What is warmup
warmup is a strategy to optimize the learning rate. The main process is that during warm-up, the learning rate increases linearly (or nonlinearly) from 0 to the initial preset lr in the optimizer, and then the learning rate decreases linearly from the initial lr in the optimizer to 0. As shown in the figure below:
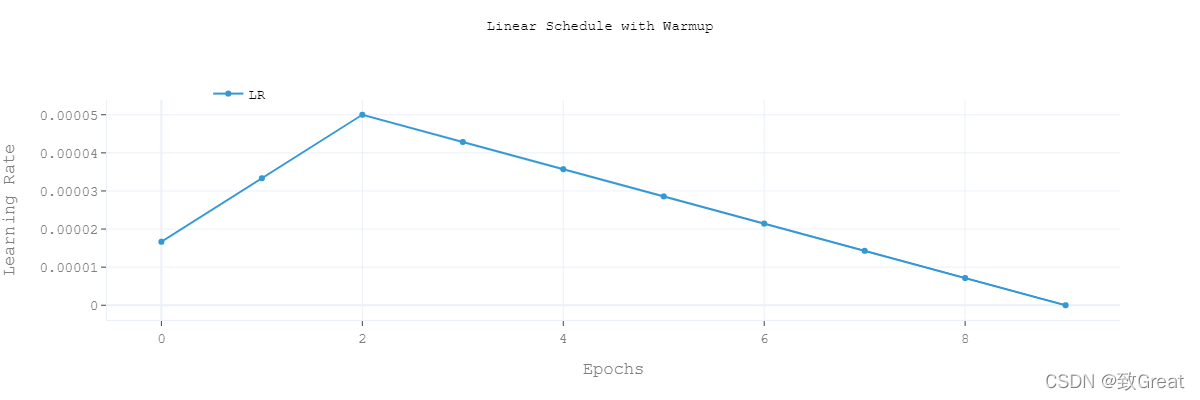
image
Role of warmup
At the beginning of training, the weights of the model are initialized randomly. At this time, if a large learning rate is selected, the model may be unstable (oscillatory). Choosing Warmup to preheat the learning rate can make the learning rate in several epoch s or step s at the beginning of training smaller. Under the preheated primary school learning rate, the model can gradually become stable, After the model is relatively stable, select the preset learning rate for training, so that the convergence speed of the model becomes faster and the effect of the model is better.
Why does warmup work
This question has not been fully proved yet. Here is the answer from Zhihu:
https://www.zhihu.com/question/338066667 Theoretically, it can be explained as follows:
- It helps to slow down the over fitting phenomenon of mini batch in advance in the initial stage of the model and maintain the stability of the distribution
- It helps to maintain the deep stability of the model
The training effect can be reflected as follows:
- At the beginning, the output of the neural network is relatively random, the loss is relatively large, and it is easy not to converge. Therefore, with a small learning rate, learn to lose and slowly rise.
- The gradient is more likely to deviate from the really better direction. If you go a little shorter, you can break it back if you make a mistake.
How to use warmup
- Example 1: warm_up_ratio sets the number of warm-up steps
from transformers import AdanW, get_linear_schedule_with_warmup optimizer = AdamW(model.parameters(), lr=lr, eps=adam_epsilon) len_dataset = 3821 # It can be calculated according to len(Dataset) in pytorch epoch = 30 batch_size = 32 total_steps = (len_dataset // batch_size) * epoch if len_dataset % batch_size = 0 else (len_dataset // batch_size + 1) * epoch # how many steps in each epoch can be calculated according to len (dataloader): total_steps = len(DataLoader) * epoch warm_up_ratio = 0.1 # Define the step to preheat scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps = warm_up_ratio * total_steps, num_training_steps = total_steps) ...... optimizer.step() scheduler.step() optimizer.zero_grad()
- Example 1: num_warmup_steps sets the number of preheating steps
# Number of training steps: [number of batches] x [number of epochs]
total_steps = len(train_dataloader) * epochs
# Designing the learning rate scheduler
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps = 50,
num_training_steps = total_steps)Empirical parameter selection
Generally, 10% of the training steps can be taken, refer to BERT. It can be adjusted according to specific tasks, mainly through warmup to make the learning rate adapt to different training sets. In addition, we can also observe the key position of loss jitter through training errors to find out the appropriate learning rate
Other nonlinear warmp strategies
def _get_scheduler(optimizer, scheduler: str, warmup_steps: int, t_total: int):
"""
Returns the correct learning rate scheduler. Available scheduler: constantlr, warmupconstant, warmuplinear, warmupcosine, warmupcosinewithhardrestarts
"""
scheduler = scheduler.lower()
if scheduler == 'constantlr':
return transformers.get_constant_schedule(optimizer)
elif scheduler == 'warmupconstant':
return transformers.get_constant_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps)
elif scheduler == 'warmuplinear':
return transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
elif scheduler == 'warmupcosine':
return transformers.get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
elif scheduler == 'warmupcosinewithhardrestarts':
return transformers.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
else:
raise ValueError("Unknown scheduler {}".format(scheduler))