Diagram
This figure is inaccurate for the underlying implementation method of some implementation classes, which has changed in the new version of JVM, such as HashMap, but the inheritance and implementation relationship has not changed. Solid white arrows are inheritance and blue dashed arrows are implementation.
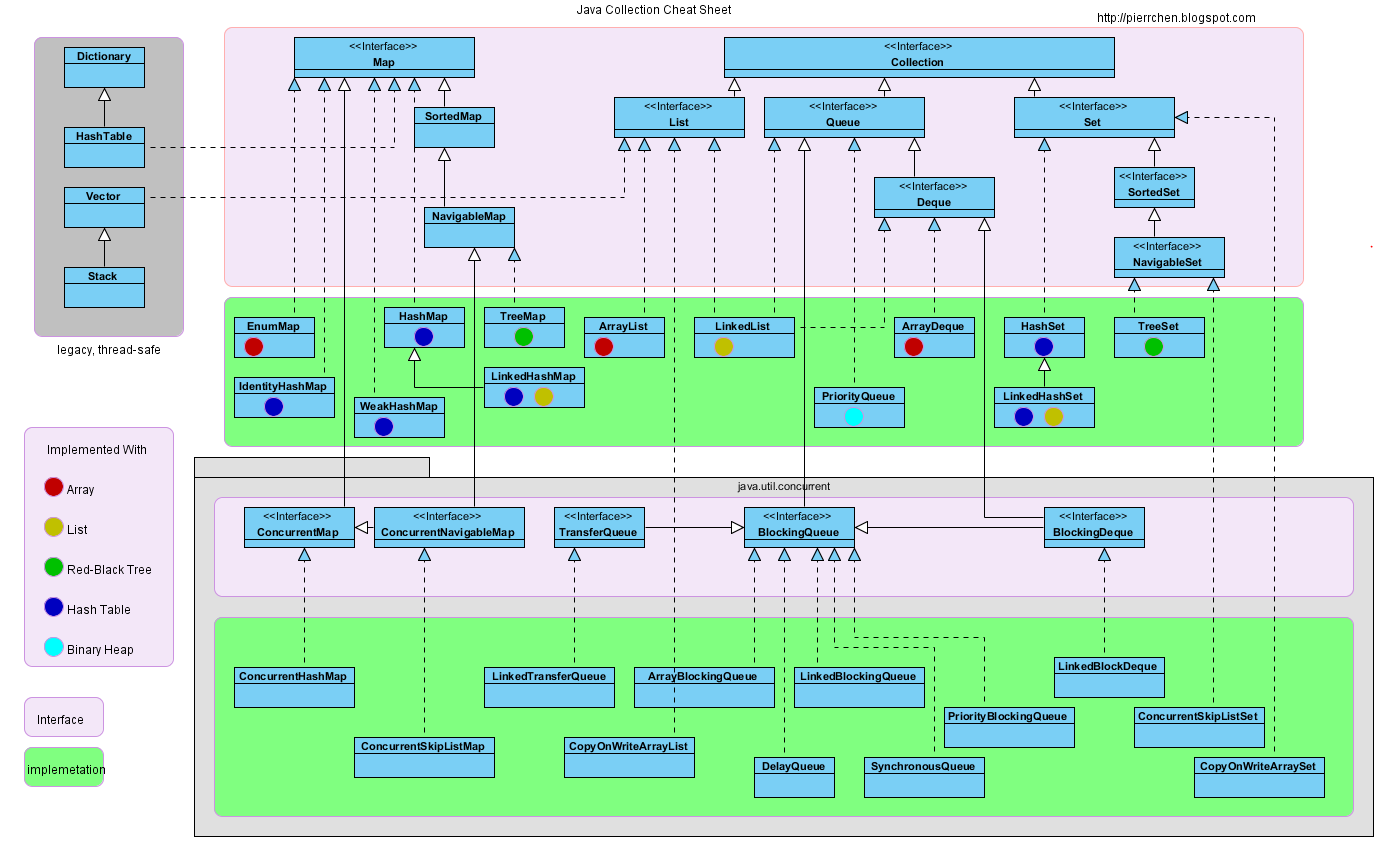
Map
HashMap
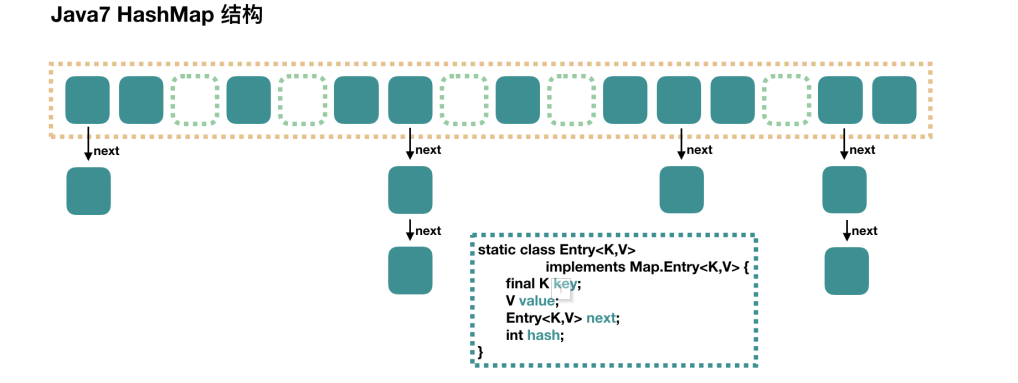
Before java8, the underlying implementation was array + linked list, which was changed from java8 to array + linked list + red black tree.
The characteristics of array are: easy addressing, difficult insertion and deletion;
The characteristics of linked list are: difficult addressing, easy insertion and deletion.
Hash table( (hash table) combines the two, which not only meets the convenience of data search, but also does not occupy too much content space, and is very convenient to use. The bottom layer of HashMap uses a hash table, puts the hashcode calculated according to the key in the array, and puts the real key and value in the chain table. When searching, first find the hashcode, and then find the same node according to the key to return value.
Java 8 has made some modifications to HashMap. The biggest difference is that it uses red black tree, so it is composed of array + linked list + red black tree. According to the introduction of Java7 HashMap, we know that when searching, we can quickly locate the location of the array according to the hash value
Specific subscripts, but later, we need to compare them one by one along the linked list to find what we need. The time complexity depends on the length of the linked list, which is O(n). In order to reduce the overhead of this part, in Java 8, when there are more than 8 elements in the linked list, the linked list will be converted into a red black tree. When searching in these locations, the time complexity can be reduced to O(logN).
The default capacity of HashMap is 16. When the array reaches 0.75 times the space utilization, it will be expanded to twice the original capacity. One key is allowed to be null, and value can be multiple keys. The corresponding keys are null and unordered.
ConcurrentHashMap
Collections.synchronizedMap(), HashTable and ConcurrentHashMap are thread safe, but the performance of the first two is too low. ConcurrentHashMap is used most of the time. ConcurrentHashMap is also unordered, but it does not allow the key value to be null.
JDK1. Before 8, the idea of concurrent HashMap was similar to that of HashMap, but it was more complex because it supports concurrent operations. The entire ConcurrentHashMap is composed of segments, which represent the meaning of "part" or "paragraph", so it will be described as segment lock in many places. Note that in the text, I use "slot" to represent a segment in many places The simple understanding is that ConcurrentHashMap is an array of segments. Segments are locked by inheriting ReentrantLock, so each operation that needs to be locked locks a segment. In this way, as long as each segment is thread safe, global thread safety is realized.
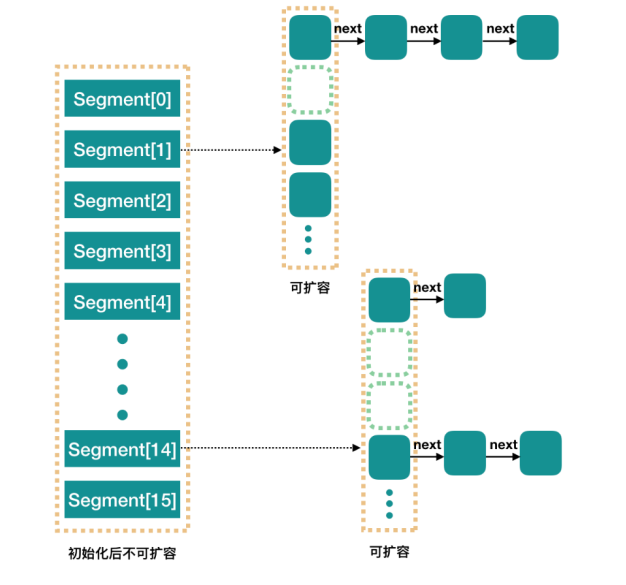
It has 16 Segments by default, so theoretically, at this time, it can support up to 16 threads to write concurrently, as long as their operations are distributed on different Segments. This value can be set to other values during initialization, but once initialized, it cannot be expanded. If the number of threads exceeds the maximum concurrency, it will spin when it cannot get the lock. Specifically, each Segment is very similar to the HashMap described earlier, but it needs to ensure thread safety, so it needs to be handled more troublesome. Every time the data is put, an attempt will be made to acquire the lock. If the acquisition fails, there must be competition from other threads, and the lock will be acquired by using scanAndLockForPut() spin.
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Before writing to the segment, you need to obtain the exclusive lock of the segment. If the acquisition fails, try to obtain the spin lock
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
// Array inside segment
HashEntry<K,V>[] tab = table;
// Use the hash value to find the array subscript that should be placed
int index = (tab.length - 1) & hash;
// first is the header of the linked list at this position of the array
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) key ||
(e.hash hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// Overwrite old value
e.value = value;
++modCount;
}
break;
}
// Continue to follow the linked list
e = e.next;
}
else {
// Whether the node is null depends on the process of obtaining the lock. The thread that did not obtain the lock helped us create the node and directly inserted the header
// If it is not null, set it directly as the linked list header; If it is null, initialize and set it as the linked list header.
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// If the threshold of the segment is exceeded, the segment needs to be expanded
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // Capacity expansion
else
// If the threshold is not reached, put the node in the index position of the array tab,
// Set the new node as the header of the original linked list
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// Unlock
unlock();
}
return oldValue;
}
From jdk1 Since 8, the underlying implementation of ConcurrentHashMap has been adjusted, and CAS+Synchronized has been adopted to replace the previous Segment+ReentrantLock. Without the concept of segment, it is consistent with the ordinary hashmap structure, except that the first node of the linked list or red black tree under each node in the array will be locked during put, because key s need to be compared in order during put, and locking the first element ensures synchronization. Compared with locking, segment can further reduce thread conflict.
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// If table is empty, initialize; Otherwise, the array index I is calculated according to the hash value. If tab[i] is empty, create a new Node directly. Note: tab[i] is actually the first Node of a linked list or red black tree.
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// If tab[i] is not empty and the hash value is MOVED, it indicates that the linked list is in the process of transfer, and the table after capacity expansion is returned.
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// Lock the first node instead of segment to further reduce thread conflict
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// If you find node e with the value of key in the linked list, you can directly set e.val = value.
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// If no Node with the value of key is found, just create a new Node and add it to the tail of the linked list (tail interpolation).
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// If the first node is of TreeBin type, the description is a red black tree structure. Execute putTreeVal.
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// If the number of nodes > = 8, the linked list structure is transformed into a red black tree structure.
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// If the count increases by 1, the transfer operation (capacity expansion) may be triggered.
addCount(1L, binCount);
return null;
}
In addition, the method of obtaining size is also optimized, jdk1 Before 8, the segment lock was used to add a lock to each segment to ensure thread concurrency. However, when obtaining the size, you need to lock all segments to obtain the accurate size. After the calculation, unlock them in turn. However, doing so will cause write operations to be blocked and reduce the performance of ConcurrentHashMap to a certain extent. JDK1. After 8, counter cells and baseCount are used to count the quantity. baseCount records the number of elements. After each element change, the value will be updated by CAS. If multiple threads add new elements concurrently and the baseCount update conflicts, counter cell will be enabled to update the total number to the corresponding position of the counter cells array by using CAS to reduce competition. If CAS fails to update a location in the counterCells array multiple times, it indicates that multiple threads are using this location. At this time, the conflict will be reduced again by expanding counterCells. Through the above efforts, it becomes very simple to count the total number of elements. As long as the sum of baseCount and counterCells is calculated, the whole process does not need to be locked.
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
LinkedHashMap
The HashMap is unordered, but sometimes it needs to be taken out according to the insertion order. LinkedHashMap is used at this time. Although LinkedHashMap adds time and space overhead, it ensures the iterative order by maintaining an additional two-way linked list. In particular, the iteration order may be an insertion order or an access order. Therefore, according to the order of elements in the linked list, LinkedHashMap can be divided into LinkedHashMap maintaining insertion order and LinkedHashMap maintaining access order. The default implementation of LinkedHashMap is sorted by insertion order. In essence, HashMap and two-way linked list are combined into one, that is, LinkedHashMap. The so-called linked HashMap is based on HashMap. Therefore, more accurately, it is a HashMap that links all Entry nodes into a two-way linked list. In LinkedHashMap, all entries put in are saved in HashMap, but because it additionally defines a two-way linked list with head as the head node, for each Entry put in, in addition to saving it to the corresponding position in the hash table, it will also be inserted into the tail of the two-way linked list.
/**
* Instantiate a LinkedHashMap;
*
* LinkedHashMap Insertion order and access order of;
* LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder);
* explain:
* When accessOrder is true, it means that the insertion and reading order of the current data is access order;
* When accessOrder is false, it means that the insertion and reading order of the current data is the insertion order;
*/
Map<String,String> map = new LinkedHashMap<>(5,0.75f,true);
// Map<String,String> map = new LinkedHashMap<>(5,0.75f,false);
map.put("1","1");
map.put("2","2");
map.put("3","3");
map.put("4","4");
map.put("5","5");
System.out.println(map.get("3"));
System.out.println(map);
TreeMap
The underlying implementation of treemap is a red black tree. The key is not allowed to be null. The thread is unsafe, but it is orderly. The sorting rules are sorted by dictionary by default. You can also customize the sorting rules and pass the sorting class in through the construction method when defining treemap.
HashTable
hashTable has been eliminated, and now basically no hashTable is used. hashMap is used for single thread and ConcurrentHashMap is used for multithreading, because all methods in it are locked with pessimistic locks, which is inefficient in the case of multithreading. And the internal implementation is still in the form of array + linked list. The official has no longer updated this.
Collection
List
ArrayList
ArrayList is ordered in the order of insertion. The underlying implementation is an array. The thread is not safe, and the content is allowed to be repeated. Like the array, the query is fast and the addition and deletion is slow (the reason for the slow addition and deletion is that when inserting or deleting elements from the middle of the ArrayList, the array needs to be copied, moved and expensive). The random access interface is implemented, which can be accessed quickly and randomly, So using the for loop to traverse the ArrayList is faster than using the iterator During capacity expansion, when the list is not empty, the capacity expansion is 1.5 times the original size. When the list is empty, the capacity expansion is the default capacity of 10.
LinkedList
The implementation of linkedList is different from ArralList. It is implemented by a linked list. It is orderly and allows repetition. The thread is unsafe. Unlike the array, it expands in disorder. As long as the front and rear nodes are specified when adding, it can expand infinitely. Because it is implemented by a linked list, it can add and delete faster and does not need to copy and move like the array, but its query is relatively slow, Because he needs to traverse one by one. (1) the array is like a person standing in a row with a number on his body. It is easy to find the 10th person according to the number on his body. However, the insertion and deletion are slow. When you want to look at a certain position to insert or delete a person, the number on the following person will change. Of course, the person who adds or deletes will always be fast at the end. 2. The linked list is like a person standing in a circle holding hands to find the 10th person It's not easy to count 10 people. You must count them one by one from the first person. But insertion and deletion are fast. When inserting, just untie the hands of two people and hold the hands of the new person again. Delete the same reason.)
Vector
Like HashTable, Vector is now used by fewer people because it is the same as collections The performance of synchronizedlist () is relatively low. ArrayList is directly used in the case of single thread, and CopyOnWriteList is used instead in the case of multi thread. The bottom layer is also implemented by array, which is orderly and allows repetition. For capacity expansion, you can specify the capacity expansion quantity through the construction method or directly expand the capacity to twice the existing capacity without specifying.
CopyOnWriteList
Collections. Synchronized list (list), but it locks the whole list whether reading or writing. When our concurrency level is particularly high, threads will wait for any operation. Therefore, it is not the best choice in some scenarios. In many scenarios, our read operations may be much larger than write operations. Obviously, we are not satisfied with using this method. In order to maximize the reading performance, the JUC package provides the CopyOnWriteArrayList class. During the use of this class, reading is not mutually exclusive, and more importantly, reading and writing are not mutually exclusive.
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();//Lock when writing, and then execute the following code
try {
//Copy the original array, and then put a new array into the original array and the added content
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
//Then assign the new array to the old array. The old array is declared with volatile, so other threads can get the latest data immediately
setArray(newElements);
return true;
} finally {
/**
* Finally release the lock. It implements locking only when writing, because at this time, even if a lock is added and used sync keyword
* Lock the whole list It is different. It realizes the separation of reading and writing, and reading is not locked, which ensures that reading is not mutually exclusive, and what's more, reading and writing are not mutually exclusive.
* /
lock.unlock();
}
}
From the source code, we can see that the re-entry lock is used in the add operation, but this lock is only for write write operations. The key to non mutual exclusion between reading and writing is that the operation of adding values is not directly completed in the original array, but uses the original array to copy a new array, then inserts the values into the new array, and finally uses the new array to replace the old array, so the insertion is completed. In this way, the old array is not modified during the add process, so the write operation does not affect the read operation. In addition, the array is defined with volatile modification to ensure memory visibility. After modification, the read thread can get the latest data immediately. (note that when calling the subList() method, an internal class of CopyOnWriteList called COWSubList is returned. Pay attention to the possible errors caused by different types when using)
//read
public E get(int index) {
return get(getArray(), index);
}
Therefore, in the case of more reads and less writes, try to use CopyOnWriteList. However, when there are fewer reads and more writes, we can use collections instead Synchronizedlist, because it is directly locked and written, and there is no need to copy the array.
Set
HashSet
In fact, the bottom layer of hashSet is stored in HashMap. Take each element as key and value, and put an empty object into HashMap.
LinkedHashSet
The underlying layer of linkedHashSet is actually implemented with LinkedHashMap, which will not be repeated.
TreeSet
At the bottom of TreeSet is TreeMap, that is, red black tree. I won't repeat it.
CopyOnWriteArraySet
The bottom layer of CopyOnWriteArraySet is actually CopyOnWriteArrayList, which is thread safe. When adding elements, it will traverse whether there are elements with the same value in the list one by one. If so, copy an original list, put the latest one in it, and then replace it (in fact, the add step of CopyOnWriteArrayList) to return true. If there are already elements, it will not be added and return false.
Queue
LinkedList
LinkedList implements both the List interface and the deque (inherit Queue) interface. Therefore, when declaring, you can not only use List = new linkedlist(); You can also use Deque deque = new LinkedList(); To declare as a stack and queue.
Implementation and operation of queue. (first in first out)
import java.util.LinkedList;
import java.util.Queue;
//Use linkedList to simulate queues, because linked lists are good at inserting and deleting
public class Hi {
public static void main(String [] args) { //Have you ever met this number knot
Queue<String> queue = new LinkedList<String>();
//Append element
queue.add("zero");
queue.offer("one");
queue.offer("two");
queue.offer("three");
queue.offer("four");
System.out.println(queue);//[zero, one, two, three, four]
//Remove the element from the team leader and delete it
System.out.println(queue.poll());// zero
System.out.println(queue.remove());//one
System.out.println(queue);//[two, three, four]
//Take the element from the team leader without deleting it
String peek = queue.peek();
System.out.println(peek); //two
//When traversing the queue, you should note that each time you get the element, it will be deleted, and the whole
//The queue becomes shorter, so you only need to judge the size of the queue
while(queue.size() > 0) {
System.out.println(queue.poll());
}//two three four
}
}
Implementation and operation of stack (first in and last out)
import java.util.Deque;
import java.util.LinkedList;
public class Hi {
public static void main(String[] args) {
/*Simulation stack, this is from the beginning*/
Deque<String> deque = new LinkedList<String>();
// push from the top of the stack to the inside
deque.push("a");
deque.push("b");
deque.push("c");
System.out.println(deque); //[c, b, a]
//After obtaining the first element of the stack, the element will not be out of the stack
System.out.println(deque.peek());//c
while(deque.size() > 0) {
//After getting the first element of the stack, the element will be out of the stack
System.out.println(deque.pop());//c b a
}
System.out.println(deque);//[]
/*The stack can also be placed upside down and taken upside down. If it is inverted, it is in the same order as the queue*/
deque.offerLast("a");//You can also put it at the end of the stack here
deque.offerLast("b");
deque.offerLast("c");// [a, b, c]
while(!deque.isEmpty())
System.out.println(deque.pollLast());
} // First output c, then b, and finally a
}