@
Relational algebra
1. Union (U)
1.1 definition:
Union (\ (\ cup \)
The result of this operation, R S, is a relationship that contains all tuples in R or S or both. Duplicate tuples do not appear in the output.
Formally: \ (R\) \(\cup\) \(S\) \(=\) \(\{\) \(t | t\) \(\in\) R or t \(\in\) S \ (\} \)
Joint compatibility: let R and S be two relationships with attributes \ ((A1, A2,..., an) \) and \ ((B1, B2,..., BN) \) respectively. If you want to merge R and S, you should meet the following two rules:
Rule 1: relationships \ (R \) and \ (S \) must have the same degree (attribute).
Rule 2: the domain of attribute \ (i \) of \ (R \) and attribute \ (i \) of S must be the same.
\(dom(A_i) = dom(B_i) \), where 1 \(\leq\) i \(\leq\) n.
1.2 example diagram

2. Difference operation
2.1 definitions
Like unions, relational difference operators require their operands to be of the same type.
Format: R - S
Formally: R - S = {t | t \ (\ in \) r and t \(\notin\) S}
Semantics: given two relationships R and s of the same type, the difference between the two relationships R-S is a relationship that contains all tuples in r that do not appear in S.
2.2 example diagram

3. Intersection
3.1 definitions
The expression r ∩ S returns all tuples that appear in relationships R and S.
Like Union and difference sets, relational intersection operators require their operands to be of the same type.
Formally: R \ (\ cap \) s = {t | t \ (\ in \) r and t \(\in\) S}
Derive from existing operator:
R \(\cap\) S = R - (R - S) = S - (S - R)
3.2 example diagram

4. Cartesian product (X)
4.1 definitions
Cartesian product or cross product is a binary operation used to combine two relationships. Suppose R and s are related to n and m attributes, Cartesian product, R × S can be written as,
R (A1, A2, ..., An) × S (B1, B2, ..., Bm)
The result of the above setting operation is,
Q (A1, A2, ..., An, B1, B2, ..., Bm)
where,
Degree (Q) = n + m
Count (q) = number of tuples in R * number of tuples in S.
4.2 example diagram

5. Select \ (\ partial \)
\(\partial_{age=19}(student)=\partial_{selection-condition}(Relation)\)
Multiple choice

6. Projection \ (\ pi \)
The projection operation is used to select only a few columns from the relationship.
\(\pi_{attributes}(Relation)\)
7.join \(\infty\)

7.1 Theta Join(\(\Theta\)) || NoEqui Join
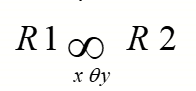
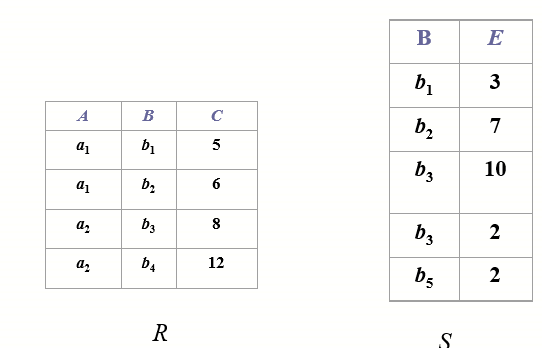
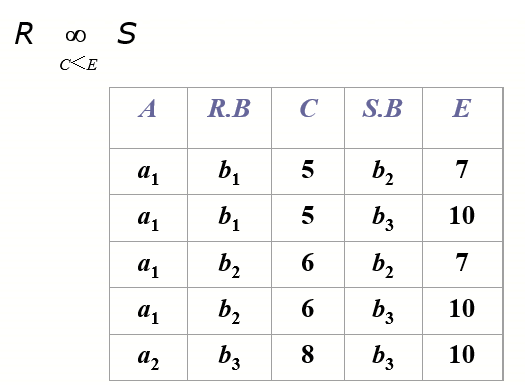
7.2 Equi join
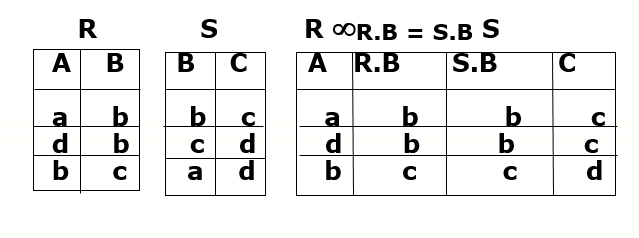
7.3 natural connection
When we omit conditions when connecting two relationships, it is called natural connection (*):
Let the relationship R1 have attributes (x1,x2,x3,M) respectively,
R2 has attributes (y1,y2,y3,y4,y5,M) respectively.
That is, the M attribute is common to the two relationships.
Then, the natural connection between R1 and R2 is a relationship with Heading(x1,x2,x3,M, y1,y2,y3,y4,y5) and body. The body is composed of all tuples, and the duplicate attribute M is deleted.
7.4 LEFT JOIN AND OUT JOIN RIGHT OUTER JOIN


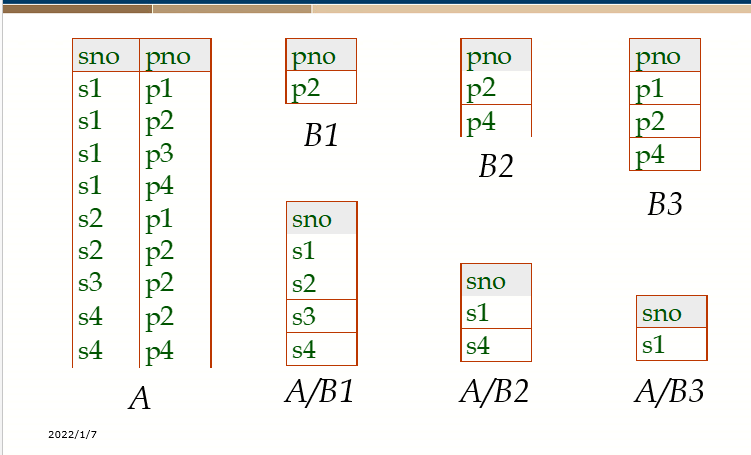
8. Division
If B contains all the attributes of A and B \ (common \) at the same time, it can be ignored directly
9. SQL statement
9.1 create database + database name
9.2 drop database + database name
9.3 ALTER TABLE Persons (ADD DateOfBirth date / MODIFY DateOfBirth year / DROP COLUMN DateOfBirth)
9.4 create table (primary key + foreign key)
CREATE TABLE rent_Info(
Order_ID int PRIMARY KEY AUTO_INCREMENT,
Date_Rented DATE NOT NULL,
Date_Returned DATE NOT NULL,
Optional_Insurance TINYINT DEFAULT 0,
Customer_ID VARCHAR(10),
Bag_ID int,
reverted TINYINT DEFAULT 0,
CONSTRAINT + (Constraint name) + FOREIGN key(Customer_ID) REFERENCES customers(Customer_ID),
CONSTRAINT FOREIGN key(Bag_ID) REFERENCES bags(Bag_ID)
);
9.5 view
create view table_name as + sentence
mysql> ALTER VIEW view_students_info
-> AS SELECT id,name,age
-> FROM tb_students_info;
mysql> DESC view_students_info;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | 0 | |
| name | varchar(45) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
drop view view_name
9.6 Oracle view

9.7 adding constraints
1.Primary key constraint add to:alter table table_name add primary key (field) delete:alter table table_name drop primary key 2.Non NULL constraint add to:alter table table_name modify Column name data type not null delete:alter table table_name modify Column name data type null 3.Unique constraint add to:alter table table_name add unique Constraint name (field) delete:alter table table_name drop key Constraint name 4.Automatic growth add to:alter table table_name modify Listing int auto_increment delete:alter table table_name modify Listing int 5.Foreign key constraint add to:alter table table_name add constraint Constraint name foreign key(Foreign key column) references Primary key table (primary key column) delete: First step:Delete foreign key alter table table_name drop foreign key Constraint name Step 2:Delete index alter table table_name drop index Index name [^1]: The constraint name is the same as the index name 6.Default value add to:alter table table_name alter Listing set default 'value' delete:alter table table_name alter Listing drop default
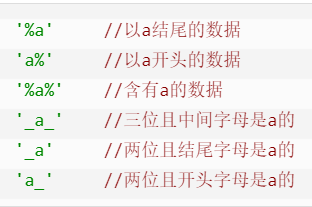
9.9 HAVING
After where and having, there are filter criteria, but there are differences:
1.where before group by, having after group by
2. Aggregate functions (avg, sum, max, min, count) cannot be placed after where as a condition, but can be placed after having
SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites INNER JOIN access_log ON Websites.id=access_log.site_id WHERE Websites.alexa < 200 GROUP BY Websites.name HAVING SUM(access_log.count) > 200;
9.10 DISTINCT
mysql> select DISTINCT(name) from info; +------+ | name | +------+ | addd | | adsd | | dcj | +------+ 3 rows in set (0.00 sec)
9.11 INNER JOIN
When using join, the differences between on and where conditions are as follows:
1. The on condition is used when generating temporary tables. It returns the records in the left table regardless of whether the condition in on is true or not.
2. The where condition is the condition for filtering the temporary table after the temporary table is generated. At this time, there is no meaning of left join (the records in the left table must be returned). If the condition is not true, all items will be filtered out.
9.12 LEFT /RIGHT JOIN
The left table lists them all

9.13 JOIN summary

9.14 ANY/ALL/IN

9.15 UNOIN / intersect / minus
The UNION operator is used to combine the result sets of two or more SELECT statements.
Note that each SELECT statement inside a UNION must have the same number of columns. Columns must also have similar data types. At the same time, the order of columns in each SELECT statement must be the same.
SELECT column_name(s) FROM table1 UNION ALL(No, ALL) Default de duplication/ instersect/ minus SELECT column_name(s) FROM table2;
9.16 sub query
9.17 Exist And No Exist


It's good to analyze layer by layer. After adding not exists, consider what information to display

9.18 UPDATE

9.19 DELETE
delete from info where age < 0;