In this part, Mr. Songtian explained the application of relevant knowledge of re database. Next, we will crawl the information of Taobao commodity page in combination with requests database.
Note: crawler practice is only for learning, not for commercial use. If there is infringement, please contact to delete!
 https://s.taobao.com/
https://s.taobao.com/Crawling target: search the commodity "Polaroid" with Taobao website and print the commodity name and price information
Related library name: requests/re
catalogue
1. Web page analysis
Open the web version of Taobao and enter the keyword "Polaroid" to get the following page:
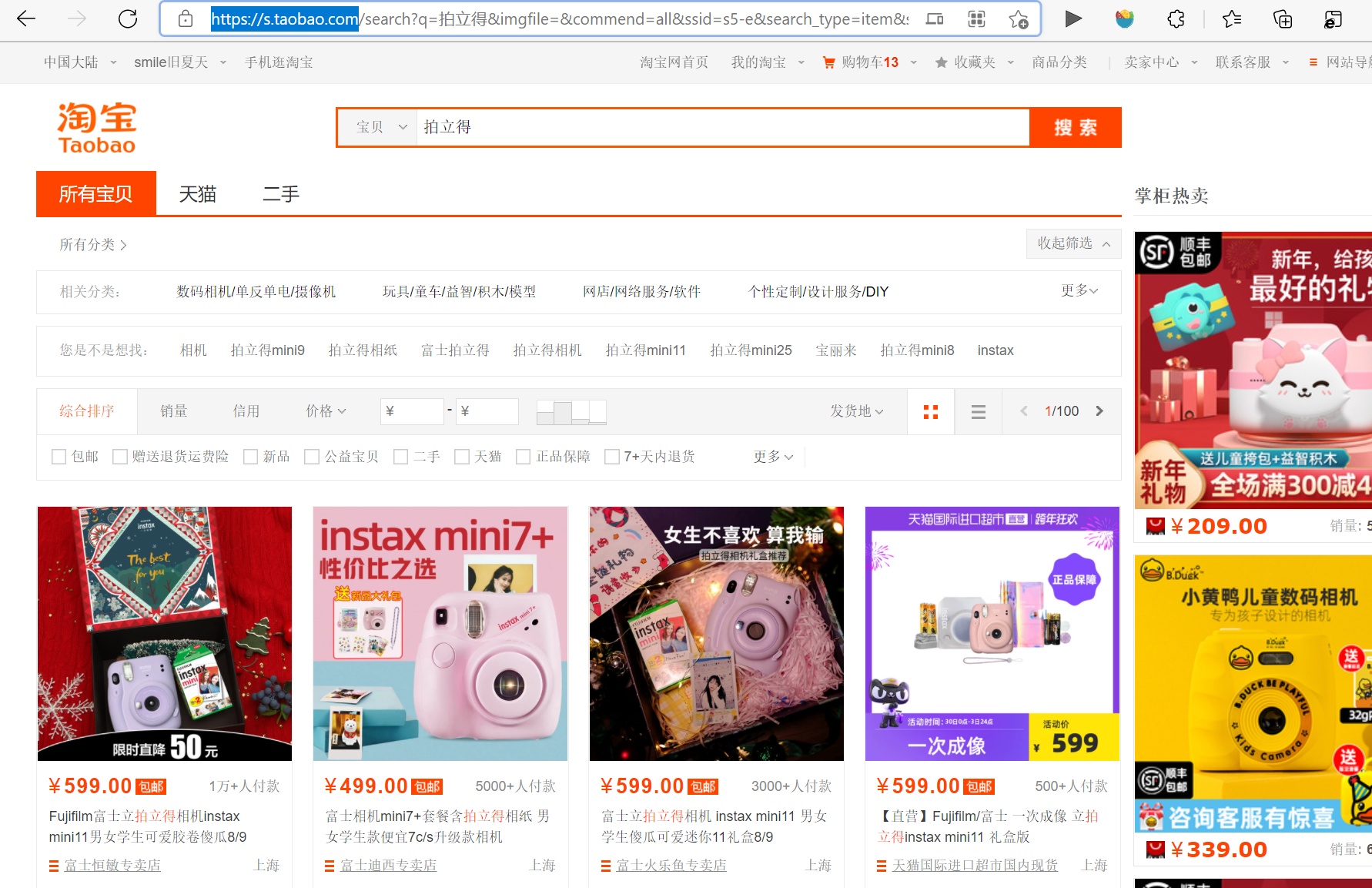
By observing the link, you can see that the keyword is after the q value:
https://s.taobao.com/search?q= Polaroid & imgfile = & command = all & SSID = s5-e & Search_ type=item&sourceId=tb. index&spm=a21bo. jianhua. 201856-taobao-item. 1&ie=utf8
The following link is obtained after turning the page. After comparison, it is found that there is s=44 at the end. In the same way, it can be found that the end of the third page is s=88, and the quantity of goods on each page is exactly 44. Therefore, next, turn the page by changing the s value:
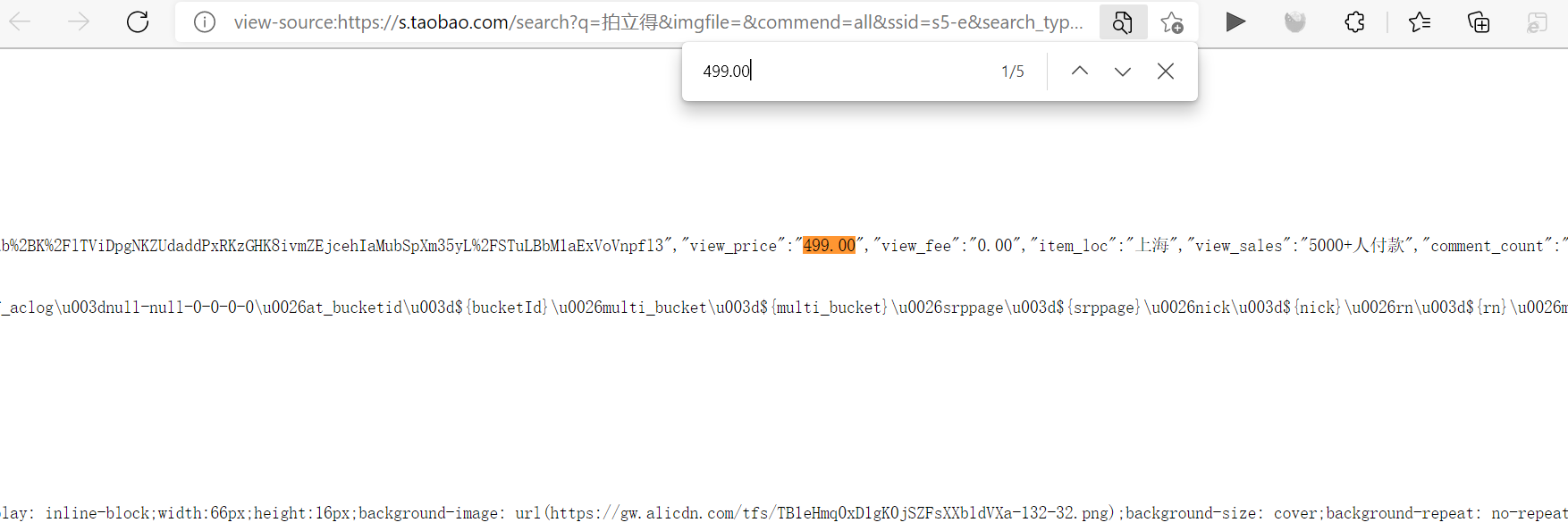
Right click to view the source code of the page, press ctrl+F to call out the search box, enter the price of the first commodity on the page 499.00, and view the location of the price information. You can see that the price is placed in view_ In the price key value pair, use the same method to copy the product name and find that the name information is placed in raw_title Key value pair, so to extract the commodity name and price information, you only need to retrieve the corresponding key value pair name and extract the subsequent values:
2. Code design
The complete code is as follows. In fact, only the headers request header information is added on the basis of the source code provided by teacher Songtian. See the notes for relevant explanations:
#Example: Taobao commodity price comparison pricing crawler
import requests
import re
def getHTMLText(headers,url):
#Define a function to get the text content of the web page source code
try:
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print('Failed to get web page information')
def parsePage(ilt,html):
#Define functions to parse page information
try:
plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
#Match view_price and its subsequent price information are and saved in the list plt
tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)
#Match raw_title and the name information after it are saved in the list plt
for i in range(len(plt)):
price=eval(plt[i].split(':')[1])
#Divide the obtained string with: and obtain the subsequent price information
title=eval(tlt[i].split(':')[1])
#Get the name information in the same way
ilt.append([price,title])
#Store price and name information in the list
except:
print('Failed to get price and name information')
def printGoodsList(ilt):
#Functions that define printing information
tplt='{:4}\t{:8}\t{:16}'
print(tplt.format('Serial number','Price','Trade name'))
count=0
#Define a counter to output sequence number information
for g in ilt:
count=count+1
print(tplt.format(count,g[0],g[1]))
#Output serial number, price and commodity name information
def main():
goods='Polaroid'
#Give the product name to search
depth=2
#Specifies the number of pages to crawl
start_url='https://s.taobao.com/search?q='+goods
#Give initial link
infoList=[]
#An empty list is given to store product information
headers = {
'user-agent': '',
'cookie': ''
}
#Enter your own request header identity information
for i in range(depth):
try:
print('Processing page{}Page information'.format(i+1))
url=start_url+'&s='+str(44*i)
html=getHTMLText(headers,url)
parsePage(infoList,html)
except:
print('getting information failure')
printGoodsList(infoList)
main()
3. Operation results
After running the code, the result of IDLE page is shown as follows:
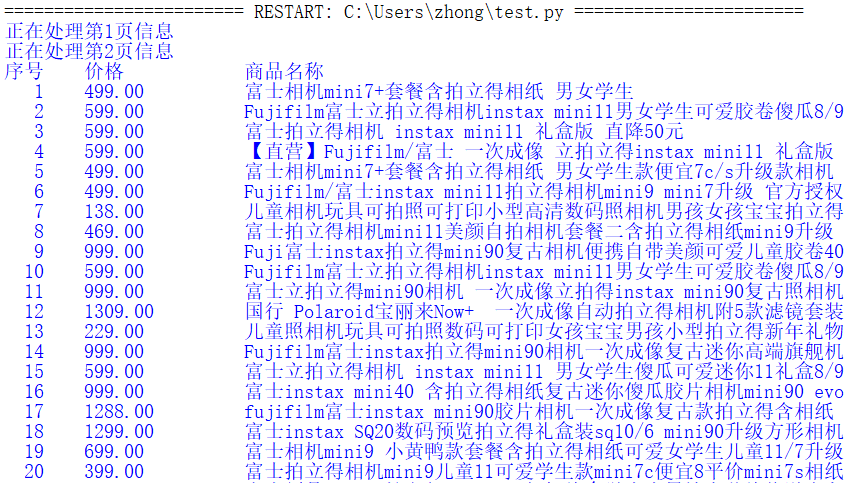
Due to the setting of try except, when there is an error at the beginning, it always prints the header and empty list without reporting an error. At first, it was thought that it was the problem of web page crawling. It was thought that the anti crawling mechanism of Taobao could not be decoded by giving only user agent and cookies. After repeated inspection, it was found that there was only a spelling error. The lesson learned this time is that if it is a practice, It doesn't matter if you don't set try exception to report an error, so it may be faster to correct the error.
reference material:
Song Tian Python web crawler and information extraction [EB / OL] https://www.icourse163.org/course/BIT-1001870001.