View. Github
1. Preface
Hello, everybody, today I want to talk about a more practical crawling tool to grab the key commodity information of Taobao, that is:
Enter keywords, sort by price, grab listed commodity information and download pictures, and support export to Excel.
If:
After reading the instructions below, the Python language is almost at an intermediate level, and the encapsulated tool is still very useful.
Feel like you're germinating ~~
2. Principles
You know what a crawler is. It's also called a web spider, a robot, etc. It means an automatic program that can grab the content that is transmitted using the network protocol.
At present, crawlers mainly use to capture websites, even if they use Http protocol to transfer all kinds of data, such as html,xml, json, etc., they also include binary content such as pictures.
The http protocol mainly includes request message and response message. Computer network must learn well. What about network programming?
Send a request message to the site server and it will return a response message with some data.
Request message, followed by a bunch of headers, may carry data, such as when post ing or get ting:
GET www.baidu.com HTTP/1.1
Response message followed by data:
HTTP/1.1 200 OK
Following are the results of Firefox F12 for reference only!
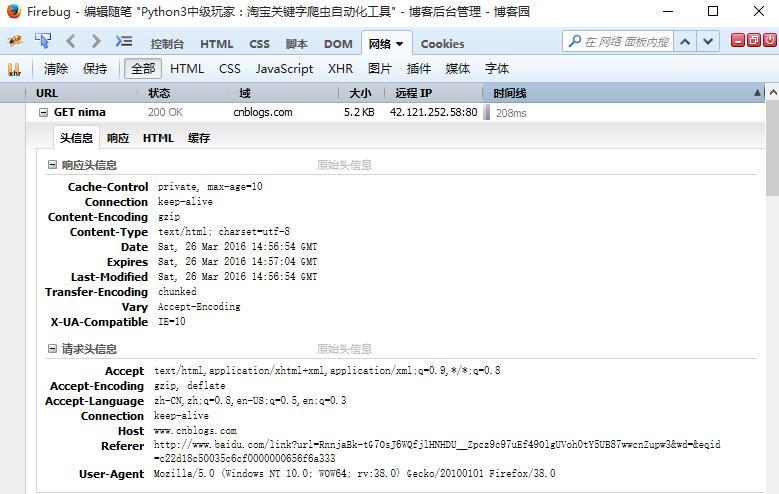
Translating: http://www.kancloud.cn/yizhin...
We only need to make normal http requests to get data. The problem is that Taobao will crawl back, or it needs to sign in.
1. In general, anti-crawlers will do some hand and foot work on their heads, encrypt some of them, such as having a Referer in the anti-theft chain, and refuse to provide services if they are not local servers.The Cookie transmitted by Session generally exists as a jsessionid header.
2. It may be considered a robot based on the number of IP visits, such as 100 visits per second, such as douba.I've grabbed most of the books on Douban ~There's a database
Solution: Nature is to disguise as human, pause, change IP, login, perfect!!
Since I prefer to play Taobao with my mobile phone, it is natural to grab the data of Taobao on my mobile phone because it is also native to HTML, so the data should be as appropriate as the PC side.
3. Ideas
After debugging according to F12, determine the link address, disguise the header, disguise the query conditions, use external Cookie files in exceptional cases, get JSONP data, replace JSON data, extract JSON data,
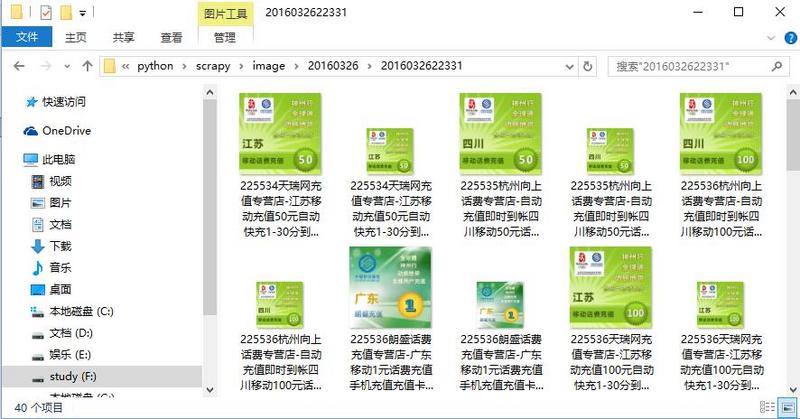
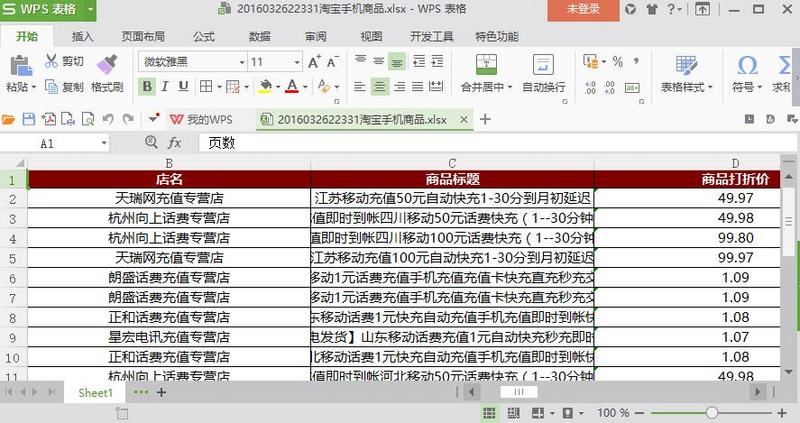
Extract picture links, change picture size, grab large pictures, picture compression, data selection fill EXCEL, generate EXCEL, KO!
4. Code
Because the code is long, let's walk through it step by step. Please be patient!
Using Python 3.4, here are file-level screenshots, partially unchecked.

1. Import corresponding modules
# -*- coding:utf-8 -*- import urllib.request, urllib.parse, http.cookiejar import os, time,re import http.cookies import xlsxwriter as wx # To install, EXCEL powerful library from PIL import Image # To install, Picture Compression Interception Library import pymysql # Need to be installed, mysql database operations Library import socket import json
Install modules using
pip3 install *
For example: pip3 install xlsxwriter
Or from Universal Warehouse http://www.lfd.uci.edu/~gohlk...
Download the corresponding version:
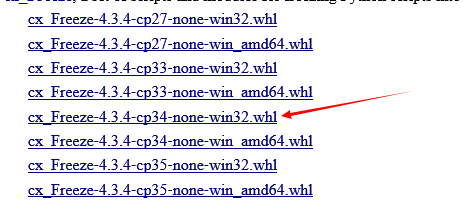
Then open cmd and go to the file directory, using:

Okay, install it yourself and consult me if you have any questions!
The core code is as follows:
def getHtml(url,daili='',postdata={}): """ //Capturing web pages: supporting cookie s //The first parameter is the web address and the second is the POST data """ # COOKIE file save path filename = 'cookie.txt' # Declare an instance of a Mozilla CookieJar object to be saved in a file cj = http.cookiejar.MozillaCookieJar(filename) # cj =http.cookiejar.LWPCookieJar(filename) # Read cookie content from file to variable # ignore_discard means to save a cookie even if it is discarded # ignore_expires means to overwrite the original file if cookies already exist in the file # Read primary COOKIE if it exists if os.path.exists(filename): cj.load(filename, ignore_discard=True, ignore_expires=True) # Read other COOKIE if os.path.exists('../subcookie.txt'): cookie = open('../subcookie.txt', 'r').read() else: cookie='ddd' # Build an open specialist with a COOKIE processor proxy_support = urllib.request.ProxyHandler({'http':'http://'+daili}) # Turn on proxy support if daili: print('agent:'+daili+'start-up') opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), urllib.request.HTTPHandler) else: opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) # Open expert plus head opener.addheaders = [('User-Agent', 'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5'), ('Referer', 'http://s.m.taobao.com'), ('Host', 'h5.m.taobao.com'), ('Cookie',cookie)] # Assign experts urllib.request.install_opener(opener) # POST needed for data if postdata: # Data URL Encoding postdata = urllib.parse.urlencode(postdata) # Sitemaps html_bytes = urllib.request.urlopen(url, postdata.encode()).read() else: html_bytes = urllib.request.urlopen(url).read() # Save COOKIE to file cj.save(ignore_discard=True, ignore_expires=True) return html_bytes
This is an omnipotent code to capture, proxy to have proxy, Post data to have data, cookie saving mechanism, external cookie reference.
Head disguised as mobile phone, okay!!
The following is a split explanation:
filename = 'cookie.txt' # Declare an instance of a Mozilla CookieJar object to be saved in a file cj = http.cookiejar.MozillaCookieJar(filename)
The above statement indicates that the cookie is saved in cookie.txt after visiting the website, and the program runs as shown in the diagram
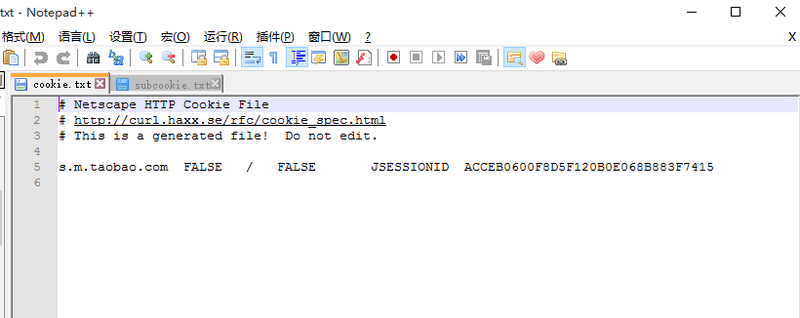
Because each time a cookie.txt is generated, it needs to be reused
# Read cookie content from file to variable # ignore_discard means to save a cookie even if it is discarded # ignore_expires means to overwrite the original file if cookies already exist in the file # Read primary COOKIE if it exists if os.path.exists(filename): cj.load(filename, ignore_discard=True, ignore_expires=True)
So if there is a cookie.txt, load it as the header.
However, there is no egg to use. Taobao encrypts and cookies are not so simple.Not enough cookies generated!
Because sometimes Taobao needs to sign in, the password generated by landing is bad, so no matter what, use a simple and rough method.
Land: http://s.m.taobao.com/h5entry
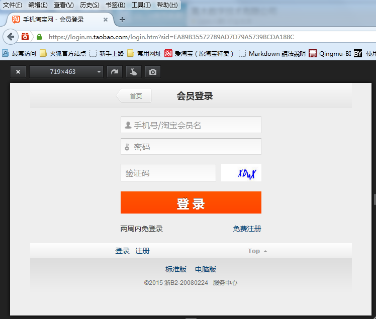
After login, press F12 on your browser, click on the network, and enter in the address bar:
http://s.m.taobao.com/search?...
Copy the Cookie as shown below.
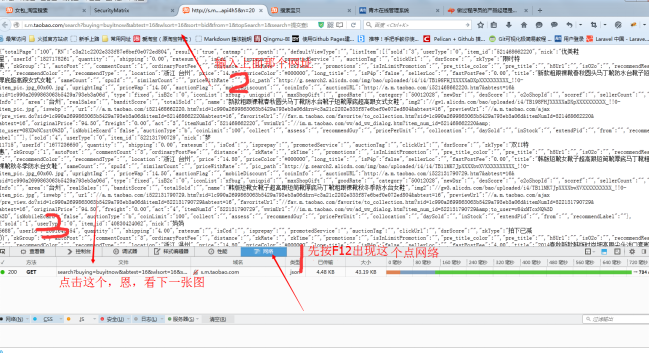
Paste the copied Cookie into the subcookie.txt file and remove the last line.

Since the JSESSIONID has been automatically generated, additional headers above are required.Here's the subcookie.txt content. It's ugly!
thw=cn; isg=A7A89D9621A9A068A783550E83F9EA75; l=ApqaMO0Erj-EZWH3j8agZ1OFylq8yx6l; cna=Hu3jDrynL3MCATsp1roB7XpN ; t=55aa84049f7d4d13fd9d35f615eca657; uc3=nk2=odrVGF%2FSsTE%3D&id2=UonciKb8CbgV7g%3D%3D&vt3=F8dAScLyUuy4Y2y %2BLsc%3D&lg2=W5iHLLyFOGW7aA%3D%3D; hng=CN%7Czh-cn%7CCNY; tracknick=%5Cu843D%5Cu7FCE%5Cu4E4B%5Cu5C18 ; _cc_=VT5L2FSpdA%3D%3D; tg=0; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato %3D0; ali_ab=59.41.214.186.1448953885940.9; miid=7373684866201455773; lzstat_uv=5949133953778742363|2144678 @2981197; lgc=%5Cu843D%5Cu7FCE%5Cu4E4B%5Cu5C18; _m_h5_tk=1e74de0ae376f631a8496c95c76f5992_1450410384099 ; _m_h5_tk_enc=dd07257232a80053507709abdb5c25ba; WAPFDFDTGFG=%2B4dRjM5djSecKyo4JwyfmJ2Wk7iKyBzheenYyV7Q4jpJ5AGWi %2BQ%3D; ockeqeudmj=jJryFc8%3D; _w_tb_nick=%E8%90%BD%E7%BF%8E%E4%B9%8B%E5%B0%98; imewweoriw=3%2Fsult5sjvHeH4Vx %2FRjBTLvgKiaerF3AknLfbEF%2Fk%2BQ%3D; munb=1871095946; _w_app_lg=18; _w_al_f=1; v=0; cookie2=1c990a2699863063b5429a793eb3a06d ; uc1=cookie14=UoWyjiifHcHNvg%3D%3D&cookie21=URm48syIYB3rzvI4Dim4&cookie15=VT5L2FSpMGV7TQ%3D%3D; mt=ci =-1_0; _tb_token_=QPkhOWpqBYou; wud=wud; supportWebp=false; sg=%E5%B0%986c; cookie1=URseavpIenqQgSuh1bZ8BwEFNWDY3M88T0 %2BWawaafIY%3D; ntm=0; unb=1871095946; _l_g_=Ug%3D%3D; _nk_=%5Cu843D%5Cu7FCE%5Cu4E4B%5Cu5C18; cookie17 =UonciKb8CbgV7g%3D%3D
In fact, sometimes you don't need subcookie.txt, but sometimes you do. The validity period is very long, several weeks!
# Read other COOKIE if os.path.exists('../subcookie.txt'): cookie = open('../subcookie.txt', 'r').read() else: cookie='ddd'
If subcookie.txt exists, read it in, otherwise it's messy. How do you feel?
# Build an open specialist with a COOKIE processor proxy_support = urllib.request.ProxyHandler({'http':'http://'+daili}) # Turn on proxy support if daili: print('agent:'+daili+'start-up') opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), urllib.request.HTTPHandler) else: opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
Build a proxy expert, if there is an agent, then join the support, if not, opener is what the initiator means, he is me!!
# Open expert plus head opener.addheaders = [('User-Agent', 'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5'), ('Referer', 'http://s.m.taobao.com'), ('Host', 'h5.m.taobao.com'), ('Cookie',cookie)]
Start disguising and see that the Cookie head is not there, our subcookie s come in handy, and we disguise as iPad s!
# Assign experts urllib.request.install_opener(opener)
Install me in a global request. Doing so is global. Once urlopen, send all heads out ~~
# POST needed for data if postdata: # Data URL Encoding postdata = urllib.parse.urlencode(postdata) # Sitemaps html_bytes = urllib.request.urlopen(url, postdata.encode()).read() else: html_bytes = urllib.request.urlopen(url).read()
If you have data to POST, first urlencode it, because there are some rules that some characters can not appear in the url, so to escape, convert the Chinese characters to%*, if one day you have been posting data errors, then you have to consider whether there are illegal characters in the url, please Baidu base64 principle!!!
Directly after escape
html_bytes = urllib.request.urlopen(url).read()
Open the url link and read it. It's binary!!
# Save COOKIE to file cj.save(ignore_discard=True, ignore_expires=True) return html_bytes
Finally, the generated cookie is saved and the captured data is returned.
This is our first core function code, there are many more behind it!
Tomorrow: Python 3 Intermediate Player: Taobao Tmall Commodity Search Crawler Automation Tool (2nd)
Can't wait, please arm github!!!