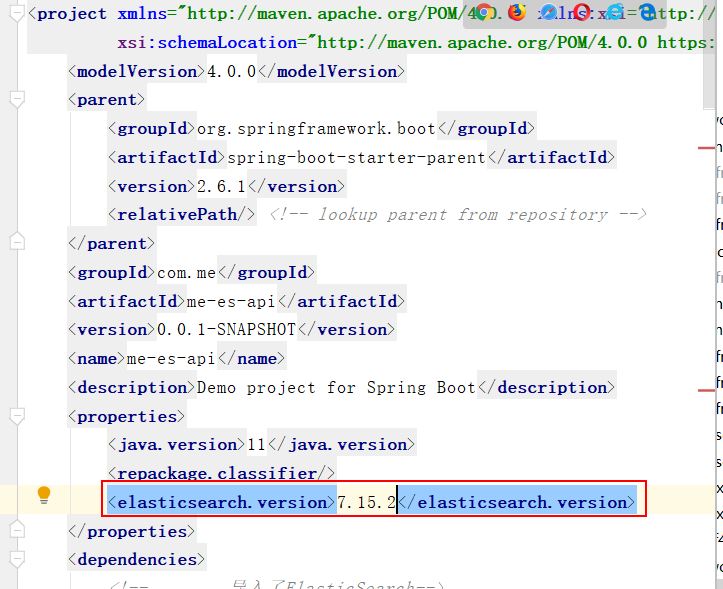
Configure a Config
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
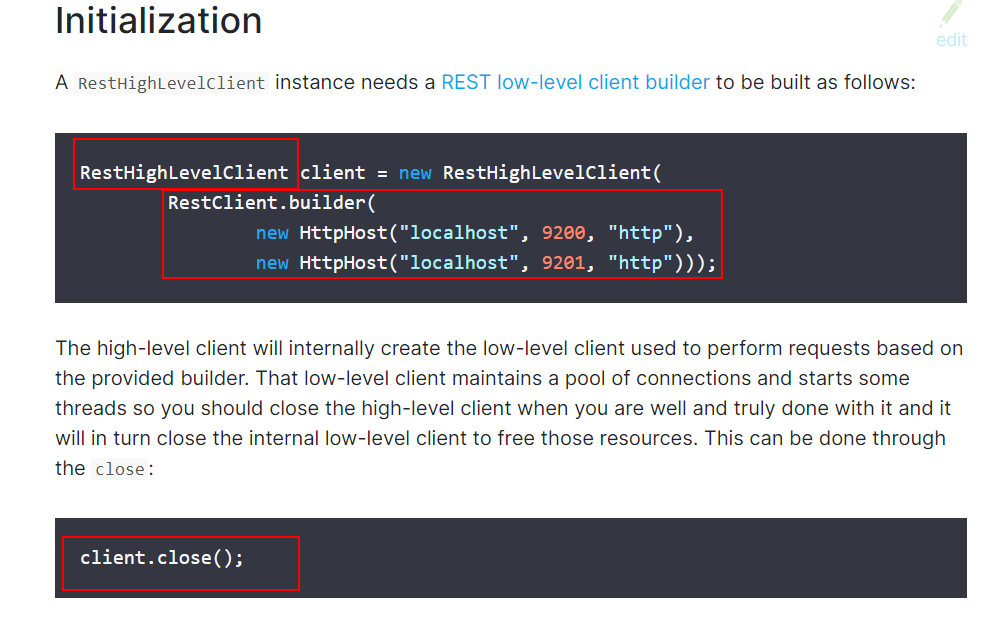
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
// IP port protocol
new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
// You can configure multiple or a single ElasticSearch
// Official configuration code
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
Official configuration code address: https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started-initialization.html
Specific API testing
1. Create index
2. Determine whether the index exists
3. Delete index
4. Create document
5. Operation document
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
// Test index creation
@Test
void testCreateIndex() throws IOException {
// 1. Create index request
CreateIndexRequest request = new CreateIndexRequest("me_index");
// 2. The client executes the request IndicesClient and gets a response after the request
CreateIndexResponse createIndexResponse =
client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
// Test to obtain the index and determine whether it exists
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("me_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
// Test delete index
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("me_index");
// delete
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
// Test add document
@Test
void testAddDocument() throws IOException {
// create object
User user = new User("Madness theory", 3);
// Create Pro request
IndexRequest request = new IndexRequest("me_index");
// Rule PUT /me_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
// Put our data into the request json
request.source(JSON.toJSONString(user), XContentType.JSON);
// The client sends the request and obtains the response result
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
System.out.println(index);
System.out.println(index.status());
}
// Get the document and judge whether it exists
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("me_index", "1");
// Do not get returned_ source context
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
// Get information about the document
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("me_index", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString()); // Print the contents of the document
System.out.println(getResponse); // Everything returned is the same as the command
}
// Update document information
@Test
void testUpdateRequest() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("me_index", "1");
updateRequest.timeout("1s");
User user = new User("Madness theory Java", 18);
updateRequest.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
// Delete document record
@Test
void testDeleteRequest() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("me_index", "1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
// Batch insert data!
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("me1", 1));
userList.add(new User("me2", 1));
userList.add(new User("me3", 1));
userList.add(new User("kuangshen1", 3));
userList.add(new User("kuangshen2", 3));
userList.add(new User("kuangshen3", 3));
// Batch request
for (int i = 0; i < userList.size(); i++) {
// For batch update and batch deletion, you can modify the corresponding request here
bulkRequest.add(new IndexRequest("me_index")
.id("" + (i + 1))
.source(JSON.toJSONString(userList.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures()); // Whether it failed or not. If false is returned, it means success!
}
// query
// SearchRequest search request
// SearchSourceBuilder condition construction
// HighlightBuilder build highlights
// TermQueryBuilder exact query
// MatchAllQueryBuilder
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("me_index");
// Build search criteria
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Query criteria can be implemented using the QueryBuilders tool
// QueryBuilders.termQuery
// QueryBuilders.matchAllQuery matches all
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("naem", "me1");
//MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("=================");
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
actual combat
Make sure ElasticSearch remains on
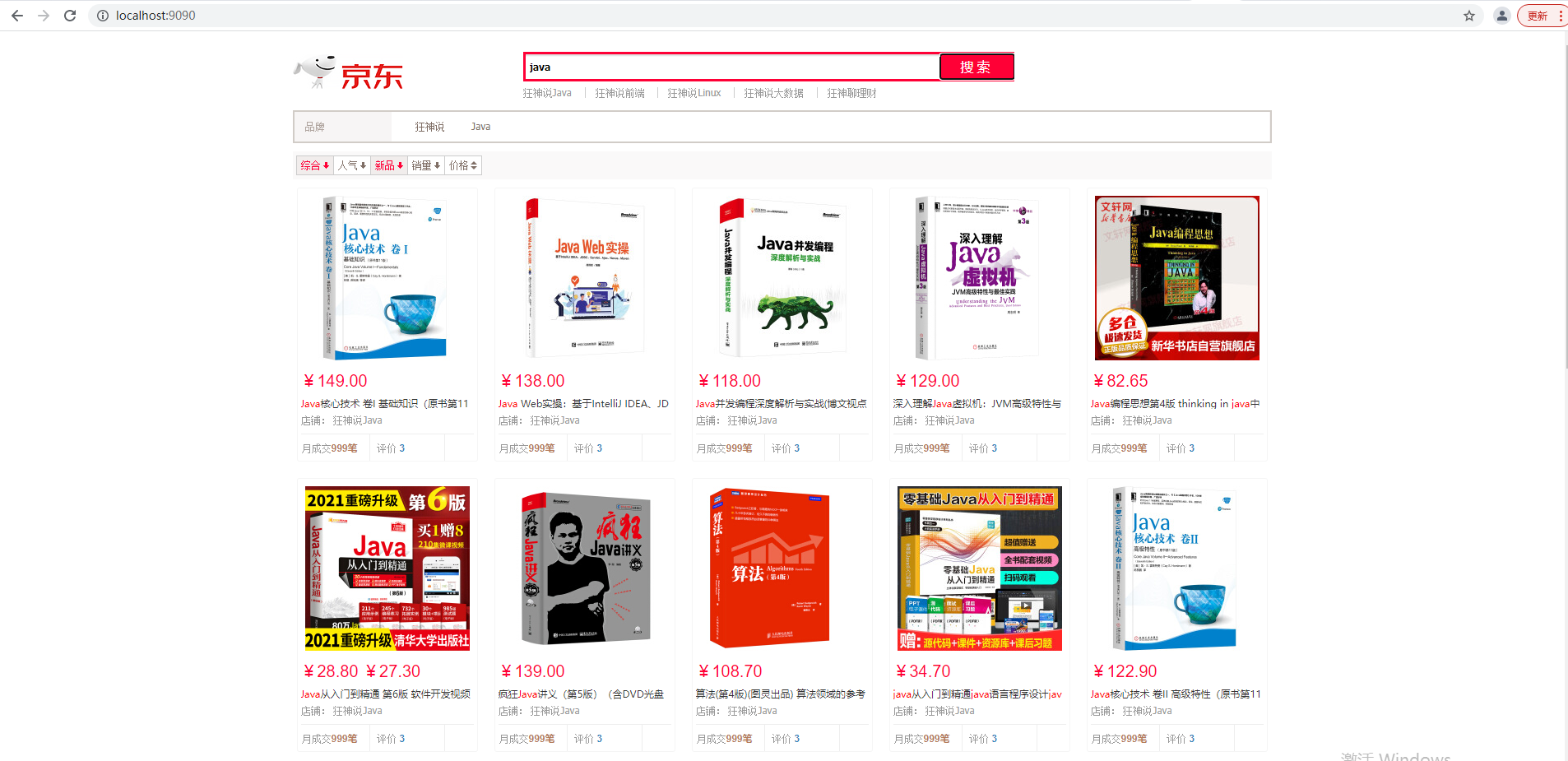
Final effect
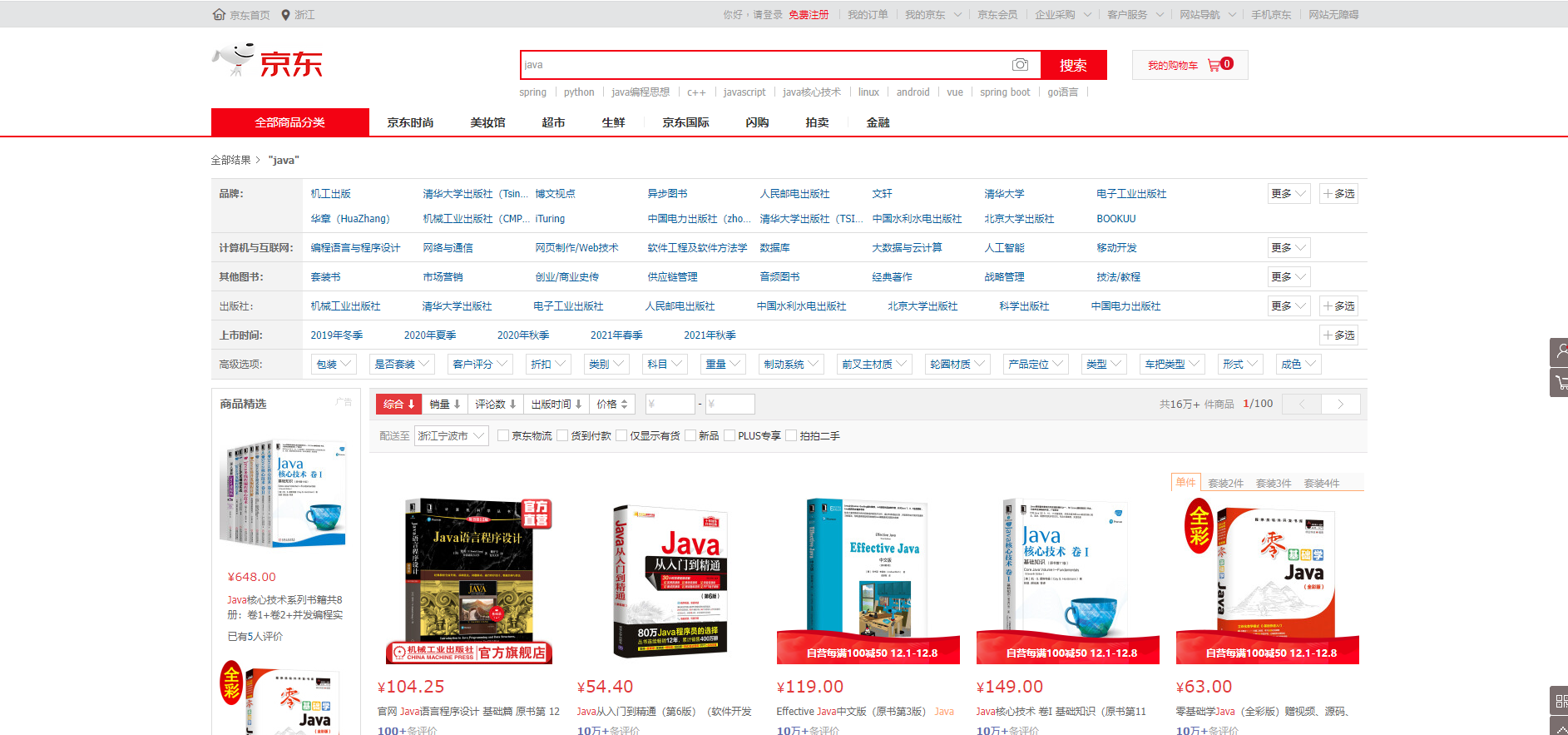
Create a new project
Reptile
Data problems? Database acquisition and message queue acquisition can become data sources and crawlers!
Crawling data: (get the page information returned by the request and filter out the data we want!)
jsoup package
<!--jSoup Parsing web pages-->
<!--Parsing web pages jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
// Get request https://search.jd.com/Search?keyword=java
// Premise: networking is required!
String url = "https://search.jd.com/Search?keyword=java";
// Parse web pages. (the document returned by jsup is the document object of the browser)
Document document = Jsoup.parse(new URL(url), 30000);
// All the methods you can use in js can be used here!
Element element = document.getElementById("J_goodsList");
// Get all lj elements
Elements elements = element.getElementsByTag("li");
// Get the content in the element. Here el is each li tag!
for (Element el : elements) {
// For websites with a lot of pictures, all pictures are loaded late!
// data-lazy-img
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
System.out.println("===================");
System.out.println(img);
System.out.println(price);
System.out.println(title);
}
Front and rear end separation
Search highlight
Finish backend effect
pojo class code
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {
private String title;
private String img;
private String price;
// You can add attributes yourself!
}
code
Tool class code
@Component
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
new HtmlParseUtil().parseJD("Psychology").forEach(System.out::println);
}
public List<Content> parseJD(String keywords) throws IOException {
String url = "https://search.jd.com/Search?keyword=" + keywords;
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodsList = new ArrayList<>();
// Get the content in the element. Here el is each li tag!
for (Element el : elements) {
// For websites with a lot of pictures, all pictures are loaded late!
// data-lazy-img
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setTitle(title);
content.setImg(img);
content.setPrice(price);
goodsList.add(content);
}
return goodsList;
}
}
Business layer code
// Business Writing
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
// 1. Parse data into ElasticSearch index
public Boolean parseContent(String keyWord) throws IOException {
List<Content> contents = new HtmlParseUtil().parseJD(keyWord);
// Put the queried data into ElasticSearch
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(
new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
// 2. Obtain these data to realize the search function
public List<Map<String,Object>> searchPageHighlightBuilder(String keyWord,int pageNo,int pageSize) throws IOException {
if (pageNo <= 1){
pageNo = 1;
}
// Condition search
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// paging
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//Exact match
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyWord);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// Perform search
searchRequest.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// Analytical results
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit documentFields : response.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
// 3. Get these data to realize the highlight function
public List<Map<String,Object>> searchPage(String keyWord,int pageNo,int pageSize) throws IOException {
if (pageNo <= 1){
pageNo = 1;
}
// Condition search
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// paging
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//Exact match
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyWord);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// Highlight
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false); // Multiple highlights
highlightBuilder.preTags("<span style='color: red;'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
// Perform search
searchRequest.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// Analytical results
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
// Resolve highlighted fields
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
if (title != null){
Text[] fragments = title.fragments();
String n_title = "";
for (Text text : fragments) {
n_title += text;
}
sourceAsMap.put("title",n_title);
}
list.add(sourceAsMap);
}
return list;
}
}
Control layer code
// Request writing
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyWord) throws IOException {
return contentService.parseContent(keyWord);
}
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyword") String keyWord,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchPage(keyWord,pageNo,pageSize);
}
}
Original video address: https://www.bilibili.com/video/BV17a4y1x7zq?spm_id_from=333.999.0.0