Interview collection: https://gitee.com/mydb/interview
HashMap is one of the most frequently used data types, and it is also one of the questions that must be asked in the interview. In particular, its underlying implementation principle is not only a common interview question, but also the cornerstone of understanding HashMap, so the importance is self-evident.
HashMap underlying implementation
The underlying implementation of HashMap in JDK 1.7 and JDK 1.8 is different. In JDK 1.7, HashMap is implemented by array + linked list, while JDK 1.8 is implemented by array + linked list or red black tree.
The implementation of HashMap in JDK 1.7 is shown in the following figure: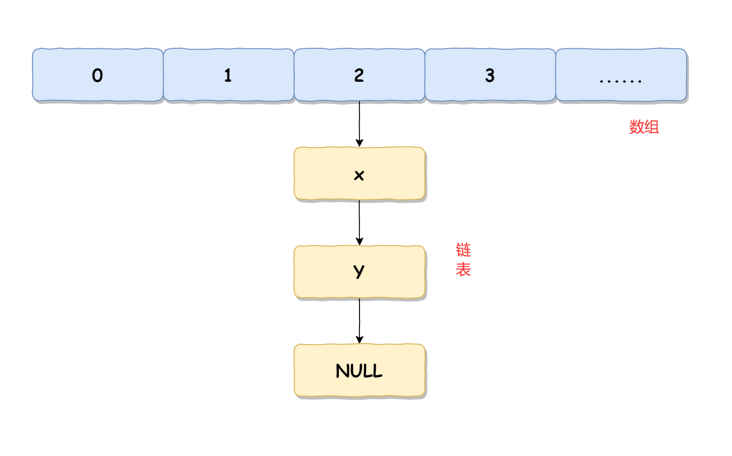
The implementation of HashMap in JDK 1.8 is shown in the following figure: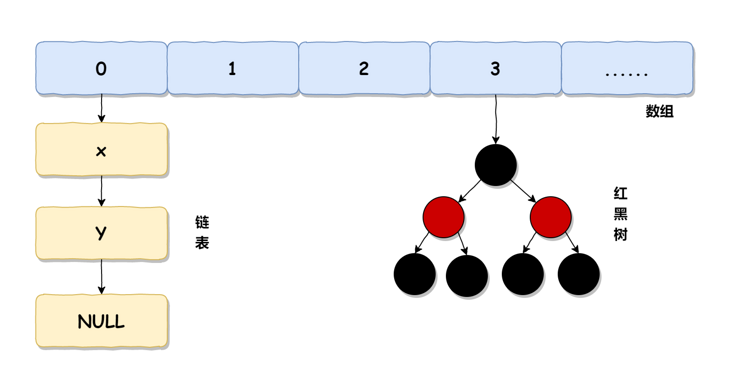
This article focuses on learning HashMap in the mainstream version of JDK 1.8. Each element in the HashMap is called a bucket. The hash bucket contains four contents:
- hash value
- key
- value
Next (next node)
HashMap insertion process
The new implementation source code of HashMap element is as follows (the following source codes are based on the mainstream version JDK 1.8):
public V put(K key, V value) { // Hash key return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // Create a hash table if the hash table is empty if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // Calculate the array index i to be inserted according to the hash value of the key if ((p = tab[i = (n - 1) & hash]) == null) // If table[i] is equal to null, insert directly tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // If the key already exists, directly overwrite the value if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // If the key does not exist, judge whether it is a red black tree else if (p instanceof TreeNode) // The red black tree directly inserts key value pairs e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // For the linked list structure, the loop is ready for insertion for (int binCount = 0; ; ++binCount) { // When the next element is empty if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // Convert to red black tree for processing if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // key already exists, directly overwriting value if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // Exceeding the maximum capacity, expansion if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }Corresponding code comments are added to the above source code. In short, the element addition process of HashMap is to hash the key value to get the hash value, and then determine whether the element position is empty according to the hash value. If it is empty, directly insert it, and if not, determine whether it is a red black tree. If it is a red black tree, directly insert it, otherwise determine whether the linked list is greater than 8, And the array length is greater than 64. If these two conditions are met, the linked list will be transformed into a red black tree, and then the elements will be inserted. If either of these two conditions is not met, the linked list will be traversed for insertion. Its execution process is shown in the following figure:
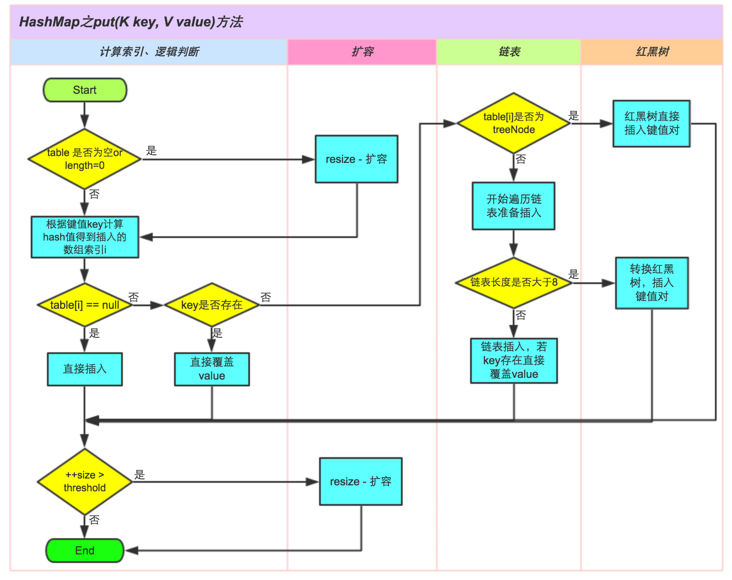
Why transfer the linked list to red black tree?
JDK 1.8 introduces a new data structure red black tree to implement HashMap, mainly for performance considerations. Because the query efficiency will be very low after the linked list exceeds a certain length. Its time complexity is O(n), while the time complexity of red black tree is O(logn). Therefore, the introduction of red black tree can speed up the query efficiency of HashMap in the case of large amount of data.
Hash algorithm implementation
The hash algorithm implementation source code of HashMap is as follows:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }Where, key hashCode() is the built-in hashCode() method in Java. It returns a hash value of type int, and then moves the hashCode to the right by 16 bits, which is exactly half of 32bit. It performs XOR operation with itself (the same is 0, the difference is 1). It is mainly to mix the high and low bits of the hash value and increase the randomness of the low bits. In this way, the HashMap hash algorithm is realized.
summary
In JDK 1.7, HashMap is implemented by array + linked list, while in JDK 1.8, it is implemented by array + linked list or red black tree. The reason why JDK 1.8 introduces red black tree is mainly due to performance considerations. When HashMap is inserted, it will judge whether the length of the current linked list is greater than 8 and the length of the array is greater than 64. If these two conditions are met, it will turn the linked list into a red black tree for insertion. Otherwise, it will traverse the linked list for insertion.
Reference documents
https://tech.meituan.com/2016/06/24/java-hashmap.html
Right and wrong are judged by ourselves, bad reputation is heard by others, and the number of gains and losses is safe.
The official account: Java interview