1, Character set overview
Character Set is a collection of multiple characters. There are many kinds of character sets. Each Character Set contains different numbers of characters. Common Character Set names: ASCII, GB2312, BIG5, Unicode, etc.
UTF (Unicode transformation format) is one of the ways to use Unicode, that is, to convert Unicode to a certain format, including UTF-8, UTF-16 and UTF-32.
UTF-8 (8-bit Unicode Transformation Format) is a variable length character encoding for Unicode, also known as universal code.
UTF-8 encodes Unicode characters in 1 to 6 bytes. It can display Chinese simplified, traditional and other languages (such as English, Japanese and Korean) on the same page.
UTF-16 encodes Unicode code points using a sequence of one or two unallocated 16 bit code units.
UTF-32 represents each Unicode code point as a 32-bit integer with the same value.
The following is the encoding method of UTF-8:
One byte: 0xxxxxxx
2, MySQL character set
MySQL character set includes two concepts: charset and collation.
Character sets define how strings are stored, and proofing rules define how strings are compared.
MySQL8.0 supports more than 270 proofreading rules of more than 40 character sets.
You can use the following instructions to view the character sets and proofreading rules supported by MySQL system. As follows:
mysql> show charset;
MySQL8. If the table created before 0 does not specify a character set, the latin1 character set, mysql8, is used by default After 0, the default utf8mb4(most bytes 4) character set is changed. The storage node of Kunlun database adopts MySQL 8 0 architecture, of course, is also the default utf8mb4.
UTF-8, writing utf8 in MySQL, is really different.
MySQL supports utf8 from version 4.1. At that time, utf8 did not define the standard of 4-6 bytes, or MySQL designers thought that 1-3 bytes of utf8 was enough.
Therefore, utf8 designed by MySQL at that time only supports 1-3 bytes of coding, not a complete utf8. This coding method has been retained until now.
Although MySQL has added utf8mb4 character set after 5.5.3, developers are used to using utf8 and other character sets to support Chinese for some time.
MySQL's utf8 will lead to some rare Chinese character insertion errors encoded by 4 bytes.
In addition, the emoji expression on the APP side is a 4-byte character. If it is not transcoded, an exception will be reported if it is directly updated to the database.
Due to historical reasons, MySQL's utf8 is often misunderstood, which has made many developers suffer. Some online articles, such as "never use utf8 in MySQL", look scary.
Of course, in a few years, the 4-byte utf8mb4 encoding may not be enough, and MySQL will add utf8mb5 and utf8mb6.
In addition to storage, characters also need to be sorted or compared in size, involving the proofreading rules corresponding to the character set. On mysql8 Check utf8mb4 corresponding proofing rules in 0:
mysql> show collationlike 'utf8mb4%'; +----------------------------+---------+-----+---------+ | Collation | Charset | Id | Default | +----------------------------+---------+-----+---------+ |utf8mb4_0900_ai_ci | utf8mb4 |255 | Yes | |utf8mb4_0900_as_ci | utf8mb4 |305 | | |utf8mb4_0900_as_cs | utf8mb4 |278 | | |utf8mb4_0900_bin | utf8mb4 |309 | | | utf8mb4_bin | utf8mb4 | 46 | | | ................... | | | | 75 rows in set (0.00sec)
The proofreading rule of utf8mb4 defaults to utf8mb4_0900_ai_ci. 0900 refers to Unicode version 9.0.0, and the meaning of suffix is as follows:
+-------------+----------------------+-----------------+ | suffix | english | describe | +-------------+----------------------+-----------------+ | _ai | accent insensitive | Accent insensitive | | _as | accent sensitive | Accent sensitive | | _ci | case insensitive | Case insensitive | | _cs | case sensitive | Case sensitive | | _bin | binary | Binary comparison | +-------------+----------------------+-----------------+
3, For example, explain the utf8 character set of MySQL
Create two tables: utf8 and utf8mb4 character sets:
CREATE TABLE tb_utf8( `id` INT AUTO_INCREMENT, `info` VARCHAR(8), PRIMARY KEY (`id`))CHARSET=utf8; CREATE TABLE tb_utf8mb4( `id` INT AUTO_INCREMENT, `info` VARCHAR(8), PRIMARY KEY (`id`)); #The default is utf8mb4
Insert data:
insert into tb_utf8(info) values("Kunlun database");
insert into tb_utf8(info) values("Kunlun database A12");
insert into tb_utf8(info) values("Kunlun database A123");#More than 8 characters failed
Check the table data and the occupied space:
mysql> selectinfo,length(info) from tb_utf8; +--------------------+--------------+ | info | length(info) | +--------------------+--------------+ | Kunlun database | 15 | | Kunlun database A12 | 18 | +--------------------+--------------+ 2 rows in set (0.00sec)
It can be seen that in the utf8 character set, general Chinese characters occupy 3 bytes and English and numbers occupy 1 byte.
Next, try the emoji expression package of 4 bytes:
Failed to insert 4-byte emoji expression package.
Because most SSH tools do not support 4-byte UTF-8 character display, the author demonstrated it directly in the Terminal of Ubuntu 20 system. The 4-byte remote Chinese characters can't find the supported Terminal interface for the time being, so we won't demonstrate it here.
We insert emoji expression package into the utf8mb4 table that supports 4 bytes, and check the data and occupied space: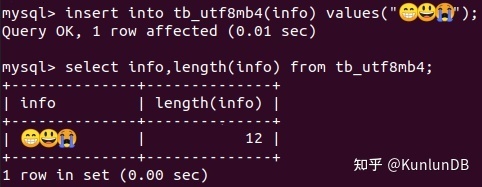
Finally, let's look at the verification rules in TB_ Insert some data into utf8mb4:
insert into tb_utf8mb4(info) values("ABC");
insert into tb_utf8mb4(info) values("Abc");
insert into tb_utf8mb4(info) values("abc"); Check the data and three records are displayed:
mysql> select info from tb_utf8mb4 where info="abc"; +------+ | info | +------+ | ABC | | Abc | | abc | +------+ 3 rows in set (0.00 sec)
This proofreading rule is very easy to use in case insensitive scenarios such as web addresses and email addresses, but if we need to be case sensitive, we can modify the proofreading rules:
alter table tb_utf8mb4 modify info varchar(8) collate utf8mb4_0900_as_cs;
Check this record again:
mysql> select info from tb_utf8mb4 where info="abc"; +------+ | info | +------+ | abc | +------+ 1 row in set (0.00 sec)
That's all for MySQL character set. Let's popularize the basic knowledge of database.
KunlunDB project is open source
[GitHub: ]
https://github.com/zettadb
[Gitee: ]
https://gitee.com/zettadb
END