1 title
Quality analysis model of enterprise hidden danger investigation based on Text Mining

2 competition background
It is of great significance for enterprises to fill in the hidden dangers of safety production independently to eliminate the risks in the embryonic stage of accidents. When enterprises fill in hidden dangers, they often do not fill in carefully, and the hidden dangers of "false and false" increase the difficulty of enterprise supervision. Using big data means to analyze the hidden danger content, find out the enterprises that fail to effectively fulfill the main responsibility, push them to the regulatory authorities, and realize accurate law enforcement, which can improve the effectiveness of regulatory means and enhance the awareness of corporate safety responsibility.
3 competition task
This competition question provides enterprises to fill in hidden danger data. Contestants need to identify whether there is "false report and false report" through intelligent means.
It is very important to see the competition questions clearly. We need to understand the objectives of the competition questions well and then do the questions, which can avoid many detours.
Data introduction
The data set of this competition is the self inspection hidden danger records filled in by desensitized enterprises.
4 data description
The training set data includes seven fields of "[id, level_1 (Level 1 standard), level_2 (Level 2 standard), level_3 (Level 3 standard), level_4 (Level 4 standard), content (hidden danger content) and label]".
Where "id" is the primary key and has no business significance; "Level-1 standard, level-2 standard, level-3 standard and level-4 standard" are the troubleshooting guidelines specified in the basic guidelines for self inspection and patrol of potential safety hazards in Shenzhen (revised in 2016). Level-1 standards correspond to different types of potential hazards, and level-2 to level-4 standards are the refinement of level-1 standards. When enterprises independently report potential hazards, they carry out potential hazard self inspection according to the level-4 standards of different types of potential hazards; "Hidden danger content" refers to the specific hidden danger reported by the enterprise; "Label" indicates the qualification of the hidden danger, "1" indicates that the hidden danger is not qualified, and "0" indicates that the hidden danger is qualified.
Forecast results file results csv
| Listing | explain |
|---|---|
| id | Enterprise number |
| label | Positive and negative sample classification |
- File name: results CSV, utf-8 encoding
- Contestants submit model results in csv/json and other file formats, and the platform scores online and ranks in real time.
5 evaluation criteria
This competition adopts F1 -score as the model evaluation standard.
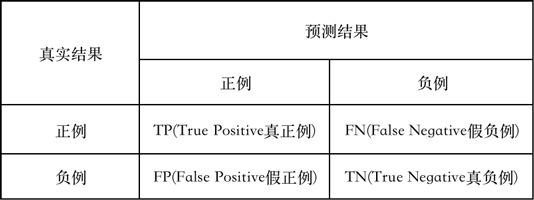
The calculation formulas of accuracy rate P, recall rate R and F1 score are as follows:

6 data analysis
- View dataset

The training set data includes seven fields: id, level_1, level_2, level_3, level_4, content and label. The test set has no label field
- Label distribution
Let's take a look at the number distribution of data tags and see how many are rowing ha ha_
sns.countplot(train.label)
plt.xlabel('label count')
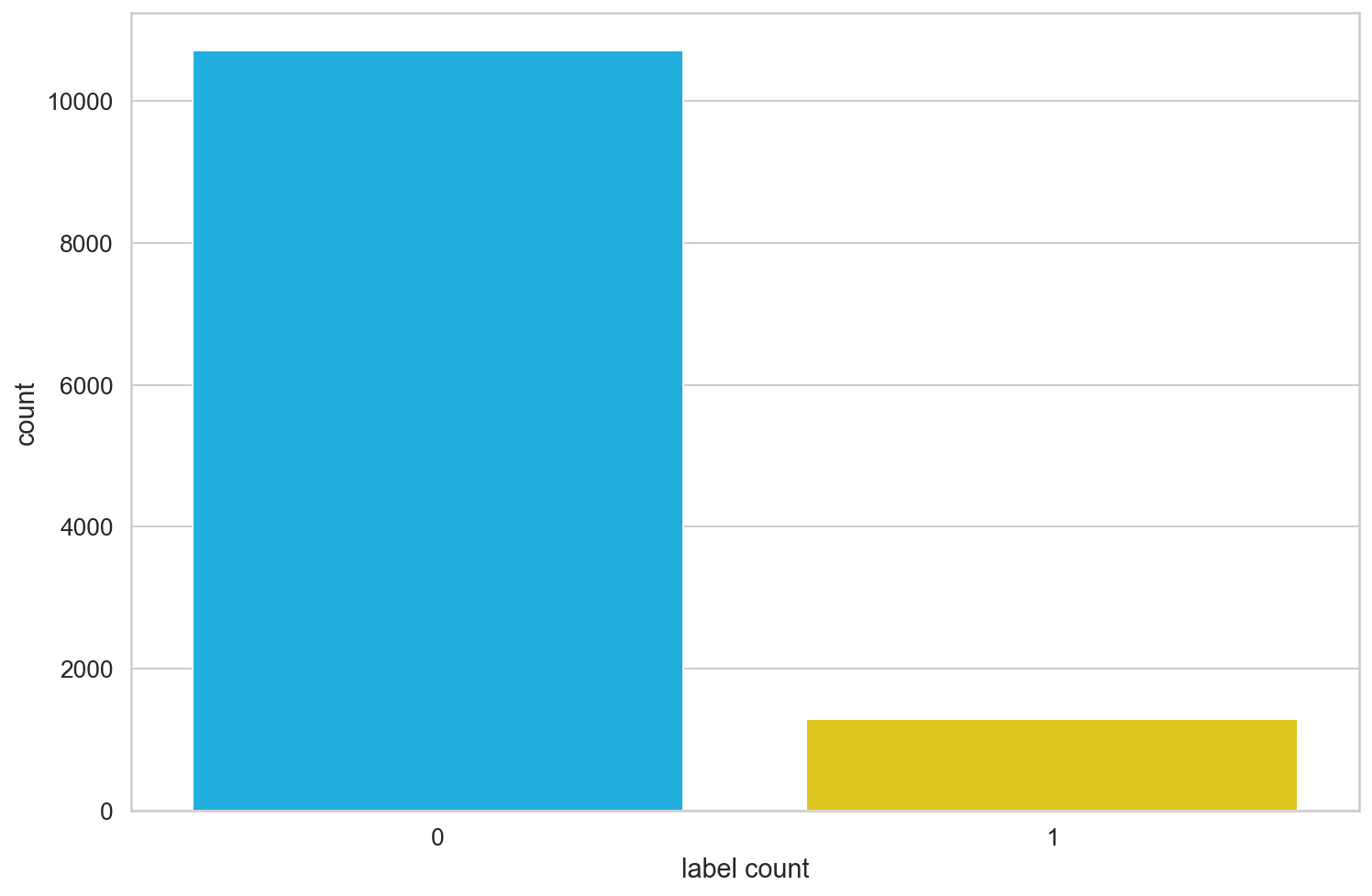
Among the 12000 data in the training set, 10712 hidden dangers are qualified and 1288 hidden dangers are unqualified, which is almost 9:1, indicating that the distribution of classification task labels is extremely unbalanced.
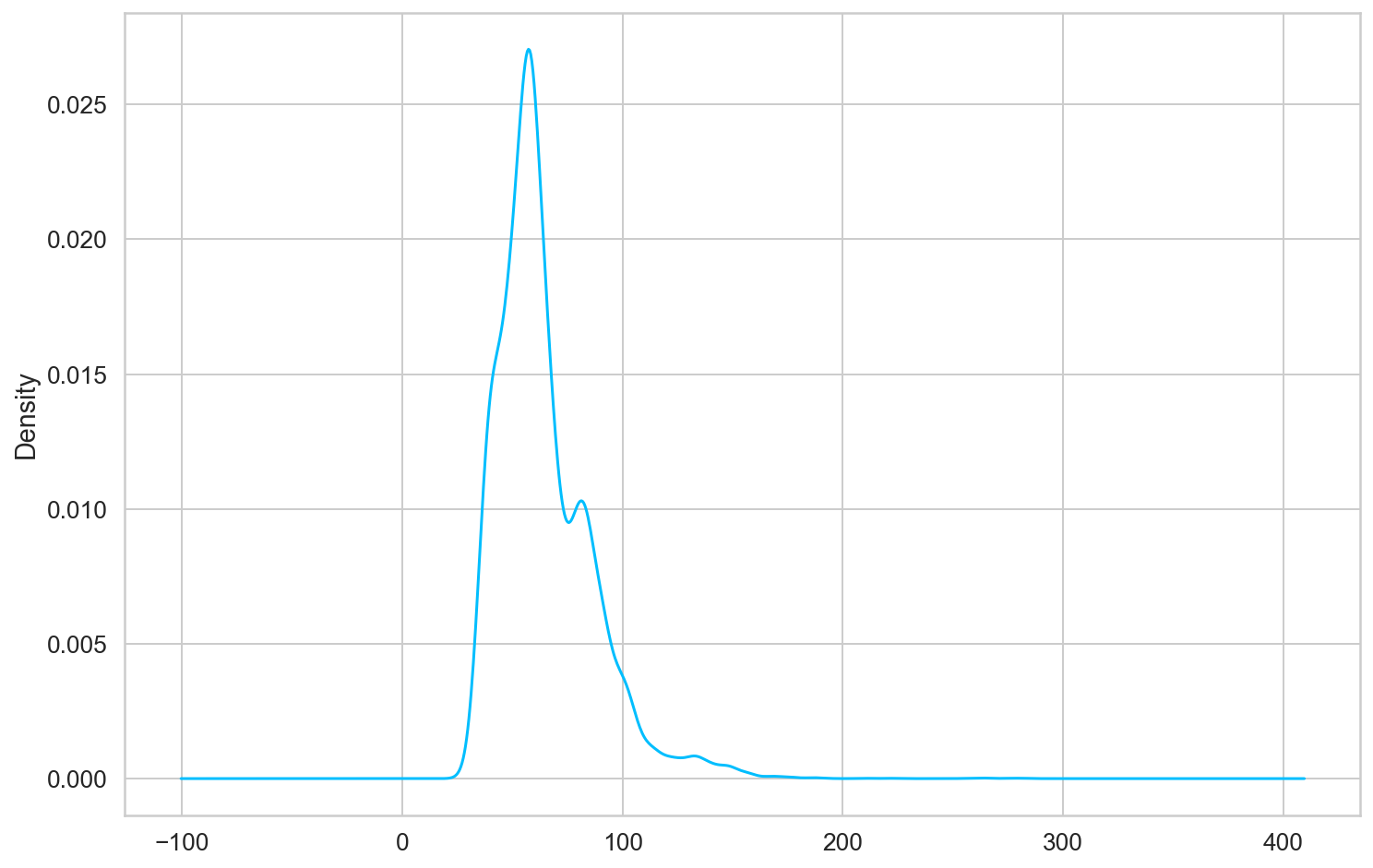
- Text length distribution
We will level_ Spliced with the text of content
train['text']=train['content']+' '+train['level_1']+' '+train['level_2']+' '+train['level_3']+' '+train['level_4'] test['text']=test['content']+' '+test['level_1']+' '+test['level_2']+' '+test['level_3']+' '+test['level_4'] train['text_len']=train['text'].map(len) test['text'].map(len).describe()
Then view the maximum length distribution of the text
count 18000.000000 mean 64.762167 std 22.720117 min 27.000000 25% 50.000000 50% 60.000000 75% 76.000000 max 504.000000 Name: text, dtype: float64
train['text_len'].plot(kind='kde')
7 quality analysis model of enterprise hidden danger troubleshooting based on BERT
The complete code can be obtained by contacting the author
7.1 import Kit
import random import numpy as np import pandas as pd from bert4keras.backend import keras, set_gelu from bert4keras.tokenizers import Tokenizer from bert4keras.models import build_transformer_model from bert4keras.optimizers import Adam, extend_with_piecewise_linear_lr from bert4keras.snippets import sequence_padding, DataGenerator from bert4keras.snippets import open from keras.layers import Lambda, Dense
Using TensorFlow backend.
7.2 setting parameters
set_gelu('tanh') # Switch gelu version
num_classes = 2 maxlen = 128 batch_size = 32 config_path = '../model/albert_small_zh_google/albert_config_small_google.json' checkpoint_path = '../model/albert_small_zh_google/albert_model.ckpt' dict_path = '../model/albert_small_zh_google/vocab.txt' # Build word breaker tokenizer = Tokenizer(dict_path, do_lower_case=True)
7.3 definition model
# Load pre training model
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
model='albert',
return_keras_model=False,
)
output = Lambda(lambda x: x[:, 0], name='CLS-token')(bert.model.output)
output = Dense(
units=num_classes,
activation='softmax',
kernel_initializer=bert.initializer
)(output)
model = keras.models.Model(bert.model.input, output)
model.summary()
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
Input-Token (InputLayer) (None, None) 0
__________________________________________________________________________________________________
Input-Segment (InputLayer) (None, None) 0
__________________________________________________________________________________________________
Embedding-Token (Embedding) (None, None, 128) 2704384 Input-Token[0][0]
__________________________________________________________________________________________________
Embedding-Segment (Embedding) (None, None, 128) 256 Input-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Token-Segment (Add) (None, None, 128) 0 Embedding-Token[0][0]
Embedding-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Position (PositionEmb (None, None, 128) 65536 Embedding-Token-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Norm (LayerNormalizat (None, None, 128) 256 Embedding-Position[0][0]
__________________________________________________________________________________________________
Embedding-Mapping (Dense) (None, None, 384) 49536 Embedding-Norm[0][0]
__________________________________________________________________________________________________
Transformer-MultiHeadSelfAttent (None, None, 384) 591360 Embedding-Mapping[0][0]
Embedding-Mapping[0][0]
Embedding-Mapping[0][0]
Transformer-FeedForward-Norm[0][0
Transformer-FeedForward-Norm[0][0
Transformer-FeedForward-Norm[0][0
Transformer-FeedForward-Norm[1][0
Transformer-FeedForward-Norm[1][0
Transformer-FeedForward-Norm[1][0
Transformer-FeedForward-Norm[2][0
Transformer-FeedForward-Norm[2][0
Transformer-FeedForward-Norm[2][0
Transformer-FeedForward-Norm[3][0
Transformer-FeedForward-Norm[3][0
Transformer-FeedForward-Norm[3][0
Transformer-FeedForward-Norm[4][0
Transformer-FeedForward-Norm[4][0
Transformer-FeedForward-Norm[4][0
__________________________________________________________________________________________________
Transformer-MultiHeadSelfAttent (None, None, 384) 0 Embedding-Mapping[0][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[0][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[1][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[2][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[3][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[4][0
Transformer-MultiHeadSelfAttentio
__________________________________________________________________________________________________
Transformer-MultiHeadSelfAttent (None, None, 384) 768 Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
__________________________________________________________________________________________________
Transformer-FeedForward (FeedFo (None, None, 384) 1181568 Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
__________________________________________________________________________________________________
Transformer-FeedForward-Add (Ad (None, None, 384) 0 Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[0][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[1][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[2][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[3][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[4][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[5][0]
__________________________________________________________________________________________________
Transformer-FeedForward-Norm (L (None, None, 384) 768 Transformer-FeedForward-Add[0][0]
Transformer-FeedForward-Add[1][0]
Transformer-FeedForward-Add[2][0]
Transformer-FeedForward-Add[3][0]
Transformer-FeedForward-Add[4][0]
Transformer-FeedForward-Add[5][0]
__________________________________________________________________________________________________
CLS-token (Lambda) (None, 384) 0 Transformer-FeedForward-Norm[5][0
__________________________________________________________________________________________________
dense_7 (Dense) (None, 2) 770 CLS-token[0][0]
==================================================================================================
Total params: 4,595,202
Trainable params: 4,595,202
Non-trainable params: 0
__________________________________________________________________________________________________
# It is derived as an optimizer with piecewise linear learning rate.
# The name parameter is optional, but it is best to fill it in to distinguish different derived optimizers.
# AdamLR = extend_with_piecewise_linear_lr(Adam, name='AdamLR')
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(1e-5), # With a sufficiently small learning rate
# optimizer=AdamLR(learning_rate=1e-4, lr_schedule={
# 1000: 1,
# 2000: 0.1
# }),
metrics=['accuracy'],
)
7.4 generating data
def load_data(valid_rate=0.3):
train_file = "../data/train.csv"
test_file = "../data/test.csv"
df_train_data = pd.read_csv("../data/train.csv")
df_test_data = pd.read_csv("../data/test.csv")
train_data, valid_data, test_data = [], [], []
for row_i, data in df_train_data.iterrows():
id, level_1, level_2, level_3, level_4, content, label = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), label
if random.random() > valid_rate:
train_data.append( (id, text, int(label)) )
else:
valid_data.append( (id, text, int(label)) )
for row_i, data in df_test_data.iterrows():
id, level_1, level_2, level_3, level_4, content = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), 0
test_data.append( (id, text, int(label)) )
return train_data, valid_data, test_data
train_data, valid_data, test_data = load_data(valid_rate=0.3)
valid_data
[(5,
'Industry/Hazardous chemicals (site) - 2016 Edition\t(1) Fire inspection\t2,Fire inspection\t8,Implementation of fire and explosion prevention measures for inflammable and explosive dangerous goods and places and fire safety of other important materials;\t Diluent and oil in explosion-proof cabinet are mixed',
0),
(3365,
'Three small sites (site) - 2016 Edition\t(1) Fire safety\t2,Fire escape and evacuation\t2,Emergency lighting and evacuation indication signs shall be set at evacuation passages and emergency exits.\t4 The emergency exit sign of the fire stairs in the building is broken',
0),
...]
len(train_data)
8403
class data_generator(DataGenerator):
"""Data generator
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, (id, text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
# Convert dataset train_generator = data_generator(train_data, batch_size) valid_generator = data_generator(valid_data, batch_size)
valid_data
[(5,
'Industry/Hazardous chemicals (site) - 2016 Edition\t(1) Fire inspection\t2,Fire inspection\t8,Implementation of fire and explosion prevention measures for inflammable and explosive dangerous goods and places and fire safety of other important materials;\t Diluent and oil in explosion-proof cabinet are mixed',
0),
(8,
'Industry/Hazardous chemicals (site) - 2016 Edition\t(1) Fire inspection\t2,Fire inspection\t2,Safety evacuation routes, evacuation indication signs, emergency lighting and emergency exits;\t Rectified',
1),
(3365,
'Three small sites (site) - 2016 Edition\t(1) Fire safety\t2,Fire escape and evacuation\t2,Emergency lighting and evacuation indication signs shall be set at evacuation passages and emergency exits.\t4 The emergency exit sign of the fire stairs in the building is broken',
0),
...]
7.5 training and verification
evaluator = Evaluator()
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=2,
callbacks=[evaluator]
)
model.load_weights('best_model.weights')
# print(u'final test acc: %05f\n' % (evaluate(test_generator)))
print(u'final test acc: %05f\n' % (evaluate(valid_generator)))
final test acc: 0.981651
print(u'final test acc: %05f\n' % (evaluate(train_generator)))
The complete code can be obtained by contacting the author