catalogue
- Team learning materials:
- 1, Transformer overview
- II. Self Attention mechanism
- 3, Multi head attention mechanism
- 4, Other relevant knowledge points
- 5, Code implementation
- 6, Text quiz
- Other references
Team learning materials:
Datawhale August team learning -Introduction to natural language processing (NLP) based on transformers
Task02 main learning contents: 2.1 - Graphic attention md 2.2 - Graphic transformer md
Statement: NLP pure Xiaobai, the content of this article is mainly used as personal learning notes. I may not understand many places very well. It is only for reference. If there is a dispute, you can check more other materials, and please leave a message in the comment area for correction! thank you
Learning suggestions For my little white, I should focus on 2.2transformer and 2.1attention as supplementary knowledge. At the beginning, I don't know what 2.1 is talking about. After reading 2.2, I can go back to 2.1. So at the beginning, I think the order is wrong. I found that there should be no order later. 2.1 should be a supplementary description of 2.2. In general, it's better to look at the 2.2 transformer first.
In addition, it is recommended to know word2vec and RNN in advance
1, Transformer overview
As mentioned earlier, attention is a supplementary explanation to the transformer, so the notes mainly introduce the transformer, and attention is interspersed as supplementary knowledge
1.1 what does transformer do
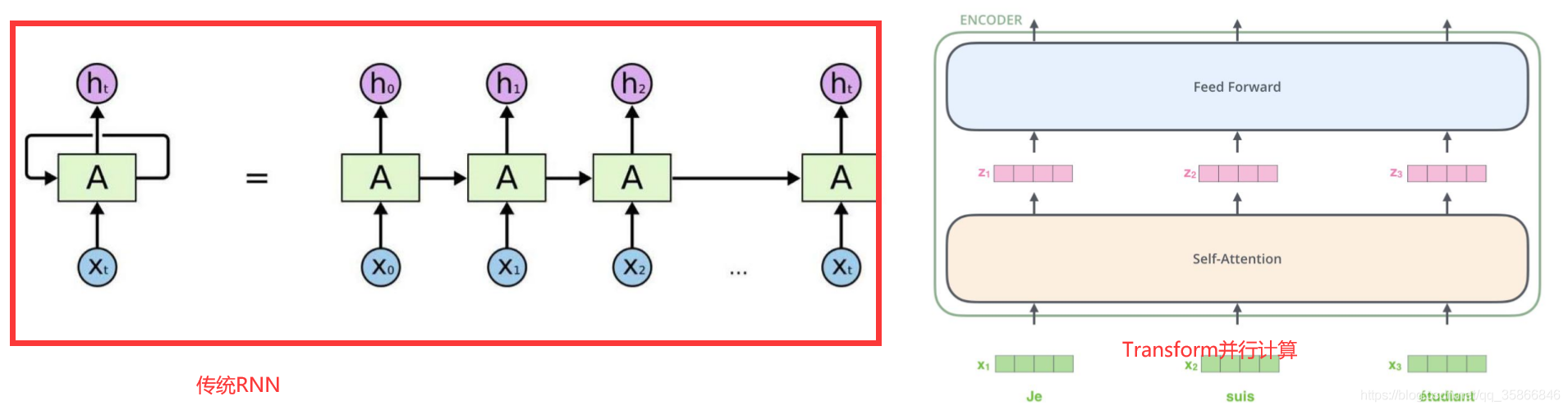
1.1.1 compared with the traditional RNN network structure, it is an enhancement
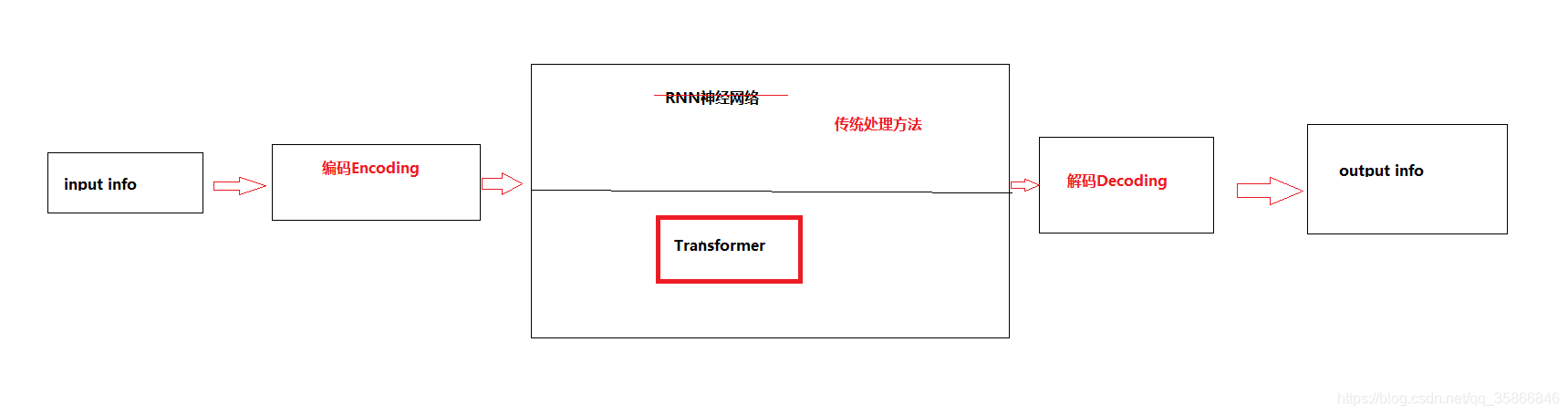
As shown in the figure above, transformer, as a network structure, replaces the RNN model in the traditional seq2seq, solves the problem of parallel computing and provides acceleration for model training
The mechanism used for parallel computing is mainly self Attention mechanism, in order to distinguish the focus information in a sentence, that is, give each word different weights, and consider more location sequence information than the traditional RNN model
1.1.2 difference from traditional word2vec
Traditional word2vec:
- The trained word vector is static, fixed, the same word and the same vector
Transform:
- Dynamically changing word vectors, combined with different contexts, the word vectors of the same word may be different
1.1.3 overall architecture of transform
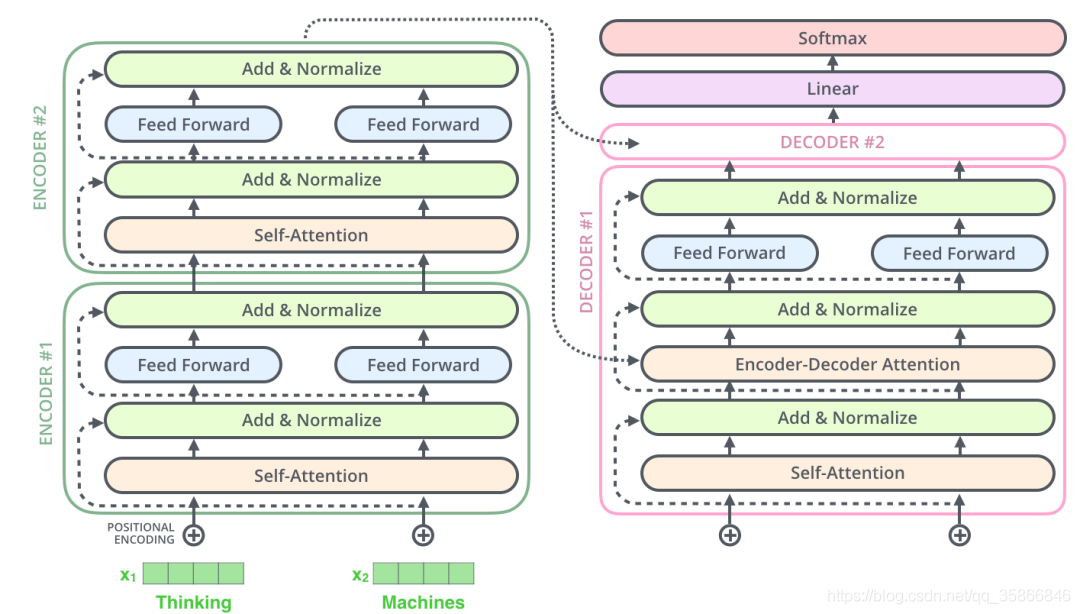
Learning objectives | what does transform need to do?
- Enter how to encode
- What is the output
- Purpose of Attention
- How to combine
II. Self Attention mechanism
2.1 what does Attention mean
- What are your concerns about input data
- How can we make the computer pay attention to these valuable information
2.2,Self. How is attention calculated
The method of matrix operation enables the calculation of Self Attention to be parallelized, which is also the final implementation of Self Attention
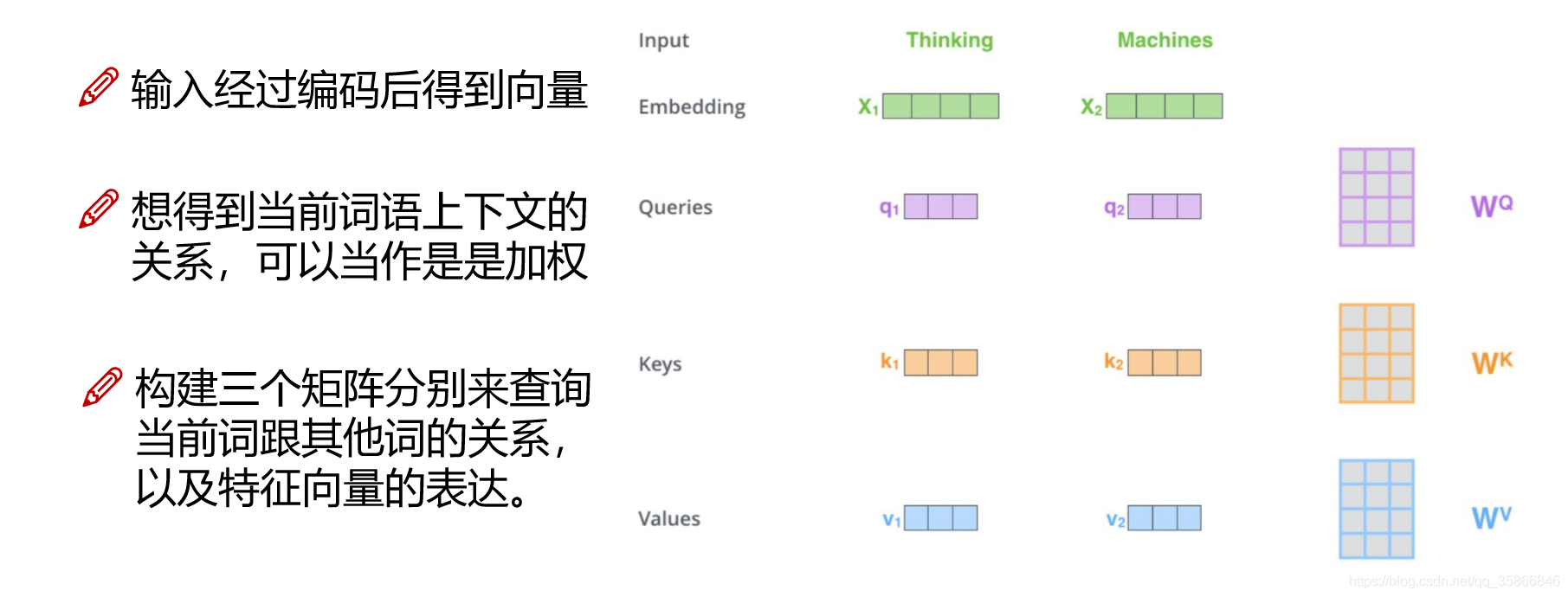
- Step 1: for each word vector input to the encoder, create three vectors: Q vector (query to query), K vector (key to be queried), and V vector (Value actual feature information). These 3 vectors are obtained by multiplying the vector of the word with the 3 matrices, which are the parameters we want to learn (first initialization, then adjustment). Finally, we need to integrate the V vectors.
- Step 2: calculate the Attention Score
It is obtained by calculating the dot product (inner product) of the Query vector corresponding to "Thinking" and the Key vector of each word in other positions. If we calculate the Attention Score of the word at the first position in the sentence, the first score is the inner product of q1 and k1, and the second score is the dot product (inner product) of q1 and k2
The m-th word (n words in total) gets n inner products: qmk1,qmk2,,,,qmkm,,,,qnkn Internal integral multiplication: multiply and sum the corresponding position elements. The greater the internal product, the greater the correlation
- Step 3: divide each score by (√ dkey) (dkey is the length of the Key vector)
In order to eliminate the influence of vector dimension and avoid the irrationality that the larger the vector dimension is, the higher the score is
- Step 4: then pass these scores through a softmax layer. Softmax can normalize the scores so that the scores are positive and add up to 1
Eliminate measures, scale and facilitate comparison
- Step 5: after getting the score of each position, multiply each score by each Value vector
- Step 6: add the vectors obtained in the previous step to get the output of the Self Attention layer at this position.
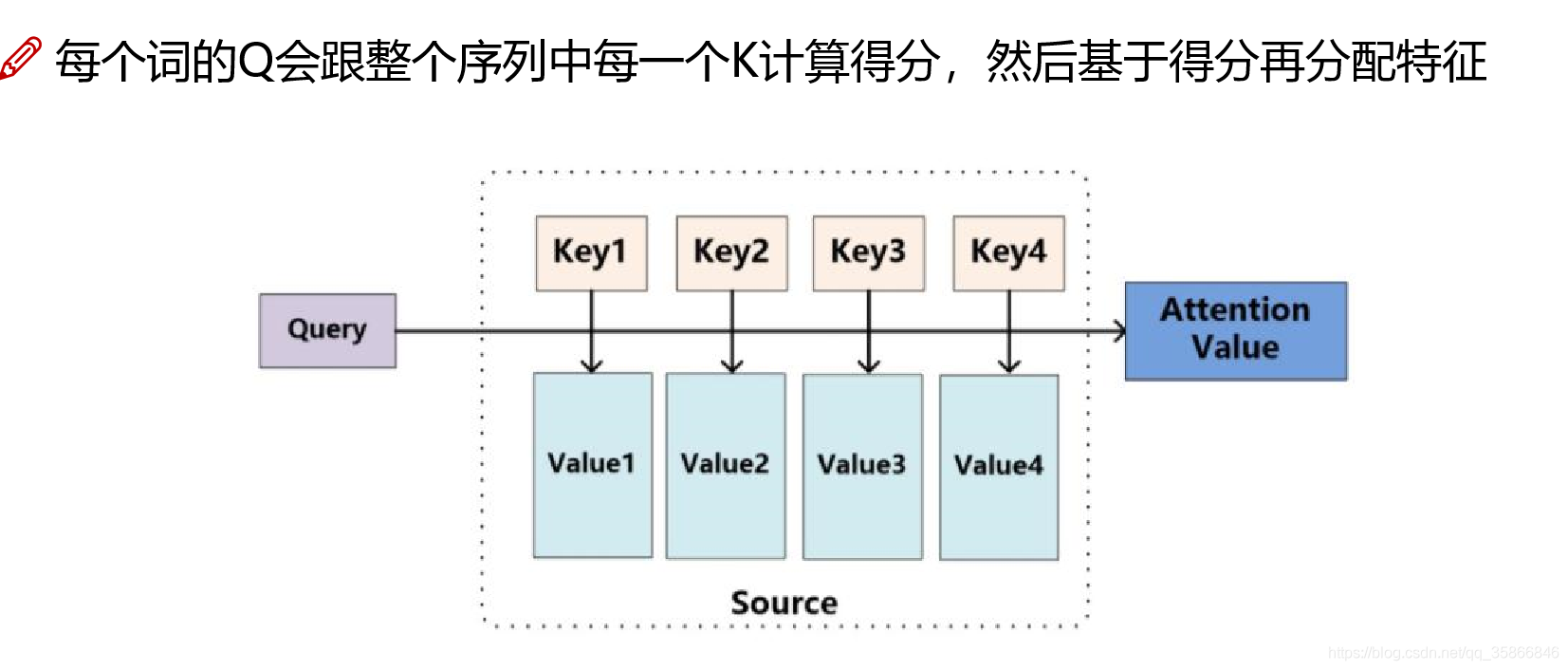
Each word no longer represents itself, but represents the weighted characteristics of the full text
Summary: Suppose that all word vectors form matrix X, weight matrix w ^ Q, w ^ k, w ^ v
According to step 1:
Q = X \cdot W^QK = X \cdot W^KV = X \cdot W^VAccording to steps 2-6, the output of self attention can be obtained
Z = \Sigma\text{softmax}\left( \frac{Q \cdot K^T}{\sqrt{d_{K}}} \right) \cdot V3, Multi head attention mechanism
Similar to filter convolution kernel and characteristic graph in convolution neural network
multi-head:
- Multiple feature expressions are obtained through different heads (generally 8 heads)
- Splice all features together
- Dimensionality can be reduced by another layer of full connection
Generally speaking, if you don't know which method is good, do more methods, and finally splice the characteristics of several methods together to reduce the dimension
4, Other relevant knowledge points
4.1 stacking multiple layers:
- After self Attention & the output from the multi head mechanism is still a vector
- Repeat the obtained vector as self Attention & the multi head mechanism continues to output vectors
- Circular multi-layer stacking, consistent calculation methods, generally only one layer is not enough
4.2 expression of location information:
In self attention, each word will consider the weighting of the whole sequence, so its occurrence position will not have any impact on the result, which is equivalent to no matter where it is placed, but it is somewhat inconsistent with the reality. We hope the model can have additional understanding of the position.
The solution is as follows: add a location code after embeddings
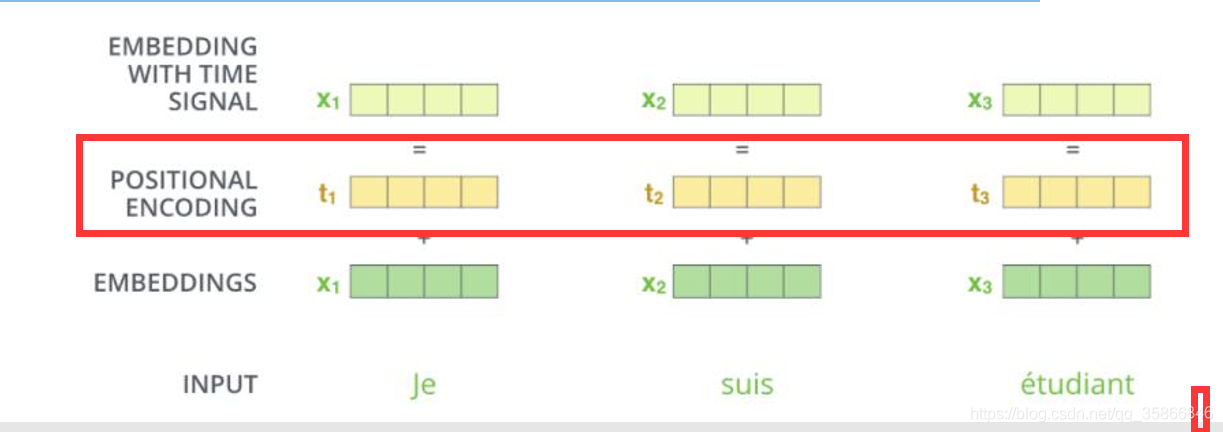
Traditional machine learning generally uses one hot coding, and the periodic expression of cosine sine is used in transformer
4.3 residual connection
Depth residual network in convolutional neural network
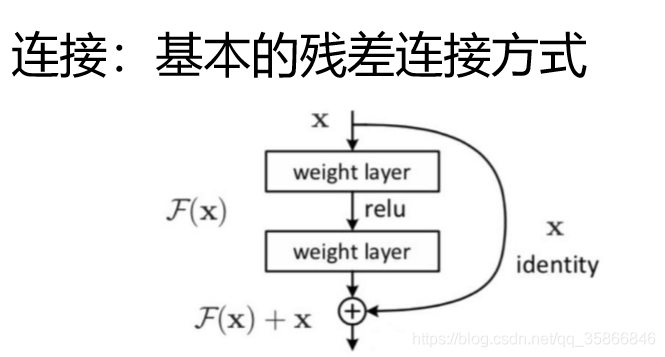
Two roads:
- After self Multi head equal feature transformation
- Bring the original features directly
Throw it into the network and let the network choose the best feature by itself
The result of residual link: at least no worse than the original
4.4 normalization
Traditional: normalization of batch transform: normalization of layer
5, Code implementation
5.1 use the MultiheadAttention of PyTorch to realize the calculation of Attention
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
Parameter Description:
- embed_dim: the dimension of the final output K, Q and V matrices. This dimension needs to be the same as that of the word vector
- num_heads: sets the number of heads' attention. If set to 1, only one set of attention is used. If set to other values, num_ The value of heads needs to be embedded_ Dim Division
- Dropout: This dropout is added after the attention score
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
Parameter Description:
- query: corresponding to the Key matrix, the shape is (L,N,E). Where l is the length of the output sequence, n is the batch size, and E is the dimension of the word vector
- Key: corresponding to the key matrix, the shape is (S,N,E). Where S is the length of the input sequence, n is the batch size, and E is the dimension of the word vector
- Value: corresponding to the value matrix, the shape is (S,N,E). Where S is the length of the input sequence, n is the batch size, and E is the dimension of the word vector
- key_padding_mask: if this parameter is provided, some padding elements in the Key matrix will be ignored when calculating the attention score and will not participate in the calculation of attention. The shape is (N,S). Where N is the batch size and S is the input sequence length.
-
- If key_ padding_ If the mask is ByteTensor, the corresponding position of non-0 elements will be ignored
-
- If key_ padding_ If the mask is BoolTensor, the position corresponding to True will be ignored
- attn_mask: some locations are ignored when calculating the output. The shape can be 2D (L,S) or 3D (N * numheads,L,S). Where l is the length of the output sequence, S is the length of the input sequence, and N is the batch size.
-
- If Attn_ If the mask is ByteTensor, the corresponding position of non-0 elements will be ignored
-
- If Attn_ If the mask is BoolTensor, the position corresponding to True will be ignored
import torch import torch.nn as nn ## nn.MultiheadAttention enter the length of dimension 0 # batch_ The size is 64 and there are 12 words. The Query vector of each word is 300 dimensions query = torch.rand(12,64,300) # batch_ The size is 64 and there are 10 words. The Key vector of each word is 300 dimensions key = torch.rand(10,64,300) # batch_ The size is 64, there are 10 words, and the Value vector of each word is 300 dimensions value= torch.rand(10,64,300) embed_dim = 300 num_heads = 1 # Output is (attn_output, attn_output_weights) multihead_attn = nn.MultiheadAttention(embed_dim, num_heads) attn_output = multihead_attn(query, key, value)[0] # output: torch.Size([12, 64, 300]) # batch_ The size is 64, there are 12 words, and the vector of each word is 300 dimensions print(attn_output.shape)
torch.Size([12, 64, 300])
5.2 use self programming to realize the calculation of Attention
import torch
from torch import nn
class MultiheadAttention(nn.Module):
def __init__(self, hid_dim, n_heads, dropout):
super(MultiheadAttention, self).__init__()
# Vector dimension of each word output
self.hid_dim = hid_dim
# Number of bulls' attention
self.n_heads = n_heads
# Mandatory hid_dim must divide by n_heads
assert hid_dim % n_heads == 0
# Definition W_q matrix
self.w_q = nn.Linear(hid_dim, hid_dim)
# Definition W_k matrix
self.w_k = nn.Linear(hid_dim, hid_dim)
# Definition W_v matrix
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
# zoom
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))
def forward(self, query, key, value, mask=None):
# K: [64,10,300], batch_ The size is 64 and there are 12 words. The Query vector of each word is 300 dimensions
# V: [64,10,300], batch_ The size is 64, there are 10 words, and the Query vector of each word is 300 dimensions
# Q: [64,12,300], batch_ The size is 64, there are 10 words, and the Query vector of each word is 300 dimensions
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# Here, the K Q V matrix is divided into multiple groups of attention and becomes a 4-dimensional matrix
# The last dimension is self hid_ dim // self. n_ Heads, which represents the vector length of each group of attention. The vector length of each head is: 300 / 6 = 50
# 64 represents batch size, 6 represents 6 groups of attention, 10 represents 10 words, and 50 represents the vector length of words of each group of attention
# K: [64,10300] split multiple groups of attention - > [64,10,6,50] transpose to get - > [64,6,10,50]
# 5: [64,10300] split multiple groups of attention - > [64,10,6,50] transpose to get - > [64,6,10,50]
# Q: [64,12300] split multiple groups of attention - > [64,12,6,50] transpose to get - > [64,6,12,50]
# Transpose is to put the number of attention 6 in the front and 10 and 50 in the back, so as to facilitate the following calculation
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
# Step 1: Q times the transpose of K, divided by scale
# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]
# attention: [64,6,12,10]
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# If the mask is not empty, set the attention score of the position where the mask is 0 to - 1e10
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
# Step 2: calculate the softmax of the result of the previous step, and then get the attention through dropout.
# Note that here, softmax is done for the last dimension, that is, softmax is done in the dimension of the input sequence
# attention: [64,6,12,10]
attention = self.do(torch.softmax(attention, dim=-1))
# In the third step, the attention result is multiplied by V to obtain the result of multi head attention
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
# Z: [64,6,12,50]
Z = torch.matmul(attention, V)
# Because query has 12 words, put 12 in the front and 5 and 60 in the back to facilitate the splicing of multiple groups of results below
# Z: [64,6,12,50] transpose - > [64,12,6,50]
Z = Z.permute(0, 2, 1, 3).contiguous()
# The matrix transformation here is to splice the results of multiple groups of attention
# The end result is [64,12300]
# Z: [64,12,6,50] -> [64,12,300]
Z = Z.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
Z = self.fc(Z)
return Z
# batch_ The size is 64 and there are 12 words. The Query vector of each word is 300 dimensions
query = torch.rand(64, 12, 300)
# batch_ The size is 64 and there are 12 words. The Key vector of each word is 300 dimensions
key = torch.rand(64, 10, 300)
# batch_ The size is 64, there are 10 words, and the Value vector of each word is 300 dimensions
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
# output: torch.Size([64, 12, 300])
print(output.shape)torch.Size([64, 12, 300])
6, Text quiz
Question 1: why does softmax calculation in transformer need to be divided by dk?
In order to eliminate the influence of vector dimension and avoid the irrationality that the larger the vector dimension is, the higher the score superposition is For details, please refer to: Why is the attention in transformer scaled?
Question 2: how to mask the padding position when calculating the attention score in transformer?
In the training process, natural language data is often input into the model in the form of batch, and the length of each sentence in a batch cannot be guaranteed to be the same, so it is necessary to use PADDING to complete all sentences to the longest length, such as taking 0 for line filling, but we know that the information of the position filled with 0 is completely meaningless, Therefore, we hope that this position will not participate in the later back propagation process. In order to avoid finally affecting the effect of the model itself, a method is proposed to Mask the completed position during training. In the calculation of self attention, we naturally don't want the attention of effective words to focus on these meaningless positions, so we use the way of PADDING MASK PADDING MASK is before softmax in the calculation of attention. Through the operation of PADDING MASK, the value at the completion position becomes a very large negative number (which can be negative infinite). In this way, when passing through the softmax layer, the probability at these positions is 0. This operation is equivalent to masking the useless information of the completion position For details, please refer to: Principle and code analysis of self attention and mask operation in Transformer
Question 3: why is positive embedding added to Transformer?
Position and order are important for some tasks, such as understanding a sentence and a video. Position and order define the syntax of sentences and the composition of videos, which are part of the semantics of sentences and videos. The recurrent neural network RNN essentially considers the order of words in sentences. Because RNN parses a sentence word by word in a sequential manner, this will integrate the order of words into RNN. Transformer uses MHSA (multi head self attention), which avoids the recursive method of RNN and speeds up the training time. At the same time, it can capture long dependencies in sentences and deal with longer inputs. When each word in the sentence passes through the Transformer's Encoder/Decoder stack at the same time, the model itself has no sense of permutation variance for each word. Therefore, a method is still needed to integrate the word order information into the model. In order to make the model aware of the input order, information about the position of each word in the sentence can be added to each word. Such information is position encoding (PE) For details, please refer to: Positive embedding in Transformer
Other references
Main development path and current mainstream methods of attention Teacher Tang Yudi - deep learning - PyTorch framework practical series Mianjing: what is Transformer location coding? Where do Q, K and V in the deep learning attention mechanism come from?
A digression: csdn's markdown is still quite convenient to write it class articles, but I want to re typeset the WeChat official account again. It's still troublesome. Today, I found a special thing, it can be a convenient transfer to WeChat official account.