Python's coding problem is basically every novice will encounter the barrier, but as long as you fully grasp it, you can jump over the pit, never change from one of them, this is not the latest I have encountered this problem, let's take a look at it.
The reason for this is an upload function done by review colleagues. Look at the following code, self.fp is the upload file handle.
fpdata = [line.strip().decode('gbk').encode('utf-8').decode('utf-8') for line in self.fp]
data = [''.join(['(', self.game, ',', ','.join(map(lambda x: "'%s'" % x, d.split(','))), ')']) for d in fpdata[1:]]- 1
- 2
This code exposes two problems
1. The default encoding uses gbk, why not utf8?
2. encode ('utf-8'). decode('utf-8') is completely unnecessary. decode('gbk') has been unicode since then.
I suggest that the uploaded text be coded as utf8, so the code becomes like this?
fpdata = [line.strip() for line in self.fp if line.strip()]
data = [''.join(['(', self.game, ',', ','.join(map(lambda x: "'%s'" % x, d.split(','))), ')']) for d in fpdata[1:]]- 1
- 2
Unicode DecodeError in Testable Times:'ascii'codec can't decode byte 0xe4 in position 0: ordinal not in range(128). This exception estimates that novices have a headache. What does that mean?
That is to say, when decode ascii string to unicode, it encounters the bit oxe4, which is not within the scope of ascii, all decode errors.
To explain the background of the project, we use Python 2.7, this is the django project, self.game is a unicode object, understand that people at first glance is sys.setdefaultencoding problem, in fact, is the following problem.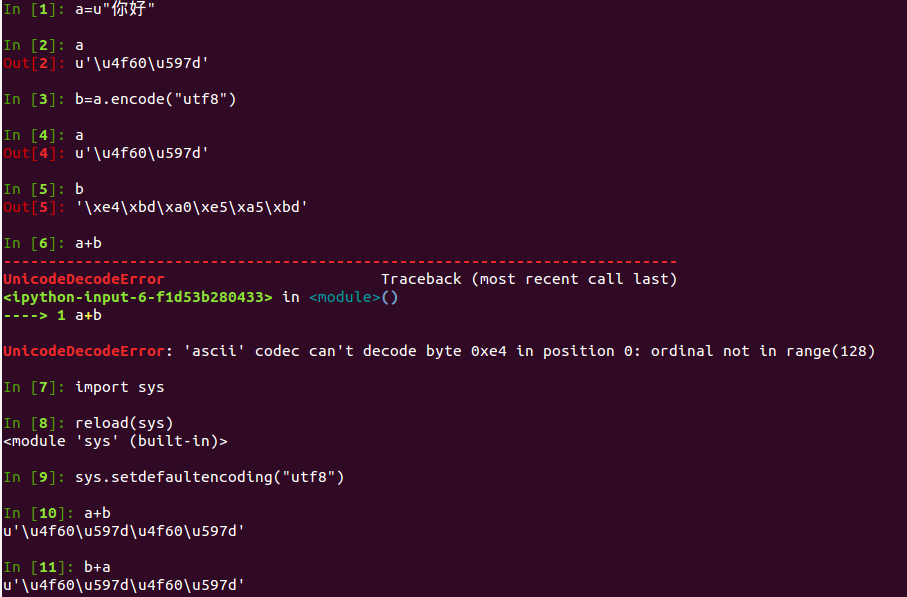
Ouch, but I clearly set the default code in settings.py. After checking it, I found a joke.
See what happened? Since fpdata is UTF8 string and self.game is unicode object, the UTF8 string will be decoded into unicode object when the string join s, but the system does not know that you are utf8 encoding, and the default use of ascii to decode is not surprising.
That's why, when encountering coding problems, veterans suggest adding sys.setdefaultencoding("utf8"), but why add such an operation? Let's look at what happened from the bottom?
PyString_Concat is called when a string connects to a unicode object, that is, a+b.
# stringobject.c
void
PyString_Concat(register PyObject **pv, register PyObject *w)
{
register PyObject *v;
if (*pv == NULL)
return;
if (w == NULL || !PyString_Check(*pv)) {
Py_CLEAR(*pv);
return;
}
v = string_concat((PyStringObject *) *pv, w);
Py_DECREF(*pv);
*pv = v;
}
static PyObject *
string_concat(register PyStringObject *a, register PyObject *bb)
{
register Py_ssize_t size;
register PyStringObject *op;
if (!PyString_Check(bb)) {
if (PyUnicode_Check(bb))
return PyUnicode_Concat((PyObject *)a, bb);
if (PyByteArray_Check(bb))
return PyByteArray_Concat((PyObject *)a, bb);
PyErr_Format(PyExc_TypeError,
"cannot concatenate 'str' and '%.200s' objects",
Py_TYPE(bb)->tp_name);
return NULL;
}
...
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
If b is detected to be a unicode object, PyUnicode_Concat is called
PyObject *PyUnicode_Concat(PyObject *left,
PyObject *right)
{
PyUnicodeObject *u = NULL, *v = NULL, *w;
/* Coerce the two arguments */
u = (PyUnicodeObject *)PyUnicode_FromObject(left);
v = (PyUnicodeObject *)PyUnicode_FromObject(right);
w = _PyUnicode_New(u->length + v->length);
Py_DECREF(v);
return (PyObject *)w;
}
PyObject *PyUnicode_FromObject(register PyObject *obj)
{
if (PyUnicode_Check(obj)) {
/* For a Unicode subtype that's not a Unicode object,
return a true Unicode object with the same data. */
return PyUnicode_FromUnicode(PyUnicode_AS_UNICODE(obj),
PyUnicode_GET_SIZE(obj));
}
return PyUnicode_FromEncodedObject(obj, NULL, "strict");
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Since A is not a unicode object, PyUnicode_FromEncodedObject is invoked to convert a into a unicode object, and the code passed is NULL.
PyObject *PyUnicode_FromEncodedObject(register PyObject *obj,
const char *encoding,
const char *errors)
{
const char *s = NULL;
Py_ssize_t len;
PyObject *v;
/* Coerce object */
if (PyString_Check(obj)) {
s = PyString_AS_STRING(obj);
len = PyString_GET_SIZE(obj);
}
/* Convert to Unicode */
v = PyUnicode_Decode(s, len, encoding, errors);
return v;
}
PyObject *PyUnicode_Decode(const char *s,
Py_ssize_t size,
const char *encoding,
const char *errors)
{
PyObject *buffer = NULL, *unicode;
if (encoding == NULL)
encoding = PyUnicode_GetDefaultEncoding();
/* Shortcuts for common default encodings */
if (strcmp(encoding, "utf-8") == 0)
return PyUnicode_DecodeUTF8(s, size, errors);
else if (strcmp(encoding, "latin-1") == 0)
return PyUnicode_DecodeLatin1(s, size, errors);
else if (strcmp(encoding, "ascii") == 0)
return PyUnicode_DecodeASCII(s, size, errors);
/* Decode via the codec registry */
buffer = PyBuffer_FromMemory((void *)s, size);
if (buffer == NULL)
goto onError;
unicode = PyCodec_Decode(buffer, encoding, errors);
return unicode;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
We see that when encoding is NULL, encoding is PyUnicode_GetDefaultEncoding(), which is actually the return value of our sys.getdefaultencoding(), which is ascii by default.
static char unicode_default_encoding[100 + 1] = "ascii";
const char *PyUnicode_GetDefaultEncoding(void)
{
return unicode_default_encoding;
}- 1
- 2
- 3
- 4
- 5
- 6
Here unicode_default_encoding is a static variable, and enough space is allocated for you to specify different encodings. Estimating 100 characters is certainly enough.
Let's look at getdefaultencoding and setdefaultencoding of the sys module
static PyObject *
sys_getdefaultencoding(PyObject *self)
{
return PyString_FromString(PyUnicode_GetDefaultEncoding());
}
static PyObject *
sys_setdefaultencoding(PyObject *self, PyObject *args)
{
if (PyUnicode_SetDefaultEncoding(encoding))
return NULL;
Py_INCREF(Py_None);
return Py_None;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
PyUnicode_SetDefaultEncoding doesn't have to think about setting up the unicode_default_encoding array. Python uses strncpy.
int PyUnicode_SetDefaultEncoding(const char *encoding)
{
PyObject *v;
/* Make sure the encoding is valid. As side effect, this also
loads the encoding into the codec registry cache. */
v = _PyCodec_Lookup(encoding);
if (v == NULL)
goto onError;
Py_DECREF(v);
strncpy(unicode_default_encoding,
encoding,
sizeof(unicode_default_encoding) - 1);
return 0;
onError:
return -1;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
We used to reload(sys) when sys.setdefaultencoding("utf8"), because there is such an operation in Python site.py.
if hasattr(sys, "setdefaultencoding"):
del sys.setdefaultencoding- 1
- 2
Of course, you can customize site.py, modify setencoding, use locale settings, that is, change if 0 to if 1. In general, the setting locale code of windows is cp936, and the server is utf8.
def setencoding():
"""Set the string encoding used by the Unicode implementation. The
default is 'ascii', but if you're willing to experiment, you can
change this."""
encoding = "ascii" # Default value set by _PyUnicode_Init()
if 0:
# Enable to support locale aware default string encodings.
import locale
loc = locale.getdefaultlocale()
if loc[1]:
encoding = loc[1]
if 0:
# Enable to switch off string to Unicode coercion and implicit
# Unicode to string conversion.
encoding = "undefined"
if encoding != "ascii":
# On Non-Unicode builds this will raise an AttributeError...
sys.setdefaultencoding(encoding) # Needs Python Unicode build !- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
So it's not difficult to code Python.
To play around with Python coding, you need to know.
1. The difference between unicode and utf8,gbk, and the conversion between unicode and specific coding.
2. When a string is connected to unicode, it will be converted to unicode, and str (unicode) will be converted to string.
3. The system default encoding ascii can be modified by sys.setdefaultencoding when no specific encoding is known.
If you can explain the following phenomena, you should be able to play around with Python's annoying coding problems.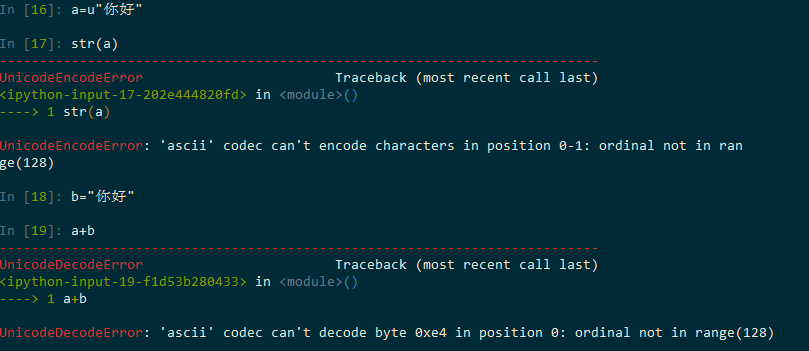
Of course, there are pits in it, such as sys.setdefaultencoding("utf8") is often seen in the group, but when print is wrong, it is actually caused by print, which will be re-coded according to sys.stdout.encoding.
Solution:
export LANG="en_US.UTF-8"- 1
Of course, I also heard many friends suggest not to use sys.setdefaultencoding, which will let you encounter a lot of pits, I have reservations about this point, the knife in your hands depends on how you use it, killing 1000 enemies, self-harm 800 or invincible.
Of course, there are pits. For example, a==b,c is a dictionary, c[a] may not be equal to c[b], because== converts the encoding, but the dictionary does not.
Here's another thing to mention. https://docs.python.org/2/library/codecs.html 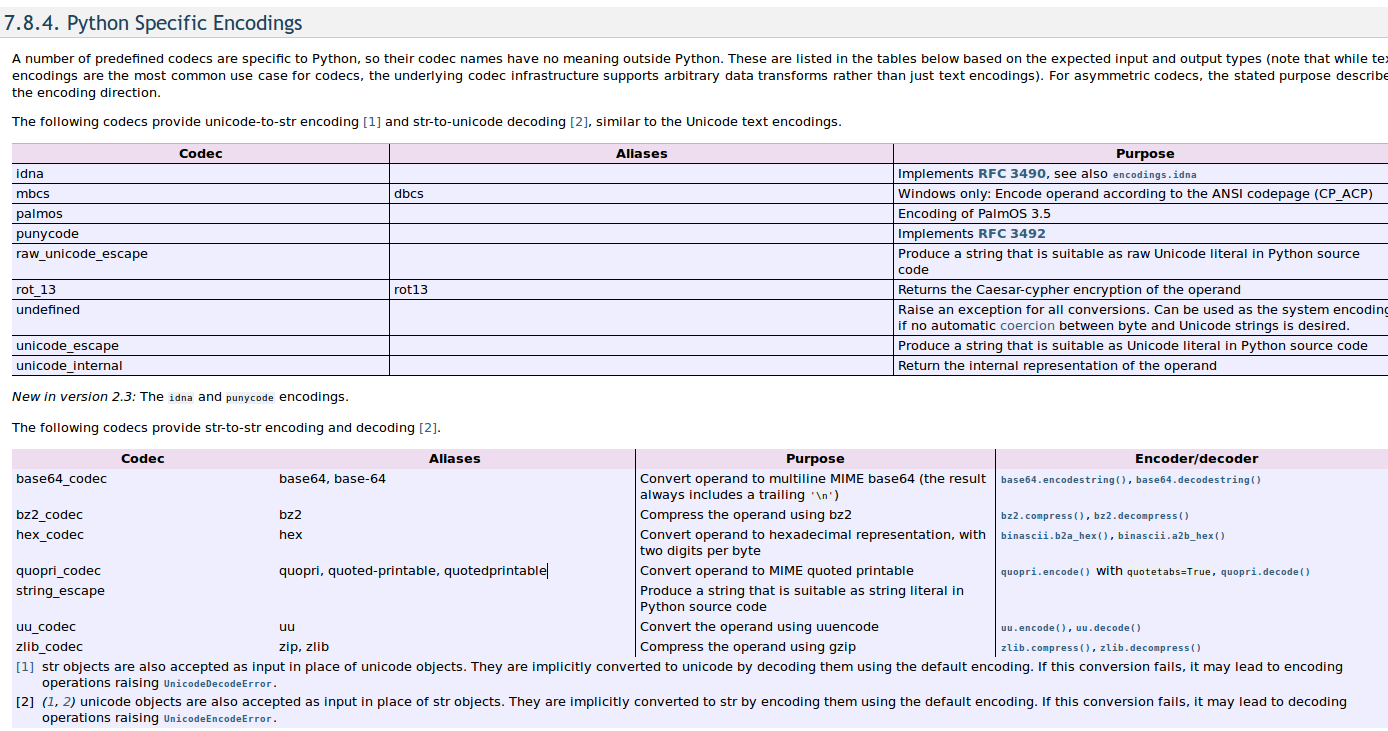
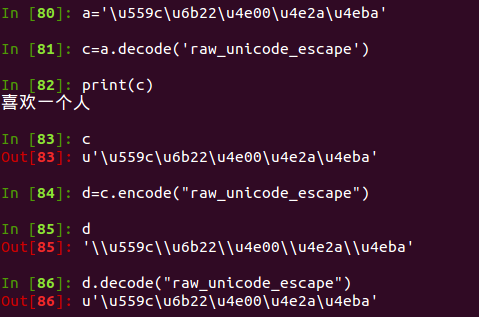
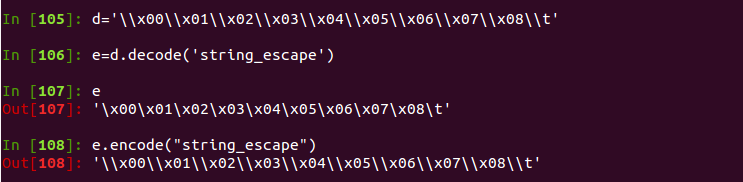
unicode_eacape provides the transformation of unicode and string.
We see that a is already a Unicode representation, but what we need is the Unicode character in python, so decode('raw_unicode_escape'), or json string returned by writing the interface.
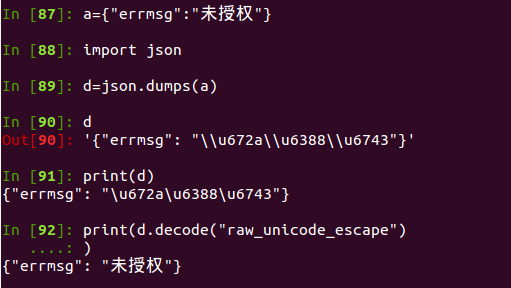
string_escape provides the conversion between string literals and python literals.