Introduction to current limiting
Now when it comes to high availability systems, we will talk about high availability protection methods: caching, degradation and current limiting. This blog will mainly talk about current limiting. Current limit is the abbreviation of Rate Limit, which means that only specified events are allowed to enter the system, and the exceeding part will be processed by denial of service, queuing or waiting, degradation, etc. For the server service, in order to ensure that part of the request traffic can get a normal response, it is better than that all requests can not get a response, and even lead to system avalanche. Current limiting and fusing are often confused. Bloggers believe that their biggest difference is that current limiting is mainly implemented in the server, while fusing is mainly implemented in the client. Of course, a service can act as both a server and a client. This also makes current limiting and fusing exist in one service at the same time, so these two concepts are easy to be confused.
Then why do you need current limiting? Many people's first reaction is that they can't afford the service, so they need to limit the flow. This is not a comprehensive statement. Bloggers believe that flow restriction is due to the scarcity of resources or self-protection measures taken for the purpose of security. Flow restriction can ensure that limited resources are used to provide maximum service capacity, and services are provided according to the expected traffic. The excess part will be rejected, queued or waiting, degraded and so on.
Current systems support current limiting differently, but there are some standards. "429 Too Many Requests" is specified in the HTTP RFC 6585 standard. The 429 status code indicates that the user has sent too many requests within a given time and needs to limit the flow (rate limit). At the same time, it contains a retry after response header to tell the client how long it can request services again.
HTTP/1.1 429 Too Many Requests
Content-Type: text/html
Retry-After: 3600
<title>Too Many Requests</title>
<h1>Too Many Requests</h1>
<p>I only allow 50 requests per hour to this Web site per
logged in user. Try again soon.</p>
Many application frameworks also integrate the current limit function and give a clear current limit ID in the returned Header.
- X-Rate-Limit-Limit: the maximum number of requests allowed in the same time period;
- X-rate-limit-maintaining: the number of remaining requests in the current time period;
- X-Rate-Limit-Reset: the number of seconds to wait to get the maximum number of requests.
This is to tell the caller about the current limiting frequency of the server through the response Header to ensure the upper limit of interface access at the back end. The client can also adjust the request according to the response Header.
Current limiting classification
In terms of current limit and splitting, there are two words: limit and current. Limit is verb limit, which is easy to understand. However, the flow is different resources or indicators under different scenarios, and the diversity is reflected in the flow. It can be byte stream in network traffic, TPS in database, QPS or concurrent requests in API, and inventory in goods But no matter what kind of "flow", the flow must be quantifiable, measurable, observable and statistical. We classify current limiting into different categories based on different ways, as shown in the figure below.
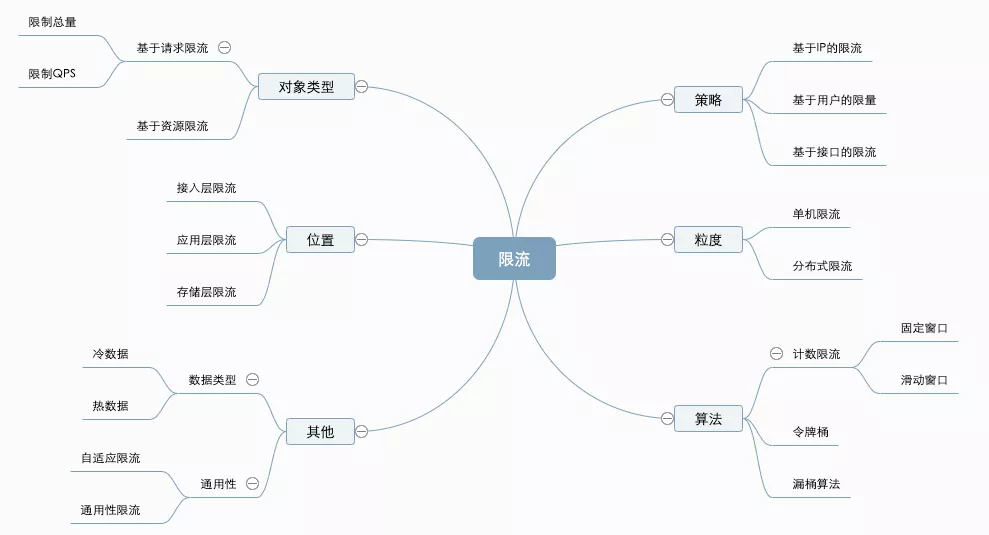
Current limiting classification
Because of the limited space, this paper will only select a few common types for description.
Current limiting particle size classification
Classification according to particle size of current limiting:
- Single machine current limiting
- Distributed current limiting
The current systems are basically distributed architecture, and there are few single machine models. The single machine current limit here is more accurate, that is, single service node current limit. Single machine current limit means that the request enters a service node and exceeds the current limit threshold, and the service node takes a current limit protection measure.
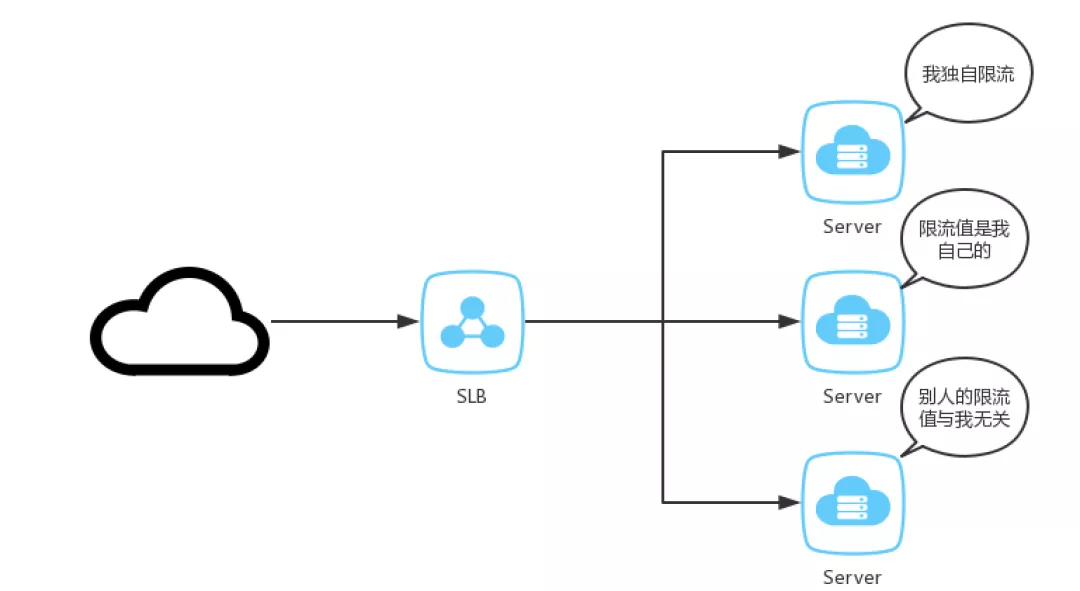
Schematic diagram of single machine current limiting
In the narrow sense, distributed current limiting is to realize multi node combined current limiting in the access layer, such as NGINX+redis, distributed gateway, etc. in the broad sense, distributed current limiting is the organic integration of multiple nodes (which can be different service nodes) to form an overall current limiting service.
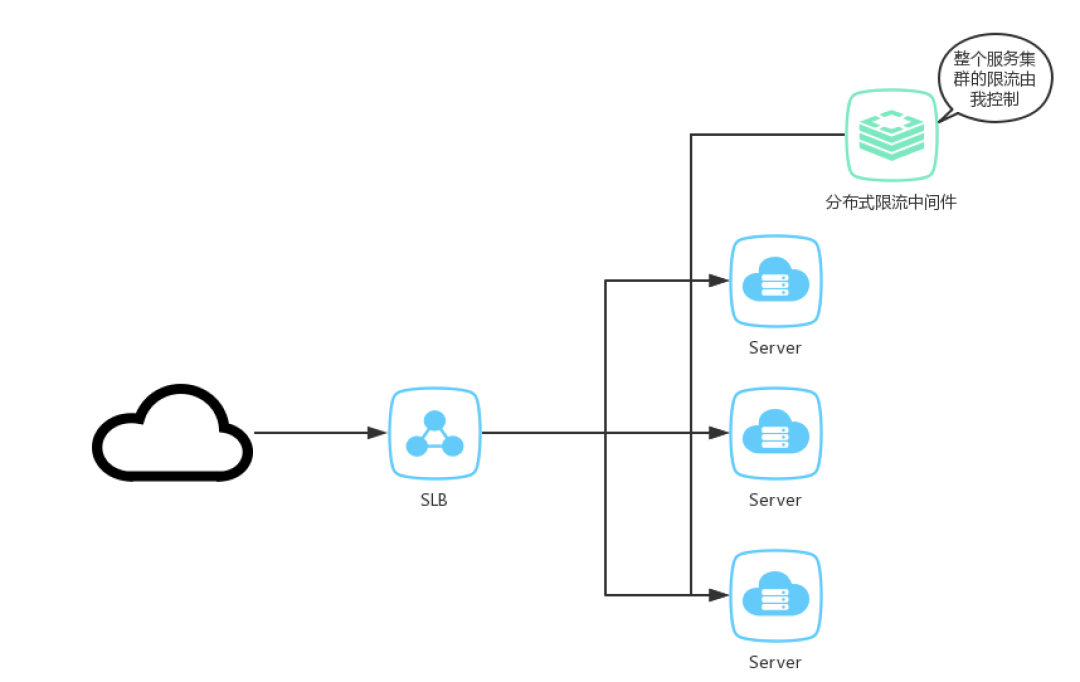
Distributed current limiting diagram
Single machine current limiting prevents traffic from crushing the service node and lacks the perception of the overall traffic. Distributed current limiting is suitable for different fine-grained current limiting control, and different current limiting rules can be matched according to different scenarios. The biggest difference from single machine current limiting is that distributed current limiting requires centralized storage. redis is commonly used. With the introduction of centralized storage, the following problems need to be solved:
- The consistency of data flow pattern is ideal. The definition of point in time consistency requires that the data of all data components are completely consistent at any time, but generally speaking, the maximum speed of information transmission is the speed of light. In fact, it can not be consistent at any time. There is always a certain time inconsistency. For the consistency in our CAP, it is only necessary to read the latest data, Achieving this does not require strict arbitrary time consistency. This can only be a consistency model in theory, which can achieve linear consistency in current limiting.
- Time consistency the time consistency here is different from the time point consistency above, which refers to the time consistency of each service node. A cluster has three machines, but the time of A/B machine is Tue Dec 3 16:29:28 CST 2019 and C is Tue Dec 3 16:29:28 CST 2019, so their time is inconsistent. There will also be some errors when ntpdate is used for synchronization. The algorithm sensitive to the time window is the error point.
- Timeout requires network communication in the distributed system. There will be network jitter, or the response will be slow due to excessive pressure on the distributed current limiting middleware, or even the timeout threshold setting is unreasonable, resulting in the timeout of the application service node. Is it to release traffic or reject traffic?
- Performance and reliability the resources of distributed current limiting middleware are always limited, and may even be single point (write single point). There is an upper limit on the performance. If the distributed current limiting middleware is not available, how to degenerate to the single machine current limiting mode is also a good degradation scheme.
Current limiting object type classification
Classification by object type:
- Request based current limiting
- Resource based current limiting
Based on request current limiting, the general implementation methods include limiting the total amount and limiting QPS. Limiting the total amount is to limit the upper limit of a certain index. For example, if you rush to buy a commodity and the volume is 10w, you can only sell 10w pieces at most. For wechat's red envelope grabbing, one red envelope in the group is divided into 10, so at most 10 people can grab it. When the eleventh person opens it, it will show "slow hand, red envelope sending is over".

The red envelope was robbed
Limiting QPS is also the current limiting method we often say. As long as it is carried out at the interface level, an interface can only be accessed 100 times in one second, then its peak QPS can only be 100. The most difficult point in limiting QPS is how to estimate the threshold and how to locate the threshold, which will be discussed below.
Resource based flow restriction is based on the usage of service resources. It is necessary to locate and limit the key resources of the service, such as limiting the number of TCP connections, threads, memory usage, etc. Limiting resources can more effectively reflect the current cleaning of services, but similar to limiting QPS, it is faced with how to confirm the threshold of resources. This threshold needs to be constantly tuned and practiced to get a satisfactory value.
Current limiting algorithm classification
No matter according to what dimension and based on what method of classification, the bottom layer of current limiting needs to be realized by algorithm. The following describes the common current limiting algorithms:
- Counter
- Token Bucket
- Leaky bucket algorithm
Counter
Fixed window counter
Counting current limiting is the simplest current limiting algorithm. In daily development, many of our current limiting algorithms are fixed window counting current limiting algorithms. For example, an interface or service can only receive 1000 requests at most in 1s, so we will set its current limiting to 1000QPS. The implementation idea of the algorithm is very simple. Maintain a counter in a fixed unit time. If it is detected that the unit time has passed, reset the counter to zero.
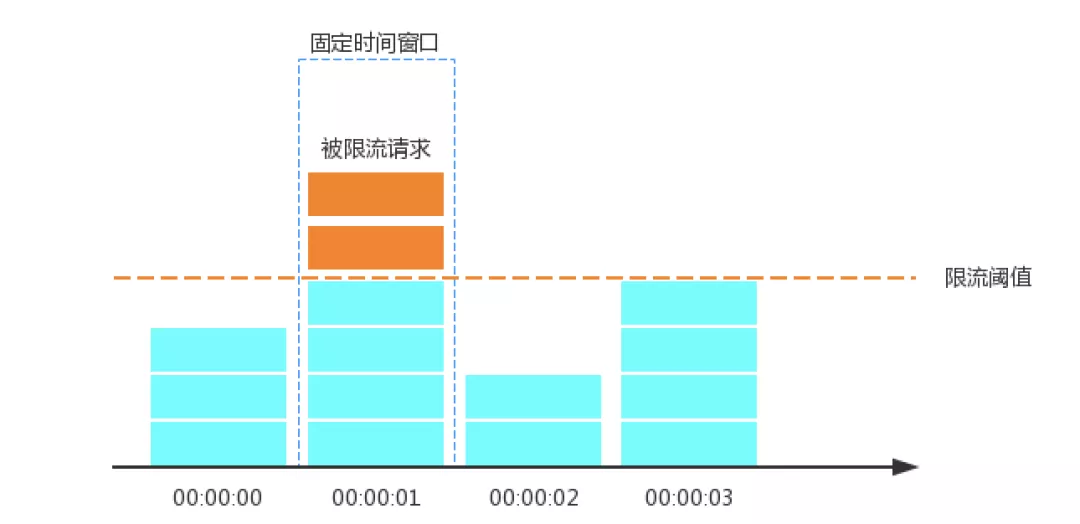
Principle of fixed window counter
Operation steps:
- The timeline is divided into multiple independent and fixed size windows;
- The request falling in each time window will increase the counter by 1;
- If the counter exceeds the current limit threshold, subsequent requests falling in the window will be rejected. However, when the time reaches the next time window, the counter will be reset to 0.
Here is a simple code.
package limit
import (
"sync/atomic"
"time"
)
type Counter struct {
Count uint64 // Initial counter
Limit uint64 // Maximum request frequency per unit time window
Interval int64 // Unit ms
RefreshTime int64 // time window
}
func NewCounter(count, limit uint64, interval, rt int64) *Counter {
return &Counter{
Count: count,
Limit: limit,
Interval: interval,
RefreshTime: rt,
}
}
func (c *Counter) RateLimit() bool {
now := time.Now().UnixNano() / 1e6
if now < (c.RefreshTime + c.Interval) {
atomic.AddUint64(&c.Count, 1)
return c.Count <= c.Limit
} else {
c.RefreshTime = now
atomic.AddUint64(&c.Count, -c.Count)
return true
}
}
Test code:
package limit
import (
"fmt"
"testing"
"time"
)
func Test_Counter(t *testing.T) {
counter := NewCounter(0, 5, 100, time.Now().Unix())
for i := 0; i < 10; i++ {
go func(i int) {
for k := 0; k <= 10; k++ {
fmt.Println(counter.RateLimit())
if k%3 == 0 {
time.Sleep(102 * time.Millisecond)
}
}
}(i)
}
time.Sleep(10 * time.Second)
}
After reading the above logic, do you think the fixed window counter is very simple? Yes, it is so simple. This is one of its advantages. It is easy to implement. At the same time, there are two serious defects. Imagine that the 1s current limit threshold in the fixed time window is 100, but 99 requests have been made in the first 100ms, so the subsequent 900ms can only pass one, which is a defect and basically has no ability to deal with sudden traffic. The second defect is that 100 requests pass within the last 500ms of the time window of 00:00:00, and 100 requests pass within the first 500ms of the time window of 00:00:01. For the service, the amount of requests reaches twice the current limit threshold within 1 second.
Sliding window counter
Sliding time window algorithm is an improvement of fixed time window algorithm, which is well known in TCP traffic control. Fixed window counter is a special case of sliding window counter. The operation steps of sliding window are as follows:
- The unit time is divided into multiple intervals, which are generally divided into multiple small time periods;
- Each interval has a counter. If a request falls within the interval, the counter in the interval will be increased by one;
- After each time period, the time window will slide one grid to the right, abandon the oldest interval and incorporate it into a new interval;
- When calculating the total number of requests in the whole time window, the counters in all time segments will be accumulated. If the total count exceeds the limit, all requests in this window will be discarded.
The finer the time window is divided and "sliding" according to time, this algorithm avoids the above two problems of fixed window counters. The disadvantage is that the higher the accuracy of the time interval, the larger the space capacity required by the algorithm.
Common implementation methods mainly include redis zset based implementation and circular queue implementation. Based on redis zset, the Key can be limited to the current ID, and the Value can be unique. It can be generated with UUID. The Score is also recorded as the same timestamp, preferably nanosecond. Use ZADD, exhibit, ZCOUNT and zremrangebyscore provided by redis to achieve this, and pay attention to turning on Pipeline to improve performance as much as possible. The implementation is very simple, but the disadvantage is that the data structure of zset will be larger and larger.
Leaky bucket algorithm
The leaky bucket algorithm is that the water enters the leaky bucket first, and then the leaky bucket leaves the water at a certain rate. When the amount of inflow water is greater than the outflow water, the excess water overflows directly. In terms of replacing water with requests, the leaky bucket is equivalent to the server queue, but when the number of requests is greater than the current limit threshold, the extra requests will be rejected. The leaky bucket algorithm is implemented by queue, which can control the access speed of traffic at a fixed rate and "flatten" the traffic.
You can understand it through the most popular picture on the Internet.
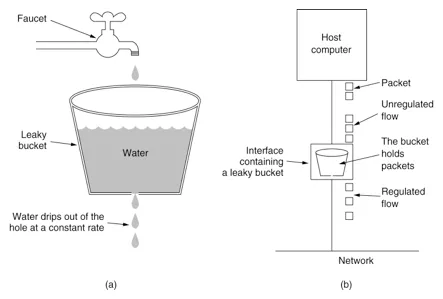
Principle of leaky bucket algorithm
Implementation steps of leaky bucket algorithm:
- Put each request into a fixed size queue for storage;
- The queue flows out the request at a fixed rate. If the queue is empty, the outflow will be stopped;
- If the queue is full, redundant requests will be rejected directly·
Leaky bucket algorithm has an obvious defect: when there are a large number of sudden requests in a short time, even if the server load is not high, each request must wait in the queue for a period of time to be responded.
Token Bucket
The principle of token bucket algorithm is that the system will put tokens into the bucket at a constant rate. If the request needs to be processed, you need to obtain a token from the bucket first. When there is no token in the bucket, the service will be denied. In principle, token bucket algorithm and leaky bucket algorithm are opposite. The former is "in" and the latter is "out". In addition to the difference in "direction" between the leaky bucket algorithm and the token bucket algorithm, there is a more important difference: the token bucket algorithm limits the average inflow rate (allows burst requests, as long as there are enough tokens to support multiple tokens at one time), and allows a certain degree of burst flow;
Implementation steps of token bucket algorithm:
- The token is generated at a fixed rate and put into the token bucket;
- If the token bucket is full, the redundant tokens will be directly discarded. When the request arrives, it will try to get the token from the token bucket, and the request with the token can be executed;
- If the bucket is empty, the request is rejected.
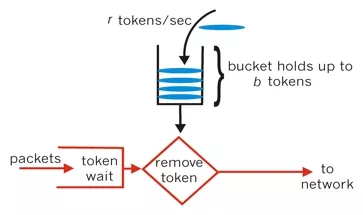
Principle of token bucket algorithm
How to choose the four strategies?
- Fixed window: the implementation is simple, but it is too rough. Unless the situation is urgent, in order to stop the loss quickly, the immediate problem can be used as a temporary emergency plan.
- Sliding window: the current limiting algorithm is simple and easy to implement, and can deal with scenarios with a small amount of sudden increase in traffic.
- Leaky bucket: there are strong requirements for the absolute uniformity of flow. The utilization rate of resources is not extreme, but its wide in and strict out mode leaves some margin while protecting the system. It is a universal scheme.
- Token bucket: the system often has a sudden increase in traffic and squeeze the performance of the service as much as possible.
How to limit current?
No matter which classification or implementation method is used, the system will face a common problem: how to confirm the current limiting threshold. Some teams set a small threshold according to their experience, and then adjust it slowly; Some teams are summarized through stress testing. The problem with this method is that the pressure measurement model is not necessarily consistent with the online environment, the single pressure of the interface can not feed back the state of the whole system, and the full link pressure measurement is difficult to truly reflect the actual traffic scene traffic ratio. Another idea is to monitor data through pressure measurement + applications. The problem is that the inflection point of system performance is unknown, and the simple prediction is not necessarily accurate or even deviates greatly from the real scene. As stated in Overload Control for Scaling WeChat Microservices, in systems with complex dependencies, overload control of specific services may be harmful to the whole system or the implementation of services may be defective. It is hoped that a more AI operation feedback system can automatically set the current limit threshold in the future, which can dynamically carry out overload protection according to the current QPS, resource status, RT and other related data.
No matter which way the current limiting threshold is given, the system should pay attention to the following points:
- Operation indicator status, such as QPS of the current service, machine resource usage, number of database connections, number of concurrent threads, etc;
- The calling relationship between resources, external link requests, associations between internal services, strong and weak dependencies between services, etc;
- Control mode, such as direct rejection, rapid failure, queuing and waiting for subsequent requests after reaching the current limit
Use of go current limiting class library
There are many current limiting class libraries. Different languages have different class libraries, such as concurrency limits, Sentinel, Guava, etc. These class libraries have many analysis and use methods. This paper mainly introduces the current limiting class library of Golang, which is the extension library of Golang: https://github.com/golang/time/rate . The code that can enter the language class library is worth studying. Do students who have studied Java lament the subtlety of AQS design! Time / rate , also has its subtle part. Let's start to enter the class library learning stage.
github.com/golang/time/rate
Before analyzing the source code, the most important thing to do is to understand the usage mode, usage scenario and API of the class library. With a preliminary understanding of the business, you can get twice the result with half the effort by reading the code. Because of the limited space, subsequent blog posts are analyzing the source code of multiple current limiting class libraries. API document of class library: https://godoc.org/golang.org/x/time/rate . Time / rate class library is a current limiting function based on token bucket algorithm. The principle of token bucket algorithm mentioned earlier is that the system will put tokens into the bucket at a constant rate, then the bucket has a fixed size, the rate of putting tokens into the bucket is also constant, and burst traffic is allowed. Viewing the document found a function:
func NewLimiter(r Limit, b int) *Limiter
newLimiter returns a new limiter that allows the rate of events to reach R and allows up to b tokens to burst. In other words, Limter limits the frequency of occurrence of time, but the bucket has a capacity of b at the beginning, and is filled with b tokens (there are at most b tokens in the token pool, so only b events can occur at a time, and one token is spent for each event), and then put r tokens into the bucket at each unit time interval (1s by default).
limter := rate.NewLimiter(10, 5)
The above example shows that the capacity of the token bucket is 5, and 10 tokens are put into the bucket every second. Careful readers will find that the first parameter of the function newlimit is the Limit type. You can see the source code and find that Limit is actually the alias of float64.
// Limit defines the maximum frequency of some events. // Limit is represented as number of events per second. // A zero Limit allows no events. type Limit float64
The current limiter can also specify the time interval for putting tokens into the bucket, which is implemented as follows:
limter := rate.NewLimiter(rate.Every(100*time.Millisecond), 5)
The effect of these two examples is the same. Using the first method, 10 tokens will not be placed at one time at an interval of every second, but will also be placed evenly at an interval of 100ms. rate.Limiter provides three methods to limit speed:
- Allow/AllowN
- Wait/WaitN
- Reserve/ReserveN
The usage and applicable scenarios of these three types of current limiting methods are compared below. Let's look at the first method:
func (lim *Limiter) Allow() bool func (lim *Limiter) AllowN(now time.Time, n int) bool
Allow is a simplified method of allow (time. Now(), 1). The focus is on the method allow. The API explanation is a little abstract and confusing. You can see the following API document explanation:
AllowN reports whether n events may happen at time now. Use this method if you intend to drop / skip events that exceed the rate limit. Otherwise use Reserve or Wait.
In fact, it is to say whether the method allow can take N tokens from the token bucket at the specified time. This means that it is possible to limit whether N events can occur simultaneously at a specified time. These two methods are non blocking, that is, once they are not satisfied, they will skip and will not wait for the number of tokens to be sufficient. That is, the second line in the document explains that if you intend to lose or skip the time exceeding the rate limit, please use this method for a long time. For example, using the previously instantiated current limiter, at a certain time, the server receives more than 8 requests at the same time. If there are less than 8 tokens in the token bucket, these 8 requests will be discarded. A small example:
func AllowDemo() {
limter := rate.NewLimiter(rate.Every(200*time.Millisecond), 5)
i := 0
for {
i++
if limter.Allow() {
fmt.Println(i, "====Allow======", time.Now())
} else {
fmt.Println(i, "====Disallow======", time.Now())
}
time.Sleep(80 * time.Millisecond)
if i == 15 {
return
}
}
}
Execution results:
1 ====Allow====== 2019-12-14 15:54:09.9852178 +0800 CST m=+0.005998001 2 ====Allow====== 2019-12-14 15:54:10.1012231 +0800 CST m=+0.122003301 3 ====Allow====== 2019-12-14 15:54:10.1823056 +0800 CST m=+0.203085801 4 ====Allow====== 2019-12-14 15:54:10.263238 +0800 CST m=+0.284018201 5 ====Allow====== 2019-12-14 15:54:10.344224 +0800 CST m=+0.365004201 6 ====Allow====== 2019-12-14 15:54:10.4242458 +0800 CST m=+0.445026001 7 ====Allow====== 2019-12-14 15:54:10.5043101 +0800 CST m=+0.525090301 8 ====Allow====== 2019-12-14 15:54:10.5852232 +0800 CST m=+0.606003401 9 ====Disallow====== 2019-12-14 15:54:10.6662181 +0800 CST m=+0.686998301 10 ====Disallow====== 2019-12-14 15:54:10.7462189 +0800 CST m=+0.766999101 11 ====Allow====== 2019-12-14 15:54:10.8272182 +0800 CST m=+0.847998401 12 ====Disallow====== 2019-12-14 15:54:10.9072192 +0800 CST m=+0.927999401 13 ====Allow====== 2019-12-14 15:54:10.9872224 +0800 CST m=+1.008002601 14 ====Disallow====== 2019-12-14 15:54:11.0672253 +0800 CST m=+1.088005501 15 ====Disallow====== 2019-12-14 15:54:11.1472946 +0800 CST m=+1.168074801
The second method: because ReserveN is complex, the second method is WaitN.
func (lim *Limiter) Wait(ctx context.Context) (err error) func (lim *Limiter) WaitN(ctx context.Context, n int) (err error)
Similar to Wait is a simplified method of WaitN(ctx, 1). Different from allow, WaitN will block. If the number of tokens in the token bucket is less than N, WaitN will block for a period of time. The duration of blocking time can be set with the first parameter ctx, and the context instance is context Withdeadline or context Withtimeout specifies the duration of blocking.
func WaitNDemo() {
limter := rate.NewLimiter(10, 5)
i := 0
for {
i++
ctx, canle := context.WithTimeout(context.Background(), 400*time.Millisecond)
if i == 6 {
// Cancel execution
canle()
}
err := limter.WaitN(ctx, 4)
if err != nil {
fmt.Println(err)
continue
}
fmt.Println(i, ",Execution:", time.Now())
if i == 10 {
return
}
}
}
Execution results:
1 ,Execution: 2019-12-14 15:45:15.538539 +0800 CST m=+0.011023401 2 ,Execution: 2019-12-14 15:45:15.8395195 +0800 CST m=+0.312003901 3 ,Execution: 2019-12-14 15:45:16.2396051 +0800 CST m=+0.712089501 4 ,Execution: 2019-12-14 15:45:16.6395169 +0800 CST m=+1.112001301 5 ,Implementation: 2019-12-14 15:45:17.0385893 +0800 CST m=+1.511073701 context canceled 7 ,Execution: 2019-12-14 15:45:17.440514 +0800 CST m=+1.912998401 8 ,Execution: 2019-12-14 15:45:17.8405152 +0800 CST m=+2.312999601 9 ,Execution: 2019-12-14 15:45:18.2405402 +0800 CST m=+2.713024601 10 ,Execution: 2019-12-14 15:45:18.6405179 +0800 CST m=+3.113002301
It is applicable to scenarios that allow blocking waiting, such as consuming messages from message queues. The maximum consumption rate can be limited. If it is too large, it will be limited to avoid excessive consumer load.
The third method:
func (lim *Limiter) Reserve() *Reservation func (lim *Limiter) ReserveN(now time.Time, n int) *Reservation
Different from the previous two methods, Reserve/ReserveN returns the reservation instance. Reservation has five methods in the API document:
func (r *Reservation) Cancel() // Equivalent to CancelAt(time.Now()) func (r *Reservation) CancelAt(now time.Time) func (r *Reservation) Delay() time.Duration // Equivalent to DelayFrom(time.Now()) func (r *Reservation) DelayFrom(now time.Time) time.Duration func (r *Reservation) OK() bool
These five methods allow developers to operate according to business scenarios. Compared with the first two types of automation, such operations are much more complex. Learn reserve / reserve n through a small example:
func ReserveNDemo() {
limter := rate.NewLimiter(10, 5)
i := 0
for {
i++
reserve := limter.ReserveN(time.Now(), 4)
// If it is false, it indicates that the specified number of tokens cannot be obtained, such as the scenario where the number of tokens required is greater than the capacity of the token bucket
if !reserve.OK() {
return
}
ts := reserve.Delay()
time.Sleep(ts)
fmt.Println("Execution:", time.Now(),ts)
if i == 10 {
return
}
}
}
Execution results:
Execution: 2019-12-14 16:22:26.6446468 +0800 CST m=+0.008000201 0s Execution: 2019-12-14 16:22:26.9466454 +0800 CST m=+0.309998801 247.999299ms Execution: 2019-12-14 16:22:27.3446473 +0800 CST m=+0.708000701 398.001399ms Execution: 2019-12-14 16:22:27.7456488 +0800 CST m=+1.109002201 399.999499ms Execution: 2019-12-14 16:22:28.1456465 +0800 CST m=+1.508999901 398.997999ms Execution: 2019-12-14 16:22:28.5456457 +0800 CST m=+1.908999101 399.0003ms Execution: 2019-12-14 16:22:28.9446482 +0800 CST m=+2.308001601 399.001099ms Execution: 2019-12-14 16:22:29.3446524 +0800 CST m=+2.708005801 399.998599ms Execution: 2019-12-14 16:22:29.7446514 +0800 CST m=+3.108004801 399.9944ms Execution: 2019-12-14 16:22:30.1446475 +0800 CST m=+3.508000901 399.9954ms
If you Cancel() before executing Delay(), the returned time interval will be 0, which means that the operation can be performed immediately without current limiting.
func ReserveNDemo2() {
limter := rate.NewLimiter(5, 5)
i := 0
for {
i++
reserve := limter.ReserveN(time.Now(), 4)
// If it is false, it indicates that the specified number of tokens cannot be obtained, such as the scenario where the number of tokens required is greater than the capacity of the token bucket
if !reserve.OK() {
return
}
if i == 6 || i == 5 {
reserve.Cancel()
}
ts := reserve.Delay()
time.Sleep(ts)
fmt.Println(i, "Execution:", time.Now(), ts)
if i == 10 {
return
}
}
}
Execution results:
1 Execution: 2019-12-14 16:25:45.7974857 +0800 CST m=+0.007005901 0s 2 Execution: 2019-12-14 16:25:46.3985135 +0800 CST m=+0.608033701 552.0048ms 3 Execution: 2019-12-14 16:25:47.1984796 +0800 CST m=+1.407999801 798.9722ms 4 Execution: 2019-12-14 16:25:47.9975269 +0800 CST m=+2.207047101 799.0061ms 5 Execution: 2019-12-14 16:25:48.7994803 +0800 CST m=+3.009000501 799.9588ms 6 Execution: 2019-12-14 16:25:48.7994803 +0800 CST m=+3.009000501 0s 7 Execution: 2019-12-14 16:25:48.7994803 +0800 CST m=+3.009000501 0s 8 Execution: 2019-12-14 16:25:49.5984782 +0800 CST m=+3.807998401 798.0054ms 9 Execution: 2019-12-14 16:25:50.3984779 +0800 CST m=+4.607998101 799.0075ms 10 Execution: 2019-12-14 16:25:51.1995131 +0800 CST m=+5.409033301 799.0078ms
See here that the current limiting mode of time/rate has been completed. In addition to the above three current limiting modes, time/rate also provides the function of dynamically adjusting the parameters of current limiter. Relevant API s are as follows:
func (lim *Limiter) SetBurst(newBurst int) // It is equivalent to setburst at (time. Now(), newburst) func (lim *Limiter) SetBurstAt(now time.Time, newBurst int)// Resets the capacity of the token bucket func (lim *Limiter) SetLimit(newLimit Limit) // Equivalent to SetLimitAt(time.Now(), newLimit) func (lim *Limiter) SetLimitAt(now time.Time, newLimit Limit)// Resets the rate at which tokens are put
These four methods allow the program to dynamically adjust the token bucket rate and token bucket capacity according to its own state.
ending
Through the above series of explanations, I believe you have a general grasp of the application scenarios, advantages and disadvantages of each current limiting, and hope to be helpful in daily development. Flow restriction is only a small part of the whole service governance. It needs to be combined with a variety of technologies to better improve the stability of services and improve the user experience at the same time.
appendix
https://github.com/uber-go/ratelimit https://en.wikipedia.org/wiki/Token_bucket
https://www.cs.columbia.edu/~ruigu/papers/socc18-final100.pdf
https://github.com/alibaba/Sentinel https://tools.ietf.org/html/rfc6585
https://www.yiichina.com/doc/guide/2.0/rest-rate-limiting
https://github.com/RussellLuo/slidingwindow
http://zim.logdown.com/posts/300977-distributed-rate-limiter
https://www.yuque.com/clip/dev-wiki/axo1wb?language=en-us
Source: http://r6d.cn/ac844