JDBC is the cornerstone of java accessing database. JDO, Hibernate, MyBatis, etc. all encapsulate JDBC. If you only use the persistence layer framework, you don't need to learn JDBC, but from the perspective of the development prospect of programmers, you must master it. The framework will be updated iteratively all the time, but the principle remains the same. Only by mastering JDBC can you respond to changes with invariance, so that you can go for a long time
1, JDBC overview
JDBC: sun company provides a set of interfaces for not limited to a specific database operation. Different database manufacturers need to provide different implementations (implementation classes) for this set of interfaces. The collection of different implementations is the driver of different databases. Therefore, java programmers only need to face this set of interface programming (that is, face interface programming, and there should be no third-party code in java code).
For example, Java. Net is defined in the standard class library sql,javax. SQL is the standard Java class library used to access the database. Using these class libraries, you can access the database resources in a standard way and conveniently. Different database manufacturers need to implement their own database operation mode (driver) according to this standard
The purpose of JDBC is to facilitate the operation of different databases and the persistence of data
Persistence: save data to a power down storage device for later use, such as disk files, XML files, and databases
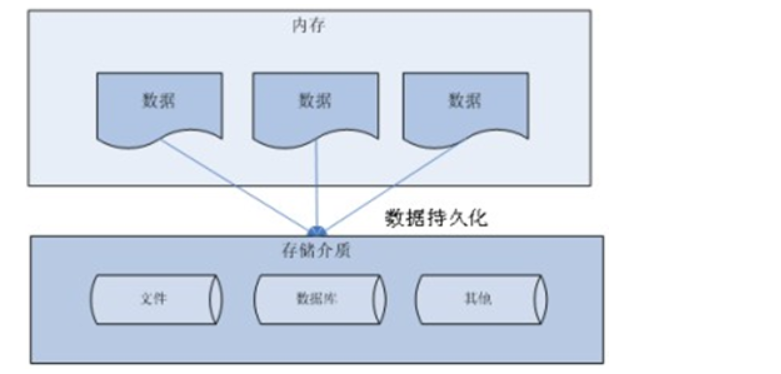
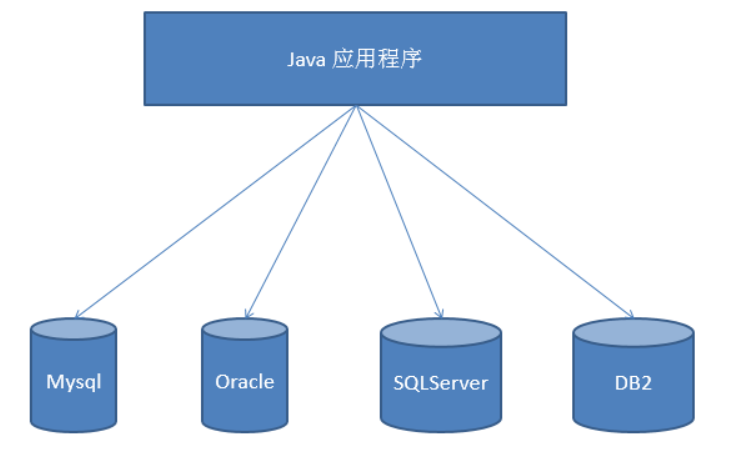
In the absence of JDBC, due to the different operation modes of different databases, the original Java code needs to be modified every time the database is switched, and the portability is very poor, as shown below
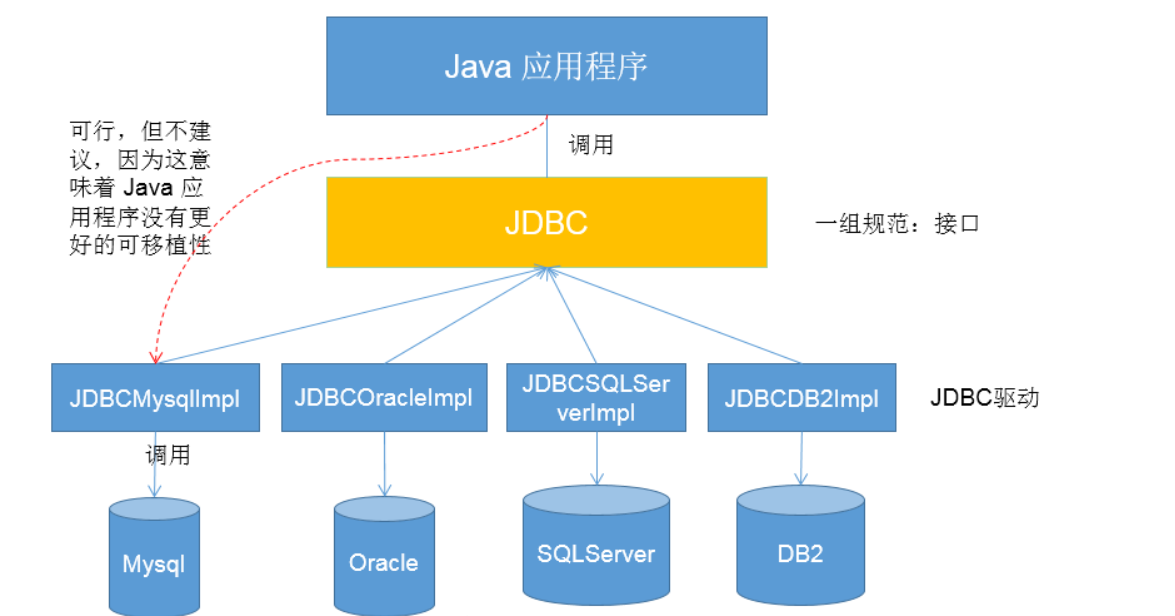
With JDBC, the Java program accesses the database as follows:
- Create the implementation class (Driver provided by a database manufacturer) object of the Driver interface in the standard class library, assign it to the interface object, and realize the upper transformation
- Call the connect method of the Driver interface to obtain the connection. Due to polymorphism and dynamic binding, the actual call is the method of the implementation class (the connect method driven and rewritten by a database manufacturer)
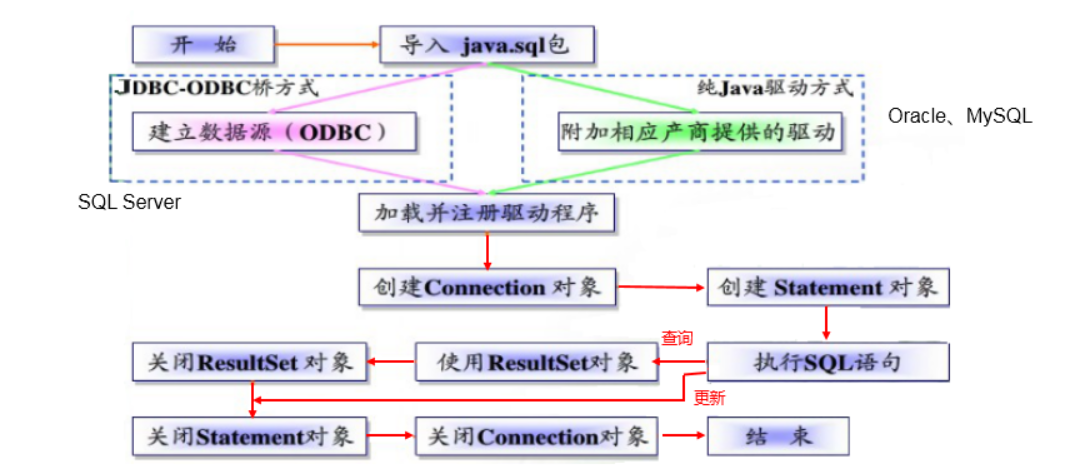
JDBC programming steps
Add: ODBC(Open Database Connectivity) is launched by Microsoft under the Windows platform. The user only needs to call ODBC API in the program, and the ODBC driver converts the call into a call request to a specific database.
2, Get database connection
2.1 Driver interface and implementation class
2.1.1 introduction to driver interface
java.sql.Driver interface is the interface that all JDBC drivers need to implement. This interface is provided for database manufacturers. Different database manufacturers provide different implementations.
- Oracle driver: Oracle jdbc. driver. OracleDriver
- mySql driver: com mySql. jdbc. Driver
To connect the java database, you need to load the database Driver (the implementation class of the Driver interface in the standard class library), so you need to import the Driver jar package of the relevant database. Here, mysql is taken as an example, Driver download address
Copy the above jar package to a directory of the Java project. It is customary to create a new lib folder.
2.1.2 load JDBC Driver (Driver implementation class)
To load the JDBC driver, you need to call the static method forName() of Class class and pass it the Class name of the JDBC driver to be loaded
- Class.forName("com.mysql.jdbc.Driver");
2.2 five connection modes of database (iteration)
Connection mode I
// Mode 1:
@Test
public void testConnection1() throws SQLException {
//1. Create Java sql. The driver interface implements the object of the class and assigns it to the interface object driver to realize the upper transformation
Driver driver = new com.mysql.jdbc.Driver();
// 2. Provide url to indicate the data of specific operation
String url = "jdbc:mysql://localhost:3306/test";
//3. Provide the object of Properties, indicating the user name and password
Properties info = new Properties();
info.setProperty("user", "root");
info.setProperty("password", "12345");
//4. Call the connect() of the driver to get the connection
Connection connect = driver.connect(url, info);
System.out.println(connect);
}
In mode 1, the API of the third-party database appears explicitly. The data related to the database is hard coded in the code and has great coupling. Whenever the database driver is switched or the data is modified, the source code needs to be modified
Connection mode II
// Mode 2: iteration of mode 1: there is no third-party api in the following programs, which makes the program more portable
@Test
public void testConnection2() throws Exception {
// 1. Use reflection to load Driver implementation class objects:
Class<?> aClass = Class.forName("com.mysql.jdbc.Driver");
// 2. Create driver (implementation class) object
Driver driver = (Driver) aClass.newInstance();
String url = "jdbc:mysql://localhost:3306/test";
String user= "root";
String password = "12345";
Properties info = new Properties();
info.setProperty("user", user);
info.setProperty("password", password);
Connection connect = driver.connect(url, info);
System.out.println(connect);
}
Compared with method 1, the Driver is instantiated only by reflection, and the API of the third-party database is not reflected in the code.
Connection mode III
// Method 3: replace Driver with Driver manager
@Test
public void testConnection3() throws Exception {
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "12345";
Class<?> aClass = Class.forName("com.mysql.jdbc.Driver");
Driver driver = (Driver) aClass.newInstance();
// Register driver
DriverManager.registerDriver(driver);
Connection connection = DriverManager.getConnection(url, user, password);
System.out.println(connection);
}
Compared with method 2, there is no need to directly access the classes that implement the Driver interface (i.e. obtain the connection through the Driver), but register the Driver in the Driver manager class (java.sql.DriverManager), and then call these Driver implementations (i.e. obtain the database connection through the DriverManager).
Connection mode IV
// Method 4: you can just load the driver without displaying the registered driver.
@Test
public void testConnection4() throws Exception {
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "12345";
Class<?> aClass = Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection(url, user, password);
System.out.println(connection);
}
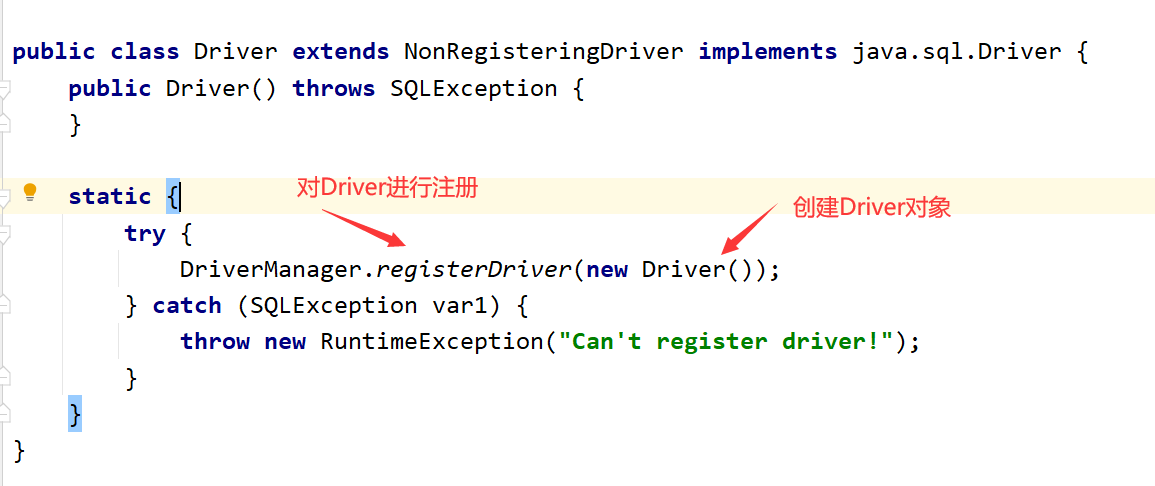
There is no need to explicitly create Driver objects and register drivers. Because there are already static code blocks in the Driver's source code (the static code will be loaded quickly with the loading of the class), the creation of the Driver object and the registration of the Driver are realized.
Connection mode V (final version)
In the above four methods, the database related information is hard coded in the code, so whenever the database information needs to be modified, the code needs to be modified.
For example, when packaging project deployment, if you modify the source code, you need to repackage the project. When the project is large, it is very time-consuming
The fifth method is to separate the code and data, save the data by using the configuration file, and load the configuration file in the code. The benefits are as follows
- If you need to modify the configuration information, you can modify it directly in the configuration file without going deep into the code
- If the configuration information is modified, the recompilation process (i.e. repackaging) is omitted.
Create a configuration file in the src directory of the project: [jdbc.properties]
user=root password=abc123 url=jdbc:mysql://localhost:3306/test driverClass=com.mysql.jdbc.Driver
//Mode 5 (final version): declare the four basic information required for database connection in the configuration file, and obtain the connection by reading the configuration file
/*
* What are the benefits of this approach?
* 1.The separation of code and data is realized. Decoupling is realized
* 2.If you need to modify the configuration file information, you can avoid repackaging the program.
*/
@Test
public void testConnection5() throws Exception {
//1. Load configuration file
InputStream is = ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties properties = new Properties();
properties.load(is);
//2. Read configuration information
String classDriver = properties.getProperty("driverClass");
String url = properties.getProperty("url");
String user = properties.getProperty("user");
String password = properties.getProperty("password");
//3. Load drive
Class.forName(classDriver);
//4. Get connection
Connection connection = DriverManager.getConnection(url, user, password);
System.out.println(connection);
}
Compared with other methods, the fifth method loads the configuration file information by obtaining the input stream of the configuration file under the class path through the getResourceAsStream method of the system class loader
2.3 URL
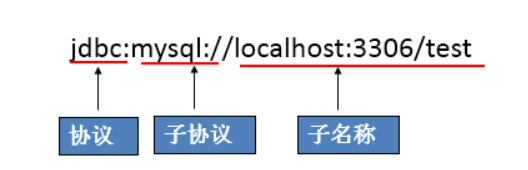
JDBC URL is used to identify a registered driver. Select the correct driver through this URL to establish a connection to the database.
The standard JDBC URL consists of three parts separated by colons.
- Master protocol: the master protocol in the JDBC URL is always jdbc
- Sub protocol: the sub protocol is used to identify a database driver
- Subname: a method of identifying a database. The sub name can be changed according to different sub protocols. The purpose of using the sub name is to provide sufficient information for locating the database. Including host name (corresponding to the ip address of the server), port number and database name
give an example:
JDBC URL s of several common databases
mysql connection URL writing method: jdbc:mysql: / / host name: mysql service port number / database name? Parameter = value & parameter = value
- jdbc: mysql://localhost:3306/zhuo (connect to the specified database zhuo)
- jdbc: mysql://localhost:3306/atguigu?useUnicode=true&characterEncoding=utf8 (if the JDBC program is inconsistent with the character set on the server side, which will lead to garbled code, you can specify the character set on the server side through parameters)
- jdbc: mysql://localhost:3306/atguigu?user=root&password=123456 (specify user and password when connecting to the database)
Oracle 9i connection URL writing method: jdbc:oracle:thin: @ host name: oracle service port number: database name
- jdbc:oracle:thin:@localhost:1521:zhuo
SQL Server connection URL writing method: jdbc:sqlserver: / / host name: sqlserver service port number: DatabaseName = database name
- jdbc:sqlserver://localhost:1433:DatabaseName=zhuo
3, PreparedStatement vs Statement
3.1 disadvantages and shortcomings of using Statement to operate data table
Create the Connection object by calling its createStatement() method. This object is used to execute static SQL statements and return execution results.
The following methods are defined in the Statement interface to execute SQL statements:
- int excuteUpdate(String sql): execute UPDATE operations INSERT, UPDATE, DELETE
- ResultSet executeQuery(String sql): execute query operation SELECT
Disadvantages of using Statement to manipulate data table:
- Problem 1: there is string splicing operation, which is cumbersome
- Problem 2: SQL injection problem
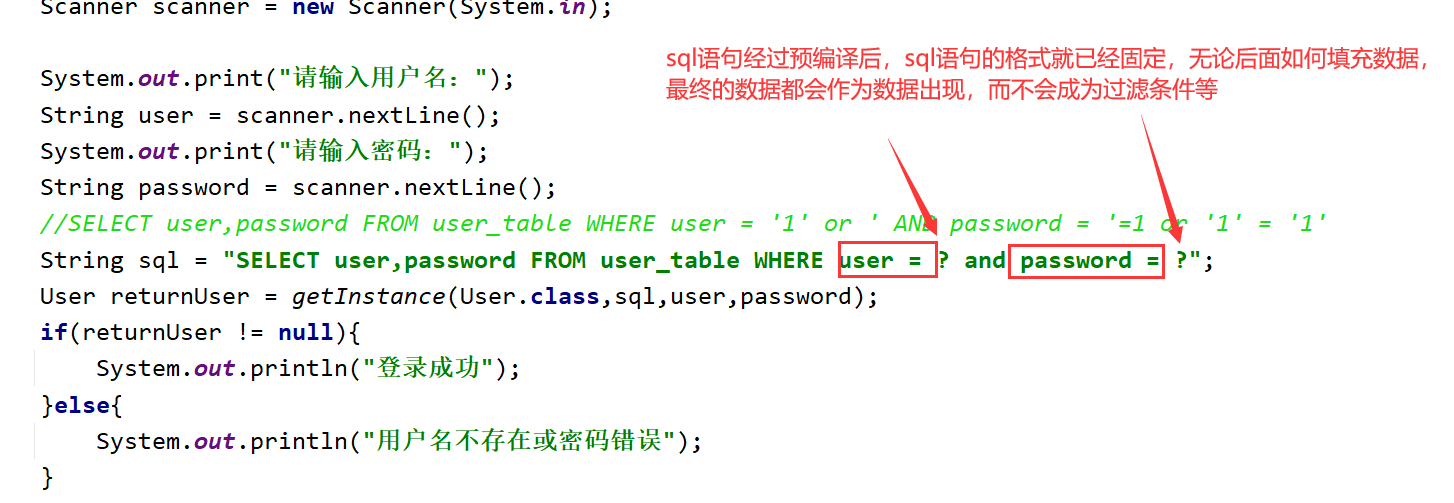
sql injection is the use of some systems that do not fully check the data entered by the user. For example, in the sql retrieval statement of user login, string splicing can be used to bypass the user login check
User login retrieval statement
 Use concatenation to bypass the check
Use concatenation to bypass the check

Code demonstration
public class StatementTest {
// Disadvantages of using Statement: you need to spell SQL statements, and there is a problem of SQL injection
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.print("user name:");
String userName = scan.nextLine();
System.out.print("password:");
String password = scan.nextLine();
String sql = "SELECT user,password FROM user_table WHERE USER = '1' or ' AND PASSWORD = '='1' or '1' = '1'";
User user = get(sql, User.class);
if (user != null) {
System.out.println("Login successful!");
} else {
System.out.println("Wrong user name or password!");
}
}
// Use Statement to realize the query operation of data table
public static <T> T get(String sql, Class<T> clazz) {
T t = null;
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
// 1. Load configuration file
InputStream is = StatementTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
// 2. Read configuration information
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
// 3. Load drive
Class.forName(driverClass);
// 4. Get connection
conn = DriverManager.getConnection(url, user, password);
st = conn.createStatement();
rs = st.executeQuery(sql);
// Get metadata of result set
ResultSetMetaData rsmd = rs.getMetaData();
// Gets the number of columns in the result set
int columnCount = rsmd.getColumnCount();
if (rs.next()) {
t = clazz.newInstance();
for (int i = 0; i < columnCount; i++) {
// 1. Get alias of column
String columnName = rsmd.getColumnLabel(i + 1);
// 2. Obtain the data in the corresponding data table according to the column name
Object columnVal = rs.getObject(columnName);
// 3. Encapsulate the data obtained from the data table into the object
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);
field.set(t, columnVal);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// close resource
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return null;
}
}
In the Statement statement, because the Statement acts as a messenger, it cannot be precompiled, that is, whenever there is a Statement, it will be sent to the database for execution, that is, the user can use string splicing to inject sql filter conditions to bypass the check.
Disadvantages of using Statement to manipulate data table:
Cannot operate Blog data
In the Statement operation database, Statement filling data can only be concatenated, while BLOB type data cannot be written by string splicing (blog data needs to be filled with IO stream)
Poor batch operation performance
In the Statement statement, the Statement cannot be precompiled. Even if it is the same operation, the whole Statement itself cannot match due to different data contents. Therefore, there is no meaning of caching the Statement, and the performance of batch operation is poor
In fact, no database will cache the compiled execution code of ordinary statements (that is, the sql statements sent by statements to the database). In this way, the incoming Statement will be compiled every time the Statement statement (sql) is executed.
3.2 advantages of Preparedstatement over Statement
PreparedStatement
- The PreparedStatement object can be obtained by calling the preparedStatement(String sql) method of the Connection object
- PreparedStatement interface is a sub interface of Statement, which represents a precompiled SQL Statement
- The parameters in the SQL statement represented by the PreparedStatement object are marked with a question mark (?) Call the setXxx() method of the PreparedStatement object to set these parameters The setXxx() method has two parameters. The first parameter is the index of the parameter in the SQL statement to be set (starting from 1), and the second parameter is the value of the parameter in the SQL statement to be set
PreparedStatement can prevent SQL injection
PreparedStatement statement is a precompiled statement, so why can SQL injection be prevented?
Because the PreparedStatement no longer injects data through concatenation, but fills the data through placeholders, so that when the sql is precompiled, its sql statement can be determined. No matter how the data is filled later, the final data will be considered as data rather than keywords (sql filter conditions, etc.)
PreparedStatement enables more efficient batch operations
DBServer provides performance optimization for precompiled statements. As long as there are statements that need to be pre compiled and executed directly after the compiler calls, the same statements that need to be pre compiled will be obtained as long as the compiler calls the pre compiled statements.
The precompiled statements executed by batch operations are the same, but the filled data is different, so they will be cached, so more efficient batch operations can be realized
PreparedStatement can manipulate Blog data
PreparedStatement is filled with data through placeholders, so you can write data to individual blog fields through io streams
4, CRUD operation using PreparedStatement
4.1 operation and access to database
Database connection is used to send commands and SQL statements to the database server and accept the results returned by the database server. In fact, a database connection is a Socket connection.
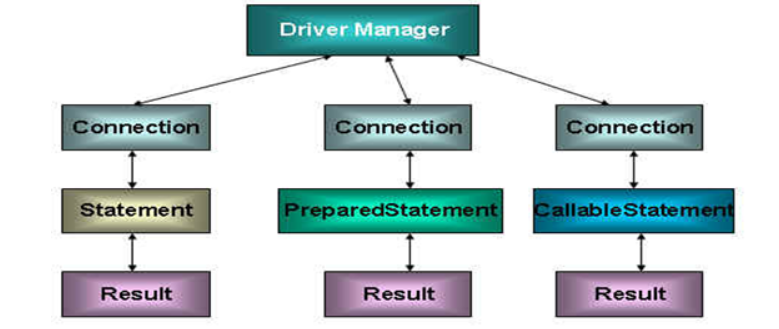
In Java There are three interfaces in the SQL package that define different ways of calling the database:
- Statement: an object used to execute a static sql statement and return the results it generates (there is a risk of sql injection and has been replaced by PrepatedStatement).
- PrepatedStatement: the SQL statement is precompiled and stored in this object, which can be used to execute the statement multiple times efficiently.
- CallableStatement: used to execute SQL stored procedures
4.2 add, delete and change operations (iteration) using PreparedStatement
Since the addition, deletion and modification operations are basically the same, the following insert statement is used to demonstrate the iteration of addition, deletion, modification and query
Version one
@Test
public void testInsert() {
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
// Get the system class loader, call the getResourceAsStream method of the system class loader, load the file of the class path, and get the input stream
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("jdbc.properties");
// Get profile information
Properties properties = new Properties();
properties.load(is);
String driverClass = properties.getProperty("driverClass");
String url = properties.getProperty("url");
String user = properties.getProperty("user");
String password = properties.getProperty("password");
// Load driver
Class.forName(driverClass);
// Call driver manager to get database connection
connection = DriverManager.getConnection(url, user, password);
String sql = "insert into customers(name,email,birth) value(?,?,?)";
// Precompiled sql
preparedStatement = connection.prepareStatement(sql);
// Fill placeholder
preparedStatement.setString(1, "Delireba");
preparedStatement.setString(2, "stormzhuo@163.com");
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
Date date = simpleDateFormat.parse("1998-07-07");
preparedStatement.setDate(3, new java.sql.Date(date.getTime()));
// Execute sql statement
preparedStatement.execute();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (preparedStatement != null) {
preparedStatement.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if (connection != null) {
connection.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
There are too many redundant codes in version 1. For example, when adding, deleting and modifying other tables, you need to input the above codes repeatedly. Therefore, you need to extract the codes of the same operations for adding, deleting and modifying other tables to construct a method
Version 2
From version 1, you can know that no matter which table is added, deleted, modified or queried, you need to obtain the database connection first, and then close the resources. Therefore, you can extract these same operations into methods and put them in the tool class
JDBCUtils.java
public class JDBCUtils {
// Get database connection
public static Connection getConnection() throws Exception {
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
String driverClass = pros.getProperty("driverClass");
String url = pros.getProperty("url");
String user = pros.getProperty("user");
String password = pros.getProperty("password");
Class.forName(driverClass);
Connection conn = DriverManager.getConnection(url, user, password);
return conn;
}
// close resource
public static void closeResource(Connection conn, Statement stat) {
try {
if (conn != null) {
conn.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if (stat != null) {
stat.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
test
@Test
public void testUpdate() {
Connection conn = null;
PreparedStatement ps = null;
try {
//1. Get the connection to the database
conn = JDBCUtils.getConnection();
//2. Precompile the sql statement and return the instance of PreparedStatement
String sql = "update customers set name=? where id=?";
ps = conn.prepareStatement(sql);
//3. Fill placeholder
ps.setObject(1, "Mr. Cang");
ps.setObject(2, 18);
//4. Implementation
ps.execute();
} catch (Exception e) {
e.printStackTrace();
} finally {
//5. Closure of resources
JDBCUtils.closeResource(conn, ps);
}
}
Version 2 has been optimized to reduce the redundant code for obtaining database connection and closing resources
Version 3 (general addition, deletion and modification)
To add, delete or change the database, you first need to obtain the connection, then precompile the sql statement, and finally fill in the placeholder. In this process, only the number of filled placeholders is different, and the filled placeholders can be solved by deformable parameters, so these operations can be extracted into a general addition, deletion and modification operation
//General addition, deletion and modification operations
public void update(String sql, Object ... args) {
Connection conn = null;
PreparedStatement ps = null;
try {
//1. Get the connection to the database
conn = JDBCUtils.getConnection();
//2. Precompile the sql statement and return the instance of PreparedStatement
ps = conn.prepareStatement(sql);
//3. Fill placeholder
for (int i = 0; i < args.length; i++) {
//Beware of parameter declaration error!! The database index starts at 1
ps.setObject(i + 1, args[i]);
}
//4. Implementation
ps.execute();
} catch (Exception e) {
e.printStackTrace();
} finally {
//5. Closure of resources
JDBCUtils.closeResource(conn, ps);
}
}
Version 3 is a general addition, deletion and modification operation, that is, any field of any table can be operated. For different field filling problems, variable parameters are used
4.3 using PreparedStatement to realize query operation (iteration)
4.3.1 data type conversion table corresponding to Java and SQL
| Java type | SQL type |
|---|---|
| boolean | BIT |
| byte | TINYINT |
| short | SMALLINT |
| int | INTEGER |
| long | BIGINT |
| String | CHAR,VARCHAR,LONGVARCHAR |
| byte array | BINARY , VAR BINARY |
| java.sql.Date | DATE |
| java.sql.Time | TIME |
| java.sql.Timestamp | TIMESTAMP |
4.3.2 ResultSet and ResultSetMetaData
ResultSet
- The query needs to call the executeQuery() method of PreparedStatement, and the query result is a ResultSet object
- The ResultSet object encapsulates the result set of database operation in the form of logical table, and the ResultSet interface is provided by the database manufacturer
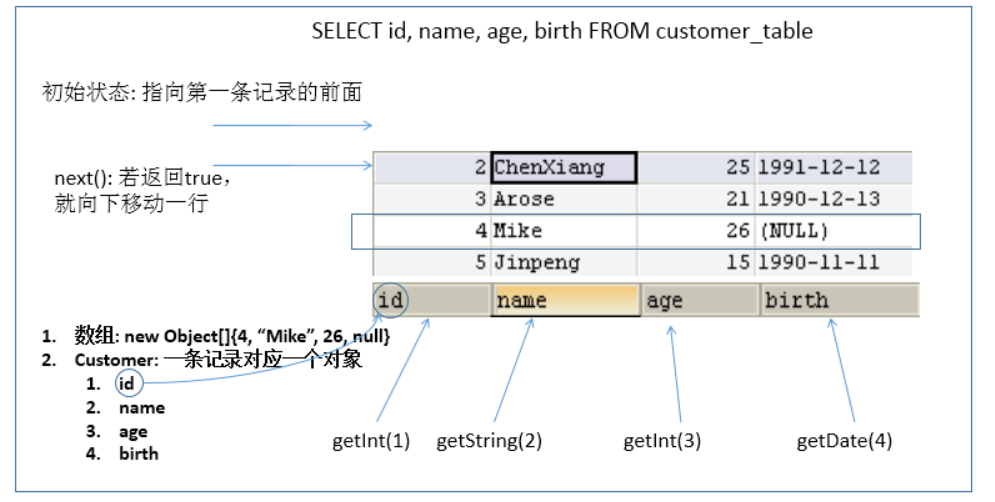
- What ResultSet returns is actually a data table. There is a pointer to the front of the first record in the data table.
- The ResultSet object maintains a cursor pointing to the current data row. Initially, the cursor is before the first row and can be moved to the next row through the next() method of the ResultSet object. Call the next () method to check whether the next line is valid. If valid, the method returns true and the pointer moves down. It is equivalent to the combination of hasNext() and next () methods of Iterator object.
- When the pointer points to a row, you can get the value of each column by calling getXxx(int index) or getXxx(int columnName).
- For example: getInt(1), getString("name") (it is recommended to use key to obtain the value of each column, that is, see the meaning of name)
-
Note: the indexes in the relevant Java API s involved in the interaction between Java and database start from 1.
ResultSetMetaData
After obtaining the ResultSet of the result set, how to know which columns are in the result set? What is the listing?
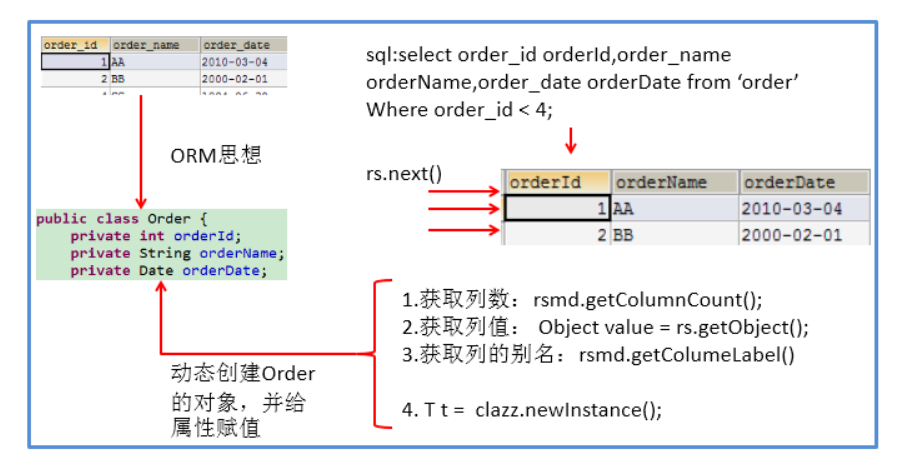
You need to use an object that describes the ResultSet, that is, resultsetmetadata
About ResultSetMetaData
- How to get ResultSetMetaData: just call the getMetaData() method of ResultSet
- Get the number of columns in the ResultSet: call the getColumnCount() method of ResultSetMetaData
- Get the column name or alias of each column in the ResultSet: call the getColumnName or getColumnLabel() method of ResultSetMetaData
ResultSetMetaData other methods
-
getColumnTypeName(int column): retrieves the database specific type name of the specified column.
-
getColumnDisplaySize(int column): indicates the maximum standard width of the specified column, in characters.
-
isNullable(int column): indicates whether the value in the specified column can be null.
-
isAutoIncrement(int column): indicates whether the specified columns are automatically numbered so that they are still read-only.
4.3.3 table query operation (iteration)
Query operation on a single table (iteration)
Version one
@Test
public void testQuery() {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
String sql = "SELECT id,name,email,birth FROM customers WHERE id=?";
ps = conn.prepareStatement(sql);
ps.setObject(1, "2");
rs = ps.executeQuery();
if (rs.next()) {
Integer id = rs.getInt(1);
String name = rs.getString(2);
String email = rs.getString(3);
Date birth = rs.getDate(4);
Customers customers = new Customers(id, name, email, birth);
System.out.println(customers);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps, rs);
}
}
Version 1 does not have generality for the query of a single table, that is, if the query field of the sql statement is changed, the field returned by the result set will also be changed. Therefore, the code encapsulated in the entity class in the result set also needs to be modified
Version 2 (general query of single table)
The query operation in version 1 contains a lot of redundant code, that is, obtaining the database connection, precompiling sql, filling placeholders, executing sql to obtain the result set, and the query result set is encapsulated in the entity class. Therefore, these operations can be extracted separately to become a general query method for a single table
Filling placeholders can be solved by deformable parameters, but it is troublesome to encapsulate the result set in entity classes, because the result sets returned by different field queries of a single table are different.
For the result set obtained by querying different fields of a single table, you can obtain metadata ResultSetMetaData through getMetaData, and then obtain the number of columns contained in the result set through metadata. When you know the number of columns, you can traverse the number of columns to obtain the value of each column
However, we don't know which column name corresponds to the value of each column. Therefore, in the process of traversal, we also need to obtain the column name corresponding to the current column value through metadata, and finally encapsulate the data in the entity class through reflection
// General query operation for customers table
public Customers customersForQuery(String sql, Object ... args) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
//Execute, get result set
rs = ps.executeQuery();
//Get metadata of result set
ResultSetMetaData rsmd = rs.getMetaData();
//Get the number of columns
if (rs.next()) {
Customers customers = new Customers();
//Gets the number of columns in the result set
int columnCount = rsmd.getColumnCount();
for (int i = 0; i < columnCount; i++) {
//Get the column value of each column: through ResultSet
Object columnValue = rs.getObject(i + 1);
//Get alias of column: getColumnLabel()
String columnName = rsmd.getColumnLabel(i + 1);
//Through reflection, assign the property of the specified object name getColumnLabel to the specified value columnValue
Field field = Customers.class.getDeclaredField(columnName);
field.setAccessible(true);
field.set(customers, columnValue);
}
return customers;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps, rs);
}
return null;
}
test
@Test
public void testQueryForCustomer() {
String sql = "SELECT id,name,email,birth FROM customers WHERE id=?";
Customers customers = customersForQuery(sql, 6);
System.out.println(customers);
sql = "SELECT email,birth FROM customers WHERE name=?";
customers = customersForQuery(sql, "Jay Chou");
System.out.println(customers);
}
General query operation for different tables (return a record in the table)
The query operation of different tables is similar to that of a single table. The main reason is that the encapsulated entity classes are different, that is, querying different tables requires returning the entities of the corresponding table. Therefore, generic methods can be used.
The value returned by a generic method is a generic entity, and the actual type is determined by the caller. That is, you need to provide a generic parameter in the generic method to let the caller provide a specific entity class
// For the general query operation of different tables, return a record in the table
public <T> T getInstance(Class<T> aClass, String sql, Object ... args) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
rs = ps.executeQuery();
// Get metadata of result set: ResultSetMetaData
ResultSetMetaData rsmd = rs.getMetaData();
if (rs.next()) {
// Get the object through the Class instance, that is, reflection
T t = aClass.newInstance();
// Get the number of columns in the result set through ResultSetMetaData
int columnCount = rsmd.getColumnCount();
// Process each column in a row of data in the result set
for (int i = 0; i < columnCount; i++) {
// Get column value
Object columnValue = rs.getObject(i + 1);
// Gets the column name of each column
String columnLabel = rsmd.getColumnLabel(i + 1);
// The columnLabel attribute assigned to the t object is assigned columnvalue: through reflection
Field field = aClass.getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t, columnValue);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps, rs);
}
return null;
}
test
@Test
public void testGetInstance() {
String sql = "SELECT id,name,email,birth FROM customers WHERE id=?";
Customers customers = getInstance(Customers.class, sql, 12);
System.out.println(customers);
sql = "SELECT order_id as orderId,order_name as orderName,order_date as orderDate FROM `order` WHERE order_id=?";
Order order = getInstance(Order.class, sql, 1);
System.out.println(order);
}
General query operation for different tables (return multiple records in the table)
If multiple records are returned, that is, the result set returned by the query contains multiple records, you need to change if (rs.next()) to while (rs.next()), and finally add the encapsulated entity class to the List set
public <T> List<T> getForList(Class<T> aClass, String sql, Object ... args) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
rs = ps.executeQuery();
//Create collection object
List<T> list = new ArrayList<>();
// Get metadata of result set: ResultSetMetaData
ResultSetMetaData rsmd = rs.getMetaData();
while (rs.next()) {
T t = aClass.newInstance();
// Get the number of columns in the result set through ResultSetMetaData
int columnCount = rsmd.getColumnCount();
// Process each column in a row of data in the result set: assign a value to the attribute specified by the t object
for (int i = 0; i < columnCount; i++) {
// Get column value
Object columnValue = rs.getObject(i + 1);
// Gets the column name of each column
String columnLabel = rsmd.getColumnLabel(i + 1);
// The columnName attribute specified to the t object is assigned a value of columnvalue: through reflection
Field field = t.getClass().getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t, columnValue);
}
list.add(t);
}
return list;
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps, rs);
}
return null;
}
test
@Test
public void testGetForList() {
String sql = "SELECT id,name,email,birth FROM customers WHERE id<?";
List<Customers> customersList = getForList(Customers.class, sql, 12);
customersList.forEach(System.out::println);
}
4.4 release of resources
At present, there are three resultsets, statement and connection resources to be released. Therefore, a general method to close resources can be written in JDBC utils, as follows
public static void closeResource(Connection conn, Statement stat, ResultSet rs) {
try {
if (conn != null) {
conn.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if (stat != null) {
stat.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if (rs != null) {
rs.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
Database Connection is a very rare resource, which must be released immediately after use. If the Connection cannot be closed in time and correctly, it will lead to system downtime. The use principle of Connection is to create as late as possible and release as early as possible.
It can be closed in finally to ensure that other code exceptions occur in time, and resources can be closed.
4.5 JDBC API summary
Two thoughts
-
The idea of interface oriented programming
-
ORM (object relational mapping)
- A data table corresponds to a java class
- A record in the table corresponds to an object of the java class
- A field in the table corresponds to an attribute of the java class
sql needs to be written in combination with column names and table attribute names. Note the alias.
Two technologies
- Metadata of JDBC result set: ResultSetMetaData
- Get the number of columns: getColumnCount()
- Get alias of column: getColumnLabel()
- Through reflection, create the object of the specified class, obtain the specified attribute and assign a value
5, Operation BLOB type field
5.1 MySQL BLOB type
In MySQL, BLOB is a large binary object. It is a container that can store a large amount of data. It can hold data of different sizes.
PreparedStatement must be used for inserting BLOB type data, because BLOB type data cannot be spliced with strings.
The four BLOB types of MySQL (they are the same except that they are different in the maximum amount of information stored), as follows
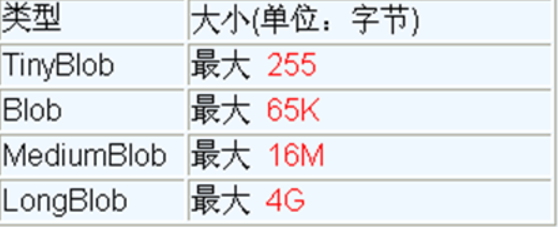
It should be noted that if the stored file is too large, the performance of the database will decline.
If the error xxx too large is reported after specifying the relevant Blob type, find my. In the mysql installation directory INI file plus the following configuration parameters: max_allowed_packet=16M. Also note: modified my After the. INI file, you need to restart the mysql service.
5.2 insert big data type into data table
@Test
public void testInsert() {
Connection conn = null;
PreparedStatement ps = null;
try {
conn = JDBCUtils.getConnection();
String sql = "INSERT INTO customers(name,email,birth,photo) values(?,?,?,?)";
ps = conn.prepareStatement(sql);
ps.setObject(1, "Mr. Cang");
ps.setObject(2, "stormzhuo@163.com");
ps.setObject(3,"1998-07-07");
// Manipulate variables of Blob type
FileInputStream fis = new FileInputStream(new File("thumb.png"));
ps.setBlob(4, fis);
int i = ps.executeUpdate();
if (i > 0) {
System.out.println("Added successfully");
} else {
System.out.println("Add failed");
}
} catch (Exception e) {
e.printStackTrace();
}
JDBCUtils.closeResource(conn, ps);
}
First, read the file data through the byte node input stream, and then write the file data into the Blog field through the setBlog method of PreparedStatement
5.2 reading big data type from data table
@Test
public void testQuery() {
InputStream is = null;
FileOutputStream fos = null;
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = JDBCUtils.getConnection();
String sql = "SELECT id,name,email,birth,photo FROM customers WHERE id=?";
ps = conn.prepareStatement(sql);
ps.setObject(1, 16);
rs = ps.executeQuery();
if (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
String email = rs.getString("email");
Date birth = rs.getDate("birth");
Customers customers = new Customers(id, name, email, birth);
System.out.println(customers);
//Read Blob type fields
Blob photo = rs.getBlob("photo");
// Get byte input stream through getBinaryStream of Blob
is = photo.getBinaryStream();
// Create byte node output stream
fos = new FileOutputStream("zhuyin.jpg");
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (is != null) {
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
JDBCUtils.closeResource(conn, ps, rs);
}
}
First, the Blog field object is obtained through the getBlob method of the result set ResultSet, then the getBinaryStream input method is obtained by calling Blog's getBinaryStream method. Finally, the byte node output stream is created to output Blog data to the specified file.
6, Batch operation
6.1 batch processing SQL statements
Batch processing
Batch processing is the processing of SQL statements in batches, rather than one statement by one. For example, when you have multiple SQL statements to execute, send one statement to the server at a time, which can also achieve results, but the efficiency is very poor. Batch processing can be used to deal with this problem (that is, send multiple SQL statements to the server at one time, and then let the server process at one time). Batch processing is only for update statements (add, delete and modify), All batches have nothing to do with queries.
When you need to insert or update records in batches, you can use the batch update mechanism of Java, which allows multiple statements to be submitted to the database for batch processing at one time. Generally, it is more efficient than submitting processing separately
JDBC batch processing statements include the following three methods:
- addBatch(String): add SQL statements or parameters that need batch processing;
- executeBatch(): execute batch processing statements;
- clearBatch(): clear cached data
Generally, we will encounter two cases of batch execution of SQL statements:
- Batch processing of multiple SQL statements;
- Batch parameter transfer of an SQL statement;
6.2 efficient batch insertion (iteration)
Example: insert 20000 pieces of data into the data table
- Provide a goods table in the database. Create the following:
CREATE TABLE goods( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) );
preparation
The mysql server turns off batch processing by default. We need to use a parameter to enable mysql to turn on batch processing support.
?rewriteBatchedStatements=true Written in the configuration file url behind
You need to use the updated MySQL driver: mysql-connector-java-5.1.37-bin jar
Implementation level 1: use Statement
@Test
public void testInsert1() throws Exception {
Connection conn = null;
Statement statement = null;
try {
long start = System.currentTimeMillis();
conn = JDBCUtils.getConnection();
statement = conn.createStatement();
for (int i = 1; i <= 20000; i++) {
String sql = "INSERT INTO goods(name) values('name_" + i + "')";
//1. "Save" sql
statement.addBatch(sql);
if (i % 500 == 0) {
//2. Implementation
statement.executeBatch();
//3. Empty
statement.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("Execution time:" + (end - start));
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, statement);
}
}
Execution time

Although batch processing can also be realized by using Statement object, this method is too inefficient because all its SQL statements are not precompiled, and the database does not provide cache for SQL statements that are not precompiled
Implementation level 2: use PreparedStatement
@Test
public void testInsert3() {
Connection conn = null;
PreparedStatement ps = null;
try {
long start = System.currentTimeMillis();
conn = JDBCUtils.getConnection();
String sql = "INSERT INTO goods(name) values(?)";
ps = conn.prepareStatement(sql);
for (int i = 1; i <= 20000; i++) {
ps.setObject(1, "name_" + i);
//1. "Save" sql
ps.addBatch();
if (i % 500 == 0) {
//2. Implementation
ps.executeBatch();
//3. Empty
ps.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("Execution time:" + (end - start));
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps);
}
}
Execution time

PreparedStatement can precompile sql statements, and the database supports caching for precompiled sql, so it is more efficient
Implementation level 3: PreparedStatement (optimization)
The second level is to save a certain amount of sql and send it to the database for execution. Because the PreparedStatement is used, the database will cache the same sql, so the batch operation efficiency is high
So can you save all the sql statements and then send them to sql for execution?
Since we save sql through the remainder conditions, when the conditions are met, batch sql statements will be executed, so the optimization space is to prevent it from submitting data when executing batch sql statements.
DML (add, delete and modify operation) submits data by default, that is, it will be submitted to the database every time the extract method is executed. Therefore, it is necessary to turn off automatic submission before executing the extract method and submit data after praising all sql statements
@Test
public void testInsert4() throws Exception {
Connection conn = null;
PreparedStatement ps = null;
try {
long start = System.currentTimeMillis();
conn = JDBCUtils.getConnection();
//1. Set not to submit data automatically
conn.setAutoCommit(false);
String sql = "INSERT INTO goods(name) values(?)";
ps = conn.prepareStatement(sql);
for (int i = 1; i <= 20000; i++) {
ps.setObject(1, "name_" + i);
//1. "Save" sql
ps.addBatch();
if (i % 500 == 0) {
//2. Implementation
ps.executeBatch();
//3. Empty
ps.clearBatch();
}
}
//2. Submit data
conn.commit();
long end = System.currentTimeMillis();
System.out.println("Execution time:" + (end - start));
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, ps);
}
}
Execution time

7, Database transaction
7.1 introduction to database transactions
Transaction: a set of logical operation units that transform data from one state to another.
Transaction processing (transaction operation): ensure that all transactions are executed as a unit of work. Even if there is a failure, this execution mode cannot be changed. When multiple operations are performed in a transaction, or all operations are committed, the changes are permanently saved; Or the database management system will discard all modifications made and roll back the whole transaction to the original state.
In order to ensure the consistency of data in the database, the manipulation of data should be a discrete group of logical units: when it is completed, the consistency of data can be maintained. When some operations in this unit fail, the whole transaction should be regarded as an error, and all operations after the starting point should be returned to the starting state.
7.2 JDBC transaction processing
Once the data is submitted, it cannot be rolled back. So when does data mean submission?
- When a connection object is created, the transaction is automatically committed by default: each time an SQL statement is executed, if the execution is successful, it will be automatically committed to the database instead of rolling back.
- Close the database connection and the data will be submitted automatically. If there are multiple operations, and each operation uses its own separate connection, the transaction cannot be guaranteed. That is, multiple operations of the same transaction must be under the same connection.
In order to execute multiple SQL statements as a transaction in JDBC program, the following things need to be done
- Call setAutoCommit(false) of Connection object; To cancel the auto commit transaction
- After all SQL statements have been successfully executed, call commit(); Method commit transaction
- When an exception occurs, call rollback(); Method rolls back the transaction
If the Connection is not closed at this time and may be reused, you need to restore its automatic submission state setAutoCommit(true). Especially when using database Connection pool technology, it is recommended to restore the automatic submission state before executing the close() method.
[case: user AA transfers 100 to user BB]
We can use the general update method of adding, deleting and modifying operations above, but the database connection will be closed after the update is executed. To support transactions, we need to modify the update
//General addition, deletion and modification operations after using transactions
public int update(Connection conn, String sql, Object ... args) {
PreparedStatement ps = null;
try {
// 1. Get the instance of PreparedStatement (or: precompiled sql statement)
ps = conn.prepareStatement(sql);
// 2. Fill placeholder
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
// 3. Execute sql statement
return ps.executeUpdate();
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
// 4. Close resources
JDBCUtils.closeResource(null, ps);
}
return 0;
}
Let's simulate that user AA transfers 100 to BB quickly. If the transfer is successful, AA will decrease by 100 and BB will increase by 100
Not using transactions
@Test
public void testUpdate() {
String sql = "UPDATE user_table SET balance=balance-100 WHERE user=?";
int i = update(sql, "AA");
// Analog network exception
System.out.println(10 / 0);
sql = "UPDATE user_table SET balance=balance+100 WHERE user=?";
int i2 = update(sql, "BB");
System.out.println("Transfer succeeded");
}
The transfer of 100 from AA to BB will execute two sql statements, one is AA minus 100 and the other is BB plus 100. When the AA minus 100 operation is completed, we simulate the network exception. At this time, the BB plus 100 operation will not be executed
Usage of transactions
To execute multiple SQL statements as a transaction, first ensure that multiple SQL statements are executed under the same connection, because the data will be submitted automatically when the database connection is closed.
Secondly, you need to turn off automatic data submission, because DML(insert,delete,update) automatically submits data by default, that is, after adding, deleting and modifying, the data will be automatically submitted to the database
After the transaction is used, when an exception occurs during the execution, the data can be rolled back to the original initial state because the committed database is not used
@Test
public void testUpdateWithTransaction() {
Connection conn = null;
try {
// 1. Get database connection
conn = JDBCUtils.getConnection();
// 2. Turn off automatic data submission and turn on transactions
conn.setAutoCommit(false);
// 3. Database operation
String sql = "UPDATE user_table SET balance=balance-100 WHERE user=?";
int i1 = update(conn, sql, "AA");
// Analog network exception
System.out.println(10 / 0);
sql = "UPDATE user_table SET balance=balance+100 WHERE user=?";
int i2 = update(conn, sql, "BB");
// 4. If there is no exception, commit the transaction
conn.commit();
System.out.println("Transfer succeeded");
} catch (Exception e) {
e.printStackTrace();
try {
//6. Restore the automatic submission function of each DML operation
conn.rollback();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
} finally {
//7. Close the connection
JDBCUtils.closeResource(conn, null);
}
}
7.3 ACID attribute of transaction
-
Atomicity
Atomicity means that a transaction is an inseparable unit of work, and operations in a transaction either occur or do not occur. -
Consistency
Transactions must transition the database from one consistency state to another. -
Isolation
Transaction isolation means that the execution of a transaction cannot be disturbed by other transactions, that is, the operations and data used in a transaction are isolated from other concurrent transactions, and the concurrent transactions cannot interfere with each other. -
Durability
Persistence means that once a transaction is committed, its changes to the data in the database are permanent, and other subsequent operations and database failures should not have any impact on it.
7.3.1 concurrency of database
For multiple transactions running at the same time, when these transactions access the same data in the database, if the necessary isolation mechanism is not taken, various concurrency problems will be caused:
- Dirty read: for two transactions T1 and T2, if T1 reads the fields that have been updated by T2 but have not been committed. Then, if T2 rolls back, the content read by T1 is temporary and invalid.
- Non repeatable reading: for two transactions T1 and T2, if T1 reads a field, then T2 updates the field. After that, T1 reads the same field again, and the value is different.
- Phantom reading: for two transactions T1 and T2, if T1 reads a table, then T2 inserts some new rows into the table. After that, if T1 reads the same table again, several more rows will appear.
7.3.2 four isolation levels
Isolation of database transactions: the database system must have the ability to isolate and run various transactions concurrently, so that they will not affect each other and avoid various concurrency problems.
The database provides four transaction isolation levels to solve different concurrency problems:
| Isolation level | describe |
|---|---|
| Read uncommitted | Allow transactions to read changes that are not committed by other things Dirty reading, unrepeatable reading and unreal reading will all appear |
| Read committed | Transactions are only allowed to read changes that have been committed by other transactions Dirty reading can be avoided, but non repeatable reading and unreal reading problems may still occur |
| Repeatable read | Ensure that transactions can read the same value from a field multiple times During the duration of this transaction, other things are prohibited from updating this field It can avoid dirty reading and unrepeatable reading, but the problem of unreal reading still exists |
| Serializable | Ensure that transactions can read the same rows from a table During the duration of this transaction, other transactions are prohibited from performing insert, update and delete operations on the table All concurrency problems can be avoided, but the performance is very low |
The degree to which a transaction is isolated from other transactions is called the isolation level. The database specifies a variety of transaction isolation levels. Different isolation levels correspond to different interference levels. The higher the isolation level, the better the data consistency, but the weaker the concurrency.
Two isolation levels are supported: Oracle commit transaction and Oracle commit transaction. The default transaction isolation level of Oracle is read committed.
Mysql supports four transaction isolation levels. The default transaction isolation level of Mysql is REPEATABLE READ.
7.3.3 setting isolation level in Java to solve concurrency problems
Read uncommitted
Three kinds of concurrency problems have not been solved, namely dirty reading, non repeatable reading and phantom reading
Next, a query transaction and an update transaction are used as two threads to demonstrate dirty reading, that is, before one user reads the table data, the table data updated by another user is not submitted to the database (that is, the final database data is unchanged). At this time, the data read by the user is the data after updating the table, However, the user's data is not submitted to the database, so dirty reading occurs.
In the previous query statement, when the statement is executed, the database connection will be closed, so it needs to be changed to support transactions, that is, the connection will not be closed.
public <T> T getInstance(Connection conn, Class<T> aClass, String sql, Object ... args) {
PreparedStatement ps = null;
ResultSet rs = null;
try {
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
rs = ps.executeQuery();
ResultSetMetaData rsmd = rs.getMetaData();
if (rs.next()) {
T t = aClass.newInstance();
int columnCount = rsmd.getColumnCount();
for (int i = 0; i < columnCount; i++) {
Object columnValue = rs.getObject(i + 1);
String columnLabel = rsmd.getColumnLabel(i + 1);
Field field = aClass.getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t, columnValue);
}
return t;
}
} catch (Exception throwables) {
throwables.printStackTrace();
} finally {
JDBCUtils.closeResource(null, ps, rs);
}
return null;
}
Test code
First set the isolation level to READ UNCOMMITTED, and then turn off automatic data submission
Secondly, after executing sql statements, do not close the database connection, because closing the connection will automatically submit data
Finally, for the update transaction, in order to see the obvious dirty reading in the query transaction, you need to use sleep to block and suspend the thread after executing the update transaction
@Test
public void testTransactionSelect() throws Exception {
Connection conn = JDBCUtils.getConnection();
conn.setTransactionIsolation(1);
conn.setAutoCommit(false);
String sql = "SELECT user, password, balance FROM user_table WHERE user=?";
User user = getInstance(conn, User.class, sql, "CC");
System.out.println(user);
}
@Test
public void testTransactionUpdate() throws Exception {
Connection conn = JDBCUtils.getConnection();
conn.setTransactionIsolation(1);
conn.setAutoCommit(false);
String sql = "UPDATE user_table SET balance=? WHERE user=?";
int cc = update(conn, sql, 5000, "CC");
Thread.sleep(15000);
System.out.println("Update successful");
}
When the select statement is executed first, the queried balance is 2000
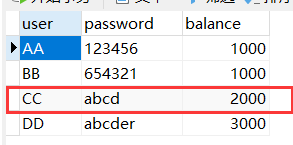
After the update statement is executed, when the select statement is executed, the queried balance is 5000
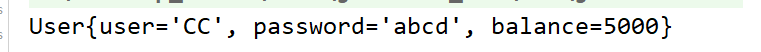
Finally, after the update operation is completed, the balance queried again becomes the original 2000

Read committed
Dirty reading is solved, but non repeatable reading and phantom reading are not solved
You only need to modify the isolation level in the above code, as follows
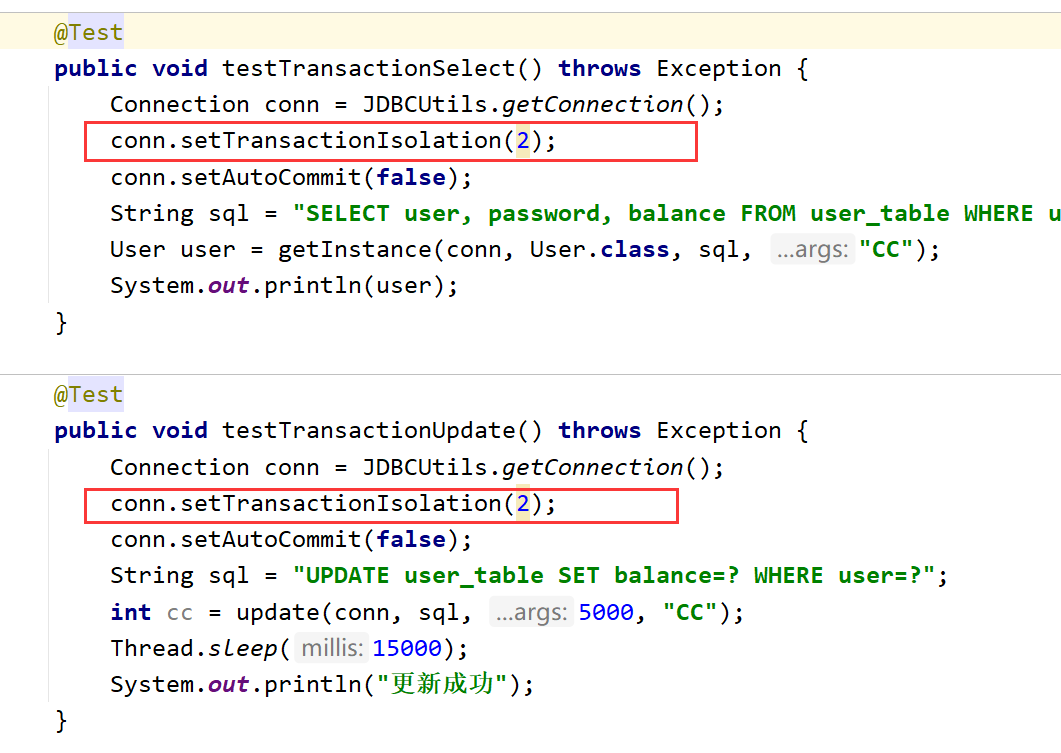
Generally, only the dirty reading problem needs to be solved, while the concurrency performance needs to be sacrificed to solve the non repeatable reading and phantom reading problems. Therefore, the latter two levels of repeatable read and serializable will not be demonstrated
8, Database connection pool
8.1 necessity of JDBC database connection pool
When developing web programs based on database, the traditional mode basically follows the following steps:
- Establish database connection in the main program (such as servlet and beans)
- Perform sql operations
- Disconnect database
The problems in this mode of development are as follows:
- It takes 1 to 05s to get the user name and password from the JDBC manager to connect to the database in memory every time (it takes 1 to 05s to get the user name and password from the JDBC manager to connect to the database). When you need a database Connection, ask for one from the database and disconnect it after execution. This way will consume a lot of resources and time. The Connection resources of the database have not been well reused. If hundreds or even thousands of people are online at the same time, frequent database Connection operation will occupy a lot of system resources, and even cause server crash.
- For each database connection, it must be disconnected after use. Otherwise, if the program fails to close due to exceptions, it will lead to memory leakage in the database system and eventually restart the database.
- This development cannot control the number of connection objects created, and system resources will be allocated without consideration. If there are too many connections, it may also lead to memory leakage and server crash.
8.2 database connection pool technology
In order to solve the problem of database connection in traditional development, database connection pool technology can be used.
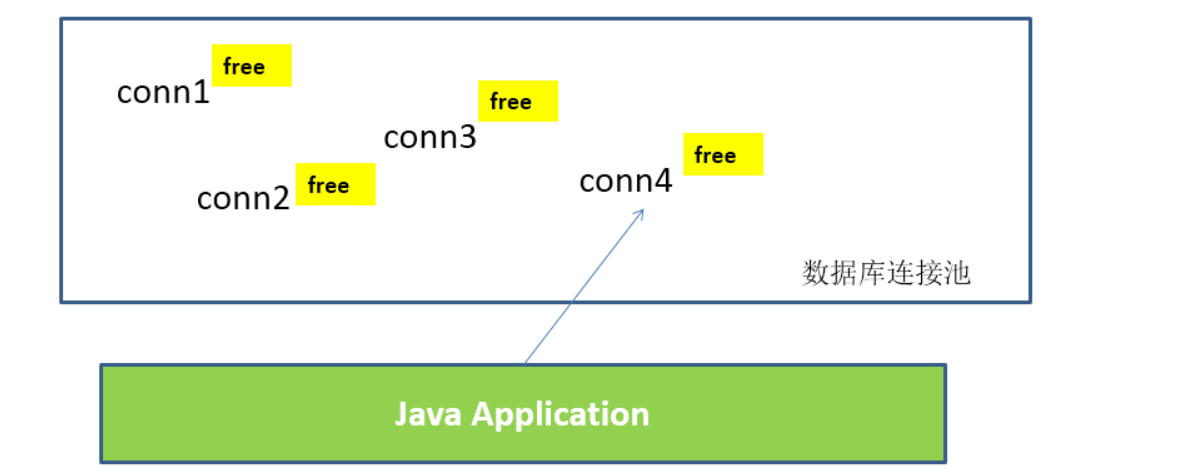
The basic idea of database connection pool is to establish a "buffer pool" for database connection. Put a certain number of connections into the buffer pool in advance. When you need to establish a database connection, just take one out of the "buffer pool" and put it back after use.
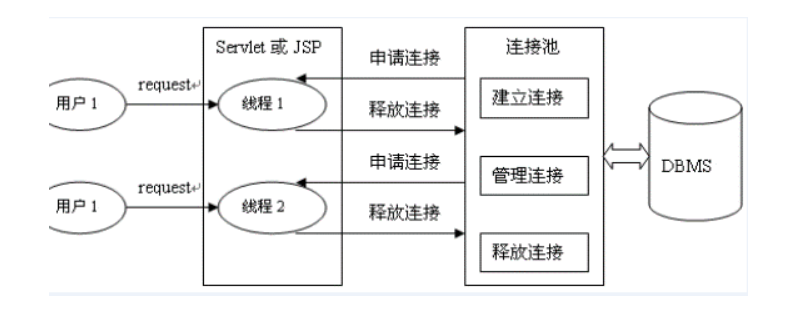
Database connection pool is responsible for allocating, managing and releasing database connections. It allows applications to reuse an existing database connection instead of re establishing one.
During initialization, the database connection pool will create a certain number of database connections into the connection pool. The number of these database connections is set by the minimum number of database connections. No matter whether these database connections are used or not, the connection pool will always ensure that there are at least so many connections. The maximum number of database connections in the connection pool limits the maximum number of connections that the connection pool can occupy. When the number of connections requested by the application from the connection pool exceeds the maximum number of connections, these requests will be added to the waiting queue.
working principle:
The database connection pool of JDBC uses javax sql. DataSource means that DataSource is just an interface, which is usually implemented by servers (Weblogic, WebSphere, Tomcat) and also provided by some open source organizations:
- DBCP is a database connection pool provided by Apache. The tomcat server has its own DBCP database connection pool. The speed is relatively c3p0 fast, but hibernate 3 no longer provides support due to its own BUG.
- C3P0 is a database connection pool provided by an open source organization, which is relatively slow and stable. hibernate is officially recommended
- Proxool is an open source project database connection pool under sourceforge. It has the function of monitoring the status of the connection pool, and its stability is c3p0 poor
- BoneCP is a database connection pool provided by an open source organization with high speed
- Druid is a database connection pool provided by Alibaba. It is said to be a database connection pool integrating the advantages of DBCP, C3P0 and Proxool. However, it is uncertain whether it is faster than BoneCP
DataSource is usually called data source, which includes two parts: connection pool and connection pool management. Traditionally, DataSource is often called connection pool
DataSource is used to replace DriverManager to obtain Connection, which is fast and can greatly improve database access speed.
Special attention:
- Data source is different from database connection. There is no need to create multiple data sources. It is the factory that generates database connection. Therefore, the whole application only needs one data source.
- When the database access is finished, the program closes the database connection as before: conn.close(); However, conn.close () does not close the physical connection of the database. It only releases the database connection and returns it to the database connection pool.
8.2.1 Druid database connection pool
Since the use of database connection pool is a routine, the most commonly used Druid database connection pool is used here
Druid is a database connection pool implementation on Alibaba's open source platform. It combines the advantages of C3P0, DBCP, Proxool and other DB pools, and adds log monitoring. It can well monitor the connection of DB pool and the execution of SQL. It can be said that it is a DB connection pool for monitoring, which can be said to be one of the best connection pools at present.
Detailed configuration parameters:
| to configure | default | explain |
|---|---|---|
| name | The significance of configuring this attribute is that if there are multiple data sources, they can be distinguished by name during monitoring. If there is no configuration, a name will be generated in the format of "DataSource -" + system identityHashCode(this) | |
| url | The url to connect to the database is different from database to database. For example: MySQL: JDBC: mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | User name to connect to the database | |
| password | Password to connect to the database. If you don't want the password written directly in the configuration file, you can use ConfigFilter. See here for details: https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter | |
| driverClassName | Automatic identification according to url is optional. If druid is not configured, dbType will be automatically identified according to url, and then corresponding driverclassname will be selected (under recommended configuration) | |
| initialSize | 0 | The number of physical connections established during initialization. Initialization occurs when the display calls the init method or the first getConnection |
| maxActive | 8 | Maximum number of connection pools |
| maxIdle | 8 | It is no longer used, and the configuration has no effect |
| minIdle | Minimum number of connection pools | |
| maxWait | The maximum waiting time to get a connection, in milliseconds. After maxWait is configured, the fair lock is enabled by default, and the concurrency efficiency will be reduced. If necessary, you can use the unfair lock by configuring the useUnfairLock attribute to true. | |
| poolPreparedStatements | false | Whether to cache preparedStatement, that is, PSCache. PSCache greatly improves the performance of databases that support cursors, such as oracle. It is recommended to close under mysql. |
| maxOpenPreparedStatements | -1 | To enable PSCache, it must be configured to be greater than 0. When greater than 0, poolPreparedStatements will be automatically triggered and modified to true. In Druid, there will be no problem that PSCache in Oracle occupies too much memory. You can configure this value to be larger, such as 100 |
| validationQuery | The sql used to check whether the connection is valid requires a query statement. If validationQuery is null, testonmirror, testOnReturn and testwhiteidle will not work. | |
| testOnBorrow | true | When applying for a connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance |
| testOnReturn | false | When returning the connection, execute validationQuery to check whether the connection is valid. This configuration will reduce the performance |
| testWhileIdle | false | It is recommended to configure to true, which will not affect performance and ensure security. Check when applying for connection. If the idle time is greater than timebetween evictionrunsmillis, execute validationQuery to check whether the connection is valid. |
| timeBetweenEvictionRunsMillis | It has two meanings: 1) the destroy thread will detect the connection interval; 2) the judgment basis of testwhiteidle. See the description of testwhiteidle attribute for details | |
| numTestsPerEvictionRun | No longer used, a DruidDataSource only supports one EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | sql executed during physical connection initialization | |
| exceptionSorter | According to dbType, the connection will be discarded when the database throws some unrecoverable exceptions | |
| filters | The attribute type is string. The extension plug-ins are configured by alias. The commonly used plug-ins are: filter for monitoring statistics: stat, filter for log: log4j, filter for defending sql injection: wall | |
| proxyFilters | The type is List. If filters and proxyFilters are configured at the same time, it is a combination relationship, not a replacement relationship |
The configuration file created under src is: [druid.properties]
url=jdbc:mysql://localhost:3306/test username=root password=12345 driverClassName=com.mysql.jdbc.Driver initialSize=10 maxActive=10
Obtain the data source through the static method of DruidDataSourceFactory factory class. The static method needs to pass in a properties parameter. Properties is used to load configuration information, including connection database information and initialization connection pool information
@Test
public void testGetConnection() throws Exception {
Properties pro = new Properties();
// Use getResourceAsStream of the system loader to load the configuration file
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
pro.load(is);
// Call factory class to get data source
DataSource dataSource = DruidDataSourceFactory.createDataSource(pro);
Connection conn = dataSource.getConnection();
System.out.println(conn);
}
8.3 replace DriverManager with Druid connection pool to obtain connection
Previously, we obtained the database connection through DriverManager. The main disadvantage is that we have to make a connection each time we use it
After using the connection pool, each connection used is obtained from the pool. When no connection is needed, the program still closes the database connection as before: conn.close(); However, conn.close () does not close the physical connection of the database. It only releases the database connection and returns it to the database connection pool.
Replace JDBC utils. With a druid connection pool Java to obtain the database connection, as follows
//Create a Druid database connection pool
private static DataSource ds = null;
static {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
try {
pros.load(is);
ds = DruidDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws Exception {
return ds.getConnection();
}
9, Implementation of CRUD with Apache dbutils
Commons dbutils is an open source JDBC tool class library provided by Apache organization. It is a simple encapsulation of JDBC and has very low learning cost. Using dbutils can greatly simplify the workload of JDBC coding without affecting the performance of the program.
9.1 introduction to main API
Tools: org apache. commons. dbutils. DbUtils
DbUtils: provides tool classes for routine work such as closing connections and loading JDBC drivers. All methods in them are static. The main methods are as follows:
- public static void close(…) throws java.sql.SQLException: the DbUtils class provides three overloaded shutdown methods. These methods check whether the supplied parameter is NULL, and if not, they close the Connection, Statement and ResultSet.
- Public static void closequiet (...): this kind of method can not only avoid closing when the Connection, Statement and ResultSet are NULL, but also hide some SQLEeception thrown in the program.
- public static void commitAndClose(Connection conn)throws SQLException: used to commit the connected transaction and then close the connection
- Public static void commitandclosequiet (connection conn): used to submit a connection and then close the connection. SQL exceptions are not thrown when closing the connection.
- public static void rollback(Connection conn)throws SQLException: conn is allowed to be null because a judgment is made inside the method
- public static void rollbackAndClose(Connection conn)throws SQLException
- rollbackAndCloseQuietly(Connection)
- public static boolean loadDriver(java.lang.String driverClassName): this party loads and registers the JDBC driver, and returns true if successful. Using this method, you do not need to catch this exception ClassNotFoundException.
org.apache.commons.dbutils.QueryRunner
This class simplifies SQL query. It can be used together with ResultSetHandler to complete most database operations and greatly reduce the amount of coding.
The QueryRunner class provides two constructors:
- Default constructor
- You need a javax sql. Datasource is used as the constructor of parameters
Main methods of QueryRunner class:
- to update
- public int update(Connection conn, String sql, Object... params) throws SQLException: used to perform an update (insert, update or delete) operation.
- insert
- public T insert(Connection conn,String sql,ResultSetHandler rsh, Object... params) throws SQLException: only INSERT statements are supported
- Batch processing
- public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: INSERT, UPDATE, or DELETE statements
- public T insertBatch(Connection conn,String sql,ResultSetHandler rsh,Object[][] params)throws SQLException: only INSERT statements are supported
- query
- public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throws SQLException: executes a query operation. In this query, each element value in the object array is used as the replacement parameter of the query statement. This method handles the creation and closing of PreparedStatement and ResultSet by itself.
org.apache.commons.dbutils.ResultSetHandler
This interface is used to process Java sql. Resultset to convert the data into another form as required.
The ResultSetHandler interface provides a separate method: object handle (Java. SQL. Resultset. RS).
Main implementation classes of the interface:
- ArrayHandler: converts the first row of data in the result set into an object array.
- ArrayListHandler: convert each row of data in the result set into an array and store it in the List.
- BeanHandler: encapsulate the first row of data in the result set into a corresponding JavaBean instance.
- BeanListHandler: encapsulate each row of data in the result set into a corresponding JavaBean instance and store it in the List.
- ColumnListHandler: store the data of a column in the result set into the List.
- KeyedHandler(name): encapsulate each row of data in the result set into a map, and then save these maps into a map. The key is the specified key.
- MapHandler: encapsulate the first row of data in the result set into a Map. key is the column name and value is the corresponding value.
- MapListHandler: encapsulate each row of data in the result set into a Map, and then store it in the List
- ScalarHandler: query a single value object
9.2 replace JDBC utils with DbUtils Java close resource
In the previous operation of closing resources by JDBC utils tool class, you can use dbutils tool class to replace it, as follows
public static void closeResource(Connection conn, Statement stat, ResultSet rs) {
DbUtils.closeQuietly(conn);
DbUtils.closeQuietly(stat);
DbUtils.closeQuietly(rs);
}
After using the DbUtils tool class, you don't need to catch exceptions and judge whether the resource is null. Check the source code. In fact, it helped me with everything we did before

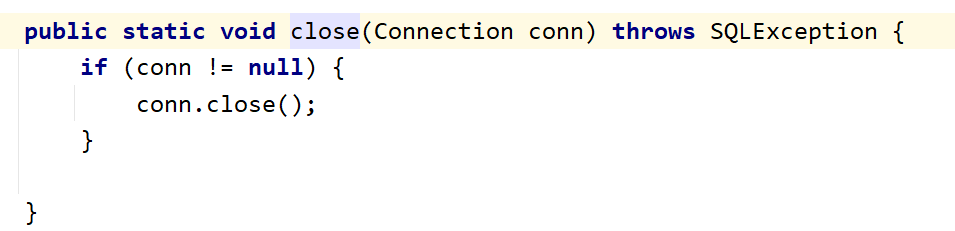
9.2 use QueryRunner class to replace general addition, deletion, modification and query
For the general operations of adding, deleting, modifying and querying previously written, you can use QueryRunner related methods to replace adding, deleting, modifying and querying
Use the update method of QueryRunner class to replace the general addition, deletion and modification operations, as follows
@Test
public void testCommonUpdate() {
Connection conn = null;
try {
QueryRunner qr = new QueryRunner();
conn = JDBCUtils.getConnection();
String sql = "update `order` set order_name=? where order_id=?";
qr.update(conn, sql, "BB" , "2");
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
By looking at the source code, we can know that the core code of update is the same as that written by ourselves. The difference is that it is more robust
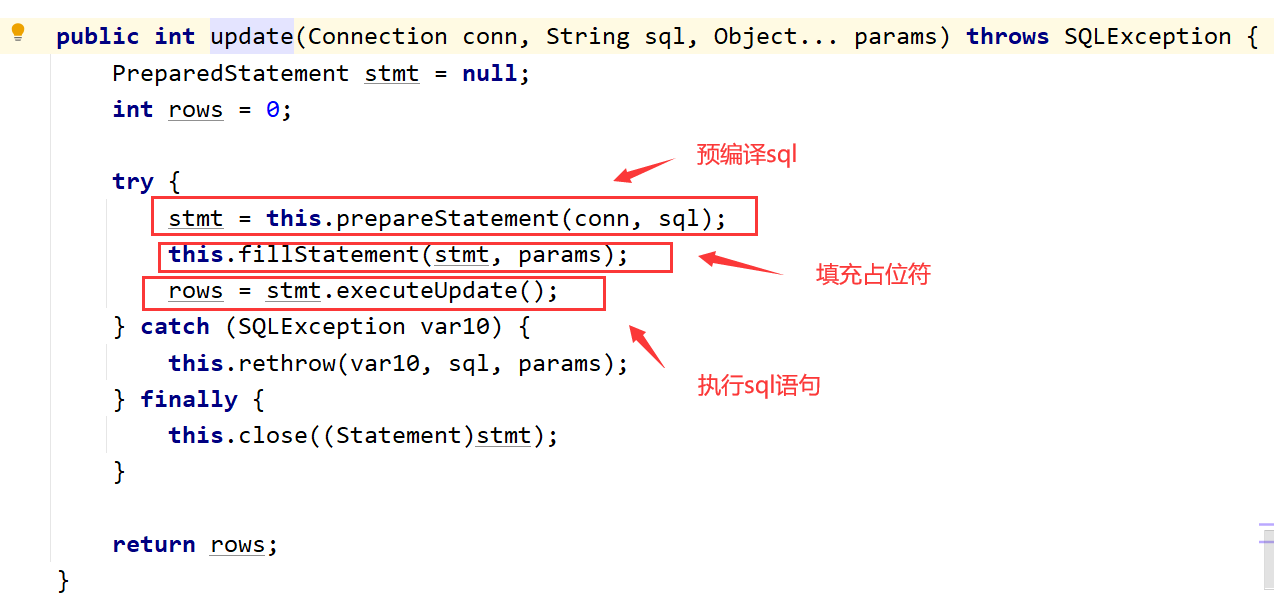


Replace the general query operation with the query method of QueryRunner class, as follows
/*
* BeanHander:Is the implementation class of ResultSetHandler interface, which is used to encapsulate a record in the table.
*/
@Test
public void testGetInstance() {
Connection conn = null;
try {
QueryRunner qr = new QueryRunner();
conn = JDBCUtils.getConnection();
String sql = "SELECT id,name,email,birth FROM customers WHERE id=?";
BeanHandler<Customers> bh = new BeanHandler<>(Customers.class);
Customers customers = qr.query(conn, sql, bh, 1);
System.out.println(customers);
sql = "SELECT order_id as orderId,order_name as orderName,order_date as orderDate FROM `order` WHERE order_id=?";
BeanHandler<Order> bh1 = new BeanHandler<>(Order.class);
Order order = qr.query(conn, sql, bh1, 1);
System.out.println(order);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn ,null, null);
}
}
/*
* BeanListHandler:It is the implementation class of ResultSetHandler interface, which is used to encapsulate the collection composed of multiple records in the table.
*/
@Test
public void testGetForList() {
Connection conn = null;
try {
QueryRunner qr = new QueryRunner();
conn = JDBCUtils.getConnection();
String sql = "SELECT id,name,email,birth FROM customers WHERE id<?";
BeanListHandler<Customers> blh = new BeanListHandler<>(Customers.class);
List<Customers> customersList = qr.query(conn, sql, blh, 12);
customersList.forEach(System.out::println);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
10, Dao design pattern
DAO(Data Access Object) is called data access object. DAO design pattern can realize the separation of business logic and data access logic in the application using database, so as to simplify the maintenance of the application. It improves the flexibility of the application by encapsulating the data access implementation (usually using JDBC Technology) in Dao class
There are many variations in Dao mode. Here is a relatively simple form. First, define a BaseDao abstract class and declare a general addition, deletion, modification and query method. You can use Apache dbutils
Then define an interface for the persistence operation of each entity. For example, the CustomersDao interface is responsible for the persistence of Customers objects, and the UserDao interface is responsible for the persistence of User objects. Finally, define the implementation classes of these interfaces, and the implementation classes inherit the BaseDao abstract class. Therefore, you can use the general addition, deletion, modification and query methods defined by BaseDao
In the general query operation of BaseDao, the Class instance of a specific Class needs to be passed in, and the name of a specific entity Class appears, so it can be further optimized


First, declare BaseDao as a generic class

Then, when the subclass inherits BaseDao, it does not retain the generic type, but specifies the specific type
 And this type is exactly the parameter of the method we passed in, so how to get this type?
And this type is exactly the parameter of the method we passed in, so how to get this type?
You can use reflection, first call the getClass method of the implementation class to get the Class instance, then call the getGenericSuperClass method of the Class instance to get the generic class of the parent class, and finally call the generic getActualTypeArguments method to get the generic parameter array of the parent class.
This type exists in the non static method parameters, so the type must be confirmed before calling the method, so the operation to obtain this type can be declared in the non static code block
After optimization, the query operation does not need to pass in specific types, but is dynamically obtained through reflection


Complete code
BaseDao.java
// Define an inherited Dao that performs basic operations on the database
public abstract class BaseDao<T> {
// Define a variable to receive generic types
private Class<T> aClass = null;
// Get the Class object of T and get the type of generic type. The generic type is determined when it is inherited by subclasses
{
//Gets the generic type in the parent class inherited by the subclass of the current BaseDAO
Type gs = this.getClass().getGenericSuperclass();
ParameterizedType pt = (ParameterizedType) gs;
//Gets the generic parameter of the parent class
Type[] ata = pt.getActualTypeArguments();
//The first parameter of the generic
aClass = (Class<T>) ata[0];
}
// General addition, deletion and modification operations (considering transaction)
public int update(Connection conn, String sql, Object... args) { // The number of placeholders in sql is the same as the length of variable parameters!
int i = 0;
try {
QueryRunner qr = new QueryRunner();
i = qr.update(conn, sql, args);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return i;
}
// General query operation, which is used to return a record in the data table (considering the previous transaction)
public T getInstance(Connection conn, String sql, Object... args) {
T t = null;
try {
QueryRunner qr = new QueryRunner();
BeanHandler<T> bh = new BeanHandler<>(aClass);
t = qr.query(conn, sql, bh, args);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return t;
}
// General query operation, which is used to return the set composed of multiple records in the data table (considering the previous transaction)
public List<T> getForList(Connection conn, String sql, Object... args) {
List<T> list = null;
try {
QueryRunner qr = new QueryRunner();
BeanListHandler<T> blh = new BeanListHandler<>(aClass);
list = qr.query(conn, sql, blh, args);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return list;
}
//General method for querying special values
public <T> T getValue(Connection conn, String sql, Object... args) {
Object obj = null;
try {
QueryRunner qr = new QueryRunner();
ScalarHandler sh = new ScalarHandler();
obj = qr.query(conn, sql, sh, args);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return (T) obj;
}
}
The following gives the persistent interface and implementation class for the Customers object
CustomersDao.java
public interface CustomersDao {
// Add cust object to database
void addCus(Connection conn, Customers customers);
// Delete a record in cust table for the specified id
int deleteCusById(Connection conn, Integer id);
// For cust objects in memory, modify the records specified in the data table
int updateCus(Connection conn, Customers customers);
// Query the specified id to get the corresponding Customer object
Customers getCusById(Connection conn, Integer id);
// A collection of all records in the query table cust
List<Customers> getAllCus(Connection conn);
// Returns the number of data entries in the data table cust
Long getCount(Connection conn);
// Returns the largest birthday in cust
Date getMaxBirth(Connection conn);
}
Implementation class
CustomersDaoImpl.java
public class CustomersDaoImpl extends BaseDao<Customers> implements CustomersDao {
@Override
public void addCus(Connection conn, Customers customers) {
String sql = "INSERT INTO customers(name,email,birth) value(?,?,?)";
update(conn, sql, customers.getName(), customers.getEmail(), customers.getBirth());
}
@Override
public int deleteCusById(Connection conn, Integer id) {
String sql = "DELETE FROM customers WHERE id=?";
return update(conn, sql, id);
}
@Override
public int updateCus(Connection conn, Customers customers) {
String sql = "UPDATE customers SET name=?,email=?,birth=? WHERE id=?";
int i = update(conn, sql, customers.getName(), customers.getEmail(), customers.getBirth(), customers.getId());
return i;
}
@Override
public Customers getCusById(Connection conn, Integer id) {
String sql = "SELECT id,name,email,birth FROM customers WHERE id=?";
return getInstance(conn, sql, id);
}
@Override
public List<Customers> getAllCus(Connection conn) {
String sql = "SELECT id,name,email,birth FROM customers";
return getForList(conn, sql);
}
@Override
public Long getCount(Connection conn) {
String sql = "SELECT COUNT(*) FROM customers";
return getValue(conn, sql);
}
@Override
public Date getMaxBirth(Connection conn) {
String sql = "SELECT MAX(birth) FROM customers";
return getValue(conn, sql);
}
}
Using JUnit to automatically generate test classes
Create a test folder at the same level as src under the project, right-click test, and perform the following operations
Download the JUnitGenerator plug-in
Right click the class to be tested and perform the following operations

The test classes are as follows
class CustomersDaoImplTest {
CustomersDao customersDao = new CustomersDaoImpl();
@Test
void testAddCus() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
Customers customers = new Customers(1, "Monkey D Luffy", "lufei@163.com", new Date(13213123213L));
customersDao.addCus(conn, customers);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
@Test
void deleteCusById() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
int i = customersDao.deleteCusById(conn, 1);
System.out.println(i);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
@Test
void updateCus() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
Customers customers = new Customers(2, "Delireba", "dilireba@163.com", new Date(1312134213L));
int i = customersDao.updateCus(conn, customers);
System.out.println(i);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
@Test
void getCusById() throws Exception {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
Customers customers = customersDao.getCusById(conn, 2);
System.out.println(customers);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
@Test
void getAllCus() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
List<Customers> list = customersDao.getAllCus(conn);
list.forEach(System.out::println);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
@Test
void getCount() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
Long count = customersDao.getCount(conn);
System.out.println(count);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
@Test
void getMaxBirth() {
Connection conn = null;
try {
conn = JDBCUtils.getConnection();
Date maxBirth = customersDao.getMaxBirth(conn);
System.out.println(maxBirth);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
}