Target level emotion analysis based on SKEP pre training model
As we all know, human natural language contains rich emotional colors: expressing people's emotions (such as sadness and happiness), expressing people's mood (such as burnout and depression), expressing people's preferences (such as like and hate), expressing people's personality characteristics and expressing people's position, etc. Emotion analysis is applied in the scenarios of commodity preference, consumption decision-making, public opinion analysis and so on. Using machines to automatically analyze these emotional tendencies will not only help enterprises understand consumers' feelings about their products, but also provide basis for product improvement; At the same time, it also helps enterprises analyze the attitudes of business partners in order to make better business decisions.
This practice will carry out the emotion analysis task based on the target level. Unlike the emotion analysis at the sentence level, the emotion analysis at the target level will analyze an aspect involved in a sentence, as shown in the following sentence.
This potato chip tastes a little salty and too spicy, but it tastes crisp.
For this sentence, it is obvious that the taste of potato chips is a negative evaluation (salty, too spicy), but it is a positive evaluation (very crisp) for the taste.
In order to facilitate the goal level emotion analysis task modeling, the emotion polarity can also be divided into three categories: positive, negative and neutral, so as to transform the emotion analysis task into a classification problem, as shown in Figure 1:
- Positive: positive emotions, such as happiness, surprise, expectation, etc;
- Negative: indicates negative emotions, such as sadness, sadness, anger, panic, etc;
- Neutral: other types of emotions;

Figure 1 emotion analysis task
This practice will be based on the pre training SKEP model seabsa16-phns
Target level emotion analysis tasks are performed on the data set.
learning resource
- For more in-depth learning materials, such as in-depth learning knowledge, paper interpretation, practical cases, etc., please refer to: awesome-DeepLearning
- For more information about the propeller frame, please refer to: Propeller deep learning platform
⭐ ⭐ ⭐ Welcome to order a small one Star , open source is not easy. I hope you can support it~ ⭐ ⭐ ⭐

1. Scheme design
The design idea of this practice is shown in Figure 2. The input of SKEP model has two parts, one is the object to be evaluated (Aspect), and the other is the corresponding comment text. After the two are spliced, they can be introduced into the SKEP model. After the SKEP model semantically encodes the text string, this practice takes the token output vector at the CLS position as the final semantic coding vector. Next, emotion will be classified according to the semantic coding vector. It should be noted that: seabsa16-phns The data set is a binary data set, and its emotional polarity only includes positive and negative categories.
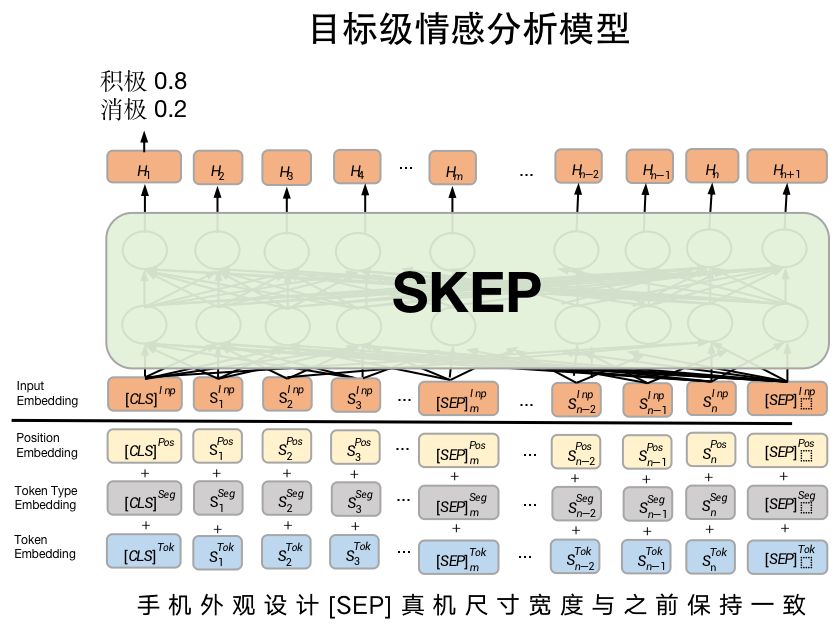
Figure 2 goal level emotion analysis modeling diagram
2. Data processing
2.1 data set introduction
This practice will be used in data sets seabsa16-phns Perform emotion analysis tasks. The data set is a target level emotion analysis data set, in which the training set contains 1334 training samples and 529 test samples. A sample of this dataset is shown below:
{
"label":1
"text":"display#quality",
"text_pair":"I was lucky to get the Hong Kong version of white today iPhone 5 Real machine, try it, talk about your feelings: 1. Real machine size and width 4/4s Keep consistent without change. The length is about one centimeter longer, which is the row of icons mentioned earlier. two. The weight of the real machine is much lighter than that of the previous generation. Personally, it feels like i9100 It weighs about the same. (it may take some time for friends who are used to the previous generation to adapt) 3. Because there is no version yet SIM The card cannot be inserted into the card. Friends who buy it should pay attention to it. It is not easy to cut the card, but need to go to the operator to replace it with a new generation SIM Card. four. The screen display effect is indeed better than that of the previous generation, whether from the perspective of clarity or different angles, iPhone 5 I think this is probably the most meaningful upgrade compared with the previous generation. five. The new data interface is smaller, better and more convenient than the previous generation. You will have this experience in the process of use. six. In terms of simple operations, the speed is faster than 4 s It should be fast, which can be felt without testing software, such as program call, photo shooting and browsing. However, at present, the price of Keng dad in the parallel market, it's best for everyone to wait and see again. Don't rush to sell.",
}
2.2 data loading
In this section, we load the training, evaluation and test data sets into memory. Since the ChnSentiCorp data set belongs to the built-in data set of paddlenlp, in this practice, we will load data directly from paddlenlp. The relevant codes are as follows.
import os
import copy
import argparse
import numpy as np
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.metrics import AccuracyAndF1
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed
from utils.data import convert_example_to_feature
train_ds = load_dataset("seabsa16", "phns", splits=["train"])
100%|██████████| 381/381 [00:00<00:00, 22249.56it/s]
2.3 converting data into feature form
After loading the data, next, we convert the training and development set data into the feature form suitable for the input model, that is, the text string data into the form of dictionary id. Here we need to load the SkepTokenizer in paddleNLP, which will help us complete the conversion from this string to dictionary id.
model_name = "skep_ernie_1.0_large_ch" batch_size = 16 max_seq_len = 256 tokenizer = SkepTokenizer.from_pretrained(model_name) trans_func = partial(convert_example_to_feature, tokenizer=tokenizer, max_seq_len=max_seq_len) train_ds = train_ds.map(trans_func, lazy=False)
[2021-11-10 14:43:12,930] [ INFO] - Downloading skep_ernie_1.0_large_ch.vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.vocab.txt 100%|██████████| 55/55 [00:00<00:00, 2032.88it/s]
2.4 construct DataLoader
Next, we need to construct a DataLoader based on the data loaded into memory. The DataLoader will support the division of data in the form of batch, so as to train the corresponding model in the form of batch.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype="int64")
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
3. Model construction
In this case, we will implement the emotion analysis function shown in Figure 2 based on the SKEP model. Specifically, we input the processed text data into the SLEP model. ERNIE will encode each token of the text and generate the corresponding vector sequence. The output vector corresponding to the CLS position of our task can represent the complete semantics of the statement, so we will use this vector for emotion classification. The corresponding codes are as follows.
class SkepForSquenceClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForSquenceClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(p=dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], self.num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
4. Training configuration
Next, define the environment for emotional analysis model training, including configuring training parameters, configuring model parameters, defining the instantiation object of the model, specifying the optimization algorithm of model training iteration, etc. the relevant codes are as follows.
# model hyperparameter setting
num_epoch = 3
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = "./checkpoint/"
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSquenceClassification(skep, num_classes=len(train_ds.label_list))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = AccuracyAndF1()
[2021-11-10 14:47:07,184] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
5. Model training
In this section, we will define a train function in which we will train the model. During training, every log_steps print a log step by step to observe the training effect of the model. Relevant codes are as follows:
def evaluate(model, data_loader, metric):
model.eval()
metric.reset()
for idx, batch_data in enumerate(data_loader):
input_ids, token_type_ids, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
# count metric
correct = metric.compute(logits, labels)
metric.update(correct)
accuracy, precision, recall, f1, _ = metric.accumulate()
return accuracy, precision, recall, f1
def train():
global_step = 1
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits, labels)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final.pdparams")
train()
epoch: 1 - global_step: 20/252 - loss:0.664008 epoch: 1 - global_step: 40/252 - loss:0.815231 epoch: 1 - global_step: 60/252 - loss:0.662032 epoch: 1 - global_step: 80/252 - loss:0.609795 epoch: 2 - global_step: 100/252 - loss:0.606419 epoch: 2 - global_step: 120/252 - loss:0.653587 epoch: 2 - global_step: 140/252 - loss:0.592340 epoch: 2 - global_step: 160/252 - loss:0.961530 epoch: 3 - global_step: 180/252 - loss:0.514817 epoch: 3 - global_step: 200/252 - loss:0.630167 epoch: 3 - global_step: 220/252 - loss:0.496368 epoch: 3 - global_step: 240/252 - loss:0.686450
6. Model reasoning
Realize a function predicted by the model and input a string of text string with emotion arbitrarily, such as "convenient transportation; good environment; good service attitude and large room". It is expected to output the emotion category contained in this text description. First, we load the trained model parameters, and then reasoning. The relevant codes are as follows.
# process data related
model_name = "skep_ernie_1.0_large_ch"
model_path = os.path.join(checkpoint, "final.pdparams")
id2label = {0:"Negative", 1:"Positive"}
# load model
loaded_state_dict = paddle.load(model_path)
ernie = SkepModel.from_pretrained(model_name)
model = SkepForSquenceClassification(ernie, num_classes=len(train_ds.label_list))
model.load_dict(loaded_state_dict)
[2021-11-10 14:51:00,184] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
def predict(text, text_pair, model, tokenizer, id2label, max_seq_len=256):
model.eval()
# processing input text
encoded_inputs = tokenizer(text=text, text_pair=text_pair, max_seq_len=max_seq_len)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# predict by model and decoding result
logits = model(input_ids, token_type_ids=token_type_ids)
label_id = paddle.argmax(logits, axis=1).numpy()[0]
# print predict result
print(f"text: {text} \ntext_pair:{text_pair} \nlabel: {id2label[label_id]}")
text = "display#quality"
text_pair = "mk16i The experience after use feels good. It's just a little thick, the screen resolution is high, and the operation is smooth. I just don't know if I can brush 4.0 My system"
predict(text, text_pair, model, tokenizer, id2label, max_seq_len=max_seq_len)
text: display#quality text_pair:mk16i The experience after use feels good. It's just a little thick, the screen resolution is high, and the operation is smooth. I just don't know if I can brush 4.0 My system label: Positive
7. More in-depth learning resources
7.1 one stop deep learning platform awesome-DeepLearning
- Introduction to deep learning
- Deep learning questions

- Characteristic course

- Industrial practice
If you have any questions during the use of paddledu, you are welcome to awesome-DeepLearning For more in-depth learning materials, please refer to Propeller deep learning platform.
Remember to order one Star ⭐ Collection oh~~

7.2 propeller technology exchange group (QQ)
At present, 2000 + students in QQ group have studied together. Welcome to join us by scanning the code