0 Preface
Because I often run various experimental tests in Linux, in order to reduce energy, I usually write the script of automatic running experiment and the script of result processing first, and finally open the experimental results directly with excel. In order to facilitate readers and write scripts in the future, the common instructions for writing shell scripts are summarized. If there are any mistakes or good suggestions and good supplements, readers are welcome to point out in the comments. I would like to say thank you in advance!
1 text content replacement and deletion
- Replace the contents of a specific line. Replace the contents in line ${line} of the hello.txt file with sudo bash -c 'echo 0 > / sys / kernel / mm / KSM / run'. Note: ${line} is a variable defined in advance and can be directly fixed to a number. Ratio 3c represents line 3- i stands for alternate text
sed -i "${line}c sudo bash -c 'echo 0 > /sys/kernel/mm/ksm/run'" hello.txt
- Replace a line that begins with a specific character. Replace all contents in the hello.txt file with "hibench.scale.profile ${var}", where ${var} is a variable
sed -i "/^hibench.scale.profile/c\hibench.scale.profile ${var}" hello.txt
- Replace the first occurrence of a character. For example, replace ${character} with ${other_character} for the first time. Note that ${other_character} and ${character} are shell variables, and $in $/ s indicates the end of the string.
sed -i "0,/${character}$/s/${character}$/${other_character}/g" hello.txt
- Add content before the first line of the file. For example, add "hello world" before the first line of hello.txt, where 1i represents the first line.
sed -i "1i\hello world" hello.txt
- Delete the first column of the file.
sed -i -e "s/[^ ]* //" hello.txt
- Delete the first line of the file. Where 1d represents the first line, nd represents the nth line, and $d represents the last line.
sed -i '1d' hello.txt
2. Row and column selection
- Print column 2 of lines 3 to 6 of the file (including lines 3 and 6)
cat test.txt | sed -n "3, 6p" | awk '{print $2}'
3 script parameter processing
- String segmentation or replacement. For example, use target_str replace source_str, for example, ${str / /, /} can be used to convert the input string parameters into an array. Note: the string should preferably be in the style of "A,B,C" or "A-B-C".
${parameter//source_str/target_str}# with target_str to replace all matching sources in the parameter variable_ str
- print the help information
read -r -d '' USAGE << EOS Usage: $0 [options] Options: args parameter meaning and value -h | --help Display help infomation. -s | --scale Data scale profile. Available value is tiny, small, large, huge, gigantic and bigdata. Default value is small. -m | --maps Mapper number in hadoop, partition number in Spark. Default value is 8. -f | --shuffles Reducer nubmer in hadoop, shuffle partition number in Spark. Default value is 8. -S | --spark-master Spark master. Standalone mode: spark://xxx:7077, YARN mode: yarn-client. Default value is yarn-client. -n | --exec-num Spark executor number when running on Yarn. Default value is 2. -c | --exec-cores Spark executor number when running on Yarn. Default value is 4. -M | --exec-mem Spark executor memory in standalone & YARN mode. Default value is 4g. -d | --driver-mem Spark dirver memory in standalone & YARN mode. Default value is 4g. -b | --benchmark HiBench benchmark, available value is: micro.sleep, micro.sort, micro.terasort, micro.wordcount, micro.repartition, micro.dfsioe, sql.aggregation, sql.join, sql.scan, websearch.nutchindexing, websearch.pagerank, ml.bayes, ml.kmeans, ml.lr, ml.als, ml.pca, ml.gbt, ml.rf, ml.svd, ml.linear, ml.lda, ml.svm. -p | --platform Which platform to run the benchmark, available value is hadoop, spark. -D | --data-size Benchmark data size. Default value is determined by data scale. If data scale and data size are set at the same time, the value of data size will be updated. The unit of data size is byte. EOS
The above code actually defines the help information as the use variable. You can output the information by echo $use (the middle section starting with usage and ending with EOS)
- Execute the corresponding instructions according to the parameters. Next to the "print help information" above, and assuming that the user executes the script and follows a pile of parameters, this step needs to parse the user parameters and execute the corresponding instructions. In fact, there are many kinds of script parameter processing, such as using getopt or getopts function. Let's take getopt function as an example.
# The following line is to execute the getopt instruction, where - o represents a short option (i.e., a command of the form. / my_shell.sh -h), and a colon represents a parameter
# The number needs to be followed by the parameter value. For example, -- help/-h (i.e. display help instruction) does not need to be followed by the parameter value, so there is no colon after h, and the scale table
# To show the scale, you need to have a specific value, so there should be a colon after s. And -- long represents the long option (i.e. / my_shell.sh --help)
# Form command)- n represents the information in case of error. Here, take the script name displayed in case of error as an example. And -- "$@" here represents the getopt instruction
# Analyze the parameters "$@"
#
ARGS=`getopt -o hs:m:f:S:n:c:M:d:b:p:D: --long help,scale:,maps:,shuffles:,spark-master:,exec-num:,exec-cores:,exec-mem:,driver-mem:,benchmark:,platform:,data-size: -n 'benchmark.sh' -- "$@"`
if [ $? != 0 ] #If the previous command (ARGS=`getopt... ` executed earlier) returns 0, it means that the user parameter is enabled
# If you use it incorrectly, print the help information at this time
then
echo "$USAGE"
exit 1
fi
eval set -- "${ARGS}" #This command will put the parameters that comply with the getopt parameter rule in the front, the others in the back, and add them on the last side--
# The following code makes corresponding processing according to the corresponding parameters. It should be noted that shift 2 here means to move the parameter to the left by 2. That is, deal with a problem
# Once the parameter is, we remove it from the parameter list. It's also easy to understand why it is 2, because our script form is similar to the following:
# ./my_ Shell.sh - s 1234 -- exec num 5. After processing the - S parameter, - s 1234 is useless, so it is 2
while true
do
case $1 in
-h|--help)
echo "$USAGE"
exit 0
;;
-s|--scale)
echo "scale=${2}"
shift 2
;;
-m|--maps)
echo "maps=${2}"
shift 2
;;
-f|--shuffles)
sed -i "/^hibench.default.shuffle.parallelism/c\hibench.default.shuffle.parallelism $2" ${CONF_DIR}/hibench.conf
shift 2
;;
-S|--spark-master)
sed -i "/^hibench.spark.master/c\hibench.spark.master $2" ${CONF_DIR}/spark.conf
shift 2
;;
--)
break
;;
*)
echo "$USAGE"
exit 1;;
esac
done
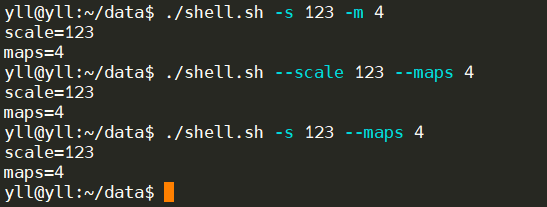
With the above parameter handling code, we can_ Shell.sh - s 123 - M 4 or. / my_shell.sh --scale 123 -maps 4 or. / my_shell.sh -s 123 --maps 4 to run the script as follows:
4 addition, subtraction, multiplication and division
4.1 shell's own addition, subtraction, multiplication and division
#!/bin/bash
# 1. expr mode. Note: expr cannot perform x^y power operation
arg1=5
arg2=5
arg3=5
add=`expr ${arg1} + ${arg2} + ${arg3}` # addition
sub=`expr ${arg1} - ${arg2} - ${arg3}` # subtraction
mul=`expr ${arg1} \* ${arg2} + ${arg3} ` # multiplication
div=`expr ${arg1} / ${arg2} + ${arg3} ` # division
mod=`expr ${arg1} % ${arg2}` # Surplus
echo "add=${add},sub=${sub},mul=${mul},div=${div},mod=${mod}"
# 2. $(()) mode
add=$(( ${arg1} + ${arg2} + ${arg3} )) # addition
sub=$(( ${arg1} - ${arg2} - ${arg3} )) # subtraction
mul=$(( ${arg1} * ( ${arg2} + ${arg3} ) )) # multiplication
div=$(( ( ${arg1} / ( ${arg2} ) + ${arg3} ) )) # division
mod=$(( ${arg1} + ${arg2} )) # Surplus
pow=$(( ${arg1} ** ${arg2} )) # arg1^arg2
echo "add=${add},sub=${sub},mul=${mul},div=${div},mod=${mod},pow=${pow}"
# 3. $[] mode
add=$[ ${arg1} + ${arg2} + ${arg3} ] # addition
sub=$[ ${arg1} - ${arg2} - ${arg3} ] # subtraction
mul=$[ ${arg1} * ( ${arg2} + ${arg3} ) ] # multiplication
div=$[ ( ${arg1} / ( ${arg2} ) + ${arg3} ) ] # division
mod=$[ ${arg1} % ${arg2} ] # Surplus
pow=$[ ${arg1} ** ${arg2} ] # arg1^arg2
echo "add=${add},sub=${sub},mul=${mul},div=${div},mod=${mod},pow=${pow}"
# 4. let mode
let add1=${arg1}+${arg2}+${arg3} # addition
add2=${arg1}
let add2+=(${arg2}+${arg3}) # addition
let sub=${arg1}-${arg2}-${arg3} # subtraction
let mul=(${arg2}+${arg3})*${arg1} # For multiplication, note that let mul=${arg1}*(${arg2}+${arg3}) will report an error
let div=(${arg1}/${arg2})+${arg3} # division
let mod=${arg1}%${arg2} # Surplus
let pow=${arg1}**${arg2} # arg1^arg2
echo "add1=${add1},add2=${add2},sub=${sub},mul=${mul},div=${div},mod=${mod},pow=${pow}"
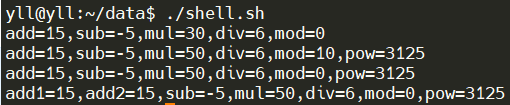
The execution results of the above code are as follows:
4.2 awk performing addition, subtraction, multiplication and division
# 1. Plot the last two columns of each line of the file
cat test.txt | awk 'NR>0{print $(NF-1),$NF}'|awk '{mul = $1*$2}; {print mul}'
# 2. Sum the first three columns of each line of the document
cat test.txt | awk 'NR>0{print $1,$2,$3}'|awk '{sum = $1+$2+$3}; {print sum}'
# 3. Sum column 2 of all lines of the file
cat test.txt | awk '{sum += $2};END {print sum}'
# 4. Sum all columns in all rows of the file
cat test.txt | awk '{sum += $2+$1+$3};END {print sum}'
# 5. Average column 2 of the document
cat test.txt | awk '{sum += $2};END {print sum/NR}'
# 6. Maximum the penultimate column of the document
cat test.txt | awk 'NR>0{print $(NF-1)}' | awk 'BEGIN {max = 0} {if ($1>max) max=$1 fi}; END {print "Max=", max}'
cat test.txt | awk 'BEGIN {max = 0} {if ($(NF-1)>max) max=$(NF-1) fi}; END {print "Max=", max}'
# # 7. Average each column of the document
cat test.txt | awk -F' ' '{for(i=1; i<=NF; i++) {a[i]+=$i; if($i!="") b[i]++}}; END {for(i=1; i<=NF; i++) printf "%s%s", a[i]/b[i],(i==NF?ORS:OFS)}'
5 others
5.1 date
date +%Y-%m-%d~%H:%M:%S # Y/m/d/H/M/S means year / month / day / hour / minute / second
5.3 sudo executes commands that can only be executed by switching to the root account
First of all, some sudo instructions cannot be executed, such as the buffer/cache instruction to clean up the system

You can use sudo bash -c "your command" to execute instructions that can only be executed by switching to the root account.