Hello, I'm an advanced Python.
preface
A few days ago, the [Pan Xi bird] boss shared a code for capturing novels in the group. I feel it's quite good. I'll share it here for you to learn.
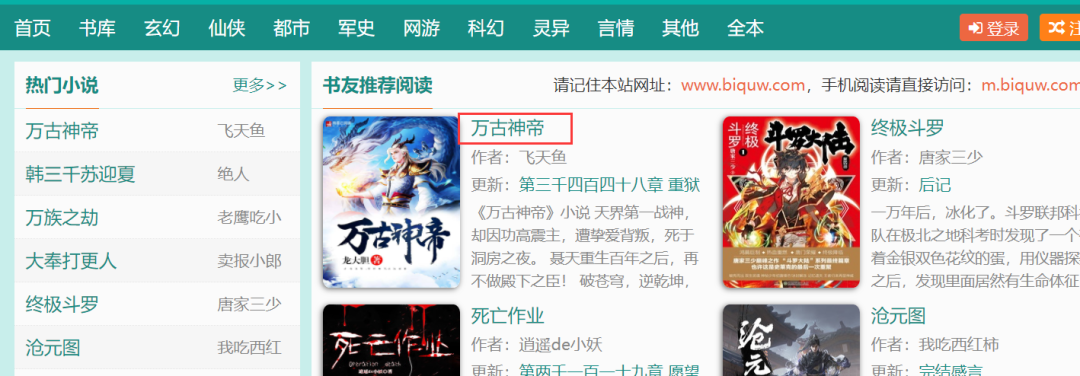
1, Novel download
If you want to download any novel on the website, click the link directly, as shown in the figure below.
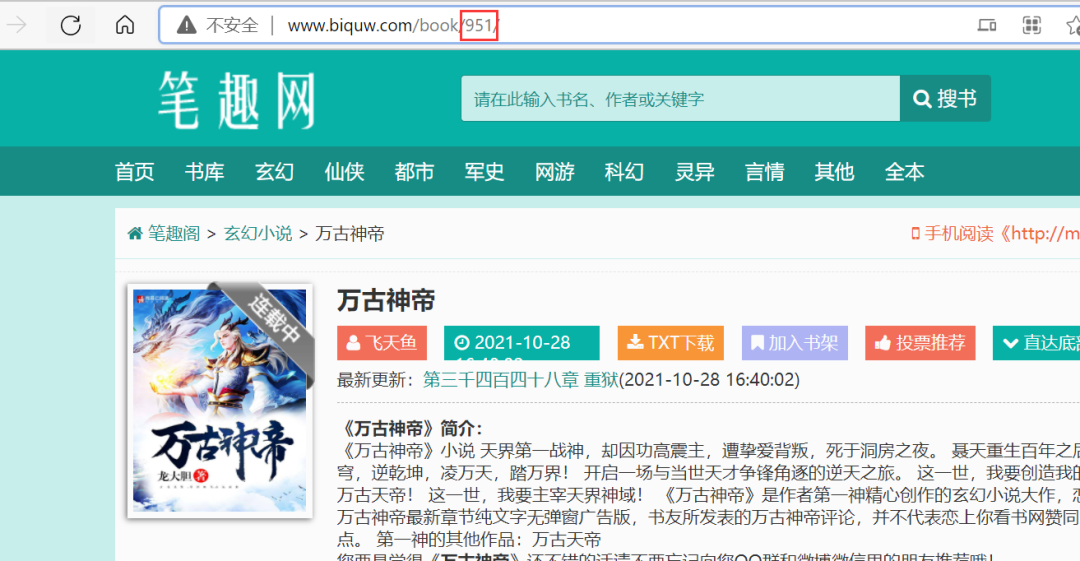
Just get the number in the URL. For example, here is 951. Then this number represents the book number of the book, which can be used in the following code.
2, Concrete implementation
The code of the boss is directly lost here, as shown below:
# coding: utf-8
'''
Biqu novel download
Research code only
Do not use for commercial purposes
Please delete within 24 hours
'''
import requests
import os
from bs4 import BeautifulSoup
import time
def book_page_list(book_id):
'''
Book number passed in bookid,Get the table of contents of all chapters of this book
:param book_id:
:return: Chapter directory and chapter address
'''
url = 'http://www.biquw.com/book/{}/'.format(book_id)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
response = requests.get(url, headers)
response.encoding = response.apparent_encoding
response = BeautifulSoup(response.text, 'lxml')
booklist = response.find('div', class_='book_list').find_all('a')
return booklist
def book_page_text(bookid, booklist):
'''
Capture and archive the contents of each chapter through the book number and chapter directory
:param bookid:str
:param booklist:
:return:None
'''
try:
for book_page in booklist:
page_name = book_page.text.replace('*', '')
page_id = book_page['href']
time.sleep(3)
url = 'http://www.biquw.com/book/{}/{}'.format(bookid,page_id)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
response_book = requests.get(url, headers)
response_book.encoding = response_book.apparent_encoding
response_book = BeautifulSoup(response_book.text, 'lxml')
book_content = response_book.find('div', id="htmlContent")
with open("./{}/{}.txt".format(bookid,page_name), 'a') as f:
f.write(book_content.text.replace('\xa0', ''))
print("Currently downloaded chapters:{}".format(page_name))
except Exception as e:
print(e)
print("Chapter content acquisition failed. Please ensure that the book number is correct and the book has normal content.")
if __name__ == '__main__':
bookid = input("Please enter the book number(number): ")
# If the directory corresponding to the book number does not exist, a new directory is created to store the chapter contents
if not os.path.isdir('./{}'.format(bookid)):
os.mkdir('./{}'.format(bookid))
try:
booklist = book_page_list(bookid)
print("Get directory successfully!")
time.sleep(5)
book_page_text(bookid, booklist)
except Exception as e:
print(e)
print("Failed to get the directory. Please make sure the book number is entered correctly!")After the program runs, enter the book number on the console to start crawling.
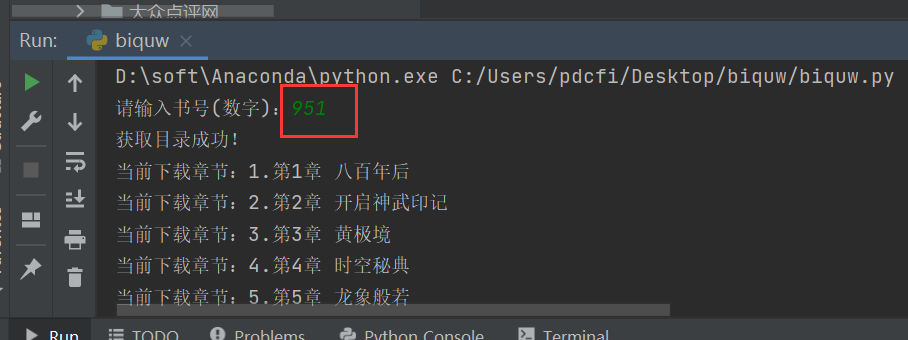
A folder named by book number will be automatically created locally, and the chapters of the novel will be stored in this folder, as shown in the figure below.

3, Frequently asked questions
Small and medium-sized partners should often encounter this problem during operation, as shown in the figure below.
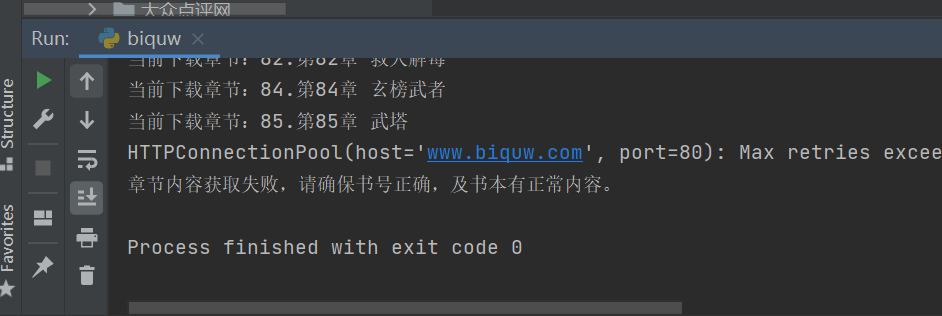
This is because the visit is too fast and the website is crawling back to you. It can be solved by setting random user agent or upper agent.

4, Summary
I'm an advanced Python. This article mainly introduces the acquisition method of novel content, which is based on web crawler, implemented through requests crawler library and bs4 selector, and gives you examples of common problems.
This article is only for code learning, communication and sharing. Don't get sick of crawlers. When crawling, choose to do it at night as much as possible. Set up more sleep. Crawlers can stop. Don't overpressure each other's servers. Remember! Remember! Remember!