Summary of High Frequency Knowledge Points - 01
1. About i++ and ++ I
Analysis of 1.1 pairs of byte codes
i = i+ =) first takes I out of the operand stack, and then makes I increase in the local variable table. After adding, I in the operand stack is assigned to i, so in general, I is increased, but I in the operand stack is unchanged, and when assigning later, I returns to its original value
i = ++i ="is incremented, then I is taken out of the operand stack and assigned, so the final value of I changes.
1.2 Instances
public class i_increase {
public static void main(String[] args) {
int i = 1;
i = i++; // i = 1
int j = i++; // j = 1
int k = i + ++i * i++; // i = 2 => 3 ==> 2 + 3 * 3 = 11
System.out.println("i:"+ i); // i = 4, executed by i++ above
System.out.println("j:"+ j);
System.out.println("k:"+ k);
}
}
// Result
i:4
j:1
k:11
2. Initialization of classes
Instantiating a subclass object first loads the static variables of the parent class, then the static variables of the subclass, then the non-static variables of the parent class, then a static block of code, and finally a parametric construction.
Initialization of subclasses in the JVM must first initialize the parent class.
- super()
- Non-static variable, top-to-bottom execution
- Parametric construction
2.1 Instance
/*
* Analysis
* - Static variables are initialized when Sun's main method loads, in top-down order
* - Pre-parent class
* - Subclass==(5) (1) (10) (6)
* - Order of direction when instantiating objects
* - super() (The parent class is also executed by the following methods)
* - Non-static variable, executing top-down
* - i = test() (To account for polymorphism, instantiate a subclass and call its methods)
* - Non-static code block
* - Parametric construction (last) == (9) (3) (2) (9) (8) (7)
* */
public class Father {
private int i = test();
private static int j = method();
static {
System.out.println("(1)");
}
Father() {
System.out.println("(2)");
}
{
System.out.println("(3)");
}
public int test(){
System.out.println("(4)");
return 1;
}
public static int method(){
System.out.println("(5)");
return 1;
}
}
public class Son extends Father{
private int i = test();
private static int j = method();
static {
System.out.println("(6)");
}
Son(){
System.out.println("(7)");
}
{
System.out.println("(8)");
}
public int test(){
System.out.println("(9)");
return 1;
}
public static int method(){
System.out.println("(10)");
return 1;
}
public static void main(String[] args) {
System.out.println("==Initialized number==");
Son s1 = new Son();
System.out.println();
Son s2 = new Son();
}
}
// Result:
(5)(1)(10)(6)
====
(9)(3)(2)(9)(8)(7)
(9)(3)(2)(9)(8)(7)
3. Method's parameter transfer mechanism-value transfer
3.1 Arguments are basic data types
Transfer data values
3.2 Arguments are reference data types
Delivery address
Special types: String, wrapper class, and so on, if changed, will not change on the original address, but will create a new object.
3.3 Instances
/*
* Analysis
* - Basic data type, direct value transfer== i = 1
* - Reference data type is address delivery
* - String And special objects such as packaging, do not change the actual parameters
* - String A reference type is created in the constant pool, and the address of the parameter changes, but the argument does not
* - Array references are address passes and change the values in the array, as the address of the argument reference does not change, so the reference to the argument also changes
* - Class references and arrays work the same way, values in reference objects change, and reference addresses of arguments do not change, leading to reference values of arguments change
* summary
* - Basic data types pass values directly, while reference data types pass addresses (classes, interfaces, arrays)
* - In parameters such as String and wrapper class, if the changed value is not a change in the original address but a re-creation
* The argument does not change because the reference address of the argument does not change, while other reference types, such as classes, interfaces, arrays
* Changing the parameter at the original address after the address has been passed causes the reference value of the argument to change
* */
public class ParameterPass {
public static void main(String[] args) {
int i = 1;
String str = "hello";
Integer num = 200;
int[] arr = {1,2,3,4,5};
MyData myData = new MyData();
change(i,str,num,arr,myData);
System.out.println(i); // i = 1
System.out.println(str); // hello
System.out.println(num); // 200
System.out.println(Arrays.toString(arr));
System.out.println(myData.a);
}
public static void change(int j, String s, Integer n, int[] arr, MyData m){
j += 1;
s += "world"; // A new string object was created in the heap, and the reference address in the method changed
arr[0] += 1; // The address of the delivery array [0], the value on the address has changed, the reference has not changed
m.a += 1; // The reference address was passed, the value in the object class changed, no new object was created
}
}
class MyData{
int a = 10;
}
// Result
1
hello
200
[2, 2, 3, 4, 5]
11
4. Member variables and local variables
Proximity principle: The proximity principle is used when there is no specific attribute of the specified variable
Classification of 4.1 Variables
-
Member variables: class variables (static variables), instance variables
-
Local variable (scope)
Execution of non-static code blocks: once per object instantiation
Method invocation: invocation executes once
4.2 Stack, Stack, Method Area
4.2.1 heap
The only purpose of this memory region is to store object instances, where almost all object instances are allocated. The description in the Java Virtual Machine specification is that all object instances and arrays are allocated on the heap.
4.2.2 stack
Usually referred to as the stack, refers to the virtual machine stack. The virtual machine stack is used to store local variables, and so on. The local variable table holds the various basic data types and object reference types of known length at compilation time (reference types, which are not the same as the object itself; they are the object's first address in heap memory). The method is executed and released automatically.
4.2.3 Method Area
Used to store data such as class information, constants, static variables, compiled code by the instant compiler that has been loaded by the virtual machine.
4.3 Life Cycle
4.3.1 Local Variables
Every thread, every execution call is a new life cycle
4.3.2 Instance variables
Initializes as objects are created, dies as objects are recycled, and each instance object has its own instance variable and is independent
4.3.3 Variables (Static Variables)
Initializes with class initialization, dies with class unloading, and all instantiated objects of the class share class variables.
4.4 Instances
/*
* Analysis
* - When a class is initialized, it is initialized with s == s = 0
* - Executes nonstatic blocks of code when instantiating objects
* - In a nonstatic block of code is a local variable and its scope is within that block.
* - If no specific variable name is specified under the same name, there is a proximity principle== i = 2 in the nonstatic block of code
* If there is no member variable with the same name =="J = 1 s = 1 This place instantiates two static variables that are shared ==" s = 2
* - Execute specific methods
* - Similarly, if the variable attribute i s not indicated under the same name, the proximity principle== applies to local variables: j = 11 member variables: i = 1 static variable (class variable): s = 3
* Here, the v1 object i s executed twice, and the second time == local variable: j = 21 member variable: i = 2 static variable (class variable): s = 4
* - v2 I s a new instance object, member variables are not shared, static variables are shared =="local variables: j = 31 member variables: i = 1 static variables (class variables): s = 5
*
* Note:
* - If you want to eliminate the influence of the proximity principle, you can
* - If it is in this class, you can add this. To distinguish
* - Class names can be added to internal classes. To distinguish
* - Local variables can only be modified with final
*
* Output Results
* 2,1,5
* 1,1,5
* */
public class Variables {
static int s;
int i;
int j;
{
int i = 1;
i++; // Proximity principle, i++ in local variables
j++;
s++;
}
public void test(int j){
j++; // Proximity principle, j++ in local variables
i++;
s++;
}
public static void main(String[] args) {
Variables v1 = new Variables();
Variables v2 = new Variables();
v1.test(10);
v1.test(20);
v2.test(30);
System.out.println(v1.i+","+v1.j+","+v1.s);
System.out.println(v2.i+","+v2.j+","+v2.s);
}
}
5. Scope of Spring Bean
You can set a scope in the configuration file, or you can add a scope @Component("SingletonBean") comment to the comment to tell Spring that this is a bean. @ The Scope("prototype") comment tells Spring that the scope of the bean is a prototype.
5.1 Difference
| Scope | describe |
|---|---|
| singleton | There is only one Bean instance in the spring IoC container and the Bean exists as a singleton, which is the default value for the bean scope. A Bean instance is automatically created when a container is created |
| prototype | A bean instance (getbean) is created when needed, and each call creates a different instance object |
| request | Each HTTP request creates a new Bean that only applies to the Spring Web ApplicationContext environment of the web. |
| session | The same HTTP Session shares a Bean, and different Sessions use different Beans. This scope only applies to the Spring Web ApplicationContext environment of the web. |
| application | Limits the life cycle of a Bean to a ServletContext. This scope only applies to the Spring Web ApplicationContext environment of the web. |
6. Transaction Propagation Behavior
Transaction propagation behavior refers to how the invoked transaction method should behave when a transaction method is invoked by another transaction method.
For example, when the methodA transaction method calls the methodB transaction method, does methodB continue to run in the caller's methodA transaction or start a new transaction for itself, which is determined by the transaction propagation behavior of methodB.
6.1 Spring defines seven propagation behaviors
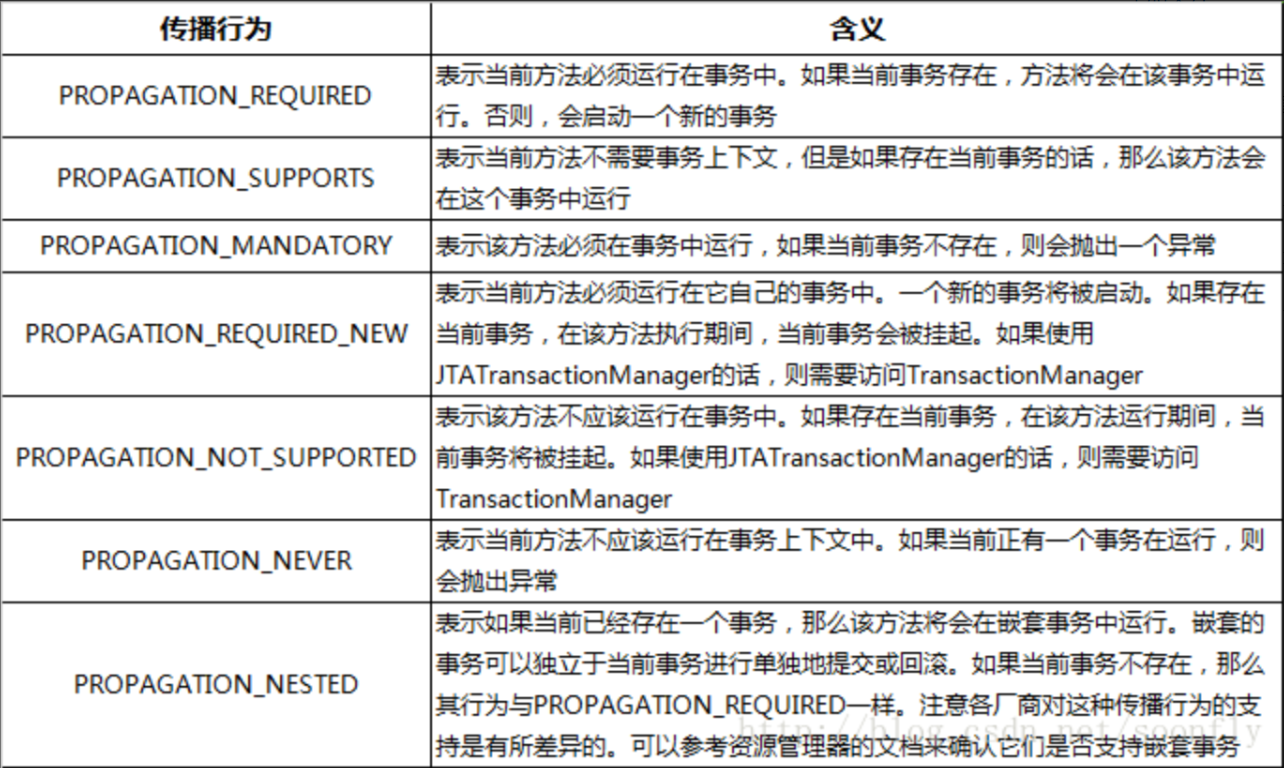
Commonly used are the first two, the first being called will continue to execute in the current transaction, the second will suspend the current transaction first, and then start its own new transaction, its own transaction will continue to execute the caller's transaction after it has been executed. Because the atomicity of the transaction is the first because it is executed in the current transaction, one of the unsuccessful executions in the process is rolled back, but if the second, the transaction opened by the callee itself does not affect the whole.
7. Concurrency issues with database transactions
7.1 Dirty Read (Updated but not Submitted)
The current transaction has read values that have been updated but not yet committed by other transactions. Other transactions may have various reasons for not committing successfully, so the value read by the current transaction is invalid or dirty.
7.2 Non-repeatable read (update and submit)
A transaction can only read data modified by another committed transaction, and each time the data is modified and committed by another transaction, the transaction can query for the latest value. (non-repeatable reading may occur at both read uncommitted and read committed isolation levels)
Transaction 1 first read a value of 20, transaction 2 modified this value of 30, transaction 1 second read value of 30, and the first read inconsistent, non-repeatable, no duplicate.
7.3 Magic Read (Update and Submit)
A transaction first queries some records based on some criteria, and then another transaction inserts records that meet these criteria into the table. When the original transaction queries according to this criteria again, it can read the records inserted by another transaction. (Hallucinations can occur at read uncommitted, read committed, and repeatable read isolation levels)
The first read has only one value, the other transactions add value, and the second read finds multiple values, which is magic reading.
8. Transaction isolation level
-
MySQL has four transaction isolation levels: read uncommitted, read committed, repeatable read, and serializable.
-
The isolation level of MySQL is used to isolate transactions from each other without affecting each other, which ensures transaction consistency.
-
Isolation level comparison: Serializable > Repeatable Read > Read Committed > Read Uncommitted
-
Comparison of the impact of isolation levels on performance: Serializable > Repeatable Read > Read Committed > Read Uncommitted
Thus, the higher the isolation level, the greater the performance of MySQL required (e.g., transaction concurrency severity). To balance the two, it is generally recommended to set the isolation level to be repeatable, and the default isolation level for MySQL is repeatable.
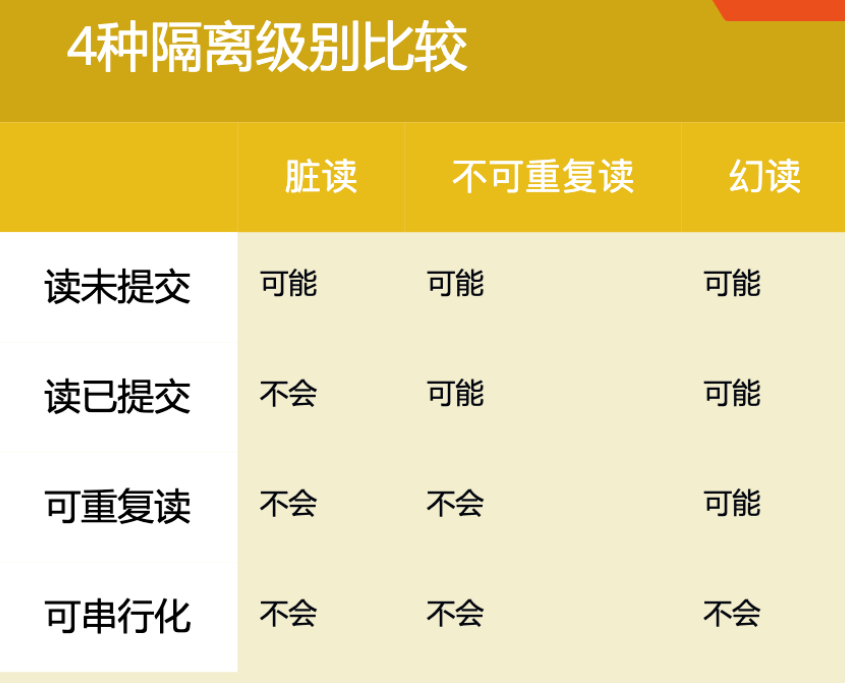
8.1 Read Uncommitted (READ UNCOMMITTED)
At the read uncommitted isolation level, transaction A can read data modified by transaction B but uncommitted.
Dirty, non-repeatable, and magic reading problems may occur, and this isolation level is rarely used. Nothing has been resolved.
8.2 Read Submitted (READ COMMITTED)
At the read committed isolation level, transaction B can only read data modified by transaction B after transaction A has been modified and committed.
The read submitted isolation level solves the problem of dirty reading, but non-repeatable and magic reading problems may occur and is rarely used.
8.3 Repeatable Read (REPEATABLE READ)
At the repeatable read isolation level, transaction B can only read the data modified by transaction B after transaction A has modified and committed the data, and after it has committed the transaction itself.
Repeatable read isolation solves dirty and non-repeatable reads, but hallucinations can occur. MVCC can solve the problem of magic reading.
1. Question: Why are write locks (write operations) enabled and other transactions readable?
Because InnoDB has an MVCC mechanism (multiversion concurrency control), snapshot reads can be used without blocking.
8.4 Serializable (SERIALIZABLE)
All kinds of problems (dirty, non-repeatable, magic) do not occur and are implemented by locking (read lock and write lock).
8.5 Comparison of four isolation levels
9.GIT branch related commands
# Switch branches, otherwise create git checkout -b <Branch name> # Merge Branches #Switch to main branch first git checkout master -> git merge <Branch name> # Delete Branch #Switch to main branch first git checkout master -> git branch -D <Branch name>
9.1 Git Workflow
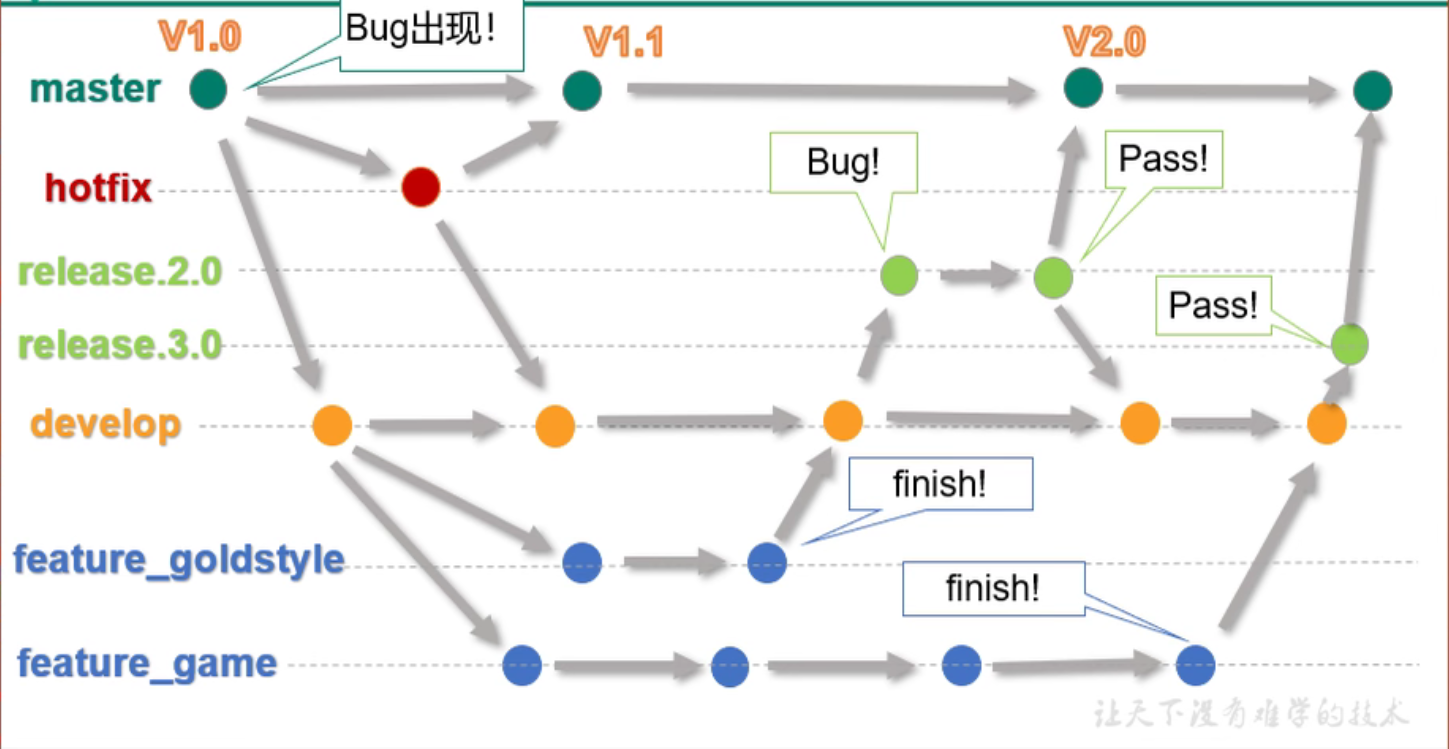
1. Notes
Development creates a new branch development under development and merges it into development when it is complete, testing goes online by merging it into the main branch, and then into development through merging it.
The main branch encountered a problem. Copy the branch and merge it into the main branch after solving the problem
10.MySQL index optimization
10.1 Index
It can be simply understood as ordered, fast data structure lookup
10.2 Advantage
Improve the efficiency of data retrieval and reduce the IO cost of the database.
Sorting data by index columns reduces the cost of sorting data and CPU consumption.
10.3 Disadvantage
Indexing greatly improves query speed, but it slows down table updates because MySQL not only saves the data, but also saves the fields with index columns added to each update of the index file.
10.4 When will the index be built?
-
Primary Key Automatically Creates Unique Index
-
Fields frequently used as query criteria should be indexed
-
Fields associated with other tables in a query, indexed by foreign key relationships
-
Selection of single-key/composite index, which is more cost-effective
-
Sorted fields in a query. Sorted fields accessed through an index will greatly improve the sorting speed
-
Statistics or Grouping Fields in Queries
10.5 What do you want to avoid creating an index?
-
Too few table records
-
Frequently added or deleted tables or fields
-
Where condition does not use fields to create an index
-
Poorly filtered fields that are not suitable for indexing and have ambiguous meanings