Relevant documents
Little buddy who wants to learn Python can pay attention to the official account of Xiaobian [Python journal].
There are many resources for whoring for nothing, ha. I will update the little knowledge of Python from time to time!!
Python learning exchange group: 773162165
development environment
Python version: 3.7.8
Related modules:
requests module;
Beatifulsoup4 module;
click module;
prettytable module;
paperdl module;
And some python built-in modules.
Environment construction
Install Python and add it to the environment variable. pip can install the relevant modules required.
Principle introduction
First of all, make sure that our goal is to search for papers on Google academic, and then download the papers we searched through SCI hub. Therefore, the first step we need to achieve is to search for papers on Google academic, and simply grab the package to find: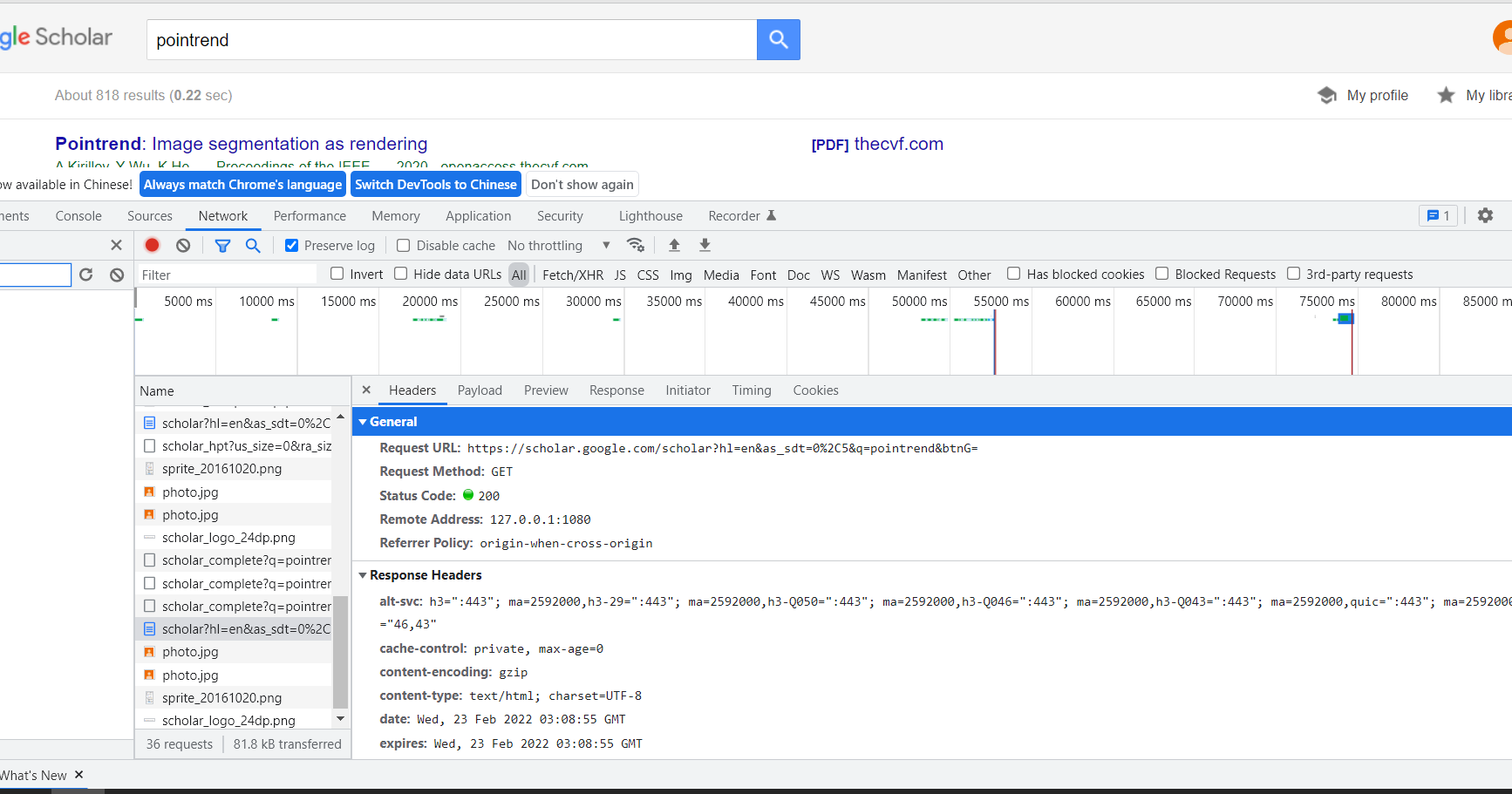
You can get the search results by requesting the following link:
https://scholar.google.com/scholar?
The parameters to be carried are also very simple:
q is the keyword of the paper we searched, and the values of other parameters can be regarded as fixed. Finally, we can extract the paper information we need with the help of the beatifulsoup4 package. Specifically, the core code is implemented as follows:
'''search paper'''
def search(self, keyword):
# search
if self.config.get('area') == 'CN':
search_url = random.choice([
'https://xs2.dailyheadlines.cc/scholar',
'https://scholar.lanfanshu.cn/scholar',
])
params = {
'hl': 'zh-CN',
'as_sdt': '0,33',
'q': keyword,
'btnG': ''
}
else:
search_url = 'https://scholar.google.com/scholar'
params = {
'hl': 'en',
'as_sdt': '0,5',
'q': keyword,
'btnG': ''
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = self.session.get(search_url, params=params, headers=headers)
# parse
soup = BeautifulSoup(response.text, features='lxml')
papers = soup.find_all('div', class_='gs_r')
paperinfos = []
for paper in papers:
try:
pdf = paper.find('div', class_='gs_ggs gs_fl')
link = paper.find('h3', class_='gs_rt')
if pdf: input_content = pdf.find('a')['href']
elif link.find('a'): input_content = link.find('a')['href']
else: continue
title = link.text
authors = paper.find('div', class_='gs_a').text.split('\xa0')[0]
paperinfo = {
'input': input_content,
'source': self.source,
'savedir': self.config['savedir'],
'ext': 'pdf',
'savename': title,
'title': title,
'authors': authors,
'download_url': None,
}
except:
continue
paperinfos.append(paperinfo)
if len(paperinfos) == self.config['search_size_per_source']: break
# return
return paperinfos
The final effect is as follows: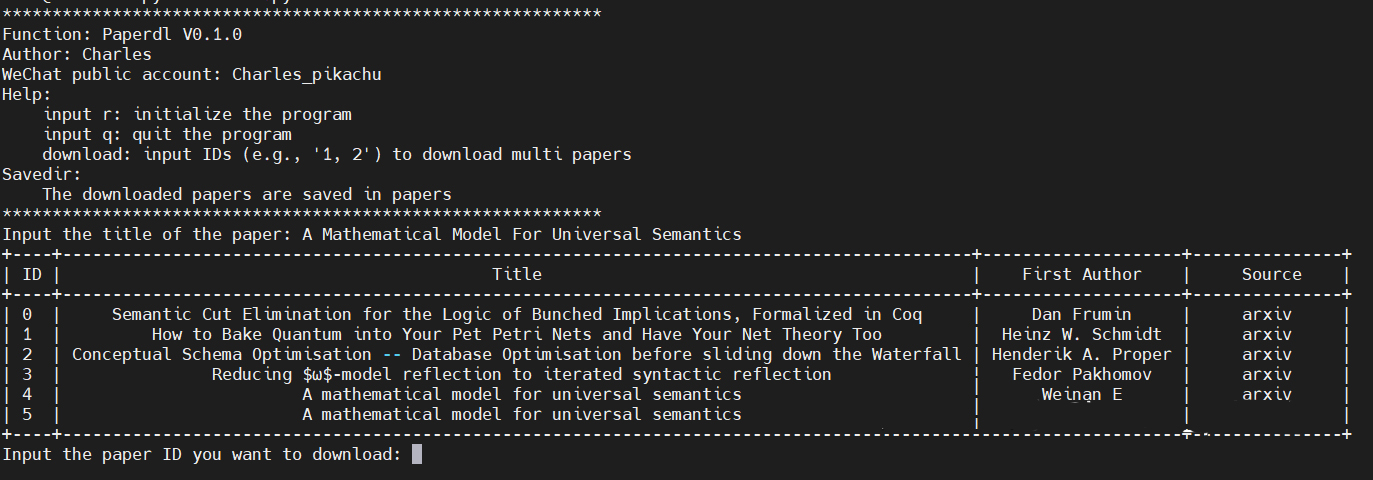
Perhaps a small partner will ask, how to use Google academic in China? In fact, everyone knows the method, but I still want to share a method that can be said on the surface, that is, using the domestic Google academic image:
If you look carefully at the code I posted, you should have found that you only need to set the area in the config file to China:
It will use the domestic Google school image by default, so my code will not be unable to use because of the wall. Moreover, I have added the function of setting proxies in my code. picture
Next, we need to use SCI hub to download the paper. The process of capturing the package is also very simple, so I won't repeat it. The final code is as follows:
'''parse paper infos before dowload paper'''
def parseinfosbeforedownload(self, paperinfos):
sci_sources = [
'https://sci-hub.st/',
'https://sci-hub.ru/',
'https://sci-hub.se/',
]
# fetch pdf url
for paperinfo in paperinfos:
input_content = paperinfo['input']
input_type = self.guessinputtype(input_content)
if input_type == 'pdf':
paperinfo['download_url'] = input_content
else:
data = {'request': input_content}
for sci_source in sci_sources:
try:
response = self.session.post(sci_source, data=data, verify=False)
html = etree.HTML(response.content)
article = html.xpath('//div[@id="article"]/embed[1]') or html.xpath('//div[@id="article"]/iframe[1]') if html is not None else None
pdf_url = urlparse(article[0].attrib['src'], scheme='http').geturl()
paperinfo['download_url'] = pdf_url
break
except:
continue
if 'download_url' not in paperinfo: paperinfo['download_url'] = None
paperinfo['source'] = self.source
# return
return paperinfos
In the code, I set up three links that are still available in SCI hub to prevent only one link from suddenly invalidating the whole code.
ok, it's done. See the relevant documents for the complete source code~
Effect display
All the code involved in this article is already open source here:
https://github.com/CharlesPikachu/paperdl
And for your convenience, it has been packaged and uploaded to pypi. You only need to install pip:
pip install paperdl
Then simply write a few lines of code:
from paperdl import paperdl
config = {'logfilepath': 'paperdl.log', 'savedir': 'papers', 'search_size_per_source': 5, 'proxies': {}}
target_srcs = ['arxiv', 'googlescholar']
client = paperdl.Paperdl(config=config)
client.run(target_srcs)
For domestic users who cannot fq, you can set config to:
config = {'area': 'CN', 'logfilepath': 'paperdl.log', 'savedir': 'papers', 'search_size_per_source': 5, 'proxies': {}}
In addition, you can only use the paper download function of scihub, for example:
from paperdl import paperdl
config = {'logfilepath': 'paperdl.log', 'savedir': 'papers', 'search_size_per_source': 5, 'proxies': {}}
client = paperdl.SciHub(config=config, logger_handle=paperdl.Logger('paper.log'))
paperinfo = {
'savename': 'mypaper',
'ext': 'pdf',
'savedir': 'outputs',
'input': 'https://ieeexplore.ieee.org/document/9193963/',
'source': 'scihub',
}
client.download([paperinfo])
The effect is as follows:
Little buddy who wants to learn Python can pay attention to the official account of Xiaobian [Python journal].
There are many resources for whoring for nothing, ha. I will update the little knowledge of Python from time to time!!
Python learning exchange group: 773162165